Compare commits
17 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
| 8ad19e115c | |||
| 250752c620 | |||
|
|
5e5f21f90e | ||
|
|
017190ccee | ||
|
|
c485502cb5 | ||
|
|
e9136d120c | ||
|
|
f88cd90ef3 | ||
|
|
b52be94d76 | ||
|
|
ed3c55ce9a | ||
|
|
9ff29cd391 | ||
|
|
54f358c51c | ||
|
|
f05a4acb04 | ||
|
|
3488d22d22 | ||
|
|
6b4381ee77 | ||
|
|
1b3aa629da | ||
|
|
79476f66a6 | ||
|
|
ef4b82a91d |
2
.github/workflows/pre-release.yml
vendored
2
.github/workflows/pre-release.yml
vendored
@ -71,7 +71,6 @@ jobs:
|
||||
rm ./backend-python/rwkv_pip/wkv_cuda.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv5.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv6.pyd
|
||||
rm ./backend-python/rwkv_pip/beta/wkv_cuda.pyd
|
||||
rm ./backend-python/get-pip.py
|
||||
rm ./backend-python/rwkv_pip/cpp/librwkv.dylib
|
||||
rm ./backend-python/rwkv_pip/cpp/rwkv.dll
|
||||
@ -100,7 +99,6 @@ jobs:
|
||||
rm ./backend-python/rwkv_pip/wkv_cuda.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv5.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv6.pyd
|
||||
rm ./backend-python/rwkv_pip/beta/wkv_cuda.pyd
|
||||
rm ./backend-python/get-pip.py
|
||||
rm ./backend-python/rwkv_pip/cpp/rwkv.dll
|
||||
rm ./backend-python/rwkv_pip/cpp/librwkv.so
|
||||
|
||||
4
.github/workflows/release.yml
vendored
4
.github/workflows/release.yml
vendored
@ -94,7 +94,6 @@ jobs:
|
||||
rm ./backend-python/rwkv_pip/wkv_cuda.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv5.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv6.pyd
|
||||
rm ./backend-python/rwkv_pip/beta/wkv_cuda.pyd
|
||||
rm ./backend-python/get-pip.py
|
||||
rm ./backend-python/rwkv_pip/cpp/librwkv.dylib
|
||||
rm ./backend-python/rwkv_pip/cpp/rwkv.dll
|
||||
@ -121,7 +120,6 @@ jobs:
|
||||
rm ./backend-python/rwkv_pip/wkv_cuda.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv5.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv6.pyd
|
||||
rm ./backend-python/rwkv_pip/beta/wkv_cuda.pyd
|
||||
rm ./backend-python/get-pip.py
|
||||
rm ./backend-python/rwkv_pip/cpp/rwkv.dll
|
||||
rm ./backend-python/rwkv_pip/cpp/librwkv.so
|
||||
@ -135,7 +133,7 @@ jobs:
|
||||
|
||||
publish-release:
|
||||
runs-on: ubuntu-22.04
|
||||
needs: [windows, linux, macos]
|
||||
needs: [ windows, linux, macos ]
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- run: gh release edit ${{github.ref_name}} --draft=false
|
||||
|
||||
@ -1,7 +1,26 @@
|
||||
## Changes
|
||||
## v1.8.4
|
||||
|
||||
- improve dynamic state api
|
||||
- fix a tps error
|
||||
- fix f05a4a, __init__.py is not embedded
|
||||
|
||||
## v1.8.3
|
||||
|
||||
### Deprecations
|
||||
|
||||
- rwkv-beta is deprecated
|
||||
|
||||
### Upgrades
|
||||
|
||||
- bump webgpu(python) (https://github.com/cryscan/web-rwkv-py)
|
||||
- sync https://github.com/JL-er/RWKV-PEFT (LoRA)
|
||||
|
||||
### Improvements
|
||||
|
||||
- improve default LoRA fine-tune params
|
||||
|
||||
### Fixes
|
||||
|
||||
- fix #342, #345: cannot import name 'packaging' from 'pkg_resources'
|
||||
- fix the huge error prompt that pops up when running in webgpu mode
|
||||
|
||||
## Install
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
<p align="center">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/d24834b0-265d-45f5-93c0-fac1e19562af">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/65c46133-7506-4b54-b64f-fe49f188afa7">
|
||||
</p>
|
||||
|
||||
<h1 align="center">RWKV Runner</h1>
|
||||
@ -248,13 +248,13 @@ computer keyboard as MIDI input.
|
||||
|
||||
### Homepage
|
||||
|
||||
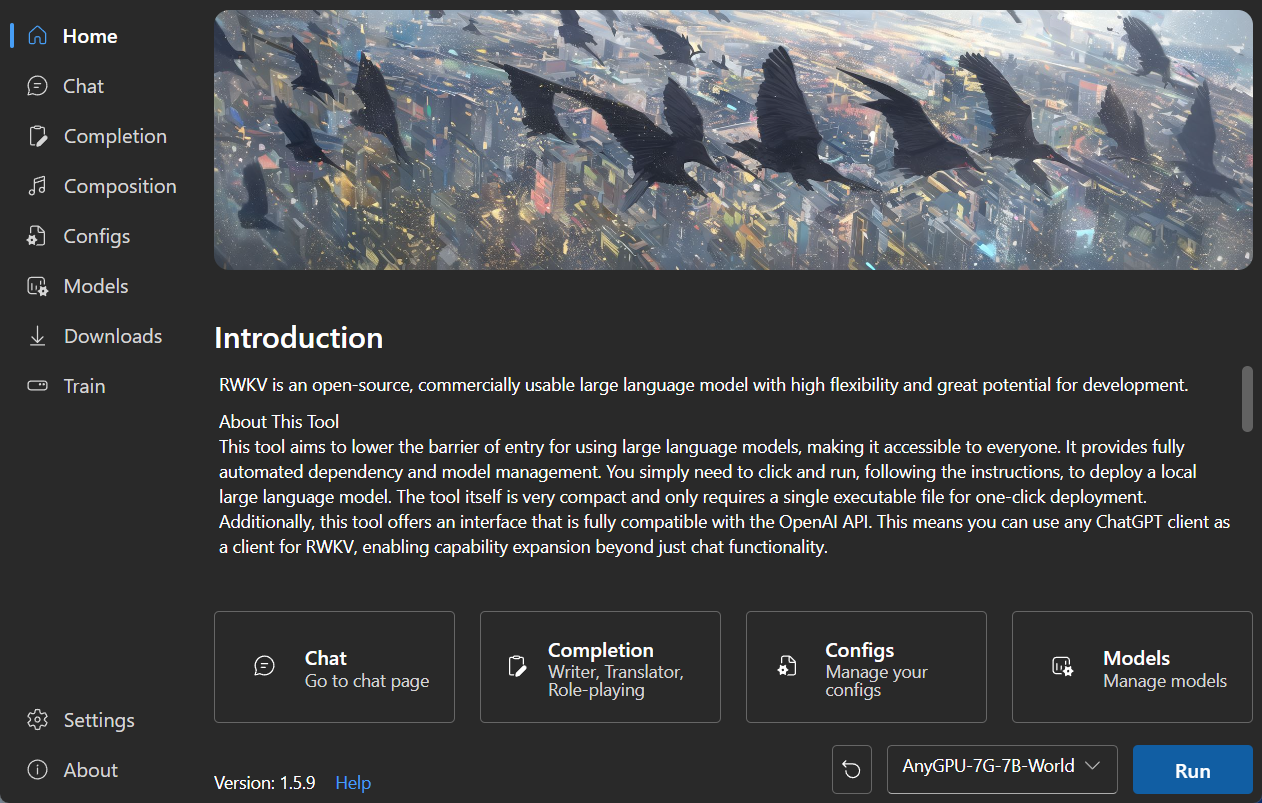
|
||||

|
||||
|
||||
### Chat
|
||||
|
||||
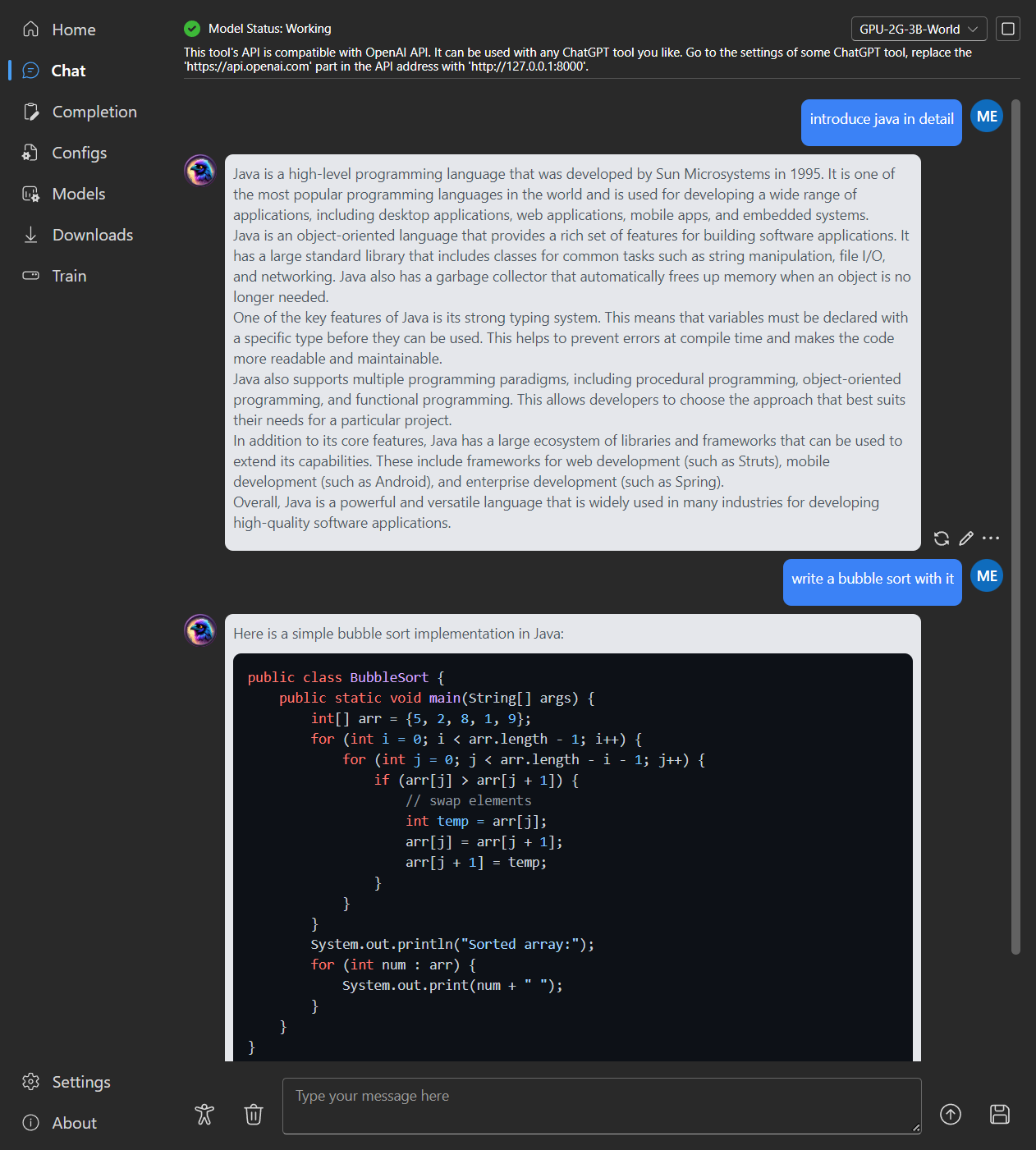
|
||||
|
||||
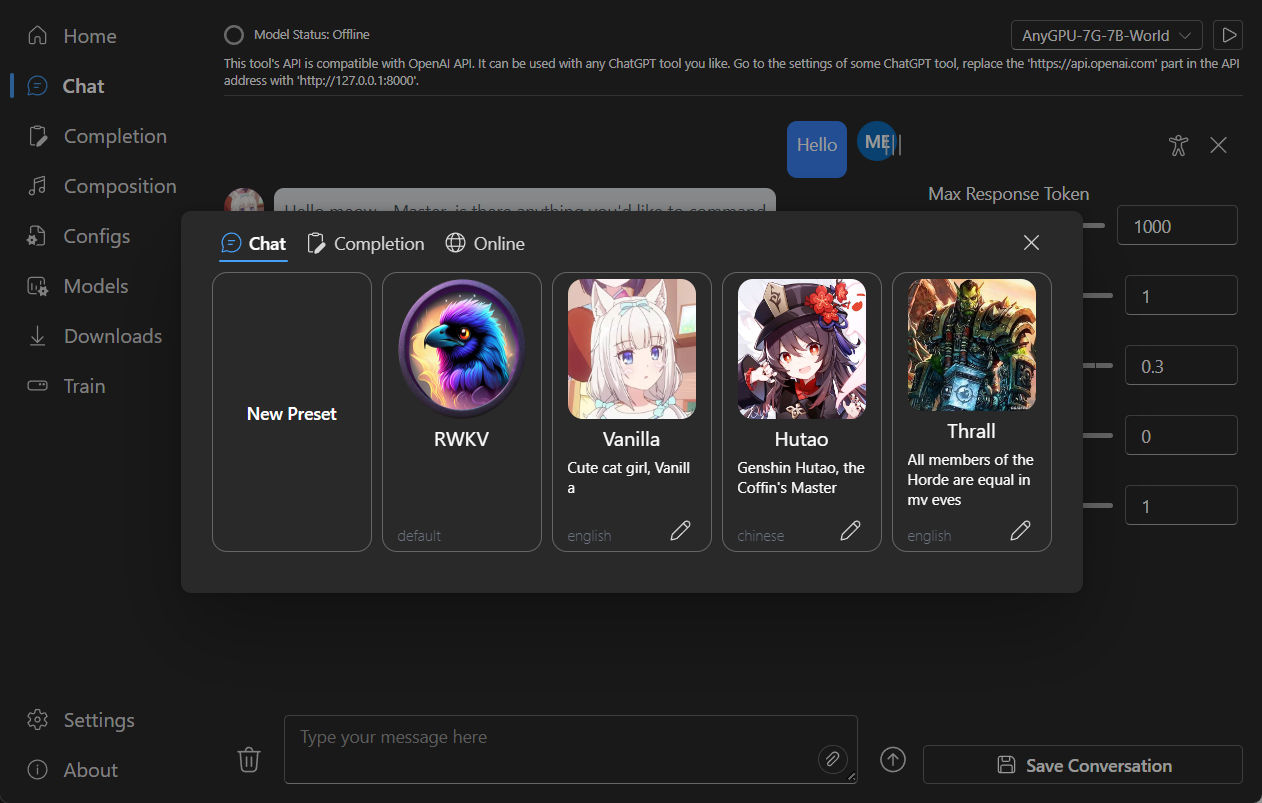
|
||||

|
||||
|
||||
### Completion
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
<p align="center">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/d24834b0-265d-45f5-93c0-fac1e19562af">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/65c46133-7506-4b54-b64f-fe49f188afa7">
|
||||
</p>
|
||||
|
||||
<h1 align="center">RWKV Runner</h1>
|
||||
@ -244,13 +244,13 @@ MIDIキーボードをお持ちでない場合、`Virtual Midi Controller 3 LE`
|
||||
|
||||
### ホームページ
|
||||
|
||||

|
||||

|
||||
|
||||
### チャット
|
||||
|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
### 補完
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
<p align="center">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/d24834b0-265d-45f5-93c0-fac1e19562af">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/65c46133-7506-4b54-b64f-fe49f188afa7">
|
||||
</p>
|
||||
|
||||
<h1 align="center">RWKV Runner</h1>
|
||||
@ -226,13 +226,13 @@ for i in np.argsort(embeddings_cos_sim)[::-1]:
|
||||
|
||||
### 主页
|
||||
|
||||
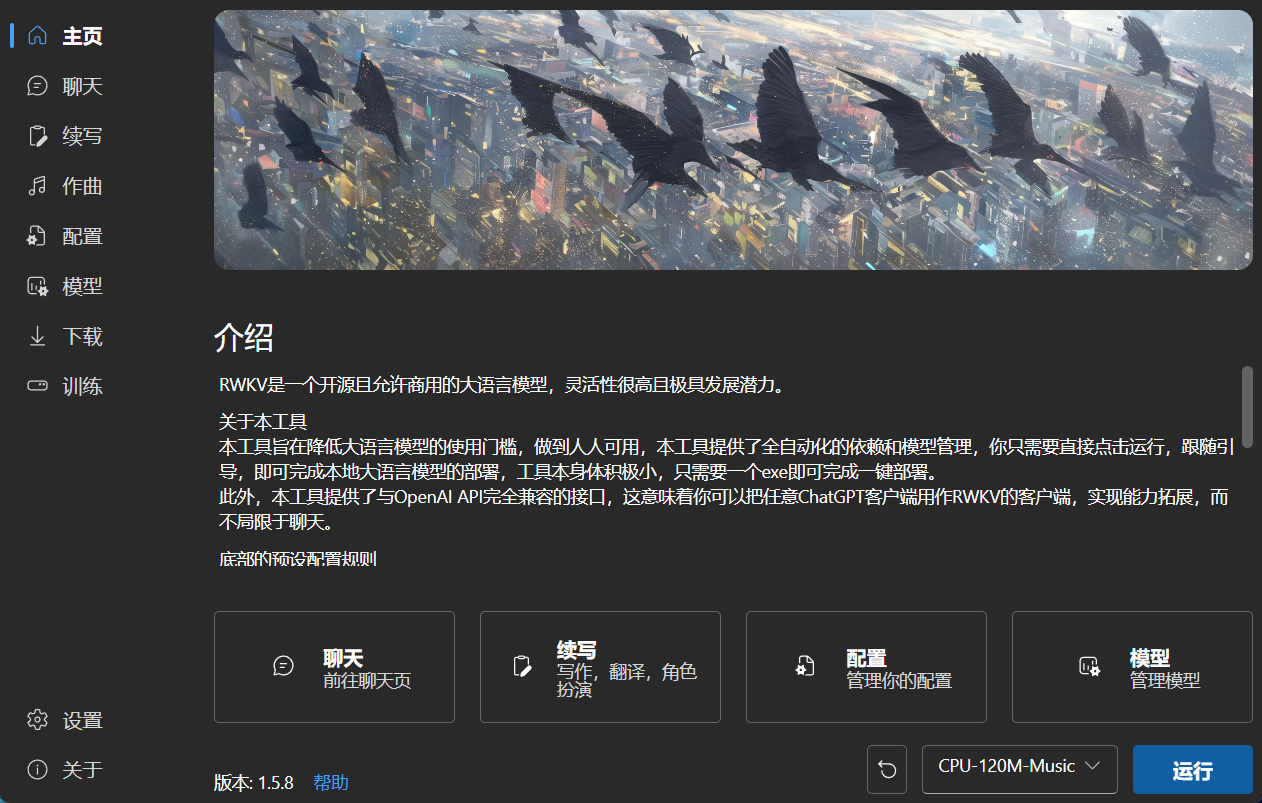
|
||||

|
||||
|
||||
### 聊天
|
||||
|
||||
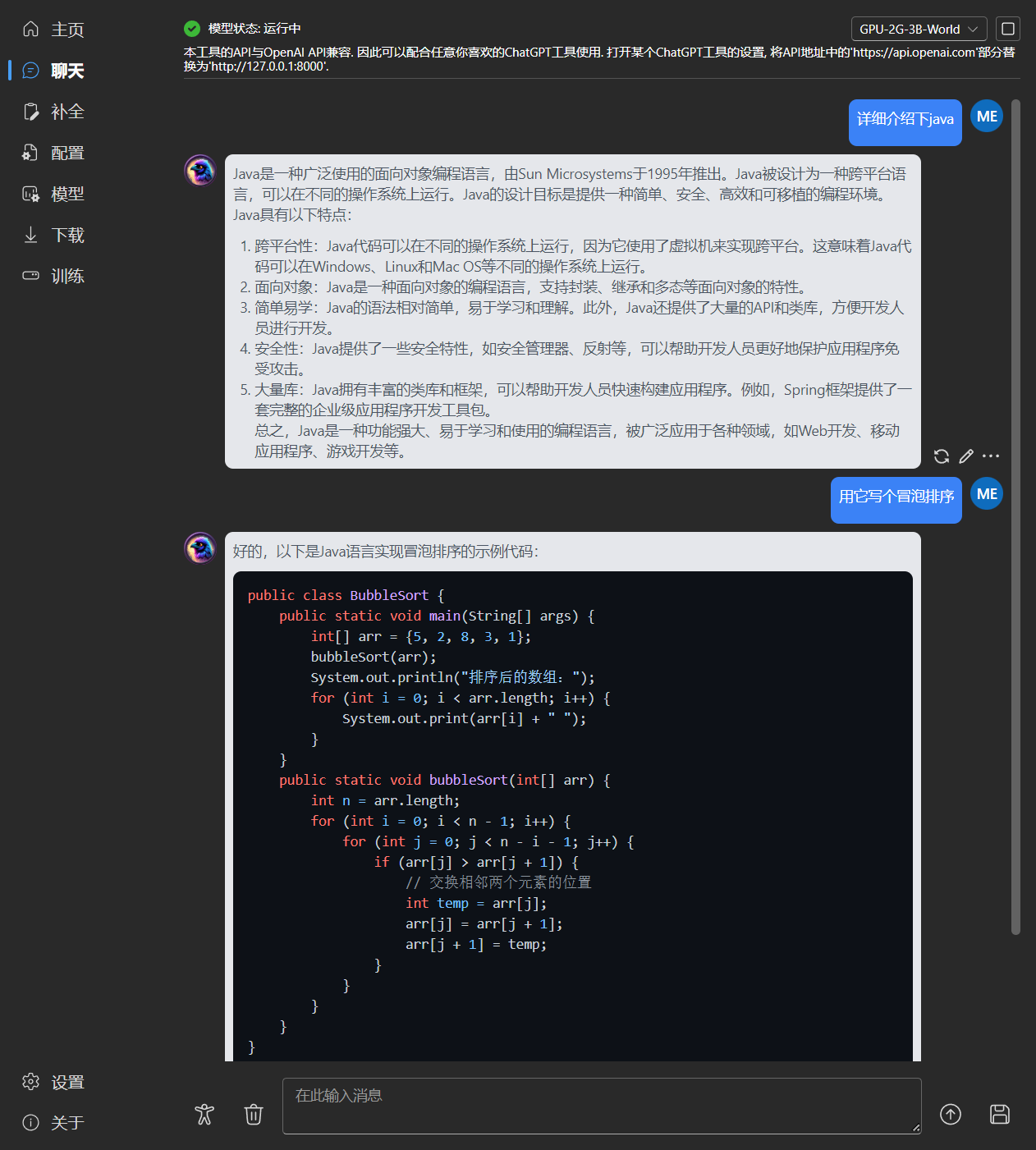
|
||||
|
||||
|
||||

|
||||
|
||||
### 续写
|
||||
|
||||
|
||||
@ -28,7 +28,7 @@ func (a *App) StartServer(python string, port int, host string, webui bool, rwkv
|
||||
args = append(args, "--webui")
|
||||
}
|
||||
if rwkvBeta {
|
||||
args = append(args, "--rwkv-beta")
|
||||
// args = append(args, "--rwkv-beta")
|
||||
}
|
||||
if rwkvcpp {
|
||||
args = append(args, "--rwkv.cpp")
|
||||
|
||||
@ -1,3 +1,8 @@
|
||||
import setuptools
|
||||
|
||||
if setuptools.__version__ >= "70.0.0":
|
||||
raise ImportError("setuptools>=70.0.0 is not supported")
|
||||
|
||||
import multipart
|
||||
import fitz
|
||||
import safetensors
|
||||
|
||||
@ -27,11 +27,6 @@ def get_args(args: Union[Sequence[str], None] = None):
|
||||
action="store_true",
|
||||
help="whether to enable WebUI (default: False)",
|
||||
)
|
||||
group.add_argument(
|
||||
"--rwkv-beta",
|
||||
action="store_true",
|
||||
help="whether to use rwkv-beta (default: False)",
|
||||
)
|
||||
group.add_argument(
|
||||
"--rwkv.cpp",
|
||||
action="store_true",
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
torch
|
||||
torchvision
|
||||
torchaudio
|
||||
setuptools==69.5.1
|
||||
rwkv==0.8.26
|
||||
langchain==0.0.322
|
||||
fastapi==0.109.1
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
torch
|
||||
torchvision
|
||||
torchaudio
|
||||
setuptools==69.5.1
|
||||
rwkv==0.8.26
|
||||
langchain==0.0.322
|
||||
fastapi==0.109.1
|
||||
|
||||
@ -171,12 +171,15 @@ async def eval_rwkv(
|
||||
),
|
||||
# "response": response,
|
||||
"model": model.name,
|
||||
"id": "chatcmpl-123",
|
||||
"system_fingerprint": "fp_44709d6fcb",
|
||||
"choices": [
|
||||
(
|
||||
{
|
||||
"delta": {"content": delta},
|
||||
"delta": {"role":Role.Assistant.value,"content": delta},
|
||||
"index": 0,
|
||||
"finish_reason": None,
|
||||
"logprobs":None
|
||||
}
|
||||
if chat_mode
|
||||
else {
|
||||
@ -218,11 +221,14 @@ async def eval_rwkv(
|
||||
),
|
||||
# "response": response,
|
||||
"model": model.name,
|
||||
"id": "chatcmpl-123",
|
||||
"system_fingerprint": "fp_44709d6fcb",
|
||||
"choices": [
|
||||
(
|
||||
{
|
||||
"delta": {},
|
||||
"index": 0,
|
||||
"logprobs": None,
|
||||
"finish_reason": "stop",
|
||||
}
|
||||
if chat_mode
|
||||
|
||||
@ -96,7 +96,9 @@ def copy_tensor_to_cpu(tensors):
|
||||
elif tensors_type == np.ndarray: # rwkv.cpp
|
||||
copied = tensors
|
||||
else: # WebGPU state
|
||||
copied = tensors.back()
|
||||
model = global_var.get(global_var.Model)
|
||||
if model:
|
||||
copied = model.model.model.back_state()
|
||||
|
||||
return copied, devices
|
||||
|
||||
@ -238,11 +240,14 @@ def longest_prefix_state(body: LongestPrefixStateBody, request: Request):
|
||||
state: Union[Any, None] = v["state"]
|
||||
logits: Union[Any, None] = v["logits"]
|
||||
|
||||
if type(state) == list and hasattr(state[0], "device"): # torch
|
||||
state_type = type(state)
|
||||
if state_type == list and hasattr(state[0], "device"): # torch
|
||||
state = [
|
||||
tensor.to(devices[i])
|
||||
if devices[i] != torch.device("cpu")
|
||||
else tensor.clone()
|
||||
(
|
||||
tensor.to(devices[i])
|
||||
if devices[i] != torch.device("cpu")
|
||||
else tensor.clone()
|
||||
)
|
||||
for i, tensor in enumerate(state)
|
||||
]
|
||||
logits = (
|
||||
@ -250,7 +255,9 @@ def longest_prefix_state(body: LongestPrefixStateBody, request: Request):
|
||||
if logits_device != torch.device("cpu")
|
||||
else logits.clone()
|
||||
)
|
||||
else: # rwkv.cpp, WebGPU
|
||||
elif state_type == np.ndarray: # rwkv.cpp
|
||||
logits = np.copy(logits)
|
||||
else: # WebGPU
|
||||
logits = np.copy(logits)
|
||||
|
||||
quick_log(request, body, "Hit:\n" + prompt)
|
||||
|
||||
124
backend-python/rwkv_pip/beta/cuda/att_one.cu
vendored
124
backend-python/rwkv_pip/beta/cuda/att_one.cu
vendored
@ -1,124 +0,0 @@
|
||||
#include "ATen/ATen.h"
|
||||
#include <cuda_fp16.h>
|
||||
#include <cuda_runtime.h>
|
||||
#include <torch/extension.h>
|
||||
|
||||
#include "element_wise.h"
|
||||
#include "util.h"
|
||||
|
||||
// Equivalent Python code:
|
||||
// ww = t_first + k
|
||||
// p = torch.maximum(pp, ww)
|
||||
// e1 = torch.exp(pp - p)
|
||||
// e2 = torch.exp(ww - p)
|
||||
// wkv = ((e1 * aa + e2 * v) / (e1 * bb + e2)).to(dtype=x.dtype)
|
||||
// ww = t_decay + pp
|
||||
// p = torch.maximum(ww, k)
|
||||
// e1 = torch.exp(ww - p)
|
||||
// e2 = torch.exp(k - p)
|
||||
// t1 = e1 * aa + e2 * v
|
||||
// t2 = e1 * bb + e2
|
||||
// r = r * wkv
|
||||
// return t1, t2, p, r
|
||||
struct WkvForwardOne {
|
||||
const float *t_first;
|
||||
const float *k;
|
||||
const float *pp;
|
||||
const float *aa;
|
||||
const float *bb;
|
||||
const float *t_decay;
|
||||
const float *v;
|
||||
/* out */ float *t1;
|
||||
/* out */ float *t2;
|
||||
/* out */ float *p;
|
||||
/* in & out */ half *r;
|
||||
|
||||
__device__ void operator()(int i) const {
|
||||
float ww = t_first[i] + k[i];
|
||||
float pp_ = pp[i];
|
||||
float p_ = (pp_ > ww) ? pp_ : ww;
|
||||
float e1 = expf(pp_ - p_);
|
||||
float e2 = expf(ww - p_);
|
||||
float aa_ = aa[i];
|
||||
float bb_ = bb[i];
|
||||
float v_ = v[i];
|
||||
r[i] = __hmul(r[i], __float2half(((e1 * aa_ + e2 * v_) / (e1 * bb_ + e2))));
|
||||
ww = t_decay[i] + pp_;
|
||||
float k_ = k[i];
|
||||
p_ = (ww > k_) ? ww : k_;
|
||||
e1 = expf(ww - p_);
|
||||
e2 = expf(k_ - p_);
|
||||
t1[i] = e1 * aa_ + e2 * v_;
|
||||
t2[i] = e1 * bb_ + e2;
|
||||
p[i] = p_;
|
||||
}
|
||||
};
|
||||
|
||||
/*
|
||||
Equivalent Python code:
|
||||
kx = xx * k_mix + sx * (1 - k_mix)
|
||||
vx = xx * v_mix + sx * (1 - v_mix)
|
||||
rx = xx * r_mix + sx * (1 - r_mix)
|
||||
*/
|
||||
|
||||
struct Mix {
|
||||
const half *xx;
|
||||
const half *sx;
|
||||
const half *k_mix;
|
||||
const half *v_mix;
|
||||
const half *r_mix;
|
||||
/* out */ half *kx;
|
||||
/* out */ half *vx;
|
||||
/* out */ half *rx;
|
||||
|
||||
__device__ void operator()(int i) const {
|
||||
half xx_ = xx[i];
|
||||
half sx_ = sx[i];
|
||||
half k_mix_ = k_mix[i];
|
||||
half v_mix_ = v_mix[i];
|
||||
half r_mix_ = r_mix[i];
|
||||
kx[i] = __hadd(__hmul(xx_, k_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), k_mix_)));
|
||||
vx[i] = __hadd(__hmul(xx_, v_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), v_mix_)));
|
||||
rx[i] = __hadd(__hmul(xx_, r_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), r_mix_)));
|
||||
}
|
||||
};
|
||||
|
||||
using torch::Tensor;
|
||||
|
||||
void gemm_fp16_cublas_tensor(Tensor a, Tensor b, Tensor c);
|
||||
|
||||
Tensor att_one(Tensor x, Tensor ln_w, Tensor ln_b, Tensor sx, Tensor k_mix,
|
||||
Tensor v_mix, Tensor r_mix, Tensor kw,
|
||||
/* imm */ Tensor kx, Tensor vw, /* imm */ Tensor vx, Tensor rw,
|
||||
/* imm */ Tensor rx, Tensor ow, Tensor t_first,
|
||||
/* imm */ Tensor k, Tensor pp, Tensor ww, Tensor aa, Tensor bb,
|
||||
Tensor t_decay, /* imm */ Tensor v, /* in & out */ Tensor r,
|
||||
/* out */ Tensor x_plus_out, /* out */ Tensor t1,
|
||||
/* out */ Tensor t2, /* out */ Tensor p) {
|
||||
Tensor xx = at::layer_norm(x, {x.size(-1)}, ln_w, ln_b);
|
||||
element_wise(Mix{data_ptr<half>(xx), data_ptr<half>(sx),
|
||||
data_ptr<half>(k_mix), data_ptr<half>(v_mix),
|
||||
data_ptr<half>(r_mix), data_ptr<half>(kx),
|
||||
data_ptr<half>(vx), data_ptr<half>(rx)},
|
||||
x.numel());
|
||||
|
||||
gemm_fp16_cublas_tensor(kx, kw, k);
|
||||
gemm_fp16_cublas_tensor(vx, vw, v);
|
||||
gemm_fp16_cublas_tensor(rx, rw, r);
|
||||
at::sigmoid_(r);
|
||||
|
||||
element_wise(WkvForwardOne{data_ptr<float>(t_first), data_ptr<float>(k),
|
||||
data_ptr<float>(pp), data_ptr<float>(aa),
|
||||
data_ptr<float>(bb), data_ptr<float>(t_decay),
|
||||
data_ptr<float>(v), data_ptr<float>(t1),
|
||||
data_ptr<float>(t2), data_ptr<float>(p),
|
||||
data_ptr<half>(r)},
|
||||
x.numel());
|
||||
|
||||
gemm_fp16_cublas_tensor(r, ow, x_plus_out);
|
||||
x_plus_out += x;
|
||||
return xx;
|
||||
}
|
||||
109
backend-python/rwkv_pip/beta/cuda/att_one_v5.cu
vendored
109
backend-python/rwkv_pip/beta/cuda/att_one_v5.cu
vendored
@ -1,109 +0,0 @@
|
||||
#include "ATen/ATen.h"
|
||||
#include <cuda_fp16.h>
|
||||
#include <cuda_runtime.h>
|
||||
#include <torch/extension.h>
|
||||
|
||||
#include "element_wise.h"
|
||||
#include "util.h"
|
||||
|
||||
// Equivalent Python code:
|
||||
// s1 = t_first * a + s
|
||||
// s2 = a + t_decay * s
|
||||
struct Fused1 {
|
||||
const float *t_first;
|
||||
const float *t_decay;
|
||||
const float *a;
|
||||
const float *s;
|
||||
const int32_t inner_size;
|
||||
/* out */ float *s1;
|
||||
/* out */ float *s2;
|
||||
|
||||
__device__ void operator()(int i) const {
|
||||
const int j = i / inner_size;
|
||||
s1[i] = t_first[j] * a[i] + s[i];
|
||||
s2[i] = a[i] + t_decay[j] * s[i];
|
||||
}
|
||||
};
|
||||
|
||||
/*
|
||||
Equivalent Python code:
|
||||
kx = xx * k_mix + sx * (1 - k_mix)
|
||||
vx = xx * v_mix + sx * (1 - v_mix)
|
||||
rx = xx * r_mix + sx * (1 - r_mix)
|
||||
*/
|
||||
|
||||
struct Mix {
|
||||
const half *xx;
|
||||
const half *sx;
|
||||
const half *k_mix;
|
||||
const half *v_mix;
|
||||
const half *r_mix;
|
||||
/* out */ half *kx;
|
||||
/* out */ half *vx;
|
||||
/* out */ half *rx;
|
||||
|
||||
__device__ void operator()(int i) const {
|
||||
half xx_ = xx[i];
|
||||
half sx_ = sx[i];
|
||||
half k_mix_ = k_mix[i];
|
||||
half v_mix_ = v_mix[i];
|
||||
half r_mix_ = r_mix[i];
|
||||
kx[i] = __hadd(__hmul(xx_, k_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), k_mix_)));
|
||||
vx[i] = __hadd(__hmul(xx_, v_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), v_mix_)));
|
||||
rx[i] = __hadd(__hmul(xx_, r_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), r_mix_)));
|
||||
}
|
||||
};
|
||||
|
||||
using torch::Tensor;
|
||||
|
||||
void gemm_fp16_cublas_tensor(Tensor a, Tensor b, Tensor c);
|
||||
|
||||
Tensor att_one_v5(Tensor x, Tensor sx, Tensor s, Tensor ln_w, Tensor ln_b,
|
||||
Tensor lx_w, Tensor lx_b, Tensor k_mix, Tensor v_mix,
|
||||
Tensor r_mix, Tensor kw,
|
||||
/* imm */ Tensor kx, Tensor vw, /* imm */ Tensor vx,
|
||||
Tensor rw,
|
||||
/* imm */ Tensor rx, Tensor ow, Tensor t_first,
|
||||
/* imm */ Tensor k, Tensor t_decay, /* imm */ Tensor v,
|
||||
/* imm */ Tensor r, /* imm */ Tensor s1,
|
||||
/* out */ Tensor x_plus_out, /* out */ Tensor s2) {
|
||||
Tensor xx = at::layer_norm(x, {x.size(-1)}, ln_w, ln_b);
|
||||
element_wise(Mix{data_ptr<half>(xx), data_ptr<half>(sx),
|
||||
data_ptr<half>(k_mix), data_ptr<half>(v_mix),
|
||||
data_ptr<half>(r_mix), data_ptr<half>(kx),
|
||||
data_ptr<half>(vx), data_ptr<half>(rx)},
|
||||
x.numel());
|
||||
|
||||
int H = t_decay.size(0);
|
||||
int S = x.size(-1) / H;
|
||||
gemm_fp16_cublas_tensor(rx, rw, r);
|
||||
r = at::reshape(r, {H, 1, S});
|
||||
gemm_fp16_cublas_tensor(kx, kw, k);
|
||||
k = at::reshape(k, {H, S, 1});
|
||||
gemm_fp16_cublas_tensor(vx, vw, v);
|
||||
v = at::reshape(v, {H, 1, S});
|
||||
|
||||
{
|
||||
Tensor a = at::matmul(k, v);
|
||||
|
||||
// s1 = t_first * a + s
|
||||
// s2 = a + t_decay * s
|
||||
element_wise(Fused1{data_ptr<float>(t_first), data_ptr<float>(t_decay),
|
||||
data_ptr<float>(a), data_ptr<float>(s),
|
||||
static_cast<int32_t>(a.size(1) * a.size(2)),
|
||||
data_ptr<float>(s1), data_ptr<float>(s2)},
|
||||
a.numel());
|
||||
}
|
||||
|
||||
Tensor out = at::matmul(r, s1);
|
||||
out = at::flatten(out);
|
||||
out = at::squeeze(at::group_norm(at::unsqueeze(out, 0), H, lx_w, lx_b), 0);
|
||||
out = at::_cast_Half(out);
|
||||
|
||||
gemm_fp16_cublas_tensor(out, ow, x_plus_out);
|
||||
x_plus_out += x;
|
||||
return xx;
|
||||
}
|
||||
178
backend-python/rwkv_pip/beta/cuda/att_seq.cu
vendored
178
backend-python/rwkv_pip/beta/cuda/att_seq.cu
vendored
@ -1,178 +0,0 @@
|
||||
#include "ATen/ATen.h"
|
||||
#include <cuda_fp16.h>
|
||||
#include <cuda_runtime.h>
|
||||
#include <torch/extension.h>
|
||||
|
||||
#include "util.h"
|
||||
#include "element_wise.h"
|
||||
|
||||
using torch::Tensor;
|
||||
|
||||
void gemm_fp16_cublas(const void *a, const void *b, void *c, int m,
|
||||
int n, int k, bool output_fp32);
|
||||
|
||||
// based on `kernel_wkv_forward`, fusing more operations
|
||||
__global__ void kernel_wkv_forward_new(
|
||||
const int B, const int T, const int C, const float *__restrict__ const _w,
|
||||
const float *__restrict__ const _u, const float *__restrict__ const _k,
|
||||
const float *__restrict__ const _v, const half *__restrict__ const r,
|
||||
half *__restrict__ const _y, float *__restrict__ const _aa,
|
||||
float *__restrict__ const _bb, float *__restrict__ const _pp) {
|
||||
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
|
||||
const int _b = idx / C;
|
||||
const int _c = idx % C;
|
||||
const int _offset = _b * T * C + _c;
|
||||
const int _state_offset = _b * C + _c;
|
||||
|
||||
float u = _u[_c];
|
||||
float w = _w[_c];
|
||||
const float *__restrict__ const k = _k + _offset;
|
||||
const float *__restrict__ const v = _v + _offset;
|
||||
half *__restrict__ const y = _y + _offset;
|
||||
|
||||
float aa = _aa[_state_offset];
|
||||
float bb = _bb[_state_offset];
|
||||
float pp = _pp[_state_offset];
|
||||
for (int i = 0; i < T; i++) {
|
||||
const int ii = i * C;
|
||||
const float kk = k[ii];
|
||||
const float vv = v[ii];
|
||||
float ww = u + kk;
|
||||
float p = max(pp, ww);
|
||||
float e1 = exp(pp - p);
|
||||
float e2 = exp(ww - p);
|
||||
y[ii] = __float2half((e1 * aa + e2 * vv) / (e1 * bb + e2));
|
||||
ww = w + pp;
|
||||
p = max(ww, kk);
|
||||
e1 = exp(ww - p);
|
||||
e2 = exp(kk - p);
|
||||
aa = e1 * aa + e2 * vv;
|
||||
bb = e1 * bb + e2;
|
||||
pp = p;
|
||||
}
|
||||
_aa[_state_offset] = aa;
|
||||
_bb[_state_offset] = bb;
|
||||
_pp[_state_offset] = pp;
|
||||
}
|
||||
|
||||
void cuda_wkv_forward_new(int B, int T, int C, float *w, float *u, float *k,
|
||||
float *v, half *r, half *y, float *aa, float *bb,
|
||||
float *pp) {
|
||||
dim3 threadsPerBlock(min(C, 32));
|
||||
assert(B * C % threadsPerBlock.x == 0);
|
||||
dim3 numBlocks(B * C / threadsPerBlock.x);
|
||||
kernel_wkv_forward_new<<<numBlocks, threadsPerBlock>>>(B, T, C, w, u, k, v, r,
|
||||
y, aa, bb, pp);
|
||||
}
|
||||
|
||||
__global__ void _att_mix(const half *xx, const half *sx, const half *k_mix,
|
||||
const half *v_mix, const half *r_mix,
|
||||
const int outer_size, const int inner_size, half *kx,
|
||||
half *vx, half *rx) {
|
||||
for (int idx2 = blockIdx.x * blockDim.x + threadIdx.x; idx2 < inner_size;
|
||||
idx2 += blockDim.x * gridDim.x) {
|
||||
half k_mix_ = k_mix[idx2];
|
||||
half v_mix_ = v_mix[idx2];
|
||||
half r_mix_ = r_mix[idx2];
|
||||
for (int row = 0; row < outer_size; ++row) {
|
||||
int idx1 = row * inner_size + idx2;
|
||||
half xx_ = xx[idx1];
|
||||
half sx_ = sx[idx1];
|
||||
kx[idx1] = __hadd(__hmul(xx_, k_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), k_mix_)));
|
||||
vx[idx1] = __hadd(__hmul(xx_, v_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), v_mix_)));
|
||||
rx[idx1] = __hadd(__hmul(xx_, r_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), r_mix_)));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void att_mix(const half *xx, const half *sx, const half *k_mix,
|
||||
const half *v_mix, const half *r_mix, const int outer_size,
|
||||
const int inner_size, half *kx, half *vx, half *rx) {
|
||||
// 256 is good enough on most GPUs
|
||||
const int32_t BLOCK_SIZE = 256;
|
||||
assert(inner_size % BLOCK_SIZE == 0);
|
||||
_att_mix<<<inner_size / BLOCK_SIZE, BLOCK_SIZE>>>(
|
||||
xx, sx, k_mix, v_mix, r_mix, outer_size, inner_size, kx, vx, rx);
|
||||
}
|
||||
|
||||
struct InplaceSigmoid {
|
||||
__device__ __forceinline__ half operator()(int i) const {
|
||||
ptr[i] = __float2half(1.0 / (1.0 + exp(-__half2float(ptr[i]))));
|
||||
}
|
||||
half *ptr;
|
||||
};
|
||||
|
||||
struct InplaceMul {
|
||||
__device__ __forceinline__ half operator()(int i) const {
|
||||
y[i] = __hmul(x[i], y[i]);
|
||||
}
|
||||
half *y;
|
||||
half *x;
|
||||
};
|
||||
|
||||
/*
|
||||
Equivalent Python code:
|
||||
|
||||
xx = F.layer_norm(x, (x.shape[-1],), weight=ln_w, bias=ln_b)
|
||||
sx = torch.cat((sx.unsqueeze(0), xx[:-1,:]))
|
||||
kx = xx * k_mix + sx * (1 - k_mix)
|
||||
vx = xx * v_mix + sx * (1 - v_mix)
|
||||
rx = xx * r_mix + sx * (1 - r_mix)
|
||||
|
||||
r = torch.sigmoid(gemm(rx, rw))
|
||||
k = gemm(kx, kw, output_dtype=torch.float32)
|
||||
v = gemm(vx, vw, output_dtype=torch.float32)
|
||||
|
||||
T = x.shape[0]
|
||||
for t in range(T):
|
||||
kk = k[t]
|
||||
vv = v[t]
|
||||
ww = t_first + kk
|
||||
p = torch.maximum(pp, ww)
|
||||
e1 = torch.exp(pp - p)
|
||||
e2 = torch.exp(ww - p)
|
||||
sx[t] = ((e1 * aa + e2 * vv) / (e1 * bb + e2)).to(dtype=x.dtype)
|
||||
ww = t_decay + pp
|
||||
p = torch.maximum(ww, kk)
|
||||
e1 = torch.exp(ww - p)
|
||||
e2 = torch.exp(kk - p)
|
||||
aa = e1 * aa + e2 * vv
|
||||
bb = e1 * bb + e2
|
||||
pp = p
|
||||
out = gemm(r * sx, ow)
|
||||
return x + out, xx[-1,:], aa, bb, pp
|
||||
*/
|
||||
Tensor att_seq(Tensor x, Tensor sx, Tensor ln_w, Tensor ln_b, Tensor k_mix,
|
||||
Tensor v_mix, Tensor r_mix, Tensor kw, Tensor vw, Tensor rw,
|
||||
Tensor ow, Tensor t_first, Tensor pp, Tensor aa, Tensor bb,
|
||||
Tensor t_decay, /* imm */ Tensor buf, /* out */ Tensor x_plus_out) {
|
||||
Tensor xx = at::layer_norm(x, {x.size(-1)}, ln_w, ln_b);
|
||||
sx = at::cat({sx.unsqueeze(0), xx.slice(0, 0, -1)}, 0);
|
||||
char* buf_ptr = (char*)buf.data_ptr();
|
||||
half* kx = (half*)buf_ptr;
|
||||
half* vx = kx + x.numel();
|
||||
half* rx = vx + x.numel();
|
||||
half* wkv_y = rx + x.numel();
|
||||
att_mix(data_ptr<half>(xx), data_ptr<half>(sx), data_ptr<half>(k_mix),
|
||||
data_ptr<half>(v_mix), data_ptr<half>(r_mix), xx.size(0), xx.size(1),
|
||||
kx, vx, rx);
|
||||
float* k = reinterpret_cast<float*>(wkv_y + x.numel());
|
||||
float* v = k + x.size(0) * kw.size(1);
|
||||
half* r = reinterpret_cast<half*>(v + x.size(0) * vw.size(1));
|
||||
|
||||
gemm_fp16_cublas(kx, kw.data_ptr(), k, x.size(0), kw.size(1), kw.size(0), true);
|
||||
gemm_fp16_cublas(vx, vw.data_ptr(), v, x.size(0), vw.size(1), vw.size(0), true);
|
||||
gemm_fp16_cublas(rx, rw.data_ptr(), r, x.size(0), rw.size(1), rw.size(0), false);
|
||||
element_wise(InplaceSigmoid{r}, x.size(0) * rw.size(1));
|
||||
cuda_wkv_forward_new(1, x.size(0), x.size(1), data_ptr<float>(t_decay),
|
||||
data_ptr<float>(t_first), k, v, r,
|
||||
wkv_y, data_ptr<float>(aa),
|
||||
data_ptr<float>(bb), data_ptr<float>(pp));
|
||||
element_wise(InplaceMul{wkv_y, r}, x.numel());
|
||||
gemm_fp16_cublas(wkv_y, ow.data_ptr(), x_plus_out.data_ptr(), x.size(0), ow.size(1), ow.size(0), false);
|
||||
x_plus_out += x;
|
||||
return xx;
|
||||
}
|
||||
21
backend-python/rwkv_pip/beta/cuda/element_wise.h
vendored
21
backend-python/rwkv_pip/beta/cuda/element_wise.h
vendored
@ -1,21 +0,0 @@
|
||||
#include <cassert>
|
||||
#include <cstddef>
|
||||
#include <cstdint>
|
||||
|
||||
template <typename Func> __global__ void _element_wise(Func func, int n) {
|
||||
for (int i = blockIdx.x * blockDim.x + threadIdx.x; i < n;
|
||||
i += blockDim.x * gridDim.x) {
|
||||
func(i);
|
||||
}
|
||||
}
|
||||
|
||||
// NOTE: packed data type (e.g. float4) is a overkill for current sizes
|
||||
// (4096 in 7B model and 768 in 0.1B model),
|
||||
// and is not faster than the plain float version.
