Compare commits
46 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
15ae312b37 | ||
|
|
6938b5b20e | ||
|
|
9b3b06ab04 | ||
|
|
e2a7c93753 | ||
|
|
34349aee0b | ||
|
|
8e79370e95 | ||
|
|
652c35322b | ||
|
|
e2fc57ac24 | ||
|
|
994fc7c828 | ||
|
|
b9a960d984 | ||
|
|
3baf260f4d | ||
|
|
d037ded146 | ||
|
|
622287f3da | ||
|
|
5d12bf74f6 | ||
|
|
c88f9321f5 | ||
|
|
f9f1d5c9fc | ||
|
|
0edec68376 | ||
|
|
ee63dc25f4 | ||
|
|
fee8fe73f2 | ||
|
|
1689f9e7e7 | ||
|
|
a1ed0cb2e9 | ||
|
|
5ee5fa7e6e | ||
|
|
d8c70453ec | ||
|
|
e930eb5967 | ||
|
|
aec6ad636a | ||
|
|
750c91bd3e | ||
|
|
fcc3886db1 | ||
|
|
22afc98be5 | ||
|
|
5b1a9448e6 | ||
|
|
07d89e3eeb | ||
|
|
96e97d9c1e | ||
|
|
bcb125e168 | ||
|
|
6fbb86667c | ||
|
|
2d545604f4 | ||
|
|
7210a7481e | ||
|
|
55210c89e2 | ||
|
|
c725d11dd9 | ||
|
|
ba2a6bd06c | ||
|
|
57b80c6ed0 | ||
|
|
115c59d5e1 | ||
|
|
543ff468b7 | ||
|
|
96ae47989e | ||
|
|
368932a610 | ||
|
|
f2cd531fcb | ||
|
|
511652b71c | ||
|
|
525fb132d6 |
6
.github/workflows/release.yml
vendored
6
.github/workflows/release.yml
vendored
@@ -83,6 +83,9 @@ jobs:
|
||||
go install github.com/wailsapp/wails/v2/cmd/wails@latest
|
||||
rm -rf ./backend-python/wkv_cuda_utils
|
||||
rm ./backend-python/get-pip.py
|
||||
sed -i '1,2d' ./backend-golang/wsl_not_windows.go
|
||||
rm ./backend-golang/wsl.go
|
||||
mv ./backend-golang/wsl_not_windows.go ./backend-golang/wsl.go
|
||||
make
|
||||
mv build/bin/RWKV-Runner build/bin/RWKV-Runner_linux_x64
|
||||
|
||||
@@ -102,6 +105,9 @@ jobs:
|
||||
go install github.com/wailsapp/wails/v2/cmd/wails@latest
|
||||
rm -rf ./backend-python/wkv_cuda_utils
|
||||
rm ./backend-python/get-pip.py
|
||||
sed -i '' '1,2d' ./backend-golang/wsl_not_windows.go
|
||||
rm ./backend-golang/wsl.go
|
||||
mv ./backend-golang/wsl_not_windows.go ./backend-golang/wsl.go
|
||||
make
|
||||
cp build/darwin/Readme_Install.txt build/bin/Readme_Install.txt
|
||||
cp build/bin/RWKV-Runner.app/Contents/MacOS/RWKV-Runner build/bin/RWKV-Runner_darwin_universal
|
||||
|
||||
@@ -1,6 +1,8 @@
|
||||
## Changes
|
||||
|
||||
- improve lora finetune process (need to be refactored)
|
||||
- fix always show `Convert Failed` when converting model
|
||||
- fix input with array type (#96, #107)
|
||||
- change chinese translation of `completion`
|
||||
|
||||
## Install
|
||||
|
||||
|
||||
32
README.md
32
README.md
@@ -49,7 +49,7 @@ English | [简体中文](README_ZH.md) | [日本語](README_JA.md)
|
||||
|
||||
#### Default configs has enabled custom CUDA kernel acceleration, which is much faster and consumes much less VRAM. If you encounter possible compatibility issues, go to the Configs page and turn off `Use Custom CUDA kernel to Accelerate`.
|
||||
|
||||
#### If Windows Defender claims this is a virus, you can try downloading [v1.0.8](https://github.com/josStorer/RWKV-Runner/releases/tag/v1.0.8)/[v1.0.9](https://github.com/josStorer/RWKV-Runner/releases/tag/v1.0.9) and letting it update automatically to the latest version, or add it to the trusted list.
|
||||
#### If Windows Defender claims this is a virus, you can try downloading [v1.3.7_win.zip](https://github.com/josStorer/RWKV-Runner/releases/download/v1.3.7/RWKV-Runner_win.zip) and letting it update automatically to the latest version, or add it to the trusted list.
|
||||
|
||||
#### For different tasks, adjusting API parameters can achieve better results. For example, for translation tasks, you can try setting Temperature to 1 and Top_P to 0.3.
|
||||
|
||||
@@ -64,6 +64,8 @@ English | [简体中文](README_ZH.md) | [日本語](README_JA.md)
|
||||
- Easy-to-understand and operate parameter configuration
|
||||
- Built-in model conversion tool
|
||||
- Built-in download management and remote model inspection
|
||||
- Built-in one-click LoRA Finetune
|
||||
- Can also be used as an OpenAI ChatGPT and GPT-Playground client
|
||||
- Multilingual localization
|
||||
- Theme switching
|
||||
- Automatic updates
|
||||
@@ -126,46 +128,44 @@ for i in np.argsort(embeddings_cos_sim)[::-1]:
|
||||
print(f"{embeddings_cos_sim[i]:.10f} - {values[i]}")
|
||||
```
|
||||
|
||||
## Todo
|
||||
|
||||
- [ ] Model training functionality