|
||||
template <typename Func>
|
||||
void element_wise(Func func, int n) {
|
||||
// 256 is good enough on most GPUs
|
||||
const int32_t BLOCK_SIZE = 256;
|
||||
assert(n % BLOCK_SIZE == 0);
|
||||
_element_wise<<<n / BLOCK_SIZE, BLOCK_SIZE>>>(func, n);
|
||||
}
|
||||
165
backend-python/rwkv_pip/beta/cuda/ffn.cu
vendored
165
backend-python/rwkv_pip/beta/cuda/ffn.cu
vendored
@ -1,165 +0,0 @@
|
||||
#include "ATen/ATen.h"
|
||||
#include <cuda_fp16.h>
|
||||
#include <cuda_runtime.h>
|
||||
#include <torch/extension.h>
|
||||
|
||||
#include "element_wise.h"
|
||||
#include "util.h"
|
||||
|
||||
using torch::Tensor;
|
||||
|
||||
void gemm_fp16_cublas(const void *a, const void *b, void *c, int ori_m,
|
||||
int ori_n, int ori_k, bool output_fp32);
|
||||
|
||||
__global__ void _ffn_seq_mix(const half *xx, const half *sx, const half *k_mix,
|
||||
const half *r_mix, const int outer_size,
|
||||
const int inner_size, half *kx, half *rx) {
|
||||
for (int idx2 = blockIdx.x * blockDim.x + threadIdx.x; idx2 < inner_size;
|
||||
idx2 += blockDim.x * gridDim.x) {
|
||||
half k_mix_ = k_mix[idx2];
|
||||
half r_mix_ = r_mix[idx2];
|
||||
for (int row = 0; row < outer_size; ++row) {
|
||||
int idx1 = row * inner_size + idx2;
|
||||
half xx_ = xx[idx1];
|
||||
half sx_ = sx[idx1];
|
||||
kx[idx1] = __hadd(__hmul(xx_, k_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), k_mix_)));
|
||||
rx[idx1] = __hadd(__hmul(xx_, r_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), r_mix_)));
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void ffn_seq_mix(const half *xx, const half *sx, const half *k_mix,
|
||||
const half *r_mix, const int outer_size, const int inner_size,
|
||||
half *kx, half *rx) {
|
||||
// 256 is good enough on most GPUs
|
||||
const int32_t BLOCK_SIZE = 256;
|
||||
assert(inner_size % BLOCK_SIZE == 0);
|
||||
_ffn_seq_mix<<<inner_size / BLOCK_SIZE, BLOCK_SIZE>>>(
|
||||
xx, sx, k_mix, r_mix, outer_size, inner_size, kx, rx);
|
||||
}
|
||||
|
||||
struct InplaceSigmoid {
|
||||
__device__ __forceinline__ void operator()(int i) const {
|
||||
ptr[i] = __float2half(1.0 / (1.0 + exp(-__half2float(ptr[i]))));
|
||||
}
|
||||
half *ptr;
|
||||
};
|
||||
|
||||
struct InplaceReLUAndSquare {
|
||||
__device__ __forceinline__ void operator()(int i) const {
|
||||
// __hmax is not defined in old cuda
|
||||
if (__hgt(ptr[i], __float2half(0))) {
|
||||
ptr[i] = __hmul(ptr[i], ptr[i]);
|
||||
} else {
|
||||
ptr[i] = __float2half(0);
|
||||
}
|
||||
}
|
||||
half *ptr;
|
||||
};
|
||||
|
||||
struct InplaceFma {
|
||||
__device__ __forceinline__ void operator()(int i) const {
|
||||
a[i] = __hfma(a[i], b[i], c[i]);
|
||||
}
|
||||
half *a;
|
||||
const half *b;
|
||||
const half *c;
|
||||
};
|
||||
|
||||
/*
|
||||
Equivalent Python code:
|
||||
|
||||
xx = F.layer_norm(x, (x.shape[-1],), weight=ln_w, bias=ln_b)
|
||||
sx = torch.cat((sx.unsqueeze(0), xx[:-1,:]))
|
||||
kx = xx * k_mix + sx * (1 - k_mix)
|
||||
rx = xx * r_mix + sx * (1 - r_mix)
|
||||
|
||||
r = torch.sigmoid(gemm(rx, rw))
|
||||
vx = torch.square(torch.relu(gemm(kx, kw)))
|
||||
out = r * gemm(vx, vw)
|
||||
return x + out, xx[-1,:]
|
||||
*/
|
||||
Tensor ffn_seq(Tensor x, Tensor sx, Tensor ln_w, Tensor ln_b, Tensor k_mix,
|
||||
Tensor r_mix, Tensor kw, Tensor vw, Tensor rw,
|
||||
/* imm */ Tensor buf,
|
||||
/* out */ Tensor x_plus_out) {
|
||||
Tensor xx = at::layer_norm(x, {x.size(-1)}, ln_w, ln_b);
|
||||
sx = at::cat({sx.unsqueeze(0), xx.slice(0, 0, -1)}, 0);
|
||||
char *buf_ptr = (char *)buf.data_ptr();
|
||||
half *kx = (half *)buf_ptr;
|
||||
half *rx = kx + x.numel();
|
||||
half *vx = rx + x.numel();
|
||||
half *r = vx + x.size(0) * kw.size(1);
|
||||
ffn_seq_mix(data_ptr<half>(xx), data_ptr<half>(sx), data_ptr<half>(k_mix),
|
||||
data_ptr<half>(r_mix), xx.size(0), xx.size(1), kx, rx);
|
||||
|
||||
gemm_fp16_cublas(rx, rw.data_ptr(), r, x.size(0), rw.size(1), x.size(1),
|
||||
false);
|
||||
element_wise(InplaceSigmoid{r}, x.size(0) * rw.size(1));
|
||||
gemm_fp16_cublas(kx, kw.data_ptr(), vx, x.size(0), kw.size(1), x.size(1),
|
||||
false);
|
||||
element_wise(InplaceReLUAndSquare{vx}, x.size(0) * kw.size(1));
|
||||
gemm_fp16_cublas(vx, vw.data_ptr(), x_plus_out.data_ptr(), x.size(0),
|
||||
vw.size(1), vw.size(0), false);
|
||||
element_wise(InplaceFma{data_ptr<half>(x_plus_out), r, data_ptr<half>(x)},
|
||||
x_plus_out.numel());
|
||||
return xx;
|
||||
}
|
||||
|
||||
struct FfnOneMix {
|
||||
__device__ __forceinline__ void operator()(int idx) {
|
||||
half k_mix_ = k_mix[idx];
|
||||
half r_mix_ = r_mix[idx];
|
||||
half xx_ = xx[idx];
|
||||
half sx_ = sx[idx];
|
||||
kx[idx] = __hadd(__hmul(xx_, k_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), k_mix_)));
|
||||
rx[idx] = __hadd(__hmul(xx_, r_mix_),
|
||||
__hmul(sx_, __hsub(__float2half(1), r_mix_)));
|
||||
}
|
||||
half *k_mix;
|
||||
half *r_mix;
|
||||
half *xx;
|
||||
half *sx;
|
||||
half *kx;
|
||||
half *rx;
|
||||
};
|
||||
|
||||
/*
|
||||
Equivalent Python code:
|
||||
|
||||
xx = F.layer_norm(x, (x.shape[-1],), weight=ln_w, bias=ln_b)
|
||||
kx = xx * k_mix + sx * (1 - k_mix)
|
||||
rx = xx * r_mix + sx * (1 - r_mix)
|
||||
|
||||
r = torch.sigmoid(gemm(rx, rw))
|
||||
vx = torch.square(torch.relu(gemm(kx, kw)))
|
||||
out = r * gemm(vx, vw)
|
||||
return x + out, xx
|
||||
*/
|
||||
Tensor ffn_one(Tensor x, Tensor sx, Tensor ln_w, Tensor ln_b, Tensor k_mix,
|
||||
Tensor r_mix, Tensor kw, Tensor vw, Tensor rw,
|
||||
/* imm */ Tensor buf,
|
||||
/* out */ Tensor x_plus_out) {
|
||||
Tensor xx = at::layer_norm(x, {x.size(-1)}, ln_w, ln_b);
|
||||
char *buf_ptr = (char *)buf.data_ptr();
|
||||
half *kx = (half *)buf_ptr;
|
||||
half *rx = kx + x.numel();
|
||||
half *vx = rx + x.numel();
|
||||
half *r = vx + x.size(0) * kw.size(1);
|
||||
element_wise(FfnOneMix{data_ptr<half>(k_mix), data_ptr<half>(r_mix),
|
||||
data_ptr<half>(xx), data_ptr<half>(sx), kx, rx},
|
||||
x.numel());
|
||||
// vector * matrix, so m = 1
|
||||
gemm_fp16_cublas(rx, rw.data_ptr(), r, 1, rw.size(1), rw.size(0), false);
|
||||
element_wise(InplaceSigmoid{r}, rw.size(1));
|
||||
gemm_fp16_cublas(kx, kw.data_ptr(), vx, 1, kw.size(1), kw.size(0), false);
|
||||
element_wise(InplaceReLUAndSquare{vx}, kw.size(1));
|
||||
gemm_fp16_cublas(vx, vw.data_ptr(), x_plus_out.data_ptr(), 1, vw.size(1),
|
||||
vw.size(0), false);
|
||||
element_wise(InplaceFma{data_ptr<half>(x_plus_out), r, data_ptr<half>(x)},
|
||||
x_plus_out.numel());
|
||||
return xx;
|
||||
}
|
||||
@ -1,128 +0,0 @@
|
||||
#include <cublas_v2.h>
|
||||
#include <cuda.h>
|
||||
#include <cuda_fp16.h>
|
||||
#include <cuda_runtime.h>
|
||||
#include <torch/extension.h>
|
||||
|
||||
#define CUBLAS_CHECK(condition) \
|
||||
for (cublasStatus_t _cublas_check_status = (condition); \
|
||||
_cublas_check_status != CUBLAS_STATUS_SUCCESS;) \
|
||||
throw std::runtime_error("cuBLAS error " + \
|
||||
std::to_string(_cublas_check_status) + " at " + \
|
||||
std::to_string(__LINE__));
|
||||
|
||||
#define CUDA_CHECK(condition) \
|
||||
for (cudaError_t _cuda_check_status = (condition); \
|
||||
_cuda_check_status != cudaSuccess;) \
|
||||
throw std::runtime_error( \
|
||||
"CUDA error " + std::string(cudaGetErrorString(_cuda_check_status)) + \
|
||||
" at " + std::to_string(__LINE__));
|
||||
|
||||
cublasHandle_t get_cublas_handle() {
|
||||
static cublasHandle_t cublas_handle = []() {
|
||||
cublasHandle_t handle = nullptr;
|
||||
CUBLAS_CHECK(cublasCreate(&handle));
|
||||
#if CUDA_VERSION < 11000
|
||||
CUBLAS_CHECK(cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH));
|
||||
#else
|
||||
CUBLAS_CHECK(cublasSetMathMode(handle, CUBLAS_DEFAULT_MATH));
|
||||
#endif // CUDA_VERSION < 11000
|
||||
return handle;
|
||||
}();
|
||||
return cublas_handle;
|
||||
}
|
||||
|
||||
/*
|
||||
NOTE: blas gemm is column-major by default, but we need row-major output.
|
||||
The data of row-major, transposed matrix is exactly the same as the
|
||||
column-major, non-transposed matrix, and C = A * B ---> C^T = B^T * A^T
|
||||
*/
|
||||
void gemm_fp16_cublas(const void *a, const void *b, void *c, int ori_m,
|
||||
int ori_n, int ori_k, bool output_fp32) {
|
||||
const auto cuda_data_type = CUDA_R_16F;
|
||||
const auto cuda_c_data_type = output_fp32 ? CUDA_R_32F : CUDA_R_16F;
|
||||
const auto compute_type = CUDA_R_32F;
|
||||
const float sp_alpha = 1.f;
|
||||
// use CUBLAS_OP_N. see the notes above
|
||||
const cublasOperation_t cublas_trans_a = CUBLAS_OP_N;
|
||||
const cublasOperation_t cublas_trans_b = CUBLAS_OP_N;
|
||||
// m = (B^T).size(0) = B.size(1) = n;
|
||||
const int cublas_m = ori_n;
|
||||
const int cublas_k = ori_k;
|
||||
// comptiable with rwkv one mode, where 1-D tensor * 2-D tensor
|
||||
// const int n = a.dense_dim() == 1 ? 1 : a.size(0);
|
||||
const int cublas_n = ori_m;
|
||||
const int cublas_lda = cublas_m;
|
||||
const int cublas_ldb = cublas_k;
|
||||
const int cublas_ldc = cublas_m;
|
||||
cublasHandle_t cublas_handle = get_cublas_handle();
|
||||
|
||||
#if CUDA_VERSION >= 11000
|
||||
cublasGemmAlgo_t algo = CUBLAS_GEMM_DEFAULT;
|
||||
#else
|
||||
cublasGemmAlgo_t algo = CUBLAS_GEMM_DFALT_TENSOR_OP;
|
||||
#endif
|
||||
const float sp_beta = 0.f;
|
||||
CUBLAS_CHECK(cublasGemmEx(
|
||||
cublas_handle, cublas_trans_a, cublas_trans_b, cublas_m, cublas_n,
|
||||
cublas_k, &sp_alpha, b, cuda_data_type, cublas_lda,
|
||||
a, cuda_data_type, cublas_ldb, &sp_beta, c,
|
||||
cuda_c_data_type, cublas_ldc, compute_type, algo));
|
||||
}
|
||||
|
||||
/*
|
||||
NOTE: blas gemm is column-major by default, but we need row-major output.
|
||||
The data of row-major, transposed matrix is exactly the same as the
|
||||
column-major, non-transposed matrix, and C = A * B ---> C^T = B^T * A^T
|
||||
*/
|
||||
void gemm_fp16_cublas_tensor(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
|
||||
if (a.sizes().size() == 1) {
|
||||
assert(b.sizes().size() == 2);
|
||||
a = at::unsqueeze(a, 0);
|
||||
}
|
||||
const auto cuda_data_type = CUDA_R_16F;
|
||||
const auto cuda_c_data_type =
|
||||
c.dtype() == torch::kFloat32 ? CUDA_R_32F : CUDA_R_16F;
|
||||
const auto compute_type = CUDA_R_32F;
|
||||
const float sp_alpha = 1.f;
|
||||
// swap a and b, and use CUBLAS_OP_N. see the notes above
|
||||
std::swap(a, b);
|
||||
const cublasOperation_t cublas_trans_a = CUBLAS_OP_N;
|
||||
const cublasOperation_t cublas_trans_b = CUBLAS_OP_N;
|
||||
// m = (B^T).size(0) = B.size(1), and = A.size(1) after swap,
|
||||
// negative axis is used because of the existence of batch matmul.
|
||||
const int m = a.size(-1);
|
||||
const int k = a.size(-2);
|
||||
const int n = b.size(-2);
|
||||
const int cublas_lda = m;
|
||||
const int cublas_ldb = k;
|
||||
const int cublas_ldc = m;
|
||||
cublasHandle_t cublas_handle = get_cublas_handle();
|
||||
|
||||
#if CUDA_VERSION >= 11000
|
||||
cublasGemmAlgo_t algo = CUBLAS_GEMM_DEFAULT;
|
||||
#else
|
||||
cublasGemmAlgo_t algo = CUBLAS_GEMM_DFALT_TENSOR_OP;
|
||||
#endif
|
||||
const float sp_beta = 0.f;
|
||||
if (a.sizes().size() == 2 && b.sizes().size() == 2) {
|
||||
CUBLAS_CHECK(cublasGemmEx(
|
||||
cublas_handle, cublas_trans_a, cublas_trans_b, m, n, k, &sp_alpha,
|
||||
a.data_ptr(), cuda_data_type, cublas_lda, b.data_ptr(), cuda_data_type,
|
||||
cublas_ldb, &sp_beta, c.data_ptr(), cuda_c_data_type, cublas_ldc,
|
||||
compute_type, algo));
|
||||
} else {
|
||||
// batch matmul
|
||||
assert(a.sizes().size() == 3 && b.sizes().size() == 3);
|
||||
|
||||
const long long int cublas_stride_a = m * k;
|
||||
const long long int cublas_stride_b = k * n;
|
||||
const long long int cublas_stride_c = m * n;
|
||||
CUBLAS_CHECK(cublasGemmStridedBatchedEx(
|
||||
cublas_handle, cublas_trans_a, cublas_trans_b, m,
|
||||
n, k, &sp_alpha, a.data_ptr(), cuda_data_type, cublas_lda,
|
||||
cublas_stride_a, b.data_ptr(), cuda_data_type, cublas_ldb, cublas_stride_b,
|
||||
&sp_beta, c.data_ptr(), cuda_c_data_type, cublas_ldc, cublas_stride_c,
|
||||
a.size(0), compute_type, algo));
|
||||
}
|
||||
}
|
||||
246
backend-python/rwkv_pip/beta/cuda/operators.cu
vendored
246
backend-python/rwkv_pip/beta/cuda/operators.cu
vendored
@ -1,246 +0,0 @@
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include "ATen/ATen.h"
|
||||
#include <cuda_fp16.h>
|
||||
#define MIN_VALUE (-1e38)
|
||||
typedef at::Half fp16;
|
||||
__half *cast(fp16 *ptr) {
|
||||
return reinterpret_cast<__half *>(ptr);
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
__global__ void kernel_wkv_forward(const int B, const int T, const int C,
|
||||
const float *__restrict__ const _w, const float *__restrict__ const _u, const F *__restrict__ const _k, const F *__restrict__ const _v,
|
||||
F *__restrict__ const _y, float *__restrict__ const _aa, float *__restrict__ const _bb, float *__restrict__ const _pp) {
|
||||
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
|
||||
const int _b = idx / C;
|
||||
const int _c = idx % C;
|
||||
const int _offset = _b * T * C + _c;
|
||||
const int _state_offset = _b * C + _c;
|
||||
|
||||
float u = _u[_c];
|
||||
float w = _w[_c];
|
||||
const F *__restrict__ const k = _k + _offset;
|
||||
const F *__restrict__ const v = _v + _offset;
|
||||
F *__restrict__ const y = _y + _offset;
|
||||
|
||||
float aa = _aa[_state_offset];
|
||||
float bb = _bb[_state_offset];
|
||||
float pp = _pp[_state_offset];
|
||||
for (int i = 0; i < T; i++) {
|
||||
const int ii = i * C;
|
||||
const float kk = float(k[ii]);
|
||||
const float vv = float(v[ii]);
|
||||
float ww = u + kk;
|
||||
float p = max(pp, ww);
|
||||
float e1 = exp(pp - p);
|
||||
float e2 = exp(ww - p);
|
||||
y[ii] = F((e1 * aa + e2 * vv) / (e1 * bb + e2));
|
||||
ww = w + pp;
|
||||
p = max(ww, kk);
|
||||
e1 = exp(ww - p);
|
||||
e2 = exp(kk - p);
|
||||
aa = e1 * aa + e2 * vv;
|
||||
bb = e1 * bb + e2;
|
||||
pp = p;
|
||||
}
|
||||
_aa[_state_offset] = aa;
|
||||
_bb[_state_offset] = bb;
|
||||
_pp[_state_offset] = pp;
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
void cuda_wkv_forward(int B, int T, int C, float *w, float *u, F *k, F *v, F *y, float *aa, float *bb, float *pp) {
|
||||
dim3 threadsPerBlock( min(C, 32) );
|
||||
assert(B * C % threadsPerBlock.x == 0);
|
||||
dim3 numBlocks(B * C / threadsPerBlock.x);
|
||||
kernel_wkv_forward<<<numBlocks, threadsPerBlock>>>(B, T, C, w, u, k, v, y, aa, bb, pp);
|
||||
}
|
||||
|
||||
template void cuda_wkv_forward<fp16>(
|
||||
int B, int T, int C,
|
||||
float *w, float *u, fp16 *k, fp16 *v, fp16 *y,
|
||||
float *aa, float *bb, float *pp);
|
||||
template void cuda_wkv_forward<float>(
|
||||
int B, int T, int C,
|
||||
float *w, float *u, float *k, float *v, float *y,
|
||||
float *aa, float *bb, float *pp);
|
||||
|
||||
__global__ void kernel_mm_seq_fp32i8(
|
||||
const int B, const int N, const int M,
|
||||
const float *__restrict__ const x, const int x_stride,
|
||||
const uint8_t *__restrict__ const w, const int w_stride,
|
||||
const float *__restrict__ const mx,
|
||||
const float *__restrict__ const rx,
|
||||
const float *__restrict__ const my,
|
||||
const float *__restrict__ const ry,
|
||||
float *__restrict__ const y, const int y_stride) {
|
||||
|
||||
const int i = blockIdx.x * blockDim.x + threadIdx.x;
|
||||
const int k = blockIdx.y * blockDim.y + threadIdx.y;
|
||||
|
||||
if (i < B && k < M) {
|
||||
float y_local = 0;
|
||||
for (int j = 0; j < N; ++j) {
|
||||
y_local += x[i * x_stride + j] * (
|
||||
(float(w[j * w_stride + k]) + 0.5f)
|
||||
* rx[k] * ry[j] + mx[k] + my[j]
|
||||
);
|
||||
}
|
||||
y[i * y_stride + k] = y_local;
|
||||
}
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
void cuda_mm8_seq(int B, int N, int M,
|
||||
F *x, int x_stride,
|
||||
uint8_t *w, int w_stride,
|
||||
F *mx, F *rx,
|
||||
F *my, F *ry,
|
||||
F *y, int y_stride);
|
||||
|
||||
template <>
|
||||
void cuda_mm8_seq<float>(int B, int N, int M,
|
||||
float *x, int x_stride,
|
||||
uint8_t *w, int w_stride,
|
||||
float *mx, float *rx,
|
||||
float *my, float *ry,
|
||||
float *y, int y_stride) {
|
||||
dim3 blockSize(1, 128);
|
||||
dim3 gridSize((B + blockSize.x - 1) / blockSize.x, (M + blockSize.y - 1) / blockSize.y);
|
||||
kernel_mm_seq_fp32i8<<<gridSize, blockSize>>>(
|
||||
B, N, M, x, x_stride, w, w_stride,
|
||||
mx, rx, my, ry, y, y_stride);
|
||||
}
|
||||
|
||||
__global__ void kernel_mm_seq_fp16i8(
|
||||
const int B, const int N, const int M,
|
||||
const __half *__restrict__ const x, const int x_stride,
|
||||
const uint8_t *__restrict__ const w, const int w_stride,
|
||||
const __half *__restrict__ const mx,
|
||||
const __half *__restrict__ const rx,
|
||||
const __half *__restrict__ const my,
|
||||
const __half *__restrict__ const ry,
|
||||
__half *__restrict__ const y, const int y_stride) {
|
||||
|
||||
const int i = blockIdx.x * blockDim.x + threadIdx.x;
|
||||
const int k = blockIdx.y * blockDim.y + threadIdx.y;
|
||||
|
||||
if (i < B && k < M) {
|
||||
float y_local = 0;
|
||||
for (int j = 0; j < N; ++j) {
|
||||
y_local += __half2float(x[i * x_stride + j]) * (
|
||||
(float(w[j * w_stride + k]) + 0.5f)
|
||||
* __half2float(rx[k]) * __half2float(ry[j])
|
||||
+ __half2float(mx[k]) + __half2float(my[j])
|
||||
);
|
||||
}
|
||||
y[i * y_stride + k] = __float2half(y_local);
|
||||
}
|
||||
}
|
||||
|
||||
template <>
|
||||
void cuda_mm8_seq<fp16>(int B, int N, int M,
|
||||
fp16 *x, int x_stride,
|
||||
uint8_t *w, int w_stride,
|
||||
fp16 *mx, fp16 *rx,
|
||||
fp16 *my, fp16 *ry,
|
||||
fp16 *y, int y_stride) {
|
||||
dim3 blockSize(1, 128);
|
||||
dim3 gridSize((B + blockSize.x - 1) / blockSize.x, (M + blockSize.y - 1) / blockSize.y);
|
||||
kernel_mm_seq_fp16i8<<<gridSize, blockSize>>>(
|
||||
B, N, M, cast(x), x_stride, w, w_stride,
|
||||
cast(mx), cast(rx), cast(my), cast(ry), cast(y), y_stride);
|
||||
}
|
||||
|
||||
#define MM8_ONE_JSPLIT 24
|
||||
#define MM8_ONE_TILE 1024
|
||||
|
||||
__global__ void kernel_mm_one_fp32i8(
|
||||
const int N, const int M,
|
||||
const float *__restrict__ const x,
|
||||
const uint8_t *__restrict__ const w, const int w_stride,
|
||||
const float *__restrict__ const mx,
|
||||
const float *__restrict__ const rx,
|
||||
const float *__restrict__ const my,
|
||||
const float *__restrict__ const ry,
|
||||
float *__restrict__ const y) {
|
||||
|
||||
const int k = blockIdx.y * blockDim.y + threadIdx.y;
|
||||
const int j0 = min(N, blockIdx.x * ((N + MM8_ONE_JSPLIT - 1) / MM8_ONE_JSPLIT));
|
||||
const int j1 = min(N, (blockIdx.x + 1) * ((N + MM8_ONE_JSPLIT - 1) / MM8_ONE_JSPLIT));
|
||||
|
||||
if (k < M) {
|
||||
float y_local = 0;
|
||||
for (int j = j0; j < j1; ++j) {
|
||||
y_local += x[j] * (
|
||||
(float(w[j * w_stride + k]) + 0.5f)
|
||||
* rx[k] * ry[j] + mx[k] + my[j]
|
||||
);
|
||||
}
|
||||
atomicAdd(&y[k], y_local);
|
||||
}
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
void cuda_mm8_one(int N, int M,
|
||||
F *x,
|
||||
uint8_t *w, int w_stride,
|
||||
F *mx, F *rx,
|
||||
F *my, F *ry,
|
||||
float *y);
|
||||
|
||||
template <>
|
||||
void cuda_mm8_one<float>(int N, int M,
|
||||
float *x,
|
||||
uint8_t *w, int w_stride,
|
||||
float *mx, float *rx,
|
||||
float *my, float *ry,
|
||||
float *y) {
|
||||
dim3 blockSize(1, MM8_ONE_TILE);
|
||||
dim3 gridSize(MM8_ONE_JSPLIT, (M + blockSize.y - 1) / blockSize.y);
|
||||
kernel_mm_one_fp32i8<<<gridSize, blockSize>>>(
|
||||
N, M, x, w, w_stride,
|
||||
mx, rx, my, ry, y);
|
||||
}
|
||||
|
||||
__global__ void kernel_mm_one_fp16i8(
|
||||
const int N, const int M,
|
||||
const __half *__restrict__ const x,
|
||||
const uint8_t *__restrict__ const w, const int w_stride,
|
||||
const __half *__restrict__ const mx,
|
||||
const __half *__restrict__ const rx,
|
||||
const __half *__restrict__ const my,
|
||||
const __half *__restrict__ const ry,
|
||||
float *__restrict__ const y) {
|
||||
|
||||
const int k = blockIdx.y * blockDim.y + threadIdx.y;
|
||||
const int j0 = min(N, blockIdx.x * ((N + MM8_ONE_JSPLIT - 1) / MM8_ONE_JSPLIT));
|
||||
const int j1 = min(N, (blockIdx.x + 1) * ((N + MM8_ONE_JSPLIT - 1) / MM8_ONE_JSPLIT));
|
||||
|
||||
if (k < M) {
|
||||
float y_local = 0;
|
||||
for (int j = j0; j < j1; ++j) {
|
||||
y_local += __half2float(x[j]) * (
|
||||
(float(w[j * w_stride + k]) + 0.5f)
|
||||
* __half2float(rx[k]) * __half2float(ry[j])
|
||||
+ __half2float(mx[k]) + __half2float(my[j])
|
||||
);
|
||||
}
|
||||
atomicAdd(&y[k], y_local);
|
||||
}
|
||||
}
|
||||
|
||||
template <>
|
||||
void cuda_mm8_one<fp16>(int N, int M,
|
||||
fp16 *x,
|
||||
uint8_t *w, int w_stride,
|
||||
fp16 *mx, fp16 *rx,
|
||||
fp16 *my, fp16 *ry,
|
||||
float *y) {
|
||||
dim3 blockSize(1, MM8_ONE_TILE);
|
||||
dim3 gridSize(MM8_ONE_JSPLIT, (M + blockSize.y - 1) / blockSize.y);
|
||||
kernel_mm_one_fp16i8<<<gridSize, blockSize>>>(
|
||||
N, M, cast(x), w, w_stride,
|
||||
cast(mx), cast(rx), cast(my), cast(ry), y);
|
||||
}
|
||||
7
backend-python/rwkv_pip/beta/cuda/util.h
vendored
7
backend-python/rwkv_pip/beta/cuda/util.h
vendored
@ -1,7 +0,0 @@
|
||||
#include "ATen/ATen.h"
|
||||
#include <cuda_fp16.h>
|
||||
|
||||
template <typename T> T *data_ptr(torch::Tensor x) { return x.data_ptr<T>(); }
|
||||
template <> inline half *data_ptr(torch::Tensor x) {
|
||||
return reinterpret_cast<half *>(x.data_ptr<at::Half>());
|
||||
}
|
||||
181
backend-python/rwkv_pip/beta/cuda/wrapper.cpp
vendored
181
backend-python/rwkv_pip/beta/cuda/wrapper.cpp
vendored
@ -1,181 +0,0 @@
|
||||
#include <torch/extension.h>
|
||||
#include "ATen/ATen.h"
|
||||
#include <iostream>
|
||||
#include <c10/cuda/CUDAGuard.h>
|
||||
|
||||
typedef at::Half fp16;
|
||||
|
||||
template <typename F>
|
||||
void cuda_wkv_forward(int B, int T, int C,
|
||||
float *w, float *u, F *k, F *v, F *y,
|
||||
float *aa, float *bb, float *pp);
|
||||
template <typename F>
|
||||
void cuda_mm8_seq(int B, int N, int M,
|
||||
F *x, int x_stride,
|
||||
uint8_t *w, int w_stride,
|
||||
F *mx, F *rx,
|
||||
F *my, F *ry,
|
||||
F *y, int y_stride);
|
||||
template <typename F>
|
||||
void cuda_mm8_one(int N, int M,
|
||||
F *x,
|
||||
uint8_t *w, int w_stride,
|
||||
F *mx, F *rx,
|
||||
F *my, F *ry,
|
||||
float *y);
|
||||
|
||||
void wkv_forward(int64_t B, int64_t T, int64_t C,
|
||||
torch::Tensor &w, torch::Tensor &u,
|
||||
torch::Tensor &k, torch::Tensor &v, torch::Tensor &y,
|
||||
torch::Tensor &aa, torch::Tensor &bb, torch::Tensor &pp) {
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(w));
|
||||
switch (k.scalar_type()) {
|
||||
case c10::ScalarType::Half:
|
||||
cuda_wkv_forward(B, T, C,
|
||||
w.data_ptr<float>(), u.data_ptr<float>(),
|
||||
k.data_ptr<fp16>(), v.data_ptr<fp16>(), y.data_ptr<fp16>(),
|
||||
aa.data_ptr<float>(), bb.data_ptr<float>(), pp.data_ptr<float>());
|
||||
break;
|
||||
case c10::ScalarType::Float:
|
||||
cuda_wkv_forward(B, T, C,
|
||||
w.data_ptr<float>(), u.data_ptr<float>(),
|
||||
k.data_ptr<float>(), v.data_ptr<float>(), y.data_ptr<float>(),
|
||||
aa.data_ptr<float>(), bb.data_ptr<float>(), pp.data_ptr<float>());
|
||||
break;
|
||||
default:
|
||||
assert(false && "Only FP16 and FP32 are currently supported");
|
||||
}
|
||||
}
|
||||
|
||||
void mm8_seq(int64_t B, int64_t N, int64_t M,
|
||||
torch::Tensor &x, torch::Tensor &w,
|
||||
torch::Tensor &mx, torch::Tensor &rx,
|
||||
torch::Tensor &my, torch::Tensor &ry,
|
||||
torch::Tensor &y) {
|
||||
assert(x.stride(1) == 1);
|
||||
assert(w.stride(1) == 1);
|
||||
assert(mx.stride(0) == 1 && rx.stride(0) == 1);
|
||||
assert(my.stride(0) == 1 && ry.stride(0) == 1);
|
||||
assert(y.stride(1) == 1);
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(w));
|
||||
switch (x.scalar_type()) {
|
||||
case c10::ScalarType::Half:
|
||||
cuda_mm8_seq(
|
||||
B, N, M,
|
||||
x.data_ptr<fp16>(), x.stride(0),
|
||||
w.data_ptr<uint8_t>(), w.stride(0),
|
||||
mx.data_ptr<fp16>(), rx.data_ptr<fp16>(),
|
||||
my.data_ptr<fp16>(), ry.data_ptr<fp16>(),
|
||||
y.data_ptr<fp16>(), y.stride(0));
|
||||
break;
|
||||
case c10::ScalarType::Float:
|
||||
cuda_mm8_seq(
|
||||
B, N, M,
|
||||
x.data_ptr<float>(), x.stride(0),
|
||||
w.data_ptr<uint8_t>(), w.stride(0),
|
||||
mx.data_ptr<float>(), rx.data_ptr<float>(),
|
||||
my.data_ptr<float>(), ry.data_ptr<float>(),
|
||||
y.data_ptr<float>(), y.stride(0));
|
||||
break;
|
||||
default:
|
||||
assert(false && "Only FP16 and FP32 are currently supported");
|
||||
}
|
||||
}
|
||||
void mm8_one(int64_t N, int64_t M,
|
||||
torch::Tensor &x, torch::Tensor &w,
|
||||
torch::Tensor &mx, torch::Tensor &rx,
|
||||
torch::Tensor &my, torch::Tensor &ry,
|
||||
torch::Tensor &y) {
|
||||
assert(x.stride(0) == 1);
|
||||
assert(w.stride(1) == 1);
|
||||
assert(mx.stride(0) == 1 && rx.stride(0) == 1);
|
||||
assert(my.stride(0) == 1 && ry.stride(0) == 1);
|
||||
assert(y.stride(0) == 1);
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(w));
|
||||
switch (x.scalar_type()) {
|
||||
case c10::ScalarType::Half:
|
||||
cuda_mm8_one(
|
||||
N, M,
|
||||
x.data_ptr<fp16>(),
|
||||
w.data_ptr<uint8_t>(), w.stride(0),
|
||||
mx.data_ptr<fp16>(), rx.data_ptr<fp16>(),
|
||||
my.data_ptr<fp16>(), ry.data_ptr<fp16>(),
|
||||
y.data_ptr<float>());
|
||||
break;
|
||||
case c10::ScalarType::Float:
|
||||
cuda_mm8_one(
|
||||
N, M,
|
||||
x.data_ptr<float>(),
|
||||
w.data_ptr<uint8_t>(), w.stride(0),
|
||||
mx.data_ptr<float>(), rx.data_ptr<float>(),
|
||||
my.data_ptr<float>(), ry.data_ptr<float>(),
|
||||
y.data_ptr<float>());
|
||||
break;
|
||||
default:
|
||||
assert(false && "Only FP16 and FP32 are currently supported");
|
||||
}
|
||||
}
|
||||
|
||||
using torch::Tensor;
|
||||
|
||||
#ifndef DISABLE_CUBLAS_GEMM
|
||||
void gemm_fp16_cublas_tensor(Tensor a, Tensor b, Tensor c);
|
||||
#endif
|
||||
|
||||
Tensor att_one(Tensor x, Tensor ln_w, Tensor ln_b, Tensor sx, Tensor k_mix,
|
||||
Tensor v_mix, Tensor r_mix, Tensor kw,
|
||||
/* imm */ Tensor kx, Tensor vw, /* imm */ Tensor vx, Tensor rw,
|
||||
/* imm */ Tensor rx, Tensor ow, Tensor t_first,
|
||||
/* imm */ Tensor k, Tensor pp, Tensor ww, Tensor aa, Tensor bb,
|
||||
Tensor t_decay, /* imm */ Tensor v, /* in & out */ Tensor r,
|
||||
/* out */ Tensor x_plus_out, /* out */ Tensor t1,
|
||||
/* out */ Tensor t2, /* out */ Tensor p);
|
||||
|
||||
Tensor att_seq(Tensor x, Tensor sx, Tensor ln_w, Tensor ln_b, Tensor k_mix,
|
||||
Tensor v_mix, Tensor r_mix, Tensor kw, Tensor vw, Tensor rw,
|
||||
Tensor ow, Tensor t_first, Tensor pp, Tensor aa, Tensor bb,
|
||||
Tensor t_decay, /* imm */ Tensor buf, /* out */ Tensor x_plus_out);
|
||||
|
||||
Tensor att_one_v5(Tensor x, Tensor sx, Tensor s, Tensor ln_w, Tensor ln_b,
|
||||
Tensor lx_w, Tensor lx_b, Tensor k_mix, Tensor v_mix,
|
||||
Tensor r_mix, Tensor kw,
|
||||
/* imm */ Tensor kx, Tensor vw, /* imm */ Tensor vx,
|
||||
Tensor rw,
|
||||
/* imm */ Tensor rx, Tensor ow, Tensor t_first,
|
||||
/* imm */ Tensor k, Tensor t_decay, /* imm */ Tensor v,
|
||||
/* imm */ Tensor r, /* imm */ Tensor s1,
|
||||
/* out */ Tensor x_plus_out, /* out */ Tensor s2);
|
||||
|
||||
Tensor ffn_seq(Tensor x, Tensor sx, Tensor ln_w, Tensor ln_b, Tensor k_mix,
|
||||
Tensor r_mix, Tensor kw, Tensor vw, Tensor rw,
|
||||
/* imm */ Tensor buf,
|
||||
/* out */ Tensor x_plus_out);
|
||||
|
||||
Tensor ffn_one(Tensor x, Tensor sx, Tensor ln_w, Tensor ln_b, Tensor k_mix,
|
||||
Tensor r_mix, Tensor kw, Tensor vw, Tensor rw,
|
||||
/* imm */ Tensor buf,
|
||||
/* out */ Tensor x_plus_out);
|
||||
|
||||
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
||||
m.def("wkv_forward", &wkv_forward, "wkv forward");
|
||||
m.def("mm8_seq", &mm8_seq, "mm8 seq");
|
||||
m.def("mm8_one", &mm8_one, "mm8 one");
|
||||
m.def("gemm_fp16_cublas", &gemm_fp16_cublas_tensor, "gemv fp16 cublas");
|
||||
m.def("att_one", &att_one, "att one");
|
||||
m.def("att_one_v5", &att_one_v5, "att one v5");
|
||||
m.def("att_seq", &att_seq, "att seq");
|
||||
m.def("ffn_seq", &ffn_seq, "ffn seq");
|
||||
m.def("ffn_one", &ffn_one, "ffn one");
|
||||
}
|
||||
|
||||
TORCH_LIBRARY(rwkv, m) {
|
||||
m.def("wkv_forward", wkv_forward);
|
||||
m.def("mm8_seq", mm8_seq);
|
||||
m.def("mm8_one", mm8_one);
|
||||
m.def("gemm_fp16_cublas", gemm_fp16_cublas_tensor);
|
||||
m.def("att_one", att_one);
|
||||
m.def("att_one_v5", &att_one_v5);
|
||||
m.def("att_seq", att_seq);
|
||||
m.def("ffn_seq", ffn_seq);
|
||||
m.def("ffn_one", ffn_one);
|
||||
}
|
||||
1821
backend-python/rwkv_pip/beta/model.py
vendored
1821
backend-python/rwkv_pip/beta/model.py
vendored
File diff suppressed because it is too large
Load Diff
BIN
backend-python/rwkv_pip/beta/wkv_cuda.pyd
vendored
BIN
backend-python/rwkv_pip/beta/wkv_cuda.pyd
vendored
Binary file not shown.
33
backend-python/rwkv_pip/webgpu/model.py
vendored
33
backend-python/rwkv_pip/webgpu/model.py
vendored
@ -13,13 +13,6 @@ except ModuleNotFoundError:
|
||||
|
||||
class RWKV:
|
||||
def __init__(self, model_path: str, strategy: str = None):
|
||||
self.info = wrp.peek_info(model_path)
|
||||
self.w = {} # fake weight
|
||||
self.w["emb.weight"] = [0] * self.info.num_vocab
|
||||
self.version = str(self.info.version).lower()
|
||||
self.wrp = getattr(wrp, self.version)
|
||||
self.version = float(self.version.replace("v", ""))
|
||||
|
||||
layer = (
|
||||
int(s.lstrip("layer"))
|
||||
for s in strategy.split()
|
||||
@ -33,21 +26,25 @@ class RWKV:
|
||||
for s in s.split(",")
|
||||
if s.startswith("chunk")
|
||||
)
|
||||
self.token_chunk_size = next(chunk_size, 32)
|
||||
|
||||
args = {
|
||||
"file": model_path,
|
||||
"turbo": True,
|
||||
"path": model_path,
|
||||
"quant": next(layer, 31) if "i8" in strategy else 0,
|
||||
"quant_nf4": next(layer, 26) if "i4" in strategy else 0,
|
||||
"token_chunk_size": next(chunk_size, 32),
|
||||
"lora": None,
|
||||
}
|
||||
self.model = self.wrp.Model(**args)
|
||||
self.model = wrp.Model(**args)
|
||||
self.info = self.model.info()
|
||||
self.w = {} # fake weight
|
||||
self.w["emb.weight"] = [0] * self.info.num_vocab
|
||||
self.version = str(self.info.version).lower()
|
||||
self.version = float(self.version.lower().replace("v", ""))
|
||||
|
||||
def forward(self, tokens: List[int], state: Union[Any, None] = None):
|
||||
if type(state).__name__ == "BackedState": # memory state
|
||||
gpu_state = self.wrp.ModelState(self.model, 1)
|
||||
gpu_state.load(state)
|
||||
else:
|
||||
gpu_state = state
|
||||
return self.wrp.run_one(self.model, tokens, gpu_state)
|
||||
if state is None:
|
||||
self.model.clear_state()
|
||||
elif type(state).__name__ == "State_Cpu":
|
||||
self.model.load_state(state)
|
||||
logits = self.model.run(tokens, self.token_chunk_size)
|
||||
ret_state = "State_Gpu"
|
||||
return logits, ret_state
|
||||
|
||||
Binary file not shown.
@ -42,7 +42,7 @@ class AbstractRWKV(ABC):
|
||||
self.top_k = 0
|
||||
self.penalty_alpha_presence = 0
|
||||
self.penalty_alpha_frequency = 1
|
||||
self.penalty_decay = 0.996
|
||||
self.penalty_decay = 0.99
|
||||
self.global_penalty = False
|
||||
self.state_path = ""
|
||||
self.state_tuned = None
|
||||
@ -617,7 +617,6 @@ def get_model_path(model_path: str) -> str:
|
||||
def RWKV(model: str, strategy: str, tokenizer: Union[str, None]) -> AbstractRWKV:
|
||||
model_path = get_model_path(model)
|
||||
|
||||
rwkv_beta = global_var.get(global_var.Args).rwkv_beta
|
||||
rwkv_cpp = getattr(global_var.get(global_var.Args), "rwkv.cpp")
|
||||
webgpu = global_var.get(global_var.Args).webgpu
|
||||
|
||||
@ -625,12 +624,7 @@ def RWKV(model: str, strategy: str, tokenizer: Union[str, None]) -> AbstractRWKV
|
||||
os.environ["RWKV_RESCALE_LAYER"] = "999"
|
||||
|
||||
# dynamic import to make RWKV_CUDA_ON work
|
||||
if rwkv_beta:
|
||||
print("Using rwkv-beta")
|
||||
from rwkv_pip.beta.model import (
|
||||
RWKV as Model,
|
||||
)
|
||||
elif rwkv_cpp:
|
||||
if rwkv_cpp:
|
||||
print("Using rwkv.cpp, strategy is ignored")
|
||||
from rwkv_pip.cpp.model import (
|
||||
RWKV as Model,
|
||||
|
||||
311
finetune/lora/v6/cuda/wkv6infctx_cuda.cu
vendored
Normal file
311
finetune/lora/v6/cuda/wkv6infctx_cuda.cu
vendored
Normal file
@ -0,0 +1,311 @@
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include "ATen/ATen.h"
|
||||
typedef at::BFloat16 bf16;
|
||||
|
||||
template <typename F>
|
||||
__global__ void kernel_forward(const int B, const int T, const int C, const int H,
|
||||
const F *__restrict__ const _r, const F *__restrict__ const _k, const F *__restrict__ const _v, const F *__restrict__ _w, const F *__restrict__ _u, F *__restrict__ _s,
|
||||
F *__restrict__ const _y)
|
||||
{
|
||||
const int b = blockIdx.x / H;
|
||||
const int h = blockIdx.x % H;
|
||||
const int i = threadIdx.x;
|
||||
_u += h*_N_;
|
||||
_s += h*_N_*_N_ + i*_N_;
|
||||
|
||||
__shared__ float r[_N_], k[_N_], u[_N_], w[_N_];
|
||||
float state[_N_];
|
||||
|
||||
__syncthreads();
|
||||
u[i] = float(_u[i]);
|
||||
__syncthreads();
|
||||
for (int j = 0; j < _N_; j++) {
|
||||
state[j] = float(_s[j]);
|
||||
}
|
||||
|
||||
for (int t = b*T*C + h*_N_ + i; t < (b+1)*T*C + h*_N_ + i; t += C)
|
||||
{
|
||||
__syncthreads();
|
||||
w[i] = __expf(-__expf(float(_w[t])));
|
||||
r[i] = float(_r[t]);
|
||||
k[i] = float(_k[t]);
|
||||
__syncthreads();
|
||||
|
||||
const float v = float(_v[t]);
|
||||
float y = 0;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j+=4)
|
||||
{
|
||||
const float4& r_ = (float4&)(r[j]);
|
||||
const float4& k_ = (float4&)(k[j]);
|
||||
const float4& w_ = (float4&)(w[j]);
|
||||
const float4& u_ = (float4&)(u[j]);
|
||||
float4& s = (float4&)(state[j]);
|
||||
float4 x;
|
||||
|
||||
x.x = k_.x * v;
|
||||
x.y = k_.y * v;
|
||||
x.z = k_.z * v;
|
||||
x.w = k_.w * v;
|
||||
|
||||
y += r_.x * (u_.x * x.x + s.x);
|
||||
y += r_.y * (u_.y * x.y + s.y);
|
||||
y += r_.z * (u_.z * x.z + s.z);
|
||||
y += r_.w * (u_.w * x.w + s.w);
|
||||
|
||||
s.x = s.x * w_.x + x.x;
|
||||
s.y = s.y * w_.y + x.y;
|
||||
s.z = s.z * w_.z + x.z;
|
||||
s.w = s.w * w_.w + x.w;
|
||||
}
|
||||
_y[t] = F(y);
|
||||
}
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
_s[j] = F(state[j]);
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
__global__ void kernel_backward_111(const int B, const int T, const int C, const int H,
|
||||
const F *__restrict__ const _r, const F *__restrict__ const _k, const F *__restrict__ const _v, const F *__restrict__ _w, const F *__restrict__ _u, const F *__restrict__ _s, const F *__restrict__ const _gy,
|
||||
F *__restrict__ const _gr, F *__restrict__ const _gk, F *__restrict__ const _gv, F *__restrict__ const _gu, F *__restrict__ const _gs)
|
||||
{
|
||||
const int b = blockIdx.x / H;
|
||||
const int h = blockIdx.x % H;
|
||||
const int i = threadIdx.x;
|
||||
_u += h*_N_;
|
||||
_s += h*_N_*_N_ + i;
|
||||
|
||||
__shared__ float u_[_N_];
|
||||
__shared__ float r[_N_], k[_N_], v[_N_], w_[_N_], gy[_N_];
|
||||
__syncthreads();
|
||||
u_[i] = float(_u[i]);
|
||||
__syncthreads();
|
||||
|
||||
const float u = u_[i];
|
||||
|
||||
float state[_N_], scccc[_N_] = {0}, sdddd[_N_] = {0}, sssss[_N_] = {0}, swwww[_N_];
|
||||
for (int j = 0; j < _N_; j++) {
|
||||
state[j] = float(_s[j*_N_]);
|
||||
swwww[j] = 1.0;
|
||||
}
|
||||
|
||||
const int t_0 = b*T*C + h*_N_ + i;
|
||||
const int t_T_1 = t_0 + (T-1)*C;
|
||||
const int t_T = t_0 + T*C;
|
||||
|
||||
float gu = 0;
|
||||
for (int t = t_0; t < t_T; t += C)
|
||||
{
|
||||
__syncthreads();
|
||||
v[i] = float(_v[t]);
|
||||
gy[i] = float(_gy[t]);
|
||||
__syncthreads();
|
||||
|
||||
const float k = float(_k[t]);
|
||||
const float w = __expf(-__expf(float(_w[t])));
|
||||
float gr = 0, gu_ = 0;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = state[j];
|
||||
float x = k * v[j];
|
||||
|
||||
gr += (u * x + s) * gy[j];
|
||||
gu_ += x * gy[j];
|
||||
s = s * w + x;
|
||||
}
|
||||
_gr[t] = F(gr);
|
||||
gu += float(_r[t]) * gu_;
|
||||
}
|
||||
_gu[b*C + h*_N_ + i] = F(gu);
|
||||
|
||||
for (int t = t_T_1; t >= t_0; t -= C)
|
||||
{
|
||||
__syncthreads();
|
||||
v[i] = float(_v[t]);
|
||||
gy[i] = float(_gy[t]);
|
||||
__syncthreads();
|
||||
|
||||
const float rr = float(_r[t]);
|
||||
const float w = __expf(-__expf(float(_w[t])));
|
||||
float gk = 0;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = scccc[j];
|
||||
float x = rr * gy[j];
|
||||
|
||||
gk += (u * x + s) * v[j];
|
||||
s = x + s * w;
|
||||
}
|
||||
_gk[t] = F(gk);
|
||||
}
|
||||
|
||||
for (int t = t_T_1; t >= t_0; t -= C)
|
||||
{
|
||||
__syncthreads();
|
||||
r[i] = float(_r[t]);
|
||||
k[i] = float(_k[t]);
|
||||
w_[i] = __expf(-__expf(float(_w[t])));
|
||||
__syncthreads();
|
||||
|
||||
const float gyy = float(_gy[t]);
|
||||
float gv = 0;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = sdddd[j];
|
||||
float x = gyy * r[j];
|
||||
|
||||
gv += (u_[j] * x + s) * k[j];
|
||||
s = x + s * w_[j];
|
||||
}
|
||||
_gv[t] = F(gv);
|
||||
}
|
||||
|
||||
for (int t = t_0; t < t_T; t += C)
|
||||
{
|
||||
__syncthreads();
|
||||
r[i] = float(_r[t]);
|
||||
w_[i] = __expf(-__expf(float(_w[t])));
|
||||
__syncthreads();
|
||||
|
||||
const float gyy = float(_gy[t]);
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& w = swwww[j];
|
||||
sssss[j] += gyy * w * r[j];
|
||||
w *= w_[j];
|
||||
}
|
||||
}
|
||||
for (int j = 0; j < _N_; j++)
|
||||
_gs[b*H*_N_*_N_ + h*_N_*_N_ + i*_N_ + j] = F(sssss[j]);
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
__global__ void kernel_backward_222(const int B, const int T, const int C, const int H,
|
||||
const F *__restrict__ const _r, const F *__restrict__ const _k, const F *__restrict__ const _v, const F *__restrict__ _w, const F *__restrict__ _u, const F *__restrict__ _s, const F *__restrict__ const _gy,
|
||||
F *__restrict__ const _gw)
|
||||
{
|
||||
const int b = blockIdx.x / H;
|
||||
const int h = blockIdx.x % H;
|
||||
const int i = threadIdx.x;
|
||||
_s += h*_N_*_N_ + i;
|
||||
|
||||
__shared__ float v[_N_], gy[_N_];
|
||||
float state[_N_], saaaa[_N_] = {0}, sbbbb[_T_-1] = {0}, scccc[_N_] = {0};
|
||||
for (int j = 0; j < _N_; j++) {
|
||||
state[j] = float(_s[j*_N_]);
|
||||
}
|
||||
|
||||
const int t_0 = b*T*C + h*_N_ + i;
|
||||
const int t_1 = t_0 + C;
|
||||
const int t_2 = t_0 + 2*C;
|
||||
const int t_T_1 = t_0 + (T-1)*C;
|
||||
|
||||
for (int t = t_T_1; t > t_1; t -= C)
|
||||
{
|
||||
__syncthreads();
|
||||
gy[i] = float(_gy[t]);
|
||||
v[i] = float(_v[t-2*C]);
|
||||
__syncthreads();
|
||||
|
||||
const float r = float(_r[t]);
|
||||
const float w = __expf(-__expf(float(_w[t-C])));
|
||||
float sum = 0.0f;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = saaaa[j];
|
||||
s = (s + r * gy[j]) * w;
|
||||
sum += s * v[j];
|
||||
}
|
||||
sbbbb[(t-t_1)/C] = sum * float(_k[t-2*C]);
|
||||
}
|
||||
{
|
||||
__syncthreads();
|
||||
gy[i] = float(_gy[t_1]);
|
||||
__syncthreads();
|
||||
|
||||
const float r = float(_r[t_1]);
|
||||
const float w = __expf(-__expf(float(_w[t_0])));
|
||||
float sum = 0.0f;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = saaaa[j];
|
||||
s = (s + r * gy[j]) * w;
|
||||
sum += s * state[j];
|
||||
}
|
||||
sbbbb[0] = sum;
|
||||
}
|
||||
|
||||
float sss = sbbbb[0];
|
||||
_gw[t_0] = F(sss * -__expf(float(_w[t_0])));
|
||||
|
||||
{
|
||||
__syncthreads();
|
||||
gy[i] = float(_gy[t_1]);
|
||||
__syncthreads();
|
||||
|
||||
const float w = __expf(-__expf(float(_w[t_0])));
|
||||
float sum = 0.0f;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = scccc[j];
|
||||
s = (s + state[j]) * w;
|
||||
sum += s * gy[j];
|
||||
}
|
||||
sss += sbbbb[1] - (sum * float(_r[t_1]));
|
||||
_gw[t_1] = F(sss * -__expf(float(_w[t_1])));
|
||||
}
|
||||
for (int t = t_2; t < t_T_1; t += C)
|
||||
{
|
||||
__syncthreads();
|
||||
gy[i] = float(_gy[t]);
|
||||
v[i] = float(_v[t-2*C]);
|
||||
__syncthreads();
|
||||
|
||||
const float w = __expf(-__expf(float(_w[t-C])));
|
||||
const float k = float(_k[t-2*C]);
|
||||
float sum = 0.0f;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = scccc[j];
|
||||
s = (s + k * v[j]) * w;
|
||||
sum += s * gy[j];
|
||||
}
|
||||
sss += sbbbb[(t-t_0)/C] - (sum * float(_r[t]));
|
||||
_gw[t] = F(sss * -__expf(float(_w[t])));
|
||||
}
|
||||
_gw[t_T_1] = 0;
|
||||
}
|
||||
|
||||
void cuda_forward(int B, int T, int C, int H, bf16 *r, bf16 *k, bf16 *v, bf16 *w, bf16 *u, bf16 *z, bf16 *y)
|
||||
{
|
||||
assert(H*_N_ == C);
|
||||
assert(_N_%4 == 0);
|
||||
kernel_forward<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, r, k, v, w, u, z, y);
|
||||
}
|
||||
|
||||
void cuda_backward(int B, int T, int C, int H, bf16 *r, bf16 *k, bf16 *v, bf16 *w, bf16 *u, bf16 *z, bf16 *gy, bf16 *gr, bf16 *gk, bf16 *gv, bf16 *gw, bf16 *gu, bf16 *gs)
|
||||
{
|
||||
assert(H*_N_ == C);
|
||||
assert(_N_%4 == 0);
|
||||
kernel_backward_111<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, r, k, v, w, u, z, gy, gr, gk, gv, gu, gs);
|
||||
kernel_backward_222<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, r, k, v, w, u, z, gy, gw);
|
||||
}
|
||||
22
finetune/lora/v6/cuda/wkv6infctx_op.cpp
vendored
Normal file
22
finetune/lora/v6/cuda/wkv6infctx_op.cpp
vendored
Normal file
@ -0,0 +1,22 @@
|
||||
#include <torch/extension.h>
|
||||
#include "ATen/ATen.h"
|
||||
typedef at::BFloat16 bf16;
|
||||
|
||||
void cuda_forward(int B, int T, int C, int H, bf16 *r, bf16 *k, bf16 *v, bf16 *w, bf16 *u, bf16 *s, bf16 *y);
|
||||
void cuda_backward(int B, int T, int C, int H, bf16 *r, bf16 *k, bf16 *v, bf16 *w, bf16 *u, bf16 *s, bf16 *gy, bf16 *gr, bf16 *gk, bf16 *gv, bf16 *gw, bf16 *gu, bf16 *gs);
|
||||
|
||||
void forward(int64_t B, int64_t T, int64_t C, int64_t H, torch::Tensor &r, torch::Tensor &k, torch::Tensor &v, torch::Tensor &w, torch::Tensor &u, torch::Tensor &s, torch::Tensor &y) {
|
||||
cuda_forward(B, T, C, H, r.data_ptr<bf16>(), k.data_ptr<bf16>(), v.data_ptr<bf16>(), w.data_ptr<bf16>(), u.data_ptr<bf16>(), s.data_ptr<bf16>(), y.data_ptr<bf16>());
|
||||
}
|
||||
void backward(int64_t B, int64_t T, int64_t C, int64_t H, torch::Tensor &r, torch::Tensor &k, torch::Tensor &v, torch::Tensor &w, torch::Tensor &u, torch::Tensor &s, torch::Tensor &gy, torch::Tensor &gr, torch::Tensor &gk, torch::Tensor &gv, torch::Tensor &gw, torch::Tensor &gu, torch::Tensor &gs) {
|
||||
cuda_backward(B, T, C, H, r.data_ptr<bf16>(), k.data_ptr<bf16>(), v.data_ptr<bf16>(), w.data_ptr<bf16>(), u.data_ptr<bf16>(), s.data_ptr<bf16>(), gy.data_ptr<bf16>(), gr.data_ptr<bf16>(), gk.data_ptr<bf16>(), gv.data_ptr<bf16>(), gw.data_ptr<bf16>(), gu.data_ptr<bf16>(), gs.data_ptr<bf16>());
|
||||
}
|
||||
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
||||
m.def("forward", &forward, "wkv6state forward");
|
||||
m.def("backward", &backward, "wkv6state backward");
|
||||
}
|
||||
|
||||
TORCH_LIBRARY(wkv6state, m) {
|
||||
m.def("forward", forward);
|
||||
m.def("backward", backward);
|
||||
}
|
||||
311
finetune/lora/v6/cuda/wkv6state_cuda.cu
vendored
Normal file
311
finetune/lora/v6/cuda/wkv6state_cuda.cu
vendored
Normal file
@ -0,0 +1,311 @@
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include "ATen/ATen.h"
|
||||
typedef at::BFloat16 bf16;
|
||||
|
||||
template <typename F>
|
||||
__global__ void kernel_forward(const int B, const int T, const int C, const int H,
|
||||
const F *__restrict__ const _r, const F *__restrict__ const _k, const F *__restrict__ const _v, const F *__restrict__ _w, const F *__restrict__ _u,const F *__restrict__ _s,
|
||||
F *__restrict__ const _y)
|
||||
{
|
||||
const int b = blockIdx.x / H;
|
||||
const int h = blockIdx.x % H;
|
||||
const int i = threadIdx.x;
|
||||
_u += h*_N_;
|
||||
_s += h*_N_*_N_ + i*_N_;
|
||||
|
||||
__shared__ float r[_N_], k[_N_], u[_N_], w[_N_];
|
||||
float state[_N_];
|
||||
|
||||
__syncthreads();
|
||||
u[i] = float(_u[i]);
|
||||
__syncthreads();
|
||||
for (int j = 0; j < _N_; j++) {
|
||||
state[j] = float(_s[j]);
|
||||
}
|
||||
|
||||
for (int t = b*T*C + h*_N_ + i; t < (b+1)*T*C + h*_N_ + i; t += C)
|
||||
{
|
||||
__syncthreads();
|
||||
w[i] = __expf(-__expf(float(_w[t])));
|
||||
r[i] = float(_r[t]);
|
||||
k[i] = float(_k[t]);
|
||||
__syncthreads();
|
||||
|
||||
const float v = float(_v[t]);
|
||||
float y = 0;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j+=4)
|
||||
{
|
||||
const float4& r_ = (float4&)(r[j]);
|
||||
const float4& k_ = (float4&)(k[j]);
|
||||
const float4& w_ = (float4&)(w[j]);
|
||||
const float4& u_ = (float4&)(u[j]);
|
||||
float4& s = (float4&)(state[j]);
|
||||
float4 x;
|
||||
|
||||
x.x = k_.x * v;
|
||||
x.y = k_.y * v;
|
||||
x.z = k_.z * v;
|
||||
x.w = k_.w * v;
|
||||
|
||||
y += r_.x * (u_.x * x.x + s.x);
|
||||
y += r_.y * (u_.y * x.y + s.y);
|
||||
y += r_.z * (u_.z * x.z + s.z);
|
||||
y += r_.w * (u_.w * x.w + s.w);
|
||||
|
||||
s.x = s.x * w_.x + x.x;
|
||||
s.y = s.y * w_.y + x.y;
|
||||
s.z = s.z * w_.z + x.z;
|
||||
s.w = s.w * w_.w + x.w;
|
||||
}
|
||||
_y[t] = F(y);
|
||||
}
|
||||
// #pragma unroll
|
||||
// for (int j = 0; j < _N_; j++)
|
||||
// _s[j] = F(state[j]);
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
__global__ void kernel_backward_111(const int B, const int T, const int C, const int H,
|
||||
const F *__restrict__ const _r, const F *__restrict__ const _k, const F *__restrict__ const _v, const F *__restrict__ _w, const F *__restrict__ _u, const F *__restrict__ _s, const F *__restrict__ const _gy,
|
||||
F *__restrict__ const _gr, F *__restrict__ const _gk, F *__restrict__ const _gv, F *__restrict__ const _gu, F *__restrict__ const _gs)
|
||||
{
|
||||
const int b = blockIdx.x / H;
|
||||
const int h = blockIdx.x % H;
|
||||
const int i = threadIdx.x;
|
||||
_u += h*_N_;
|
||||
_s += h*_N_*_N_ + i;
|
||||
|
||||
__shared__ float u_[_N_];
|
||||
__shared__ float r[_N_], k[_N_], v[_N_], w_[_N_], gy[_N_];
|
||||
__syncthreads();
|
||||
u_[i] = float(_u[i]);
|
||||
__syncthreads();
|
||||
|
||||
const float u = u_[i];
|
||||
|
||||
float state[_N_], scccc[_N_] = {0}, sdddd[_N_] = {0}, sssss[_N_] = {0}, swwww[_N_];
|
||||
for (int j = 0; j < _N_; j++) {
|
||||
state[j] = float(_s[j*_N_]);
|
||||
swwww[j] = 1.0;
|
||||
}
|
||||
|
||||
const int t_0 = b*T*C + h*_N_ + i;
|
||||
const int t_T_1 = t_0 + (T-1)*C;
|
||||
const int t_T = t_0 + T*C;
|
||||
|
||||
float gu = 0;
|
||||
for (int t = t_0; t < t_T; t += C)
|
||||
{
|
||||
__syncthreads();
|
||||
v[i] = float(_v[t]);
|
||||
gy[i] = float(_gy[t]);
|
||||
__syncthreads();
|
||||
|
||||
const float k = float(_k[t]);
|
||||
const float w = __expf(-__expf(float(_w[t])));
|
||||
float gr = 0, gu_ = 0;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = state[j];
|
||||
float x = k * v[j];
|
||||
|
||||
gr += (u * x + s) * gy[j];
|
||||
gu_ += x * gy[j];
|
||||
s = s * w + x;
|
||||
}
|
||||
_gr[t] = F(gr);
|
||||
gu += float(_r[t]) * gu_;
|
||||
}
|
||||
_gu[b*C + h*_N_ + i] = F(gu);
|
||||
|
||||
for (int t = t_T_1; t >= t_0; t -= C)
|
||||
{
|
||||
__syncthreads();
|
||||
v[i] = float(_v[t]);
|
||||
gy[i] = float(_gy[t]);
|
||||
__syncthreads();
|
||||
|
||||
const float rr = float(_r[t]);
|
||||
const float w = __expf(-__expf(float(_w[t])));
|
||||
float gk = 0;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = scccc[j];
|
||||
float x = rr * gy[j];
|
||||
|
||||
gk += (u * x + s) * v[j];
|
||||
s = x + s * w;
|
||||
}
|
||||
_gk[t] = F(gk);
|
||||
}
|
||||
|
||||
for (int t = t_T_1; t >= t_0; t -= C)
|
||||
{
|
||||
__syncthreads();
|
||||
r[i] = float(_r[t]);
|
||||
k[i] = float(_k[t]);
|
||||
w_[i] = __expf(-__expf(float(_w[t])));
|
||||
__syncthreads();
|
||||
|
||||
const float gyy = float(_gy[t]);
|
||||
float gv = 0;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = sdddd[j];
|
||||
float x = gyy * r[j];
|
||||
|
||||
gv += (u_[j] * x + s) * k[j];
|
||||
s = x + s * w_[j];
|
||||
}
|
||||
_gv[t] = F(gv);
|
||||
}
|
||||
|
||||
for (int t = t_0; t < t_T; t += C)
|
||||
{
|
||||
__syncthreads();
|
||||
r[i] = float(_r[t]);
|
||||
w_[i] = __expf(-__expf(float(_w[t])));
|
||||
__syncthreads();
|
||||
|
||||
const float gyy = float(_gy[t]);
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& w = swwww[j];
|
||||
sssss[j] += gyy * w * r[j];
|
||||
w *= w_[j];
|
||||
}
|
||||
}
|
||||
for (int j = 0; j < _N_; j++)
|
||||
_gs[b*H*_N_*_N_ + h*_N_*_N_ + i*_N_ + j] = F(sssss[j]);
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
__global__ void kernel_backward_222(const int B, const int T, const int C, const int H,
|
||||
const F *__restrict__ const _r, const F *__restrict__ const _k, const F *__restrict__ const _v, const F *__restrict__ _w, const F *__restrict__ _u, const F *__restrict__ _s, const F *__restrict__ const _gy,
|
||||
F *__restrict__ const _gw)
|
||||
{
|
||||
const int b = blockIdx.x / H;
|
||||
const int h = blockIdx.x % H;
|
||||
const int i = threadIdx.x;
|
||||
_s += h*_N_*_N_ + i;
|
||||
|
||||
__shared__ float v[_N_], gy[_N_];
|
||||
float state[_N_], saaaa[_N_] = {0}, sbbbb[_T_-1] = {0}, scccc[_N_] = {0};
|
||||
for (int j = 0; j < _N_; j++) {
|
||||
state[j] = float(_s[j*_N_]);
|
||||
}
|
||||
|
||||
const int t_0 = b*T*C + h*_N_ + i;
|
||||
const int t_1 = t_0 + C;
|
||||
const int t_2 = t_0 + 2*C;
|
||||
const int t_T_1 = t_0 + (T-1)*C;
|
||||
|
||||
for (int t = t_T_1; t > t_1; t -= C)
|
||||
{
|
||||
__syncthreads();
|
||||
gy[i] = float(_gy[t]);
|
||||
v[i] = float(_v[t-2*C]);
|
||||
__syncthreads();
|
||||
|
||||
const float r = float(_r[t]);
|
||||
const float w = __expf(-__expf(float(_w[t-C])));
|
||||
float sum = 0.0f;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = saaaa[j];
|
||||
s = (s + r * gy[j]) * w;
|
||||
sum += s * v[j];
|
||||
}
|
||||
sbbbb[(t-t_1)/C] = sum * float(_k[t-2*C]);
|
||||
}
|
||||
{
|
||||
__syncthreads();
|
||||
gy[i] = float(_gy[t_1]);
|
||||
__syncthreads();
|
||||
|
||||
const float r = float(_r[t_1]);
|
||||
const float w = __expf(-__expf(float(_w[t_0])));
|
||||
float sum = 0.0f;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = saaaa[j];
|
||||
s = (s + r * gy[j]) * w;
|
||||
sum += s * state[j];
|
||||
}
|
||||
sbbbb[0] = sum;
|
||||
}
|
||||
|
||||
float sss = sbbbb[0];
|
||||
_gw[t_0] = F(sss * -__expf(float(_w[t_0])));
|
||||
|
||||
{
|
||||
__syncthreads();
|
||||
gy[i] = float(_gy[t_1]);
|
||||
__syncthreads();
|
||||
|
||||
const float w = __expf(-__expf(float(_w[t_0])));
|
||||
float sum = 0.0f;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = scccc[j];
|
||||
s = (s + state[j]) * w;
|
||||
sum += s * gy[j];
|
||||
}
|
||||
sss += sbbbb[1] - (sum * float(_r[t_1]));
|
||||
_gw[t_1] = F(sss * -__expf(float(_w[t_1])));
|
||||
}
|
||||
for (int t = t_2; t < t_T_1; t += C)
|
||||
{
|
||||
__syncthreads();
|
||||
gy[i] = float(_gy[t]);
|
||||
v[i] = float(_v[t-2*C]);
|
||||
__syncthreads();
|
||||
|
||||
const float w = __expf(-__expf(float(_w[t-C])));
|
||||
const float k = float(_k[t-2*C]);
|
||||
float sum = 0.0f;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
{
|
||||
float& s = scccc[j];
|
||||
s = (s + k * v[j]) * w;
|
||||
sum += s * gy[j];
|
||||
}
|
||||
sss += sbbbb[(t-t_0)/C] - (sum * float(_r[t]));
|
||||
_gw[t] = F(sss * -__expf(float(_w[t])));
|
||||
}
|
||||
_gw[t_T_1] = 0;
|
||||
}
|
||||
|
||||
void cuda_forward(int B, int T, int C, int H, bf16 *r, bf16 *k, bf16 *v, bf16 *w, bf16 *u, bf16 *z, bf16 *y)
|
||||
{
|
||||
assert(H*_N_ == C);
|
||||
assert(_N_%4 == 0);
|
||||
kernel_forward<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, r, k, v, w, u, z, y);
|
||||
}
|
||||
|
||||
void cuda_backward(int B, int T, int C, int H, bf16 *r, bf16 *k, bf16 *v, bf16 *w, bf16 *u, bf16 *z, bf16 *gy, bf16 *gr, bf16 *gk, bf16 *gv, bf16 *gw, bf16 *gu, bf16 *gs)
|
||||
{
|
||||
assert(H*_N_ == C);
|
||||
assert(_N_%4 == 0);
|
||||
kernel_backward_111<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, r, k, v, w, u, z, gy, gr, gk, gv, gu, gs);
|
||||
kernel_backward_222<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, r, k, v, w, u, z, gy, gw);
|
||||
}
|
||||
22
finetune/lora/v6/cuda/wkv6state_op.cpp
vendored
Normal file
22
finetune/lora/v6/cuda/wkv6state_op.cpp
vendored
Normal file
@ -0,0 +1,22 @@
|
||||
#include <torch/extension.h>
|
||||
#include "ATen/ATen.h"
|
||||
typedef at::BFloat16 bf16;
|
||||
|
||||
void cuda_forward(int B, int T, int C, int H, bf16 *r, bf16 *k, bf16 *v, bf16 *w, bf16 *u, bf16 *s, bf16 *y);
|
||||
void cuda_backward(int B, int T, int C, int H, bf16 *r, bf16 *k, bf16 *v, bf16 *w, bf16 *u, bf16 *s, bf16 *gy, bf16 *gr, bf16 *gk, bf16 *gv, bf16 *gw, bf16 *gu, bf16 *gs);
|
||||
|
||||
void forward(int64_t B, int64_t T, int64_t C, int64_t H, torch::Tensor &r, torch::Tensor &k, torch::Tensor &v, torch::Tensor &w, torch::Tensor &u, torch::Tensor &s, torch::Tensor &y) {
|
||||
cuda_forward(B, T, C, H, r.data_ptr<bf16>(), k.data_ptr<bf16>(), v.data_ptr<bf16>(), w.data_ptr<bf16>(), u.data_ptr<bf16>(), s.data_ptr<bf16>(), y.data_ptr<bf16>());
|
||||
}
|
||||
void backward(int64_t B, int64_t T, int64_t C, int64_t H, torch::Tensor &r, torch::Tensor &k, torch::Tensor &v, torch::Tensor &w, torch::Tensor &u, torch::Tensor &s, torch::Tensor &gy, torch::Tensor &gr, torch::Tensor &gk, torch::Tensor &gv, torch::Tensor &gw, torch::Tensor &gu, torch::Tensor &gs) {
|
||||
cuda_backward(B, T, C, H, r.data_ptr<bf16>(), k.data_ptr<bf16>(), v.data_ptr<bf16>(), w.data_ptr<bf16>(), u.data_ptr<bf16>(), s.data_ptr<bf16>(), gy.data_ptr<bf16>(), gr.data_ptr<bf16>(), gk.data_ptr<bf16>(), gv.data_ptr<bf16>(), gw.data_ptr<bf16>(), gu.data_ptr<bf16>(), gs.data_ptr<bf16>());
|
||||
}
|
||||
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
||||
m.def("forward", &forward, "wkv6state forward");
|
||||
m.def("backward", &backward, "wkv6state backward");
|
||||
}
|
||||
|
||||
TORCH_LIBRARY(wkv6state, m) {
|
||||
m.def("forward", forward);
|
||||
m.def("backward", backward);
|
||||
}
|
||||
16
finetune/lora/v6/demo/demo-lora-merge.sh
vendored
Normal file
16
finetune/lora/v6/demo/demo-lora-merge.sh
vendored
Normal file
@ -0,0 +1,16 @@
|
||||
|
||||
base_model='/home/rwkv/JL/model/rwkv-x060-7b-world-v2.1-36%trained-20240413-ctx4k.pth'
|
||||
lora_init='/home/rwkv/JL/out_model/nf4/init_lora.pth'
|
||||
lora_checkpoint='/home/rwkv/JL/out_model/nf4/rwkv-0.pth'
|
||||
output='/home/rwkv/JL/model/nf4-world.pth'
|
||||
QUANT='nf4' #follow train
|
||||
TYPE='lora'
|
||||
Lora_alpha=128
|
||||
|
||||
python merge/merge.py --base_model $base_model \
|
||||
--lora_init $lora_init \
|
||||
--lora_checkpoint $lora_checkpoint \
|
||||
--output $output \
|
||||
--quant $QUANT \
|
||||
--type $TYPE \
|
||||
--lora_alpha $Lora_alpha
|
||||
27
finetune/lora/v6/demo/demo-lora.sh
vendored
Normal file
27
finetune/lora/v6/demo/demo-lora.sh
vendored
Normal file
@ -0,0 +1,27 @@
|
||||
load_model='/home/rwkv/JL/model/rwkv-x060-7b-world-v2.1-36%trained-20240413-ctx4k.pth'
|
||||
proj_dir='/home/rwkv/JL/out_model/nf4'
|
||||
data_file='/home/rwkv/JL/data/roleplay'
|
||||
|
||||
QUANT='nf4' #4bit nf4 fp4 none
|
||||
|
||||
lora_r=64
|
||||
lora_alpha=128
|
||||
|
||||
n_layer=32
|
||||
n_embd=4096
|
||||
|
||||
micro_bsz=8
|
||||
epoch_save=1
|
||||
epoch_steps=1000
|
||||
ctx_len=1024
|
||||
|
||||
python train.py --load_model $load_model \
|
||||
--proj_dir $proj_dir --data_file $data_file \
|
||||
--data_type binidx --vocab_size 65536 \
|
||||
--ctx_len $ctx_len --epoch_steps $epoch_steps --epoch_count 20 --epoch_begin 0 --epoch_save $epoch_save --micro_bsz $micro_bsz \
|
||||
--n_layer $n_layer --n_embd $n_embd \
|
||||
--pre_ffn 0 --head_qk 0 --lr_init 5e-5 --lr_final 5e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
|
||||
--accelerator gpu --devices 1 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 1 \
|
||||
--my_testing "x060" \
|
||||
--lora_load rwkv-0 --lora --lora_r $lora_r --lora_alpha $lora_alpha --lora_dropout 0.01 --lora_parts=att,ffn,time,ln \
|
||||
--quant $QUANT
|
||||
15
finetune/lora/v6/demo/demo-pissa-merge.sh
vendored
Normal file
15
finetune/lora/v6/demo/demo-pissa-merge.sh
vendored
Normal file
@ -0,0 +1,15 @@
|
||||
|
||||
|
||||
base_model='/home/rwkv/JL/model/RWKV-x060-World-1B6-v2-20240208-ctx4096.pth'
|
||||
lora_init='/home/rwkv/JL/out_model/nf4/init_lora.pth'
|
||||
lora_checkpoint='/home/rwkv/JL/out_model/nf4/rwkv-0.pth'
|
||||
output='/home/rwkv/JL/model/end-world.pth'
|
||||
QUANT='nf4' #follow train
|
||||
TYPE='pissa'
|
||||
|
||||
python merge/merge.py --base_model $base_model \
|
||||
--lora_init $lora_init \
|
||||
--lora_checkpoint $lora_checkpoint \
|
||||
--output $output \
|
||||
--quant $QUANT \
|
||||
--type $TYPE
|
||||
40
finetune/lora/v6/demo/demo-pissa.sh
vendored
Normal file
40
finetune/lora/v6/demo/demo-pissa.sh
vendored
Normal file
@ -0,0 +1,40 @@
|
||||
|
||||
load_model='/home/rwkv/JL/model/RWKV-x060-World-1B6-v2.1-20240328-ctx4096.pth'
|
||||
proj_dir='/home/rwkv/JL/out_model/nf4'
|
||||
data_file='/home/rwkv/JL/data/end_text_document'
|
||||
|
||||
QUANT='nf4' #4bit nf4 fp4 none
|
||||
svd_niter=4
|
||||
lora_r=64
|
||||
|
||||
n_layer=24
|
||||
n_embd=2048
|
||||
|
||||
micro_bsz=8
|
||||
epoch_save=1
|
||||
epoch_steps=1000
|
||||
ctx_len=1024
|
||||
|
||||
python train.py --load_model $load_model \
|
||||
--proj_dir $proj_dir --data_file $data_file \
|
||||
--data_type binidx --vocab_size 65536 \
|
||||
--ctx_len $ctx_len --epoch_steps $epoch_steps --epoch_count 1 --epoch_begin 0 --epoch_save $epoch_save --micro_bsz $micro_bsz \
|
||||
--n_layer $n_layer --n_embd $n_embd \
|
||||
--pre_ffn 0 --head_qk 0 --lr_init 5e-5 --lr_final 5e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
|
||||
--accelerator gpu --devices 1 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 1 \
|
||||
--my_testing "x060" \
|
||||
--lora_load rwkv-0 --lora --lora_r $lora_r --lora_alpha 128 --lora_dropout 0.01 --lora_parts=att,ffn,time,ln \
|
||||
--PISSA --svd_niter $svd_niter \
|
||||
--dataload pad
|
||||
|
||||
###remove load_model
|
||||
# python train.py --proj_dir $proj_dir --data_file $data_file \
|
||||
# --data_type binidx --vocab_size 65536 \
|
||||
# --ctx_len $ctx_len --epoch_steps $epoch_steps --epoch_count 20 --epoch_begin 0 --epoch_save $epoch_save --micro_bsz $micro_bsz \
|
||||
# --n_layer $n_layer --n_embd $n_embd \
|
||||
# --pre_ffn 0 --head_qk 0 --lr_init 5e-5 --lr_final 5e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
|
||||
# --accelerator gpu --devices 1 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 1 \
|
||||
# --my_testing "x060" \
|
||||
# --lora_load rwkv-0 --lora --lora_r $lora_r --lora_alpha 128 --lora_dropout 0.01 --lora_parts=att,ffn,time,ln \
|
||||
# --PISSA --svd_niter $svd_niter \
|
||||
# --quant $QUANT
|
||||
27
finetune/lora/v6/demo/demo-qpissa-pt.sh
vendored
Normal file
27
finetune/lora/v6/demo/demo-qpissa-pt.sh
vendored
Normal file
@ -0,0 +1,27 @@
|
||||
load_model='/home/rwkv/JL/model/rwkv-x060-7b-world-v2.1-36%trained-20240413-ctx4k.pth'
|
||||
proj_dir='/home/rwkv/JL/out_model/nf4'
|
||||
data_file='/home/rwkv/JL/data/roleplay'
|
||||
|
||||
QUANT='nf4' #4bit nf4 fp4 none
|
||||
svd_niter=4
|
||||
lora_r=64
|
||||
|
||||
n_layer=32
|
||||
n_embd=4096
|
||||
|
||||
micro_bsz=4
|
||||
epoch_save=1
|
||||
epoch_steps=1000
|
||||
ctx_len=1024
|
||||
|
||||
|
||||
python train.py --proj_dir $proj_dir --data_file $data_file \
|
||||
--data_type binidx --vocab_size 65536 \
|
||||
--ctx_len $ctx_len --epoch_steps $epoch_steps --epoch_count 20 --epoch_begin 0 --epoch_save $epoch_save --micro_bsz $micro_bsz \
|
||||
--n_layer $n_layer --n_embd $n_embd \
|
||||
--pre_ffn 0 --head_qk 0 --lr_init 5e-5 --lr_final 5e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
|
||||
--accelerator gpu --devices 1 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 1 \
|
||||
--my_testing "x060" \
|
||||
--lora_load rwkv-0 --lora --lora_r $lora_r --lora_alpha 128 --lora_dropout 0.01 --lora_parts=att,ffn,time,ln \
|
||||
--PISSA --svd_niter $svd_niter \
|
||||
--quant $QUANT
|
||||
8
finetune/lora/v6/demo/demo-state-merge.sh
vendored
Normal file
8
finetune/lora/v6/demo/demo-state-merge.sh
vendored
Normal file
@ -0,0 +1,8 @@
|
||||
base_model='/home/rwkv/JL/model/RWKV-x060-World-3B-v2.1-20240417-ctx4096.pth'
|
||||
state_checkpoint='/home/rwkv/JL/out_model/state/rwkv-9.pth'
|
||||
output='/home/rwkv/JL/model/state-0.pth'
|
||||
|
||||
|
||||
python merge/merge_state.py --base_model $base_model \
|
||||
--state_checkpoint $state_checkpoint \
|
||||
--output $output
|
||||
22
finetune/lora/v6/demo/demo-state-tuning.sh
vendored
Normal file
22
finetune/lora/v6/demo/demo-state-tuning.sh
vendored
Normal file
@ -0,0 +1,22 @@
|
||||
load_model='/home/rwkv/JL/model/RWKV-x060-World-1B6-v2.1-20240328-ctx4096.pth'
|
||||
proj_dir='/home/rwkv/JL/out_model/state'
|
||||
data_file='/home/rwkv/JL/data/end_text_document'
|
||||
|
||||
|
||||
n_layer=24
|
||||
n_embd=2048
|
||||
|
||||
micro_bsz=1
|
||||
epoch_save=1
|
||||
epoch_steps=1000
|
||||
ctx_len=1024
|
||||
|
||||
python train.py --load_model $load_model \
|
||||
--proj_dir $proj_dir --data_file $data_file \
|
||||
--data_type binidx --vocab_size 65536 \
|
||||
--ctx_len $ctx_len --epoch_steps $epoch_steps --epoch_count 1 --epoch_begin 0 --epoch_save $epoch_save --micro_bsz $micro_bsz \
|
||||
--n_layer $n_layer --n_embd $n_embd \
|
||||
--pre_ffn 0 --head_qk 0 --lr_init 1 --lr_final 1e-1 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
|
||||
--accelerator gpu --devices 1 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 0 \
|
||||
--my_testing "x060" \
|
||||
--train_type "state" --dataload pad --wandb fla --fla
|
||||
27
finetune/lora/v6/demo/demo-training-prepare.sh
vendored
Normal file
27
finetune/lora/v6/demo/demo-training-prepare.sh
vendored
Normal file
@ -0,0 +1,27 @@
|
||||
#!/bin/bash
|
||||
|
||||
# Create data directory
|
||||
|
||||
mkdir -p data
|
||||
|
||||
# Download minipile (1498226207 tokens, around 3GB)
|
||||
|
||||
wget --continue -O data/minipile.idx https://huggingface.co/datasets/BlinkDL/minipile-tokenized/resolve/main/rwkv_vocab_v20230424/minipile.idx
|
||||
wget --continue -O data/minipile.bin https://huggingface.co/datasets/BlinkDL/minipile-tokenized/resolve/main/rwkv_vocab_v20230424/minipile.bin
|
||||
|
||||
# Generate initial model (L12-D768 = 169M)
|
||||
|
||||
BASE_NAME="model/0.1-1"
|
||||
N_LAYER="12"
|
||||
N_EMBD="768"
|
||||
|
||||
# magic_prime = the largest 3n+2 prime smaller than datalen/ctxlen-1 (= 1498226207/512-1 = 2926222.06 in this case)
|
||||
# use https://www.dcode.fr/prime-numbers-search
|
||||
|
||||
python train.py --wandb "" --proj_dir $BASE_NAME \
|
||||
--data_file "data/minipile" --data_type "binidx" --vocab_size 65536 \
|
||||
--ctx_len 512 --my_pile_stage 1 --epoch_count 1 --epoch_begin 0 \
|
||||
--epoch_save 1 --weight_decay 0 --head_size_a 64 \
|
||||
--num_nodes 1 --micro_bsz 1 --n_layer $N_LAYER --n_embd $N_EMBD --pre_ffn 0 --head_qk 0 --my_exit_tokens 1498226207 --magic_prime 2926181 \
|
||||
--lr_init 1e-5 --lr_final 1e-5 --warmup_steps 10 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 --my_pile_edecay 0 \
|
||||
--accelerator cpu --devices 1 --precision bf16 --strategy deepspeed_stage_2 --grad_cp 0 --enable_progress_bar False --ds_bucket_mb 200
|
||||
21
finetune/lora/v6/demo/demo-training-run.sh
vendored
Normal file
21
finetune/lora/v6/demo/demo-training-run.sh
vendored
Normal file
@ -0,0 +1,21 @@
|
||||
#!/bin/bash
|
||||
|
||||
BASE_NAME="model/0.1-1"
|
||||
N_LAYER="12"
|
||||
N_EMBD="768"
|
||||
M_BSZ="16" # takes 16G VRAM (reduce this to save VRAM)
|
||||
LR_INIT="6e-4"
|
||||
LR_FINAL="6e-5"
|
||||
GRAD_CP=0 # set to 1 to save VRAM (will be slower)
|
||||
EPOCH_SAVE=10
|
||||
|
||||
# magic_prime = the largest 3n+2 prime smaller than datalen/ctxlen-1 (= 1498226207/512-1 = 2926222.06 in this case)
|
||||
# use https://www.dcode.fr/prime-numbers-search
|
||||
|
||||
python train.py --load_model "0" --wandb "RWKV-5-Test" --proj_dir $BASE_NAME \
|
||||
--ctx_len 512 --my_pile_stage 3 --epoch_count 999999 --epoch_begin 0 \
|
||||
--data_file "data/minipile" --my_exit_tokens 1498226207 --magic_prime 2926181 \
|
||||
--num_nodes 1 --micro_bsz $M_BSZ --n_layer $N_LAYER --n_embd $N_EMBD --pre_ffn 0 --head_qk 0 \
|
||||
--lr_init $LR_INIT --lr_final $LR_FINAL --warmup_steps 10 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 --my_pile_edecay 0 --data_type "binidx" --vocab_size 65536 \
|
||||
--weight_decay 0.001 --epoch_save $EPOCH_SAVE --head_size_a 64 \
|
||||
--accelerator gpu --devices 1 --precision bf16 --strategy deepspeed_stage_2 --grad_cp $GRAD_CP --enable_progress_bar True --ds_bucket_mb 200
|
||||
182
finetune/lora/v6/demo/demo.jsonl
vendored
Normal file
182
finetune/lora/v6/demo/demo.jsonl
vendored
Normal file
File diff suppressed because one or more lines are too long
25
finetune/lora/v6/demo/infctx.sh
vendored
Normal file
25
finetune/lora/v6/demo/infctx.sh
vendored
Normal file
@ -0,0 +1,25 @@
|
||||
load_model='/home/rwkv/JL/model/RWKV-x060-World-1B6-v2.1-20240328-ctx4096.pth'
|
||||
proj_dir='/home/rwkv/JL/out_model/infctx'
|
||||
data_file='/home/rwkv/JL/data/roleplay'
|
||||
|
||||
|
||||
n_layer=24
|
||||
n_embd=2048
|
||||
|
||||
micro_bsz=8
|
||||
epoch_save=5
|
||||
epoch_steps=1000
|
||||
ctx_len=16384
|
||||
chunk_ctx=2048
|
||||
|
||||
|
||||
python train.py --load_model $load_model \
|
||||
--proj_dir $proj_dir --data_file $data_file \
|
||||
--data_type binidx --vocab_size 65536 \
|
||||
--ctx_len $ctx_len --epoch_steps $epoch_steps --epoch_count 1 --epoch_begin 0 --epoch_save $epoch_save --micro_bsz $micro_bsz \
|
||||
--n_layer $n_layer --n_embd $n_embd \
|
||||
--pre_ffn 0 --head_qk 0 --lr_init 1e-4 --lr_final 1e-4 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 \
|
||||
--accelerator gpu --devices 1 --precision bf16 --strategy deepspeed_stage_1 --grad_cp 1 \
|
||||
--lora_load rwkv-0 --lora --lora_r 64 --lora_alpha 128 --lora_dropout 0.01 --lora_parts=att,ffn,time,ln \
|
||||
--my_testing "x060" --dataload pad \
|
||||
--train_type infctx --chunk_ctx $chunk_ctx --fla --wandb infctx
|
||||
50
finetune/lora/v6/fla/__init__.py
vendored
Normal file
50
finetune/lora/v6/fla/__init__.py
vendored
Normal file
@ -0,0 +1,50 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from fla.layers import (ABCAttention, BasedLinearAttention, DeltaNet,
|
||||
GatedLinearAttention, HGRN2Attention, LinearAttention,
|
||||
MultiScaleRetention, ReBasedLinearAttention)
|
||||
from fla.models import (ABCForCausalLM, ABCModel, DeltaNetForCausalLM,
|
||||
DeltaNetModel, GLAForCausalLM, GLAModel,
|
||||
HGRN2ForCausalLM, HGRN2Model, HGRNForCausalLM,
|
||||
HGRNModel, LinearAttentionForCausalLM,
|
||||
LinearAttentionModel, RetNetForCausalLM, RetNetModel,
|
||||
RWKV6ForCausalLM, RWKV6Model, TransformerForCausalLM,
|
||||
TransformerModel)
|
||||
from fla.ops import (chunk_gla, chunk_retention, fused_chunk_based,
|
||||
fused_chunk_gla, fused_chunk_retention)
|
||||
|
||||
__all__ = [
|
||||
'ABCAttention',
|
||||
'BasedLinearAttention',
|
||||
'DeltaNet',
|
||||
'HGRN2Attention',
|
||||
'GatedLinearAttention',
|
||||
'LinearAttention',
|
||||
'MultiScaleRetention',
|
||||
'ReBasedLinearAttention',
|
||||
'ABCForCausalLM',
|
||||
'ABCModel',
|
||||
'DeltaNetForCausalLM',
|
||||
'DeltaNetModel',
|
||||
'HGRNForCausalLM',
|
||||
'HGRNModel',
|
||||
'HGRN2ForCausalLM',
|
||||
'HGRN2Model',
|
||||
'GLAForCausalLM',
|
||||
'GLAModel',
|
||||
'LinearAttentionForCausalLM',
|
||||
'LinearAttentionModel',
|
||||
'RetNetForCausalLM',
|
||||
'RetNetModel',
|
||||
'RWKV6ForCausalLM',
|
||||
'RWKV6Model',
|
||||
'TransformerForCausalLM',
|
||||
'TransformerModel',
|
||||
'chunk_gla',
|
||||
'chunk_retention',
|
||||
'fused_chunk_based',
|
||||
'fused_chunk_gla',
|
||||
'fused_chunk_retention'
|
||||
]
|
||||
|
||||
__version__ = '0.1'
|
||||
25
finetune/lora/v6/fla/layers/__init__.py
vendored
Normal file
25
finetune/lora/v6/fla/layers/__init__.py
vendored
Normal file
@ -0,0 +1,25 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from .abc import ABCAttention
|
||||
from .based import BasedLinearAttention
|
||||
from .delta_net import DeltaNet
|
||||
from .gla import GatedLinearAttention
|
||||
from .hgrn import HGRNAttention
|
||||
from .hgrn2 import HGRN2Attention
|
||||
from .linear_attn import LinearAttention
|
||||
from .multiscale_retention import MultiScaleRetention
|
||||
from .rebased import ReBasedLinearAttention
|
||||
from .rwkv6 import RWKV6Attention
|
||||
|
||||
__all__ = [
|
||||
'ABCAttention',
|
||||
'BasedLinearAttention',
|
||||
'DeltaNet',
|
||||
'GatedLinearAttention',
|
||||
'HGRNAttention',
|
||||
'HGRN2Attention',
|
||||
'LinearAttention',
|
||||
'MultiScaleRetention',
|
||||
'ReBasedLinearAttention',
|
||||
'RWKV6Attention'
|
||||
]
|
||||
195
finetune/lora/v6/fla/layers/abc.py
vendored
Normal file
195
finetune/lora/v6/fla/layers/abc.py
vendored
Normal file
@ -0,0 +1,195 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import warnings
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from einops import rearrange
|
||||
from transformers.cache_utils import Cache
|
||||
|
||||
from fla.modules import (FusedRMSNormSwishGate, RMSNorm, RotaryEmbedding,
|
||||
ShortConvolution)
|
||||
from fla.modules.activations import swiglu, swish
|
||||
from fla.modules.convolution import proj_then_conv1d
|
||||
from fla.ops.abc.chunk import chunk_abc
|
||||
|
||||
|
||||
class ABCAttention(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int = 1024,
|
||||
expand_k: float = 0.5,
|
||||
expand_v: float = 1.0,
|
||||
num_heads: int = 4,
|
||||
use_short_conv: bool = False,
|
||||
conv_size: int = 4,
|
||||
conv_bias: bool = False,
|
||||
share_conv_kernel: bool = True,
|
||||
num_slots: Optional[int] = None,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-5,
|
||||
gate_low_rank_dim: int = 16,
|
||||
gate_logit_normalizer: int = 16,
|
||||
use_input_gate: bool = False,
|
||||
use_output_gate: bool = True,
|
||||
use_norm: bool = True,
|
||||
clamp_min: Optional[float] = -32,
|
||||
clamp_max: Optional[float] = 32,
|
||||
layer_idx: Optional[int] = None,
|
||||
**kwargs
|
||||
) -> ABCAttention:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.num_heads = num_heads
|
||||
self.key_dim = int(self.hidden_size * self.expand_k)
|
||||
self.value_dim = int(self.hidden_size * self.expand_v)
|
||||
self.head_k_dim = self.key_dim // self.num_heads
|
||||
self.head_v_dim = self.value_dim // self.num_heads
|
||||
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.conv_bias = conv_bias
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
|
||||
self.gate_low_rank_dim = gate_low_rank_dim
|
||||
self.gate_logit_normalizer = gate_logit_normalizer
|
||||
|
||||
self.use_input_gate = use_input_gate
|
||||
self.use_output_gate = use_output_gate
|
||||
self.use_norm = use_norm
|
||||
|
||||
if num_slots is None:
|
||||
num_slots = self.head_k_dim
|
||||
self.num_slots = num_slots
|
||||
|
||||
self.norm_eps = norm_eps
|
||||
|
||||
self.clamp_min = clamp_min
|
||||
self.clamp_max = clamp_max
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
if layer_idx is None:
|
||||
warnings.warn(
|
||||
f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will "
|
||||
"to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` "
|
||||
"when creating this class."
|
||||
)
|
||||
|
||||
self.q_proj = nn.Linear(self.hidden_size, self.key_dim, bias=False)
|
||||
self.k_proj = nn.Linear(self.hidden_size, self.key_dim, bias=False)
|
||||
self.v_proj = nn.Linear(self.hidden_size, self.value_dim, bias=False)
|
||||
|
||||
if use_output_gate:
|
||||
self.g_proj = nn.Linear(self.hidden_size, self.value_dim, bias=False)
|
||||
self.s_proj = nn.Linear(self.hidden_size, self.num_heads * self.num_slots, bias=False)
|
||||
self.o_proj = nn.Linear(self.value_dim, self.hidden_size, bias=False)
|
||||
|
||||
if use_short_conv:
|
||||
self.conv_size = conv_size
|
||||
if share_conv_kernel:
|
||||
self.h_conv1d = ShortConvolution(hidden_size, conv_size, activation='silu')
|
||||
else:
|
||||
self.q_conv1d = ShortConvolution(self.key_dim, conv_size, activation='silu')
|
||||
self.k_conv1d = ShortConvolution(self.key_dim, conv_size, activation='silu')
|
||||
self.v_conv1d = ShortConvolution(self.value_dim, conv_size, activation='silu')
|
||||
|
||||
if self.use_norm:
|
||||
if self.use_output_gate:
|
||||
self.g_norm = FusedRMSNormSwishGate(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
else:
|
||||
self.g_norm = RMSNorm(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
|
||||
if self.use_rope:
|
||||
self.rotary = RotaryEmbedding(self.head_k_dim)
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Cache] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
**kwargs
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
|
||||
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
hidden_states = self.h_conv1d(hidden_states)
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
else:
|
||||
q = proj_then_conv1d(hidden_states, self.q_proj.weight, self.q_conv1d.weight, self.q_conv1d.bias)
|
||||
k = proj_then_conv1d(hidden_states, self.k_proj.weight, self.k_conv1d.weight, self.k_conv1d.bias)
|
||||
v = proj_then_conv1d(hidden_states, self.v_proj.weight, self.v_conv1d.weight, self.v_conv1d.bias)
|
||||
else:
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
|
||||
if self.use_input_gate:
|
||||
q, k, v = map(lambda x: swish(x), (q, k, v))
|
||||
|
||||
if self.use_rope:
|
||||
q = rearrange(q, '... (h d) -> ... h d', h=self.num_heads)
|
||||
k = rearrange(k, '... (h d) -> ... h d', h=self.num_heads)
|
||||
seqlen_offset = 0
|
||||
if past_key_values is not None:
|
||||
seqlen_offset = past_key_values.get_seq_length(self.layer_idx)
|
||||
q, k = self.rotary(q, k, seqlen_offset)
|
||||
q = rearrange(q, 'b n h d -> b h n d', h=self.num_heads)
|
||||
k = rearrange(k, 'b n h d -> b h n d', h=self.num_heads)
|
||||
else:
|
||||
q = rearrange(q, 'b n (h d) -> b h n d', h=self.num_heads)
|
||||
k = rearrange(k, 'b n (h d) -> b h n d', h=self.num_heads)
|
||||
v = rearrange(v, 'b n (h d) -> b h n d', h=self.num_heads)
|
||||
|
||||
# [batch_size, n_heads, seq_len, num_slots]
|
||||
s = rearrange(self.s_proj(hidden_states), 'b t (h m) -> b h t m', h=self.num_heads)
|
||||
s = s.clamp_(self.clamp_min, self.clamp_max)
|
||||
|
||||
last_state = past_key_values[self.layer_idx] if use_cache else None
|
||||
o, last_state = chunk_abc(q, k, v, s, initial_state=last_state, output_final_state=use_cache)
|
||||
if past_key_values is not None and last_state is not None:
|
||||
past_key_values.update(last_state, self.layer_idx, q.shape[2])
|
||||
|
||||
o = rearrange(o, 'b h t d -> b t h d')
|
||||
if self.use_norm and not self.use_output_gate:
|
||||
o = self.g_norm(o)
|
||||
elif self.use_output_gate:
|
||||
g = rearrange(self.g_proj(hidden_states), 'b t (h d) -> b t h d', h=self.num_heads)
|
||||
o = self.g_norm(o, g) if self.use_norm else swiglu(g, o)
|
||||
o = rearrange(o, 'b t h d -> b t (h d)')
|
||||
o = self.o_proj(o)
|
||||
|
||||
return o, None, past_key_values
|
||||
|
||||
def init_state(self, batch_size: int) -> Tuple[torch.Tensor]:
|
||||
param = next(self.parameters())
|
||||
state = tuple()
|
||||
if self.use_short_conv:
|
||||
state += (param.new_zeros(batch_size, self.hidden_size, self.conv_size),)
|
||||
state += (param.new_zeros(batch_size, self.num_heads, self.head_k_dim, self.num_slots),
|
||||
param.new_zeros(batch_size, self.num_heads, self.num_slots, self.head_v_dim))
|
||||
return state
|
||||
|
||||
def state_size(self, sequence_length: int = 2048):
|
||||
return self.num_heads * self.key_dim * self.head_v_dim
|
||||
126
finetune/lora/v6/fla/layers/based.py
vendored
Normal file
126
finetune/lora/v6/fla/layers/based.py
vendored
Normal file
@ -0,0 +1,126 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
"""
|
||||
Linear attention in Based.
|
||||
https://github.com/HazyResearch/zoology/blob/main/zoology/mixers/based.py
|
||||
"""
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from einops import rearrange
|
||||
|
||||
from fla.modules.feature_map import TaylorFeatureMap
|
||||
from fla.ops.based import parallel_based
|
||||
from fla.ops.linear_attn import chunk_linear_attn, fused_chunk_linear_attn
|
||||
|
||||
|
||||
class BasedLinearAttention(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
l_max: int = 2048,
|
||||
feature_dim: int = 16,
|
||||
num_key_value_heads: int = 12,
|
||||
num_heads: int = 12,
|
||||
feature_name: str = "taylor_exp",
|
||||
eps: float = 1e-12,
|
||||
causal: bool = True,
|
||||
mode: str = "parallel",
|
||||
):
|
||||
super().__init__()
|
||||
self.hidden_size
|
||||
self.l_max = l_max
|
||||
self.mode = mode
|
||||
assert self.mode in ["fused_chunk", "parallel", 'chunk']
|
||||
|
||||
# linear attention
|
||||
self.feature_name = feature_name
|
||||
self.feature_dim = feature_dim
|
||||
self.num_key_value_heads = num_key_value_heads
|
||||
self.num_heads = num_heads
|
||||
self.head_dim = self.hidden_size // self.num_key_value_heads
|
||||
self.causal = causal
|
||||
|
||||
self.q_proj = nn.Linear(self.hidden_size, self.feature_dim * self.num_heads, bias=False)
|
||||
self.k_proj = nn.Linear(self.hidden_size, self.feature_dim * self.num_heads, bias=False)
|
||||
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
|
||||
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
|
||||
self.dropout = nn.Identity()
|
||||
self.feature_map = TaylorFeatureMap(feature_dim)
|
||||
self.eps = eps
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(self, hidden_states: torch.Tensor, **kwargs):
|
||||
mode = self.mode
|
||||
q, k, v = self.q_proj(hidden_states), self.k_proj(hidden_states), self.v_proj(hidden_states)
|
||||
q, k, v = map(lambda x: rearrange(x, "b l (h d) -> b h l d", h=self.num_heads), [q, k, v])
|
||||
if mode == "fused_chunk":
|
||||
q, k = self.feature_map(q), self.feature_map(k)
|
||||
o = fused_chunk_linear_attn(q, k, v, normalize=True, scale=1)
|
||||
elif mode == 'chunk':
|
||||
q, k = self.feature_map(q), self.feature_map(k)
|
||||
o = chunk_linear_attn(q, k, v, normalize=True, scale=1)
|
||||
elif mode == 'parallel':
|
||||
assert q.shape[-1] <= 128
|
||||
o = parallel_based(q, k, v, True, True)
|
||||
o = rearrange(o, "b h l d -> b l (h d)")
|
||||
o = self.o_proj(o)
|
||||
o = self.dropout(o)
|
||||
return o
|
||||
|
||||
# https://github.com/HazyResearch/zoology/blob/main/zoology/mixers/based.py#L119
|
||||
|
||||
def forward_reference(self, hidden_states: torch.Tensor, filters: torch.Tensor = None, *args, **kwargs):
|
||||
"""
|
||||
x (torch.Tensor): tensor of shape (b, d, l)
|
||||
y (torch.Tensor): tensor of shape (b, d, l)
|
||||
"""
|
||||
# hidden_states = hidden_states.transpose(1, 2)
|
||||
b, l, _ = hidden_states.size()
|
||||
q, k, v = self.q_proj(hidden_states), self.k_proj(hidden_states), self.v_proj(hidden_states)
|
||||
|
||||
q = q.view(b, l, self.num_heads, self.feature_dim).transpose(1, 2)
|
||||
k = k.view(b, l, self.num_key_value_heads, self.feature_dim).transpose(1, 2)
|
||||
v = v.view(b, l, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
||||
|
||||
# Linear attention
|
||||
q, k = self.feature_map(q), self.feature_map(k)
|
||||
q, k, v = q.unsqueeze(-2), k.unsqueeze(-2), v.unsqueeze(-1)
|
||||
|
||||
# Compute attention
|
||||
if self.causal:
|
||||
y = ((q * (k * v).cumsum(2)).sum(-1) / ((q * k.cumsum(2)).sum(-1) + self.eps))
|
||||
else:
|
||||
y = ((q * (k * v).sum(2, True)).sum(-1) / ((q * k.sum(2, True)).sum(-1) + self.eps))
|
||||
y = rearrange(y, 'b h l d -> b l (h d)')
|
||||
y = self.o_proj(y.to(hidden_states.dtype))
|
||||
y = self.dropout(y)
|
||||
return y.to(hidden_states.dtype)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
batch = 4
|
||||
seq_len = 1024
|
||||
hidden_size = 1024
|
||||
dtype = torch.float32
|
||||
x = torch.randn(batch, seq_len, hidden_size).to(dtype).cuda().requires_grad_(True)
|
||||
dy = torch.randn(batch, seq_len, hidden_size).to(dtype).cuda()
|
||||
model = BasedLinearAttention(hidden_size, mode='chunk').to(dtype).cuda()
|
||||
y = model(x)
|
||||
y.backward(dy, retain_graph=True)
|
||||
x_grad, x.grad = x.grad, None
|
||||
y2 = model.forward_reference(x)
|
||||
y2.backward(dy)
|
||||
assert y.allclose(y2, 0, 1e-4), breakpoint()
|
||||
assert x_grad.allclose(x.grad, 0, 1e-4), breakpoint()
|
||||
print("Pass")
|
||||
254
finetune/lora/v6/fla/layers/delta_net.py
vendored
Normal file
254
finetune/lora/v6/fla/layers/delta_net.py
vendored
Normal file
@ -0,0 +1,254 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Sect4.2 of Linear Transformers Are Secretly Fast Weight Programmers https://arxiv.org/abs/2102.11174
|
||||
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from einops import rearrange
|
||||
from transformers.cache_utils import Cache
|
||||
|
||||
|
||||
from fla.modules import FusedRMSNormSwishGate, RMSNorm, ShortConvolution, LayerNorm
|
||||
from fla.modules.rotary import RotaryEmbedding
|
||||
from fla.ops.delta_rule import (fused_chunk_delta_rule,
|
||||
fused_recurrent_linear_attn_delta_rule,
|
||||
chunk_delta_rule)
|
||||
from torch.nn import functional as F
|
||||
|
||||
|
||||
def simple_norm(x):
|
||||
return (F.normalize(x, dim=-1) * x.shape[-1] ** 0.5).to(x)
|
||||
|
||||
|
||||
# @torch.jit.script
|
||||
def elu_p1(x):
|
||||
return (F.elu(x, 1., False) + 1.).to(x)
|
||||
|
||||
|
||||
# @torch.jit.script
|
||||
def sum_norm(x):
|
||||
return (x / x.sum(-1, keepdim=True)).to(x)
|
||||
|
||||
|
||||
# @torch.jit.script
|
||||
def elu_norm(x):
|
||||
dtype = x.dtype
|
||||
x = F.elu(x, 1., False) + 1.
|
||||
return (x / x.sum(-1, keepdim=True)).to(dtype)
|
||||
|
||||
|
||||
|
||||
|
||||
# https://github.com/IDSIA/recurrent-fwp/blob/master/algorithmic/layers.py#L86C1-L146C1
|
||||
class DeltaNet(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
d_model: int = None,
|
||||
hidden_size: int = 1024,
|
||||
expand_k: float = 1.0,
|
||||
expand_v: float = 1.0,
|
||||
num_heads: int = 4,
|
||||
mode: str = 'fused_chunk',
|
||||
chunk_size: int = 16,
|
||||
use_beta: bool = True,
|
||||
use_gate: bool = True,
|
||||
use_rope: bool = False,
|
||||
use_output_norm: bool = True,
|
||||
use_elu: bool = False,
|
||||
use_short_conv: bool = True,
|
||||
conv_size: int = 4,
|
||||
conv_bias: bool = False,
|
||||
share_conv_kernel: bool = False,
|
||||
layer_idx: int = None,
|
||||
qk_activation: str = 'silu',
|
||||
qk_norm: str = None,
|
||||
save_memory: str = False,
|
||||
**kwargs
|
||||
) -> DeltaNet:
|
||||
super().__init__()
|
||||
self.mode = mode
|
||||
self.qk_activation = qk_activation
|
||||
self.qk_norm = qk_norm
|
||||
assert self.qk_activation in ['silu', 'relu', 'elu', 'identity']
|
||||
assert self.qk_norm in ['l2', 'sum']
|
||||
if d_model is not None:
|
||||
hidden_size = d_model
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.num_heads = num_heads
|
||||
self.chunk_size = chunk_size
|
||||
self.use_gate = use_gate
|
||||
self.use_output_norm = use_output_norm
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.conv_bias = conv_bias
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
|
||||
self.key_dim = int(hidden_size * expand_k)
|
||||
self.value_dim = int(hidden_size * expand_v)
|
||||
self.head_qk_dim = self.key_dim // num_heads
|
||||
self.head_v_dim = self.value_dim // num_heads
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
self.silu = torch.nn.SiLU()
|
||||
|
||||
assert mode in ['chunk', 'fused_chunk', 'fused_recurrent'], f"Not suppoerted mode `{mode}`."
|
||||
assert self.key_dim % num_heads == 0, f"key dim must be divisible by num_heads of {num_heads}"
|
||||
assert self.value_dim % num_heads == 0, f"value dim must be divisible by num_heads of {num_heads}"
|
||||
|
||||
self.q_proj = nn.Linear(hidden_size, self.key_dim, bias=False)
|
||||
self.k_proj = nn.Linear(hidden_size, self.key_dim, bias=False)
|
||||
self.v_proj = nn.Linear(hidden_size, self.value_dim, bias=False)
|
||||
self.o_proj = nn.Linear(self.value_dim, hidden_size, bias=False)
|
||||
|
||||
self.use_beta = use_beta
|
||||
self.use_elu = use_elu
|
||||
if self.use_beta:
|
||||
self.b_proj = nn.Linear(hidden_size, self.num_heads, bias=False)
|
||||
if use_short_conv:
|
||||
self.conv_size = conv_size
|
||||
if share_conv_kernel:
|
||||
self.h_conv1d = ShortConvolution(hidden_size, conv_size, activation=None)
|
||||
else:
|
||||
self.q_conv1d = ShortConvolution(self.key_dim, conv_size, activation='silu' if qk_activation == 'silu' else None)
|
||||
self.k_conv1d = ShortConvolution(self.key_dim, conv_size, activation='silu' if qk_activation == 'silu' else None)
|
||||
self.v_conv1d = ShortConvolution(self.value_dim, conv_size, activation='silu')
|
||||
if use_gate:
|
||||
self.g_proj = nn.Linear(hidden_size, self.value_dim, bias=False)
|
||||
if self.use_gate:
|
||||
self.norm = FusedRMSNormSwishGate(self.head_v_dim)
|
||||
else:
|
||||
self.norm = RMSNorm(self.head_v_dim)
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Cache] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
**kwargs
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
|
||||
|
||||
# change to inference mode.
|
||||
mode = 'fused_recurrent' if hidden_states.shape[1] < 64 else self.mode
|
||||
last_state = past_key_values[self.layer_idx] if use_cache else None
|
||||
|
||||
if attention_mask is not None:
|
||||
if attention_mask.shape[-1] != hidden_states.shape[-2]:
|
||||
attention_mask = attention_mask[:, -1:]
|
||||
|
||||
if self.use_short_conv:
|
||||
conv_state = last_state[0] if use_cache else None
|
||||
if self.share_conv_kernel:
|
||||
# conv state is updated inplace
|
||||
hidden_states = self.h_conv1d(hidden_states, attention_mask, conv_state)
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
else:
|
||||
conv_state_q = last_state[0] if use_cache else None
|
||||
conv_state_k = last_state[1] if use_cache else None
|
||||
conv_state_v = last_state[2] if use_cache else None
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
q = self.q_proj(hidden_states)
|
||||
q = self.q_conv1d(q, attention_mask, conv_state_q)
|
||||
k = self.k_conv1d(k, attention_mask, conv_state_k)
|
||||
v = self.v_conv1d(v, attention_mask, conv_state_v)
|
||||
else:
|
||||
q = (self.q_proj(hidden_states))
|
||||
k = (self.k_proj(hidden_states))
|
||||
v = self.silu(self.v_proj(hidden_states))
|
||||
|
||||
# dealing with left-padding
|
||||
if attention_mask is not None:
|
||||
v = v.mul_(attention_mask.unsqueeze(-1))
|
||||
|
||||
q, k, v = map(lambda x: rearrange(x, 'b l (h d) -> b h l d', h=self.num_heads), (q, k, v))
|
||||
|
||||
if self.qk_activation != 'silu':
|
||||
if self.qk_activation == 'relu':
|
||||
q, k = q.relu(), k.relu()
|
||||
elif self.qk_activation == 'elu':
|
||||
q, k = elu_p1(q), elu_p1(k)
|
||||
elif self.qk_activation == 'identity':
|
||||
pass
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
if self.qk_norm is not None:
|
||||
if self.qk_norm == 'l2':
|
||||
k = torch.nn.functional.normalize(k, dim=-1, p=2).to(v) #auto mixed precision type transfer is annoying.