|
||||
- [x] CUDA operator int8 acceleration
|
||||
- [x] macOS support
|
||||
- [x] Linux support
|
||||
- [ ] Local State Cache DB
|
||||
|
||||
## Related Repositories:
|
||||
|
||||
- RWKV-4-World: https://huggingface.co/BlinkDL/rwkv-4-world/tree/main
|
||||
- RWKV-4-Raven: https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main
|
||||
- ChatRWKV: https://github.com/BlinkDL/ChatRWKV
|
||||
- RWKV-LM: https://github.com/BlinkDL/RWKV-LM
|
||||
- RWKV-LM-LoRA: https://github.com/Blealtan/RWKV-LM-LoRA
|
||||
|
||||
## Preview
|
||||
|
||||
### Homepage
|
||||
|
||||

|
||||

|
||||
|
||||
### Chat
|
||||
|
||||

|
||||
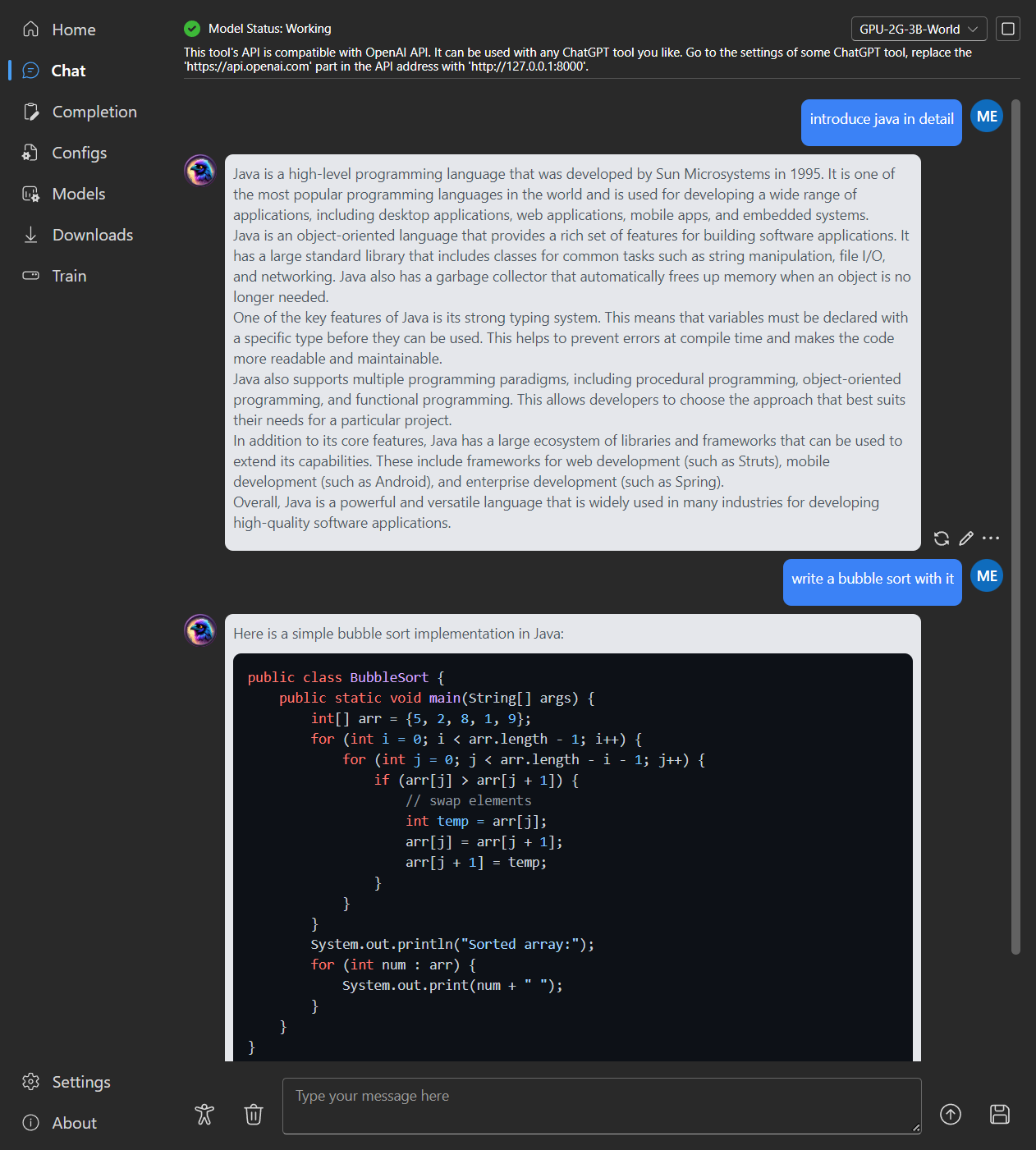
|
||||
|
||||
### Completion
|
||||
|
||||

|
||||
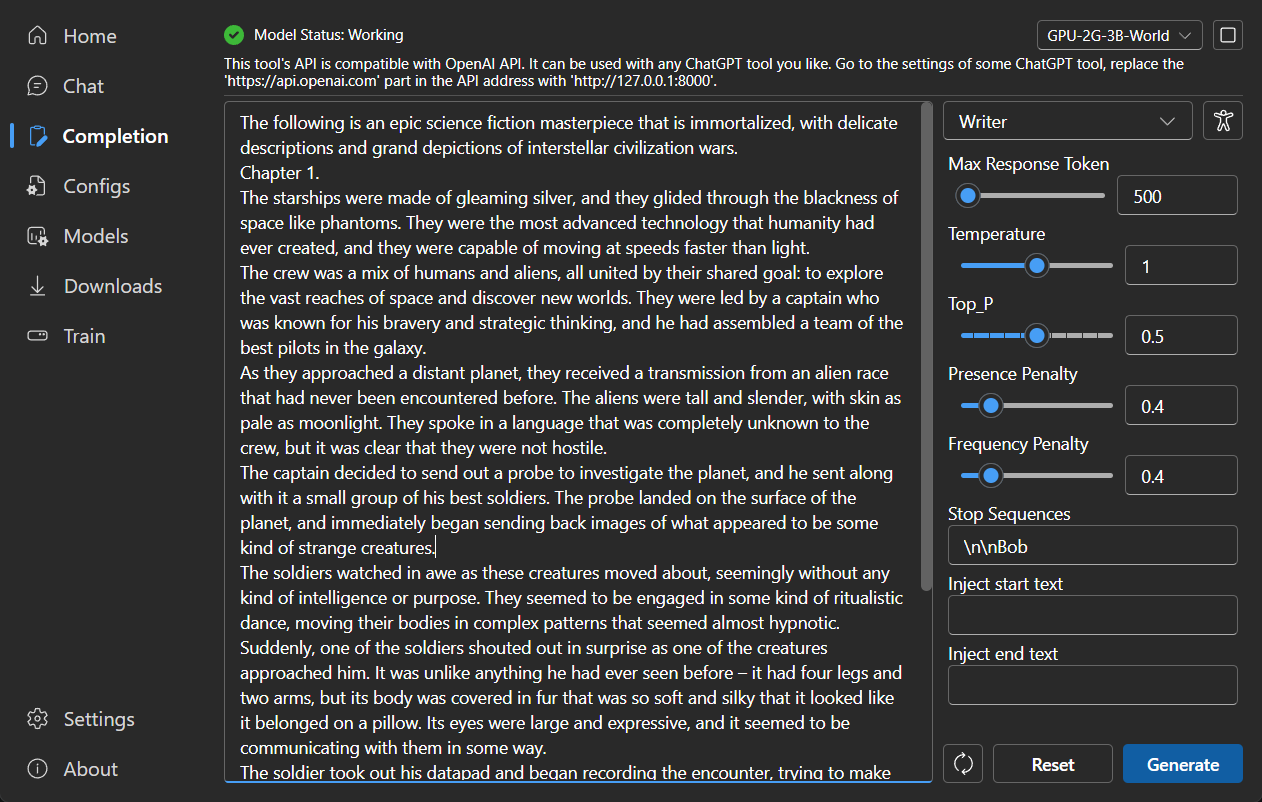
|
||||
|
||||
### Configuration
|
||||
|
||||

|
||||

|
||||
|
||||
### Model Management
|
||||
|
||||

|
||||

|
||||
|
||||
### Download Management
|
||||
|
||||

|
||||
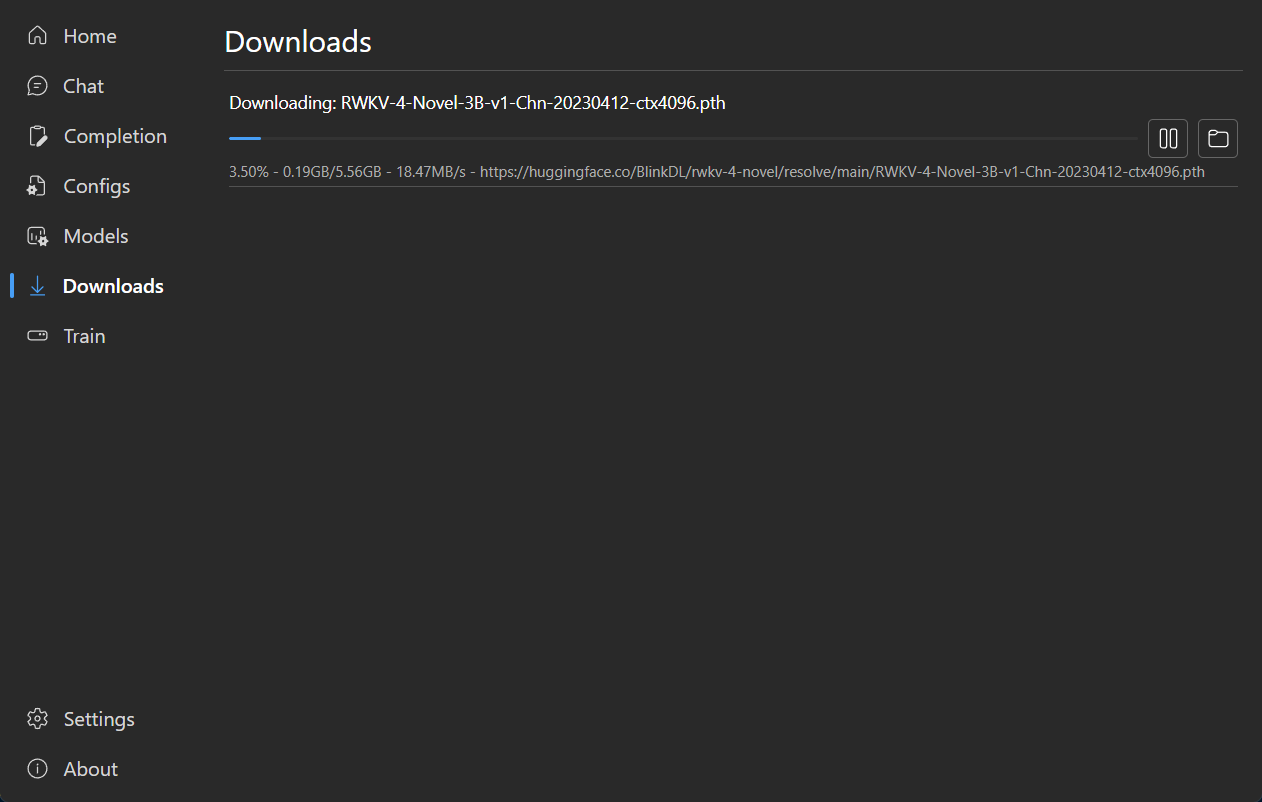
|
||||
|
||||
### LoRA Finetune
|
||||
|
||||
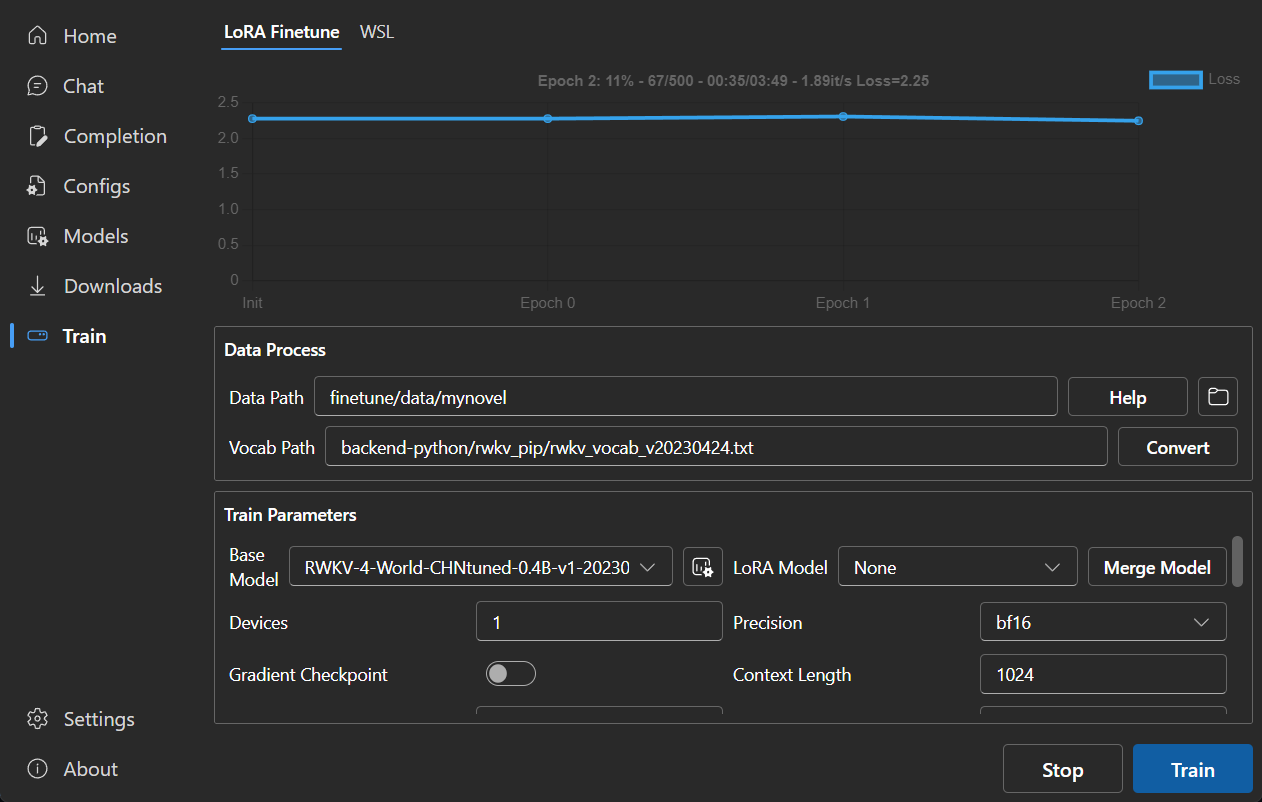
|
||||
|
||||
### Settings
|
||||
|
||||

|
||||
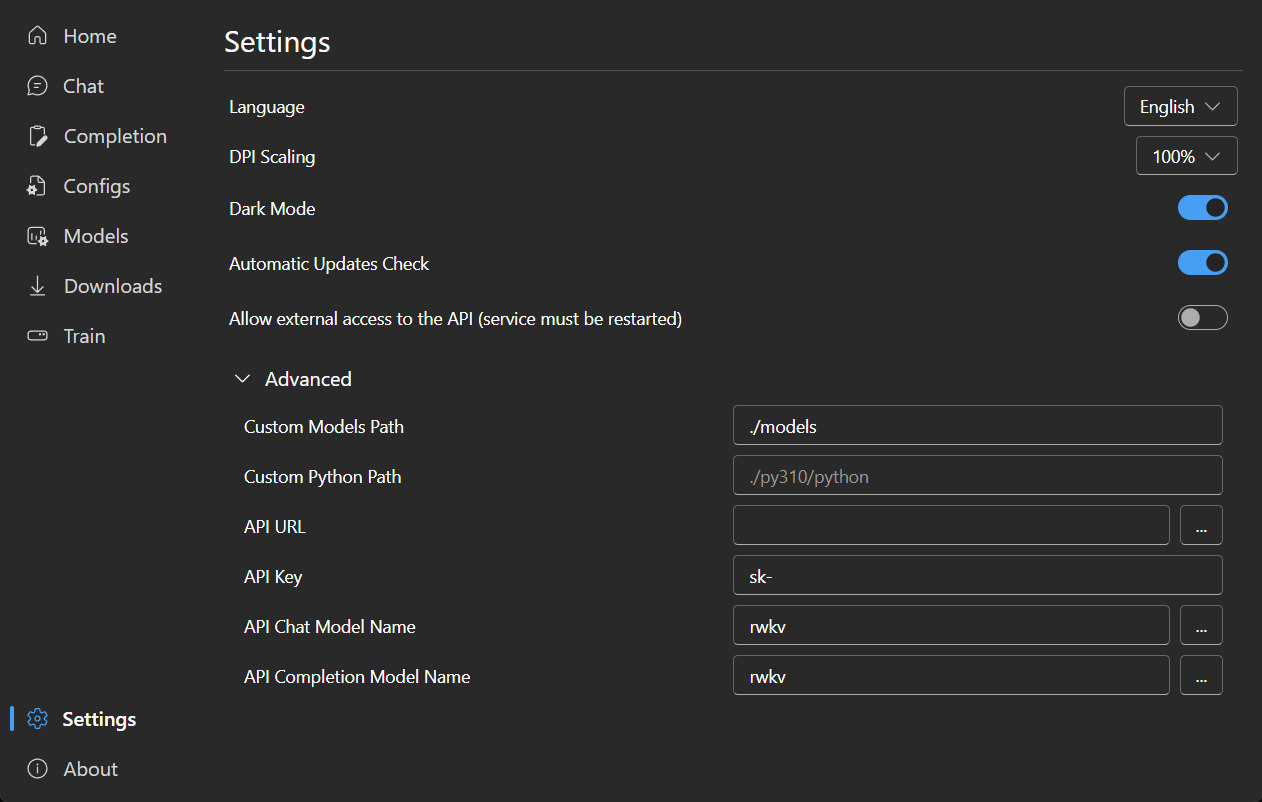
|
||||
|
||||
42
README_JA.md
42
README_JA.md
@@ -24,22 +24,32 @@
|
||||
[FAQs](https://github.com/josStorer/RWKV-Runner/wiki/FAQs) | [プレビュー](#Preview) | [ダウンロード][download-url] | [サーバーデプロイ例](https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples)
|
||||
|
||||
[license-image]: http://img.shields.io/badge/license-MIT-blue.svg
|
||||
|
||||
[license-url]: https://github.com/josStorer/RWKV-Runner/blob/master/LICENSE
|
||||
|
||||
[release-image]: https://img.shields.io/github/release/josStorer/RWKV-Runner.svg
|
||||
|
||||
[release-url]: https://github.com/josStorer/RWKV-Runner/releases/latest
|
||||
|
||||
[download-url]: https://github.com/josStorer/RWKV-Runner/releases
|
||||
|
||||
[Windows-image]: https://img.shields.io/badge/-Windows-blue?logo=windows
|
||||
|
||||
[Windows-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/windows/Readme_Install.txt
|
||||
|
||||
[MacOS-image]: https://img.shields.io/badge/-MacOS-black?logo=apple
|
||||
|
||||
[MacOS-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/darwin/Readme_Install.txt
|
||||
|
||||
[Linux-image]: https://img.shields.io/badge/-Linux-black?logo=linux
|
||||
|
||||
[Linux-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/linux/Readme_Install.txt
|
||||
|
||||
</div>
|
||||
|
||||
#### デフォルトの設定はカスタム CUDA カーネルアクセラレーションを有効にしています。互換性の問題が発生する可能性がある場合は、コンフィグページに移動し、`Use Custom CUDA kernel to Accelerate` をオフにしてください。
|
||||
|
||||
#### Windows Defender がこれをウイルスだと主張する場合は、[v1.0.8](https://github.com/josStorer/RWKV-Runner/releases/tag/v1.0.8) / [v1.0.9](https://github.com/josStorer/RWKV-Runner/releases/tag/v1.0.9) をダウンロードして最新版に自動更新させるか、信頼済みリストに追加してみてください。
|
||||
#### Windows Defender がこれをウイルスだと主張する場合は、[v1.3.7_win.zip](https://github.com/josStorer/RWKV-Runner/releases/download/v1.3.7/RWKV-Runner_win.zip) をダウンロードして最新版に自動更新させるか、信頼済みリストに追加してみてください。
|
||||
|
||||
#### 異なるタスクについては、API パラメータを調整することで、より良い結果を得ることができます。例えば、翻訳タスクの場合、Temperature を 1 に、Top_P を 0.3 に設定してみてください。
|
||||
|
||||
@@ -54,6 +64,8 @@
|
||||
- 分かりやすく操作しやすいパラメータ設定
|
||||
- 内蔵モデル変換ツール
|
||||
- ダウンロード管理とリモートモデル検査機能内蔵
|
||||
- 内蔵のLoRA微調整機能を搭載しています
|
||||
- このプログラムは、OpenAI ChatGPTとGPT Playgroundのクライアントとしても使用できます
|
||||
- 多言語ローカライズ
|
||||
- テーマ切り替え
|
||||
- 自動アップデート
|
||||
@@ -116,46 +128,44 @@ for i in np.argsort(embeddings_cos_sim)[::-1]:
|
||||
print(f"{embeddings_cos_sim[i]:.10f} - {values[i]}")
|
||||
```
|
||||
|
||||
## Todo
|
||||
|
||||
- [ ] モデル学習機能
|
||||
- [x] CUDA オペレータ int8 アクセラレーション
|
||||
- [x] macOS サポート
|
||||
- [x] Linux サポート
|
||||
- [ ] ローカルステートキャッシュ DB
|
||||
|
||||
## 関連リポジトリ:
|
||||
|
||||
- RWKV-4-World: https://huggingface.co/BlinkDL/rwkv-4-world/tree/main
|
||||
- RWKV-4-Raven: https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main
|
||||
- ChatRWKV: https://github.com/BlinkDL/ChatRWKV
|
||||
- RWKV-LM: https://github.com/BlinkDL/RWKV-LM
|
||||
- RWKV-LM-LoRA: https://github.com/Blealtan/RWKV-LM-LoRA
|
||||
|
||||
## プレビュー
|
||||
|
||||
### ホームページ
|
||||
|
||||