|
||||
q = torch.nn.functional.normalize(q, dim=-1, p=2).to(v)
|
||||
elif self.qk_norm == 'sum':
|
||||
q = sum_norm(q).to(v)
|
||||
k = sum_norm(k).to(v)
|
||||
|
||||
if self.use_beta:
|
||||
beta = rearrange(self.b_proj(hidden_states), 'b l h -> b h l').sigmoid()
|
||||
else:
|
||||
beta = q.new_ones(q.shape[0], q.shape[1], q.shape[2])
|
||||
state = past_key_values[self.layer_idx][-1] if use_cache else None
|
||||
if mode == 'fused_recurrent':
|
||||
o, recurrent_state = fused_recurrent_linear_attn_delta_rule(q, k, v, beta, state, output_final_state=use_cache)
|
||||
elif mode == 'fused_chunk':
|
||||
assert self.chunk_size in [16, 32, 64]
|
||||
o, recurrent_state = fused_chunk_delta_rule(q, k, v, beta, self.chunk_size, state, output_final_state=use_cache)
|
||||
elif mode == 'chunk':
|
||||
assert self.chunk_size in [16, 32, 64]
|
||||
o, recurrent_state = chunk_delta_rule(q, k, v, beta, self.chunk_size, state, output_final_state=use_cache)
|
||||
else:
|
||||
raise NotImplementedError(f"Not supported mode `{mode}`.")
|
||||
|
||||
if past_key_values is not None:
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
state = (conv_state, recurrent_state)
|
||||
else:
|
||||
state = (conv_state_q, conv_state_k, conv_state_v, recurrent_state)
|
||||
else:
|
||||
state = (recurrent_state,)
|
||||
past_key_values.update(state, self.layer_idx)
|
||||
|
||||
o = rearrange(o, 'b h l d -> b l h d')
|
||||
if self.use_gate:
|
||||
g = rearrange(self.g_proj(hidden_states), 'b l (h d) -> b l h d', h=self.num_heads)
|
||||
o = self.norm(o, g)
|
||||
else:
|
||||
o = self.norm(o)
|
||||
o = rearrange(o, 'b l h d -> b l (h d)')
|
||||
o = self.o_proj(o)
|
||||
|
||||
return o, None, past_key_values
|
||||
|
||||
def init_state(self, batch_size: int) -> Tuple[torch.Tensor]:
|
||||
param = next(self.parameters())
|
||||
state = tuple()
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
state += (param.new_zeros(batch_size, self.hidden_size, self.conv_size),)
|
||||
else:
|
||||
# for q/k/v each
|
||||
state += (param.new_zeros(batch_size, self.key_dim, self.conv_size),
|
||||
param.new_zeros(batch_size, self.key_dim, self.conv_size),
|
||||
param.new_zeros(batch_size, self.value_dim, self.conv_size))
|
||||
state += (param.new_zeros(batch_size, self.num_heads, self.head_qk_dim, self.head_v_dim),)
|
||||
return state
|
||||
234
finetune/lora/v6/fla/layers/gated_abc.py
vendored
Normal file
234
finetune/lora/v6/fla/layers/gated_abc.py
vendored
Normal file
@ -0,0 +1,234 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import warnings
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from einops import rearrange, repeat
|
||||
from transformers.cache_utils import Cache
|
||||
|
||||
from fla.modules import (FusedRMSNormSwishGateLinear, RMSNormLinear,
|
||||
RotaryEmbedding, ShortConvolution)
|
||||
from fla.modules.activations import ACT2FN, swiglu_linear, swish
|
||||
from fla.ops.abc.chunk_gate import chunk_gated_abc
|
||||
|
||||
|
||||
class GatedABCAttention(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int = 1024,
|
||||
expand_k: float = 1.,
|
||||
expand_v: float = 1.,
|
||||
num_heads: int = 4,
|
||||
num_kv_heads: Optional[int] = None,
|
||||
use_short_conv: bool = False,
|
||||
conv_size: int = 4,
|
||||
conv_bias: bool = False,
|
||||
share_conv_kernel: bool = True,
|
||||
num_slots: Optional[int] = None,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-5,
|
||||
gate_low_rank_dim: Optional[int] = None,
|
||||
gate_logit_normalizer: int = 16,
|
||||
feature_map: str = 'swish',
|
||||
use_rope: bool = False,
|
||||
use_output_gate: bool = False,
|
||||
use_norm: bool = True,
|
||||
layer_idx: Optional[int] = None,
|
||||
**kwargs
|
||||
) -> GatedABCAttention:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.num_heads = num_heads
|
||||
self.num_kv_heads = num_heads if num_kv_heads is None else num_kv_heads
|
||||
self.num_kv_groups = self.num_heads // self.num_kv_heads
|
||||
self.key_dim = int(hidden_size * expand_k)
|
||||
self.value_dim = int(hidden_size * expand_v)
|
||||
self.key_dim_per_group = self.key_dim // self.num_kv_groups
|
||||
self.value_dim_per_group = self.value_dim // self.num_kv_groups
|
||||
self.head_k_dim = self.key_dim // self.num_heads
|
||||
self.head_v_dim = self.value_dim // self.num_heads
|
||||
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.conv_bias = conv_bias
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
|
||||
if gate_low_rank_dim is None:
|
||||
gate_low_rank_dim = self.hidden_size // 16
|
||||
self.gate_low_rank_dim = gate_low_rank_dim
|
||||
self.gate_logit_normalizer = gate_logit_normalizer
|
||||
|
||||
self.feature_map = feature_map
|
||||
self.use_rope = use_rope
|
||||
self.use_output_gate = use_output_gate
|
||||
self.use_norm = use_norm
|
||||
|
||||
if num_slots is None:
|
||||
num_slots = self.head_k_dim
|
||||
self.num_slots = num_slots
|
||||
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
if layer_idx is None:
|
||||
warnings.warn(
|
||||
f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will "
|
||||
"to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` "
|
||||
"when creating this class."
|
||||
)
|
||||
|
||||
self.q_proj = nn.Linear(self.hidden_size, self.key_dim, bias=False)
|
||||
self.k_proj = nn.Linear(self.hidden_size, self.key_dim_per_group, bias=False)
|
||||
self.v_proj = nn.Linear(self.hidden_size, self.value_dim_per_group, bias=False)
|
||||
self.f_proj = nn.Linear(self.hidden_size, self.num_kv_heads * self.num_slots, bias=False)
|
||||
|
||||
if use_output_gate:
|
||||
self.g_proj = nn.Linear(hidden_size, self.value_dim, bias=False)
|
||||
|
||||
if use_short_conv:
|
||||
self.conv_size = conv_size
|
||||
if share_conv_kernel:
|
||||
self.h_conv1d = ShortConvolution(hidden_size, conv_size, activation='silu')
|
||||
else:
|
||||
self.q_conv1d = ShortConvolution(self.key_dim, conv_size, activation='silu')
|
||||
self.k_conv1d = ShortConvolution(self.key_dim_per_group, conv_size, activation='silu')
|
||||
self.v_conv1d = ShortConvolution(self.value_dim_per_group, conv_size, activation='silu')
|
||||
|
||||
if self.use_norm:
|
||||
if self.use_output_gate:
|
||||
self.g_norm = FusedRMSNormSwishGateLinear(self.hidden_size, elementwise_affine, norm_eps)
|
||||
else:
|
||||
self.g_norm = RMSNormLinear(self.hidden_size, elementwise_affine, norm_eps)
|
||||
self.o_proj = nn.Linear(self.value_dim, self.hidden_size, bias=False)
|
||||
|
||||
if self.use_rope:
|
||||
self.rotary = RotaryEmbedding(self.head_k_dim)
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Cache] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
lower_bound: Optional[torch.Tensor] = None,
|
||||
**kwargs
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
|
||||
|
||||
last_state = past_key_values[self.layer_idx] if use_cache else None
|
||||
if self.use_short_conv:
|
||||
conv_state = last_state[0] if use_cache else None
|
||||
if self.share_conv_kernel:
|
||||
# conv state is updated inplace
|
||||
hidden_states = self.h_conv1d(hidden_states, attention_mask, conv_state)
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
else:
|
||||
conv_state_q = last_state[0] if use_cache else None
|
||||
conv_state_k = last_state[1] if use_cache else None
|
||||
conv_state_v = last_state[2] if use_cache else None
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
q = self.q_conv1d(q, attention_mask, conv_state_q)
|
||||
k = self.k_conv1d(k, attention_mask, conv_state_k)
|
||||
v = self.v_conv1d(v, attention_mask, conv_state_v)
|
||||
else:
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
f = self.f_proj(hidden_states)
|
||||
|
||||
if self.use_rope:
|
||||
q = rearrange(q, '... (h d) -> ... h d', h=self.num_heads)
|
||||
k = rearrange(k, '... (h d) -> ... h d', h=self.num_kv_heads)
|
||||
seqlen_offset = 0
|
||||
if past_key_values is not None:
|
||||
seqlen_offset = past_key_values.get_seq_length(self.layer_idx)
|
||||
q, k = self.rotary(q, k, seqlen_offset)
|
||||
q = rearrange(q, 'b n h d -> b h n d', h=self.num_heads)
|
||||
k = rearrange(k, 'b n h d -> b h n d', h=self.num_kv_heads)
|
||||
else:
|
||||
q = rearrange(q, 'b n (h d) -> b h n d', h=self.num_heads)
|
||||
if self.num_kv_groups > 1:
|
||||
k = repeat(k, 'b n (h d) -> b (h g) n d', h=self.num_kv_heads, g=self.num_kv_groups)
|
||||
else:
|
||||
k = rearrange(k, 'b n (h d) -> b h n d', h=self.num_kv_heads)
|
||||
if self.num_kv_groups > 1:
|
||||
v = repeat(v, 'b n (h d) -> b (h g) n d', h=self.num_kv_heads, g=self.num_kv_groups)
|
||||
f = repeat(f, 'b n (h m) -> b (h g) n m', h=self.num_kv_heads, g=self.num_kv_groups)
|
||||
else:
|
||||
v = rearrange(v, 'b n (h d) -> b h n d', h=self.num_kv_heads)
|
||||
f = rearrange(f, 'b n (h m) -> b h n m', h=self.num_kv_heads)
|
||||
|
||||
if self.feature_map is not None:
|
||||
q, k, v = map(lambda x: ACT2FN[self.feature_map](x), (q, k, v))
|
||||
f = F.logsigmoid(f) / self.gate_logit_normalizer
|
||||
s = (1 - f.exp()).to(f.dtype)
|
||||
# dealing with left-padding
|
||||
if attention_mask is not None:
|
||||
s = s.mul_(attention_mask.view(attention_mask.shape[0], 1, -1, 1))
|
||||
v = v.mul_(attention_mask.view(attention_mask.shape[0], 1, -1, 1))
|
||||
|
||||
recurrent_state = last_state[-2:] if use_cache else None
|
||||
o, recurrent_state = chunk_gated_abc(q, k, v, s, f,
|
||||
initial_state=recurrent_state,
|
||||
output_final_state=use_cache)
|
||||
if past_key_values is not None:
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
last_state = (conv_state,) + recurrent_state
|
||||
else:
|
||||
last_state = (conv_state_q, conv_state_k, conv_state_v) + recurrent_state
|
||||
else:
|
||||
last_state = recurrent_state
|
||||
past_key_values.update(last_state, self.layer_idx, q.shape[2])
|
||||
|
||||
o = rearrange(o, 'b h t d -> b t (h d)')
|
||||
if self.use_norm and not self.use_output_gate:
|
||||
o = swish(o)
|
||||
o = self.g_norm(o, self.o_proj.weight, self.o_proj.bias)
|
||||
elif self.use_output_gate and not self.use_norm:
|
||||
o = swiglu_linear(self.g_proj(hidden_states), o, self.o_proj.weight, self.o_proj.bias)
|
||||
elif self.use_output_gate and self.use_norm:
|
||||
o = self.g_norm(o, self.g_proj(hidden_states), self.o_proj.weight, self.o_proj.bias)
|
||||
else:
|
||||
o = self.o_proj(o)
|
||||
return o, None, past_key_values
|
||||
|
||||
def init_state(self, batch_size: int) -> Tuple[torch.Tensor]:
|
||||
param = next(self.parameters())
|
||||
state = tuple()
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
state += (param.new_zeros(batch_size, self.hidden_size, self.conv_size),)
|
||||
else:
|
||||
state += (param.new_zeros(batch_size, self.key_dim, self.conv_size),
|
||||
param.new_zeros(batch_size, self.key_dim, self.conv_size),
|
||||
param.new_zeros(batch_size, self.value_dim, self.conv_size))
|
||||
state += (param.new_zeros(batch_size, self.num_heads, self.head_k_dim, self.num_slots),
|
||||
param.new_zeros(batch_size, self.num_heads, self.num_slots, self.head_v_dim))
|
||||
return state
|
||||
|
||||
def state_size(self, sequence_length: int = 2048):
|
||||
return self.num_heads * self.key_dim * self.head_v_dim
|
||||
268
finetune/lora/v6/fla/layers/gla.py
vendored
Normal file
268
finetune/lora/v6/fla/layers/gla.py
vendored
Normal file
@ -0,0 +1,268 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from einops import rearrange, repeat
|
||||
from transformers.cache_utils import Cache
|
||||
|
||||
from fla.modules import FusedRMSNormSwishGate, RMSNorm, ShortConvolution
|
||||
from fla.modules.activations import ACT2FN
|
||||
from fla.ops.gla import chunk_gla, fused_chunk_gla, fused_recurrent_gla
|
||||
|
||||
|
||||
class GatedLinearAttention(nn.Module):
|
||||
r"""
|
||||
The layer implementaion for [Gated Linear Attention Transformers with Hardware-Efficient Training](https://arxiv.org/abs/2312.06635). # noqa
|
||||
|
||||
Args:
|
||||
mode (str, Optional):
|
||||
Which GLA kernel to use.
|
||||
Currently available: `chunk`, `fused_recurrent`, and `fused_chunk`.
|
||||
Default: `chunk`.
|
||||
hidden_size (int, Optional):
|
||||
The hidden size of the input. Default: 1024.
|
||||
expand_k (float, Optional):
|
||||
The expansion ratio for the key dim. Default: 0.5.
|
||||
expand_v (float, Optional):
|
||||
The expansion ratio for the value dim. Default: 1.0.
|
||||
num_heads (int, Optional):
|
||||
The number of heads. Default: 4.
|
||||
num_kv_heads (int, Optional):
|
||||
The number of key/value heads, used for MQA. Default: None.
|
||||
feature_map (str, Optional):
|
||||
Feature map function applied to queries/keys. Default: None.
|
||||
use_short_conv (bool, Optional):
|
||||
Whether to use short convolutions. Default: `False`.
|
||||
conv_size (int, Optional):
|
||||
The kernel size of the short convolution, only used when `use_short_conv` is `True`. Default: 4.
|
||||
conv_bias (bool, Optional):
|
||||
Whether to use bias in the short convolution, only used when `use_short_conv` is `True`. Default: `False`.
|
||||
share_conv_kernel (bool, Optional):
|
||||
Whether to apply convolutions berfore q/k/v mapping, only taking effects when `use_short_conv`. Default: `True`.
|
||||
use_output_gate (bool, Optional):
|
||||
Whether to use output gate. Default: `True`.
|
||||
gate_fn (str, Optional):
|
||||
The activation function for the output gate. Default: `swish`.
|
||||
elementwise_affine (bool, Optional):
|
||||
If `True`, applies elementwise affine to LayerNorm with learnable parameters. Default: `True`.
|
||||
norm_eps (float, Optional):
|
||||
The epsilon value for the layernorm/rmsnorm layer. Default: 1e-5.
|
||||
gate_logit_normalizer (int, Optional):
|
||||
The normalizer for the gate logits, appied after `logsigmoid`. Default: 16.
|
||||
gate_low_rank_dim (int, Optional):
|
||||
The low rank dim for the gate projection. Default: 16.
|
||||
clamp_min (float, Optional):
|
||||
The minimum value for the gate logits. Default: None.
|
||||
fuse_norm (bool, Optional):
|
||||
Whether to fuse the norm and the output gate for better memory footprint. Default: `True`.
|
||||
layer_idx (int, Optional):
|
||||
The index of the layer. Default: None.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
mode: str = 'chunk',
|
||||
hidden_size: int = 1024,
|
||||
expand_k: float = 0.5,
|
||||
expand_v: float = 1.0,
|
||||
num_heads: int = 4,
|
||||
num_kv_heads: Optional[int] = None,
|
||||
feature_map: Optional[str] = None,
|
||||
use_short_conv: bool = False,
|
||||
conv_size: int = 4,
|
||||
conv_bias: bool = False,
|
||||
share_conv_kernel: bool = True,
|
||||
use_output_gate: bool = True,
|
||||
gate_fn: str = 'swish',
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-5,
|
||||
gate_logit_normalizer: int = 16,
|
||||
gate_low_rank_dim: int = 16,
|
||||
clamp_min: Optional[float] = None,
|
||||
fuse_norm: bool = True,
|
||||
layer_idx: int = None,
|
||||
) -> GatedLinearAttention:
|
||||
super().__init__()
|
||||
|
||||
self.mode = mode
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.num_heads = num_heads
|
||||
self.num_kv_heads = num_kv_heads if num_kv_heads is not None else num_heads
|
||||
self.num_kv_groups = self.num_heads // self.num_kv_heads
|
||||
self.feature_map_fn = ACT2FN[feature_map] if feature_map is not None else None
|
||||
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.conv_bias = conv_bias
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
self.use_output_gate = use_output_gate
|
||||
|
||||
self.key_dim = int(hidden_size * expand_k)
|
||||
self.value_dim = int(hidden_size * expand_v)
|
||||
self.key_dim_per_group = self.key_dim // self.num_kv_groups
|
||||
self.value_dim_per_group = self.value_dim // self.num_kv_groups
|
||||
self.clamp_min = clamp_min
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
assert mode in ['chunk', 'fused_recurrent', 'fused_chunk'], f"Not suppoerted mode `{mode}`."
|
||||
assert self.key_dim % num_heads == 0, f"key dim must be divisible by num_heads of {num_heads}"
|
||||
assert self.value_dim % num_heads == 0, f"value dim must be divisible by num_heads of {num_heads}"
|
||||
|
||||
self.head_qk_dim = self.key_dim // num_heads
|
||||
self.head_v_dim = self.value_dim // num_heads
|
||||
|
||||
self.q_proj = nn.Linear(hidden_size, self.key_dim, bias=False)
|
||||
self.k_proj = nn.Linear(hidden_size, self.key_dim_per_group, bias=False)
|
||||
self.v_proj = nn.Linear(hidden_size, self.value_dim_per_group, bias=False)
|
||||
if self.use_output_gate:
|
||||
self.g_proj = nn.Linear(hidden_size, self.value_dim, bias=False)
|
||||
|
||||
if use_short_conv:
|
||||
self.conv_size = conv_size
|
||||
if share_conv_kernel:
|
||||
self.h_conv1d = ShortConvolution(hidden_size, conv_size, activation='silu')
|
||||
else:
|
||||
self.q_conv1d = ShortConvolution(self.key_dim, conv_size, activation='silu')
|
||||
self.k_conv1d = ShortConvolution(self.key_dim_per_group, conv_size, activation='silu')
|
||||
self.v_conv1d = ShortConvolution(self.value_dim_per_group, conv_size, activation='silu')
|
||||
|
||||
self.gk_proj = nn.Sequential(nn.Linear(hidden_size, gate_low_rank_dim, bias=False),
|
||||
nn.Linear(gate_low_rank_dim, self.key_dim_per_group, bias=True))
|
||||
self.o_proj = nn.Linear(self.value_dim, hidden_size, bias=False)
|
||||
|
||||
if gate_fn == 'swish' and fuse_norm and use_output_gate:
|
||||
self.g_norm_swish_gate = FusedRMSNormSwishGate(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
self.fuse_norm_and_gate = True
|
||||
else:
|
||||
self.fuse_norm_and_gate = False
|
||||
self.g_norm = RMSNorm(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
self.gate_fn = ACT2FN[gate_fn]
|
||||
|
||||
self.gate_logit_normalizer = gate_logit_normalizer
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Cache] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
**kwargs
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
|
||||
# launching the triton kernel for just one token will actually be slower
|
||||
mode = 'fused_recurrent' if hidden_states.shape[1] == 1 else self.mode
|
||||
|
||||
last_state = past_key_values[self.layer_idx] if use_cache else None
|
||||
if self.use_short_conv:
|
||||
conv_state = last_state[0] if use_cache else None
|
||||
if self.share_conv_kernel:
|
||||
# conv state is updated inplace
|
||||
hidden_states = self.h_conv1d(hidden_states, attention_mask, conv_state)
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
else:
|
||||
conv_state_q = last_state[0] if use_cache else None
|
||||
conv_state_k = last_state[1] if use_cache else None
|
||||
conv_state_v = last_state[2] if use_cache else None
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
q = self.q_conv1d(q, attention_mask, conv_state_q)
|
||||
k = self.k_conv1d(k, attention_mask, conv_state_k)
|
||||
v = self.v_conv1d(v, attention_mask, conv_state_v)
|
||||
else:
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
gk = self.gk_proj(hidden_states)
|
||||
|
||||
if self.feature_map_fn is not None:
|
||||
q, k = map(self.feature_map_fn, (q, k))
|
||||
# dealing with left-padding
|
||||
if attention_mask is not None:
|
||||
v = v.mul_(attention_mask.unsqueeze(-1))
|
||||
q = rearrange(q, 'b l (h d) -> b h l d', h=self.num_heads)
|
||||
if self.num_kv_groups > 1:
|
||||
k, v, gk = (repeat(x, 'b l (h d) -> b (h g) l d', h=self.num_kv_heads, g=self.num_kv_groups) for x in (k, v, gk))
|
||||
else:
|
||||
k, v, gk = (rearrange(x, 'b l (h d) -> b h l d', h=self.num_kv_heads) for x in (k, v, gk))
|
||||
gk = F.logsigmoid(gk) / self.gate_logit_normalizer
|
||||
|
||||
if self.clamp_min is not None:
|
||||
gk = torch.clamp_min(gk, self.clamp_min)
|
||||
|
||||
recurrent_state = last_state[-1] if use_cache else None
|
||||
if mode == 'fused_recurrent':
|
||||
o, recurrent_state = fused_recurrent_gla(q, k, v, gk, initial_state=recurrent_state, output_final_state=use_cache)
|
||||
elif mode == 'fused_chunk':
|
||||
o, recurrent_state = fused_chunk_gla(q, k, v, gk, initial_state=recurrent_state, output_final_state=use_cache)
|
||||
elif mode == 'chunk':
|
||||
o, recurrent_state = chunk_gla(q, k, v, gk, initial_state=recurrent_state, output_final_state=use_cache)
|
||||
else:
|
||||
raise NotImplementedError(f"Not supported mode `{mode}`.")
|
||||
|
||||
if past_key_values is not None:
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
last_state = (conv_state, recurrent_state)
|
||||
else:
|
||||
last_state = (conv_state_q, conv_state_k, conv_state_v, recurrent_state)
|
||||
else:
|
||||
last_state = (recurrent_state,)
|
||||
past_key_values.update(last_state, self.layer_idx, q.shape[2])
|
||||
|
||||
o = rearrange(o, 'b h l d -> b l h d')
|
||||
if self.use_output_gate:
|
||||
g = self.g_proj(hidden_states)
|
||||
if self.fuse_norm_and_gate:
|
||||
g = rearrange(g, 'b l (h d) -> b l h d', h=self.num_heads)
|
||||
o = self.g_norm_swish_gate(o, g)
|
||||
o = rearrange(o, 'b l h d -> b l (h d)')
|
||||
else:
|
||||
o = rearrange(self.g_norm(o), 'b l h d -> b l (h d)')
|
||||
o = o * self.gate_fn(g)
|
||||
else:
|
||||
o = rearrange(self.g_norm(o), 'b l h d -> b l (h d)')
|
||||
o = self.o_proj(o)
|
||||
|
||||
return o, None, past_key_values
|
||||
|
||||
def init_state(self, batch_size: int) -> Tuple[torch.Tensor]:
|
||||
param = next(self.parameters())
|
||||
state = tuple()
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
state += (param.new_zeros(batch_size, self.hidden_size, self.conv_size),)
|
||||
else:
|
||||
state += (param.new_zeros(batch_size, self.key_dim, self.conv_size),
|
||||
param.new_zeros(batch_size, self.key_dim, self.conv_size),
|
||||
param.new_zeros(batch_size, self.value_dim, self.conv_size))
|
||||
state += (param.new_zeros(batch_size, self.num_heads, self.head_qk_dim, self.head_v_dim),)
|
||||
return state
|
||||
|
||||
def state_size(self, **kwargs) -> int:
|
||||
state_size = self.key_dim * self.head_v_dim
|
||||
for module in self.children():
|
||||
if isinstance(module, ShortConvolution):
|
||||
state_size += module.state_size
|
||||
return state_size
|
||||
165
finetune/lora/v6/fla/layers/hgrn.py
vendored
Normal file
165
finetune/lora/v6/fla/layers/hgrn.py
vendored
Normal file
@ -0,0 +1,165 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# "Hierarchically Gated Recurrent Neural Network for Sequence Modeling" [https://arxiv.org/abs/2311.04823]
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from einops import rearrange
|
||||
from transformers.cache_utils import Cache
|
||||
|
||||
from fla.modules import FusedRMSNormSwishGate, ShortConvolution
|
||||
from fla.modules.activations import swiglu
|
||||
from fla.ops.hgrn import chunk_hgrn, fused_recurrent_hgrn
|
||||
|
||||
|
||||
class HGRNAttention(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
mode: str = 'chunk',
|
||||
hidden_size: int = 1024,
|
||||
num_heads: Optional[int] = None,
|
||||
expand_ratio: Optional[int] = 1,
|
||||
use_short_conv: bool = False,
|
||||
conv_size: int = 4,
|
||||
conv_bias: bool = False,
|
||||
share_conv_kernel: bool = True,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-5,
|
||||
layer_idx: int = None
|
||||
) -> HGRNAttention:
|
||||
super().__init__()
|
||||
|
||||
self.mode = mode
|
||||
self.hidden_size = hidden_size
|
||||
self.num_heads = num_heads
|
||||
self.expand_ratio = expand_ratio
|
||||
self.input_dim = int(hidden_size * expand_ratio)
|
||||
self.head_dim = self.input_dim // self.num_heads
|
||||
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.conv_bias = conv_bias
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
assert mode in ['chunk', 'fused_recurrent'], f"Not suppoerted mode `{mode}`."
|
||||
assert self.hidden_size % num_heads == 0, f"hidden size must be divisible by num_heads of {num_heads}"
|
||||
|
||||
self.i_proj = nn.Linear(hidden_size, self.input_dim, bias=False)
|
||||
self.f_proj = nn.Linear(hidden_size, self.input_dim, bias=False)
|
||||
self.g_proj = nn.Linear(hidden_size, self.input_dim, bias=False)
|
||||
|
||||
if use_short_conv:
|
||||
self.conv_size = conv_size
|
||||
if share_conv_kernel:
|
||||
self.h_conv1d = ShortConvolution(hidden_size, conv_size, activation='silu')
|
||||
else:
|
||||
self.q_conv1d = ShortConvolution(self.input_dim, conv_size, activation='silu')
|
||||
self.f_conv1d = ShortConvolution(self.input_dim, conv_size, activation='silu')
|
||||
self.i_conv1d = ShortConvolution(self.input_dim, conv_size, activation='silu')
|
||||
|
||||
self.g_norm = FusedRMSNormSwishGate(self.input_dim, elementwise_affine, norm_eps)
|
||||
self.o_proj = nn.Linear(self.input_dim, hidden_size, bias=False)
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Cache] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
lower_bound: Optional[torch.Tensor] = None,
|
||||
**kwargs
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
|
||||
# launching the triton kernel for just one token will actually be slower
|
||||
mode = 'fused_recurrent' if hidden_states.shape[1] == 1 else self.mode
|
||||
|
||||
last_state = past_key_values[self.layer_idx] if use_cache else None
|
||||
if self.use_short_conv:
|
||||
conv_state = last_state[0] if use_cache else None
|
||||
if self.share_conv_kernel:
|
||||
# conv state is updated inplace
|
||||
hidden_states = self.h_conv1d(hidden_states, attention_mask, conv_state)
|
||||
i = self.i_proj(hidden_states)
|
||||
f = self.f_proj(hidden_states)
|
||||
else:
|
||||
conv_state_i = last_state[2] if use_cache else None
|
||||
conv_state_f = last_state[1] if use_cache else None
|
||||
i = self.i_conv1d(self.i_proj(hidden_states), attention_mask, conv_state_i)
|
||||
f = self.f_conv1d(self.f_proj(hidden_states), attention_mask, conv_state_f)
|
||||
else:
|
||||
i = self.i_proj(hidden_states)
|
||||
f = self.f_proj(hidden_states)
|
||||
|
||||
# the lower bound for the first layer is zero
|
||||
if lower_bound is None or self.layer_idx == 0:
|
||||
i, f = swiglu(i, 1 - f.sigmoid()), F.logsigmoid(f)
|
||||
else:
|
||||
g = lower_bound + (1 - lower_bound) * f.sigmoid()
|
||||
i, f = swiglu(i, 1 - g), g.log()
|
||||
|
||||
# dealing with left-padding
|
||||
if attention_mask is not None:
|
||||
i = i.mul_(attention_mask.unsqueeze(-1))
|
||||
i, f = map(lambda x: rearrange(x, 'b l (h d) -> b h l d', h=self.num_heads), (i, f))
|
||||
|
||||
recurrent_state = last_state[-1] if use_cache else None
|
||||
if mode == 'chunk':
|
||||
o, recurrent_state = chunk_hgrn(i, f, initial_state=recurrent_state, output_final_state=use_cache)
|
||||
elif mode == 'fused_recurrent':
|
||||
o, recurrent_state = fused_recurrent_hgrn(i, f, initial_state=recurrent_state, output_final_state=use_cache)
|
||||
else:
|
||||
raise NotImplementedError(f"Not supported mode `{mode}`.")
|
||||
|
||||
if past_key_values is not None:
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
last_state = (conv_state, recurrent_state)
|
||||
else:
|
||||
last_state = (conv_state_i, conv_state_f, recurrent_state)
|
||||
else:
|
||||
last_state = (recurrent_state,)
|
||||
past_key_values.update(last_state, self.layer_idx, i.shape[2])
|
||||
|
||||
o = self.g_norm(self.g_proj(hidden_states), rearrange(o, 'b h l d -> b l (h d)'))
|
||||
o = self.o_proj(o)
|
||||
|
||||
return o, None, past_key_values
|
||||
|
||||
def init_state(self, batch_size: int) -> Tuple[torch.Tensor]:
|
||||
param = next(self.parameters())
|
||||
state = tuple()
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
state += (param.new_zeros(batch_size, self.hidden_size, self.conv_size),)
|
||||
else:
|
||||
state += (param.new_zeros(batch_size, self.hidden_size, self.conv_size),
|
||||
param.new_zeros(batch_size, self.hidden_size, self.conv_size),
|
||||
param.new_zeros(batch_size, self.hidden_size, self.conv_size))
|
||||
state += (param.new_zeros(batch_size, self.num_heads, self.head_dim),)
|
||||
return state
|
||||
|
||||
def state_size(self, **kwargs) -> int:
|
||||
state_size = self.hidden_size
|
||||
for module in self.children():
|
||||
if isinstance(module, ShortConvolution):
|
||||
state_size += module.state_size
|
||||
return state_size
|
||||
186
finetune/lora/v6/fla/layers/hgrn2.py
vendored
Normal file
186
finetune/lora/v6/fla/layers/hgrn2.py
vendored
Normal file
@ -0,0 +1,186 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# "HGRN2: Gated Linear RNNs with State Expansion"[https://arxiv.org/abs/2404.07904]
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from einops import rearrange
|
||||
from transformers.cache_utils import Cache
|
||||
|
||||
from fla.modules import RMSNorm, ShortConvolution
|
||||
from fla.modules.activations import swish
|
||||
from fla.ops.gla import chunk_gla, fused_chunk_gla, fused_recurrent_gla
|
||||
|
||||
|
||||
class HGRN2Attention(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
mode: str = 'chunk',
|
||||
hidden_size: int = 1024,
|
||||
num_heads: Optional[int] = None,
|
||||
expand_ratio: Optional[int] = 128,
|
||||
use_short_conv: bool = False,
|
||||
conv_size: int = 4,
|
||||
conv_bias: bool = False,
|
||||
share_conv_kernel: bool = True,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-5,
|
||||
layer_idx: int = None
|
||||
) -> HGRN2Attention:
|
||||
super().__init__()
|
||||
|
||||
self.mode = mode
|
||||
self.hidden_size = hidden_size
|
||||
|
||||
if expand_ratio is None and num_heads is not None:
|
||||
expand_ratio = hidden_size // num_heads
|
||||
elif expand_ratio is not None and num_heads is None:
|
||||
num_heads = hidden_size // expand_ratio
|
||||
else:
|
||||
raise RuntimeError("One of `expand_ratio` or `num_heads` should be provided.")
|
||||
self.num_heads = num_heads
|
||||
self.expand_ratio = expand_ratio
|
||||
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.conv_bias = conv_bias
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
|
||||
self.forget_dim = int(self.num_heads * self.expand_ratio)
|
||||
self.input_dim = hidden_size
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
assert mode in ['chunk', 'fused_recurrent', 'fused_chunk'], f"Not suppoerted mode `{mode}`."
|
||||
assert self.forget_dim % num_heads == 0, f"forget dim must be divisible by num_heads of {num_heads}"
|
||||
assert self.input_dim % num_heads == 0, f"input dim must be divisible by num_heads of {num_heads}"
|
||||
|
||||
self.head_f_dim = self.expand_ratio
|
||||
self.head_i_dim = self.hidden_size // num_heads
|
||||
|
||||
self.q_proj = nn.Linear(hidden_size, self.forget_dim, bias=False)
|
||||
self.f_proj = nn.Linear(hidden_size, self.forget_dim, bias=False)
|
||||
self.i_proj = nn.Linear(hidden_size, self.input_dim, bias=False)
|
||||
|
||||
if use_short_conv:
|
||||
self.conv_size = conv_size
|
||||
if share_conv_kernel:
|
||||
self.h_conv1d = ShortConvolution(hidden_size, conv_size, activation='silu')
|
||||
else:
|
||||
self.q_conv1d = ShortConvolution(self.forget_dim, conv_size, activation='silu')
|
||||
self.f_conv1d = ShortConvolution(self.forget_dim, conv_size, activation='silu')
|
||||
self.i_conv1d = ShortConvolution(self.input_dim, conv_size, activation='silu')
|
||||
|
||||
self.g_norm = RMSNorm(self.hidden_size, elementwise_affine, norm_eps)
|
||||
self.o_proj = nn.Linear(self.input_dim, hidden_size, bias=False)
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Cache] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
lower_bound: Optional[torch.Tensor] = None,
|
||||
**kwargs
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
|
||||
# launching the triton kernel for just one token will actually be slower
|
||||
mode = 'fused_recurrent' if hidden_states.shape[1] == 1 else self.mode
|
||||
|
||||
last_state = past_key_values[self.layer_idx] if use_cache else None
|
||||
if self.use_short_conv:
|
||||
conv_state = last_state[0] if use_cache else None
|
||||
if self.share_conv_kernel:
|
||||
# conv state is updated inplace
|
||||
hidden_states = self.h_conv1d(hidden_states, attention_mask, conv_state)
|
||||
q = self.q_proj(hidden_states)
|
||||
f = self.f_proj(hidden_states)
|
||||
i = self.i_proj(hidden_states)
|
||||
else:
|
||||
conv_state_q = last_state[0] if use_cache else None
|
||||
conv_state_f = last_state[1] if use_cache else None
|
||||
conv_state_i = last_state[2] if use_cache else None
|
||||
q = self.q_proj(hidden_states)
|
||||
f = self.f_proj(hidden_states)
|
||||
i = self.i_proj(hidden_states)
|
||||
q = self.q_conv1d(q, attention_mask, conv_state_q)
|
||||
f = self.f_conv1d(f, attention_mask, conv_state_f)
|
||||
i = self.i_conv1d(i, attention_mask, conv_state_i)
|
||||
else:
|
||||
q = self.q_proj(hidden_states)
|
||||
f = self.f_proj(hidden_states)
|
||||
i = self.i_proj(hidden_states)
|
||||
|
||||
# dealing with left-padding
|
||||
if attention_mask is not None:
|
||||
i = i.mul_(attention_mask.unsqueeze(-1))
|
||||
|
||||
q = swish(q)
|
||||
# the lower bound for the first layer is zero
|
||||
if lower_bound is None or self.layer_idx == 0:
|
||||
k, g = 1 - f.sigmoid(), F.logsigmoid(f)
|
||||
else:
|
||||
g = lower_bound + (1 - lower_bound) * f.sigmoid()
|
||||
k, g = 1 - g, g.log()
|
||||
q, k, i, g = map(lambda x: rearrange(x, 'b l (h d) -> b h l d', h=self.num_heads), (q, k, i, g))
|
||||
|
||||
recurrent_state = last_state[-1] if use_cache else None
|
||||
if mode == 'fused_recurrent':
|
||||
o, recurrent_state = fused_recurrent_gla(q, k, i, g, initial_state=recurrent_state, output_final_state=use_cache)
|
||||
elif mode == 'fused_chunk':
|
||||
o, recurrent_state = fused_chunk_gla(q, k, i, g, initial_state=recurrent_state, output_final_state=use_cache)
|
||||
elif mode == 'chunk':
|
||||
o, recurrent_state = chunk_gla(q, k, i, g, initial_state=recurrent_state, output_final_state=use_cache)
|
||||
else:
|
||||
raise NotImplementedError(f"Not supported mode `{mode}`.")
|
||||
|
||||
if past_key_values is not None:
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
last_state = (conv_state, recurrent_state)
|
||||
else:
|
||||
last_state = (conv_state_q, conv_state_f, conv_state_i, recurrent_state)
|
||||
else:
|
||||
last_state = (recurrent_state,)
|
||||
past_key_values.update(last_state, self.layer_idx, q.shape[2])
|
||||
|
||||
o = self.g_norm(rearrange(o, 'b h l d -> b l (h d)'))
|
||||
o = self.o_proj(o)
|
||||
|
||||
return o, None, past_key_values
|
||||
|
||||
def init_state(self, batch_size: int) -> Tuple[torch.Tensor]:
|
||||
param = next(self.parameters())
|
||||
state = tuple()
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
state += (param.new_zeros(batch_size, self.hidden_size, self.conv_size),)
|
||||
else:
|
||||
state += (param.new_zeros(batch_size, self.forget_dim, self.conv_size),
|
||||
param.new_zeros(batch_size, self.forget_dim, self.conv_size),
|
||||
param.new_zeros(batch_size, self.input_dim, self.conv_size))
|
||||
state += (param.new_zeros(batch_size, self.num_heads, self.head_f_dim, self.head_i_dim),)
|
||||
return state
|
||||
|
||||
def state_size(self, **kwargs) -> int:
|
||||
state_size = self.forget_dim * self.head_i_dim
|
||||
for module in self.children():
|
||||
if isinstance(module, ShortConvolution):
|
||||
state_size += module.state_size
|
||||
return state_size
|
||||
156
finetune/lora/v6/fla/layers/linear_attn.py
vendored
Normal file
156
finetune/lora/v6/fla/layers/linear_attn.py
vendored
Normal file
@ -0,0 +1,156 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from einops import rearrange
|
||||
|
||||
from fla.modules import RMSNorm
|
||||
from fla.modules.feature_map import (DPFPFeatureMap, HadamardFeatureMap,
|
||||
HedgehogFeatureMap, T2RFeatureMap)
|
||||
from fla.ops.linear_attn import (chunk_linear_attn, fused_chunk_linear_attn,
|
||||
fused_recurrent_linear_attn)
|
||||
|
||||
|
||||
class LinearAttention(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: str = 1024,
|
||||
expand_k: int = 1.0,
|
||||
expand_v: int = 1.0,
|
||||
num_heads: int = 8,
|
||||
mode: str = 'chunk',
|
||||
feature_map: str = 'elementwise_product',
|
||||
tie_feature_map_qk: bool = False,
|
||||
output_norm: str = 'rmsnorm',
|
||||
norm_q: bool = False,
|
||||
norm_k: bool = False,
|
||||
# standard linear attention normalization
|
||||
do_feature_map_norm: bool = False,
|
||||
elementwise_affine: bool = True,
|
||||
norm_eps: float = 1e-5,
|
||||
**kwargs,
|
||||
):
|
||||
super().__init__()
|
||||
assert feature_map in ['elu', 'relu', 'hedgehog', 't2r', 'dpfp',
|
||||
'identity', 'elementwise_product'], f"Not supported feature map `{feature_map}`."
|
||||
|
||||
assert output_norm in ['rmsnorm', 'identity'], f"Not supported output norm `{output_norm}`."
|
||||
|
||||
self.hidden_size
|
||||
self.mode = mode
|
||||
self.key_dim = int(hidden_size * expand_k)
|
||||
self.value_dim = int(hidden_size * expand_v)
|
||||
self.num_heads = num_heads
|
||||
|
||||
assert mode in ['chunk', 'fused_chunk', 'fused_recurrent'], f"Not suppoerted mode `{mode}`."
|
||||
assert self.key_dim % num_heads == 0, f"key dim must be divisible by num_heads of {num_heads}"
|
||||
assert self.value_dim % num_heads == 0, f"value dim must be divisible by num_heads of {num_heads}"
|
||||
|
||||
self.head_qk_dim = self.key_dim // num_heads
|
||||
self.head_v_dim = self.value_dim // num_heads
|
||||
|
||||
if feature_map == 'hedgehog':
|
||||
if tie_feature_map_qk:
|
||||
self.feature_map_q = self.feature_map_k = HedgehogFeatureMap(head_dim=self.head_qk_dim)
|
||||
else:
|
||||
self.feature_map_q = HedgehogFeatureMap(head_dim=self.head_qk_dim)
|
||||
self.feature_map_k = HedgehogFeatureMap(head_dim=self.head_qk_dim)
|
||||
|
||||
elif feature_map == 't2r':
|
||||
if tie_feature_map_qk:
|
||||
self.feature_map_q = self.feature_map_k = T2RFeatureMap(head_dim=self.head_qk_dim)
|
||||
else:
|
||||
self.feature_map_q = T2RFeatureMap(head_dim=self.head_qk_dim)
|
||||
self.feature_map_k = T2RFeatureMap(head_dim=self.head_qk_dim)
|
||||
|
||||
elif feature_map == 'elementwise_product':
|
||||
if tie_feature_map_qk:
|
||||
self.feature_map_q = self.feature_map_k = HadamardFeatureMap(head_dim=self.head_qk_dim)
|
||||
else:
|
||||
self.feature_map_q = HadamardFeatureMap(head_dim=self.head_qk_dim)
|
||||
self.feature_map_k = HadamardFeatureMap(head_dim=self.head_qk_dim)
|
||||
|
||||
elif feature_map == 'dpfp':
|
||||
self.feature_map_q = DPFPFeatureMap(head_dim=self.head_qk_dim)
|
||||
self.feature_map_k = DPFPFeatureMap(head_dim=self.head_qk_dim)
|
||||
|
||||
elif feature_map == 'elu':
|
||||
def elu(x):
|
||||
return F.elu(x) + 1
|
||||
self.feature_map_q = elu
|
||||
self.feature_map_k = elu
|
||||
|
||||
elif feature_map == 'relu':
|
||||
self.feature_map_q = nn.ReLU()
|
||||
self.feature_map_k = nn.ReLU()
|
||||
|
||||
elif feature_map == 'identity':
|
||||
self.feature_map_q = nn.Identity()
|
||||
self.feature_map_k = nn.Identity()
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
self.do_feature_map_norm = do_feature_map_norm
|
||||
if output_norm == 'rmsnorm':
|
||||
self.norm = RMSNorm(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
elif output_norm == 'identity':
|
||||
self.norm = nn.Identity()
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
self.q_proj = nn.Linear(hidden_size, self.key_dim, bias=False)
|
||||
self.k_proj = nn.Linear(hidden_size, self.key_dim, bias=False)
|
||||
self.v_proj = nn.Linear(hidden_size, self.value_dim, bias=False)
|
||||
self.o_proj = nn.Linear(self.value_dim, hidden_size, bias=False)
|
||||
|
||||
self.norm_q = norm_q
|
||||
self.norm_k = norm_k
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(self, x):
|
||||
mode = self.mode
|
||||
q = rearrange(self.q_proj(x), 'b n (h d) -> b h n d', h=self.num_heads)
|
||||
k = rearrange(self.k_proj(x), 'b n (h d) -> b h n d', h=self.num_heads)
|
||||
v = rearrange(self.v_proj(x), 'b n (h d) -> b h n d', h=self.num_heads)
|
||||
q = self.feature_map_q(q)
|
||||
k = self.feature_map_k(k)
|
||||
if self.norm_q:
|
||||
q = q / (q.sum(-1, keepdim=True) + 1e-4)
|
||||
if self.norm_k:
|
||||
k = k / (k.sum(-1, keepdim=True) + 1e-4)
|
||||
|
||||
if mode == 'chunk':
|
||||
o = chunk_linear_attn(q, k, v, normalize=self.do_feature_map_norm)
|
||||
elif mode == 'fused_chunk':
|
||||
o = fused_chunk_linear_attn(q, k, v, normalize=self.do_feature_map_norm)
|
||||
elif mode == 'fused_recurrent':
|
||||
o = fused_recurrent_linear_attn(q, k, v, normalize=self.do_feature_map_norm)
|
||||
else:
|
||||
raise NotImplementedError
|
||||
o = self.norm(o)
|
||||
o = rearrange(o, 'b h n d -> b n (h d)')
|
||||
o = self.o_proj(o)
|
||||
return o
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
import torch
|
||||
batch = 4
|
||||
seq_len = 1024
|
||||
hidden_size = 1024
|
||||
x = torch.randn(batch, seq_len, hidden_size).to(torch.bfloat16).cuda().requires_grad_(True)
|
||||
model = LinearAttention(hidden_size, feature_map='dplp').to(torch.bfloat16).cuda()
|
||||
y = model(x)
|
||||
print(y.shape)
|
||||
y.sum().backward()
|
||||
print(x.grad.shape)
|
||||
271
finetune/lora/v6/fla/layers/multiscale_retention.py
vendored
Normal file
271
finetune/lora/v6/fla/layers/multiscale_retention.py
vendored
Normal file
@ -0,0 +1,271 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from einops import rearrange, repeat
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.cache_utils import Cache
|
||||
|
||||
from fla.modules import FusedRMSNormSwishGate, RMSNorm, ShortConvolution
|
||||
from fla.modules.rotary import RotaryEmbedding
|
||||
from fla.ops.retention import (chunk_retention, fused_chunk_retention,
|
||||
fused_recurrent_retention, parallel_retention)
|
||||
|
||||
|
||||
class MultiScaleRetention(nn.Module):
|
||||
r"""
|
||||
The layer implementaion for [Retentive Network: A Successor to Transformer for Large Language Models](https://arxiv.org/pdf/2307.08621.pdf). # noqa
|
||||
|
||||
Args:
|
||||
mode (str, Optional):
|
||||
Which Retention kernel to use.
|
||||
Currently available: `chunk`, `fused_recurrent`, `parallel`, and `fused_chunk`.
|
||||
Default: `fused_chunk`.
|
||||
hidden_size (int, Optional):
|
||||
The hidden size of the input. Default: 1024.
|
||||
expand_k (float, Optional):
|
||||
The expansion ratio for the key dim. Default: 1.0.
|
||||
expand_v (float, Optional):
|
||||
The expansion ratio for the value dim. Default: 2.0.
|
||||
num_heads (int, Optional):
|
||||
The number of heads. Default: 8.
|
||||
num_kv_heads (int, Optional):
|
||||
The number of key/value heads, used for MQA. Default: None.
|
||||
feature_map (str, Optional):
|
||||
Feature map function applied to queries/keys. Default: None.
|
||||
use_short_conv (bool, Optional):
|
||||
Whether to use short convolutions. Default: `False`.
|
||||
conv_size (int, Optional):
|
||||
The kernel size of the short convolution, only used when `use_short_conv` is `True`. Default: 4.
|
||||
conv_bias (bool, Optional):
|
||||
Whether to use bias in the short convolution, only used when `use_short_conv` is `True`. Default: `False`.
|
||||
share_conv_kernel (bool, Optional):
|
||||
Whether to apply convolutions berfore q/k/v mapping, only taking effects when `use_short_conv`. Default: `True`.
|
||||
use_output_gate (bool, Optional):
|
||||
Whether to use output gate. Default: `True`.
|
||||
gate_fn (str, Optional):
|
||||
The activation function for the output gate. Default: `swish`.
|
||||
elementwise_affine (bool, Optional):
|
||||
If `True`, applies elementwise affine to LayerNorm with learnable parameters. Default: `True`.
|
||||
norm_eps (float, Optional):
|
||||
The epsilon value for the layernorm/rmsnorm layer. Default: 1e-5.
|
||||
fuse_norm (bool, Optional):
|
||||
Whether to fuse the norm and the output gate for better memory footprint. Default: `True`.
|
||||
layer_idx (int, Optional):
|
||||
The index of the layer. Default: None.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
mode: str = 'fused_chunk',
|
||||
hidden_size: int = 1024,
|
||||
expand_k: float = 1.0,
|
||||
expand_v: float = 2.0,
|
||||
num_heads: int = 8,
|
||||
num_kv_heads: Optional[int] = None,
|
||||
feature_map: Optional[str] = None,
|
||||
use_short_conv: bool = False,
|
||||
conv_size: int = 4,
|
||||
conv_bias: bool = False,
|
||||
share_conv_kernel: bool = True,
|
||||
use_output_gate: bool = True,
|
||||
gate_fn: str = 'swish',
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-5,
|
||||
fuse_norm: bool = True,
|
||||
layer_idx: int = None,
|
||||
**kwargs
|
||||
) -> MultiScaleRetention:
|
||||
super().__init__()
|
||||
|
||||
self.mode = mode
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.num_heads = num_heads
|
||||
self.num_kv_heads = num_kv_heads if num_kv_heads is not None else num_heads
|
||||
self.num_kv_groups = self.num_heads // self.num_kv_heads
|
||||
self.feature_map_fn = ACT2FN[feature_map] if feature_map is not None else None
|
||||
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.conv_bias = conv_bias
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
self.use_output_gate = use_output_gate
|
||||
|
||||
self.key_dim = int(hidden_size * expand_k)
|
||||
self.value_dim = int(hidden_size * expand_v)
|
||||
self.key_dim_per_group = self.key_dim // self.num_kv_groups
|
||||
self.value_dim_per_group = self.value_dim // self.num_kv_groups
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
assert mode in ['chunk', 'fused_chunk', 'parallel', 'fused_recurrent'], f"Not suppoerted mode `{mode}`."
|
||||
assert self.key_dim % num_heads == 0, f"key dim must be divisible by num_heads of {num_heads}"
|
||||
assert self.value_dim % num_heads == 0, f"value dim must be divisible by num_heads of {num_heads}"
|
||||
|
||||
self.head_qk_dim = self.key_dim // num_heads
|
||||
self.head_v_dim = self.value_dim // num_heads
|
||||
|
||||
self.q_proj = nn.Linear(hidden_size, self.key_dim, bias=False)
|
||||
self.k_proj = nn.Linear(hidden_size, self.key_dim_per_group, bias=False)
|
||||
self.v_proj = nn.Linear(hidden_size, self.value_dim_per_group, bias=False)
|
||||
if self.use_output_gate:
|
||||
self.g_proj = nn.Linear(hidden_size, self.value_dim, bias=False)
|
||||
|
||||
if use_short_conv:
|
||||
self.conv_size = conv_size
|
||||
if share_conv_kernel:
|
||||
self.h_conv1d = ShortConvolution(hidden_size, conv_size, activation='silu')
|
||||
else:
|
||||
self.q_conv1d = ShortConvolution(self.key_dim, conv_size, activation='silu')
|
||||
self.k_conv1d = ShortConvolution(self.key_dim_per_group, conv_size, activation='silu')
|
||||
self.v_conv1d = ShortConvolution(self.value_dim_per_group, conv_size, activation='silu')
|
||||
|
||||
self.o_proj = nn.Linear(self.value_dim, hidden_size, bias=False)
|
||||
|
||||
if gate_fn == 'swish' and fuse_norm and use_output_gate:
|
||||
self.g_norm_swish_gate = FusedRMSNormSwishGate(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
self.fuse_norm_and_gate = True
|
||||
else:
|
||||
self.fuse_norm_and_gate = False
|
||||
self.g_norm = RMSNorm(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
self.gate_fn = ACT2FN[gate_fn]
|
||||
|
||||
# TODO: fix this issue
|
||||
# https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/ops/triton/rotary.py#L180
|
||||
# Ideally, we would want to support arbitrary d_head_qk
|
||||
assert self.head_qk_dim <= 256, "head_qk_dim must be less than or equal to 256"
|
||||
self.rotary = RotaryEmbedding(dim=self.head_qk_dim)
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Cache] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
**kwargs
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
|
||||
# launching the triton kernel for just one token will actually be slower
|
||||
mode = 'fused_recurrent' if hidden_states.shape[1] == 1 else self.mode
|
||||
|
||||
last_state = past_key_values[self.layer_idx] if use_cache else None
|
||||
if self.use_short_conv:
|
||||
conv_state = last_state[0] if use_cache else None
|
||||
if self.share_conv_kernel:
|
||||
# conv state is updated inplace
|
||||
hidden_states = self.h_conv1d(hidden_states, attention_mask, conv_state)
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
else:
|
||||
conv_state_q = last_state[0] if use_cache else None
|
||||
conv_state_k = last_state[1] if use_cache else None
|
||||
conv_state_v = last_state[2] if use_cache else None
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
q = self.q_conv1d(q, attention_mask, conv_state_q)
|
||||
k = self.k_conv1d(k, attention_mask, conv_state_k)
|
||||
v = self.v_conv1d(v, attention_mask, conv_state_v)
|
||||
else:
|
||||
q = self.q_proj(hidden_states)
|
||||
k = self.k_proj(hidden_states)
|
||||
v = self.v_proj(hidden_states)
|
||||
|
||||
# dealing with left-padding
|
||||
if attention_mask is not None:
|
||||
v = v.mul_(attention_mask.unsqueeze(-1))
|
||||
q = rearrange(q, '... (h d) -> ... h d', h=self.num_heads)
|
||||
k = rearrange(k, '... (h d) -> ... h d', h=self.num_kv_heads)
|
||||
if self.feature_map_fn is not None:
|
||||
q, k = map(self.feature_map_fn, (q, k))
|
||||
|
||||
seqlen_offset, max_seqlen = 0, None
|
||||
if past_key_values is not None:
|
||||
seqlen_offset = past_key_values.get_seq_length(self.layer_idx)
|
||||
max_seqlen = q.shape[1] + seqlen_offset
|
||||
if attention_mask is not None:
|
||||
# to deliminate the offsets of padding tokens
|
||||
seqlen_offset = seqlen_offset + attention_mask.sum(-1) - attention_mask.shape[-1]
|
||||
max_seqlen = q.shape[1] + max(seqlen_offset)
|
||||
q, k = self.rotary(q, k, seqlen_offset, max_seqlen)
|
||||
q = q.transpose(1, 2)
|
||||
if self.num_kv_groups > 1:
|
||||
k = repeat(k, 'b t h d -> b (h g) t d', h=self.num_kv_heads, g=self.num_kv_groups)
|
||||
v = repeat(v, 'b t (h d) -> b (h g) t d', h=self.num_kv_heads, g=self.num_kv_groups)
|
||||
else:
|
||||
k, v = rearrange(k, 'b t h d -> b h t d'), rearrange(v, 'b t (h d) -> b h t d', h=self.num_kv_heads)
|
||||
|
||||
state = last_state[-1] if use_cache else None
|
||||
if mode == 'chunk':
|
||||
o, recurrent_state = chunk_retention(q, k, v, initial_state=state, output_final_state=use_cache)
|
||||
elif mode == 'fused_chunk':
|
||||
o, recurrent_state = fused_chunk_retention(q, k, v, initial_state=state, output_final_state=use_cache)
|
||||
elif mode == 'parallel':
|
||||
o, recurrent_state = parallel_retention(q, k, v, initial_state=state, output_final_state=use_cache)
|
||||
elif mode == 'fused_recurrent':
|
||||
o, recurrent_state = fused_recurrent_retention(q, k, v, initial_state=state, output_final_state=use_cache)
|
||||
else:
|
||||
raise NotImplementedError(f"Not supported mode `{mode}`.")
|
||||
|
||||
if past_key_values is not None:
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
last_state = (conv_state, recurrent_state)
|
||||
else:
|
||||
last_state = (conv_state_q, conv_state_k, conv_state_v, recurrent_state)
|
||||
else:
|
||||
last_state = (recurrent_state,)
|
||||
past_key_values.update(last_state, self.layer_idx, q.shape[2])
|
||||
|
||||
o = rearrange(o, 'b h l d -> b l h d')
|
||||
if self.use_output_gate:
|
||||
g = self.g_proj(hidden_states)
|
||||
if self.fuse_norm_and_gate:
|
||||
g = rearrange(g, 'b l (h d) -> b l h d', h=self.num_heads)
|
||||
o = self.g_norm_swish_gate(o, g)
|
||||
o = rearrange(o, 'b l h d -> b l (h d)')
|
||||
else:
|
||||
o = rearrange(self.g_norm(o), 'b l h d -> b l (h d)')
|
||||
o = o * self.gate_fn(g)
|
||||
else:
|
||||
o = rearrange(self.g_norm(o), 'b l h d -> b l (h d)')
|
||||
o = self.o_proj(o)
|
||||
|
||||
return o, None, past_key_values
|
||||
|
||||
def init_state(self, batch_size: int) -> Tuple[torch.Tensor]:
|
||||
param = next(self.parameters())
|
||||
state = tuple()
|
||||
if self.use_short_conv:
|
||||
if self.share_conv_kernel:
|
||||
state += (param.new_zeros(batch_size, self.hidden_size, self.conv_size),)
|
||||
else:
|
||||
state += (param.new_zeros(batch_size, self.key_dim, self.conv_size),
|
||||
param.new_zeros(batch_size, self.key_dim, self.conv_size),
|
||||
param.new_zeros(batch_size, self.value_dim, self.conv_size))
|
||||
state += (param.new_zeros(batch_size, self.num_heads, self.head_qk_dim, self.head_v_dim),)
|
||||
return state
|
||||
|
||||
def state_size(self, **kwargs) -> int:
|
||||
state_size = self.key_dim * self.head_v_dim
|
||||
for module in self.children():
|
||||
if isinstance(module, ShortConvolution):
|
||||
state_size += module.state_size
|
||||
return state_size
|
||||
137
finetune/lora/v6/fla/layers/rebased.py
vendored
Normal file
137
finetune/lora/v6/fla/layers/rebased.py
vendored
Normal file
@ -0,0 +1,137 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
"""
|
||||
https://github.com/corl-team/rebased/blob/main/flash_linear_attention/fla/layers/rebased_fast.py
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from einops import rearrange
|
||||
|
||||
from fla.modules.feature_map import RebasedFeatureMap
|
||||
from fla.ops.linear_attn import chunk_linear_attn, fused_chunk_linear_attn
|
||||
from fla.ops.rebased import parallel_rebased
|
||||
|
||||
|
||||
class ReBasedLinearAttention(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
l_max: int = 2048,
|
||||
feature_dim: int = 16,
|
||||
num_key_value_heads: int = 16,
|
||||
num_heads: int = 16,
|
||||
use_gamma: Optional[bool] = True,
|
||||
use_beta: Optional[bool] = True,
|
||||
normalize: Optional[bool] = True,
|
||||
causal: bool = True,
|
||||
eps: float = 1e-5,
|
||||
mode: str = "parallel",
|
||||
layer_idx: Optional[int] = None,
|
||||
**kwargs
|
||||
) -> ReBasedLinearAttention:
|
||||
super().__init__()
|
||||
self.hidden_size = hidden_size
|
||||
self.l_max = l_max
|
||||
self.mode = mode
|
||||
assert self.mode in ["fused_chunk", "parallel", 'chunk']
|
||||
|
||||
# linear attention
|
||||
self.feature_dim = feature_dim
|
||||
self.num_key_value_heads = num_key_value_heads
|
||||
self.num_heads = num_heads
|
||||
self.head_dim = self.hidden_size // self.num_key_value_heads
|
||||
self.use_gamma = use_gamma
|
||||
self.use_beta = use_beta
|
||||
self.normalize = normalize
|
||||
self.causal = causal
|
||||
|
||||
self.feature_map = RebasedFeatureMap(self.feature_dim, use_gamma, use_beta, normalize)
|
||||
self.q_proj = nn.Linear(self.hidden_size, self.feature_dim * self.num_heads, bias=False)
|
||||
self.k_proj = nn.Linear(self.hidden_size, self.feature_dim * self.num_heads, bias=False)
|
||||
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
|
||||
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
|
||||
self.dropout = nn.Identity()
|
||||
self.eps = eps
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(self, hidden_states: torch.Tensor, **kwargs):
|
||||
mode = self.mode
|
||||
q, k, v = self.q_proj(hidden_states), self.k_proj(hidden_states), self.v_proj(hidden_states)
|
||||
q, k, v = map(lambda x: rearrange(x, "b l (h d) -> b h l d", h=self.num_heads), [q, k, v])
|
||||
q, k = self.feature_map(q, flatten=(mode != 'parallel')), self.feature_map(k, flatten=(mode != 'parallel'))
|
||||
if mode == "fused_chunk":
|
||||
o = fused_chunk_linear_attn(q, k, v, normalize=True, scale=1)
|
||||
elif mode == 'chunk':
|
||||
o = chunk_linear_attn(q, k, v, normalize=True, scale=1)
|
||||
elif mode == 'parallel':
|
||||
assert q.shape[-1] <= 128
|
||||
o = parallel_rebased(q, k, v, self.eps, True, True)
|
||||
o = rearrange(o, "b h l d -> b l (h d)")
|
||||
o = self.o_proj(o)
|
||||
o = self.dropout(o)
|
||||
return o
|
||||
|
||||
# https://github.com/HazyResearch/zoology/blob/main/zoology/mixers/based.py#L119
|
||||
def forward_reference(self, hidden_states: torch.Tensor, filters: torch.Tensor = None, *args, **kwargs):
|
||||
"""
|
||||
x (torch.Tensor): tensor of shape (b, d, l)
|
||||
y (torch.Tensor): tensor of shape (b, d, l)
|
||||
"""
|
||||
# hidden_states = hidden_states.transpose(1, 2)
|
||||
b, l, _ = hidden_states.size()
|
||||
q, k, v = self.q_proj(hidden_states), self.k_proj(hidden_states), self.v_proj(hidden_states)
|
||||
|
||||
q = q.view(b, l, self.num_heads, self.feature_dim).transpose(1, 2)
|
||||
k = k.view(b, l, self.num_key_value_heads, self.feature_dim).transpose(1, 2)
|
||||
v = v.view(b, l, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
||||
|
||||
# Linear attention
|
||||
q, k = self.feature_map(q), self.feature_map(k)
|
||||
q, k, v = q.unsqueeze(-2), k.unsqueeze(-2), v.unsqueeze(-1)
|
||||
|
||||
# Compute attention
|
||||
if self.causal:
|
||||
y = ((q * (k * v).cumsum(2)).sum(-1) / ((q * k.cumsum(2)).sum(-1) + self.eps))
|
||||
else:
|
||||
y = ((q * (k * v).sum(2, True)).sum(-1) / ((q * k.sum(2, True)).sum(-1) + self.eps))
|
||||
y = rearrange(y, 'b h l d -> b l (h d)')
|
||||
y = self.o_proj(y.to(hidden_states.dtype))
|
||||
y = self.dropout(y)
|
||||
return y.to(hidden_states.dtype)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
batch = 4
|
||||
seq_len = 1024
|
||||
hidden_size = 1024
|
||||
dtype = torch.float32
|
||||
x = torch.randn(batch, seq_len, hidden_size).to(dtype).cuda().requires_grad_(True)
|
||||
dy = torch.randn(batch, seq_len, hidden_size).to(dtype).cuda()
|
||||
model = ReBasedLinearAttention(hidden_size=hidden_size, mode='parallel').to(dtype).cuda()
|
||||
|
||||
y = model(x)
|
||||
y.backward(dy, retain_graph=True)
|
||||
x_grad, x.grad = x.grad, None
|
||||
print(model.mode)
|
||||
model.mode = 'fused_chunk'
|
||||
y2 = model(x)
|
||||
print(model.mode)
|
||||
y2.backward(dy)
|
||||
# assert y.allclose(y2, 0, 1e-4), breakpoint()
|
||||
# assert x_grad.allclose(x.grad, 0, 1e-4), breakpoint()
|
||||
print("Pass")
|
||||
264
finetune/lora/v6/fla/layers/rwkv6.py
vendored
Normal file
264
finetune/lora/v6/fla/layers/rwkv6.py
vendored
Normal file
@ -0,0 +1,264 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# "Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence"[https://arxiv.org/abs/2404.05892]
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from einops import rearrange
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.cache_utils import Cache
|
||||
|
||||
from fla.modules import FusedLayerNormSwishGate, LayerNorm
|
||||
from fla.ops.rwkv6 import chunk_rwkv6, fused_recurrent_rwkv6
|
||||
|
||||
|
||||
class RWKV6Attention(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
mode: str = 'chunk',
|
||||
hidden_size: int = 1024,
|
||||
expand_k: float = 0.5,
|
||||
expand_v: float = 1.0,
|
||||
num_heads: int = 4,
|
||||
gate_fn: str = 'swish',
|
||||
proj_low_rank_dim: int = 32,
|
||||
gate_low_rank_dim: int = 64,
|
||||
fuse_norm: bool = True,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-5,
|
||||
layer_idx: int = None,
|
||||
**kwargs
|
||||
) -> RWKV6Attention:
|
||||
super().__init__()
|
||||
|
||||
self.mode = mode
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.num_heads = num_heads
|
||||
self.proj_low_rank_dim = proj_low_rank_dim
|
||||
self.gate_low_rank_dim = gate_low_rank_dim
|
||||
|
||||
self.key_dim = int(hidden_size * expand_k)
|
||||
self.value_dim = int(hidden_size * expand_v)
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
assert mode in ['chunk', 'fused_recurrent'], f"Not suppoerted mode `{mode}`."
|
||||
assert self.key_dim % num_heads == 0, f"key dim must be divisible by num_heads of {num_heads}"
|
||||
assert self.value_dim % num_heads == 0, f"value dim must be divisible by num_heads of {num_heads}"
|
||||
|
||||
self.head_qk_dim = self.key_dim // num_heads
|
||||
self.head_v_dim = self.value_dim // num_heads
|
||||
|
||||
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
|
||||
self.x_proj = nn.Sequential(
|
||||
LerpLinear(hidden_size, proj_low_rank_dim * 5),
|
||||
nn.Tanh(),
|
||||
nn.Linear(proj_low_rank_dim * 5, hidden_size, bias=True)
|
||||
)
|
||||
self.r_proj = DDLerpLinear(hidden_size, self.key_dim)
|
||||
self.w_proj = DDLerpLinear(hidden_size, self.key_dim, low_rank_dim=gate_low_rank_dim)
|
||||
self.k_proj = DDLerpLinear(hidden_size, self.key_dim)
|
||||
self.v_proj = DDLerpLinear(hidden_size, self.value_dim)
|
||||
self.g_proj = DDLerpLinear(hidden_size, self.value_dim)
|
||||
self.bonus = nn.Parameter(torch.zeros(num_heads, self.head_qk_dim))
|
||||
|
||||
self.o_proj = nn.Linear(self.value_dim, hidden_size, bias=False)
|
||||
|
||||
if gate_fn == 'swish' and fuse_norm:
|
||||
self.g_norm_swish_gate = FusedLayerNormSwishGate(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
self.fuse_norm_and_gate = True
|
||||
else:
|
||||
self.fuse_norm_and_gate = False
|
||||
self.g_norm = LayerNorm(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
self.gate_fn = ACT2FN[gate_fn]
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
if isinstance(module, nn.Parameter):
|
||||
nn.init.xavier_uniform_(module, gain=2 ** -2.5)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Cache] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
**kwargs
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Cache]]:
|
||||
batch_size, seq_len, hidden_size = hidden_states.size()
|
||||
# launching the triton kernel for just one token will actually be slower
|
||||
mode = 'fused_recurrent' if hidden_states.shape[1] == 1 else self.mode
|
||||
|
||||
delta = self.time_shift(hidden_states) - hidden_states
|
||||
x = self.x_proj[0](hidden_states, delta).view(batch_size, seq_len, -1, self.proj_low_rank_dim)
|
||||
r, w, k, v, g = torch.einsum('b l n r, n r d-> b l n d',
|
||||
self.x_proj[1](x),
|
||||
self.x_proj[2].weight.view(5, -1, hidden_size)).unbind(-2)
|
||||
r = self.r_proj(hidden_states, r, delta)
|
||||
w = self.w_proj(hidden_states, w, delta)
|
||||
k = self.k_proj(hidden_states, k, delta)
|
||||
v = self.v_proj(hidden_states, v, delta)
|
||||
g = self.g_proj(hidden_states, g, delta)
|
||||
|
||||
# dealing with left-padding
|
||||
if attention_mask is not None:
|
||||
v = v.mul_(attention_mask.unsqueeze(-1))
|
||||
r, w, k, v = map(lambda x: rearrange(x, 'b l (h d) -> b h l d', h=self.num_heads), (r, w, k, v))
|
||||
w = -torch.exp(w)
|
||||
u = self.bonus
|
||||
|
||||
last_state = past_key_values[self.layer_idx] if use_cache else None
|
||||
state = last_state[-1] if use_cache else None
|
||||
if mode == 'fused_recurrent':
|
||||
o, recurrent_state = fused_recurrent_rwkv6(r, k, v, w, u, initial_state=state, output_final_state=use_cache)
|
||||
elif mode == 'chunk':
|
||||
o, recurrent_state = chunk_rwkv6(r, k, v, w, u, initial_state=state, output_final_state=use_cache)
|
||||
else:
|
||||
raise NotImplementedError(f"Not supported mode `{mode}`.")
|
||||
|
||||
if past_key_values is not None:
|
||||
past_key_values.update((recurrent_state,), self.layer_idx, r.shape[2])
|
||||
|
||||
o = rearrange(o, 'b h l d -> b l h d')
|
||||
if self.fuse_norm_and_gate:
|
||||
g = rearrange(g, 'b l (h d) -> b l h d', h=self.num_heads)
|
||||
o = self.g_norm_swish_gate(o, g)
|
||||
o = rearrange(o, 'b l h d -> b l (h d)')
|
||||
else:
|
||||
o = self.g_norm(o)
|
||||
o = rearrange(o, 'b l h d -> b l (h d)')
|
||||
o = o * self.gate_fn(g)
|
||||
o = self.o_proj(o)
|
||||
|
||||
return o, None, past_key_values
|
||||
|
||||
def init_state(self, batch_size: int) -> Tuple[torch.Tensor]:
|
||||
param = next(self.parameters())
|
||||
state = (param.new_zeros(batch_size, self.num_heads, self.head_qk_dim, self.head_v_dim),)
|
||||
return state
|
||||
|
||||
def state_size(self, **kwargs) -> int:
|
||||
state_size = self.key_dim * self.head_v_dim
|
||||
return state_size
|
||||
|
||||
|
||||
class LoRA(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
input_dim: int,
|
||||
output_dim: int,
|
||||
low_rank_dim: int,
|
||||
bias: Optional[bool] = True
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.input_dim = input_dim
|
||||
self.output_dim = output_dim
|
||||
self.low_rank_dim = low_rank_dim
|
||||
self.bias = bias
|
||||
|
||||
self.lora = nn.Sequential(
|
||||
nn.Linear(input_dim, low_rank_dim, bias=False),
|
||||
nn.Tanh(),
|
||||
nn.Linear(low_rank_dim, output_dim, bias=bias)
|
||||
)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}("
|
||||
s += f"input_dim={self.input_dim}, low_rank_dim={self.low_rank_dim}, output_dim={self.output_dim}"
|
||||
if not self.bias:
|
||||
s += f", bias={self.bias}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
return self.lora(x)
|
||||
|
||||
|
||||
class LerpLinear(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
input_dim: int,
|
||||
output_dim: int,
|
||||
low_rank_dim: Optional[int] = None
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.input_dim = input_dim
|
||||
self.output_dim = output_dim
|
||||
self.low_rank_dim = low_rank_dim
|
||||
|
||||
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
|
||||
if low_rank_dim is None:
|
||||
self.linear = nn.Linear(input_dim, output_dim, bias=False)
|
||||
else:
|
||||
self.linear = LoRA(input_dim, output_dim, low_rank_dim)
|
||||
self.mu = nn.Parameter(torch.zeros(input_dim))
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}({self.input_dim}, {self.output_dim}"
|
||||
if self.low_rank_dim is not None:
|
||||
s += f", low_rank_dim={self.low_rank_dim}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x: torch.Tensor, delta: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
if delta is None:
|
||||
shifted = self.time_shift(x)
|
||||
if len(shifted.shape) == 2:
|
||||
shifted = shifted.unsqueeze(1)
|
||||
delta = shifted - x
|
||||
return self.linear(x + delta * self.mu)
|
||||
|
||||
|
||||
class DDLerpLinear(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
input_dim: int,
|
||||
output_dim: int,
|
||||
low_rank_dim: Optional[int] = None
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.input_dim = input_dim
|
||||
self.output_dim = output_dim
|
||||
self.low_rank_dim = low_rank_dim
|
||||
|
||||
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
|
||||
if low_rank_dim is None:
|
||||
self.linear = nn.Linear(input_dim, output_dim, bias=False)
|
||||
else:
|
||||
self.linear = LoRA(input_dim, output_dim, low_rank_dim)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}({self.input_dim}, {self.output_dim}"
|
||||
if self.low_rank_dim is not None:
|
||||
s += f", low_rank_dim={self.low_rank_dim}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x: torch.Tensor, mu: torch.Tensor, delta: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
if delta is None:
|
||||
shifted = self.time_shift(x)
|
||||
if len(shifted.shape) == 2:
|
||||
shifted = shifted.unsqueeze(1)
|
||||
delta = shifted - x
|
||||
return self.linear(x + delta * mu)
|
||||
143
finetune/lora/v6/fla/layers/simple_gla.py
vendored
Normal file
143
finetune/lora/v6/fla/layers/simple_gla.py
vendored
Normal file
@ -0,0 +1,143 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from einops import rearrange
|
||||
from transformers.activations import ACT2FN
|
||||
|
||||
from fla.modules import FusedRMSNormSwishGate, RMSNorm
|
||||
from fla.ops.simple_gla import chunk_simple_gla
|
||||
|
||||
|
||||
class SimpleGatedLinearAttention(nn.Module):
|
||||
r"""
|
||||
The layer implementaion for [Gated Linear Attention Transformers with Hardware-Efficient Training](https://arxiv.org/abs/2312.06635). # noqa
|
||||
This layer calls the simplified GLA kernel in which the gating is head-wise instead of elementwise.
|
||||
|
||||
Args:
|
||||
mode (str, Optional):
|
||||
Which GLA kernel to use.
|
||||
Currently available: `chunk`.
|
||||
Default: `chunk`.
|
||||
hidden_size (int, Optional):
|
||||
The hidden size of the input. Default: 1024.
|
||||
expand_k (float, Optional):
|
||||
The expansion ratio for the key dim. Default: 0.5.
|
||||
expand_v (float, Optional):
|
||||
The expansion ratio for the value dim. Default: 1.0.
|
||||
num_heads (int, Optional):
|
||||
The number of heads. Default: 4.
|
||||
gate_fn (str, Optional):
|
||||
The activation function for the output gate. Default: `swish`.
|
||||
elementwise_affine (bool, Optional):
|
||||
If `True`, applies elementwise affine to LayerNorm with learnable parameters. Default: `True`.
|
||||
norm_eps (float, Optional):
|
||||
The epsilon value for the layernorm/rmsnorm layer. Default: 1e-5.
|
||||
gate_logit_normalizer (int, Optional):
|
||||
The normalizer for the gate logits, appied after `logsigmoid`. Default: 16.
|
||||
fuse_norm (bool, Optional):
|
||||
Whether to fuse the norm and the output gate for better memory footprint. Default: `True`.
|
||||
layer_idx (int, Optional):
|
||||
The index of the layer. Default: None.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
mode: str = 'chunk',
|
||||
hidden_size: int = 1024,
|
||||
expand_k: float = 1.0,
|
||||
expand_v: float = 2.0,
|
||||
num_heads: int = 4,
|
||||
gate_fn: str = 'swish',
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-5,
|
||||
gate_logit_normalizer: int = 16,
|
||||
fuse_norm: bool = True,
|
||||
**kwargs
|
||||
) -> SimpleGatedLinearAttention:
|
||||
super().__init__()
|
||||
self.hidden_size = hidden_size
|
||||
|
||||
self.mode = mode
|
||||
self.key_dim = int(hidden_size * expand_k)
|
||||
self.value_dim = int(hidden_size * expand_v)
|
||||
assert mode in ['chunk'], f"Not suppoerted mode `{mode}`."
|
||||
assert self.key_dim % num_heads == 0, f"key dim must be divisible by num_heads of {num_heads}"
|
||||
assert self.value_dim % num_heads == 0, f"value dim must be divisible by num_heads of {num_heads}"
|
||||
self.num_heads = num_heads
|
||||
self.head_qk_dim = self.key_dim // num_heads
|
||||
self.head_v_dim = self.value_dim // num_heads
|
||||
self.gate_fn = ACT2FN[gate_fn]
|
||||
|
||||
self.q_proj = nn.Linear(hidden_size, self.key_dim, bias=False)
|
||||
self.k_proj = nn.Linear(hidden_size, self.key_dim, bias=False)
|
||||
self.v_proj = nn.Linear(hidden_size, self.value_dim, bias=False)
|
||||
self.g_proj = nn.Linear(hidden_size, self.value_dim, bias=False)
|
||||
|
||||
self.gk_proj = nn.Linear(hidden_size, self.num_heads)
|
||||
self.o_proj = nn.Linear(self.value_dim, hidden_size, bias=False)
|
||||
|
||||
if gate_fn == 'swish' and fuse_norm:
|
||||
self.g_norm_swish_gate = FusedRMSNormSwishGate(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
self.fuse_norm_and_gate = True
|
||||
else:
|
||||
self.fuse_norm_and_gate = False
|
||||
self.g_norm = RMSNorm(self.head_v_dim, elementwise_affine, norm_eps)
|
||||
|
||||
self.gate_logit_normalizer = gate_logit_normalizer
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(self, x):
|
||||
mode = self.mode
|
||||
q = rearrange(self.q_proj(x), 'b n (h d) -> b h n d', h=self.num_heads)
|
||||
k = rearrange(self.k_proj(x), 'b n (h d) -> b h n d', h=self.num_heads)
|
||||
v = rearrange(self.v_proj(x), 'b n (h d) -> b h n d', h=self.num_heads)
|
||||
gk = rearrange(self.gk_proj(x), 'b n h -> b h n')
|
||||
gk = (F.logsigmoid(gk) / self.gate_logit_normalizer)
|
||||
|
||||
if mode == 'chunk':
|
||||
o = chunk_simple_gla(q, k, v, gk)
|
||||
else:
|
||||
raise NotImplementedError(f"Not supported mode `{mode}`.")
|
||||
|
||||
o = rearrange(o, 'b h l d -> b l h d')
|
||||
g = self.g_proj(x)
|
||||
|
||||
if self.fuse_norm_and_gate:
|
||||
g = rearrange(g, 'b l (h d) -> b l h d', h=self.num_heads)
|
||||
o = self.g_norm_swish_gate(o, g)
|
||||
o = rearrange(o, 'b l h d -> b l (h d)')
|
||||
else:
|
||||
o = self.g_norm(o)
|
||||
o = rearrange(o, 'b l h d -> b l (h d)')
|
||||
o = o * self.gate_fn(g)
|
||||
o = self.o_proj(o)
|
||||
return o
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
batch = 4
|
||||
seq_len = 1024
|
||||
|
||||
hidden_size = 2048
|
||||
x = torch.randn(batch, seq_len, hidden_size).to(torch.bfloat16).cuda().requires_grad_(True)
|
||||
model = SimpleGatedLinearAttention(hidden_size=hidden_size, mode='chunk').to(torch.bfloat16).cuda()
|
||||
y = model(x)
|
||||
print(y.shape)
|
||||
y.sum().backward()
|
||||
print(x.grad.shape)
|
||||
29
finetune/lora/v6/fla/models/__init__.py
vendored
Normal file
29
finetune/lora/v6/fla/models/__init__.py
vendored
Normal file
@ -0,0 +1,29 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from fla.models.abc import ABCConfig, ABCForCausalLM, ABCModel
|
||||
from fla.models.delta_net import (DeltaNetConfig, DeltaNetForCausalLM,
|
||||
DeltaNetModel)
|
||||
from fla.models.gla import GLAConfig, GLAForCausalLM, GLAModel
|
||||
from fla.models.hgrn import HGRNConfig, HGRNForCausalLM, HGRNModel
|
||||
from fla.models.hgrn2 import HGRN2Config, HGRN2ForCausalLM, HGRN2Model
|
||||
from fla.models.linear_attn import (LinearAttentionConfig,
|
||||
LinearAttentionForCausalLM,
|
||||
LinearAttentionModel)
|
||||
from fla.models.mamba import MambaConfig, MambaForCausalLM, MambaModel
|
||||
from fla.models.retnet import RetNetConfig, RetNetForCausalLM, RetNetModel
|
||||
from fla.models.rwkv6 import RWKV6Config, RWKV6ForCausalLM, RWKV6Model
|
||||
from fla.models.transformer import (TransformerConfig, TransformerForCausalLM,
|
||||
TransformerModel)
|
||||
|
||||
__all__ = [
|
||||
'ABCConfig', 'ABCForCausalLM', 'ABCModel',
|
||||
'DeltaNetConfig', 'DeltaNetForCausalLM', 'DeltaNetModel',
|
||||
'GLAConfig', 'GLAForCausalLM', 'GLAModel',
|
||||
'HGRNConfig', 'HGRNForCausalLM', 'HGRNModel',
|
||||
'HGRN2Config', 'HGRN2ForCausalLM', 'HGRN2Model',
|
||||
'LinearAttentionConfig', 'LinearAttentionForCausalLM', 'LinearAttentionModel',
|
||||
'MambaConfig', 'MambaForCausalLM', 'MambaModel',
|
||||
'RetNetConfig', 'RetNetForCausalLM', 'RetNetModel',
|
||||
'RWKV6Config', 'RWKV6ForCausalLM', 'RWKV6Model',
|
||||
'TransformerConfig', 'TransformerForCausalLM', 'TransformerModel'
|
||||
]
|
||||
13
finetune/lora/v6/fla/models/abc/__init__.py
vendored
Normal file
13
finetune/lora/v6/fla/models/abc/__init__.py
vendored
Normal file
@ -0,0 +1,13 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
||||
|
||||
from fla.models.abc.configuration_abc import ABCConfig
|
||||
from fla.models.abc.modeling_abc import ABCForCausalLM, ABCModel
|
||||
|
||||
AutoConfig.register(ABCConfig.model_type, ABCConfig)
|
||||
AutoModel.register(ABCConfig, ABCModel)
|
||||
AutoModelForCausalLM.register(ABCConfig, ABCForCausalLM)
|
||||
|
||||
|
||||
__all__ = ['ABCConfig', 'ABCForCausalLM', 'ABCModel']
|
||||
74
finetune/lora/v6/fla/models/abc/configuration_abc.py
vendored
Normal file
74
finetune/lora/v6/fla/models/abc/configuration_abc.py
vendored
Normal file
@ -0,0 +1,74 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class ABCConfig(PretrainedConfig):
|
||||
|
||||
model_type = 'abc'
|
||||
keys_to_ignore_at_inference = ['past_key_values']
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size: int = 32000,
|
||||
hidden_size: int = 2048,
|
||||
gate_low_rank_dim: int = 16,
|
||||
clamp_min: float = -32,
|
||||
clamp_max: float = 32,
|
||||
hidden_ratio: Optional[int] = 4,
|
||||
intermediate_size: Optional[int] = None,
|
||||
num_hidden_layers: int = 24,
|
||||
num_heads: int = 4,
|
||||
num_slots: Optional[int] = 64,
|
||||
use_short_conv: bool = True,
|
||||
conv_size: int = 4,
|
||||
share_conv_kernel: bool = True,
|
||||
exapnd_k: float = 0.5,
|
||||
exapnd_v: float = 1,
|
||||
hidden_act: str = "swish",
|
||||
max_position_embeddings: int = 2048,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-6,
|
||||
use_cache: bool = True,
|
||||
pad_token_id: int = None,
|
||||
bos_token_id: int = 1,
|
||||
eos_token_id: int = 2,
|
||||
initializer_range: float = 0.02,
|
||||
tie_word_embeddings: bool = False,
|
||||
fuse_norm: bool = True,
|
||||
fuse_cross_entropy: bool = True,
|
||||
**kwargs
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.gate_low_rank_dim = gate_low_rank_dim
|
||||
self.clamp_min = clamp_min
|
||||
self.clamp_max = clamp_max
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_heads = num_heads
|
||||
self.num_slots = num_slots
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
self.expand_k = exapnd_k
|
||||
self.expand_v = exapnd_v
|
||||
self.hidden_act = hidden_act
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.norm_eps = norm_eps
|
||||
self.use_cache = use_cache
|
||||
self.initializer_range = initializer_range
|
||||
self.fuse_cross_entropy = fuse_cross_entropy
|
||||
self.fuse_norm = fuse_norm
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
394
finetune/lora/v6/fla/models/abc/modeling_abc.py
vendored
Normal file
394
finetune/lora/v6/fla/models/abc/modeling_abc.py
vendored
Normal file
@ -0,0 +1,394 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.checkpoint
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast)
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import logging
|
||||
|
||||
from fla.layers.abc import ABCAttention
|
||||
from fla.models.abc.configuration_abc import ABCConfig
|
||||
from fla.models.utils import RecurrentCache
|
||||
from fla.modules import FusedCrossEntropyLoss, RMSNorm
|
||||
from fla.modules.activations import swiglu_linear
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class ABCMLP(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
hidden_ratio: Optional[int] = None,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = 'swish'
|
||||
) -> ABCMLP:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
# the final number of params is `hidden_ratio * hidden_size^2`
|
||||
# `intermediate_size` is chosen to be a multiple of 256 closest to `2/3 * hidden_size * hidden_ratio`
|
||||
if hidden_ratio is None:
|
||||
hidden_ratio = 4
|
||||
if intermediate_size is None:
|
||||
intermediate_size = int(hidden_size * hidden_ratio * 2 / 3)
|
||||
intermediate_size = 256 * ((intermediate_size + 256 - 1) // 256)
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
y = self.gate_proj(x)
|
||||
gate, y = y.chunk(2, -1)
|
||||
return swiglu_linear(gate, y, self.down_proj.weight, self.down_proj.bias)
|
||||
|
||||
|
||||
class ABCBlock(nn.Module):
|
||||
def __init__(self, config: ABCConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.attn_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.attn = ABCAttention(
|
||||
hidden_size=config.hidden_size,
|
||||
expand_k=config.expand_k,
|
||||
expand_v=config.expand_v,
|
||||
num_heads=config.num_heads,
|
||||
num_slots=config.num_slots,
|
||||
use_short_conv=config.use_short_conv,
|
||||
conv_size=config.conv_size,
|
||||
share_conv_kernel=config.share_conv_kernel,
|
||||
gate_fn=config.hidden_act,
|
||||
elementwise_affine=config.elementwise_affine,
|
||||
norm_eps=config.norm_eps,
|
||||
clamp_min=config.clamp_min,
|
||||
clamp_max=config.clamp_max,
|
||||
fuse_norm=config.fuse_norm,
|
||||
layer_idx=layer_idx
|
||||
)
|
||||
self.mlp_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.mlp = ABCMLP(
|
||||
hidden_size=config.hidden_size,
|
||||
hidden_ratio=config.hidden_ratio,
|
||||
intermediate_size=config.intermediate_size,
|
||||
hidden_act=config.hidden_act
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
hidden_states = self.attn_norm(hidden_states)
|
||||
hidden_states, attentions, past_key_values = self.attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
hidden_states, residual = self.mlp_norm(hidden_states, residual, True)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states, attentions, past_key_values)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class ABCPreTrainedModel(PreTrainedModel):
|
||||
|
||||
config_class = ABCConfig
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ['ABCBlock']
|
||||
|
||||
def __init__(self, *inputs, **kwargs):
|
||||
super().__init__(*inputs, **kwargs)
|
||||
|
||||
def _init_weights(
|
||||
self,
|
||||
module: nn.Module,
|
||||
rescale_prenorm_residual: bool = True,
|
||||
num_residuals_per_layer: int = 2,
|
||||
):
|
||||
if isinstance(module, (nn.Linear, nn.Conv1d)):
|
||||
# Slightly different from the TF version which uses truncated_normal for initialization
|
||||
# cf https://github.com/pytorch/pytorch/pull/5617
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
elif isinstance(module, nn.Embedding):
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
|
||||
if rescale_prenorm_residual:
|
||||
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
||||
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
||||
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
||||
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
||||
#
|
||||
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
||||
for name, p in module.named_parameters():
|
||||
if name in ["o_proj.weight", "down_proj.weight"]:
|
||||
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
||||
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
|
||||
# We need to reinit p since this code could be called multiple times
|
||||
# Having just p *= scale would repeatedly scale it down
|
||||
with torch.no_grad():
|
||||
p /= math.sqrt(num_residuals_per_layer * self.config.num_hidden_layers)
|
||||
|
||||
|
||||
class ABCModel(ABCPreTrainedModel):
|
||||
|
||||
def __init__(self, config: ABCConfig):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
self.layers = nn.ModuleList([ABCBlock(config, layer_idx) for layer_idx in range(config.num_hidden_layers)])
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.norm_eps)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embeddings = value
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None, # noqa
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None
|
||||
) -> Union[Tuple, BaseModelOutputWithPast]:
|
||||
if output_attentions:
|
||||
warnings.warn("`ABCModel` does not `output_attentions` now, setting it to `False`.")
|
||||
output_attentions = False
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
use_cache = use_cache if use_cache is not None else (self.config.use_cache if not self.training else False)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size = input_ids.shape[0]
|
||||
elif inputs_embeds is not None:
|
||||
batch_size = inputs_embeds.shape[0]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
if use_cache:
|
||||
if past_key_values is None:
|
||||
past_key_values = [layer.attn.init_state(batch_size) for layer in self.layers]
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
if use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_attns = () if output_attentions else None
|
||||
for layer in self.layers:
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
hidden_states, attentions, past_key_values = self._gradient_checkpointing_func(
|
||||
layer.__call__,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
use_cache,
|
||||
output_attentions
|
||||
)
|
||||
else:
|
||||
hidden_states, attentions, past_key_values = layer(
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
|
||||
if output_attentions:
|
||||
all_attns += (attentions,)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
next_cache = None
|
||||
if use_cache:
|
||||
next_cache = past_key_values.to_legacy_cache()
|
||||
if not return_dict:
|
||||
return tuple(x for x in [hidden_states, next_cache, all_hidden_states, all_attns] if x is not None)
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_attns
|
||||
)
|
||||
|
||||
|
||||
class ABCForCausalLM(ABCPreTrainedModel):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = ABCModel(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embeddings = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
def generate(self, *args, **kwargs):
|
||||
try:
|
||||
return super().generate(*args, **kwargs)
|
||||
except AttributeError as exception:
|
||||
if 'past_key_values' in str(exception):
|
||||
raise AttributeError(
|
||||
f"You tried to call `generate` with a decoding strategy that manipulates `past_key_values`, "
|
||||
f"which is not supported for {self.__class__.__name__}. "
|
||||
f"Try another generation strategy instead. "
|
||||
f"For the available generation strategies, check this doc: "
|
||||
f"https://huggingface.co/docs/transformers/en/generation_strategies#decoding-strategies"
|
||||
)
|
||||
else:
|
||||
raise exception
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
**kwargs
|
||||
):
|
||||
# only last token for `inputs_ids` if the `past_key_values` is passed along.
|
||||
if past_key_values is not None:
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values, input_ids.shape[1] - 1)
|
||||
input_ids = input_ids[:, -1:]
|
||||
|
||||
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
||||
if inputs_embeds is not None and past_key_values is None:
|
||||
model_inputs = {'inputs_embeds': inputs_embeds}
|
||||
else:
|
||||
model_inputs = {'input_ids': input_ids}
|
||||
model_inputs['past_key_values'] = past_key_values
|
||||
return model_inputs
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
inputs_embeds=inputs_embeds,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
if self.config.fuse_cross_entropy:
|
||||
loss_fct = FusedCrossEntropyLoss(inplace_backward=True)
|
||||
else:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
labels = torch.cat((labels[..., 1:], torch.full_like(labels[:, :1], loss_fct.ignore_index)), 1)
|
||||
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
14
finetune/lora/v6/fla/models/delta_net/__init__.py
vendored
Normal file
14
finetune/lora/v6/fla/models/delta_net/__init__.py
vendored
Normal file
@ -0,0 +1,14 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
||||
|
||||
from fla.models.delta_net.configuration_delta_net import \
|
||||
DeltaNetConfig
|
||||
from fla.models.delta_net.modeling_delta_net import (
|
||||
DeltaNetForCausalLM, DeltaNetModel)
|
||||
|
||||
AutoConfig.register(DeltaNetConfig.model_type, DeltaNetConfig)
|
||||
AutoModel.register(DeltaNetConfig, DeltaNetModel)
|
||||
AutoModelForCausalLM.register(DeltaNetConfig, DeltaNetForCausalLM)
|
||||
|
||||
__all__ = ['DeltaNetConfig', 'DeltaNetForCausalLM', 'DeltaNetModel']
|
||||
77
finetune/lora/v6/fla/models/delta_net/configuration_delta_net.py
vendored
Normal file
77
finetune/lora/v6/fla/models/delta_net/configuration_delta_net.py
vendored
Normal file
@ -0,0 +1,77 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class DeltaNetConfig(PretrainedConfig):
|
||||
|
||||
model_type = 'delta_net'
|
||||
keys_to_ignore_at_inference = ['past_key_values']
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size: int = 32000,
|
||||
hidden_size: int = 2048,
|
||||
expand_k: int = 1,
|
||||
expand_v: int = 1,
|
||||
use_gate: bool = False,
|
||||
use_short_conv: bool = True,
|
||||
conv_size: int = 4,
|
||||
share_conv_kernel: bool = False,
|
||||
use_rope: bool = False,
|
||||
use_beta: bool = True,
|
||||
use_output_norm: bool = True,
|
||||
hidden_ratio: Optional[int] = 4,
|
||||
intermediate_size: Optional[int] = None,
|
||||
num_hidden_layers: int = 24,
|
||||
num_heads: int = 4,
|
||||
attn_mode: str = "chunk",
|
||||
qk_norm: str = 'l2',
|
||||
qk_activation: str = 'silu',
|
||||
chunk_size: int = 64,
|
||||
hidden_act: str = "swish",
|
||||
max_position_embeddings: int = 2048,
|
||||
rms_norm_eps: float = 1e-6,
|
||||
use_cache: bool = True,
|
||||
pad_token_id: int = None,
|
||||
bos_token_id: int = 1,
|
||||
eos_token_id: int = 2,
|
||||
tie_word_embeddings: bool = False,
|
||||
initializer_range: float = 0.02,
|
||||
fuse_cross_entropy: bool = True,
|
||||
**kwargs
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_heads = num_heads
|
||||
self.attn_mode = attn_mode
|
||||
self.hidden_act = hidden_act
|
||||
self.rms_norm_eps = rms_norm_eps
|
||||
self.use_cache = use_cache
|
||||
self.initializer_range = initializer_range
|
||||
self.fuse_cross_entropy = fuse_cross_entropy
|
||||
self.use_gate = use_gate
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
self.use_rope = use_rope
|
||||
self.use_beta = use_beta
|
||||
self.use_output_norm = use_output_norm
|
||||
self.qk_norm = qk_norm
|
||||
self.qk_activation = qk_activation
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
405
finetune/lora/v6/fla/models/delta_net/modeling_delta_net.py
vendored
Normal file
405
finetune/lora/v6/fla/models/delta_net/modeling_delta_net.py
vendored
Normal file
@ -0,0 +1,405 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.checkpoint
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast)
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import logging
|
||||
|
||||
from fla.layers.delta_net import DeltaNet
|
||||
from fla.models.delta_net.configuration_delta_net import DeltaNetConfig
|
||||
from fla.models.utils import RecurrentCache
|
||||
from fla.modules import FusedCrossEntropyLoss, RMSNorm
|
||||
from fla.modules.activations import swiglu_linear
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class DeltaNetMLP(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
hidden_ratio: Optional[int] = None,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = 'swish'
|
||||
) -> DeltaNetMLP:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
# the final number of params is `hidden_ratio * hidden_size^2`
|
||||
# `intermediate_size` is chosen to be a multiple of 256 closest to `2/3 * hidden_size * hidden_ratio`
|
||||
if hidden_ratio is None:
|
||||
hidden_ratio = 4
|
||||
if intermediate_size is None:
|
||||
intermediate_size = int(hidden_size * hidden_ratio * 2 / 3)
|
||||
intermediate_size = 256 * ((intermediate_size + 256 - 1) // 256)
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
y = self.gate_proj(x)
|
||||
gate, y = y.chunk(2, -1)
|
||||
return swiglu_linear(gate, y, self.down_proj.weight, self.down_proj.bias)
|
||||
|
||||
|
||||
class DeltaNetBlock(nn.Module):
|
||||
def __init__(self, config: DeltaNetConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.attn_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.rms_norm_eps)
|
||||
self.attn = DeltaNet(
|
||||
mode=config.attn_mode,
|
||||
hidden_size=config.hidden_size,
|
||||
expand_k=config.expand_k,
|
||||
expand_v=config.expand_v,
|
||||
num_heads=config.num_heads,
|
||||
use_gate=config.use_gate,
|
||||
use_rope=config.use_rope,
|
||||
use_beta=config.use_beta,
|
||||
use_short_conv=config.use_short_conv,
|
||||
use_output_norm=config.use_output_norm,
|
||||
conv_size=config.conv_size,
|
||||
share_conv_kernel=config.share_conv_kernel,
|
||||
layer_idx=layer_idx,
|
||||
qk_norm=config.qk_norm,
|
||||
qk_activation=config.qk_activation
|
||||
)
|
||||
self.mlp_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.rms_norm_eps)
|
||||
self.mlp = DeltaNetMLP(
|
||||
hidden_size=config.hidden_size,
|
||||
hidden_ratio=config.hidden_ratio,
|
||||
intermediate_size=config.intermediate_size,
|
||||
hidden_act=config.hidden_act
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
hidden_states = self.attn_norm(hidden_states)
|
||||
hidden_states, attentions, past_key_values = self.attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
hidden_states, residual = self.mlp_norm(hidden_states, residual, True)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states, attentions, past_key_values)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class DeltaNetPreTrainedModel(PreTrainedModel):
|
||||
|
||||
config_class = DeltaNetConfig
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ['DeltaNetBlock']
|
||||
|
||||
def __init__(self, *inputs, **kwargs):
|
||||
super().__init__(*inputs, **kwargs)
|
||||
|
||||
def _init_weights(
|
||||
self,
|
||||
module: nn.Module,
|
||||
rescale_prenorm_residual: bool = True,
|
||||
num_residuals_per_layer: int = 2,
|
||||
):
|
||||
if isinstance(module, (nn.Linear, nn.Conv1d)):
|
||||
# Slightly different from the TF version which uses truncated_normal for initialization
|
||||
# cf https://github.com/pytorch/pytorch/pull/5617
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
elif isinstance(module, nn.Embedding):
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
|
||||
if rescale_prenorm_residual:
|
||||
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
||||
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
||||
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
||||
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
||||
#
|
||||
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
||||
for name, p in module.named_parameters():
|
||||
if name in ["o_proj.weight", "down_proj.weight"]:
|
||||
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
||||
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
|
||||
# We need to reinit p since this code could be called multiple times
|
||||
# Having just p *= scale would repeatedly scale it down
|
||||
with torch.no_grad():
|
||||
p /= math.sqrt(num_residuals_per_layer * self.config.num_hidden_layers)
|
||||
|
||||
|
||||
class DeltaNetModel(DeltaNetPreTrainedModel):
|
||||
|
||||
def __init__(self, config: DeltaNetConfig):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
self.layers = nn.ModuleList([DeltaNetBlock(config, layer_idx) for layer_idx in range(config.num_hidden_layers)])
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embeddings = value
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None, # noqa
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None
|
||||
) -> Union[Tuple, BaseModelOutputWithPast]:
|
||||
if output_attentions:
|
||||
warnings.warn("`DeltaNetModel` does not `output_attentions` now, setting it to `False`.")
|
||||
output_attentions = False
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
use_cache = use_cache if use_cache is not None else (self.config.use_cache if not self.training else False)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size = input_ids.shape[0]
|
||||
elif inputs_embeds is not None:
|
||||
batch_size = inputs_embeds.shape[0]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
if use_cache:
|
||||
if past_key_values is None:
|
||||
past_key_values = [layer.attn.init_state(batch_size) for layer in self.layers]
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
if use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_attns = () if output_attentions else None
|
||||
for layer in self.layers:
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
hidden_states, attentions, past_key_values = self._gradient_checkpointing_func(
|
||||
layer.__call__,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
use_cache,
|
||||
output_attentions
|
||||
)
|
||||
else:
|
||||
hidden_states, attentions, past_key_values = layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
|
||||
if output_attentions:
|
||||
all_attns += (attentions,)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
next_cache = past_key_values
|
||||
# if use_cache:
|
||||
# next_cache = past_key_values.to_legacy_cache()
|
||||
if not return_dict:
|
||||
return tuple(x for x in [hidden_states, next_cache, all_hidden_states, all_attns] if x is not None)
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_attns
|
||||
)
|
||||
|
||||
|
||||
class DeltaNetForCausalLM(DeltaNetPreTrainedModel):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = DeltaNetModel(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embeddings = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
def generate(self, *args, **kwargs):
|
||||
try:
|
||||
return super().generate(*args, **kwargs)
|
||||
except AttributeError as exception:
|
||||
if 'past_key_values' in str(exception):
|
||||
raise AttributeError(
|
||||
f"You tried to call `generate` with a decoding strategy that manipulates `past_key_values`, "
|
||||
f"which is not supported for {self.__class__.__name__}. "
|
||||
f"Try another generation strategy instead. "
|
||||
f"For the available generation strategies, check this doc: "
|
||||
f"https://huggingface.co/docs/transformers/en/generation_strategies#decoding-strategies"
|
||||
)
|
||||
else:
|
||||
raise exception
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
**kwargs
|
||||
):
|
||||
# only last token for `inputs_ids` if the `past_key_values` is passed along.
|
||||
if past_key_values is not None:
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values, input_ids.shape[1] - 1)
|
||||
# breakpoint()
|
||||
input_ids, attention_mask = input_ids[:, -1:], attention_mask[:, -1:]
|
||||
|
||||
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
||||
if inputs_embeds is not None and past_key_values is None:
|
||||
model_inputs = {'inputs_embeds': inputs_embeds}
|
||||
else:
|
||||
# The `contiguous()` here is necessary to have a static stride during decoding. torchdynamo otherwise
|
||||
# recompiles graphs as the stride of the inputs is a guard.
|
||||
# Ref: https://github.com/huggingface/transformers/pull/29114
|
||||
# TODO: use `next_tokens` directly instead.
|
||||
model_inputs = {'input_ids': input_ids.contiguous()}
|
||||
|
||||
model_inputs.update({
|
||||
'past_key_values': past_key_values,
|
||||
'use_cache': kwargs.get('use_cache'),
|
||||
'attention_mask': attention_mask,
|
||||
})
|
||||
return model_inputs
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
inputs_embeds=inputs_embeds,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
if self.config.fuse_cross_entropy:
|
||||
loss_fct = FusedCrossEntropyLoss(inplace_backward=True)
|
||||
else:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
labels = torch.cat((labels[..., 1:], torch.full_like(labels[:, :1], loss_fct.ignore_index)), 1)
|
||||
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
13
finetune/lora/v6/fla/models/gla/__init__.py
vendored
Normal file
13
finetune/lora/v6/fla/models/gla/__init__.py
vendored
Normal file
@ -0,0 +1,13 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
||||
|
||||
from fla.models.gla.configuration_gla import GLAConfig
|
||||
from fla.models.gla.modeling_gla import GLAForCausalLM, GLAModel
|
||||
|
||||
AutoConfig.register(GLAConfig.model_type, GLAConfig)
|
||||
AutoModel.register(GLAConfig, GLAModel)
|
||||
AutoModelForCausalLM.register(GLAConfig, GLAForCausalLM)
|
||||
|
||||
|
||||
__all__ = ['GLAConfig', 'GLAForCausalLM', 'GLAModel']
|
||||
80
finetune/lora/v6/fla/models/gla/configuration_gla.py
vendored
Normal file
80
finetune/lora/v6/fla/models/gla/configuration_gla.py
vendored
Normal file
@ -0,0 +1,80 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class GLAConfig(PretrainedConfig):
|
||||
|
||||
model_type = 'gla'
|
||||
keys_to_ignore_at_inference = ['past_key_values']
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size: int = 32000,
|
||||
hidden_size: int = 2048,
|
||||
expand_k: int = 0.5,
|
||||
expand_v: int = 1,
|
||||
hidden_ratio: Optional[int] = 4,
|
||||
intermediate_size: Optional[int] = None,
|
||||
num_hidden_layers: int = 24,
|
||||
num_heads: int = 4,
|
||||
num_kv_heads: Optional[int] = None,
|
||||
feature_map: Optional[str] = None,
|
||||
attn_mode: str = "chunk",
|
||||
use_short_conv: bool = False,
|
||||
conv_size: int = 4,
|
||||
share_conv_kernel: bool = True,
|
||||
use_output_gate: bool = True,
|
||||
clamp_min: Optional[float] = None,
|
||||
hidden_act: str = "swish",
|
||||
max_position_embeddings: int = 2048,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-6,
|
||||
use_gk: bool = True,
|
||||
use_gv: bool = False,
|
||||
use_cache: bool = True,
|
||||
pad_token_id: int = None,
|
||||
bos_token_id: int = 1,
|
||||
eos_token_id: int = 2,
|
||||
tie_word_embeddings: bool = False,
|
||||
initializer_range: float = 0.02,
|
||||
fuse_norm: bool = True,
|
||||
fuse_cross_entropy: bool = True,
|
||||
**kwargs
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_heads = num_heads
|
||||
self.num_kv_heads = num_kv_heads
|
||||
self.feature_map = feature_map
|
||||
self.attn_mode = attn_mode
|
||||
self.clamp_min = clamp_min
|
||||
self.hidden_act = hidden_act
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.norm_eps = norm_eps
|
||||
self.use_gk = use_gk
|
||||
self.use_gv = use_gv
|
||||
self.use_cache = use_cache
|
||||
self.initializer_range = initializer_range
|
||||
self.fuse_norm = fuse_norm
|
||||
self.fuse_cross_entropy = fuse_cross_entropy
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
self.use_output_gate = use_output_gate
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
403
finetune/lora/v6/fla/models/gla/modeling_gla.py
vendored
Normal file
403
finetune/lora/v6/fla/models/gla/modeling_gla.py
vendored
Normal file
@ -0,0 +1,403 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.checkpoint
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast)
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import logging
|
||||
|
||||
from fla.layers.gla import GatedLinearAttention
|
||||
from fla.models.gla.configuration_gla import GLAConfig
|
||||
from fla.models.utils import RecurrentCache
|
||||
from fla.modules import FusedCrossEntropyLoss, RMSNorm
|
||||
from fla.modules.activations import swiglu_linear
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class GLAMLP(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
hidden_ratio: Optional[int] = None,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = 'swish'
|
||||
) -> GLAMLP:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
# the final number of params is `hidden_ratio * hidden_size^2`
|
||||
# `intermediate_size` is chosen to be a multiple of 256 closest to `2/3 * hidden_size * hidden_ratio`
|
||||
if hidden_ratio is None:
|
||||
hidden_ratio = 4
|
||||
if intermediate_size is None:
|
||||
intermediate_size = int(hidden_size * hidden_ratio * 2 / 3)
|
||||
intermediate_size = 256 * ((intermediate_size + 256 - 1) // 256)
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
y = self.gate_proj(x)
|
||||
gate, y = y.chunk(2, -1)
|
||||
return swiglu_linear(gate, y, self.down_proj.weight, self.down_proj.bias)
|
||||
|
||||
|
||||
class GLABlock(nn.Module):
|
||||
def __init__(self, config: GLAConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.attn_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.attn = GatedLinearAttention(
|
||||
mode=config.attn_mode,
|
||||
hidden_size=config.hidden_size,
|
||||
expand_k=config.expand_k,
|
||||
expand_v=config.expand_v,
|
||||
num_heads=config.num_heads,
|
||||
num_kv_heads=config.num_kv_heads,
|
||||
feature_map=config.feature_map,
|
||||
use_short_conv=config.use_short_conv,
|
||||
conv_size=config.conv_size,
|
||||
share_conv_kernel=config.share_conv_kernel,
|
||||
use_output_gate=config.use_output_gate,
|
||||
gate_fn=config.hidden_act,
|
||||
elementwise_affine=config.elementwise_affine,
|
||||
norm_eps=config.norm_eps,
|
||||
clamp_min=config.clamp_min,
|
||||
fuse_norm=config.fuse_norm,
|
||||
layer_idx=layer_idx
|
||||
)
|
||||
self.mlp_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.mlp = GLAMLP(
|
||||
hidden_size=config.hidden_size,
|
||||
hidden_ratio=config.hidden_ratio,
|
||||
intermediate_size=config.intermediate_size,
|
||||
hidden_act=config.hidden_act
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
residual = hidden_states
|
||||
hidden_states = self.attn_norm(hidden_states)
|
||||
hidden_states, attentions, past_key_values = self.attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
hidden_states, residual = self.mlp_norm(hidden_states, residual, True)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states, attentions, past_key_values)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class GLAPreTrainedModel(PreTrainedModel):
|
||||
|
||||
config_class = GLAConfig
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ['GLABlock']
|
||||
|
||||
def __init__(self, *inputs, **kwargs):
|
||||
super().__init__(*inputs, **kwargs)
|
||||
|
||||
def _init_weights(
|
||||
self,
|
||||
module: nn.Module,
|
||||
rescale_prenorm_residual: bool = True,
|
||||
num_residuals_per_layer: int = 2,
|
||||
):
|
||||
if isinstance(module, (nn.Linear, nn.Conv1d)):
|
||||
# Slightly different from the TF version which uses truncated_normal for initialization
|
||||
# cf https://github.com/pytorch/pytorch/pull/5617
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
elif isinstance(module, nn.Embedding):
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
|
||||
if rescale_prenorm_residual:
|
||||
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
||||
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
||||
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
||||
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
||||
#
|
||||
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
||||
for name, p in module.named_parameters():
|
||||
if name in ["o_proj.weight", "down_proj.weight"]:
|
||||
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
||||
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
|
||||
# We need to reinit p since this code could be called multiple times
|
||||
# Having just p *= scale would repeatedly scale it down
|
||||
with torch.no_grad():
|
||||
p /= math.sqrt(num_residuals_per_layer * self.config.num_hidden_layers)
|
||||
|
||||
|
||||
class GLAModel(GLAPreTrainedModel):
|
||||
|
||||
def __init__(self, config: GLAConfig):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
self.layers = nn.ModuleList([GLABlock(config, layer_idx) for layer_idx in range(config.num_hidden_layers)])
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.norm_eps)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embeddings = value
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None, # noqa
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None
|
||||
) -> Union[Tuple, BaseModelOutputWithPast]:
|
||||
if output_attentions:
|
||||
warnings.warn("`GLAModel` does not `output_attentions` now, setting it to `False`.")