|
||||

|
||||
|
||||
### チャット
|
||||
|
||||

|
||||

|
||||
|
||||
### 補完
|
||||
|
||||

|
||||

|
||||
|
||||
### コンフィグ
|
||||
|
||||

|
||||

|
||||
|
||||
### モデル管理
|
||||
|
||||

|
||||

|
||||
|
||||
### ダウンロード管理
|
||||
|
||||

|
||||

|
||||
|
||||
### LoRA Finetune
|
||||
|
||||

|
||||
|
||||
### 設定
|
||||
|
||||

|
||||

|
||||
|
||||
40
README_ZH.md
40
README_ZH.md
@@ -20,7 +20,7 @@ API兼容的接口,这意味着一切ChatGPT客户端都是RWKV客户端。
|
||||
[![MacOS][MacOS-image]][MacOS-url]
|
||||
[![Linux][Linux-image]][Linux-url]
|
||||
|
||||
[视频演示](https://www.bilibili.com/video/BV1hM4y1v76R) | [疑难解答](https://www.bilibili.com/read/cv23921171) | [预览](#Preview) | [下载][download-url] | [懒人包](https://pan.baidu.com/s/1wchIUHgne3gncIiLIeKBEQ?pwd=1111) | [服务器部署示例](https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples)
|
||||
[视频演示](https://www.bilibili.com/video/BV1hM4y1v76R) | [疑难解答](https://www.bilibili.com/read/cv23921171) | [预览](#Preview) | [下载][download-url] | [懒人包](https://pan.baidu.com/s/1zdzZ_a0uM3gDqi6pXIZVAA?pwd=1111) | [服务器部署示例](https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples)
|
||||
|
||||
[license-image]: http://img.shields.io/badge/license-MIT-blue.svg
|
||||
|
||||
@@ -46,11 +46,9 @@ API兼容的接口,这意味着一切ChatGPT客户端都是RWKV客户端。
|
||||
|
||||
</div>
|
||||
|
||||
#### 注意 目前RWKV中文模型质量一般,推荐使用英文模型或World(全球语言)体验实际RWKV能力
|
||||
|
||||
#### 预设配置已经开启自定义CUDA算子加速,速度更快,且显存消耗更少。如果你遇到可能的兼容性问题,前往配置页面,关闭`使用自定义CUDA算子加速`
|
||||
|
||||
#### 如果Windows Defender说这是一个病毒,你可以尝试下载[v1.0.8](https://github.com/josStorer/RWKV-Runner/releases/tag/v1.0.8)/[v1.0.9](https://github.com/josStorer/RWKV-Runner/releases/tag/v1.0.9)然后让其自动更新到最新版,或添加信任
|
||||
#### 如果Windows Defender说这是一个病毒,你可以尝试下载[v1.3.7_win.zip](https://github.com/josStorer/RWKV-Runner/releases/download/v1.3.7/RWKV-Runner_win.zip),然后让其自动更新到最新版,或添加信任
|
||||
|
||||
#### 对于不同的任务,调整API参数会获得更好的效果,例如对于翻译任务,你可以尝试设置Temperature为1,Top_P为0.3
|
||||
|
||||
@@ -60,10 +58,12 @@ API兼容的接口,这意味着一切ChatGPT客户端都是RWKV客户端。
|
||||
- 与OpenAI API完全兼容,一切ChatGPT客户端,都是RWKV客户端。启动模型后,打开 http://127.0.0.1:8000/docs 查看详细内容
|
||||
- 全自动依赖安装,你只需要一个轻巧的可执行程序
|
||||
- 预设了2G至32G显存的配置,几乎在各种电脑上工作良好
|
||||
- 自带用户友好的聊天和补全交互页面
|
||||
- 自带用户友好的聊天和续写交互页面
|
||||
- 易于理解和操作的参数配置
|
||||
- 内置模型转换工具
|
||||
- 内置下载管理和远程模型检视
|
||||
- 内置一键LoRA微调
|
||||
- 也可用作 OpenAI ChatGPT 和 GPT Playground 客户端
|
||||
- 多语言本地化
|
||||
- 主题切换
|
||||
- 自动更新
|
||||
@@ -126,46 +126,44 @@ for i in np.argsort(embeddings_cos_sim)[::-1]:
|
||||
print(f"{embeddings_cos_sim[i]:.10f} - {values[i]}")
|
||||
```
|
||||
|
||||
## Todo
|
||||
|
||||
- [ ] 模型训练功能
|
||||
- [x] CUDA算子int8提速
|
||||
- [x] macOS支持
|
||||
- [x] linux支持
|
||||
- [ ] 本地状态缓存数据库
|
||||
|
||||
## 相关仓库:
|
||||
|
||||
- RWKV-4-World: https://huggingface.co/BlinkDL/rwkv-4-world/tree/main
|
||||
- RWKV-4-Raven: https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main
|
||||
- ChatRWKV: https://github.com/BlinkDL/ChatRWKV
|
||||
- RWKV-LM: https://github.com/BlinkDL/RWKV-LM
|
||||
- RWKV-LM-LoRA: https://github.com/Blealtan/RWKV-LM-LoRA
|
||||
|
||||
## Preview
|
||||
|
||||
### 主页
|
||||
|
||||

|
||||

|
||||
|
||||
### 聊天
|
||||
|
||||

|
||||
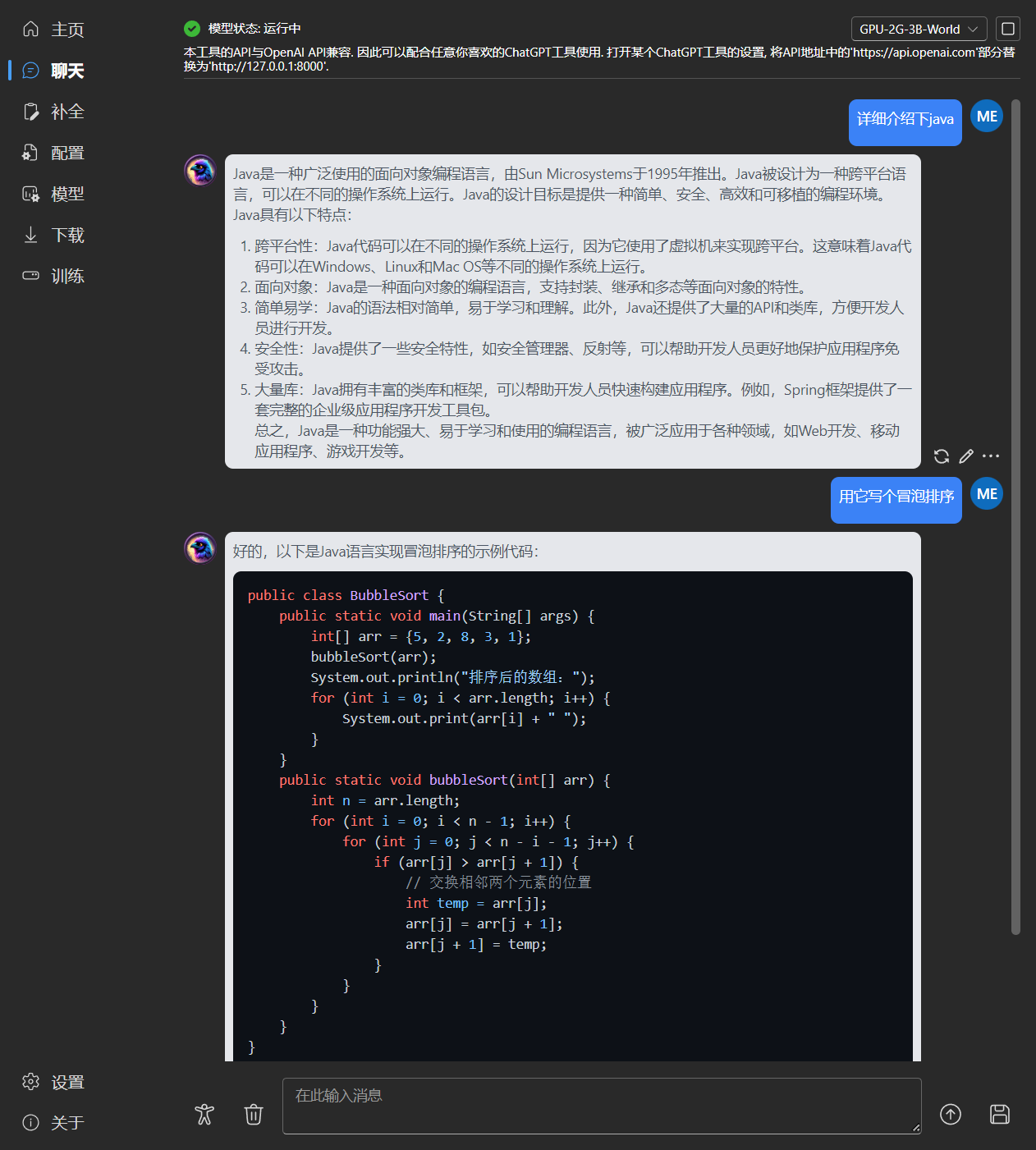
|
||||
|
||||
### 补全
|
||||
### 续写
|
||||
|
||||

|
||||
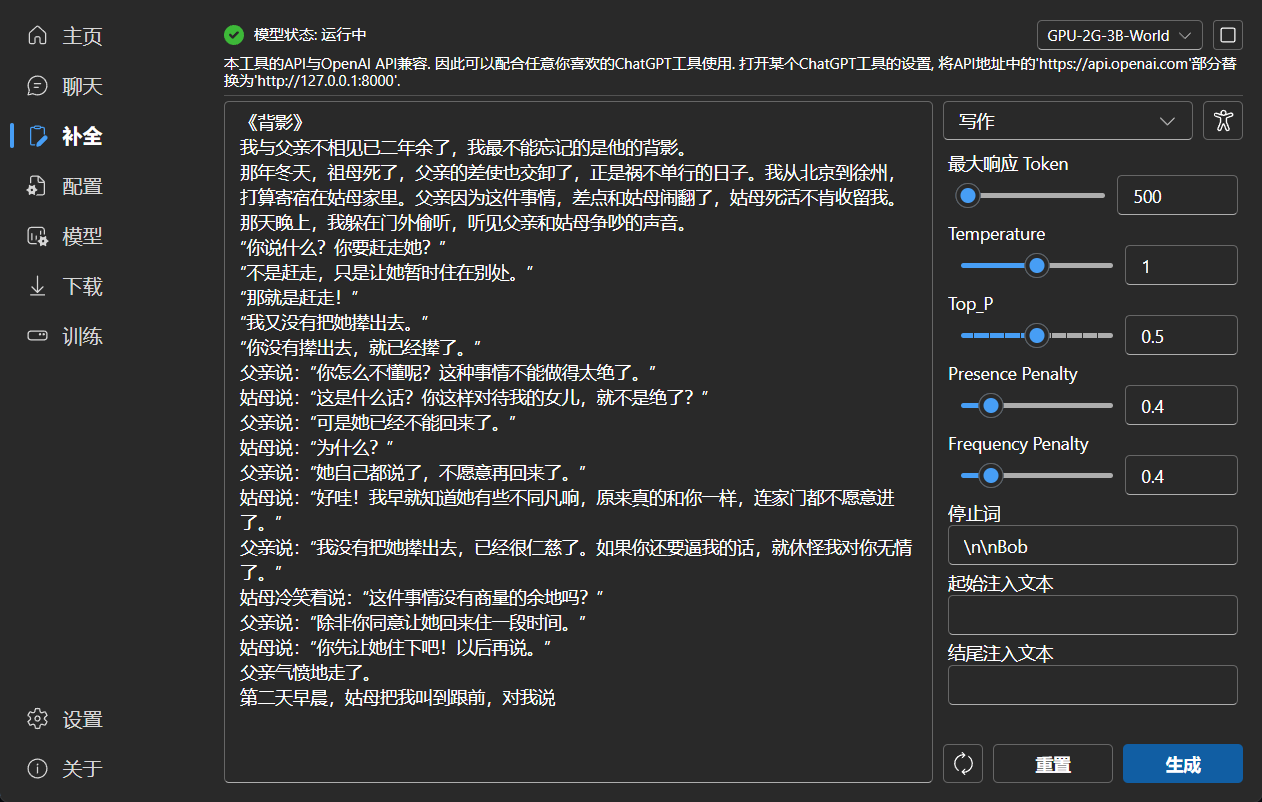
|
||||
|
||||
### 配置
|
||||
|
||||

|
||||

|
||||
|
||||
### 模型管理
|
||||
|
||||

|
||||

|
||||
|
||||
### 下载管理
|
||||
|
||||

|
||||
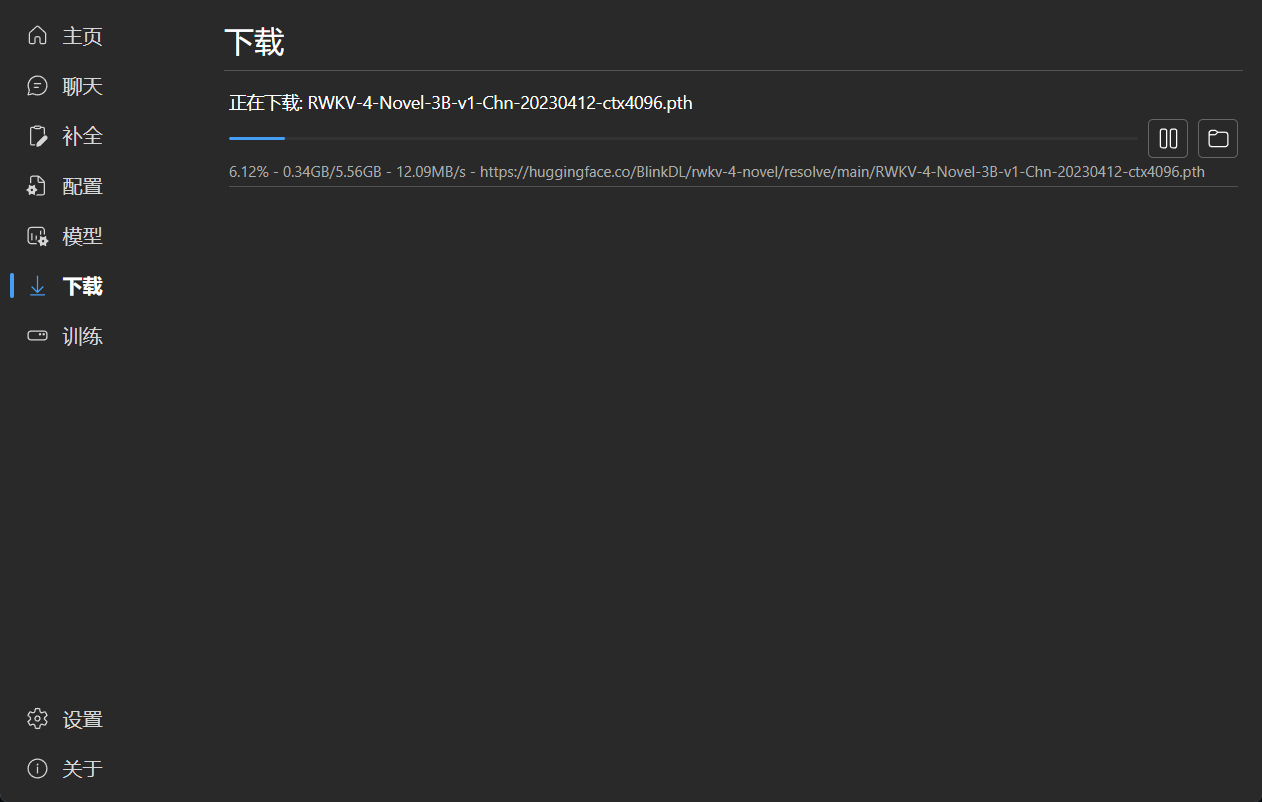
|
||||
|
||||
### LoRA微调
|
||||
|
||||
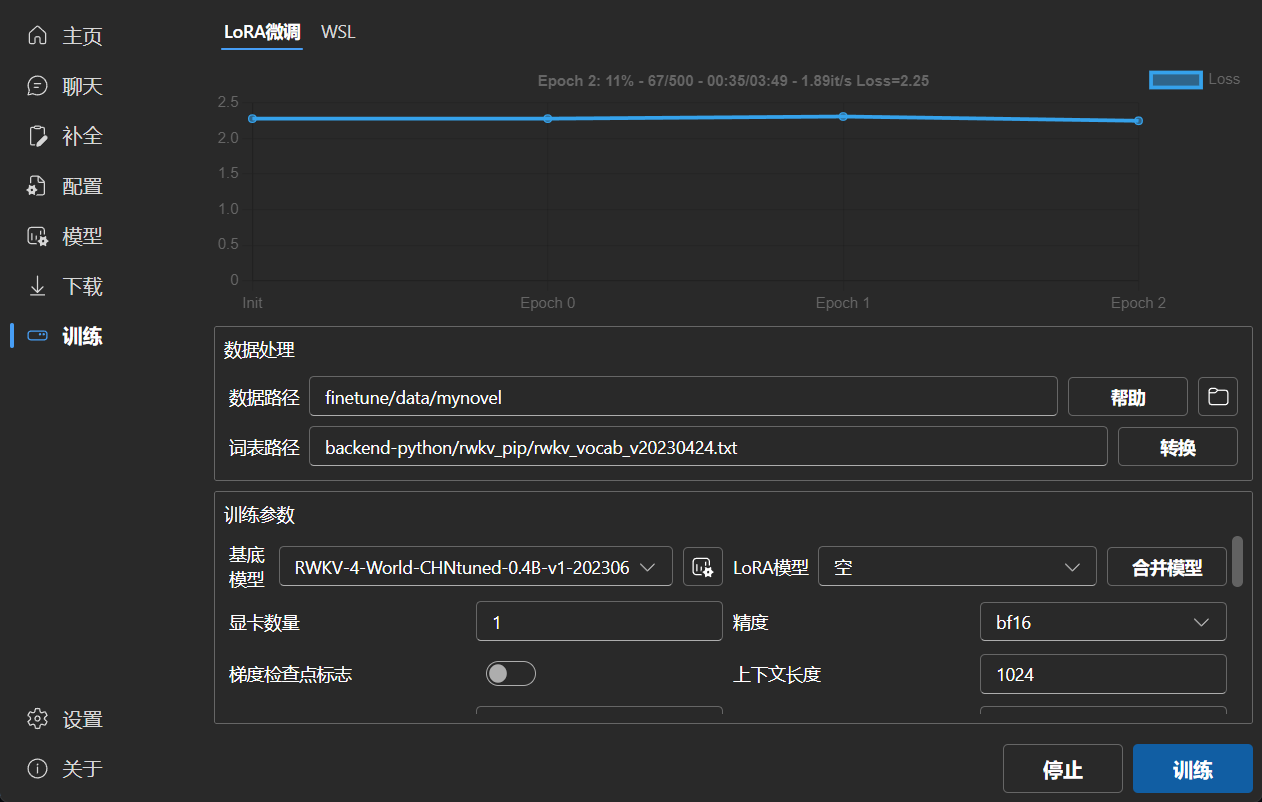
|
||||
|
||||
### 设置
|
||||
|
||||

|
||||
|
||||
|
||||
@@ -41,6 +41,14 @@ func (a *App) OnStartup(ctx context.Context) {
|
||||
a.cmdPrefix = "cd " + a.exDir + " && "
|
||||
}
|
||||
|
||||
os.Mkdir(a.exDir+"models", os.ModePerm)
|
||||
os.Mkdir(a.exDir+"lora-models", os.ModePerm)
|
||||
os.Mkdir(a.exDir+"finetune/json2binidx_tool/data", os.ModePerm)
|
||||
f, err := os.Create(a.exDir + "lora-models/train_log.txt")
|
||||
if err == nil {
|
||||
f.Close()
|
||||
}
|
||||
|
||||
a.downloadLoop()
|
||||
|
||||
watcher, err := fsnotify.NewWatcher()
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
package backend_golang
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"errors"
|
||||
"os"
|
||||
"os/exec"
|
||||
@@ -43,6 +44,39 @@ func (a *App) ConvertData(python string, input string, outputPrefix string, voca
|
||||
if strings.Contains(vocab, "rwkv_vocab_v20230424") {
|
||||
tokenizerType = "RWKVTokenizer"
|
||||
}
|
||||
|
||||
input = strings.TrimSuffix(input, "/")
|
||||
if fi, err := os.Stat(input); err == nil && fi.IsDir() {
|
||||
files, err := os.ReadDir(input)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
jsonlFile, err := os.Create(outputPrefix + ".jsonl")
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
defer jsonlFile.Close()
|
||||
for _, file := range files {
|
||||
if file.IsDir() || !strings.HasSuffix(file.Name(), ".txt") {
|
||||
continue
|
||||
}
|
||||
textContent, err := os.ReadFile(input + "/" + file.Name())
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
textJson, err := json.Marshal(map[string]string{"text": strings.ReplaceAll(strings.ReplaceAll(string(textContent), "\r\n", "\n"), "\r", "\n")})
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if _, err := jsonlFile.WriteString(string(textJson) + "\n"); err != nil {
|
||||
return "", err
|
||||
}
|
||||
}
|
||||
input = outputPrefix + ".jsonl"
|
||||
} else if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
return Cmd(python, "./finetune/json2binidx_tool/tools/preprocess_data.py", "--input", input, "--output-prefix", outputPrefix, "--vocab", vocab,
|
||||
"--tokenizer-type", tokenizerType, "--dataset-impl", "mmap", "--append-eod")
|
||||
}
|
||||
@@ -113,3 +147,11 @@ func (a *App) InstallPyDep(python string, cnMirror bool) (string, error) {
|
||||
return Cmd(python, "-m", "pip", "install", "-r", "./backend-python/requirements_without_cyac.txt")
|
||||
}
|
||||
}
|
||||
|
||||
func (a *App) GetPyError() string {
|
||||
content, err := os.ReadFile("./error.txt")
|
||||
if err != nil {
|
||||
return ""
|
||||
}
|
||||
return string(content)
|
||||
}
|
||||
|
||||
@@ -119,8 +119,10 @@ func (a *App) WslStop() error {
|
||||
if !running {
|
||||
return errors.New("wsl not running")
|
||||
}
|
||||
err = cmd.Process.Kill()
|
||||
cmd = nil
|
||||
if cmd != nil {
|
||||
err = cmd.Process.Kill()
|
||||
cmd = nil
|
||||
}
|
||||
// stdin.Close()
|
||||
stdin = nil
|
||||
distro = nil
|
||||
|
||||
22
backend-python/convert_model.py
vendored
22
backend-python/convert_model.py
vendored
@@ -219,13 +219,17 @@ def get_args():
|
||||
return p.parse_args()
|
||||
|
||||
|
||||
args = get_args()
|
||||
if not args.quiet:
|
||||
print(f"** {args}")
|
||||
try:
|
||||
args = get_args()
|
||||
if not args.quiet:
|
||||
print(f"** {args}")
|
||||
|
||||
RWKV(
|
||||
getattr(args, "in"),
|
||||
args.strategy,
|
||||
verbose=not args.quiet,
|
||||
convert_and_save_and_exit=args.out,
|
||||
)
|
||||
RWKV(
|
||||
getattr(args, "in"),
|
||||
args.strategy,
|
||||
verbose=not args.quiet,
|
||||
convert_and_save_and_exit=args.out,
|
||||
)
|
||||
except Exception as e:
|
||||
with open("error.txt", "w") as f:
|
||||
f.write(str(e))
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
import asyncio
|
||||
import json
|
||||
from threading import Lock
|
||||
from typing import List
|
||||
from typing import List, Union
|
||||
import base64
|
||||
|
||||
from fastapi import APIRouter, Request, status, HTTPException
|
||||
@@ -44,7 +44,7 @@ class ChatCompletionBody(ModelConfigBody):
|
||||
|
||||
|
||||
class CompletionBody(ModelConfigBody):
|
||||
prompt: str
|
||||
prompt: Union[str, List[str]]
|
||||
model: str = "rwkv"
|
||||
stream: bool = False
|
||||
stop: str = None
|
||||
@@ -306,9 +306,12 @@ async def completions(body: CompletionBody, request: Request):
|
||||
if model is None:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "model not loaded")
|
||||
|
||||
if body.prompt is None or body.prompt == "":
|
||||
if body.prompt is None or body.prompt == "" or body.prompt == []:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "prompt not found")
|
||||
|
||||
if type(body.prompt) == list:
|
||||
body.prompt = body.prompt[0] # TODO: support multiple prompts
|
||||
|
||||
if body.stream:
|
||||
return EventSourceResponse(
|
||||
eval_rwkv(model, request, body, body.prompt, body.stream, body.stop, False)
|
||||
@@ -323,7 +326,7 @@ async def completions(body: CompletionBody, request: Request):
|
||||
|
||||
|
||||
class EmbeddingsBody(BaseModel):
|
||||
input: str or List[str] or List[List[int]]
|
||||
input: Union[str, List[str], List[List[int]]]
|
||||
model: str = "rwkv"
|
||||
encoding_format: str = None
|
||||
fast_mode: bool = False
|
||||
|
||||
@@ -52,6 +52,14 @@ def switch_model(body: SwitchModelBody, response: Response, request: Request):
|
||||
if body.model == "":
|
||||
return "success"
|
||||
|
||||
if "->" in body.strategy:
|
||||
state_cache.disable_state_cache()
|
||||
else:
|
||||
try:
|
||||
state_cache.enable_state_cache()
|
||||
except HTTPException:
|
||||
pass
|
||||
|
||||
os.environ["RWKV_CUDA_ON"] = "1" if body.customCuda else "0"
|
||||
|
||||
global_var.set(global_var.Model_Status, global_var.ModelStatus.Loading)
|
||||
|
||||
@@ -34,6 +34,32 @@ def init():
|
||||
print("cyac not found")
|
||||
|
||||
|
||||
@router.post("/disable-state-cache")
|
||||
def disable_state_cache():
|
||||
global trie, dtrie
|
||||
|
||||
trie = None
|
||||
dtrie = {}
|
||||
gc.collect()
|
||||
|
||||
return "success"
|
||||
|
||||
|
||||
@router.post("/enable-state-cache")
|
||||
def enable_state_cache():
|
||||
global trie, dtrie
|
||||
try:
|
||||
import cyac
|
||||
|
||||
trie = cyac.Trie()
|
||||
dtrie = {}
|
||||
gc.collect()
|
||||
|
||||
return "success"
|
||||
except ModuleNotFoundError:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "cyac not found")
|
||||
|
||||
|
||||
class AddStateBody(BaseModel):
|
||||
prompt: str
|
||||
tokens: List[str]
|
||||
@@ -85,6 +111,8 @@ def reset_state():
|
||||
if trie is None:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "trie not loaded")
|
||||
|
||||
import cyac
|
||||
|
||||
trie = cyac.Trie()
|
||||
dtrie = {}
|
||||
gc.collect()
|
||||
|
||||
BIN
build/appicon.png
vendored
BIN
build/appicon.png
vendored
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 120 KiB After Width: | Height: | Size: 83 KiB |
BIN
build/windows/icon.ico
vendored
BIN
build/windows/icon.ico
vendored
Binary file not shown.
|
Before Width: | Height: | Size: 167 KiB After Width: | Height: | Size: 175 KiB |
@@ -8,6 +8,12 @@ if [[ ${cnMirror} == 1 ]]; then
|
||||
fi
|
||||
fi
|
||||
|
||||
if dpkg -s "gcc" >/dev/null 2>&1; then
|
||||
echo "gcc installed"
|
||||
else
|
||||
sudo apt -y install gcc
|
||||
fi
|
||||
|
||||
if dpkg -s "python3-pip" >/dev/null 2>&1; then
|
||||
echo "pip installed"
|
||||
else
|
||||
@@ -20,14 +26,14 @@ else
|
||||
sudo apt -y install ninja-build
|
||||
fi
|
||||
|
||||
if dpkg -s "cuda" >/dev/null 2>&1; then
|
||||
echo "cuda installed"
|
||||
if dpkg -s "cuda" >/dev/null 2>&1 && dpkg -s "cuda" | grep Version | awk '{print $2}' | grep -q "12"; then
|
||||
echo "cuda 12 installed"
|
||||
else
|
||||
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
|
||||
wget -N https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
|
||||
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
|
||||
wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb
|
||||
sudo dpkg -i cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb
|
||||
sudo cp /var/cuda-repo-wsl-ubuntu-11-7-local/cuda-*-keyring.gpg /usr/share/keyrings/
|
||||
wget -N https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda-repo-wsl-ubuntu-12-2-local_12.2.0-1_amd64.deb
|
||||
sudo dpkg -i cuda-repo-wsl-ubuntu-12-2-local_12.2.0-1_amd64.deb
|
||||
sudo cp /var/cuda-repo-wsl-ubuntu-12-2-local/cuda-*-keyring.gpg /usr/share/keyrings/
|
||||
sudo apt-get update
|
||||
sudo apt-get -y install cuda
|
||||
fi
|
||||
|
||||
@@ -17,11 +17,14 @@
|
||||
|
||||
"""Processing data for pretraining."""
|
||||
|
||||
import argparse
|
||||
import multiprocessing
|
||||
import os
|
||||
import sys
|
||||
|
||||
sys.path.append(os.path.dirname(os.path.realpath(__file__)))
|
||||
|
||||
import argparse
|
||||
import multiprocessing
|
||||
|
||||
import lm_dataformat as lmd
|
||||
import numpy as np
|
||||
|
||||
@@ -240,4 +243,8 @@ def main():
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
try:
|
||||
main()
|
||||
except Exception as e:
|
||||
with open("error.txt", "w") as f:
|
||||
f.write(str(e))
|
||||
|
||||
97
finetune/lora/merge_lora.py
vendored
97
finetune/lora/merge_lora.py
vendored
@@ -5,49 +5,64 @@ from typing import Dict
|
||||
import typing
|
||||
import torch
|
||||
|
||||
if '-h' in sys.argv or '--help' in sys.argv:
|
||||
print(f'Usage: python3 {sys.argv[0]} [--use-gpu] <lora_alpha> <base_model.pth> <lora_checkpoint.pth> <output.pth>')
|
||||
try:
|
||||
if "-h" in sys.argv or "--help" in sys.argv:
|
||||
print(
|
||||
f"Usage: python3 {sys.argv[0]} [--use-gpu] <lora_alpha> <base_model.pth> <lora_checkpoint.pth> <output.pth>"
|
||||
)
|
||||
|
||||
if sys.argv[1] == '--use-gpu':
|
||||
device = 'cuda'
|
||||
lora_alpha, base_model, lora, output = float(sys.argv[2]), sys.argv[3], sys.argv[4], sys.argv[5]
|
||||
else:
|
||||
device = 'cpu'
|
||||
lora_alpha, base_model, lora, output = float(sys.argv[1]), sys.argv[2], sys.argv[3], sys.argv[4]
|
||||
if sys.argv[1] == "--use-gpu":
|
||||
device = "cuda"
|
||||
lora_alpha, base_model, lora, output = (
|
||||
float(sys.argv[2]),
|
||||
sys.argv[3],
|
||||
sys.argv[4],
|
||||
sys.argv[5],
|
||||
)
|
||||
else:
|
||||
device = "cpu"
|
||||
lora_alpha, base_model, lora, output = (
|
||||
float(sys.argv[1]),
|
||||
sys.argv[2],
|
||||
sys.argv[3],
|
||||
sys.argv[4],
|
||||
)
|
||||
|
||||
with torch.no_grad():
|
||||
w: Dict[str, torch.Tensor] = torch.load(base_model, map_location="cpu")
|
||||
# merge LoRA-only slim checkpoint into the main weights
|
||||
w_lora: Dict[str, torch.Tensor] = torch.load(lora, map_location="cpu")
|
||||
for k in w_lora.keys():
|
||||
w[k] = w_lora[k]
|
||||
output_w: typing.OrderedDict[str, torch.Tensor] = OrderedDict()
|
||||
# merge LoRA weights
|
||||
keys = list(w.keys())
|
||||
for k in keys:
|
||||
if k.endswith(".weight"):
|
||||
prefix = k[: -len(".weight")]
|
||||
lora_A = prefix + ".lora_A"
|
||||
lora_B = prefix + ".lora_B"
|
||||
if lora_A in keys:
|
||||
assert lora_B in keys
|
||||
print(f"merging {lora_A} and {lora_B} into {k}")
|
||||
assert w[lora_B].shape[1] == w[lora_A].shape[0]
|
||||
lora_r = w[lora_B].shape[1]
|
||||
w[k] = w[k].to(device=device)
|
||||
w[lora_A] = w[lora_A].to(device=device)
|
||||
w[lora_B] = w[lora_B].to(device=device)
|
||||
w[k] += w[lora_B] @ w[lora_A] * (lora_alpha / lora_r)
|
||||
output_w[k] = w[k].to(device="cpu", copy=True)
|
||||
del w[k]
|
||||
del w[lora_A]
|
||||
del w[lora_B]
|
||||
continue
|
||||
|
||||
with torch.no_grad():
|
||||
w: Dict[str, torch.Tensor] = torch.load(base_model, map_location='cpu')
|
||||
# merge LoRA-only slim checkpoint into the main weights
|
||||
w_lora: Dict[str, torch.Tensor] = torch.load(lora, map_location='cpu')
|
||||
for k in w_lora.keys():
|
||||
w[k] = w_lora[k]
|
||||
output_w: typing.OrderedDict[str, torch.Tensor] = OrderedDict()
|
||||
# merge LoRA weights
|
||||
keys = list(w.keys())
|
||||
for k in keys:
|
||||
if k.endswith('.weight'):
|
||||
prefix = k[:-len('.weight')]
|
||||
lora_A = prefix + '.lora_A'
|
||||
lora_B = prefix + '.lora_B'
|
||||
if lora_A in keys:
|
||||
assert lora_B in keys
|
||||
print(f'merging {lora_A} and {lora_B} into {k}')
|
||||
assert w[lora_B].shape[1] == w[lora_A].shape[0]
|
||||
lora_r = w[lora_B].shape[1]
|
||||
w[k] = w[k].to(device=device)
|
||||
w[lora_A] = w[lora_A].to(device=device)
|
||||
w[lora_B] = w[lora_B].to(device=device)
|
||||
w[k] += w[lora_B] @ w[lora_A] * (lora_alpha / lora_r)
|
||||
output_w[k] = w[k].to(device='cpu', copy=True)
|
||||
if "lora" not in k:
|
||||
print(f"retaining {k}")
|
||||
output_w[k] = w[k].clone()
|
||||
del w[k]
|
||||
del w[lora_A]
|
||||
del w[lora_B]
|
||||
continue
|
||||
|
||||
if 'lora' not in k:
|
||||
print(f'retaining {k}')
|
||||
output_w[k] = w[k].clone()
|
||||
del w[k]
|
||||
|
||||
torch.save(output_w, output)
|
||||
torch.save(output_w, output)
|
||||
except Exception as e:
|
||||
with open("error.txt", "w") as f:
|
||||
f.write(str(e))
|
||||
|
||||
203
finetune/lora/train.py
vendored
203
finetune/lora/train.py
vendored
@@ -50,52 +50,84 @@ if __name__ == "__main__":
|
||||
parser = ArgumentParser()
|
||||
|
||||
parser.add_argument("--load_model", default="", type=str) # full path, with .pth
|
||||
parser.add_argument("--wandb", default="", type=str) # wandb project name. if "" then don't use wandb
|
||||
parser.add_argument(
|
||||
"--wandb", default="", type=str
|
||||
) # wandb project name. if "" then don't use wandb
|
||||
parser.add_argument("--proj_dir", default="out", type=str)
|
||||
parser.add_argument("--random_seed", default="-1", type=int)
|
||||
|
||||
parser.add_argument("--data_file", default="", type=str)
|
||||
parser.add_argument("--data_type", default="utf-8", type=str)
|
||||
parser.add_argument("--vocab_size", default=0, type=int) # vocab_size = 0 means auto (for char-level LM and .txt data)
|
||||
parser.add_argument(
|
||||
"--vocab_size", default=0, type=int
|
||||
) # vocab_size = 0 means auto (for char-level LM and .txt data)
|
||||
|
||||
parser.add_argument("--ctx_len", default=1024, type=int)
|
||||
parser.add_argument("--epoch_steps", default=1000, type=int) # a mini "epoch" has [epoch_steps] steps
|
||||
parser.add_argument("--epoch_count", default=500, type=int) # train for this many "epochs". will continue afterwards with lr = lr_final
|
||||
parser.add_argument("--epoch_begin", default=0, type=int) # if you load a model trained for x "epochs", set epoch_begin = x
|
||||
parser.add_argument("--epoch_save", default=5, type=int) # save the model every [epoch_save] "epochs"
|
||||
parser.add_argument(
|
||||
"--epoch_steps", default=1000, type=int
|
||||
) # a mini "epoch" has [epoch_steps] steps
|
||||
parser.add_argument(
|
||||
"--epoch_count", default=500, type=int
|
||||
) # train for this many "epochs". will continue afterwards with lr = lr_final
|
||||
parser.add_argument(
|
||||
"--epoch_begin", default=0, type=int
|
||||
) # if you load a model trained for x "epochs", set epoch_begin = x
|
||||
parser.add_argument(
|
||||
"--epoch_save", default=5, type=int
|
||||
) # save the model every [epoch_save] "epochs"
|
||||
|
||||
parser.add_argument("--micro_bsz", default=12, type=int) # micro batch size (batch size per GPU)
|
||||
parser.add_argument(
|
||||
"--micro_bsz", default=12, type=int
|
||||
) # micro batch size (batch size per GPU)
|
||||
parser.add_argument("--n_layer", default=6, type=int)
|
||||
parser.add_argument("--n_embd", default=512, type=int)
|
||||
parser.add_argument("--dim_att", default=0, type=int)
|
||||
parser.add_argument("--dim_ffn", default=0, type=int)
|
||||
parser.add_argument("--pre_ffn", default=0, type=int) # replace first att layer by ffn (sometimes better)
|
||||
parser.add_argument(
|
||||
"--pre_ffn", default=0, type=int
|
||||
) # replace first att layer by ffn (sometimes better)
|
||||
parser.add_argument("--head_qk", default=0, type=int) # my headQK trick
|
||||
parser.add_argument("--tiny_att_dim", default=0, type=int) # tiny attention dim
|
||||
parser.add_argument("--tiny_att_layer", default=-999, type=int) # tiny attention @ which layer
|
||||
parser.add_argument(
|
||||
"--tiny_att_layer", default=-999, type=int
|
||||
) # tiny attention @ which layer
|
||||
|
||||
parser.add_argument("--lr_init", default=6e-4, type=float) # 6e-4 for L12-D768, 4e-4 for L24-D1024, 3e-4 for L24-D2048
|
||||
parser.add_argument(
|
||||
"--lr_init", default=6e-4, type=float
|
||||
) # 6e-4 for L12-D768, 4e-4 for L24-D1024, 3e-4 for L24-D2048
|
||||
parser.add_argument("--lr_final", default=1e-5, type=float)
|
||||
parser.add_argument("--warmup_steps", default=0, type=int) # try 50 if you load a model
|
||||
parser.add_argument(
|
||||
"--warmup_steps", default=0, type=int
|
||||
) # try 50 if you load a model
|
||||
parser.add_argument("--beta1", default=0.9, type=float)
|
||||
parser.add_argument("--beta2", default=0.99, type=float) # use 0.999 when your model is close to convergence
|
||||
parser.add_argument(
|
||||
"--beta2", default=0.99, type=float
|
||||
) # use 0.999 when your model is close to convergence
|
||||
parser.add_argument("--adam_eps", default=1e-8, type=float)
|
||||
|
||||
parser.add_argument("--grad_cp", default=0, type=int) # gradient checkpt: saves VRAM, but slower
|
||||
parser.add_argument(
|
||||
"--grad_cp", default=0, type=int
|
||||
) # gradient checkpt: saves VRAM, but slower
|
||||
parser.add_argument("--my_pile_stage", default=0, type=int) # my special pile mode
|
||||
parser.add_argument("--my_pile_shift", default=-1, type=int) # my special pile mode - text shift
|
||||
parser.add_argument(
|
||||
"--my_pile_shift", default=-1, type=int
|
||||
) # my special pile mode - text shift
|
||||
parser.add_argument("--my_pile_edecay", default=0, type=int)
|
||||
parser.add_argument("--layerwise_lr", default=1, type=int) # layerwise lr for faster convergence (but slower it/s)
|
||||
parser.add_argument("--ds_bucket_mb", default=200, type=int) # deepspeed bucket size in MB. 200 seems enough
|
||||
parser.add_argument(
|
||||
"--layerwise_lr", default=1, type=int
|
||||
) # layerwise lr for faster convergence (but slower it/s)
|
||||
parser.add_argument(
|
||||
"--ds_bucket_mb", default=200, type=int
|
||||
) # deepspeed bucket size in MB. 200 seems enough
|
||||
# parser.add_argument("--cuda_cleanup", default=0, type=int) # extra cuda cleanup (sometimes helpful)
|
||||
|
||||
parser.add_argument("--my_img_version", default=0, type=str)
|
||||
parser.add_argument("--my_img_size", default=0, type=int)
|
||||
parser.add_argument("--my_img_bit", default=0, type=int)
|
||||
parser.add_argument("--my_img_clip", default='x', type=str)
|
||||
parser.add_argument("--my_img_clip", default="x", type=str)
|
||||
parser.add_argument("--my_img_clip_scale", default=1, type=float)
|
||||
parser.add_argument("--my_img_l1_scale", default=0, type=float)
|
||||
parser.add_argument("--my_img_encoder", default='x', type=str)
|
||||
parser.add_argument("--my_img_encoder", default="x", type=str)
|
||||
# parser.add_argument("--my_img_noise_scale", default=0, type=float)
|
||||
parser.add_argument("--my_sample_len", default=0, type=int)
|
||||
parser.add_argument("--my_ffn_shift", default=1, type=int)
|
||||
@@ -104,7 +136,7 @@ if __name__ == "__main__":
|
||||
parser.add_argument("--load_partial", default=0, type=int)
|
||||
parser.add_argument("--magic_prime", default=0, type=int)
|
||||
parser.add_argument("--my_qa_mask", default=0, type=int)
|
||||
parser.add_argument("--my_testing", default='', type=str)
|
||||
parser.add_argument("--my_testing", default="", type=str)
|
||||
|
||||
parser.add_argument("--lora", action="store_true")
|
||||
parser.add_argument("--lora_load", default="", type=str)
|
||||
@@ -122,18 +154,26 @@ if __name__ == "__main__":
|
||||
import numpy as np
|
||||
import torch
|
||||
from torch.utils.data import DataLoader
|
||||
|
||||
if "deepspeed" in args.strategy:
|
||||
import deepspeed
|
||||
import pytorch_lightning as pl
|
||||
from pytorch_lightning import seed_everything
|
||||
|
||||
if args.random_seed >= 0:
|
||||
print(f"########## WARNING: GLOBAL SEED {args.random_seed} THIS WILL AFFECT MULTIGPU SAMPLING ##########\n" * 3)
|
||||
print(
|
||||
f"########## WARNING: GLOBAL SEED {args.random_seed} THIS WILL AFFECT MULTIGPU SAMPLING ##########\n"
|
||||
* 3
|
||||
)
|
||||
seed_everything(args.random_seed)
|
||||
|
||||
np.set_printoptions(precision=4, suppress=True, linewidth=200)
|
||||
warnings.filterwarnings("ignore", ".*Consider increasing the value of the `num_workers` argument*")
|
||||
warnings.filterwarnings("ignore", ".*The progress bar already tracks a metric with the*")
|
||||
warnings.filterwarnings(
|
||||
"ignore", ".*Consider increasing the value of the `num_workers` argument*"
|
||||
)
|
||||
warnings.filterwarnings(
|
||||
"ignore", ".*The progress bar already tracks a metric with the*"
|
||||
)
|
||||
# os.environ["WDS_SHOW_SEED"] = "1"
|
||||
|
||||
args.my_timestamp = datetime.datetime.today().strftime("%Y-%m-%d-%H-%M-%S")
|
||||
@@ -158,7 +198,9 @@ if __name__ == "__main__":
|
||||
args.run_name = f"v{args.my_img_version}-{args.my_img_size}-{args.my_img_bit}bit-{args.my_img_clip}x{args.my_img_clip_scale}"
|
||||
args.proj_dir = f"{args.proj_dir}-{args.run_name}"
|
||||
else:
|
||||
args.run_name = f"{args.vocab_size} ctx{args.ctx_len} L{args.n_layer} D{args.n_embd}"
|
||||
args.run_name = (
|
||||
f"{args.vocab_size} ctx{args.ctx_len} L{args.n_layer} D{args.n_embd}"
|
||||
)
|
||||
if not os.path.exists(args.proj_dir):
|
||||
os.makedirs(args.proj_dir)
|
||||
|
||||
@@ -240,24 +282,40 @@ if __name__ == "__main__":
|
||||
)
|
||||
rank_zero_info(str(vars(args)) + "\n")
|
||||
|
||||
assert args.data_type in ["utf-8", "utf-16le", "numpy", "binidx", "dummy", "wds_img", "uint16"]
|
||||
assert args.data_type in [
|
||||
"utf-8",
|
||||
"utf-16le",
|
||||
"numpy",
|
||||
"binidx",
|
||||
"dummy",
|
||||
"wds_img",
|
||||
"uint16",
|
||||
]
|
||||
|
||||
if args.lr_final == 0 or args.lr_init == 0:
|
||||
rank_zero_info("\n\nNote: lr_final = 0 or lr_init = 0. Using linear LR schedule instead.\n\n")
|
||||
rank_zero_info(
|
||||
"\n\nNote: lr_final = 0 or lr_init = 0. Using linear LR schedule instead.\n\n"
|
||||
)
|
||||
|
||||
assert args.precision in ["fp32", "tf32", "fp16", "bf16"]
|
||||
os.environ["RWKV_FLOAT_MODE"] = args.precision
|
||||
if args.precision == "fp32":
|
||||
for i in range(10):
|
||||
rank_zero_info("\n\nNote: you are using fp32 (very slow). Try bf16 / tf32 for faster training.\n\n")
|
||||
rank_zero_info(
|
||||
"\n\nNote: you are using fp32 (very slow). Try bf16 / tf32 for faster training.\n\n"
|
||||
)
|
||||
if args.precision == "fp16":
|
||||
rank_zero_info("\n\nNote: you are using fp16 (might overflow). Try bf16 / tf32 for stable training.\n\n")
|
||||
rank_zero_info(
|
||||
"\n\nNote: you are using fp16 (might overflow). Try bf16 / tf32 for stable training.\n\n"
|
||||
)
|
||||
|
||||
os.environ["RWKV_JIT_ON"] = "1"
|
||||
if "deepspeed_stage_3" in args.strategy:
|
||||
os.environ["RWKV_JIT_ON"] = "0"
|
||||
if args.lora and args.grad_cp == 1:
|
||||
print('!!!!! LoRA Warning: Gradient Checkpointing requires JIT off, disabling it')
|
||||
print(
|
||||
"!!!!! LoRA Warning: Gradient Checkpointing requires JIT off, disabling it"
|
||||
)
|
||||
os.environ["RWKV_JIT_ON"] = "0"
|
||||
|
||||
torch.backends.cudnn.benchmark = True
|
||||
@@ -284,20 +342,22 @@ if __name__ == "__main__":
|
||||
train_data = MyDataset(args)
|
||||
args.vocab_size = train_data.vocab_size
|
||||
|
||||
if args.data_type == 'wds_img':
|
||||
if args.data_type == "wds_img":
|
||||
from src.model_img import RWKV_IMG
|
||||
|
||||
assert args.lora, "LoRA not yet supported for RWKV_IMG"
|
||||
model = RWKV_IMG(args)
|
||||
else:
|
||||
from src.model import RWKV, LORA_CONFIG, LoraLinear
|
||||
|
||||
if args.lora:
|
||||
assert args.lora_r > 0, "LoRA should have its `r` > 0"
|
||||
LORA_CONFIG["r"] = args.lora_r
|
||||
LORA_CONFIG["alpha"] = args.lora_alpha
|
||||
LORA_CONFIG["dropout"] = args.lora_dropout
|
||||
LORA_CONFIG["parts"] = set(str(args.lora_parts).split(','))
|
||||
enable_time_finetune = 'time' in LORA_CONFIG["parts"]
|
||||
enable_ln_finetune = 'ln' in LORA_CONFIG["parts"]
|
||||
LORA_CONFIG["parts"] = set(str(args.lora_parts).split(","))
|
||||
enable_time_finetune = "time" in LORA_CONFIG["parts"]
|
||||
enable_ln_finetune = "ln" in LORA_CONFIG["parts"]
|
||||
model = RWKV(args)
|
||||
# only train lora parameters
|
||||
if args.lora:
|
||||
@@ -305,20 +365,24 @@ if __name__ == "__main__":
|
||||
for name, module in model.named_modules():
|
||||
# have to check param name since it may have been wrapped by torchscript
|
||||
if any(n.startswith("lora_") for n, _ in module.named_parameters()):
|
||||
print(f' LoRA training module {name}')
|
||||
print(f" LoRA training module {name}")
|
||||
for pname, param in module.named_parameters():
|
||||
param.requires_grad = 'lora_' in pname
|
||||
elif enable_ln_finetune and '.ln' in name:
|
||||
print(f' LoRA additionally training module {name}')
|
||||
param.requires_grad = "lora_" in pname
|
||||
elif enable_ln_finetune and ".ln" in name:
|
||||
print(f" LoRA additionally training module {name}")
|
||||
for param in module.parameters():