|
||||
output_attentions = False
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
use_cache = use_cache if use_cache is not None else (self.config.use_cache if not self.training else False)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size = input_ids.shape[0]
|
||||
elif inputs_embeds is not None:
|
||||
batch_size = inputs_embeds.shape[0]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
if use_cache:
|
||||
if past_key_values is None:
|
||||
past_key_values = [layer.attn.init_state(batch_size) for layer in self.layers]
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
if use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_attns = () if output_attentions else None
|
||||
for layer in self.layers:
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
hidden_states, attentions, past_key_values = self._gradient_checkpointing_func(
|
||||
layer.__call__,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
use_cache,
|
||||
output_attentions
|
||||
)
|
||||
else:
|
||||
hidden_states, attentions, past_key_values = layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
|
||||
if output_attentions:
|
||||
all_attns += (attentions,)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
next_cache = None
|
||||
if use_cache:
|
||||
next_cache = past_key_values.to_legacy_cache()
|
||||
if not return_dict:
|
||||
return tuple(x for x in [hidden_states, next_cache, all_hidden_states, all_attns] if x is not None)
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_attns
|
||||
)
|
||||
|
||||
|
||||
class GLAForCausalLM(GLAPreTrainedModel):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = GLAModel(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embeddings = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
def generate(self, *args, **kwargs):
|
||||
try:
|
||||
return super().generate(*args, **kwargs)
|
||||
except AttributeError as exception:
|
||||
if 'past_key_values' in str(exception):
|
||||
raise AttributeError(
|
||||
f"You tried to call `generate` with a decoding strategy that manipulates `past_key_values`, "
|
||||
f"which is not supported for {self.__class__.__name__}. "
|
||||
f"Try another generation strategy instead. "
|
||||
f"For the available generation strategies, check this doc: "
|
||||
f"https://huggingface.co/docs/transformers/en/generation_strategies#decoding-strategies"
|
||||
)
|
||||
else:
|
||||
raise exception
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
**kwargs
|
||||
):
|
||||
# only last token for `inputs_ids` if the `past_key_values` is passed along.
|
||||
if past_key_values is not None:
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values, input_ids.shape[1] - 1)
|
||||
input_ids, attention_mask = input_ids[:, -1:], attention_mask[:, -1:]
|
||||
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
||||
if inputs_embeds is not None and past_key_values is None:
|
||||
model_inputs = {'inputs_embeds': inputs_embeds}
|
||||
else:
|
||||
# The `contiguous()` here is necessary to have a static stride during decoding. torchdynamo otherwise
|
||||
# recompiles graphs as the stride of the inputs is a guard.
|
||||
# Ref: https://github.com/huggingface/transformers/pull/29114
|
||||
# TODO: use `next_tokens` directly instead.
|
||||
model_inputs = {'input_ids': input_ids.contiguous()}
|
||||
|
||||
model_inputs.update({
|
||||
'past_key_values': past_key_values,
|
||||
'use_cache': kwargs.get('use_cache'),
|
||||
'attention_mask': attention_mask,
|
||||
})
|
||||
return model_inputs
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
inputs_embeds=inputs_embeds,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
if self.config.fuse_cross_entropy:
|
||||
loss_fct = FusedCrossEntropyLoss(inplace_backward=True)
|
||||
else:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
labels = torch.cat((labels[..., 1:], torch.full_like(labels[:, :1], loss_fct.ignore_index)), 1)
|
||||
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
13
finetune/lora/v6/fla/models/hgrn/__init__.py
vendored
Normal file
13
finetune/lora/v6/fla/models/hgrn/__init__.py
vendored
Normal file
@ -0,0 +1,13 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
||||
|
||||
from fla.models.hgrn.configuration_hgrn import HGRNConfig
|
||||
from fla.models.hgrn.modeling_hgrn import HGRNForCausalLM, HGRNModel
|
||||
|
||||
AutoConfig.register(HGRNConfig.model_type, HGRNConfig)
|
||||
AutoModel.register(HGRNConfig, HGRNModel)
|
||||
AutoModelForCausalLM.register(HGRNConfig, HGRNForCausalLM)
|
||||
|
||||
|
||||
__all__ = ['HGRNConfig', 'HGRNForCausalLM', 'HGRNModel']
|
||||
66
finetune/lora/v6/fla/models/hgrn/configuration_hgrn.py
vendored
Normal file
66
finetune/lora/v6/fla/models/hgrn/configuration_hgrn.py
vendored
Normal file
@ -0,0 +1,66 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class HGRNConfig(PretrainedConfig):
|
||||
|
||||
model_type = 'hgrn'
|
||||
keys_to_ignore_at_inference = ['past_key_values']
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
attn_mode: str = "chunk",
|
||||
vocab_size: int = 32000,
|
||||
hidden_size: int = 2048,
|
||||
num_hidden_layers: int = 24,
|
||||
num_heads: Optional[int] = 1,
|
||||
expand_ratio: Optional[int] = 1,
|
||||
use_short_conv: bool = False,
|
||||
conv_size: int = 4,
|
||||
share_conv_kernel: bool = True,
|
||||
use_lower_bound: bool = True,
|
||||
hidden_ratio: Optional[int] = 4,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = "swish",
|
||||
max_position_embeddings: int = 2048,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-6,
|
||||
use_cache: bool = True,
|
||||
pad_token_id: int = None,
|
||||
bos_token_id: int = 1,
|
||||
eos_token_id: int = 2,
|
||||
tie_word_embeddings: bool = False,
|
||||
initializer_range: float = 0.02,
|
||||
fuse_cross_entropy: bool = True,
|
||||
**kwargs
|
||||
):
|
||||
self.attn_mode = attn_mode
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_heads = num_heads
|
||||
self.expand_ratio = expand_ratio
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
self.use_lower_bound = use_lower_bound
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
self.hidden_act = hidden_act
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.norm_eps = norm_eps
|
||||
self.use_cache = use_cache
|
||||
self.initializer_range = initializer_range
|
||||
self.fuse_cross_entropy = fuse_cross_entropy
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
407
finetune/lora/v6/fla/models/hgrn/modeling_hgrn.py
vendored
Normal file
407
finetune/lora/v6/fla/models/hgrn/modeling_hgrn.py
vendored
Normal file
@ -0,0 +1,407 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.checkpoint
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast)
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import logging
|
||||
|
||||
from fla.layers.hgrn import HGRNAttention
|
||||
from fla.models.hgrn.configuration_hgrn import HGRNConfig
|
||||
from fla.models.utils import RecurrentCache
|
||||
from fla.modules import FusedCrossEntropyLoss, RMSNorm
|
||||
from fla.modules.activations import swiglu_linear
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class HGRNMLP(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
hidden_ratio: Optional[int] = None,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = 'swish'
|
||||
) -> HGRNMLP:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
# the final number of params is `hidden_ratio * hidden_size^2`
|
||||
# `intermediate_size` is chosen to be a multiple of 256 closest to `2/3 * hidden_size * hidden_ratio`
|
||||
if hidden_ratio is None:
|
||||
hidden_ratio = 4
|
||||
if intermediate_size is None:
|
||||
intermediate_size = int(hidden_size * hidden_ratio * 2 / 3)
|
||||
intermediate_size = 256 * ((intermediate_size + 256 - 1) // 256)
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
y = self.gate_proj(x)
|
||||
gate, y = y.chunk(2, -1)
|
||||
return swiglu_linear(gate, y, self.down_proj.weight, self.down_proj.bias)
|
||||
|
||||
|
||||
class HGRNBlock(nn.Module):
|
||||
def __init__(self, config: HGRNConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.attn_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.attn = HGRNAttention(
|
||||
mode=config.attn_mode,
|
||||
hidden_size=config.hidden_size,
|
||||
num_heads=config.num_heads,
|
||||
expand_ratio=config.expand_ratio,
|
||||
use_short_conv=config.use_short_conv,
|
||||
conv_size=config.conv_size,
|
||||
share_conv_kernel=config.share_conv_kernel,
|
||||
elementwise_affine=config.elementwise_affine,
|
||||
norm_eps=config.norm_eps,
|
||||
layer_idx=layer_idx
|
||||
)
|
||||
self.mlp_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.mlp = HGRNMLP(
|
||||
hidden_size=config.hidden_size,
|
||||
hidden_ratio=config.hidden_ratio,
|
||||
intermediate_size=config.intermediate_size,
|
||||
hidden_act=config.hidden_act
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
lower_bound: Optional[torch.Tensor] = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
residual = hidden_states
|
||||
hidden_states = self.attn_norm(hidden_states)
|
||||
hidden_states, attentions, past_key_values = self.attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
lower_bound=lower_bound
|
||||
)
|
||||
hidden_states, residual = self.mlp_norm(hidden_states, residual, True)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states, attentions, past_key_values)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class HGRNPreTrainedModel(PreTrainedModel):
|
||||
|
||||
config_class = HGRNConfig
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ['HGRNBlock']
|
||||
|
||||
def __init__(self, *inputs, **kwargs):
|
||||
super().__init__(*inputs, **kwargs)
|
||||
|
||||
def _init_weights(
|
||||
self,
|
||||
module: nn.Module,
|
||||
rescale_prenorm_residual: bool = True,
|
||||
num_residuals_per_layer: int = 2,
|
||||
):
|
||||
if isinstance(module, (nn.Linear, nn.Conv1d)):
|
||||
# Slightly different from the TF version which uses truncated_normal for initialization
|
||||
# cf https://github.com/pytorch/pytorch/pull/5617
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
elif isinstance(module, nn.Embedding):
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
|
||||
if rescale_prenorm_residual:
|
||||
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
||||
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
||||
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
||||
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
||||
#
|
||||
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
||||
for name, p in module.named_parameters():
|
||||
if name in ["o_proj.weight", "down_proj.weight"]:
|
||||
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
||||
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
|
||||
# We need to reinit p since this code could be called multiple times
|
||||
# Having just p *= scale would repeatedly scale it down
|
||||
with torch.no_grad():
|
||||
p /= math.sqrt(num_residuals_per_layer * self.config.num_hidden_layers)
|
||||
|
||||
|
||||
class HGRNModel(HGRNPreTrainedModel):
|
||||
|
||||
def __init__(self, config: HGRNConfig):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
if config.use_lower_bound:
|
||||
self.lower_bounds = nn.Parameter(torch.zeros(config.num_hidden_layers, config.hidden_size))
|
||||
self.layers = nn.ModuleList([HGRNBlock(config, layer_idx) for layer_idx in range(config.num_hidden_layers)])
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.norm_eps)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embeddings = value
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None, # noqa
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None
|
||||
) -> Union[Tuple, BaseModelOutputWithPast]:
|
||||
if output_attentions:
|
||||
warnings.warn("`HGRNModel` does not `output_attentions` now, setting it to `False`.")
|
||||
output_attentions = False
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
use_cache = use_cache if use_cache is not None else (self.config.use_cache if not self.training else False)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size = input_ids.shape[0]
|
||||
elif inputs_embeds is not None:
|
||||
batch_size = inputs_embeds.shape[0]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
if use_cache:
|
||||
if past_key_values is None:
|
||||
past_key_values = [layer.attn.init_state(batch_size) for layer in self.layers]
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
if use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_attns = () if output_attentions else None
|
||||
|
||||
if self.config.use_lower_bound:
|
||||
lower_bounds = self.lower_bounds.softmax(0)
|
||||
lower_bounds = lower_bounds.cumsum(0) - lower_bounds[0]
|
||||
for i, layer in enumerate(self.layers):
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
lower_bound = lower_bounds[i] if self.config.use_lower_bound else None
|
||||
if self.gradient_checkpointing and self.training:
|
||||
hidden_states, attentions, past_key_values = self._gradient_checkpointing_func(
|
||||
layer.__call__,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
use_cache,
|
||||
output_attentions,
|
||||
lower_bound
|
||||
)
|
||||
else:
|
||||
hidden_states, attentions, past_key_values = layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
lower_bound=lower_bound
|
||||
)
|
||||
|
||||
if output_attentions:
|
||||
all_attns += (attentions,)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
next_cache = None
|
||||
if use_cache:
|
||||
next_cache = past_key_values.to_legacy_cache()
|
||||
if not return_dict:
|
||||
return tuple(x for x in [hidden_states, next_cache, all_hidden_states, all_attns] if x is not None)
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_attns
|
||||
)
|
||||
|
||||
|
||||
class HGRNForCausalLM(HGRNPreTrainedModel):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = HGRNModel(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embeddings = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
def generate(self, *args, **kwargs):
|
||||
try:
|
||||
return super().generate(*args, **kwargs)
|
||||
except AttributeError as exception:
|
||||
if 'past_key_values' in str(exception):
|
||||
raise AttributeError(
|
||||
f"You tried to call `generate` with a decoding strategy that manipulates `past_key_values`, "
|
||||
f"which is not supported for {self.__class__.__name__}. "
|
||||
f"Try another generation strategy instead. "
|
||||
f"For the available generation strategies, check this doc: "
|
||||
f"https://huggingface.co/docs/transformers/en/generation_strategies#decoding-strategies"
|
||||
)
|
||||
else:
|
||||
raise exception
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
**kwargs
|
||||
):
|
||||
# only last token for `inputs_ids` if the `past_key_values` is passed along.
|
||||
if past_key_values is not None:
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values, input_ids.shape[1] - 1)
|
||||
input_ids, attention_mask = input_ids[:, -1:], attention_mask[:, -1:]
|
||||
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
||||
if inputs_embeds is not None and past_key_values is None:
|
||||
model_inputs = {'inputs_embeds': inputs_embeds}
|
||||
else:
|
||||
# The `contiguous()` here is necessary to have a static stride during decoding. torchdynamo otherwise
|
||||
# recompiles graphs as the stride of the inputs is a guard.
|
||||
# Ref: https://github.com/huggingface/transformers/pull/29114
|
||||
# TODO: use `next_tokens` directly instead.
|
||||
model_inputs = {'input_ids': input_ids.contiguous()}
|
||||
|
||||
model_inputs.update({
|
||||
'past_key_values': past_key_values,
|
||||
'use_cache': kwargs.get('use_cache'),
|
||||
'attention_mask': attention_mask,
|
||||
})
|
||||
return model_inputs
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
inputs_embeds=inputs_embeds,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
if self.config.fuse_cross_entropy:
|
||||
loss_fct = FusedCrossEntropyLoss(inplace_backward=True)
|
||||
else:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
labels = torch.cat((labels[..., 1:], torch.full_like(labels[:, :1], loss_fct.ignore_index)), 1)
|
||||
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
13
finetune/lora/v6/fla/models/hgrn2/__init__.py
vendored
Normal file
13
finetune/lora/v6/fla/models/hgrn2/__init__.py
vendored
Normal file
@ -0,0 +1,13 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
||||
|
||||
from fla.models.hgrn2.configuration_hgrn2 import HGRN2Config
|
||||
from fla.models.hgrn2.modeling_hgrn2 import HGRN2ForCausalLM, HGRN2Model
|
||||
|
||||
AutoConfig.register(HGRN2Config.model_type, HGRN2Config)
|
||||
AutoModel.register(HGRN2Config, HGRN2Model)
|
||||
AutoModelForCausalLM.register(HGRN2Config, HGRN2ForCausalLM)
|
||||
|
||||
|
||||
__all__ = ['HGRN2Config', 'HGRN2ForCausalLM', 'HGRN2Model']
|
||||
66
finetune/lora/v6/fla/models/hgrn2/configuration_hgrn2.py
vendored
Normal file
66
finetune/lora/v6/fla/models/hgrn2/configuration_hgrn2.py
vendored
Normal file
@ -0,0 +1,66 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class HGRN2Config(PretrainedConfig):
|
||||
|
||||
model_type = 'hgrn2'
|
||||
keys_to_ignore_at_inference = ['past_key_values']
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size: int = 32000,
|
||||
hidden_size: int = 2048,
|
||||
num_hidden_layers: int = 24,
|
||||
attn_mode: str = "chunk",
|
||||
num_heads: Optional[int] = None,
|
||||
expand_ratio: Optional[int] = 128,
|
||||
use_short_conv: bool = False,
|
||||
conv_size: int = 4,
|
||||
share_conv_kernel: bool = True,
|
||||
use_lower_bound: bool = True,
|
||||
hidden_ratio: Optional[int] = 4,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = "swish",
|
||||
max_position_embeddings: int = 2048,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-6,
|
||||
use_cache: bool = True,
|
||||
pad_token_id: int = None,
|
||||
bos_token_id: int = 1,
|
||||
eos_token_id: int = 2,
|
||||
tie_word_embeddings: bool = False,
|
||||
initializer_range: float = 0.02,
|
||||
fuse_cross_entropy: bool = True,
|
||||
**kwargs
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.attn_mode = attn_mode
|
||||
self.num_heads = num_heads
|
||||
self.expand_ratio = expand_ratio
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
self.use_lower_bound = use_lower_bound
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
self.hidden_act = hidden_act
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.norm_eps = norm_eps
|
||||
self.use_cache = use_cache
|
||||
self.initializer_range = initializer_range
|
||||
self.fuse_cross_entropy = fuse_cross_entropy
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
407
finetune/lora/v6/fla/models/hgrn2/modeling_hgrn2.py
vendored
Normal file
407
finetune/lora/v6/fla/models/hgrn2/modeling_hgrn2.py
vendored
Normal file
@ -0,0 +1,407 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.checkpoint
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast)
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import logging
|
||||
|
||||
from fla.layers.hgrn2 import HGRN2Attention
|
||||
from fla.models.hgrn2.configuration_hgrn2 import HGRN2Config
|
||||
from fla.models.utils import RecurrentCache
|
||||
from fla.modules import FusedCrossEntropyLoss, RMSNorm
|
||||
from fla.modules.activations import swiglu_linear
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class HGRN2MLP(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
hidden_ratio: Optional[int] = None,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = 'swish'
|
||||
) -> HGRN2MLP:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
# the final number of params is `hidden_ratio * hidden_size^2`
|
||||
# `intermediate_size` is chosen to be a multiple of 256 closest to `2/3 * hidden_size * hidden_ratio`
|
||||
if hidden_ratio is None:
|
||||
hidden_ratio = 4
|
||||
if intermediate_size is None:
|
||||
intermediate_size = int(hidden_size * hidden_ratio * 2 / 3)
|
||||
intermediate_size = 256 * ((intermediate_size + 256 - 1) // 256)
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
y = self.gate_proj(x)
|
||||
gate, y = y.chunk(2, -1)
|
||||
return swiglu_linear(gate, y, self.down_proj.weight, self.down_proj.bias)
|
||||
|
||||
|
||||
class HGRN2Block(nn.Module):
|
||||
def __init__(self, config: HGRN2Config, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.attn_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.attn = HGRN2Attention(
|
||||
mode=config.attn_mode,
|
||||
hidden_size=config.hidden_size,
|
||||
num_heads=config.num_heads,
|
||||
expand_ratio=config.expand_ratio,
|
||||
use_short_conv=config.use_short_conv,
|
||||
conv_size=config.conv_size,
|
||||
share_conv_kernel=config.share_conv_kernel,
|
||||
elementwise_affine=config.elementwise_affine,
|
||||
norm_eps=config.norm_eps,
|
||||
layer_idx=layer_idx
|
||||
)
|
||||
self.mlp_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.mlp = HGRN2MLP(
|
||||
hidden_size=config.hidden_size,
|
||||
hidden_ratio=config.hidden_ratio,
|
||||
intermediate_size=config.intermediate_size,
|
||||
hidden_act=config.hidden_act
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
lower_bound: Optional[torch.Tensor] = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
residual = hidden_states
|
||||
hidden_states = self.attn_norm(hidden_states)
|
||||
hidden_states, attentions, past_key_values = self.attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
lower_bound=lower_bound
|
||||
)
|
||||
hidden_states, residual = self.mlp_norm(hidden_states, residual, True)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states, attentions, past_key_values)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class HGRN2PreTrainedModel(PreTrainedModel):
|
||||
|
||||
config_class = HGRN2Config
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ['HGRN2Block']
|
||||
|
||||
def __init__(self, *inputs, **kwargs):
|
||||
super().__init__(*inputs, **kwargs)
|
||||
|
||||
def _init_weights(
|
||||
self,
|
||||
module: nn.Module,
|
||||
rescale_prenorm_residual: bool = True,
|
||||
num_residuals_per_layer: int = 2,
|
||||
):
|
||||
if isinstance(module, (nn.Linear, nn.Conv1d)):
|
||||
# Slightly different from the TF version which uses truncated_normal for initialization
|
||||
# cf https://github.com/pytorch/pytorch/pull/5617
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
elif isinstance(module, nn.Embedding):
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
|
||||
if rescale_prenorm_residual:
|
||||
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
||||
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
||||
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
||||
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
||||
#
|
||||
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
||||
for name, p in module.named_parameters():
|
||||
if name in ["o_proj.weight", "down_proj.weight"]:
|
||||
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
||||
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
|
||||
# We need to reinit p since this code could be called multiple times
|
||||
# Having just p *= scale would repeatedly scale it down
|
||||
with torch.no_grad():
|
||||
p /= math.sqrt(num_residuals_per_layer * self.config.num_hidden_layers)
|
||||
|
||||
|
||||
class HGRN2Model(HGRN2PreTrainedModel):
|
||||
|
||||
def __init__(self, config: HGRN2Config):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
if config.use_lower_bound:
|
||||
self.lower_bounds = nn.Parameter(torch.zeros(config.num_hidden_layers, config.hidden_size))
|
||||
self.layers = nn.ModuleList([HGRN2Block(config, layer_idx) for layer_idx in range(config.num_hidden_layers)])
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.norm_eps)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embeddings = value
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None, # noqa
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None
|
||||
) -> Union[Tuple, BaseModelOutputWithPast]:
|
||||
if output_attentions:
|
||||
warnings.warn("`HGRN2Model` does not `output_attentions` now, setting it to `False`.")
|
||||
output_attentions = False
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
use_cache = use_cache if use_cache is not None else (self.config.use_cache if not self.training else False)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size = input_ids.shape[0]
|
||||
elif inputs_embeds is not None:
|
||||
batch_size = inputs_embeds.shape[0]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
if use_cache:
|
||||
if past_key_values is None:
|
||||
past_key_values = [layer.attn.init_state(batch_size) for layer in self.layers]
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
if use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_attns = () if output_attentions else None
|
||||
|
||||
if self.config.use_lower_bound:
|
||||
lower_bounds = self.lower_bounds.softmax(0)
|
||||
lower_bounds = lower_bounds.cumsum(0) - lower_bounds[0]
|
||||
for i, layer in enumerate(self.layers):
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
lower_bound = lower_bounds[i] if self.config.use_lower_bound else None
|
||||
if self.gradient_checkpointing and self.training:
|
||||
hidden_states, attentions, past_key_values = self._gradient_checkpointing_func(
|
||||
layer.__call__,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
use_cache,
|
||||
output_attentions,
|
||||
lower_bound
|
||||
)
|
||||
else:
|
||||
hidden_states, attentions, past_key_values = layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
lower_bound=lower_bound
|
||||
)
|
||||
|
||||
if output_attentions:
|
||||
all_attns += (attentions,)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
next_cache = None
|
||||
if use_cache:
|
||||
next_cache = past_key_values.to_legacy_cache()
|
||||
if not return_dict:
|
||||
return tuple(x for x in [hidden_states, next_cache, all_hidden_states, all_attns] if x is not None)
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_attns
|
||||
)
|
||||
|
||||
|
||||
class HGRN2ForCausalLM(HGRN2PreTrainedModel):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = HGRN2Model(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embeddings = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
def generate(self, *args, **kwargs):
|
||||
try:
|
||||
return super().generate(*args, **kwargs)
|
||||
except AttributeError as exception:
|
||||
if 'past_key_values' in str(exception):
|
||||
raise AttributeError(
|
||||
f"You tried to call `generate` with a decoding strategy that manipulates `past_key_values`, "
|
||||
f"which is not supported for {self.__class__.__name__}. "
|
||||
f"Try another generation strategy instead. "
|
||||
f"For the available generation strategies, check this doc: "
|
||||
f"https://huggingface.co/docs/transformers/en/generation_strategies#decoding-strategies"
|
||||
)
|
||||
else:
|
||||
raise exception
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
**kwargs
|
||||
):
|
||||
# only last token for `inputs_ids` if the `past_key_values` is passed along.
|
||||
if past_key_values is not None:
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values, input_ids.shape[1] - 1)
|
||||
input_ids, attention_mask = input_ids[:, -1:], attention_mask[:, -1:]
|
||||
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
||||
if inputs_embeds is not None and past_key_values is None:
|
||||
model_inputs = {'inputs_embeds': inputs_embeds}
|
||||
else:
|
||||
# The `contiguous()` here is necessary to have a static stride during decoding. torchdynamo otherwise
|
||||
# recompiles graphs as the stride of the inputs is a guard.
|
||||
# Ref: https://github.com/huggingface/transformers/pull/29114
|
||||
# TODO: use `next_tokens` directly instead.
|
||||
model_inputs = {'input_ids': input_ids.contiguous()}
|
||||
|
||||
model_inputs.update({
|
||||
'past_key_values': past_key_values,
|
||||
'use_cache': kwargs.get('use_cache'),
|
||||
'attention_mask': attention_mask,
|
||||
})
|
||||
return model_inputs
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
inputs_embeds=inputs_embeds,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
if self.config.fuse_cross_entropy:
|
||||
loss_fct = FusedCrossEntropyLoss(inplace_backward=True)
|
||||
else:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
labels = torch.cat((labels[..., 1:], torch.full_like(labels[:, :1], loss_fct.ignore_index)), 1)
|
||||
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
14
finetune/lora/v6/fla/models/linear_attn/__init__.py
vendored
Normal file
14
finetune/lora/v6/fla/models/linear_attn/__init__.py
vendored
Normal file
@ -0,0 +1,14 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
||||
|
||||
from fla.models.linear_attn.configuration_linear_attn import \
|
||||
LinearAttentionConfig
|
||||
from fla.models.linear_attn.modeling_linear_attn import (
|
||||
LinearAttentionForCausalLM, LinearAttentionModel)
|
||||
|
||||
AutoConfig.register(LinearAttentionConfig.model_type, LinearAttentionConfig)
|
||||
AutoModel.register(LinearAttentionConfig, LinearAttentionModel)
|
||||
AutoModelForCausalLM.register(LinearAttentionConfig, LinearAttentionForCausalLM)
|
||||
|
||||
__all__ = ['LinearAttentionConfig', 'LinearAttentionForCausalLM', 'LinearAttentionModel']
|
||||
70
finetune/lora/v6/fla/models/linear_attn/configuration_linear_attn.py
vendored
Normal file
70
finetune/lora/v6/fla/models/linear_attn/configuration_linear_attn.py
vendored
Normal file
@ -0,0 +1,70 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class LinearAttentionConfig(PretrainedConfig):
|
||||
|
||||
model_type = 'linear_attn'
|
||||
keys_to_ignore_at_inference = ['past_key_values']
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size: int = 32000,
|
||||
hidden_size: int = 2048,
|
||||
expand_k: int = 1,
|
||||
expand_v: int = 1,
|
||||
hidden_ratio: Optional[int] = 4,
|
||||
intermediate_size: Optional[int] = None,
|
||||
num_hidden_layers: int = 24,
|
||||
num_heads: int = 4,
|
||||
attn_mode: str = "fused_chunk",
|
||||
feature_map: str = "elementwise_product",
|
||||
tie_feature_map_qk: bool = False,
|
||||
norm_q: bool = False,
|
||||
norm_k: bool = False,
|
||||
norm_feature_map: bool = False,
|
||||
hidden_act: str = "swish",
|
||||
max_position_embeddings: int = 2048,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-6,
|
||||
use_cache: bool = True,
|
||||
pad_token_id: int = None,
|
||||
bos_token_id: int = 1,
|
||||
eos_token_id: int = 2,
|
||||
tie_word_embeddings: bool = False,
|
||||
initializer_range: float = 0.02,
|
||||
fuse_cross_entropy: bool = True,
|
||||
**kwargs
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_heads = num_heads
|
||||
self.attn_mode = attn_mode
|
||||
self.feature_map = feature_map
|
||||
self.tie_feature_map_qk = tie_feature_map_qk
|
||||
self.norm_q = norm_q
|
||||
self.norm_k = norm_k
|
||||
self.norm_feature_map = norm_feature_map
|
||||
self.hidden_act = hidden_act
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.norm_eps = norm_eps
|
||||
self.use_cache = use_cache
|
||||
self.initializer_range = initializer_range
|
||||
self.fuse_cross_entropy = fuse_cross_entropy
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
424
finetune/lora/v6/fla/models/linear_attn/modeling_linear_attn.py
vendored
Normal file
424
finetune/lora/v6/fla/models/linear_attn/modeling_linear_attn.py
vendored
Normal file
@ -0,0 +1,424 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.checkpoint
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.cache_utils import Cache, DynamicCache
|
||||
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast)
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import logging
|
||||
|
||||
from fla.layers.linear_attn import LinearAttention
|
||||
from fla.models.linear_attn.configuration_linear_attn import \
|
||||
LinearAttentionConfig
|
||||
from fla.modules import FusedCrossEntropyLoss, RMSNorm
|
||||
from fla.modules.activations import swiglu_linear
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class LinearAttentionMLP(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
hidden_ratio: Optional[int] = None,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = 'swish'
|
||||
) -> LinearAttentionMLP:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
# the final number of params is `hidden_ratio * hidden_size^2`
|
||||
# `intermediate_size` is chosen to be a multiple of 256 closest to `2/3 * hidden_size * hidden_ratio`
|
||||
if hidden_ratio is None:
|
||||
hidden_ratio = 4
|
||||
if intermediate_size is None:
|
||||
intermediate_size = int(hidden_size * hidden_ratio * 2 / 3)
|
||||
intermediate_size = 256 * ((intermediate_size + 256 - 1) // 256)
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
y = self.gate_proj(x)
|
||||
gate, y = y.chunk(2, -1)
|
||||
return swiglu_linear(gate, y, self.down_proj.weight, self.down_proj.bias)
|
||||
|
||||
|
||||
class LinearAttentionBlock(nn.Module):
|
||||
def __init__(self, config: LinearAttentionConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.attn_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.attn = LinearAttention(
|
||||
hidden_size=config.hidden_size,
|
||||
expand_k=config.expand_k,
|
||||
expand_v=config.expand_v,
|
||||
num_heads=config.num_heads,
|
||||
mode=config.attn_mode,
|
||||
feature_map=config.feature_map,
|
||||
tie_feature_map_qk=config.tie_feature_map_qk,
|
||||
norm_q=config.norm_q,
|
||||
norm_k=config.norm_k,
|
||||
do_feature_map_norm=config.norm_feature_map,
|
||||
elementwise_affine=config.elementwise_affine,
|
||||
norm_eps=config.norm_eps,
|
||||
layer_idx=layer_idx
|
||||
)
|
||||
self.mlp_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.mlp = LinearAttentionMLP(
|
||||
hidden_size=config.hidden_size,
|
||||
hidden_ratio=config.hidden_ratio,
|
||||
intermediate_size=config.intermediate_size,
|
||||
hidden_act=config.hidden_act
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: Optional[bool] = False,
|
||||
use_cache: Optional[bool] = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
|
||||
residual = hidden_states
|
||||
# currently not supported
|
||||
attn_weights, present_key_value = None, None
|
||||
|
||||
hidden_states = self.attn_norm(hidden_states)
|
||||
hidden_states = self.attn(hidden_states)
|
||||
hidden_states, residual = self.mlp_norm(hidden_states, residual, True)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states,)
|
||||
|
||||
if output_attentions:
|
||||
outputs += (attn_weights,)
|
||||
|
||||
if use_cache:
|
||||
outputs += (present_key_value,)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class LinearAttentionPreTrainedModel(PreTrainedModel):
|
||||
config_class = LinearAttentionConfig
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ['LinearAttentionBlock']
|
||||
|
||||
def __init__(self, *inputs, **kwargs):
|
||||
super().__init__(*inputs, **kwargs)
|
||||
|
||||
def _init_weights(
|
||||
self,
|
||||
module: nn.Module,
|
||||
rescale_prenorm_residual: bool = True,
|
||||
num_residuals_per_layer: int = 2,
|
||||
):
|
||||
if isinstance(module, (nn.Linear, nn.Conv1d)):
|
||||
# Slightly different from the TF version which uses truncated_normal for initialization
|
||||
# cf https://github.com/pytorch/pytorch/pull/5617
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
elif isinstance(module, nn.Embedding):
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
|
||||
if rescale_prenorm_residual:
|
||||
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
||||
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
||||
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
||||
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
||||
#
|
||||
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
||||
for name, p in module.named_parameters():
|
||||
if name in ["o_proj.weight", "down_proj.weight"]:
|
||||
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
||||
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
|
||||
# We need to reinit p since this code could be called multiple times
|
||||
# Having just p *= scale would repeatedly scale it down
|
||||
with torch.no_grad():
|
||||
p /= math.sqrt(num_residuals_per_layer * self.config.num_hidden_layers)
|
||||
|
||||
|
||||
class LinearAttentionModel(LinearAttentionPreTrainedModel):
|
||||
|
||||
def __init__(self, config: LinearAttentionConfig):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
self.layers = nn.ModuleList(
|
||||
[LinearAttentionBlock(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
|
||||
)
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.norm_eps)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embeddings = value
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, BaseModelOutputWithPast]:
|
||||
if output_attentions:
|
||||
warnings.warn(
|
||||
"`LinearAttentionModel` does not support output attention weights now, "
|
||||
"so `output_attentions` is set to `False`."
|
||||
)
|
||||
output_attentions = False
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
use_cache = use_cache if use_cache is not None else (self.config.use_cache if not self.training else False)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
_, seq_length = input_ids.shape[:2]
|
||||
elif inputs_embeds is not None:
|
||||
_, seq_length = inputs_embeds.shape[:2]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
past_key_values_length = 0
|
||||
if use_cache:
|
||||
use_legacy_cache = not isinstance(past_key_values, Cache)
|
||||
if use_legacy_cache:
|
||||
past_key_values = DynamicCache.from_legacy_cache(past_key_values)
|
||||
past_key_values_length = past_key_values.get_usable_length(seq_length)
|
||||
|
||||
if position_ids is None:
|
||||
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
||||
position_ids = torch.arange(
|
||||
past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
|
||||
)
|
||||
position_ids = position_ids.unsqueeze(0)
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
|
||||
# embed positions
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
if use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
# decoder layers
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_self_attns = () if output_attentions else None
|
||||
next_decoder_cache = None
|
||||
|
||||
for decoder_layer in self.layers:
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
layer_outputs = self._gradient_checkpointing_func(
|
||||
decoder_layer.__call__,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
position_ids,
|
||||
past_key_values,
|
||||
output_attentions,
|
||||
use_cache,
|
||||
)
|
||||
else:
|
||||
layer_outputs = decoder_layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_values,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
)
|
||||
|
||||
hidden_states = layer_outputs[0]
|
||||
|
||||
if use_cache:
|
||||
next_decoder_cache = layer_outputs[2 if output_attentions else 1]
|
||||
|
||||
if output_attentions:
|
||||
all_self_attns += (layer_outputs[1],)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
next_cache = None
|
||||
if use_cache:
|
||||
next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
|
||||
if not return_dict:
|
||||
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_self_attns,
|
||||
)
|
||||
|
||||
|
||||
class LinearAttentionForCausalLM(LinearAttentionPreTrainedModel):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = LinearAttentionModel(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embeddings = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
def generate(self, *args, **kwargs):
|
||||
try:
|
||||
return super().generate(*args, **kwargs)
|
||||
except AttributeError as exc:
|
||||
# Expected exception: "AttributeError: '(object name)' object has no attribute 'past_key_values'"
|
||||
if 'past_key_values' in str(exc):
|
||||
raise AttributeError(
|
||||
f"You tried to call `generate` with a decoding strategy that manipulates `past_key_values`, "
|
||||
f"which is not supported for {self.__class__.__name__}. "
|
||||
f"Try another generation strategy instead. "
|
||||
f"For the available generation strategies, check this doc: "
|
||||
f"https://huggingface.co/docs/transformers/en/generation_strategies#decoding-strategies"
|
||||
)
|
||||
else:
|
||||
raise exc
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
state: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
**kwargs
|
||||
):
|
||||
# only last token for inputs_ids if the state is passed along.
|
||||
if state is not None:
|
||||
input_ids = input_ids[:, -1].unsqueeze(-1)
|
||||
|
||||
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
||||
if inputs_embeds is not None and state is None:
|
||||
model_inputs = {"inputs_embeds": inputs_embeds}
|
||||
else:
|
||||
model_inputs = {"input_ids": input_ids}
|
||||
model_inputs["state"] = state
|
||||
return model_inputs
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
if self.config.fuse_cross_entropy:
|
||||
loss_fct = FusedCrossEntropyLoss(inplace_backward=True)
|
||||
else:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
labels = torch.cat((labels[..., 1:], torch.full_like(labels[:, :1], loss_fct.ignore_index)), 1)
|
||||
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
14
finetune/lora/v6/fla/models/mamba/__init__.py
vendored
Normal file
14
finetune/lora/v6/fla/models/mamba/__init__.py
vendored
Normal file
@ -0,0 +1,14 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
||||
|
||||
from fla.models.mamba.configuration_mamba import MambaConfig
|
||||
from fla.models.mamba.modeling_mamba import (MambaBlock, MambaForCausalLM,
|
||||
MambaModel)
|
||||
|
||||
AutoConfig.register(MambaConfig.model_type, MambaConfig, True)
|
||||
AutoModel.register(MambaConfig, MambaModel, True)
|
||||
AutoModelForCausalLM.register(MambaConfig, MambaForCausalLM, True)
|
||||
|
||||
|
||||
__all__ = ['MambaConfig', 'MambaForCausalLM', 'MambaModel', 'MambaBlock']
|
||||
156
finetune/lora/v6/fla/models/mamba/configuration_mamba.py
vendored
Normal file
156
finetune/lora/v6/fla/models/mamba/configuration_mamba.py
vendored
Normal file
@ -0,0 +1,156 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2024 The HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""MAMBA configuration"""
|
||||
|
||||
import math
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class MambaConfig(PretrainedConfig):
|
||||
"""
|
||||
This is the configuration class to store the configuration of a [`MambaModel`]. It is used to instantiate a MAMBA
|
||||
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
|
||||
defaults will yield a similar configuration to that of the MAMBA
|
||||
[state-spaces/mamba-2.8b](https://huggingface.co/state-spaces/mamba-2.8b) architecture.
|
||||
|
||||
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
||||
documentation from [`PretrainedConfig`] for more information.
|
||||
|
||||
|
||||
Args:
|
||||
vocab_size (`int`, *optional*, defaults to 50280):
|
||||
Vocabulary size of the MAMBA model. Defines the number of different tokens that can be represented by the
|
||||
`inputs_ids` passed when calling [`MambaModel`].
|
||||
hidden_size (`int`, *optional*, defaults to 768):
|
||||
Dimensionality of the embeddings and hidden states.
|
||||
state_size (`int`, *optional*, defaults to 16): shape of the state space latents.
|
||||
num_hidden_layers (`int`, *optional*, defaults to 32):
|
||||
Number of hidden layers in the model.
|
||||
layer_norm_epsilon (`float`, *optional*, defaults to 1e-05):
|
||||
The epsilon to use in the layer normalization layers.
|
||||
pad_token_id (`int`, *optional*, defaults to 0):
|
||||
Padding token id.
|
||||
bos_token_id (`int`, *optional*, defaults to 0):
|
||||
The id of the beginning of sentence token in the vocabulary.
|
||||
eos_token_id (`int`, *optional*, defaults to 0):
|
||||
The id of the end of sentence token in the vocabulary.
|
||||
expand (`int`, *optional*, defaults to 2): Expanding factor used to determine the intermediate size.
|
||||
conv_kernel (`int`, *optional*, defaults to 4): Size of the convolution kernel.
|
||||
use_bias (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to use bias in ["in_proj", "out_proj"] of the mixer block
|
||||
use_conv_bias (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to use bias in the convolution layer of the mixer block.
|
||||
hidden_act (`str`, *optional*, defaults to `"silu"`):
|
||||
The non-linear activation function (function or string) in the decoder.
|
||||
initializer_range (`float`, *optional*, defaults to 0.1):
|
||||
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
||||
residual_in_fp32 (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not residuals should be in `float32`.
|
||||
If set to `False` residuals will keep the same `dtype` as the rest of the model
|
||||
time_step_rank (`Union[int,str]`, *optional*, defaults to `"auto"`):
|
||||
Rank of the the discretization projection matrix.
|
||||
`"auto"` means that it will default to `math.ceil(self.hidden_size / 16)`
|
||||
time_step_scale (`float`, *optional*, defaults to 1.0):
|
||||
Scale used used to scale `dt_proj.bias`.
|
||||
time_step_min (`float`, *optional*, defaults to 0.001):
|
||||
Minimum `time_step` used to bound `dt_proj.bias`.
|
||||
time_step_max (`float`, *optional*, defaults to 0.1):
|
||||
Maximum `time_step` used to bound `dt_proj.bias`.
|
||||
time_step_init_scheme (`float`, *optional*, defaults to `"random"`):
|
||||
Init scheme used for `dt_proj.weight`. Should be one of `["random","uniform"]`
|
||||
time_step_floor (`float`, *optional*, defaults to 0.0001):
|
||||
Minimum clamping value of the `dt_proj.bias` layer initialization.
|
||||
rescale_prenorm_residual (`bool`, *optional*, defaults to `False`):
|
||||
Whether or not to rescale `out_proj` weights when initializing.
|
||||
use_cache (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not the cache should be used.
|
||||
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
>>> from transformers import MambaConfig, MambaModel
|
||||
|
||||
>>> # Initializing a Mamba configuration
|
||||
>>> configuration = MambaConfig()
|
||||
|
||||
>>> # Initializing a model (with random weights) from the configuration
|
||||
>>> model = MambaModel(configuration)
|
||||
|
||||
>>> # Accessing the model configuration
|
||||
>>> configuration = model.config
|
||||
```"""
|
||||
|
||||
model_type = "mamba"
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size=32000,
|
||||
hidden_size=2048,
|
||||
state_size=16,
|
||||
num_hidden_layers=48,
|
||||
layer_norm_epsilon=1e-5,
|
||||
pad_token_id= 0,
|
||||
bos_token_id= 1,
|
||||
eos_token_id= 2,
|
||||
expand=2,
|
||||
conv_kernel=4,
|
||||
use_bias=False,
|
||||
use_conv_bias=True,
|
||||
hidden_act="silu",
|
||||
initializer_range=0.1,
|
||||
residual_in_fp32=False,
|
||||
time_step_rank="auto",
|
||||
time_step_scale=1.0,
|
||||
time_step_min=0.001,
|
||||
time_step_max=0.1,
|
||||
time_step_init_scheme="random",
|
||||
time_step_floor=1e-4,
|
||||
rescale_prenorm_residual=False,
|
||||
use_cache=True,
|
||||
fuse_norm: bool = True,
|
||||
fuse_cross_entropy: bool = True,
|
||||
tie_word_embeddings: bool = False,
|
||||
**kwargs,
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.hidden_size = hidden_size
|
||||
self.state_size = state_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.layer_norm_epsilon = layer_norm_epsilon
|
||||
self.conv_kernel = conv_kernel
|
||||
self.expand = expand
|
||||
self.intermediate_size = int(expand * self.hidden_size)
|
||||
self.bos_token_id = bos_token_id
|
||||
self.eos_token_id = eos_token_id
|
||||
self.pad_token_id = pad_token_id
|
||||
self.use_bias = use_bias
|
||||
self.use_conv_bias = use_conv_bias
|
||||
self.hidden_act = hidden_act
|
||||
self.initializer_range = initializer_range
|
||||
self.time_step_rank = math.ceil(self.hidden_size / 16) if time_step_rank == "auto" else time_step_rank
|
||||
self.time_step_scale = time_step_scale
|
||||
self.time_step_min = time_step_min
|
||||
self.time_step_max = time_step_max
|
||||
self.time_step_init_scheme = time_step_init_scheme
|
||||
self.time_step_floor = time_step_floor
|
||||
self.rescale_prenorm_residual = rescale_prenorm_residual
|
||||
self.residual_in_fp32 = residual_in_fp32
|
||||
self.use_cache = use_cache
|
||||
self.fuse_cross_entropy = fuse_cross_entropy
|
||||
self.fuse_norm = fuse_norm
|
||||
|
||||
super().__init__(bos_token_id=bos_token_id, eos_token_id=eos_token_id, pad_token_id=pad_token_id, tie_word_embeddings=tie_word_embeddings, **kwargs)
|
||||
605
finetune/lora/v6/fla/models/mamba/modeling_mamba.py
vendored
Normal file
605
finetune/lora/v6/fla/models/mamba/modeling_mamba.py
vendored
Normal file
@ -0,0 +1,605 @@
|
||||
# coding=utf-8
|
||||
# Copyright 2024 state-spaces/mamba org and HuggingFace Inc. team.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""PyTorch MAMBA model."""
|
||||
|
||||
import math
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Dict, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.utils.checkpoint
|
||||
from torch import nn
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import ModelOutput, logging
|
||||
|
||||
from fla.models.mamba.configuration_mamba import MambaConfig
|
||||
from fla.modules import FusedCrossEntropyLoss, RMSNorm
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
try:
|
||||
from mamba_ssm.ops.selective_scan_interface import (mamba_inner_fn,
|
||||
selective_scan_fn)
|
||||
from mamba_ssm.ops.triton.selective_state_update import \
|
||||
selective_state_update
|
||||
except ImportError:
|
||||
selective_state_update, selective_scan_fn, mamba_inner_fn = None, None, None
|
||||
|
||||
try:
|
||||
from causal_conv1d import causal_conv1d_fn, causal_conv1d_update
|
||||
except ImportError:
|
||||
causal_conv1d_update, causal_conv1d_fn = None, None
|
||||
|
||||
is_fast_path_available = all(
|
||||
(selective_state_update, selective_scan_fn, causal_conv1d_fn, causal_conv1d_update, mamba_inner_fn)
|
||||
)
|
||||
|
||||
|
||||
class MambaCache:
|
||||
def __init__(self, config, batch_size, dtype=torch.float16, device=None):
|
||||
self.seqlen_offset = 0
|
||||
self.dtype = dtype
|
||||
intermediate_size = config.intermediate_size
|
||||
ssm_state_size = config.state_size
|
||||
conv_kernel_size = config.conv_kernel
|
||||
|
||||
self.conv_states = {
|
||||
i: torch.zeros(batch_size, intermediate_size, conv_kernel_size, device=device, dtype=dtype)
|
||||
for i in range(config.num_hidden_layers)
|
||||
}
|
||||
self.ssm_states = {
|
||||
i: torch.zeros(batch_size, intermediate_size, ssm_state_size, device=device, dtype=dtype)
|
||||
for i in range(config.num_hidden_layers)
|
||||
}
|
||||
|
||||
|
||||
class MambaMixer(nn.Module):
|
||||
"""
|
||||
Compute ∆, A, B, C, and D the state space parameters and compute the `contextualized_states`.