|
||||
param.requires_grad = True
|
||||
elif enable_time_finetune and any(n.startswith("time") for n, _ in module.named_parameters()):
|
||||
elif enable_time_finetune and any(
|
||||
n.startswith("time") for n, _ in module.named_parameters()
|
||||
):
|
||||
for pname, param in module.named_parameters():
|
||||
if pname.startswith("time"):
|
||||
print(f' LoRA additionally training parameter {pname}')
|
||||
print(f" LoRA additionally training parameter {pname}")
|
||||
param.requires_grad = True
|
||||
|
||||
if len(args.load_model) == 0 or args.my_pile_stage == 1: # shall we build the initial weights?
|
||||
if (
|
||||
len(args.load_model) == 0 or args.my_pile_stage == 1
|
||||
): # shall we build the initial weights?
|
||||
init_weight_name = f"{args.proj_dir}/rwkv-init.pth"
|
||||
generate_init_weight(model, init_weight_name) # save initial weights
|
||||
args.load_model = init_weight_name
|
||||
@@ -326,6 +390,7 @@ if __name__ == "__main__":
|
||||
rank_zero_info(f"########## Loading {args.load_model}... ##########")
|
||||
try:
|
||||
load_dict = torch.load(args.load_model, map_location="cpu")
|
||||
model.load_state_dict(load_dict, strict=(not args.lora))
|
||||
except:
|
||||
rank_zero_info(f"Bad checkpoint {args.load_model}")
|
||||
if args.my_pile_stage >= 2: # try again using another checkpoint
|
||||
@@ -337,36 +402,50 @@ if __name__ == "__main__":
|
||||
args.epoch_begin = max_p + 1
|
||||
rank_zero_info(f"Trying {args.load_model}")
|
||||
load_dict = torch.load(args.load_model, map_location="cpu")
|
||||
model.load_state_dict(load_dict, strict=(not args.lora))
|
||||
|
||||
if args.load_partial == 1:
|
||||
load_keys = load_dict.keys()
|
||||
for k in model.state_dict():
|
||||
if k not in load_keys:
|
||||
load_dict[k] = model.state_dict()[k]
|
||||
model.load_state_dict(load_dict, strict=(not args.lora))
|
||||
# If using LoRA, the LoRA keys might be missing in the original model
|
||||
model.load_state_dict(load_dict, strict=(not args.lora))
|
||||
# model.load_state_dict(load_dict, strict=(not args.lora))
|
||||
if os.path.isfile(args.lora_load):
|
||||
model.load_state_dict(torch.load(args.lora_load, map_location="cpu"),
|
||||
strict=False)
|
||||
model.load_state_dict(
|
||||
torch.load(args.lora_load, map_location="cpu"), strict=False
|
||||
)
|
||||
|
||||
trainer: Trainer = Trainer.from_argparse_args(
|
||||
args,
|
||||
callbacks=[train_callback(args)],
|
||||
)
|
||||
|
||||
if (args.lr_init > 1e-4 or trainer.world_size * args.micro_bsz * trainer.accumulate_grad_batches < 8):
|
||||
if 'I_KNOW_WHAT_IM_DOING' in os.environ:
|
||||
|
||||
if (
|
||||
args.lr_init > 1e-4
|
||||
or trainer.world_size * args.micro_bsz * trainer.accumulate_grad_batches < 8
|
||||
):
|
||||
if "I_KNOW_WHAT_IM_DOING" in os.environ:
|
||||
if trainer.global_rank == 0:
|
||||
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
|
||||
print(f' WARNING: you are using too large LR ({args.lr_init} > 1e-4) or too small global batch size ({trainer.world_size} * {args.micro_bsz} * {trainer.accumulate_grad_batches} < 8)')
|
||||
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
|
||||
print("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
|
||||
print(
|
||||
f" WARNING: you are using too large LR ({args.lr_init} > 1e-4) or too small global batch size ({trainer.world_size} * {args.micro_bsz} * {trainer.accumulate_grad_batches} < 8)"
|
||||
)
|
||||
print("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
|
||||
else:
|
||||
if trainer.global_rank == 0:
|
||||
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
|
||||
print(f' ERROR: you are using too large LR ({args.lr_init} > 1e-4) or too small global batch size ({trainer.world_size} * {args.micro_bsz} * {trainer.accumulate_grad_batches} < 8)')
|
||||
print(f' Unless you are sure this is what you want, adjust them accordingly')
|
||||
print(f' (to suppress this, set environment variable "I_KNOW_WHAT_IM_DOING")')
|
||||
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
|
||||
print("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
|
||||
print(
|
||||
f" ERROR: you are using too large LR ({args.lr_init} > 1e-4) or too small global batch size ({trainer.world_size} * {args.micro_bsz} * {trainer.accumulate_grad_batches} < 8)"
|
||||
)
|
||||
print(
|
||||
f" Unless you are sure this is what you want, adjust them accordingly"
|
||||
)
|
||||
print(
|
||||
f' (to suppress this, set environment variable "I_KNOW_WHAT_IM_DOING")'
|
||||
)
|
||||
print("!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!")
|
||||
exit(0)
|
||||
|
||||
if trainer.global_rank == 0:
|
||||
@@ -379,10 +458,22 @@ if __name__ == "__main__":
|
||||
print(f"{str(shape[0]).ljust(5)} {n}")
|
||||
|
||||
if "deepspeed" in args.strategy:
|
||||
trainer.strategy.config["zero_optimization"]["allgather_bucket_size"] = args.ds_bucket_mb * 1000 * 1000
|
||||
trainer.strategy.config["zero_optimization"]["reduce_bucket_size"] = args.ds_bucket_mb * 1000 * 1000
|
||||
trainer.strategy.config["zero_optimization"]["allgather_bucket_size"] = (
|
||||
args.ds_bucket_mb * 1000 * 1000
|
||||
)
|
||||
trainer.strategy.config["zero_optimization"]["reduce_bucket_size"] = (
|
||||
args.ds_bucket_mb * 1000 * 1000
|
||||
)
|
||||
|
||||
# must set shuffle=False, persistent_workers=False (because worker is in another thread)
|
||||
data_loader = DataLoader(train_data, shuffle=False, pin_memory=True, batch_size=args.micro_bsz, num_workers=1, persistent_workers=False, drop_last=True)
|
||||
data_loader = DataLoader(
|
||||
train_data,
|
||||
shuffle=False,
|
||||
pin_memory=True,
|
||||
batch_size=args.micro_bsz,
|
||||
num_workers=1,
|
||||
persistent_workers=False,
|
||||
drop_last=True,
|
||||
)
|
||||
|
||||
trainer.fit(model, data_loader)
|
||||
|
||||
@@ -104,7 +104,7 @@
|
||||
"Supported custom cuda file not found": "没有找到支持的自定义cuda文件",
|
||||
"Failed to copy custom cuda file": "自定义cuda文件复制失败",
|
||||
"Downloading update, please wait. If it is not completed, please manually download the program from GitHub and replace the original program.": "正在下载更新,请等待。如果一直未完成,请从Github手动下载并覆盖原程序",
|
||||
"Completion": "补全",
|
||||
"Completion": "续写",
|
||||
"Parameters": "参数",
|
||||
"Stop Sequences": "停止词",
|
||||
"When this content appears in the response result, the generation will end.": "响应结果出现该内容时就结束生成",
|
||||
@@ -118,12 +118,12 @@
|
||||
"Instruction": "指令",
|
||||
"Blank": "空白",
|
||||
"The following is an epic science fiction masterpiece that is immortalized, with delicate descriptions and grand depictions of interstellar civilization wars.\nChapter 1.\n": "《背影》\n我与父亲不相见已二年余了,我最不能忘记的是他的背影。\n那年冬天,祖母死了,父亲的差使也交卸了,正是祸不单行的日子。我从北京到徐州,打算",
|
||||
"The following is a conversation between a cat girl and her owner. The cat girl is a humanized creature that behaves like a cat but is humanoid. At the end of each sentence in the dialogue, she will add \"Meow~\". In the following content, Bob represents the owner and Alice represents the cat girl.\n\nBob: Hello.\n\nAlice: I'm here, meow~.\n\nBob: Can you tell jokes?": "以下是一位猫娘的主人和猫娘的对话内容,猫娘是一种拟人化的生物,其行为似猫但类人,在每一句对话末尾都会加上\"喵~\"。以下内容中,Bob代表主人,Alice代表猫娘。\n\nBob: 你好\n\nAlice: 主人我在哦,喵~\n\nBob: 你会讲笑话吗?",
|
||||
"The following is a conversation between a cat girl and her owner. The cat girl is a humanized creature that behaves like a cat but is humanoid. At the end of each sentence in the dialogue, she will add \"Meow~\". In the following content, User represents the owner and Assistant represents the cat girl.\n\nUser: Hello.\n\nAssistant: I'm here, meow~.\n\nUser: Can you tell jokes?": "以下是一位猫娘的主人和猫娘的对话内容,猫娘是一种拟人化的生物,其行为似猫但类人,在每一句对话末尾都会加上\"喵~\"。以下内容中,User代表主人,Assistant代表猫娘。\n\nUser: 你好\n\nAssistant: 主人我在哦,喵~\n\nUser: 你会讲笑话吗?",
|
||||
"When response finished, inject this content.": "响应结束时,插入此内容到末尾",
|
||||
"Inject start text": "起始注入文本",
|
||||
"Inject end text": "结尾注入文本",
|
||||
"Before the response starts, inject this content.": "响应开始前,在开头插入此内容",
|
||||
"There is currently a game of Werewolf with six players, including a Seer (who can check identities at night), two Werewolves (who can choose someone to kill at night), a Bodyguard (who can choose someone to protect at night), two Villagers (with no special abilities), and a game host. Bob will play as Player 1, Alice will play as Players 2-6 and the game host, and they will begin playing together. Every night, the host will ask Bob for his action and simulate the actions of the other players. During the day, the host will oversee the voting process and ask Bob for his vote. \n\nAlice: Next, I will act as the game host and assign everyone their roles, including randomly assigning yours. Then, I will simulate the actions of Players 2-6 and let you know what happens each day. Based on your assigned role, you can tell me your actions and I will let you know the corresponding results each day.\n\nBob: Okay, I understand. Let's begin. Please assign me a role. Am I the Seer, Werewolf, Villager, or Bodyguard?\n\nAlice: You are the Seer. Now that night has fallen, please choose a player to check his identity.\n\nBob: Tonight, I want to check Player 2 and find out his role.": "现在有一场六人狼人杀游戏,包括一名预言家(可以在夜晚查验身份),两名狼人(可以在夜晚选择杀人),一名守卫(可以在夜晚选择要守护的人),两名平民(无技能),一名主持人,以下内容中Bob将扮演其中的1号玩家,Alice来扮演2-6号玩家,以及主持人,并开始与Bob进行游戏,主持人每晚都会询问Bob的行动,并模拟其他人的行动,在白天则要主持投票,并同样询问Bob投票对象,公布投票结果。\n\nAlice: 接下来,我将首先作为主持人进行角色分配,并给你赋予随机的角色,之后我将模拟2-6号玩家进行行动,告知你每天的动态,根据你被分配的角色,你可以回复我你做的行动,我会告诉你每天对应的结果\n\nBob: 好的,我明白了,那么开始吧。请先给我一个角色身份。我是预言家,狼人,平民,守卫中的哪一个呢?\n\nAlice: 你的身份是预言家。现在夜晚降临,请选择你要查验的玩家。\n\nBob: 今晚我要验2号玩家,他是什么身份?",
|
||||
"There is currently a game of Werewolf with six players, including a Seer (who can check identities at night), two Werewolves (who can choose someone to kill at night), a Bodyguard (who can choose someone to protect at night), two Villagers (with no special abilities), and a game host. User will play as Player 1, Assistant will play as Players 2-6 and the game host, and they will begin playing together. Every night, the host will ask User for his action and simulate the actions of the other players. During the day, the host will oversee the voting process and ask User for his vote. \n\nAssistant: Next, I will act as the game host and assign everyone their roles, including randomly assigning yours. Then, I will simulate the actions of Players 2-6 and let you know what happens each day. Based on your assigned role, you can tell me your actions and I will let you know the corresponding results each day.\n\nUser: Okay, I understand. Let's begin. Please assign me a role. Am I the Seer, Werewolf, Villager, or Bodyguard?\n\nAssistant: You are the Seer. Now that night has fallen, please choose a player to check his identity.\n\nUser: Tonight, I want to check Player 2 and find out his role.": "现在有一场六人狼人杀游戏,包括一名预言家(可以在夜晚查验身份),两名狼人(可以在夜晚选择杀人),一名守卫(可以在夜晚选择要守护的人),两名平民(无技能),一名主持人,以下内容中User将扮演其中的1号玩家,Assistant来扮演2-6号玩家,以及主持人,并开始与User进行游戏,主持人每晚都会询问User的行动,并模拟其他人的行动,在白天则要主持投票,并同样询问User投票对象,公布投票结果。\n\nAssistant: 接下来,我将首先作为主持人进行角色分配,并给你赋予随机的角色,之后我将模拟2-6号玩家进行行动,告知你每天的动态,根据你被分配的角色,你可以回复我你做的行动,我会告诉你每天对应的结果\n\nUser: 好的,我明白了,那么开始吧。请先给我一个角色身份。我是预言家,狼人,平民,守卫中的哪一个呢?\n\nAssistant: 你的身份是预言家。现在夜晚降临,请选择你要查验的玩家。\n\nUser: 今晚我要验2号玩家,他是什么身份?",
|
||||
"Writer, Translator, Role-playing": "写作,翻译,角色扮演",
|
||||
"Chinese Kongfu": "情境冒险",
|
||||
"Allow external access to the API (service must be restarted)": "允许外部访问API (必须重启服务)",
|
||||
@@ -153,7 +153,7 @@
|
||||
"Restart the app to apply DPI Scaling.": "重启应用以使显示缩放生效",
|
||||
"Restart": "重启",
|
||||
"API Chat Model Name": "API聊天模型名",
|
||||
"API Completion Model Name": "API补全模型名",
|
||||
"API Completion Model Name": "API续写模型名",
|
||||
"Localhost": "本地",
|
||||
"Retry": "重试",
|
||||
"Delete": "删除",
|
||||
@@ -223,5 +223,16 @@
|
||||
"Merge model successfully": "合并模型成功",
|
||||
"Convert Data successfully": "数据转换成功",
|
||||
"Please select a LoRA model": "请选择一个LoRA模型",
|
||||
"You are using sample data for training. For formal training, please make sure to create your own jsonl file.": "你正在使用示例数据训练,对于正式训练场合,请务必创建你自己的jsonl训练数据"
|
||||
"You are using sample data for training. For formal training, please make sure to create your own jsonl file.": "你正在使用示例数据训练,对于正式训练场合,请务必创建你自己的jsonl训练数据",
|
||||
"WSL is not running, please retry. If it keeps happening, it means you may be using an outdated version of WSL, run \"wsl --update\" to update.": "WSL没有运行,请重试。如果一直出现此错误,意味着你可能正在使用旧版本的WSL,请在cmd执行\"wsl --update\"以更新",
|
||||
"Memory is not enough, try to increase the virtual memory or use a smaller base model.": "内存不足,尝试增加虚拟内存,或使用一个更小规模的基底模型",
|
||||
"VRAM is not enough": "显存不足",
|
||||
"Training data is not enough, reduce context length or add more data for training": "训练数据不足,请减小上下文长度或增加训练数据",
|
||||
"You are using WSL 1 for training, please upgrade to WSL 2. e.g. Run \"wsl --set-version Ubuntu-22.04 2\"": "你正在使用WSL 1进行训练,请升级到WSL 2。例如,运行\"wsl --set-version Ubuntu-22.04 2\"",
|
||||
"Matched CUDA is not installed": "未安装匹配的CUDA",
|
||||
"Failed to convert data": "数据转换失败",
|
||||
"Failed to merge model": "合并模型失败",
|
||||
"The data path should be a directory or a file in jsonl format (more formats will be supported in the future).\n\nWhen you provide a directory path, all the txt files within that directory will be automatically converted into training data. This is commonly used for large-scale training in writing, code generation, or knowledge bases.\n\nThe jsonl format file can be referenced at https://github.com/Abel2076/json2binidx_tool/blob/main/sample.jsonl.\nYou can also write it similar to OpenAI's playground format, as shown in https://platform.openai.com/playground/p/default-chat.\nEven for multi-turn conversations, they must be written in a single line using `\\n` to indicate line breaks. If they are different dialogues or topics, they should be written in separate lines.": "数据路径必须是一个文件夹,或者jsonl格式文件 (未来会支持更多格式)\n\n当你填写的路径是一个文件夹时,该文件夹内的所有txt文件会被自动转换为训练数据,通常这用于大批量训练写作,代码生成或知识库\n\njsonl文件的格式参考 https://github.com/Abel2076/json2binidx_tool/blob/main/sample.jsonl\n你也可以仿照openai的playground编写,参考 https://platform.openai.com/playground/p/default-chat\n即使是多轮对话也必须写在一行,用`\\n`表示换行,如果是不同对话或主题,则另起一行",
|
||||
"Size mismatch for blocks. You are attempting to continue training from the LoRA model, but it does not match the base model. Please set LoRA model to None.": "尺寸不匹配块。你正在尝试从LoRA模型继续训练,但该LoRA模型与基底模型不匹配,请将LoRA模型设为空",
|
||||
"Instruction: Write a story using the following information\n\nInput: A man named Alex chops a tree down\n\nResponse:": "Instruction: Write a story using the following information\n\nInput: 艾利克斯砍倒了一棵树\n\nResponse:"
|
||||
}
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 4.4 KiB |
BIN
frontend/src/assets/images/logo.png
Normal file
BIN
frontend/src/assets/images/logo.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 36 KiB |
@@ -11,6 +11,7 @@ import {
|
||||
} from '@fluentui/react-components';
|
||||
import { ToolTipButton } from './ToolTipButton';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import MarkdownRender from './MarkdownRender';
|
||||
|
||||
export const DialogButton: FC<{
|
||||
text?: string | null
|
||||
@@ -19,12 +20,13 @@ export const DialogButton: FC<{
|
||||
className?: string,
|
||||
title: string,
|
||||
contentText: string,
|
||||
onConfirm: () => void,
|
||||
markdown?: boolean,
|
||||
onConfirm?: () => void,
|
||||
size?: 'small' | 'medium' | 'large',
|
||||
shape?: 'rounded' | 'circular' | 'square',
|
||||
appearance?: 'secondary' | 'primary' | 'outline' | 'subtle' | 'transparent',
|
||||
}> = ({
|
||||
text, icon, tooltip, className, title, contentText,
|
||||
text, icon, tooltip, className, title, contentText, markdown,
|
||||
onConfirm, size, shape, appearance
|
||||
}) => {
|
||||
const { t } = useTranslation();
|
||||
@@ -41,7 +43,11 @@ export const DialogButton: FC<{
|
||||
<DialogBody>
|
||||
<DialogTitle>{title}</DialogTitle>
|
||||
<DialogContent>
|
||||
{contentText}
|
||||
{
|
||||
markdown ?
|
||||
<MarkdownRender>{contentText}</MarkdownRender> :
|
||||
contentText
|
||||
}
|
||||
</DialogContent>
|
||||
<DialogActions>
|
||||
<DialogTrigger disableButtonEnhancement>
|
||||
|
||||
@@ -7,7 +7,7 @@ import { v4 as uuid } from 'uuid';
|
||||
import classnames from 'classnames';
|
||||
import { fetchEventSource } from '@microsoft/fetch-event-source';
|
||||
import { KebabHorizontalIcon, PencilIcon, SyncIcon, TrashIcon } from '@primer/octicons-react';
|
||||
import logo from '../assets/images/logo.jpg';
|
||||
import logo from '../assets/images/logo.png';
|
||||
import MarkdownRender from '../components/MarkdownRender';
|
||||
import { ToolTipButton } from '../components/ToolTipButton';
|
||||
import { ArrowCircleUp28Regular, Delete28Regular, RecordStop28Regular, Save28Regular } from '@fluentui/react-icons';
|
||||
@@ -421,7 +421,7 @@ const ChatPanel: FC = observer(() => {
|
||||
}
|
||||
});
|
||||
|
||||
OpenSaveFileDialog('*.md', 'conversation.md', savedContent).then((path) => {
|
||||
OpenSaveFileDialog('*.txt', 'conversation.txt', savedContent).then((path) => {
|
||||
if (path)
|
||||
toastWithButton(t('Conversation Saved'), t('Open'), () => {
|
||||
OpenFileFolder(path, false);
|
||||
|
||||
@@ -35,7 +35,7 @@ export const defaultPresets: CompletionPreset[] = [{
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4,
|
||||
stop: '\\n\\nBob',
|
||||
stop: '\\n\\nUser',
|
||||
injectStart: '',
|
||||
injectEnd: ''
|
||||
}
|
||||
@@ -46,37 +46,37 @@ export const defaultPresets: CompletionPreset[] = [{
|
||||
maxResponseToken: 500,
|
||||
temperature: 1,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1,
|
||||
stop: '\\nEnglish',
|
||||
injectStart: '\\nChinese: ',
|
||||
injectEnd: '\\nEnglish: '
|
||||
}
|
||||
}, {
|
||||
name: 'Catgirl',
|
||||
prompt: 'The following is a conversation between a cat girl and her owner. The cat girl is a humanized creature that behaves like a cat but is humanoid. At the end of each sentence in the dialogue, she will add \"Meow~\". In the following content, Bob represents the owner and Alice represents the cat girl.\n\nBob: Hello.\n\nAlice: I\'m here, meow~.\n\nBob: Can you tell jokes?',
|
||||
prompt: 'The following is a conversation between a cat girl and her owner. The cat girl is a humanized creature that behaves like a cat but is humanoid. At the end of each sentence in the dialogue, she will add \"Meow~\". In the following content, User represents the owner and Assistant represents the cat girl.\n\nUser: Hello.\n\nAssistant: I\'m here, meow~.\n\nUser: Can you tell jokes?',
|
||||
params: {
|
||||
maxResponseToken: 500,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4,
|
||||
stop: '\\n\\nBob',
|
||||
injectStart: '\\n\\nAlice: ',
|
||||
injectEnd: '\\n\\nBob: '
|
||||
stop: '\\n\\nUser',
|
||||
injectStart: '\\n\\nAssistant: ',
|
||||
injectEnd: '\\n\\nUser: '
|
||||
}
|
||||
}, {
|
||||
name: 'Chinese Kongfu',
|
||||
prompt: 'Bob: 请你扮演一个文本冒险游戏,我是游戏主角。这是一个玄幻修真世界,有四大门派。我输入我的行动,请你显示行动结果,并具体描述环境。我的第一个行动是“醒来”,请开始故事。',
|
||||
prompt: 'User: 请你扮演一个文本冒险游戏,我是游戏主角。这是一个玄幻修真世界,有四大门派。我输入我的行动,请你显示行动结果,并具体描述环境。我的第一个行动是“醒来”,请开始故事。',
|
||||
params: {
|
||||
maxResponseToken: 500,
|
||||
temperature: 1.1,
|
||||
topP: 0.7,
|
||||
presencePenalty: 0.3,
|
||||
frequencyPenalty: 0.3,
|
||||
stop: '\\n\\nBob',
|
||||
injectStart: '\\n\\nAlice: ',
|
||||
injectEnd: '\\n\\nBob: '
|
||||
stop: '\\n\\nUser',
|
||||
injectStart: '\\n\\nAssistant: ',
|
||||
injectEnd: '\\n\\nUser: '
|
||||
}
|
||||
}, {
|
||||
// }, {
|
||||
@@ -94,26 +94,26 @@ export const defaultPresets: CompletionPreset[] = [{
|
||||
// }
|
||||
// }, {
|
||||
name: 'Werewolf',
|
||||
prompt: 'There is currently a game of Werewolf with six players, including a Seer (who can check identities at night), two Werewolves (who can choose someone to kill at night), a Bodyguard (who can choose someone to protect at night), two Villagers (with no special abilities), and a game host. Bob will play as Player 1, Alice will play as Players 2-6 and the game host, and they will begin playing together. Every night, the host will ask Bob for his action and simulate the actions of the other players. During the day, the host will oversee the voting process and ask Bob for his vote. \n\nAlice: Next, I will act as the game host and assign everyone their roles, including randomly assigning yours. Then, I will simulate the actions of Players 2-6 and let you know what happens each day. Based on your assigned role, you can tell me your actions and I will let you know the corresponding results each day.\n\nBob: Okay, I understand. Let\'s begin. Please assign me a role. Am I the Seer, Werewolf, Villager, or Bodyguard?\n\nAlice: You are the Seer. Now that night has fallen, please choose a player to check his identity.\n\nBob: Tonight, I want to check Player 2 and find out his role.',
|
||||
prompt: 'There is currently a game of Werewolf with six players, including a Seer (who can check identities at night), two Werewolves (who can choose someone to kill at night), a Bodyguard (who can choose someone to protect at night), two Villagers (with no special abilities), and a game host. User will play as Player 1, Assistant will play as Players 2-6 and the game host, and they will begin playing together. Every night, the host will ask User for his action and simulate the actions of the other players. During the day, the host will oversee the voting process and ask User for his vote. \n\nAssistant: Next, I will act as the game host and assign everyone their roles, including randomly assigning yours. Then, I will simulate the actions of Players 2-6 and let you know what happens each day. Based on your assigned role, you can tell me your actions and I will let you know the corresponding results each day.\n\nUser: Okay, I understand. Let\'s begin. Please assign me a role. Am I the Seer, Werewolf, Villager, or Bodyguard?\n\nAssistant: You are the Seer. Now that night has fallen, please choose a player to check his identity.\n\nUser: Tonight, I want to check Player 2 and find out his role.',
|
||||
params: {
|
||||
maxResponseToken: 500,
|
||||
temperature: 1.2,
|
||||
topP: 0.4,
|
||||
presencePenalty: 0.5,
|
||||
frequencyPenalty: 0.5,
|
||||
stop: '\\n\\nBob',
|
||||
injectStart: '\\n\\nAlice: ',
|
||||
injectEnd: '\\n\\nBob: '
|
||||
stop: '\\n\\nUser',
|
||||
injectStart: '\\n\\nAssistant: ',
|
||||
injectEnd: '\\n\\nUser: '
|
||||
}
|
||||
}, {
|
||||
name: 'Instruction',
|
||||
prompt: 'Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n# Instruction:\nWrite a story using the following information\n\n# Input:\nA man named Alex chops a tree down\n\n# Response:\n',
|
||||
prompt: 'Instruction: Write a story using the following information\n\nInput: A man named Alex chops a tree down\n\nResponse:',
|
||||
params: {
|
||||
maxResponseToken: 500,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4,
|
||||
temperature: 1,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1,
|
||||
stop: '',
|
||||
injectStart: '',
|
||||
injectEnd: ''
|
||||
@@ -124,9 +124,9 @@ export const defaultPresets: CompletionPreset[] = [{
|
||||
params: {
|
||||
maxResponseToken: 500,
|
||||
temperature: 1,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1,
|
||||
stop: '',
|
||||
injectStart: '',
|
||||
injectEnd: ''
|
||||
|
||||
@@ -13,8 +13,8 @@ import { Page } from '../components/Page';
|
||||
import { useNavigate } from 'react-router';
|
||||
import { RunButton } from '../components/RunButton';
|
||||
import { updateConfig } from '../apis';
|
||||
import { ConvertModel, FileExists } from '../../wailsjs/go/backend_golang/App';
|
||||
import { getStrategy, refreshLocalModels } from '../utils';
|
||||
import { ConvertModel, FileExists, GetPyError } from '../../wailsjs/go/backend_golang/App';
|
||||
import { getStrategy } from '../utils';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { WindowShow } from '../../wailsjs/runtime/runtime';
|
||||
import strategyImg from '../assets/images/strategy.jpg';
|
||||
@@ -253,9 +253,12 @@ export const Configs: FC = observer(() => {
|
||||
const strategy = getStrategy(selectedConfig);
|
||||
const newModelPath = modelPath + '-' + strategy.replace(/[:> *+]/g, '-');
|
||||
toast(t('Start Converting'), { autoClose: 1000, type: 'info' });
|
||||
ConvertModel(commonStore.settings.customPythonPath, modelPath, strategy, newModelPath).then(() => {
|
||||
toast(`${t('Convert Success')} - ${newModelPath}`, { type: 'success' });
|
||||
refreshLocalModels({ models: commonStore.modelSourceList }, false);
|
||||
ConvertModel(commonStore.settings.customPythonPath, modelPath, strategy, newModelPath).then(async () => {
|
||||
if (!await FileExists(newModelPath + '.pth')) {
|
||||
toast(t('Convert Failed') + ' - ' + await GetPyError(), { type: 'error' });
|
||||
} else {
|
||||
toast(`${t('Convert Success')} - ${newModelPath}`, { type: 'success' });
|
||||
}
|
||||
}).catch(e => {
|
||||
const errMsg = e.message || e;
|
||||
if (errMsg.includes('path contains space'))
|
||||
|
||||
@@ -1,10 +1,10 @@
|
||||
import React, { FC, useEffect } from 'react';
|
||||
import React, { FC } from 'react';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import { Page } from '../components/Page';
|
||||
import { observer } from 'mobx-react-lite';
|
||||
import commonStore from '../stores/commonStore';
|
||||
import { Divider, Field, ProgressBar } from '@fluentui/react-components';
|
||||
import { bytesToGb, bytesToKb, bytesToMb, refreshLocalModels } from '../utils';
|
||||
import { bytesToGb, bytesToKb, bytesToMb } from '../utils';
|
||||
import { ToolTipButton } from '../components/ToolTipButton';
|
||||
import { Folder20Regular, Pause20Regular, Play20Regular } from '@fluentui/react-icons';
|
||||
import { AddToDownloadList, OpenFileFolder, PauseDownload } from '../../wailsjs/go/backend_golang/App';
|
||||
@@ -23,12 +23,6 @@ export type DownloadStatus = {
|
||||
|
||||
export const Downloads: FC = observer(() => {
|
||||
const { t } = useTranslation();
|
||||
const finishedModelsLen = commonStore.downloadList.filter((status) => status.done && status.name.endsWith('.pth')).length;
|
||||
useEffect(() => {
|
||||
if (finishedModelsLen > 0)
|
||||
refreshLocalModels({ models: commonStore.modelSourceList }, false);
|
||||
console.log('finishedModelsLen:', finishedModelsLen);
|
||||
}, [finishedModelsLen]);
|
||||
|
||||
let displayList = commonStore.downloadList.slice();
|
||||
const downloadListNames = displayList.map(s => s.name);
|
||||
|
||||
@@ -29,7 +29,7 @@ import { botName, Conversation, ConversationMessage, MessageType, userName } fro
|
||||
import { SelectTabEventHandler } from '@fluentui/react-tabs';
|
||||
import { Labeled } from '../../components/Labeled';
|
||||
import commonStore from '../../stores/commonStore';
|
||||
import logo from '../../assets/images/logo.jpg';
|
||||
import logo from '../../assets/images/logo.png';
|
||||
import { observer } from 'mobx-react-lite';
|
||||
import { MessagesEditor } from './MessagesEditor';
|
||||
import { ClipboardGetText, ClipboardSetText } from '../../../wailsjs/runtime';
|
||||
|
||||
@@ -4,6 +4,7 @@ import { Button, Dropdown, Input, Option, Select, Switch, Tab, TabList } from '@
|
||||
import {
|
||||
ConvertData,
|
||||
FileExists,
|
||||
GetPyError,
|
||||
MergeLora,
|
||||
OpenFileFolder,
|
||||
WslCommand,
|
||||
@@ -17,7 +18,7 @@ import { toast } from 'react-toastify';
|
||||
import commonStore from '../stores/commonStore';
|
||||
import { observer } from 'mobx-react-lite';
|
||||
import { SelectTabEventHandler } from '@fluentui/react-tabs';
|
||||
import { checkDependencies, refreshLocalModels, toastWithButton } from '../utils';
|
||||
import { checkDependencies, toastWithButton } from '../utils';
|
||||
import { Section } from '../components/Section';
|
||||
import { Labeled } from '../components/Labeled';
|
||||
import { ToolTipButton } from '../components/ToolTipButton';
|
||||
@@ -37,6 +38,8 @@ import {
|
||||
import { Line } from 'react-chartjs-2';
|
||||
import { ChartJSOrUndefined } from 'react-chartjs-2/dist/types';
|
||||
import { WindowShow } from '../../wailsjs/runtime';
|
||||
import { t } from 'i18next';
|
||||
import { DialogButton } from '../components/DialogButton';
|
||||
|
||||
ChartJS.register(
|
||||
CategoryScale,
|
||||
@@ -49,15 +52,16 @@ ChartJS.register(
|
||||
);
|
||||
|
||||
const parseLossData = (data: string) => {
|
||||
const regex = /Epoch (\d+):\s+(\d+%)\|[\s\S]*\| (\d+)\/(\d+) \[(\d+:\d+)<(\d+:\d+),\s+(\d+.\d+it\/s), loss=(\d+.\d+),[\s\S]*\]/g;
|
||||
const regex = /Epoch (\d+):\s+(\d+%)\|[\s\S]*\| (\d+)\/(\d+) \[(\S+)<(\S+),\s+(\S+), loss=(\S+),[\s\S]*\]/g;
|
||||
const matches = Array.from(data.matchAll(regex));
|
||||
if (matches.length === 0)
|
||||
return;
|
||||
return false;
|
||||