|
||||
A, D are input independent (see Mamba paper [1] Section 3.5.2 "Interpretation of A" for why A isn't selective)
|
||||
∆, B, C are input-dependent (this is a key difference between Mamba and the linear time invariant S4,
|
||||
and is why Mamba is called **selective** state spaces)
|
||||
"""
|
||||
|
||||
def __init__(self, config, layer_idx):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
self.ssm_state_size = config.state_size
|
||||
self.conv_kernel_size = config.conv_kernel
|
||||
self.intermediate_size = config.intermediate_size
|
||||
self.time_step_rank = config.time_step_rank
|
||||
self.layer_idx = layer_idx
|
||||
self.use_conv_bias = config.use_conv_bias
|
||||
self.conv1d = nn.Conv1d(
|
||||
in_channels=self.intermediate_size,
|
||||
out_channels=self.intermediate_size,
|
||||
bias=config.use_conv_bias,
|
||||
kernel_size=config.conv_kernel,
|
||||
groups=self.intermediate_size,
|
||||
padding=config.conv_kernel - 1,
|
||||
)
|
||||
|
||||
self.activation = config.hidden_act
|
||||
self.act = ACT2FN[config.hidden_act]
|
||||
|
||||
# projection of the input hidden states
|
||||
self.in_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=config.use_bias)
|
||||
# selective projection used to make dt, B and C input dependant
|
||||
self.x_proj = nn.Linear(self.intermediate_size, self.time_step_rank + self.ssm_state_size * 2, bias=False)
|
||||
# time step projection (discretization)
|
||||
self.dt_proj = nn.Linear(self.time_step_rank, self.intermediate_size, bias=True)
|
||||
|
||||
# S4D real initialization. These are not discretized!
|
||||
# The core is to load them, compute the discrete states, then write the updated state. Keeps the memory bounded
|
||||
A = torch.arange(1, self.ssm_state_size + 1, dtype=torch.float32)[None, :]
|
||||
A = A.expand(self.intermediate_size, -1).contiguous()
|
||||
|
||||
self.A_log = nn.Parameter(torch.log(A))
|
||||
self.D = nn.Parameter(torch.ones(self.intermediate_size))
|
||||
self.out_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=config.use_bias)
|
||||
self.use_bias = config.use_bias
|
||||
|
||||
if not is_fast_path_available:
|
||||
logger.warning_once(
|
||||
"The fast path is not available because on of "
|
||||
"`(selective_state_update, selective_scan_fn, causal_conv1d_fn, causal_conv1d_update, mamba_inner_fn)`"
|
||||
" is None. Falling back to the naive implementation. "
|
||||
"To install follow https://github.com/state-spaces/mamba/#installation and"
|
||||
" https://github.com/Dao-AILab/causal-conv1d"
|
||||
)
|
||||
|
||||
def cuda_kernels_forward(self, hidden_states: torch.Tensor, cache_params: Optional[MambaCache] = None):
|
||||
# 1. Gated MLP's linear projection
|
||||
projected_states = self.in_proj(hidden_states).transpose(1, 2)
|
||||
|
||||
if self.training and cache_params is None: # Doesn't support outputting the states -> used for training
|
||||
contextualized_states = mamba_inner_fn(
|
||||
projected_states,
|
||||
self.conv1d.weight,
|
||||
self.conv1d.bias if self.use_conv_bias else None,
|
||||
self.x_proj.weight,
|
||||
self.dt_proj.weight,
|
||||
self.out_proj.weight,
|
||||
self.out_proj.bias.float() if self.use_bias else None,
|
||||
-torch.exp(self.A_log.float()),
|
||||
None, # input-dependent B
|
||||
None, # input-dependent C
|
||||
self.D.float(),
|
||||
delta_bias=self.dt_proj.bias.float(),
|
||||
delta_softplus=True,
|
||||
)
|
||||
|
||||
else:
|
||||
hidden_states, gate = projected_states.chunk(2, dim=1)
|
||||
|
||||
# 2. Convolution sequence transformation
|
||||
conv_weights = self.conv1d.weight.view(self.conv1d.weight.size(0), self.conv1d.weight.size(2))
|
||||
if cache_params is not None and cache_params.seqlen_offset > 0:
|
||||
hidden_states = causal_conv1d_update(
|
||||
hidden_states.squeeze(-1),
|
||||
cache_params.conv_states[self.layer_idx],
|
||||
conv_weights,
|
||||
self.conv1d.bias,
|
||||
self.activation,
|
||||
)
|
||||
hidden_states = hidden_states.unsqueeze(-1)
|
||||
else:
|
||||
if cache_params is not None:
|
||||
conv_states = nn.functional.pad(
|
||||
hidden_states, (self.conv_kernel_size - hidden_states.shape[-1], 0)
|
||||
)
|
||||
cache_params.conv_states[self.layer_idx].copy_(conv_states)
|
||||
hidden_states = causal_conv1d_fn(
|
||||
hidden_states, conv_weights, self.conv1d.bias, activation=self.activation
|
||||
)
|
||||
|
||||
# 3. State Space Model sequence transformation
|
||||
# 3.a. input varying initialization of time_step, B and C
|
||||
ssm_parameters = self.x_proj(hidden_states.transpose(1, 2))
|
||||
time_step, B, C = torch.split(
|
||||
ssm_parameters, [self.time_step_rank, self.ssm_state_size, self.ssm_state_size], dim=-1
|
||||
)
|
||||
discrete_time_step = self.dt_proj.weight @ time_step.transpose(1, 2)
|
||||
|
||||
A = -torch.exp(self.A_log.float())
|
||||
# 3.c perform the recurrence y ← SSM(A, B, C)(x)
|
||||
time_proj_bias = self.dt_proj.bias.float() if hasattr(self.dt_proj, "bias") else None
|
||||
if cache_params is not None and cache_params.seqlen_offset > 0:
|
||||
scan_outputs = selective_state_update(
|
||||
cache_params.ssm_states[self.layer_idx],
|
||||
hidden_states[..., 0],
|
||||
discrete_time_step[..., 0],
|
||||
A,
|
||||
B[:, 0],
|
||||
C[:, 0],
|
||||
self.D,
|
||||
gate[..., 0],
|
||||
time_proj_bias,
|
||||
dt_softplus=True,
|
||||
).unsqueeze(-1)
|
||||
else:
|
||||
scan_outputs, ssm_state = selective_scan_fn(
|
||||
hidden_states,
|
||||
discrete_time_step,
|
||||
A,
|
||||
B.transpose(1, 2),
|
||||
C.transpose(1, 2),
|
||||
self.D.float(),
|
||||
gate,
|
||||
time_proj_bias,
|
||||
delta_softplus=True,
|
||||
return_last_state=True,
|
||||
)
|
||||
if ssm_state is not None and cache_params is not None:
|
||||
cache_params.ssm_states[self.layer_idx].copy_(ssm_state)
|
||||
|
||||
# 4. Final linear projection
|
||||
contextualized_states = self.out_proj(scan_outputs.transpose(1, 2))
|
||||
return contextualized_states
|
||||
|
||||
# fmt: off
|
||||
def slow_forward(self, input_states, cache_params: Optional[MambaCache] = None):
|
||||
batch_size, seq_len, _ = input_states.shape
|
||||
dtype = input_states.dtype
|
||||
# 1. Gated MLP's linear projection
|
||||
# [batch, 2 * intermediate_size, seq_len]
|
||||
projected_states = self.in_proj(input_states).transpose(1, 2)
|
||||
hidden_states, gate = projected_states.chunk(2, dim=1)
|
||||
|
||||
# 2. Convolution sequence transformation
|
||||
if cache_params is not None:
|
||||
ssm_state = cache_params.ssm_states[self.layer_idx].clone()
|
||||
if cache_params.seqlen_offset > 0:
|
||||
# [batch, intermediate_size, conv_kernel_size]
|
||||
conv_state = cache_params.conv_states[self.layer_idx]
|
||||
conv_state = torch.roll(conv_state, shifts=-1, dims=-1)
|
||||
conv_state[:, :, -1] = hidden_states[:, :, 0]
|
||||
cache_params.conv_states[self.layer_idx].copy_(conv_state)
|
||||
hidden_states = torch.sum(conv_state * self.conv1d.weight[:, 0, :], dim=-1)
|
||||
if self.use_conv_bias:
|
||||
hidden_states += self.conv1d.bias
|
||||
# [batch, intermediate_size, 1] : decoding
|
||||
hidden_states = self.act(hidden_states).to(dtype).unsqueeze(-1)
|
||||
else:
|
||||
conv_state = nn.functional.pad(
|
||||
hidden_states,
|
||||
(self.conv_kernel_size - hidden_states.shape[-1], 0)
|
||||
)
|
||||
cache_params.conv_states[self.layer_idx].copy_(conv_state)
|
||||
# [batch, intermediate_size, seq_len]
|
||||
hidden_states = self.act(self.conv1d(hidden_states)[..., :seq_len])
|
||||
else:
|
||||
ssm_state = torch.zeros(
|
||||
(batch_size, self.intermediate_size, self.ssm_state_size),
|
||||
device=hidden_states.device, dtype=dtype
|
||||
)
|
||||
# [batch, intermediate_size, seq_len]
|
||||
hidden_states = self.act(self.conv1d(hidden_states)[..., :seq_len])
|
||||
|
||||
# 3. State Space Model sequence transformation
|
||||
# 3.a. Selection: [batch, seq_len, self.time_step_rank + self.ssm_state_size * 2]
|
||||
ssm_parameters = self.x_proj(hidden_states.transpose(1, 2))
|
||||
time_step, B, C = torch.split(
|
||||
ssm_parameters, [self.time_step_rank, self.ssm_state_size, self.ssm_state_size], dim=-1
|
||||
)
|
||||
# [batch, seq_len, intermediate_size]
|
||||
discrete_time_step = self.dt_proj(time_step)
|
||||
# [batch, intermediate_size, seq_len]
|
||||
discrete_time_step = nn.functional.softplus(discrete_time_step).transpose(1, 2)
|
||||
|
||||
# 3.b. Discretization: B and C to [batch, seq_len, intermediate_size, ssm_state_size] (SRAM)
|
||||
# [intermediate_size, ssm_state_size]
|
||||
A = -torch.exp(self.A_log.float())
|
||||
# [batch, intermediate_size, seq_len, ssm_state_size]
|
||||
discrete_A = torch.exp(A[None, :, None, :] * discrete_time_step[:, :, :, None])
|
||||
# [batch, intermediade_size, seq_len, ssm_state_size]
|
||||
discrete_B = discrete_time_step[:, :, :, None] * B[:, None, :, :].float()
|
||||
deltaB_u = discrete_B * hidden_states[:, :, :, None].float()
|
||||
|
||||
# 3.c perform the recurrence y ← SSM(A, B, C)(x)
|
||||
scan_outputs = []
|
||||
for i in range(seq_len):
|
||||
# [batch, intermediade_size, ssm_state]
|
||||
ssm_state = discrete_A[:, :, i, :] * ssm_state + deltaB_u[:, :, i, :]
|
||||
# [batch, intermediade_size, 1]
|
||||
scan_output = torch.matmul(ssm_state.to(dtype), C[:, i, :].unsqueeze(-1))
|
||||
scan_outputs.append(scan_output[:, :, 0])
|
||||
# [batch, seq_len, intermediade_size]
|
||||
scan_output = torch.stack(scan_outputs, dim=-1)
|
||||
scan_output = scan_output + (hidden_states * self.D[None, :, None])
|
||||
scan_output = (scan_output * self.act(gate))
|
||||
|
||||
if cache_params is not None:
|
||||
cache_params.ssm_states[self.layer_idx].copy_(ssm_state)
|
||||
|
||||
# 4. Final linear projection
|
||||
# [batch, seq_len, hidden_size]
|
||||
contextualized_states = self.out_proj(scan_output.transpose(1, 2))
|
||||
return contextualized_states
|
||||
# fmt: on
|
||||
|
||||
def forward(self, hidden_states, cache_params: Optional[MambaCache] = None):
|
||||
if is_fast_path_available and "cuda" in self.x_proj.weight.device.type:
|
||||
return self.cuda_kernels_forward(hidden_states, cache_params)
|
||||
return self.slow_forward(hidden_states, cache_params)
|
||||
|
||||
|
||||
class MambaBlock(nn.Module):
|
||||
def __init__(self, config, layer_idx):
|
||||
super().__init__()
|
||||
self.config = config
|
||||
self.layer_idx = layer_idx
|
||||
self.residual_in_fp32 = config.residual_in_fp32
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.layer_norm_epsilon)
|
||||
self.mixer = MambaMixer(config, layer_idx=layer_idx)
|
||||
|
||||
def forward(self, hidden_states, cache_params: Optional[MambaCache] = None):
|
||||
residual = hidden_states
|
||||
hidden_states = self.norm(hidden_states)
|
||||
# if self.residual_in_fp32:
|
||||
# residual = residual.to(torch.float32)
|
||||
hidden_states = self.mixer(hidden_states, cache_params=cache_params)
|
||||
hidden_states = residual + hidden_states
|
||||
return hidden_states
|
||||
|
||||
|
||||
class MambaPreTrainedModel(PreTrainedModel):
|
||||
"""
|
||||
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
||||
models.
|
||||
"""
|
||||
|
||||
config_class = MambaConfig
|
||||
base_model_prefix = "backbone"
|
||||
_no_split_modules = ["MambaBlock"]
|
||||
supports_gradient_checkpointing = True
|
||||
|
||||
def _init_weights(self, module):
|
||||
"""Initialize the weights."""
|
||||
if isinstance(module, MambaMixer):
|
||||
module.A_log._no_weight_decay = True
|
||||
module.D._no_weight_decay = True
|
||||
|
||||
dt_init_std = self.config.time_step_rank**-0.5 * self.config.time_step_scale
|
||||
if self.config.time_step_init_scheme == "constant":
|
||||
nn.init.constant_(module.dt_proj.weight, dt_init_std)
|
||||
elif self.config.time_step_init_scheme == "random":
|
||||
nn.init.uniform_(module.dt_proj.weight, -dt_init_std, dt_init_std)
|
||||
|
||||
dt = torch.exp(
|
||||
torch.rand(self.config.intermediate_size)
|
||||
* (math.log(self.config.time_step_max) - math.log(self.config.time_step_min))
|
||||
+ math.log(self.config.time_step_min)
|
||||
).clamp(min=self.config.time_step_floor)
|
||||
# # Inverse of softplus: https://github.com/pytorch/pytorch/issues/72759
|
||||
inv_dt = dt + torch.log(-torch.expm1(-dt))
|
||||
with torch.no_grad():
|
||||
module.dt_proj.bias.copy_(inv_dt)
|
||||
module.dt_proj.bias._no_reinit = True
|
||||
|
||||
if isinstance(module, nn.Linear):
|
||||
if module.bias is not None:
|
||||
if not getattr(module.bias, "_no_reinit", False):
|
||||
nn.init.zeros_(module.bias)
|
||||
elif isinstance(module, nn.Embedding):
|
||||
nn.init.normal_(module.weight, std=self.config.initializer_range)
|
||||
|
||||
if self.config.rescale_prenorm_residual:
|
||||
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
||||
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
||||
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
||||
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
||||
#
|
||||
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
||||
for name, p in module.named_parameters():
|
||||
if name in ["out_proj.weight"]:
|
||||
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
||||
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
|
||||
# We need to reinit p since this code could be called multiple times
|
||||
# Having just p *= scale would repeatedly scale it down
|
||||
nn.init.kaiming_uniform_(p, a=math.sqrt(5))
|
||||
with torch.no_grad():
|
||||
p /= math.sqrt(self.config.num_layers)
|
||||
|
||||
|
||||
@dataclass
|
||||
class MambaOutput(ModelOutput):
|
||||
"""
|
||||
Class for the MAMBA model outputs.
|
||||
|
||||
Args:
|
||||
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
||||
Sequence of hidden-states at the output of the last layer of the model.
|
||||
cache_params (`MambaCache`):
|
||||
The state of the model at the last time step. Can be used in a forward method with the next `input_ids` to
|
||||
avoid providing the old `input_ids`.
|
||||
|
||||
Includes both the State space model state matrices after the selective scan, and the Convolutional states
|
||||
hidden_states (`tuple(torch.FloatTensor)`, *optional*,
|
||||
returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
|
||||
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
|
||||
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
|
||||
"""
|
||||
|
||||
last_hidden_state: Optional[torch.FloatTensor] = None
|
||||
cache_params: Optional[MambaCache] = None
|
||||
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class MambaCausalLMOutput(ModelOutput):
|
||||
"""
|
||||
Base class for causal language model (or autoregressive) outputs.
|
||||
|
||||
Args:
|
||||
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
|
||||
Language modeling loss (for next-token prediction).
|
||||
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
|
||||
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
|
||||
cache_params (`MambaCache`):
|
||||
The state of the model at the last time step. Can be used in a forward method with the next `input_ids` to
|
||||
avoid providing the old `input_ids`.
|
||||
|
||||
Includes both the State space model state matrices after the selective scan, and the Convolutional states
|
||||
hidden_states (`tuple(torch.FloatTensor)`, *optional*,
|
||||
returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
|
||||
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
|
||||
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
|
||||
|
||||
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
|
||||
"""
|
||||
|
||||
loss: Optional[torch.FloatTensor] = None
|
||||
logits: Optional[torch.FloatTensor] = None
|
||||
cache_params: Optional[MambaCache] = None
|
||||
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
|
||||
|
||||
|
||||
class MambaModel(MambaPreTrainedModel):
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
|
||||
self.embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
|
||||
self.layers = nn.ModuleList([MambaBlock(config, layer_idx=idx) for idx in range(config.num_hidden_layers)])
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
self.norm_f = RMSNorm(config.hidden_size, eps=config.layer_norm_epsilon)
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def set_input_embeddings(self, new_embeddings):
|
||||
self.embeddings = new_embeddings
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
inputs_embeds: Optional[torch.LongTensor] = None,
|
||||
cache_params: Optional[MambaCache] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
**kwargs, # `attention_mask` is passed by the tokenizer and we don't want it
|
||||
) -> Union[Tuple, MambaOutput]:
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
use_cache = use_cache if use_cache is not None else (self.config.use_cache if not self.training else False)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
if (input_ids is None) ^ (inputs_embeds is not None): # ^ is python for xor
|
||||
raise ValueError(
|
||||
"You cannot specify both input_ids and inputs_embeds at the same time, and must specify either one"
|
||||
)
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
|
||||
if self.gradient_checkpointing and self.training and use_cache:
|
||||
use_cache = False
|
||||
|
||||
if cache_params is None and use_cache:
|
||||
cache_params = MambaCache(
|
||||
self.config, inputs_embeds.size(0), device=inputs_embeds.device, dtype=inputs_embeds.dtype
|
||||
)
|
||||
|
||||
hidden_states = inputs_embeds
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
for mixer_block in self.layers:
|
||||
if self.gradient_checkpointing and self.training:
|
||||
hidden_states = self._gradient_checkpointing_func(mixer_block.__call__, hidden_states, cache_params)
|
||||
else:
|
||||
hidden_states = mixer_block(hidden_states, cache_params=cache_params)
|
||||
|
||||
if output_hidden_states:
|
||||
all_hidden_states = all_hidden_states + (hidden_states,)
|
||||
|
||||
if use_cache:
|
||||
cache_params.seqlen_offset += inputs_embeds.shape[1]
|
||||
|
||||
hidden_states = self.norm_f(hidden_states)
|
||||
|
||||
if output_hidden_states:
|
||||
all_hidden_states = all_hidden_states + (hidden_states,)
|
||||
|
||||
if not return_dict:
|
||||
return tuple(v for v in [hidden_states, cache_params, all_hidden_states] if v is not None)
|
||||
|
||||
return MambaOutput(
|
||||
last_hidden_state=hidden_states,
|
||||
cache_params=cache_params if use_cache else None,
|
||||
hidden_states=all_hidden_states,
|
||||
)
|
||||
|
||||
|
||||
class MambaForCausalLM(MambaPreTrainedModel):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.backbone = MambaModel(config)
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.backbone.get_input_embeddings()
|
||||
|
||||
def set_input_embeddings(self, new_embeddings):
|
||||
return self.backbone.set_input_embeddings(new_embeddings)
|
||||
|
||||
def _update_model_kwargs_for_generation(
|
||||
self, outputs: ModelOutput, model_kwargs: Dict[str, Any], **kwargs
|
||||
) -> Dict[str, Any]:
|
||||
model_kwargs["cache_params"] = outputs.get("cache_params", None)
|
||||
return model_kwargs
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self, input_ids, cache_params: Optional[MambaCache] = None, inputs_embeds=None, attention_mask=None, **kwargs
|
||||
):
|
||||
# only last token for inputs_ids if the state is passed along.
|
||||
if cache_params is not None:
|
||||
input_ids = input_ids[:, -1].unsqueeze(-1)
|
||||
|
||||
if inputs_embeds is not None and cache_params is None:
|
||||
model_inputs = {"inputs_embeds": inputs_embeds}
|
||||
else:
|
||||
model_inputs = {"input_ids": input_ids}
|
||||
|
||||
model_inputs["cache_params"] = cache_params
|
||||
return model_inputs
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
cache_params: Optional[MambaCache] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
**kwargs, # for now we need this for generation
|
||||
) -> Union[Tuple, MambaCausalLMOutput]:
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
|
||||
`labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
|
||||
are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
|
||||
"""
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
mamba_outputs = self.backbone(
|
||||
input_ids,
|
||||
cache_params=cache_params,
|
||||
inputs_embeds=inputs_embeds,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
use_cache=use_cache,
|
||||
)
|
||||
hidden_states = mamba_outputs[0]
|
||||
logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
if self.config.fuse_cross_entropy:
|
||||
loss_fct = FusedCrossEntropyLoss(inplace_backward=True)
|
||||
else:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
labels = torch.cat((labels[..., 1:], torch.full_like(labels[:, :1], loss_fct.ignore_index)), 1)
|
||||
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + mamba_outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return MambaCausalLMOutput(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
cache_params=mamba_outputs.cache_params,
|
||||
hidden_states=mamba_outputs.hidden_states,
|
||||
)
|
||||
13
finetune/lora/v6/fla/models/retnet/__init__.py
vendored
Normal file
13
finetune/lora/v6/fla/models/retnet/__init__.py
vendored
Normal file
@ -0,0 +1,13 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
||||
|
||||
from fla.models.retnet.configuration_retnet import RetNetConfig
|
||||
from fla.models.retnet.modeling_retnet import RetNetForCausalLM, RetNetModel
|
||||
|
||||
AutoConfig.register(RetNetConfig.model_type, RetNetConfig)
|
||||
AutoModel.register(RetNetConfig, RetNetModel)
|
||||
AutoModelForCausalLM.register(RetNetConfig, RetNetForCausalLM)
|
||||
|
||||
|
||||
__all__ = ['RetNetConfig', 'RetNetForCausalLM', 'RetNetModel']
|
||||
76
finetune/lora/v6/fla/models/retnet/configuration_retnet.py
vendored
Normal file
76
finetune/lora/v6/fla/models/retnet/configuration_retnet.py
vendored
Normal file
@ -0,0 +1,76 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class RetNetConfig(PretrainedConfig):
|
||||
|
||||
model_type = 'retnet'
|
||||
keys_to_ignore_at_inference = ['past_key_values']
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size: int = 32000,
|
||||
hidden_size: int = 2048,
|
||||
expand_k: int = 1,
|
||||
expand_v: int = 2,
|
||||
hidden_ratio: Optional[int] = 2,
|
||||
intermediate_size: Optional[int] = None,
|
||||
num_hidden_layers: int = 24,
|
||||
num_heads: int = 8,
|
||||
num_kv_heads: Optional[int] = None,
|
||||
feature_map: Optional[str] = None,
|
||||
attn_mode: str = "fused_chunk",
|
||||
hidden_act: str = "swish",
|
||||
use_short_conv: bool = False,
|
||||
conv_size: int = 4,
|
||||
share_conv_kernel: bool = True,
|
||||
use_output_gate: bool = True,
|
||||
max_position_embeddings: int = 2048,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-6,
|
||||
use_cache: bool = True,
|
||||
pad_token_id: int = None,
|
||||
bos_token_id: int = 1,
|
||||
eos_token_id: int = 2,
|
||||
tie_word_embeddings: bool = False,
|
||||
initializer_range: float = 0.02,
|
||||
fuse_norm: bool = True,
|
||||
fuse_cross_entropy: bool = True,
|
||||
**kwargs
|
||||
) -> RetNetConfig:
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_heads = num_heads
|
||||
self.num_kv_heads = num_kv_heads
|
||||
self.feature_map = feature_map
|
||||
self.attn_mode = attn_mode
|
||||
self.hidden_act = hidden_act
|
||||
self.use_short_conv = use_short_conv
|
||||
self.conv_size = conv_size
|
||||
self.share_conv_kernel = share_conv_kernel
|
||||
self.use_output_gate = use_output_gate
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.norm_eps = norm_eps
|
||||
self.use_cache = use_cache
|
||||
self.initializer_range = initializer_range
|
||||
self.fuse_norm = fuse_norm
|
||||
self.fuse_cross_entropy = fuse_cross_entropy
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
410
finetune/lora/v6/fla/models/retnet/modeling_retnet.py
vendored
Normal file
410
finetune/lora/v6/fla/models/retnet/modeling_retnet.py
vendored
Normal file
@ -0,0 +1,410 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.checkpoint
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast)
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import logging
|
||||
|
||||
from fla.layers.multiscale_retention import MultiScaleRetention
|
||||
from fla.models.retnet.configuration_retnet import RetNetConfig
|
||||
from fla.models.utils import RecurrentCache
|
||||
from fla.modules import FusedCrossEntropyLoss, RMSNorm
|
||||
from fla.modules.activations import swiglu_linear
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class RetNetMLP(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
hidden_ratio: Optional[int] = None,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = 'swish'
|
||||
) -> RetNetMLP:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
# the final number of params is `hidden_ratio * hidden_size^2`
|
||||
# `intermediate_size` is chosen to be a multiple of 256 closest to `2/3 * hidden_size * hidden_ratio`
|
||||
if hidden_ratio is None:
|
||||
hidden_ratio = 4
|
||||
if intermediate_size is None:
|
||||
intermediate_size = int(hidden_size * hidden_ratio * 2 / 3)
|
||||
intermediate_size = 256 * ((intermediate_size + 256 - 1) // 256)
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
y = self.gate_proj(x)
|
||||
gate, y = y.chunk(2, -1)
|
||||
return swiglu_linear(gate, y, self.down_proj.weight, self.down_proj.bias)
|
||||
|
||||
|
||||
class RetNetBlock(nn.Module):
|
||||
def __init__(self, config: RetNetConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.attn_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.attn = MultiScaleRetention(
|
||||
mode=config.attn_mode,
|
||||
hidden_size=config.hidden_size,
|
||||
expand_k=config.expand_k,
|
||||
expand_v=config.expand_v,
|
||||
num_heads=config.num_heads,
|
||||
num_kv_heads=config.num_kv_heads,
|
||||
feature_map=config.feature_map,
|
||||
use_output_gate=config.use_output_gate,
|
||||
gate_fn=config.hidden_act,
|
||||
elementwise_affine=config.elementwise_affine,
|
||||
norm_eps=config.norm_eps,
|
||||
fuse_norm=config.fuse_norm,
|
||||
layer_idx=layer_idx
|
||||
)
|
||||
self.mlp_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.mlp = RetNetMLP(
|
||||
hidden_size=config.hidden_size,
|
||||
hidden_ratio=config.hidden_ratio,
|
||||
intermediate_size=config.intermediate_size,
|
||||
hidden_act=config.hidden_act
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
hidden_states = self.attn_norm(hidden_states)
|
||||
hidden_states, attentions, past_key_values = self.attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
hidden_states, residual = self.mlp_norm(hidden_states, residual, True)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states, attentions, past_key_values)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class RetNetPreTrainedModel(PreTrainedModel):
|
||||
|
||||
config_class = RetNetConfig
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ['RetNetBlock']
|
||||
|
||||
def __init__(self, *inputs, **kwargs):
|
||||
super().__init__(*inputs, **kwargs)
|
||||
|
||||
def _init_weights(
|
||||
self,
|
||||
module: nn.Module,
|
||||
rescale_prenorm_residual: bool = True,
|
||||
num_residuals_per_layer: int = 2,
|
||||
):
|
||||
if isinstance(module, (nn.Linear, nn.Conv1d)):
|
||||
# Slightly different from the TF version which uses truncated_normal for initialization
|
||||
# cf https://github.com/pytorch/pytorch/pull/5617
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
elif isinstance(module, nn.Embedding):
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
|
||||
if rescale_prenorm_residual:
|
||||
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
||||
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
||||
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
||||
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
||||
#
|
||||
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
||||
for name, p in module.named_parameters():
|
||||
if name in ["o_proj.weight", "down_proj.weight"]:
|
||||
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
||||
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
|
||||
# We need to reinit p since this code could be called multiple times
|
||||
# Having just p *= scale would repeatedly scale it down
|
||||
with torch.no_grad():
|
||||
p /= math.sqrt(num_residuals_per_layer * self.config.num_hidden_layers)
|
||||
|
||||
|
||||
class RetNetModel(RetNetPreTrainedModel):
|
||||
|
||||
def __init__(self, config: RetNetConfig):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
self.layers = nn.ModuleList(
|
||||
[RetNetBlock(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
|
||||
)
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.norm_eps)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embeddings = value
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None, # noqa
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None
|
||||
) -> Union[Tuple, BaseModelOutputWithPast]:
|
||||
if output_attentions:
|
||||
warnings.warn(
|
||||
"`RetNetModel` does not support output attention weights now, so `output_attentions` is set to `False`."
|
||||
)
|
||||
output_attentions = False
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
use_cache = use_cache if use_cache is not None else (self.config.use_cache if not self.training else False)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size, seq_len = input_ids.shape[:2]
|
||||
elif inputs_embeds is not None:
|
||||
batch_size, seq_len = inputs_embeds.shape[:2]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
if use_cache:
|
||||
if past_key_values is None:
|
||||
past_key_values = [layer.attn.init_state(batch_size) for layer in self.layers]
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
if use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_attns = () if output_attentions else None
|
||||
for layer in self.layers:
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
hidden_states, attentions, past_key_values = self._gradient_checkpointing_func(
|
||||
layer.__call__,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
use_cache,
|
||||
output_attentions
|
||||
)
|
||||
else:
|
||||
hidden_states, attentions, past_key_values = layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
|
||||
if output_attentions:
|
||||
all_attns += (attentions,)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
next_cache = None
|
||||
if use_cache:
|
||||
next_cache = past_key_values.to_legacy_cache()
|
||||
if not return_dict:
|
||||
return tuple(x for x in [hidden_states, next_cache, all_hidden_states, all_attns] if x is not None)
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_attns
|
||||
)
|
||||
|
||||
|
||||
class RetNetForCausalLM(RetNetPreTrainedModel):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = RetNetModel(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embeddings = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
def generate(self, *args, **kwargs):
|
||||
try:
|
||||
return super().generate(*args, **kwargs)
|
||||
except AttributeError as exception:
|
||||
# Expected exception: "AttributeError: '(object name)' object has no attribute 'past_key_values'"
|
||||
if 'past_key_values' in str(exception):
|
||||
raise AttributeError(
|
||||
f"You tried to call `generate` with a decoding strategy that manipulates `past_key_values`, "
|
||||
f"which is not supported for {self.__class__.__name__}. "
|
||||
f"Try another generation strategy instead. "
|
||||
f"For the available generation strategies, check this doc: "
|
||||
f"https://huggingface.co/docs/transformers/en/generation_strategies#decoding-strategies"
|
||||
)
|
||||
else:
|
||||
raise exception
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
past_key_values: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
**kwargs
|
||||
):
|
||||
# only last token for `inputs_ids` if the `past_key_values` is passed along.
|
||||
if past_key_values is not None:
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values, input_ids.shape[1] - 1)
|
||||
input_ids, attention_mask = input_ids[:, -1:], attention_mask[:, -1:]
|
||||
|
||||
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
||||
if inputs_embeds is not None and past_key_values is None:
|
||||
model_inputs = {'inputs_embeds': inputs_embeds}
|
||||
else:
|
||||
# The `contiguous()` here is necessary to have a static stride during decoding. torchdynamo otherwise
|
||||
# recompiles graphs as the stride of the inputs is a guard.
|
||||
# Ref: https://github.com/huggingface/transformers/pull/29114
|
||||
# TODO: use `next_tokens` directly instead.
|
||||
model_inputs = {'input_ids': input_ids.contiguous()}
|
||||
|
||||
model_inputs.update({
|
||||
'past_key_values': past_key_values,
|
||||
'use_cache': kwargs.get('use_cache'),
|
||||
'attention_mask': attention_mask,
|
||||
})
|
||||
return model_inputs
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
inputs_embeds=inputs_embeds,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
if self.config.fuse_cross_entropy:
|
||||
loss_fct = FusedCrossEntropyLoss(inplace_backward=True)
|
||||
else:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
labels = torch.cat((labels[..., 1:], torch.full_like(labels[:, :1], loss_fct.ignore_index)), 1)
|
||||
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
13
finetune/lora/v6/fla/models/rwkv6/__init__.py
vendored
Normal file
13
finetune/lora/v6/fla/models/rwkv6/__init__.py
vendored
Normal file
@ -0,0 +1,13 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
||||
|
||||
from fla.models.rwkv6.configuration_rwkv6 import RWKV6Config
|
||||
from fla.models.rwkv6.modeling_rwkv6 import RWKV6ForCausalLM, RWKV6Model
|
||||
|
||||
AutoConfig.register(RWKV6Config.model_type, RWKV6Config)
|
||||
AutoModel.register(RWKV6Config, RWKV6Model)
|
||||
AutoModelForCausalLM.register(RWKV6Config, RWKV6ForCausalLM)
|
||||
|
||||
|
||||
__all__ = ['RWKV6Config', 'RWKV6ForCausalLM', 'RWKV6Model']
|
||||
66
finetune/lora/v6/fla/models/rwkv6/configuration_rwkv6.py
vendored
Normal file
66
finetune/lora/v6/fla/models/rwkv6/configuration_rwkv6.py
vendored
Normal file
@ -0,0 +1,66 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class RWKV6Config(PretrainedConfig):
|
||||
|
||||
model_type = 'rwkv6'
|
||||
keys_to_ignore_at_inference = ['past_key_values']
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
attn_mode: str = "chunk",
|
||||
vocab_size: int = 32000,
|
||||
hidden_size: int = 2048,
|
||||
expand_k: int = 0.5,
|
||||
expand_v: int = 1,
|
||||
hidden_ratio: Optional[int] = 3.5,
|
||||
intermediate_size: Optional[int] = None,
|
||||
use_glu: Optional[bool] = False,
|
||||
num_hidden_layers: int = 24,
|
||||
num_heads: int = 4,
|
||||
proj_low_rank_dim: int = 32,
|
||||
gate_low_rank_dim: int = 64,
|
||||
hidden_act: str = "sqrelu",
|
||||
max_position_embeddings: int = 2048,
|
||||
eps: float = 1e-6,
|
||||
use_cache: bool = True,
|
||||
pad_token_id: int = None,
|
||||
bos_token_id: int = 1,
|
||||
eos_token_id: int = 2,
|
||||
tie_word_embeddings: bool = False,
|
||||
initializer_range: float = 0.02,
|
||||
fuse_norm: bool = True,
|
||||
fuse_cross_entropy: bool = True,
|
||||
**kwargs
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.expand_k = expand_k
|
||||
self.expand_v = expand_v
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
self.use_glu = use_glu
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_heads = num_heads
|
||||
self.proj_low_rank_dim = proj_low_rank_dim
|
||||
self.gate_low_rank_dim = gate_low_rank_dim
|
||||
self.attn_mode = attn_mode
|
||||
self.hidden_act = hidden_act
|
||||
self.eps = eps
|
||||
self.use_cache = use_cache
|
||||
self.initializer_range = initializer_range
|
||||
self.fuse_norm = fuse_norm
|
||||
self.fuse_cross_entropy = fuse_cross_entropy
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
443
finetune/lora/v6/fla/models/rwkv6/modeling_rwkv6.py
vendored
Normal file
443
finetune/lora/v6/fla/models/rwkv6/modeling_rwkv6.py
vendored
Normal file
@ -0,0 +1,443 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.utils.checkpoint
|
||||
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast)
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import logging
|
||||
|
||||
from fla.layers.rwkv6 import LerpLinear, RWKV6Attention
|
||||
from fla.models.rwkv6.configuration_rwkv6 import RWKV6Config
|
||||
from fla.models.utils import RecurrentCache
|
||||
from fla.modules import FusedCrossEntropyLoss, LayerNorm
|
||||
from fla.modules.activations import ACT2FN, swiglu_linear
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class RWKV6FeedForward(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
hidden_ratio: Optional[int] = None,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = 'sqrelu',
|
||||
layer_idx: int = None
|
||||
) -> RWKV6FeedForward:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
if hidden_ratio is None:
|
||||
hidden_ratio = 3.5
|
||||
if intermediate_size is None:
|
||||
intermediate_size = int(hidden_size * hidden_ratio)
|
||||
intermediate_size = 32 * ((intermediate_size + 32 - 1) // 32)
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
|
||||
self.time_shift = nn.ZeroPad2d((0, 0, 1, -1))
|
||||
|
||||
self.key = LerpLinear(hidden_size, intermediate_size)
|
||||
self.value = nn.Linear(intermediate_size, hidden_size)
|
||||
self.receptance = LerpLinear(hidden_size, hidden_size)
|
||||
self.act_fn = ACT2FN[hidden_act]
|
||||
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
def forward(self, x: torch.Tensor, state: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
if state is not None:
|
||||
raise NotImplementedError("Past state is not yet supported in `RWKV6FeedForward`.")
|
||||
shifted = self.time_shift(x)
|
||||
if len(shifted.shape) == 2:
|
||||
shifted = shifted.unsqueeze(1)
|
||||
delta = shifted - x
|
||||
key = self.act_fn(self.key(x, delta))
|
||||
value = self.value(key)
|
||||
receptance = self.receptance(x, delta)
|
||||
return receptance.sigmoid() * value
|
||||
|
||||
|
||||
class RWKV6GLU(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
hidden_ratio: Optional[int] = None,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = 'swish',
|
||||
layer_idx: int = None
|
||||
) -> RWKV6GLU:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
# the final number of params is `hidden_ratio * hidden_size^2`
|
||||
# `intermediate_size` is chosen to be a multiple of 256 closest to `2/3 * hidden_size * hidden_ratio`
|
||||
if hidden_ratio is None:
|
||||
hidden_ratio = 4
|
||||
if intermediate_size is None:
|
||||
intermediate_size = int(hidden_size * hidden_ratio * 2 / 3)
|
||||
intermediate_size = 256 * ((intermediate_size + 256 - 1) // 256)
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
y = self.gate_proj(x)
|
||||
gate, y = y.chunk(2, -1)
|
||||
return swiglu_linear(gate, y, self.down_proj.weight, self.down_proj.bias)
|
||||
|
||||
|
||||
class RWKV6Block(nn.Module):
|
||||
def __init__(self, config: RWKV6Config, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.attn_norm = LayerNorm(hidden_size=config.hidden_size, eps=config.eps)
|
||||
self.attn = RWKV6Attention(
|
||||
mode=config.attn_mode,
|
||||
hidden_size=config.hidden_size,
|
||||
expand_k=config.expand_k,
|
||||
expand_v=config.expand_v,
|
||||
num_heads=config.num_heads,
|
||||
proj_low_rank_dim=config.proj_low_rank_dim,
|
||||
gate_low_rank_dim=config.gate_low_rank_dim,
|
||||
eps=config.eps,
|
||||
fuse_norm=config.fuse_norm,
|
||||
layer_idx=layer_idx
|
||||
)
|
||||
self.ffn_norm = LayerNorm(hidden_size=config.hidden_size, eps=config.eps)
|
||||
self.ffn = (RWKV6GLU if config.use_glu else RWKV6FeedForward)(
|
||||
hidden_size=config.hidden_size,
|
||||
hidden_ratio=config.hidden_ratio,
|
||||
intermediate_size=config.intermediate_size,
|
||||
hidden_act=config.hidden_act,
|
||||
layer_idx=layer_idx
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
residual = hidden_states
|
||||
hidden_states = self.attn_norm(hidden_states)
|
||||
hidden_states, attentions, past_key_values = self.attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
hidden_states, residual = self.ffn_norm(hidden_states, residual, True)
|
||||
hidden_states = self.ffn(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states, attentions, past_key_values)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class RWKV6PreTrainedModel(PreTrainedModel):
|
||||
|
||||
config_class = RWKV6Config
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ['RWKV6Block']
|
||||
|
||||
def __init__(self, *inputs, **kwargs):
|
||||
super().__init__(*inputs, **kwargs)
|
||||
|
||||
def _init_weights(
|
||||
self,
|
||||
module: nn.Module,
|
||||
rescale_prenorm_residual: bool = True,
|
||||
num_residuals_per_layer: int = 2,
|
||||
):
|
||||
if isinstance(module, (nn.Linear, nn.Conv1d)):
|
||||
# Slightly different from the TF version which uses truncated_normal for initialization
|
||||
# cf https://github.com/pytorch/pytorch/pull/5617
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
elif isinstance(module, nn.Parameter):
|
||||
nn.init.normal_(module, mean=0.0, std=self.config.initializer_range)
|
||||
elif isinstance(module, nn.Embedding):
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
|
||||
if rescale_prenorm_residual:
|
||||
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
||||
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
||||
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
||||
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
||||
#
|
||||
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
||||
for name, p in module.named_parameters():
|
||||
if name in ["o_proj.weight", "down_proj.weight"]:
|
||||
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
||||
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
|
||||
# We need to reinit p since this code could be called multiple times
|
||||
# Having just p *= scale would repeatedly scale it down
|
||||
with torch.no_grad():
|
||||
p /= math.sqrt(num_residuals_per_layer * self.config.num_hidden_layers)
|
||||
|
||||
|
||||
class RWKV6Model(RWKV6PreTrainedModel):
|
||||
|
||||
def __init__(self, config: RWKV6Config):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
self.layers = nn.ModuleList([RWKV6Block(config, layer_idx) for layer_idx in range(config.num_hidden_layers)])
|
||||
self.norm = LayerNorm(config.hidden_size, eps=config.eps)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embeddings = value
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None, # noqa
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None
|
||||
) -> Union[Tuple, BaseModelOutputWithPast]:
|
||||
if output_attentions:
|
||||
warnings.warn("`RWKV6Model` does not `output_attentions` now, setting it to `False`.")
|
||||
output_attentions = False
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
use_cache = use_cache if use_cache is not None else (self.config.use_cache if not self.training else False)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size = input_ids.shape[0]
|
||||
elif inputs_embeds is not None:
|
||||
batch_size = inputs_embeds.shape[0]
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
if use_cache:
|
||||
if past_key_values is None:
|
||||
past_key_values = [layer.attn.init_state(batch_size) for layer in self.layers]
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
if use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_attns = () if output_attentions else None
|
||||
for layer in self.layers:
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
hidden_states, attentions, past_key_values = self._gradient_checkpointing_func(
|
||||
layer.__call__,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
use_cache,
|
||||
output_attentions
|
||||
)
|
||||
else:
|
||||
hidden_states, attentions, past_key_values = layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
|
||||
if output_attentions:
|
||||
all_attns += (attentions,)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
next_cache = None
|
||||
if use_cache:
|
||||
next_cache = past_key_values.to_legacy_cache()
|
||||
if not return_dict:
|
||||
return tuple(x for x in [hidden_states, next_cache, all_hidden_states, all_attns] if x is not None)
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_attns
|
||||
)
|
||||
|
||||
|
||||
class RWKV6ForCausalLM(RWKV6PreTrainedModel):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = RWKV6Model(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embeddings = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
def generate(self, *args, **kwargs):
|
||||
try:
|
||||
return super().generate(*args, **kwargs)
|
||||
except AttributeError as exception:
|
||||
if 'past_key_values' in str(exception):
|
||||
raise AttributeError(
|
||||
f"You tried to call `generate` with a decoding strategy that manipulates `past_key_values`, "
|
||||
f"which is not supported for {self.__class__.__name__}. "
|
||||
f"Try another generation strategy instead. "
|
||||
f"For the available generation strategies, check this doc: "
|
||||
f"https://huggingface.co/docs/transformers/en/generation_strategies#decoding-strategies"
|
||||
)
|
||||
else:
|
||||
raise exception
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
**kwargs
|
||||
):
|
||||
# only last token for `inputs_ids` if the `past_key_values` is passed along.
|
||||
if past_key_values is not None:
|
||||
if not isinstance(past_key_values, RecurrentCache):
|
||||
past_key_values = RecurrentCache.from_legacy_cache(past_key_values, input_ids.shape[1] - 1)
|
||||
input_ids, attention_mask = input_ids[:, -1:], attention_mask[:, -1:]
|
||||
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
||||
if inputs_embeds is not None and past_key_values is None:
|
||||
model_inputs = {'inputs_embeds': inputs_embeds}
|
||||
else:
|
||||
# The `contiguous()` here is necessary to have a static stride during decoding. torchdynamo otherwise
|
||||
# recompiles graphs as the stride of the inputs is a guard.
|
||||
# Ref: https://github.com/huggingface/transformers/pull/29114
|
||||
# TODO: use `next_tokens` directly instead.
|
||||
model_inputs = {'input_ids': input_ids.contiguous()}
|
||||
|
||||
model_inputs.update({
|
||||
'past_key_values': past_key_values,
|
||||
'use_cache': kwargs.get('use_cache'),
|
||||
'attention_mask': attention_mask,
|
||||
})
|
||||
return model_inputs
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[List[torch.Tensor]]] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
inputs_embeds=inputs_embeds,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
if self.config.fuse_cross_entropy:
|
||||
loss_fct = FusedCrossEntropyLoss(inplace_backward=True)
|
||||
else:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
labels = torch.cat((labels[..., 1:], torch.full_like(labels[:, :1], loss_fct.ignore_index)), 1)
|
||||
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
14
finetune/lora/v6/fla/models/transformer/__init__.py
vendored
Normal file
14
finetune/lora/v6/fla/models/transformer/__init__.py
vendored
Normal file
@ -0,0 +1,14 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM
|
||||
|
||||
from fla.models.transformer.configuration_transformer import TransformerConfig
|
||||
from fla.models.transformer.modeling_transformer import (
|
||||
TransformerForCausalLM, TransformerModel)
|
||||
|
||||
AutoConfig.register(TransformerConfig.model_type, TransformerConfig)
|
||||
AutoModel.register(TransformerConfig, TransformerModel)
|
||||
AutoModelForCausalLM.register(TransformerConfig, TransformerForCausalLM)
|
||||
|
||||
|
||||
__all__ = ['TransformerConfig', 'TransformerForCausalLM', 'TransformerModel']
|
||||
61
finetune/lora/v6/fla/models/transformer/configuration_transformer.py
vendored
Normal file
61
finetune/lora/v6/fla/models/transformer/configuration_transformer.py
vendored
Normal file
@ -0,0 +1,61 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from typing import Optional
|
||||
|
||||
from transformers.configuration_utils import PretrainedConfig
|
||||
|
||||
|
||||
class TransformerConfig(PretrainedConfig):
|
||||
|
||||
model_type = 'transformer'
|
||||
keys_to_ignore_at_inference = ['past_key_values']
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
vocab_size: int = 32000,
|
||||
hidden_size: int = 2048,
|
||||
hidden_ratio: Optional[int] = 4,
|
||||
intermediate_size: Optional[int] = None,
|
||||
num_hidden_layers: int = 24,
|
||||
num_heads: int = 32,
|
||||
num_kv_heads: int = None,
|
||||
hidden_act: str = "swish",
|
||||
max_position_embeddings: int = 2048,
|
||||
initializer_range: float = 0.02,
|
||||
elementwise_affine: Optional[bool] = True,
|
||||
norm_eps: float = 1e-6,
|
||||
use_cache: bool = True,
|
||||
pad_token_id: int = None,
|
||||
bos_token_id: int = 1,
|
||||
eos_token_id: int = 2,
|
||||
tie_word_embeddings: bool = False,
|
||||
attention_bias: bool = False,
|
||||
fuse_norm: bool = True,
|
||||
fuse_cross_entropy: bool = True,
|
||||
**kwargs,
|
||||
):
|
||||
self.vocab_size = vocab_size
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
self.hidden_size = hidden_size
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
self.num_hidden_layers = num_hidden_layers
|
||||
self.num_heads = num_heads
|
||||
self.num_kv_heads = num_kv_heads
|
||||
|
||||
self.hidden_act = hidden_act
|
||||
self.initializer_range = initializer_range
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.norm_eps = norm_eps
|
||||
self.use_cache = use_cache
|
||||
self.attention_bias = attention_bias
|
||||
self.fuse_cross_entropy = fuse_cross_entropy
|
||||
self.fuse_norm = fuse_norm
|
||||
|
||||
super().__init__(
|
||||
pad_token_id=pad_token_id,
|
||||
bos_token_id=bos_token_id,
|
||||
eos_token_id=eos_token_id,
|
||||
tie_word_embeddings=tie_word_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
522
finetune/lora/v6/fla/models/transformer/modeling_transformer.py
vendored
Normal file
522
finetune/lora/v6/fla/models/transformer/modeling_transformer.py
vendored
Normal file
@ -0,0 +1,522 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import torch.utils.checkpoint
|
||||
from einops import rearrange
|
||||
from transformers.activations import ACT2FN
|
||||
from transformers.cache_utils import Cache, DynamicCache
|
||||
from transformers.modeling_outputs import (BaseModelOutputWithPast,
|
||||
CausalLMOutputWithPast)
|
||||
from transformers.modeling_utils import PreTrainedModel
|
||||
from transformers.utils import logging
|
||||
|
||||
from fla.models.transformer.configuration_transformer import TransformerConfig
|
||||
from fla.modules import FusedCrossEntropyLoss, RMSNorm, RotaryEmbedding
|
||||
from fla.modules.activations import swiglu_linear
|
||||
|
||||
try:
|
||||
from flash_attn import flash_attn_func, flash_attn_varlen_func
|
||||
from flash_attn.bert_padding import (index_first_axis, pad_input,
|
||||
unpad_input)
|
||||
except ImportError:
|
||||
warnings.warn("Flash Attention is not installed. Please install it via `pip install flash-attn --no-build-isolation`")
|
||||
flash_attn_func = None
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
|
||||
class TransformerAttention(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
config: TransformerConfig,
|
||||
layer_idx: Optional[int] = None,
|
||||
**kwargs
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.config = config
|
||||
self.layer_idx = layer_idx
|
||||
|
||||
self.num_heads = config.num_heads
|
||||
if config.num_kv_heads is None:
|
||||
self.num_kv_heads = self.num_heads
|
||||
else:
|
||||
self.num_kv_heads = config.num_kv_heads
|
||||
self.num_kv_groups = config.num_heads // self.num_kv_heads
|
||||
self.hidden_size = config.hidden_size
|
||||
self.head_dim = self.hidden_size // self.num_heads
|
||||
self.kv_dim = self.num_kv_heads * self.head_dim
|
||||
self.kv_dim = self.num_kv_heads * self.head_dim
|
||||
self.max_position_embeddings = config.max_position_embeddings
|
||||
|
||||
self.q_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
|
||||
self.k_proj = nn.Linear(self.hidden_size, self.kv_dim, bias=False)
|
||||
self.v_proj = nn.Linear(self.hidden_size, self.kv_dim, bias=False)
|
||||
self.o_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
|
||||
|
||||
self.rotary = RotaryEmbedding(self.head_dim)
|
||||
|
||||
self.apply(self._initialize_weights)
|
||||
|
||||
def _initialize_weights(self, module: nn.Module):
|
||||
if getattr(module, "_is_hf_initialized", False):
|
||||
return
|
||||
if isinstance(module, nn.Linear):
|
||||
nn.init.xavier_uniform_(module.weight, gain=2 ** -2.5)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
module._is_hf_initialized = True
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[Cache] = None,
|
||||
output_attentions: bool = False,
|
||||
use_cache: bool = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
batch_size, q_len, _ = hidden_states.size()
|
||||
q = rearrange(self.q_proj(hidden_states), '... (h d) -> ... h d', h=self.num_heads)
|
||||
k = rearrange(self.k_proj(hidden_states), '... (h d) -> ... h d', h=self.num_kv_heads)
|
||||
v = rearrange(self.v_proj(hidden_states), 'b t (h d) -> b h t d', h=self.num_kv_heads)
|
||||
|
||||
seqlen_offset = 0
|
||||
if past_key_values is not None:
|
||||
seqlen_offset = past_key_values.get_seq_length(self.layer_idx)
|
||||
|
||||
if attention_mask is not None:
|
||||
# to deliminate the offsets of padding tokens
|
||||
seqlen_offset = seqlen_offset + attention_mask.sum(-1) - attention_mask.shape[-1]
|
||||
q, k = self.rotary(q, k, seqlen_offset, self.max_position_embeddings)
|
||||
|
||||
k = rearrange(k, 'b t h d -> b h t d')
|
||||
if past_key_values is not None:
|
||||
k, v = past_key_values.update(k, v, self.layer_idx)
|
||||
k, v = rearrange(k, 'b h t d -> b t h d'), rearrange(v, 'b h t d -> b t h d')
|
||||
if self.num_kv_groups > 1:
|
||||
k = rearrange(k.unsqueeze(-2).repeat(1, 1, 1, self.num_kv_groups, 1), 'b t h g d -> b t (h g) d')
|
||||
v = rearrange(v.unsqueeze(-2).repeat(1, 1, 1, self.num_kv_groups, 1), 'b t h g d -> b t (h g) d')
|
||||
|
||||
if flash_attn_func is None:
|
||||
raise ImportError("Please install Flash Attention via `pip install flash-attn --no-build-isolation` first")
|
||||
|
||||
# Contains at least one padding token in the sequence
|
||||
if attention_mask is not None:
|
||||
q, k, v, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(q, k, v, attention_mask, q_len)
|
||||
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
|
||||
max_seqlen_q, max_seqlen_k = max_seq_lens
|
||||
o = flash_attn_varlen_func(
|
||||
q, k, v,
|
||||
cu_seqlens_q=cu_seqlens_q,
|
||||
cu_seqlens_k=cu_seqlens_k,
|
||||
max_seqlen_q=max_seqlen_q,
|
||||
max_seqlen_k=max_seqlen_k,
|
||||
causal=True
|
||||
)
|
||||
o = pad_input(o, indices_q, batch_size, q_len)
|
||||
else:
|
||||
o = flash_attn_func(q, k, v, causal=True)
|
||||
o = o.reshape(batch_size, q_len, self.hidden_size)
|
||||
o = self.o_proj(o)
|
||||
|
||||
if not output_attentions:
|
||||
attentions = None
|
||||
|
||||
return o, attentions, past_key_values
|
||||
|
||||
def _upad_input(self, q, k, v, attention_mask, q_len):
|
||||
seqlens = attention_mask.sum(-1, dtype=torch.int32)
|
||||
indices_k = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
|
||||
max_seqlen_k = seqlens.max().item()
|
||||
cu_seqlens_k = F.pad(torch.cumsum(seqlens, dim=0, dtype=torch.int32), (1, 0))
|
||||
batch_size, seq_len, num_key_value_heads, head_dim = k.shape
|
||||
|
||||
k = index_first_axis(k.reshape(batch_size * seq_len, num_key_value_heads, head_dim), indices_k)
|
||||
v = index_first_axis(v.reshape(batch_size * seq_len, num_key_value_heads, head_dim), indices_k)
|
||||
if q_len == seq_len:
|
||||
q = index_first_axis(q.reshape(batch_size * seq_len, self.num_heads, head_dim), indices_k)
|
||||
cu_seqlens_q = cu_seqlens_k
|
||||
max_seqlen_q = max_seqlen_k
|
||||
indices_q = indices_k
|
||||
elif q_len == 1:
|
||||
max_seqlen_q = 1
|
||||
# There is a memcpy here, that is very bad.
|
||||
cu_seqlens_q = torch.arange(batch_size + 1, dtype=torch.int32, device=q.device)
|
||||
indices_q = cu_seqlens_q[:-1]
|
||||
q = q.squeeze(1)
|
||||
else:
|
||||
# The -q_len: slice assumes left padding.
|
||||
attention_mask = attention_mask[:, -q_len:]
|
||||
q, indices_q, cu_seqlens_q, max_seqlen_q = unpad_input(q, attention_mask)
|
||||
|
||||
return q, k, v, indices_q, (cu_seqlens_q, cu_seqlens_k), (max_seqlen_q, max_seqlen_k)
|
||||
|
||||
|
||||
class TransformerMLP(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
hidden_ratio: Optional[int] = None,
|
||||
intermediate_size: Optional[int] = None,
|
||||
hidden_act: str = 'swish'
|
||||
) -> TransformerMLP:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
# the final number of params is `hidden_ratio * hidden_size^2`
|
||||
# `intermediate_size` is chosen to be a multiple of 256 closest to `2/3 * hidden_size * hidden_ratio`
|
||||
if hidden_ratio is None:
|
||||
hidden_ratio = 4
|
||||
if intermediate_size is None:
|
||||
intermediate_size = int(hidden_size * hidden_ratio * 2 / 3)
|
||||
intermediate_size = 256 * ((intermediate_size + 256 - 1) // 256)
|
||||
self.hidden_ratio = hidden_ratio
|
||||
self.intermediate_size = intermediate_size
|
||||
|
||||
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size * 2, bias=False)
|
||||
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
||||
self.act_fn = ACT2FN[hidden_act]
|
||||
|
||||
def forward(self, x):
|
||||
y = self.gate_proj(x)
|
||||
gate, y = y.chunk(2, -1)
|
||||
return swiglu_linear(gate, y, self.down_proj.weight, self.down_proj.bias)
|
||||
|
||||
|
||||
class TransformerBlock(nn.Module):
|
||||
def __init__(self, config: TransformerConfig, layer_idx: int):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
|
||||
self.attn_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.attn = TransformerAttention(
|
||||
config=config,
|
||||
layer_idx=layer_idx
|
||||
)
|
||||
self.mlp_norm = RMSNorm(hidden_size=config.hidden_size, eps=config.norm_eps)
|
||||
self.mlp = TransformerMLP(
|
||||
hidden_size=config.hidden_size,
|
||||
hidden_ratio=config.hidden_ratio,
|
||||
intermediate_size=config.intermediate_size,
|
||||
hidden_act=config.hidden_act
|
||||
)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: Optional[bool] = False,
|
||||
use_cache: Optional[bool] = False,
|
||||
**kwargs,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
|
||||
residual = hidden_states
|
||||
hidden_states = self.attn_norm(hidden_states)
|
||||
hidden_states, attentions, past_key_values = self.attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions
|
||||
)
|
||||
hidden_states, residual = self.mlp_norm(hidden_states, residual, True)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states,)
|
||||
|
||||
if output_attentions:
|
||||
outputs += (attentions,)
|
||||
|
||||
if use_cache:
|
||||
outputs += (past_key_values,)
|
||||
|
||||
return outputs
|
||||
|
||||
|
||||
class TransformerPreTrainedModel(PreTrainedModel):
|
||||
|
||||
config_class = TransformerConfig
|
||||
supports_gradient_checkpointing = True
|
||||
_no_split_modules = ['TransformerBlock']
|
||||
|
||||
def __init__(self, *inputs, **kwargs):
|
||||
super().__init__(*inputs, **kwargs)
|
||||
|
||||
def _init_weights(
|
||||
self,
|
||||
module: nn.Module,
|
||||
rescale_prenorm_residual: bool = True,
|
||||
num_residuals_per_layer: int = 2,
|
||||
):
|
||||
if isinstance(module, (nn.Linear, nn.Conv1d)):
|
||||
# Slightly different from the TF version which uses truncated_normal for initialization
|
||||
# cf https://github.com/pytorch/pytorch/pull/5617
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.bias is not None:
|
||||
nn.init.zeros_(module.bias)
|
||||
elif isinstance(module, nn.Embedding):
|
||||
nn.init.normal_(module.weight, mean=0.0, std=self.config.initializer_range)
|
||||
if module.padding_idx is not None:
|
||||
module.weight.data[module.padding_idx].zero_()
|
||||
|
||||
if rescale_prenorm_residual:
|
||||
# Reinitialize selected weights subject to the OpenAI GPT-2 Paper Scheme:
|
||||
# > A modified initialization which accounts for the accumulation on the residual path with model depth. Scale
|
||||
# > the weights of residual layers at initialization by a factor of 1/√N where N is the # of residual layers.
|
||||
# > -- GPT-2 :: https://openai.com/blog/better-language-models/
|
||||
#
|
||||
# Reference (Megatron-LM): https://github.com/NVIDIA/Megatron-LM/blob/main/megatron/model/gpt_model.py
|
||||
for name, p in module.named_parameters():
|
||||
if name in ["o_proj.weight", "down_proj.weight"]:
|
||||
# Special Scaled Initialization --> There are 2 Layer Norms per Transformer Block
|
||||
# Following Pytorch init, except scale by 1/sqrt(2 * n_layer)
|
||||
# We need to reinit p since this code could be called multiple times
|
||||
# Having just p *= scale would repeatedly scale it down
|
||||
with torch.no_grad():
|
||||
p /= math.sqrt(num_residuals_per_layer * self.config.num_hidden_layers)
|
||||
|
||||
|
||||
class TransformerModel(TransformerPreTrainedModel):
|
||||
|
||||
def __init__(self, config: TransformerConfig):
|
||||
super().__init__(config)
|
||||
self.padding_idx = config.pad_token_id
|
||||
self.vocab_size = config.vocab_size
|
||||
|
||||
self.embeddings = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
||||
self.layers = nn.ModuleList([TransformerBlock(config, layer_idx) for layer_idx in range(config.num_hidden_layers)])
|
||||
self.norm = RMSNorm(config.hidden_size, eps=config.norm_eps)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.embeddings = value
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
if output_attentions:
|
||||
warnings.warn(
|
||||
"`TransformerModel` does not support output attention weights now, so `output_attentions` is set to `False`."