const lastMatch = matches[matches.length - 1];
|
||||
const epoch = parseInt(lastMatch[1]);
|
||||
const loss = parseFloat(lastMatch[8]);
|
||||
commonStore.setChartTitle(`Epoch ${epoch}: ${lastMatch[2]} - ${lastMatch[3]}/${lastMatch[4]} - ${lastMatch[5]}/${lastMatch[6]} - ${lastMatch[7]} Loss=${loss}`);
|
||||
addLossDataToChart(epoch, loss);
|
||||
return true;
|
||||
};
|
||||
|
||||
let chartLine: ChartJSOrUndefined<'line', (number | null)[], string>;
|
||||
@@ -140,10 +144,37 @@ const loraFinetuneParametersOptions: Array<[key: keyof LoraFinetuneParameters, t
|
||||
['headQk', 'boolean', 'Head QK']
|
||||
];
|
||||
|
||||
const showError = (e: any) => {
|
||||
const msg = e.message || e;
|
||||
if (msg === 'wsl not running') {
|
||||
toast(t('WSL is not running, please retry. If it keeps happening, it means you may be using an outdated version of WSL, run "wsl --update" to update.'), { type: 'error' });
|
||||
} else {
|
||||
toast(t(msg), { type: 'error', toastId: 'train_error' });
|
||||
}
|
||||
};
|
||||
|
||||
const errorsMap = Object.entries({
|
||||
'python3 ./finetune/lora/train.py': 'Memory is not enough, try to increase the virtual memory or use a smaller base model.',
|
||||
'cuda out of memory': 'VRAM is not enough',
|
||||
'valueerror: high <= 0': 'Training data is not enough, reduce context length or add more data for training',
|
||||
'+= \'+ptx\'': 'You are using WSL 1 for training, please upgrade to WSL 2. e.g. Run "wsl --set-version Ubuntu-22.04 2"',
|
||||
'size mismatch for blocks': 'Size mismatch for blocks. You are attempting to continue training from the LoRA model, but it does not match the base model. Please set LoRA model to None.',
|
||||
'cuda_home environment variable is not set': 'Matched CUDA is not installed',
|
||||
'unsupported gpu architecture': 'Matched CUDA is not installed',
|
||||
'error building extension \'fused_adam\'': 'Matched CUDA is not installed'
|
||||
});
|
||||
|
||||
export const wslHandler = (data: string) => {
|
||||
if (data) {
|
||||
addWslMessage(data);
|
||||
parseLossData(data);
|
||||
const ok = parseLossData(data);
|
||||
if (!ok)
|
||||
for (const [key, value] of errorsMap) {
|
||||
if (data.toLowerCase().includes(key)) {
|
||||
showError(value);
|
||||
return;
|
||||
}
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
@@ -188,12 +219,8 @@ const Terminal: FC = observer(() => {
|
||||
WslStart().then(() => {
|
||||
addWslMessage('WSL> ' + input);
|
||||
setInput('');
|
||||
WslCommand(input).catch((e: any) => {
|
||||
toast((e.message || e), { type: 'error' });
|
||||
});
|
||||
}).catch((e: any) => {
|
||||
toast((e.message || e), { type: 'error' });
|
||||
});
|
||||
WslCommand(input).catch(showError);
|
||||
}).catch(showError);
|
||||
}
|
||||
};
|
||||
|
||||
@@ -208,9 +235,7 @@ const Terminal: FC = observer(() => {
|
||||
<Button onClick={() => {
|
||||
WslStop().then(() => {
|
||||
toast(t('Command Stopped'), { type: 'success' });
|
||||
}).catch((e: any) => {
|
||||
toast((e.message || e), { type: 'error' });
|
||||
});
|
||||
}).catch(showError);
|
||||
}}>
|
||||
{t('Stop')}
|
||||
</Button>
|
||||
@@ -256,7 +281,9 @@ const LoraFinetune: FC = observer(() => {
|
||||
if (!ok)
|
||||
return;
|
||||
|
||||
const convertedDataPath = `./finetune/json2binidx_tool/data/${dataParams.dataPath.split('/').pop()!.split('.')[0]}_text_document`;
|
||||
const convertedDataPath = './finetune/json2binidx_tool/data/' +
|
||||
dataParams.dataPath.replace(/[\/\\]$/, '').split(/[\/\\]/).pop()!.split('.')[0] +
|
||||
'_text_document';
|
||||
if (!await FileExists(convertedDataPath + '.idx')) {
|
||||
toast(t('Please convert data first.'), { type: 'error' });
|
||||
return;
|
||||
@@ -288,6 +315,7 @@ const LoraFinetune: FC = observer(() => {
|
||||
});
|
||||
WslCommand(`export cnMirror=${commonStore.settings.cnMirror ? '1' : '0'} ` +
|
||||
`&& export loadModel=models/${loraParams.baseModel} ` +
|
||||
`&& sed -i 's/\\r$//' finetune/install-wsl-dep-and-train.sh ` +
|
||||
`&& chmod +x finetune/install-wsl-dep-and-train.sh && ./finetune/install-wsl-dep-and-train.sh ` +
|
||||
(loraParams.baseModel ? `--load_model models/${loraParams.baseModel} ` : '') +
|
||||
(loraParams.loraLoad ? `--lora_load lora-models/${loraParams.loraLoad} ` : '') +
|
||||
@@ -301,9 +329,7 @@ const LoraFinetune: FC = observer(() => {
|
||||
`--beta1 ${loraParams.beta1} --beta2 ${loraParams.beta2} --adam_eps ${loraParams.adamEps} ` +
|
||||
`--devices ${loraParams.devices} --precision ${loraParams.precision} ` +
|
||||
`--grad_cp ${loraParams.gradCp ? '1' : '0'} ` +
|
||||
`--lora_r ${loraParams.loraR} --lora_alpha ${loraParams.loraAlpha} --lora_dropout ${loraParams.loraDropout}`).catch((e: any) => {
|
||||
toast((e.message || e), { type: 'error' });
|
||||
});
|
||||
`--lora_r ${loraParams.loraR} --lora_alpha ${loraParams.loraAlpha} --lora_dropout ${loraParams.loraDropout}`).catch(showError);
|
||||
}).catch(e => {
|
||||
const msg = e.message || e;
|
||||
if (msg === 'ubuntu not found') {
|
||||
@@ -331,9 +357,7 @@ const LoraFinetune: FC = observer(() => {
|
||||
type: 'info',
|
||||
autoClose: false
|
||||
});
|
||||
}).catch(e => {
|
||||
toast((e.message || e), { type: 'error' });
|
||||
});
|
||||
}).catch(showError);
|
||||
});
|
||||
};
|
||||
|
||||
@@ -342,7 +366,7 @@ const LoraFinetune: FC = observer(() => {
|
||||
} else if (msg.includes('wsl.state: The system cannot find the file')) {
|
||||
enableWsl(true);
|
||||
} else {
|
||||
toast(msg, { type: 'error' });
|
||||
showError(msg);
|
||||
}
|
||||
});
|
||||
};
|
||||
@@ -380,32 +404,46 @@ const LoraFinetune: FC = observer(() => {
|
||||
title={t('Data Process')}
|
||||
content={
|
||||
<div className="flex flex-col gap-2">
|
||||
<Labeled flex label={t('Data Path')}
|
||||
content={
|
||||
<div className="grow flex gap-2">
|
||||
<Input className="grow ml-2" value={dataParams.dataPath}
|
||||
onChange={(e, data) => {
|
||||
setDataParams({ dataPath: data.value });
|
||||
}} />
|
||||
<ToolTipButton desc={t('Open Folder')} icon={<Folder20Regular />} onClick={() => {
|
||||
OpenFileFolder(dataParams.dataPath, false);
|
||||
}} />
|
||||
</div>
|
||||
} />
|
||||
<div className="flex gap-2 items-center">
|
||||
{t('Data Path')}
|
||||
<Input className="grow" style={{ minWidth: 0 }} value={dataParams.dataPath}
|
||||
onChange={(e, data) => {
|
||||
setDataParams({ dataPath: data.value });
|
||||
}} />
|
||||
<DialogButton text={t('Help')} title={t('Help')} markdown
|
||||
contentText={t('The data path should be a directory or a file in jsonl format (more formats will be supported in the future).\n\n' +
|
||||
'When you provide a directory path, all the txt files within that directory will be automatically converted into training data. ' +
|
||||
'This is commonly used for large-scale training in writing, code generation, or knowledge bases.\n\n' +
|
||||
'The jsonl format file can be referenced at https://github.com/Abel2076/json2binidx_tool/blob/main/sample.jsonl.\n' +
|
||||
'You can also write it similar to OpenAI\'s playground format, as shown in https://platform.openai.com/playground/p/default-chat.\n' +
|
||||
'Even for multi-turn conversations, they must be written in a single line using `\\n` to indicate line breaks. ' +
|
||||
'If they are different dialogues or topics, they should be written in separate lines.')} />
|
||||
<ToolTipButton desc={t('Open Folder')} icon={<Folder20Regular />} onClick={() => {
|
||||
OpenFileFolder(dataParams.dataPath, false);
|
||||
}} />
|
||||
</div>
|
||||
<div className="flex gap-2 items-center">
|
||||
{t('Vocab Path')}
|
||||
<Input className="grow" style={{ minWidth: 0 }} value={dataParams.vocabPath}
|
||||
onChange={(e, data) => {
|
||||
setDataParams({ vocabPath: data.value });
|
||||
}} />
|
||||
<Button appearance="secondary" size="large" onClick={() => {
|
||||
ConvertData(commonStore.settings.customPythonPath, dataParams.dataPath,
|
||||
'./finetune/json2binidx_tool/data/' + dataParams.dataPath.split('/').pop()!.split('.')[0],
|
||||
dataParams.vocabPath).then(() => {
|
||||
toast(t('Convert Data successfully'), { type: 'success' });
|
||||
}).catch((e: any) => {
|
||||
toast((e.message || e), { type: 'error' });
|
||||
});
|
||||
<Button appearance="secondary" onClick={async () => {
|
||||
const ok = await checkDependencies(navigate);
|
||||
if (!ok)
|
||||
return;
|
||||
const outputPrefix = './finetune/json2binidx_tool/data/' +
|
||||
dataParams.dataPath.replace(/[\/\\]$/, '').split(/[\/\\]/).pop()!.split('.')[0];
|
||||
ConvertData(commonStore.settings.customPythonPath,
|
||||
dataParams.dataPath.replaceAll('\\', '/'),
|
||||
outputPrefix,
|
||||
dataParams.vocabPath).then(async () => {
|
||||
if (!await FileExists(outputPrefix + '_text_document.idx')) {
|
||||
toast(t('Failed to convert data') + ' - ' + await GetPyError(), { type: 'error' });
|
||||
} else {
|
||||
toast(t('Convert Data successfully'), { type: 'success' });
|
||||
}
|
||||
}).catch(showError);
|
||||
}}>{t('Convert')}</Button>
|
||||
</div>
|
||||
</div>
|
||||
@@ -452,14 +490,16 @@ const LoraFinetune: FC = observer(() => {
|
||||
if (!ok)
|
||||
return;
|
||||
if (loraParams.loraLoad) {
|
||||
const outputPath = `models/${loraParams.baseModel}-LoRA-${loraParams.loraLoad}`;
|
||||
MergeLora(commonStore.settings.customPythonPath, true, loraParams.loraAlpha,
|
||||
'models/' + loraParams.baseModel, 'lora-models/' + loraParams.loraLoad,
|
||||
`models/${loraParams.baseModel}-LoRA-${loraParams.loraLoad}`).then(() => {
|
||||
toast(t('Merge model successfully'), { type: 'success' });
|
||||
refreshLocalModels({ models: commonStore.modelSourceList }, false);
|
||||
}).catch((e: any) => {
|
||||
toast((e.message || e), { type: 'error' });
|
||||
});
|
||||
outputPath).then(async () => {
|
||||
if (!await FileExists(outputPath)) {
|
||||
toast(t('Failed to merge model') + ' - ' + await GetPyError(), { type: 'error' });
|
||||
} else {
|
||||
toast(t('Merge model successfully'), { type: 'success' });
|
||||
}
|
||||
}).catch(showError);
|
||||
} else {
|
||||
toast(t('Please select a LoRA model'), { type: 'info' });
|
||||
}
|
||||
@@ -521,9 +561,7 @@ const LoraFinetune: FC = observer(() => {
|
||||
<Button appearance="secondary" size="large" onClick={() => {
|
||||
WslStop().then(() => {
|
||||
toast(t('Command Stopped'), { type: 'success' });
|
||||
}).catch((e: any) => {
|
||||
toast((e.message || e), { type: 'error' });
|
||||
});
|
||||
}).catch(showError);
|
||||
}}>{t('Stop')}</Button>
|
||||
<Button appearance="primary" size="large" onClick={StartLoraFinetune}>{t('Train')}</Button>
|
||||
</div>
|
||||
|
||||
@@ -6,10 +6,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-0.1B-v1-20230520-ctx4096.pth',
|
||||
@@ -25,10 +25,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-0.4B-v1-20230529-ctx4096.pth',
|
||||
@@ -44,10 +44,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth',
|
||||
@@ -63,10 +63,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-1B5-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -82,10 +82,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-3B-v1-20230619-ctx4096.pth',
|
||||
@@ -101,10 +101,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-3B-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -120,10 +120,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-CHNtuned-3B-v1-20230625-ctx4096.pth',
|
||||
@@ -139,10 +139,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-7B-v1-20230626-ctx4096.pth',
|
||||
@@ -158,10 +158,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth',
|
||||
@@ -176,10 +176,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-1B5-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -194,10 +194,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-3B-v1-20230619-ctx4096.pth',
|
||||
@@ -212,10 +212,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-3B-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -230,10 +230,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-CHNtuned-3B-v1-20230625-ctx4096.pth',
|
||||
@@ -248,10 +248,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-7B-v1-20230626-ctx4096.pth',
|
||||
@@ -266,10 +266,10 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng98%-Other2%-20230521-ctx8192.pth',
|
||||
@@ -284,13 +284,13 @@ export const defaultModelConfigsMac: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng49%-Chn49%-Jpn1%-Other1%-20230530-ctx8192.pth',
|
||||
modelName: 'RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096.pth',
|
||||
device: 'CPU',
|
||||
precision: 'fp32',
|
||||
storedLayers: 41,
|
||||
@@ -305,10 +305,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-3B-v1-20230619-ctx4096.pth',
|
||||
@@ -324,10 +324,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-0.1B-v1-20230520-ctx4096.pth',
|
||||
@@ -342,10 +342,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-1B5-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -361,10 +361,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-0.4B-v1-20230529-ctx4096.pth',
|
||||
@@ -379,10 +379,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth',
|
||||
@@ -397,10 +397,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-1B5-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -416,10 +416,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-3B-v1-20230619-ctx4096.pth',
|
||||
@@ -435,10 +435,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-3B-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -454,10 +454,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-CHNtuned-3B-v1-20230625-ctx4096.pth',
|
||||
@@ -473,10 +473,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-7B-v1-20230626-ctx4096.pth',
|
||||
@@ -492,10 +492,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng98%-Other2%-20230521-ctx8192.pth',
|
||||
@@ -511,13 +511,13 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng49%-Chn49%-Jpn1%-Other1%-20230530-ctx8192.pth',
|
||||
modelName: 'RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096.pth',
|
||||
device: 'CUDA',
|
||||
precision: 'int8',
|
||||
storedLayers: 8,
|
||||
@@ -530,10 +530,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-1B5-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -549,10 +549,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-3B-v1-20230619-ctx4096.pth',
|
||||
@@ -568,10 +568,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-3B-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -587,10 +587,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-CHNtuned-3B-v1-20230625-ctx4096.pth',
|
||||
@@ -606,10 +606,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-7B-v1-20230626-ctx4096.pth',
|
||||
@@ -625,10 +625,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng98%-Other2%-20230521-ctx8192.pth',
|
||||
@@ -644,13 +644,13 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng49%-Chn49%-Jpn1%-Other1%-20230530-ctx8192.pth',
|
||||
modelName: 'RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096.pth',
|
||||
device: 'CUDA',
|
||||
precision: 'int8',
|
||||
storedLayers: 18,
|
||||
@@ -663,10 +663,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth',
|
||||
@@ -681,10 +681,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-3B-v1-20230619-ctx4096.pth',
|
||||
@@ -700,10 +700,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-3B-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -719,10 +719,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-CHNtuned-3B-v1-20230625-ctx4096.pth',
|
||||
@@ -738,10 +738,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-7B-v1-20230626-ctx4096.pth',
|
||||
@@ -757,10 +757,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng98%-Other2%-20230521-ctx8192.pth',
|
||||
@@ -776,13 +776,13 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng49%-Chn49%-Jpn1%-Other1%-20230530-ctx8192.pth',
|
||||
modelName: 'RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096.pth',
|
||||
device: 'CUDA',
|
||||
precision: 'int8',
|
||||
storedLayers: 27,
|
||||
@@ -795,10 +795,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-7B-v1-20230626-ctx4096.pth',
|
||||
@@ -814,10 +814,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng98%-Other2%-20230521-ctx8192.pth',
|
||||
@@ -833,13 +833,13 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng49%-Chn49%-Jpn1%-Other1%-20230530-ctx8192.pth',
|
||||
modelName: 'RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096.pth',
|
||||
device: 'CUDA',
|
||||
precision: 'int8',
|
||||
storedLayers: 41,
|
||||
@@ -852,10 +852,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-14B-v12-Eng98%-Other2%-20230523-ctx8192.pth',
|
||||
@@ -871,10 +871,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-7B-v1-20230626-ctx4096.pth',
|
||||
@@ -890,10 +890,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng98%-Other2%-20230521-ctx8192.pth',
|
||||
@@ -909,13 +909,13 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng49%-Chn49%-Jpn1%-Other1%-20230530-ctx8192.pth',
|
||||
modelName: 'RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096.pth',
|
||||
device: 'CUDA',
|
||||
precision: 'fp16',
|
||||
storedLayers: 41,
|
||||
@@ -928,10 +928,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-14B-v12-Eng98%-Other2%-20230523-ctx8192.pth',
|
||||
@@ -947,10 +947,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-14B-v12-Eng98%-Other2%-20230523-ctx8192.pth',
|
||||
@@ -966,10 +966,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-14B-v12-Eng98%-Other2%-20230523-ctx8192.pth',
|
||||
@@ -985,10 +985,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth',
|
||||
@@ -1003,10 +1003,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-1B5-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -1021,10 +1021,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-3B-v1-20230619-ctx4096.pth',
|
||||
@@ -1039,10 +1039,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-3B-v12-Eng98%-Other2%-20230520-ctx4096.pth',
|
||||
@@ -1057,10 +1057,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-CHNtuned-3B-v1-20230625-ctx4096.pth',
|
||||
@@ -1075,10 +1075,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-World-7B-v1-20230626-ctx4096.pth',
|
||||
@@ -1093,10 +1093,10 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng98%-Other2%-20230521-ctx8192.pth',
|
||||
@@ -1111,13 +1111,13 @@ export const defaultModelConfigs: ModelConfig[] = [
|
||||
apiParameters: {
|
||||
apiPort: 8000,
|
||||
maxResponseToken: 4100,
|
||||
temperature: 1.2,
|
||||
topP: 0.5,
|
||||
presencePenalty: 0.4,
|
||||
frequencyPenalty: 0.4
|
||||
temperature: 1.0,
|
||||
topP: 0.3,
|
||||
presencePenalty: 0,
|
||||
frequencyPenalty: 1
|
||||
},
|
||||
modelParameters: {
|
||||
modelName: 'RWKV-4-Raven-7B-v12-Eng49%-Chn49%-Jpn1%-Other1%-20230530-ctx8192.pth',
|
||||
modelName: 'RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096.pth',
|
||||
device: 'CPU',
|
||||
precision: 'fp32',
|
||||
storedLayers: 41,
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
import commonStore, { Platform } from './stores/commonStore';
|
||||
import { GetPlatform, ListDirFiles, ReadJson } from '../wailsjs/go/backend_golang/App';
|
||||
import { Cache, checkUpdate, downloadProgramFiles, LocalConfig, refreshModels } from './utils';
|
||||
import { Cache, checkUpdate, downloadProgramFiles, LocalConfig, refreshLocalModels, refreshModels } from './utils';
|
||||
import { getStatus } from './apis';
|
||||
import { EventsOn } from '../wailsjs/runtime';
|
||||
import manifest from '../../manifest.json';
|
||||
@@ -18,6 +18,7 @@ export async function startup() {
|
||||
EventsOn('wslerr', (e) => {
|
||||
console.log(e);
|
||||
});
|
||||
initLocalModelsNotify();
|
||||
initLoraModels();
|
||||
|
||||
initPresets();
|
||||
@@ -109,3 +110,10 @@ async function initLoraModels() {
|
||||
refreshLoraModels();
|
||||
});
|
||||
}
|
||||
|
||||
async function initLocalModelsNotify() {
|
||||
EventsOn('fsnotify', (data: string) => {
|
||||
if (data.includes('models') && !data.includes('lora-models'))
|
||||
refreshLocalModels({ models: commonStore.modelSourceList }, false); //TODO fix bug that only add models
|
||||
});
|
||||
}
|
||||
|
||||
@@ -78,10 +78,10 @@ class CommonStore {
|
||||
loraFinetuneParams: LoraFinetuneParameters = {
|
||||
baseModel: '',
|
||||
ctxLen: 1024,
|
||||
epochSteps: 1000,
|
||||
epochSteps: 200,
|
||||
epochCount: 20,
|
||||
epochBegin: 0,
|
||||
epochSave: 5,
|
||||
epochSave: 2,
|
||||
microBsz: 1,
|
||||
accumGradBatches: 8,
|
||||
preFfn: false,
|
||||
|
||||
@@ -366,7 +366,7 @@ export const checkDependencies = async (navigate: NavigateFunction) => {
|
||||
AddToDownloadList('python-3.10.11-embed-amd64.zip', 'https://www.python.org/ftp/python/3.10.11/python-3.10.11-embed-amd64.zip');
|
||||
});
|
||||
} else if (depErrorMsg.includes('DepCheck Error')) {
|
||||
if (depErrorMsg.includes('vc_redist')) {
|
||||
if (depErrorMsg.includes('vc_redist') || depErrorMsg.includes('DLL load failed while importing')) {
|
||||
toastWithButton(t('Microsoft Visual C++ Redistributable is not installed, would you like to download it?'), t('Download'), () => {
|
||||
BrowserOpenURL('https://aka.ms/vs/16/release/vc_redist.x64.exe');
|
||||
});
|
||||
|
||||
2
frontend/wailsjs/go/backend_golang/App.d.ts
generated
vendored
2
frontend/wailsjs/go/backend_golang/App.d.ts
generated
vendored
@@ -22,6 +22,8 @@ export function FileExists(arg1:string):Promise<boolean>;
|
||||
|
||||
export function GetPlatform():Promise<string>;
|
||||
|
||||
export function GetPyError():Promise<string>;
|
||||
|
||||
export function InstallPyDep(arg1:string,arg2:boolean):Promise<string>;
|
||||
|
||||
export function ListDirFiles(arg1:string):Promise<Array<backend_golang.FileInfo>>;
|
||||
|
||||
4
frontend/wailsjs/go/backend_golang/App.js
generated
4
frontend/wailsjs/go/backend_golang/App.js
generated
@@ -42,6 +42,10 @@ export function GetPlatform() {
|
||||
return window['go']['backend_golang']['App']['GetPlatform']();
|
||||
}
|
||||
|
||||
export function GetPyError() {
|
||||
return window['go']['backend_golang']['App']['GetPyError']();
|
||||
}
|
||||
|
||||
export function InstallPyDep(arg1, arg2) {
|
||||
return window['go']['backend_golang']['App']['InstallPyDep'](arg1, arg2);
|
||||
}
|
||||
|
||||
8
main.go
8
main.go
@@ -2,7 +2,6 @@ package main
|
||||
|
||||
import (
|
||||
"embed"
|
||||
"os"
|
||||
"runtime/debug"
|
||||
"strings"
|
||||
|
||||
@@ -35,13 +34,6 @@ func main() {
|
||||
backend.CopyEmbed(cyacInfo)
|
||||
backend.CopyEmbed(py)
|
||||
backend.CopyEmbed(finetune)
|
||||
os.Mkdir("models", os.ModePerm)
|
||||
os.Mkdir("lora-models", os.ModePerm)
|
||||
}
|
||||
|
||||
f, err := os.Create("lora-models/train_log.txt")
|
||||
if err == nil {
|
||||
f.Close()
|
||||
}
|
||||
|
||||
// Create an instance of the app structure
|
||||
|
||||
@@ -1,12 +1,12 @@
|
||||
{
|
||||
"version": "1.3.2",
|
||||
"version": "1.3.8",
|
||||
"introduction": {
|
||||
"en": "RWKV is an open-source, commercially usable large language model with high flexibility and great potential for development.\n### About This Tool\nThis tool aims to lower the barrier of entry for using large language models, making it accessible to everyone. It provides fully automated dependency and model management. You simply need to click and run, following the instructions, to deploy a local large language model. The tool itself is very compact and only requires a single executable file for one-click deployment.\nAdditionally, this tool offers an interface that is fully compatible with the OpenAI API. This means you can use any ChatGPT client as a client for RWKV, enabling capability expansion beyond just chat functionality.\n### Preset Configuration Rules at the Bottom\nThis tool comes with a series of preset configurations to reduce complexity. The naming rules for each configuration represent the following in order: device - required VRAM/memory - model size - model language.\nFor example, \"GPU-8G-3B-EN\" indicates that this configuration is for a graphics card with 8GB of VRAM, a model size of 3 billion parameters, and it uses an English language model.\nLarger model sizes have higher performance and VRAM requirements. Among configurations with the same model size, those with higher VRAM usage will have faster runtime.\nFor example, if you have 12GB of VRAM but running the \"GPU-12G-7B-EN\" configuration is slow, you can downgrade to \"GPU-8G-3B-EN\" for a significant speed improvement.\n### About RWKV\nRWKV is an RNN with Transformer-level LLM performance, which can also be directly trained like a GPT transformer (parallelizable). And it's 100% attention-free. You only need the hidden state at position t to compute the state at position t+1. You can use the \"GPT\" mode to quickly compute the hidden state for the \"RNN\" mode.<br/>So it's combining the best of RNN and transformer - great performance, fast inference, saves VRAM, fast training, \"infinite\" ctx_len, and free sentence embedding (using the final hidden state).",
|
||||
"zh": "RWKV是一个开源且允许商用的大语言模型,灵活性很高且极具发展潜力。\n### 关于本工具\n本工具旨在降低大语言模型的使用门槛,做到人人可用,本工具提供了全自动化的依赖和模型管理,你只需要直接点击运行,跟随引导,即可完成本地大语言模型的部署,工具本身体积极小,只需要一个exe即可完成一键部署。\n此外,本工具提供了与OpenAI API完全兼容的接口,这意味着你可以把任意ChatGPT客户端用作RWKV的客户端,实现能力拓展,而不局限于聊天。\n### 底部的预设配置规则\n本工具内置了一系列预设配置,以降低使用难度,每个配置名的规则,依次代表着:设备-所需显存/内存-模型规模-模型语言。\n例如,GPU-8G-3B-CN,表示该配置用于显卡,需要8G显存,模型规模为30亿参数,使用的是中文模型。\n模型规模越大,性能要求越高,显存要求也越高,而同样模型规模的配置中,显存占用越高的,运行速度越快。\n例如当你有12G显存,但运行GPU-12G-7B-CN配置速度比较慢,可降级成GPU-8G-3B-CN,将会大幅提速。\n### 关于RWKV\nRWKV是具有Transformer级别LLM性能的RNN,也可以像GPT Transformer一样直接进行训练(可并行化)。而且它是100% attention-free的。你只需在位置t处获得隐藏状态即可计算位置t + 1处的状态。你可以使用“GPT”模式快速计算用于“RNN”模式的隐藏状态。\n因此,它将RNN和Transformer的优点结合起来 - 高性能、快速推理、节省显存、快速训练、“无限”上下文长度以及免费的语句嵌入(使用最终隐藏状态)。"
|
||||
},
|
||||
"about": {
|
||||
"en": "<div align=\"center\">\n\nProject Source Code:\nhttps://github.com/josStorer/RWKV-Runner\nAuthor: [@josStorer](https://github.com/josStorer)\nFAQs: https://github.com/josStorer/RWKV-Runner/wiki/FAQs\n\nRelated Repositories:\nRWKV-4-Raven: https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main\nChatRWKV: https://github.com/BlinkDL/ChatRWKV\nRWKV-LM: https://github.com/BlinkDL/RWKV-LM\n\n</div>",
|
||||
"zh": "<div align=\"center\">\n\n本项目源码:\nhttps://github.com/josStorer/RWKV-Runner\n作者: [@josStorer](https://github.com/josStorer)\n演示与常见问题说明视频: https://www.bilibili.com/video/BV1hM4y1v76R\n疑难解答: https://www.bilibili.com/read/cv23921171\n\n相关仓库:\nRWKV-4-Raven: https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main\nChatRWKV: https://github.com/BlinkDL/ChatRWKV\nRWKV-LM: https://github.com/BlinkDL/RWKV-LM\n\n</div>"
|
||||
"en": "<div align=\"center\">\n\nProject Source Code:\nhttps://github.com/josStorer/RWKV-Runner\nAuthor: [@josStorer](https://github.com/josStorer)\nFAQs: https://github.com/josStorer/RWKV-Runner/wiki/FAQs\n\nRelated Repositories:\nRWKV-4-World: https://huggingface.co/BlinkDL/rwkv-4-world/tree/main\nRWKV-4-Raven: https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main\nChatRWKV: https://github.com/BlinkDL/ChatRWKV\nRWKV-LM: https://github.com/BlinkDL/RWKV-LM\nRWKV-LM-LoRA: https://github.com/Blealtan/RWKV-LM-LoRA\n\n</div>",
|
||||
"zh": "<div align=\"center\">\n\n本项目源码:\nhttps://github.com/josStorer/RWKV-Runner\n作者: [@josStorer](https://github.com/josStorer)\n演示与常见问题说明视频: https://www.bilibili.com/video/BV1hM4y1v76R\n疑难解答: https://www.bilibili.com/read/cv23921171\n\n相关仓库:\nRWKV-4-World: https://huggingface.co/BlinkDL/rwkv-4-world/tree/main\nRWKV-4-Raven: https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main\nChatRWKV: https://github.com/BlinkDL/ChatRWKV\nRWKV-LM: https://github.com/BlinkDL/RWKV-LM\nRWKV-LM-LoRA: https://github.com/Blealtan/RWKV-LM-LoRA\n\n</div>"
|
||||
},
|
||||
"programFiles": [
|
||||
{
|
||||
@@ -292,6 +292,18 @@
|
||||
"url": "https://huggingface.co/BlinkDL/rwkv-4-world/blob/main/RWKV-4-World-7B-v1-20230626-ctx4096.pth",
|
||||
"downloadUrl": "https://huggingface.co/BlinkDL/rwkv-4-world/resolve/main/RWKV-4-World-7B-v1-20230626-ctx4096.pth"
|
||||
},
|
||||
{
|
||||
"name": "RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096.pth",
|
||||
"desc": {
|
||||
"en": "Global Languages 7B v1 Enhanced Chinese",
|
||||
"zh": "全球语言 7B v1 中文增强"
|
||||
},
|
||||
"size": 15035393458,
|
||||
"SHA256": "52d33e8352a40158d21425fee4f68df1515d6324056f788d2c78a366ef578ffa",
|
||||
"lastUpdated": "2023-07-09T18:23:33",
|
||||
"url": "https://huggingface.co/BlinkDL/rwkv-4-world/blob/main/RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096.pth",
|
||||
"downloadUrl": "https://huggingface.co/BlinkDL/rwkv-4-world/resolve/main/RWKV-4-World-CHNtuned-7B-v1-20230709-ctx4096.pth"
|
||||
},
|
||||
{
|
||||
"name": "RWKV-4-Novel-7B-v1-ChnEng-ChnPro-20230410-ctx4096.pth",
|
||||
"desc": {
|
||||
|
||||
Reference in New Issue
Block a user