|
||||
)
|
||||
output_attentions = False
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
use_cache = use_cache if use_cache is not None else (self.config.use_cache if not self.training else False)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is None and inputs_embeds is None:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if use_cache:
|
||||
use_legacy_cache = not isinstance(past_key_values, Cache)
|
||||
if use_legacy_cache:
|
||||
past_key_values = DynamicCache.from_legacy_cache(past_key_values)
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embeddings(input_ids)
|
||||
|
||||
# embed positions
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
if use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
||||
)
|
||||
use_cache = False
|
||||
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_attns = () if output_attentions else None
|
||||
next_decoder_cache = None
|
||||
|
||||
for layer in self.layers:
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
layer_outputs = self._gradient_checkpointing_func(
|
||||
layer.__call__,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
past_key_values,
|
||||
output_attentions,
|
||||
use_cache
|
||||
)
|
||||
else:
|
||||
layer_outputs = layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache
|
||||
)
|
||||
|
||||
hidden_states = layer_outputs[0]
|
||||
|
||||
if use_cache:
|
||||
next_decoder_cache = layer_outputs[2 if output_attentions else 1]
|
||||
|
||||
if output_attentions:
|
||||
all_attns += (layer_outputs[1],)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
next_cache = None
|
||||
if use_cache:
|
||||
next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
|
||||
if not return_dict:
|
||||
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_attns] if v is not None)
|
||||
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_attns
|
||||
)
|
||||
|
||||
|
||||
class TransformerForCausalLM(TransformerPreTrainedModel):
|
||||
_tied_weights_keys = ["lm_head.weight"]
|
||||
|
||||
def __init__(self, config):
|
||||
super().__init__(config)
|
||||
self.model = TransformerModel(config)
|
||||
self.vocab_size = config.vocab_size
|
||||
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
||||
|
||||
# Initialize weights and apply final processing
|
||||
self.post_init()
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.embeddings
|
||||
|
||||
def set_input_embeddings(self, value):
|
||||
self.model.embeddings = value
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.lm_head
|
||||
|
||||
def set_output_embeddings(self, new_embeddings):
|
||||
self.lm_head = new_embeddings
|
||||
|
||||
def set_decoder(self, decoder):
|
||||
self.model = decoder
|
||||
|
||||
def get_decoder(self):
|
||||
return self.model
|
||||
|
||||
def prepare_inputs_for_generation(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
past_key_values: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
**kwargs
|
||||
):
|
||||
# only last token for `inputs_ids` if the `past_key_values` is passed along.
|
||||
if past_key_values is not None:
|
||||
input_ids = input_ids[:, -1:]
|
||||
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
||||
if inputs_embeds is not None and past_key_values is None:
|
||||
model_inputs = {'inputs_embeds': inputs_embeds}
|
||||
else:
|
||||
# The `contiguous()` here is necessary to have a static stride during decoding. torchdynamo otherwise
|
||||
# recompiles graphs as the stride of the inputs is a guard.
|
||||
# Ref: https://github.com/huggingface/transformers/pull/29114
|
||||
# TODO: use `next_tokens` directly instead.
|
||||
model_inputs = {'input_ids': input_ids.contiguous()}
|
||||
|
||||
model_inputs.update({
|
||||
'past_key_values': past_key_values,
|
||||
'use_cache': kwargs.get('use_cache'),
|
||||
'attention_mask': attention_mask,
|
||||
})
|
||||
return model_inputs
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, CausalLMOutputWithPast]:
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
outputs = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
if self.config.fuse_cross_entropy:
|
||||
loss_fct = FusedCrossEntropyLoss(inplace_backward=True)
|
||||
else:
|
||||
loss_fct = nn.CrossEntropyLoss()
|
||||
# Enable model parallelism
|
||||
labels = labels.to(logits.device)
|
||||
labels = torch.cat((labels[..., 1:], torch.full_like(labels[:, :1], loss_fct.ignore_index)), 1)
|
||||
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
|
||||
|
||||
if not return_dict:
|
||||
output = (logits,) + outputs[1:]
|
||||
return (loss,) + output if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithPast(
|
||||
loss=loss,
|
||||
logits=logits,
|
||||
past_key_values=outputs.past_key_values,
|
||||
hidden_states=outputs.hidden_states,
|
||||
attentions=outputs.attentions,
|
||||
)
|
||||
107
finetune/lora/v6/fla/models/utils.py
vendored
Normal file
107
finetune/lora/v6/fla/models/utils.py
vendored
Normal file
@ -0,0 +1,107 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Any, Dict, List, Optional, Tuple
|
||||
|
||||
import torch
|
||||
from transformers.cache_utils import Cache
|
||||
|
||||
|
||||
class RecurrentCache(Cache):
|
||||
"""
|
||||
A cache used for storing hidden states produced by flash linear attention models.
|
||||
|
||||
It stores the states of each layer as the tensor of shape `[batch_size, key_dim, value_dim]`.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
seen_tokens: int = 0
|
||||
) -> RecurrentCache:
|
||||
|
||||
self.states: List[torch.Tensor] = []
|
||||
self._seen_tokens = seen_tokens # Used in `generate` to keep tally of how many tokens the cache has seen
|
||||
|
||||
def __getitem__(self, layer_idx: int) -> torch.Tensor:
|
||||
if layer_idx < len(self):
|
||||
return self.states[layer_idx]
|
||||
else:
|
||||
raise KeyError(f"Cache only has {len(self)} layers, attempted to access layer with index {layer_idx}")
|
||||
|
||||
def __iter__(self):
|
||||
for state in self.states:
|
||||
yield state
|
||||
|
||||
def __len__(self):
|
||||
return len(self.states)
|
||||
|
||||
def update(
|
||||
self,
|
||||
state: Tuple[torch.Tensor],
|
||||
layer_idx: int,
|
||||
offset: Optional[int] = 1,
|
||||
cache_kwargs: Optional[Dict[str, Any]] = None,
|
||||
) -> Tuple[torch.Tensor]:
|
||||
"""
|
||||
Updates the cache with the new `state` for the layer `layer_idx`.
|
||||
|
||||
Parameters:
|
||||
state (`Tuple[torch.Tensor]`):
|
||||
The new state to cache.
|
||||
layer_idx (`int`):
|
||||
The index of the layer to cache the states for.
|
||||
offset (`int`):
|
||||
The offset of current fed tokens.
|
||||
cache_kwargs (`Dict[str, Any]`, `optional`):
|
||||
Additional arguments for the cache subclass.
|
||||
|
||||
Return:
|
||||
The updated state.
|
||||
"""
|
||||
|
||||
if isinstance(state, torch.Tensor):
|
||||
state = (state,)
|
||||
if len(self.states) <= layer_idx:
|
||||
self.states.append(state)
|
||||
else:
|
||||
for i, s in enumerate(state):
|
||||
self.states[layer_idx][i].copy_(s)
|
||||
# update the number of seen tokens once we achieve the last layer
|
||||
if layer_idx == len(self) - 1:
|
||||
self._seen_tokens += offset
|
||||
|
||||
return state
|
||||
|
||||
def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
|
||||
"""Returns the sequence length of the cached states. A layer index can be optionally passed."""
|
||||
if len(self.states) <= layer_idx:
|
||||
return 0
|
||||
return self._seen_tokens
|
||||
|
||||
def get_max_length(self) -> Optional[int]:
|
||||
"""Returns the maximum sequence length of the cached states. RecurrentCache does not have a maximum length."""
|
||||
return None
|
||||
|
||||
def reorder_cache(self, beam_idx: torch.LongTensor):
|
||||
"""Reorders the cache for beam search, given the selected beam indices."""
|
||||
for layer_idx in range(len(self.states)):
|
||||
device = self.states[layer_idx].device
|
||||
self.states[layer_idx] = self.states[layer_idx].index_select(0, beam_idx.to(device))
|
||||
|
||||
def to_legacy_cache(self) -> Tuple[torch.Tensor]:
|
||||
return tuple(self.states)
|
||||
|
||||
@classmethod
|
||||
def from_legacy_cache(
|
||||
cls,
|
||||
past_key_values: Optional[Tuple[torch.Tensor]] = None,
|
||||
seen_tokens: int = 0
|
||||
) -> RecurrentCache:
|
||||
"""Converts a cache in the legacy cache format into an equivalent `RecurrentCache`."""
|
||||
|
||||
cache = cls(seen_tokens)
|
||||
if past_key_values is not None:
|
||||
for layer_idx in range(len(past_key_values)):
|
||||
cache.update(past_key_values[layer_idx], layer_idx)
|
||||
return cache
|
||||
20
finetune/lora/v6/fla/modules/__init__.py
vendored
Normal file
20
finetune/lora/v6/fla/modules/__init__.py
vendored
Normal file
@ -0,0 +1,20 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from fla.modules.convolution import (ImplicitLongConvolution, LongConvolution,
|
||||
ShortConvolution)
|
||||
from fla.modules.fused_cross_entropy import FusedCrossEntropyLoss
|
||||
from fla.modules.fused_norm_gate import (FusedLayerNormSwishGate,
|
||||
FusedLayerNormSwishGateLinear,
|
||||
FusedRMSNormSwishGate,
|
||||
FusedRMSNormSwishGateLinear)
|
||||
from fla.modules.layernorm import (LayerNorm, LayerNormLinear, RMSNorm,
|
||||
RMSNormLinear)
|
||||
from fla.modules.rotary import RotaryEmbedding
|
||||
|
||||
__all__ = [
|
||||
'ImplicitLongConvolution', 'LongConvolution', 'ShortConvolution',
|
||||
'FusedCrossEntropyLoss',
|
||||
'LayerNorm', 'LayerNormLinear', 'RMSNorm', 'RMSNormLinear',
|
||||
'FusedLayerNormSwishGate', 'FusedLayerNormSwishGateLinear', 'FusedRMSNormSwishGate', 'FusedRMSNormSwishGateLinear',
|
||||
'RotaryEmbedding'
|
||||
]
|
||||
394
finetune/lora/v6/fla/modules/activations.py
vendored
Normal file
394
finetune/lora/v6/fla/modules/activations.py
vendored
Normal file
@ -0,0 +1,394 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Copyright (c) 2023-2024, Tri Dao, Yu Zhang, Songlin Yang.
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from fla.utils import contiguous
|
||||
|
||||
sigmoid_fwd_codestring = """
|
||||
template <typename T> T sigmoid_fwd(T x) {
|
||||
return 1.0f / (1.0f + ::exp(-float(x)));
|
||||
}
|
||||
"""
|
||||
sigmoid_bwd_codestring = """
|
||||
template <typename T> T sigmoid_bwd(T x, T g) {
|
||||
float x_sigmoid = 1.0f / (1.0f + ::exp(-float(x)));
|
||||
return float(g) * x_sigmoid * (1.0f - x_sigmoid);
|
||||
}
|
||||
"""
|
||||
|
||||
sigmoid_fwd = torch.cuda.jiterator._create_jit_fn(sigmoid_fwd_codestring)
|
||||
sigmoid_bwd = torch.cuda.jiterator._create_jit_fn(sigmoid_bwd_codestring)
|
||||
|
||||
|
||||
class SigmoidFunction(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
def forward(ctx, x):
|
||||
ctx.save_for_backward(x)
|
||||
return sigmoid_fwd(x)
|
||||
|
||||
@staticmethod
|
||||
def backward(ctx, dout):
|
||||
x, = ctx.saved_tensors
|
||||
return sigmoid_bwd(x, dout)
|
||||
|
||||
|
||||
sigmoid = SigmoidFunction.apply
|
||||
|
||||
|
||||
@triton.autotune(
|
||||
configs=[
|
||||
triton.Config({'BT': 16}, num_warps=2),
|
||||
triton.Config({'BT': 16}, num_warps=4),
|
||||
triton.Config({'BT': 16}, num_warps=8),
|
||||
triton.Config({'BT': 32}, num_warps=2),
|
||||
triton.Config({'BT': 32}, num_warps=4),
|
||||
triton.Config({'BT': 32}, num_warps=8),
|
||||
triton.Config({'BT': 64}, num_warps=2),
|
||||
triton.Config({'BT': 64}, num_warps=4),
|
||||
triton.Config({'BT': 64}, num_warps=8),
|
||||
triton.Config({'BT': 128}, num_warps=2),
|
||||
triton.Config({'BT': 128}, num_warps=4),
|
||||
triton.Config({'BT': 128}, num_warps=8),
|
||||
triton.Config({'BT': 256}, num_warps=2),
|
||||
triton.Config({'BT': 256}, num_warps=4),
|
||||
triton.Config({'BT': 256}, num_warps=8)
|
||||
],
|
||||
key=['D']
|
||||
)
|
||||
@triton.jit
|
||||
def logsigmoid_fwd_kernel(
|
||||
x,
|
||||
y,
|
||||
T: tl.constexpr,
|
||||
D: tl.constexpr,
|
||||
BT: tl.constexpr
|
||||
):
|
||||
i = tl.program_id(0)
|
||||
o_i = i * BT + tl.arange(0, BT)
|
||||
|
||||
p_x = x + o_i
|
||||
p_y = y + o_i
|
||||
mask = o_i < T
|
||||
|
||||
# [D,]
|
||||
b_x = tl.load(p_x, mask=mask, other=0.).to(tl.float32)
|
||||
b_m = tl.minimum(0., b_x)
|
||||
b_z = 1. + tl.exp(-tl.abs(b_x))
|
||||
b_y = b_m - tl.log(b_z)
|
||||
tl.store(p_y, b_y.to(p_y.dtype.element_ty), mask=mask)
|
||||
|
||||
|
||||
@triton.autotune(
|
||||
configs=[
|
||||
triton.Config({'BT': 16}, num_warps=2),
|
||||
triton.Config({'BT': 16}, num_warps=4),
|
||||
triton.Config({'BT': 16}, num_warps=8),
|
||||
triton.Config({'BT': 32}, num_warps=2),
|
||||
triton.Config({'BT': 32}, num_warps=4),
|
||||
triton.Config({'BT': 32}, num_warps=8),
|
||||
triton.Config({'BT': 64}, num_warps=2),
|
||||
triton.Config({'BT': 64}, num_warps=4),
|
||||
triton.Config({'BT': 64}, num_warps=8),
|
||||
triton.Config({'BT': 128}, num_warps=2),
|
||||
triton.Config({'BT': 128}, num_warps=4),
|
||||
triton.Config({'BT': 128}, num_warps=8),
|
||||
triton.Config({'BT': 256}, num_warps=2),
|
||||
triton.Config({'BT': 256}, num_warps=4),
|
||||
triton.Config({'BT': 256}, num_warps=8)
|
||||
],
|
||||
key=['D']
|
||||
)
|
||||
@triton.jit
|
||||
def logsigmoid_bwd_kernel(
|
||||
x,
|
||||
dx,
|
||||
dy,
|
||||
T: tl.constexpr,
|
||||
D: tl.constexpr,
|
||||
BT: tl.constexpr
|
||||
):
|
||||
i = tl.program_id(0)
|
||||
o_i = i * BT + tl.arange(0, BT)
|
||||
|
||||
p_x = x + o_i
|
||||
p_dx = dx + o_i
|
||||
p_dy = dy + o_i
|
||||
mask = o_i < T
|
||||
|
||||
# [D,]
|
||||
b_x = tl.load(p_x, mask=mask, other=0.).to(tl.float32)
|
||||
b_dy = tl.load(p_dy, mask=mask, other=0.).to(tl.float32)
|
||||
b_dx = b_dy * (1. - tl.sigmoid(b_x))
|
||||
tl.store(p_dx, b_dx.to(p_dx.dtype.element_ty), mask=mask)
|
||||
|
||||
|
||||
class LogSigmoidFunction(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
@contiguous
|
||||
def forward(ctx, x):
|
||||
T, D = x.numel(), x.shape[-1]
|
||||
y = torch.empty_like(x)
|
||||
logsigmoid_fwd_kernel[lambda meta: (triton.cdiv(meta['T'], meta['D']),)](x, y, T=T, D=D)
|
||||
ctx.save_for_backward(x,)
|
||||
return y
|
||||
|
||||
@staticmethod
|
||||
@contiguous
|
||||
def backward(ctx, dy):
|
||||
x, = ctx.saved_tensors
|
||||
T, D = x.numel(), x.shape[-1]
|
||||
dx = torch.empty_like(x)
|
||||
logsigmoid_bwd_kernel[lambda meta: (triton.cdiv(meta['T'], meta['D']),)](x, dx, dy, T=T, D=D)
|
||||
return dx
|
||||
|
||||
|
||||
logsigmoid = LogSigmoidFunction.apply
|
||||
|
||||
swish_fwd_codestring = """
|
||||
template <typename T> T swish_fwd(T x) {
|
||||
float x_sigmoid = 1.0f / (1.0f + ::exp(-float(x)));
|
||||
return float(x) * x_sigmoid;
|
||||
}
|
||||
"""
|
||||
swish_bwd_codestring = """
|
||||
template <typename T> T swish_bwd(T x, T g) {
|
||||
float x_sigmoid = 1.0f / (1.0f + ::exp(-float(x)));
|
||||
return float(g) * x_sigmoid * (1.0f - float(x) * x_sigmoid + float(x));
|
||||
}
|
||||
"""
|
||||
|
||||
swish_fwd = torch.cuda.jiterator._create_jit_fn(swish_fwd_codestring)
|
||||
swish_bwd = torch.cuda.jiterator._create_jit_fn(swish_bwd_codestring)
|
||||
|
||||
|
||||
class SwishFunction(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
def forward(ctx, x):
|
||||
ctx.save_for_backward(x)
|
||||
return swish_fwd(x)
|
||||
|
||||
@staticmethod
|
||||
def backward(ctx, dout):
|
||||
x, = ctx.saved_tensors
|
||||
return swish_bwd(x, dout)
|
||||
|
||||
|
||||
swish = SwishFunction.apply
|
||||
|
||||
# 1/sqrt(2*pi)-> 0.3989423
|
||||
# 1/sqrt(2) -> 0.70710678
|
||||
# sqrt(2/pi) -> 0.79788456
|
||||
|
||||
|
||||
# this function is tanh approximation of gelu
|
||||
# actual gelu is:
|
||||
# x * 0.5 * (1.0 + torch.erf(x * 0.70710678))
|
||||
@torch.jit.script
|
||||
def bias_gelu(y, bias):
|
||||
x = bias + y
|
||||
return (x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))).to(dtype=y.dtype)
|
||||
|
||||
|
||||
# gradient of tanh approximation of gelu
|
||||
# gradient of actual gelu is:
|
||||
# 0.5 * (1. + torch.erf(x * 0.70710678)) + 0.3989423 * x * torch.exp(-0.5 * x * x)
|
||||
@torch.jit.script
|
||||
def bias_gelu_bwd(g, y, bias):
|
||||
"""Assume that y has shape (B, D) and bias has shape (D)"""
|
||||
x = bias + y
|
||||
tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))
|
||||
# sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243
|
||||
ff = 0.5 * x * ((1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)) + 0.5 * (
|
||||
1 + tanh_out
|
||||
)
|
||||
grad_y = ff * g
|
||||
return grad_y.to(dtype=y.dtype), grad_y.sum(dim=(0), dtype=bias.dtype)
|
||||
|
||||
|
||||
class GeLUFunction(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
# bias is an optional argument
|
||||
def forward(ctx, input, bias):
|
||||
ctx.save_for_backward(input, bias)
|
||||
return bias_gelu(input, bias)
|
||||
|
||||
@staticmethod
|
||||
def backward(ctx, grad_output):
|
||||
input, bias = ctx.saved_tensors
|
||||
tmp = bias_gelu_bwd(grad_output, input, bias)
|
||||
return tmp, tmp
|
||||
|
||||
|
||||
bias_gelu_impl = GeLUFunction.apply
|
||||
|
||||
|
||||
# this function is tanh approximation of gelu
|
||||
# actual gelu is:
|
||||
# x * 0.5 * (1.0 + torch.erf(x * 0.70710678))
|
||||
@torch.jit.script
|
||||
def gelu_fwd(x):
|
||||
return (x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))).to(dtype=x.dtype)
|
||||
|
||||
|
||||
# gradient of tanh approximation of gelu
|
||||
# gradient of actual gelu is:
|
||||
# 0.5 * (1. + torch.erf(x * 0.70710678)) + 0.3989423 * x * torch.exp(-0.5 * x * x)
|
||||
@torch.jit.script
|
||||
def gelu_bwd(g, x):
|
||||
tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))
|
||||
# sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243
|
||||
ff = 0.5 * x * ((1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)) + 0.5 * (
|
||||
1 + tanh_out
|
||||
)
|
||||
return (ff * g).to(dtype=x.dtype)
|
||||
|
||||
|
||||
class FastGeLUFunction(torch.autograd.Function):
|
||||
@staticmethod
|
||||
# bias is an optional argument
|
||||
def forward(ctx, input):
|
||||
ctx.save_for_backward(input)
|
||||
return gelu_fwd(input)
|
||||
|
||||
@staticmethod
|
||||
def backward(ctx, grad_output):
|
||||
(input,) = ctx.saved_tensors
|
||||
tmp = gelu_bwd(grad_output, input)
|
||||
return tmp
|
||||
|
||||
|
||||
fast_gelu_impl = FastGeLUFunction.apply
|
||||
|
||||
|
||||
@torch.jit.script
|
||||
def relu_bwd(g, x):
|
||||
return torch.where(x >= 0, g, 0.0).to(dtype=x.dtype)
|
||||
|
||||
|
||||
@torch.jit.script
|
||||
def sqrelu_fwd(x):
|
||||
r = F.relu(x)
|
||||
return (r * r).to(dtype=x.dtype)
|
||||
|
||||
|
||||
@torch.jit.script
|
||||
def sqrelu_bwd(g, x):
|
||||
return (2.0 * g * F.relu(x)).to(dtype=x.dtype)
|
||||
|
||||
|
||||
class SquaredReLUFunction(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
def forward(ctx, input):
|
||||
ctx.save_for_backward(input)
|
||||
return sqrelu_fwd(input)
|
||||
|
||||
@staticmethod
|
||||
def backward(ctx, grad_output):
|
||||
input, = ctx.saved_tensors
|
||||
return sqrelu_bwd(grad_output, input)
|
||||
|
||||
|
||||
sqrelu = SquaredReLUFunction.apply
|
||||
|
||||
|
||||
swiglu_fwd_codestring = """
|
||||
template <typename T> T swiglu_fwd(T x, T y) {
|
||||
return float(x) * float(y) / (1.0f + ::exp(-float(x)));
|
||||
}
|
||||
"""
|
||||
swiglu_bwd_codestring = """
|
||||
template <typename T> T swiglu_bwd(T x, T y, T g, T& dx, T& dy) {
|
||||
float x_sigmoid = 1.0f / (1.0f + ::exp(-float(x)));
|
||||
dx = x_sigmoid * (1 + float(x) * (1.0f - x_sigmoid)) * float(g) * float(y);
|
||||
dy = float(x) * x_sigmoid * float(g);
|
||||
}
|
||||
"""
|
||||
|
||||
swiglu_bwd_with_output_codestring = """
|
||||
template <typename T> T swiglu_bwd_with_output(T x, T y, T g, T& dx, T& dy, T& z) {
|
||||
float x_sigmoid = 1.0f / (1.0f + ::exp(-float(x)));
|
||||
float x_swish = float(x) * x_sigmoid;
|
||||
dx = x_sigmoid * (1 + float(x) * (1.0f - x_sigmoid)) * float(g) * float(y);
|
||||
dy = x_swish * float(g);
|
||||
z = x_swish * float(y);
|
||||
}
|
||||
"""
|
||||
|
||||
swiglu_fwd = torch.cuda.jiterator._create_jit_fn(swiglu_fwd_codestring)
|
||||
swiglu_bwd = torch.cuda.jiterator._create_multi_output_jit_fn(swiglu_bwd_codestring, num_outputs=2)
|
||||
swiglu_bwd_with_output = torch.cuda.jiterator._create_multi_output_jit_fn(swiglu_bwd_with_output_codestring, num_outputs=3)
|
||||
|
||||
|
||||
class SwiGLUFunction(torch.autograd.Function):
|
||||
r"""
|
||||
Swish-Gated Linear Unit (SwiGLU) function.
|
||||
|
||||
.. math::
|
||||
\text{SwiGLU}(x, y) = swish(x) * y = \frac{x}{1 + \exp(-x)} * y
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def forward(ctx, x, y):
|
||||
ctx.save_for_backward(x, y)
|
||||
return swiglu_fwd(x, y)
|
||||
|
||||
@staticmethod
|
||||
def backward(ctx, dout):
|
||||
x, y = ctx.saved_tensors
|
||||
return swiglu_bwd(x, y, dout)
|
||||
|
||||
|
||||
class SwiGLULinearFunction(torch.autograd.Function):
|
||||
r"""
|
||||
Swish-Gated Linear Unit (SwiGLU) function followed by a linear transformation.
|
||||
|
||||
.. math::
|
||||
\text{SwiGLULinear}(x, y, W, b) = (swish(x) * y) W + b
|
||||
|
||||
This simple wrap discards the intermediate results of SwiGLU(x, y) to save memory.
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def forward(ctx, x, y, weight, bias):
|
||||
z = swiglu_fwd(x, y)
|
||||
out = F.linear(z.to(weight.dtype), weight, bias)
|
||||
# We don't store z, will be recomputed in the backward pass to save memory
|
||||
ctx.save_for_backward(x, y, weight)
|
||||
ctx.linear_bias_is_none = bias is None
|
||||
return out
|
||||
|
||||
@staticmethod
|
||||
def backward(ctx, dout, *args):
|
||||
x, y, weight = ctx.saved_tensors
|
||||
dout = dout.reshape(-1, dout.shape[-1])
|
||||
dz = F.linear(dout, weight.t()).view_as(x)
|
||||
dx, dy, z = swiglu_bwd_with_output(x, y, dz)
|
||||
dlinear_weight = torch.einsum("bo,bi->oi", dout, z.reshape(-1, z.shape[-1]))
|
||||
dlinear_bias = None if ctx.linear_bias_is_none else dout.sum(0)
|
||||
return dx, dy, dlinear_weight, dlinear_bias
|
||||
|
||||
|
||||
swiglu = SwiGLUFunction.apply
|
||||
|
||||
swiglu_linear = SwiGLULinearFunction.apply
|
||||
|
||||
ACT2FN = {
|
||||
'relu': F.relu,
|
||||
'sigmoid': sigmoid,
|
||||
'logsigmoid': logsigmoid,
|
||||
'silu': swish,
|
||||
'swish': swish,
|
||||
'sqrelu': sqrelu,
|
||||
'gelu': fast_gelu_impl,
|
||||
'bias_gelu': bias_gelu_impl,
|
||||
}
|
||||
336
finetune/lora/v6/fla/modules/convolution.py
vendored
Normal file
336
finetune/lora/v6/fla/modules/convolution.py
vendored
Normal file
@ -0,0 +1,336 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# from https://github.com/HazyResearch/zoology/blob/main/zoology/mixers/convolution.py
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from einops import rearrange
|
||||
|
||||
from fla.modules.activations import ACT2FN
|
||||
from fla.utils import checkpoint
|
||||
|
||||
try:
|
||||
from causal_conv1d import causal_conv1d_fn, causal_conv1d_update
|
||||
except ImportError:
|
||||
causal_conv1d_fn = None
|
||||
causal_conv1d_update = None
|
||||
|
||||
|
||||
def fft_conv(u, k, dropout_mask, gelu=True, k_rev=None):
|
||||
seqlen = u.shape[-1]
|
||||
fft_size = 2 * seqlen
|
||||
k_f = torch.fft.rfft(k, n=fft_size) / fft_size
|
||||
if k_rev is not None:
|
||||
k_rev_f = torch.fft.rfft(k_rev, n=fft_size) / fft_size
|
||||
k_f = k_f + k_rev_f.conj()
|
||||
u_f = torch.fft.rfft(u.to(dtype=k.dtype), n=fft_size)
|
||||
|
||||
if len(u.shape) > 3:
|
||||
k_f = k_f.unsqueeze(1)
|
||||
y = torch.fft.irfft(u_f * k_f, n=fft_size, norm="forward")[..., :seqlen]
|
||||
|
||||
out = y + u
|
||||
if gelu:
|
||||
out = F.gelu(out)
|
||||
if dropout_mask is not None:
|
||||
return (out * rearrange(dropout_mask, "b H -> b H 1")).to(dtype=u.dtype)
|
||||
else:
|
||||
return out.to(dtype=u.dtype)
|
||||
|
||||
|
||||
@checkpoint
|
||||
def proj_then_conv1d(
|
||||
x: torch.Tensor,
|
||||
proj_weight: torch.Tensor,
|
||||
conv1d_weight: torch.Tensor,
|
||||
conv1d_bias: Optional[torch.Tensor] = None,
|
||||
cache: Optional[torch.Tensor] = None
|
||||
) -> torch.Tensor:
|
||||
# We do matmul and transpose BLH -> HBL at the same time
|
||||
x = rearrange(proj_weight @ rearrange(x, "b l d -> d (b l)"), "d (b l) -> b d l", l=x.shape[-2])
|
||||
|
||||
if causal_conv1d_fn is None:
|
||||
raise ImportError("`causal_conv1d_fn` is not available. Please install `causal-conv1d` first.")
|
||||
if cache is None:
|
||||
x = causal_conv1d_fn(
|
||||
x=x,
|
||||
weight=rearrange(conv1d_weight, "d 1 w -> d w"),
|
||||
bias=conv1d_bias,
|
||||
activation="silu",
|
||||
).transpose(1, 2)
|
||||
else:
|
||||
assert x.shape[-1] == 1, "Only support decoding with 1 token at a time for now"
|
||||
x = x.squeeze(-1)
|
||||
x = causal_conv1d_update(
|
||||
x=x,
|
||||
weight=rearrange(conv1d_weight, "d 1 w -> d w"),
|
||||
bias=conv1d_bias,
|
||||
cache=cache,
|
||||
activation="silu",
|
||||
)
|
||||
return x
|
||||
|
||||
|
||||
class ShortConvolution(nn.Conv1d):
|
||||
"""
|
||||
Simple wrapper around `nn.Conv1d` that accepts dimension last.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
kernel_size: int,
|
||||
bias: bool = False,
|
||||
activation: Optional[str] = 'silu',
|
||||
use_causal_conv: Optional[bool] = True
|
||||
):
|
||||
super().__init__(in_channels=hidden_size,
|
||||
out_channels=hidden_size,
|
||||
kernel_size=kernel_size,
|
||||
groups=hidden_size,
|
||||
bias=bias,
|
||||
padding=kernel_size - 1)
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.activation = None
|
||||
if activation is not None:
|
||||
assert activation in ['silu', 'swish'], f"Activation `{activation}` not supported yet."
|
||||
self.activation = activation
|
||||
|
||||
if use_causal_conv:
|
||||
if causal_conv1d_fn is None:
|
||||
warnings.warn("Please install `causal-conv1d` to use causal convolutions, setting `use_causal_conv` to False.")
|
||||
use_causal_conv = False
|
||||
self.use_causal_conv = use_causal_conv
|
||||
|
||||
def extra_repr(self):
|
||||
s = ('{in_channels}, {out_channels}, kernel_size={kernel_size}'
|
||||
', stride={stride}')
|
||||
if self.padding != (0,) * len(self.padding):
|
||||
s += ', padding={padding}'
|
||||
if self.dilation != (1,) * len(self.dilation):
|
||||
s += ', dilation={dilation}'
|
||||
if self.output_padding != (0,) * len(self.output_padding):
|
||||
s += ', output_padding={output_padding}'
|
||||
if self.groups != 1:
|
||||
s += ', groups={groups}'
|
||||
if self.bias is None:
|
||||
s += ', bias=False'
|
||||
if self.padding_mode != 'zeros':
|
||||
s += ', padding_mode={padding_mode}'
|
||||
if self.activation is not None:
|
||||
s += ', activation={activation}'
|
||||
if not self.use_causal_conv:
|
||||
s += ', use_causal_conv={use_causal_conv}'
|
||||
return s.format(**self.__dict__)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
x: torch.Tensor,
|
||||
mask: Optional[torch.Tensor] = None,
|
||||
cache: Optional[torch.Tensor] = None
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Args:
|
||||
x (`torch.Tensor`):
|
||||
Tensor of shape `[batch_size, seq_len, hidden_size]`
|
||||
mask (`Optional[torch.Tensor]`):
|
||||
Attention mask dealing with padded positions.
|
||||
cache (`Optional[torch.Tensor]`):
|
||||
Previous cache tensor of shape `[batch_size, hidden_size, kernel_size]`,
|
||||
Returns:
|
||||
Tensor of shape `[batch_size, seq_len, hidden_size]`. The `cache` (if provided) is updated inplace.
|
||||
"""
|
||||
|
||||
if mask is not None:
|
||||
x = x.mul_(mask.unsqueeze(-1))
|
||||
if cache is not None and x.shape[1] == 1:
|
||||
return self.step(x, cache)
|
||||
x = rearrange(x, "b l d -> b d l")
|
||||
# Update state (B D W)
|
||||
if cache is not None:
|
||||
cache.copy_(F.pad(x, (self.kernel_size[0] - x.shape[-1], 0)))
|
||||
if self.use_causal_conv:
|
||||
x = causal_conv1d_fn(
|
||||
x=x,
|
||||
weight=rearrange(self.weight, "d 1 w -> d w"),
|
||||
bias=self.bias,
|
||||
activation=self.activation,
|
||||
)
|
||||
else:
|
||||
x = self._conv_forward(x, self.weight, self.bias)[..., :x.shape[-1]]
|
||||
if self.activation is not None:
|
||||
x = ACT2FN[self.activation](x)
|
||||
return rearrange(x, "b d l -> b l d")
|
||||
|
||||
def step(
|
||||
self,
|
||||
x: torch.Tensor,
|
||||
cache: torch.Tensor
|
||||
):
|
||||
assert x.shape[1] == 1, "Only support decoding with 1 token at a time for now"
|
||||
|
||||
x = x.squeeze(1)
|
||||
if self.use_causal_conv:
|
||||
x = causal_conv1d_update(
|
||||
x=x,
|
||||
conv_state=cache,
|
||||
weight=rearrange(self.weight, "d 1 w -> d w"),
|
||||
bias=self.bias,
|
||||
activation=self.activation,
|
||||
)
|
||||
else:
|
||||
dtype = x.dtype
|
||||
cache.copy_(torch.roll(cache, shifts=-1, dims=-1))
|
||||
cache[:, :, -1] = x
|
||||
x = torch.sum(cache * rearrange(self.weight, "d 1 w -> d w"), dim=-1)
|
||||
if self.bias is not None:
|
||||
x = x + self.bias
|
||||
if self.activation is not None:
|
||||
x = ACT2FN[self.activation](x).to(dtype=dtype)
|
||||
return x.unsqueeze(1)
|
||||
|
||||
@property
|
||||
def state_size(self) -> int:
|
||||
return self.hidden_size * self.kernel_size
|
||||
|
||||
|
||||
class LongConvolution(nn.Module):
|
||||
"""
|
||||
LongConvolution applies a convolution operation on the input tensor using a fixed
|
||||
filter of length l_max.
|
||||
The filter is learned during training and is applied using FFT convolution.
|
||||
Args:
|
||||
hidden_size (int): The number of expected features in the input and output.
|
||||
l_max (int): The maximum sequence length.
|
||||
Returns:
|
||||
y: (b, l, d) tensor
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
l_max: int,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Initializes the LongConvolution module.
|
||||
Args:
|
||||
hidden_size (int): The number of expected features in the input and output.
|
||||
l_max (int): The maximum sequence length.
|
||||
"""
|
||||
super().__init__()
|
||||
self.hidden_size = hidden_size
|
||||
self.filter = nn.Parameter(torch.randn(self.hidden_size, l_max), requires_grad=True)
|
||||
|
||||
def forward(self, x: torch.Tensor, *args, **kwargs):
|
||||
"""
|
||||
Applies the LongConvolution operation on the input tensor.
|
||||
Args:
|
||||
x: (b, l, d) tensor
|
||||
Returns:
|
||||
y: (b, l, d) tensor
|
||||
"""
|
||||
x = x.transpose(1, 2)
|
||||
y = fft_conv(x, self.filter, dropout_mask=None, gelu=False)
|
||||
y = y.transpose(1, 2)
|
||||
return y.to(dtype=x.dtype)
|
||||
|
||||
|
||||
class PositionalEmbedding(nn.Module):
|
||||
def __init__(self, emb_dim: int, seq_len: int, **kwargs):
|
||||
"""Complex exponential positional embeddings for implicit long convolution filters."""
|
||||
super().__init__()
|
||||
|
||||
self.seq_len = seq_len
|
||||
# The time embedding fed to the filteres is normalized so that t_f = 1
|
||||
t = torch.linspace(0, 1, self.seq_len)[None, :, None] # 1, L, 1
|
||||
|
||||
if emb_dim > 1:
|
||||
bands = (emb_dim - 1) // 2
|
||||
# To compute the right embeddings we use the "proper" linspace
|
||||
t_rescaled = torch.linspace(0, seq_len - 1, seq_len)[None, :, None]
|
||||
w = 2 * math.pi * t_rescaled / seq_len # 1, L, 1
|
||||
|
||||
f = torch.linspace(1e-4, bands - 1, bands)[None, None]
|
||||
z = torch.exp(-1j * f * w)
|
||||
z = torch.cat([t, z.real, z.imag], dim=-1)
|
||||
self.z = nn.Parameter(z, requires_grad=False)
|
||||
|
||||
def forward(self, L):
|
||||
return self.z[:, :L]
|
||||
|
||||
|
||||
class ImplicitLongConvolution(nn.Module):
|
||||
"""
|
||||
Long convolution with implicit filter parameterized by an MLP.
|
||||
|
||||
Args:
|
||||
hidden_size (int):
|
||||
The number of expected features in the input and output.
|
||||
l_max (int):
|
||||
The maximum sequence length.
|
||||
d_emb (Optional[int]):
|
||||
The dimension of the positional embeddings. Must be odd and greater or equal to 3 (time, sine and cosine).
|
||||
Defaults to 3.
|
||||
d_hidden (Optional[int]):
|
||||
The number of features in the hidden layer of the MLP. Defaults to 16.
|
||||
|
||||
Attributes:
|
||||
pos_emb (`PositionalEmbedding`): The positional embedding layer.
|
||||
mlp (`nn.Sequential`): The MLP that parameterizes the implicit filter.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
l_max: int,
|
||||
d_emb: int = 3,
|
||||
d_hidden: int = 16,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
Long convolution with implicit filter parameterized by an MLP.
|
||||
|
||||
|
||||
"""
|
||||
super().__init__()
|
||||
self.hidden_size = hidden_size
|
||||
self.d_emb = d_emb
|
||||
|
||||
assert (
|
||||
d_emb % 2 != 0 and d_emb >= 3
|
||||
), "d_emb must be odd and greater or equal to 3 (time, sine and cosine)"
|
||||
self.pos_emb = PositionalEmbedding(d_emb, l_max)
|
||||
|
||||
# final linear layer
|
||||
self.mlp = nn.Sequential(
|
||||
nn.Linear(d_emb, d_hidden),
|
||||
torch.nn.ReLU(),
|
||||
nn.Linear(d_hidden, hidden_size),
|
||||
)
|
||||
|
||||
def filter(self, seq_len: int, *args, **kwargs):
|
||||
k = self.mlp(self.pos_emb(seq_len))
|
||||
|
||||
return k.transpose(1, 2)
|
||||
|
||||
def forward(self, x: torch.Tensor, *args, **kwargs):
|
||||
"""
|
||||
Args:
|
||||
x: (b, l, d) tensor
|
||||
Returns:
|
||||
y: (b, l, d) tensor
|
||||
"""
|
||||
x = x.transpose(1, 2)
|
||||
k = self.filter(x.shape[-1])
|
||||
y = fft_conv(x, k, dropout_mask=None, gelu=False)
|
||||
|
||||
y = y.transpose(1, 2)
|
||||
return y.to(dtype=x.dtype)
|
||||
235
finetune/lora/v6/fla/modules/feature_map.py
vendored
Normal file
235
finetune/lora/v6/fla/modules/feature_map.py
vendored
Normal file
@ -0,0 +1,235 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
from fla.modules.layernorm import layer_norm_fn
|
||||
from fla.utils import checkpoint
|
||||
|
||||
|
||||
@checkpoint
|
||||
def flatten_diag_outer_product(x, y):
|
||||
z = torch.einsum("...i,...j->...ij", x, y)
|
||||
N = z.size(-1)
|
||||
indicies = torch.triu_indices(N, N)
|
||||
return z[..., indicies[0], indicies[1]]
|
||||
|
||||
|
||||
@checkpoint
|
||||
def flatten_diag_outer_product_off1(x, y):
|
||||
z = torch.einsum("...i,...j->...ij", x, y)
|
||||
N = z.size(-1)
|
||||
indicies = torch.triu_indices(N, N, 1)
|
||||
indices2 = torch.arange(0, N)
|
||||
return z[..., indicies[0], indicies[1]], z[..., indices2, indices2]
|
||||
|
||||
|
||||
def is_power_of_2(n):
|
||||
return (n & (n - 1) == 0) and n != 0
|
||||
|
||||
|
||||
class HedgehogFeatureMap(nn.Module):
|
||||
|
||||
r"""
|
||||
Hedgehog feature map as introduced in
|
||||
`The Hedgehog & the Porcupine: Expressive Linear Attentions with Softmax Mimicry <https://arxiv.org/abs/2402.04347>`_
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
head_dim: int
|
||||
) -> HedgehogFeatureMap:
|
||||
super().__init__()
|
||||
# Trainable map
|
||||
self.layer = nn.Linear(head_dim, head_dim)
|
||||
self.init_weights_()
|
||||
|
||||
def init_weights_(self):
|
||||
"""Initialize trainable map as identity"""
|
||||
with torch.no_grad():
|
||||
identity = torch.eye(*self.layer.weight.shape[-2:], dtype=torch.float)
|
||||
self.layer.weight.copy_(identity.to(self.layer.weight))
|
||||
nn.init.zeros_(self.layer.bias)
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
x = self.layer(x) # shape b, h, l, d
|
||||
return torch.cat([2*x, -2*x], dim=-1).softmax(-1)
|
||||
|
||||
|
||||
class T2RFeatureMap(nn.Module):
|
||||
|
||||
r"""
|
||||
Simple linear mapping feature map as in
|
||||
`Finetuning Pretrained Transformers into RNNs <https://arxiv.org/abs/2103.13076>`_
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
head_dim: int,
|
||||
dot_dim: int = None
|
||||
) -> T2RFeatureMap:
|
||||
super().__init__()
|
||||
# Trainable map
|
||||
if dot_dim is None:
|
||||
dot_dim = head_dim
|
||||
self.layer = nn.Linear(head_dim, dot_dim)
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
return self.layer(x).relu()
|
||||
|
||||
|
||||
class DPFPFeatureMap(nn.Module):
|
||||
|
||||
r"""
|
||||
Deterministic Parameter-Free Projection (DPFP) feature map in
|
||||
`Linear Transformers Are Secretly Fast Weight Programmers <https://arxiv.org/abs/2102.11174>`_
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
head_dim: int,
|
||||
nu: int = 4
|
||||
) -> DPFPFeatureMap:
|
||||
super().__init__()
|
||||
self.nu = nu
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
x = torch.cat([x.relu(), -x.relu()], dim=-1)
|
||||
x_rolled = torch.cat([x.roll(shifts=j, dims=-1) for j in range(1, self.nu+1)], dim=-1)
|
||||
x_repeat = torch.cat([x] * self.nu, dim=-1)
|
||||
return x_repeat * x_rolled
|
||||
|
||||
|
||||
class HadamardFeatureMap(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
head_dim: int
|
||||
) -> HadamardFeatureMap:
|
||||
super().__init__()
|
||||
# Trainable map
|
||||
self.layer1 = nn.Linear(head_dim, head_dim)
|
||||
self.layer2 = nn.Linear(head_dim, head_dim)
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
return self.layer1(x) * self.layer2(x)
|
||||
|
||||
|
||||
class LearnableOuterProductFeatureMap(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
head_dim: int,
|
||||
feature_dim: int
|
||||
) -> LearnableOuterProductFeatureMap:
|
||||
super().__init__()
|
||||
# Trainable map
|
||||
self.layer1 = nn.Linear(head_dim, feature_dim, bias=False)
|
||||
self.layer2 = nn.Linear(head_dim, feature_dim, bias=False)
|
||||
self.normalizer = feature_dim ** -0.5
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
return flatten_diag_outer_product(self.layer1(x), self.layer2(x))
|
||||
|
||||
|
||||
class LearnablePolySketchNonNegativeFeatureMap(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
head_dim: int,
|
||||
sketch_size: Optional[int] = None,
|
||||
degree: Optional[int] = 2
|
||||
) -> LearnablePolySketchNonNegativeFeatureMap:
|
||||
super().__init__()
|
||||
|
||||
assert is_power_of_2(degree) and degree >= 2, f"The degree {degree} must be a power of 2"
|
||||
|
||||
self.head_dim = head_dim
|
||||
self.sketch_size = sketch_size if sketch_size is not None else head_dim
|
||||
self.degree = degree
|
||||
|
||||
self.gamma = nn.Parameter(torch.ones(head_dim))
|
||||
self.beta = nn.Parameter(torch.zeros(head_dim))
|
||||
# NOTE: the sketch layers defined here are quite different from the original paper
|
||||
# currently we simply use linear layers without any non-linear activations
|
||||
self.sketches1 = nn.ModuleList([
|
||||
nn.Linear(head_dim, sketch_size, bias=False),
|
||||
*[nn.Linear(sketch_size, sketch_size, bias=False) for _ in range(int(math.log2(self.degree)) - 2)]
|
||||
])
|
||||
self.sketches2 = nn.ModuleList([
|
||||
nn.Linear(head_dim, sketch_size, bias=False),
|
||||
*[nn.Linear(sketch_size, sketch_size, bias=False) for _ in range(int(math.log2(self.degree)) - 2)]
|
||||
])
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
# Section 2.1
|
||||
x = layer_norm_fn(x, self.gamma, self.beta)
|
||||
# first map the input to sketch size with learnable parameters
|
||||
x = self.sketches1[0](x) * self.sketches2[0](x) * self.head_dim ** -0.5
|
||||
for i in range(1, int(math.log2(self.degree)) - 1):
|
||||
x = self.sketches1[i](x) * self.sketches2[i](x) * self.head_dim ** -0.5
|
||||
# do sketch mapping for log2(p) - 1 times in total
|
||||
# do p=2 mapping to ensure non-negativity
|
||||
return flatten_diag_outer_product(x, x)
|
||||
|
||||
|
||||
class TaylorFeatureMap(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
head_dim: int
|
||||
) -> TaylorFeatureMap:
|
||||
super().__init__()
|
||||
self.head_dim = head_dim
|
||||
self.r2 = math.sqrt(2)
|
||||
self.rd = math.sqrt(self.head_dim)
|
||||
self.rrd = math.sqrt(self.rd)
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
x2_1, x2_2 = flatten_diag_outer_product_off1(x, x)
|
||||
return torch.cat([torch.ones_like(x[..., 0:1]), x / self.rrd, x2_2 / (self.rd * self.r2), x2_1 / self.rd], dim=-1)
|
||||
|
||||
|
||||
class RebasedFeatureMap(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
head_dim: int,
|
||||
use_gamma: Optional[bool] = True,
|
||||
use_beta: Optional[bool] = True,
|
||||
normalize: Optional[bool] = True
|
||||
) -> RebasedFeatureMap:
|
||||
super().__init__()
|
||||
|
||||
self.head_dim = head_dim
|
||||
self.use_gamma = use_gamma
|
||||
self.use_beta = use_beta
|
||||
self.normalize = normalize
|
||||
|
||||
self.gamma = None
|
||||
self.beta = None
|
||||
if use_gamma:
|
||||
self.gamma = nn.Parameter(torch.ones(head_dim))
|
||||
if use_beta:
|
||||
self.beta = nn.Parameter(torch.zeros(head_dim))
|
||||
|
||||
def forward(self, x: torch.Tensor, flatten: Optional[bool] = True):
|
||||
if self.use_beta and self.use_gamma and self.normalize:
|
||||
x = layer_norm_fn(x, self.gamma, self.beta)
|
||||
elif self.normalize:
|
||||
x = F.layer_norm(x, (self.head_dim,), self.gamma, self.beta)
|
||||
elif self.use_gamma and self.use_beta:
|
||||
x = torch.addcmul(self.beta, x, self.gamma)
|
||||
elif self.use_gamma:
|
||||
x = x.mul(self.gamma)
|
||||
else:
|
||||
raise RuntimeError(f"Not supported combination of `use_gamma`, `use_beta` and `normalize`, "
|
||||
f"which is currentlt set as (`{self.use_gamma}`, `{self.use_beta}`, `{self.normalize}`)")
|
||||
if not flatten:
|
||||
return x
|
||||
x2_1, x2_2 = flatten_diag_outer_product_off1(x, x)
|
||||
# rebased use learnable parameters to approximate any quadratic function
|
||||
return torch.cat([x2_2 * self.head_dim ** -0.5, x2_1 * (2 / self.head_dim) ** 0.5], dim=-1)
|
||||
398
finetune/lora/v6/fla/modules/fused_cross_entropy.py
vendored
Normal file
398
finetune/lora/v6/fla/modules/fused_cross_entropy.py
vendored
Normal file
@ -0,0 +1,398 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Copyright (c) 2023, Tri Dao.
|
||||
|
||||
from typing import Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
# `all_gather_into_tensor` and `reduce_scatter_tensor` are new placeholders for
|
||||
# `_all_gather_base` and `_reduce_scatter_base`. They require the most recent
|
||||
# version of PyTorch. The following 2 lines are for backward compatibility with
|
||||
# older PyTorch.
|
||||
if "all_gather_into_tensor" not in dir(torch.distributed):
|
||||
torch.distributed.all_gather_into_tensor = torch.distributed._all_gather_base
|
||||
|
||||
|
||||
@triton.heuristics(
|
||||
{
|
||||
"HAS_SMOOTHING": lambda args: args["smoothing"] > 0.0,
|
||||
}
|
||||
)
|
||||
@triton.jit
|
||||
def cross_entropy_fwd_kernel(
|
||||
loss_ptr, # data ptrs
|
||||
lse_ptr,
|
||||
z_loss_ptr,
|
||||
logits_ptr,
|
||||
labels_ptr,
|
||||
smoothing,
|
||||
logit_scale,
|
||||
lse_square_scale,
|
||||
ignored_index,
|
||||
total_classes,
|
||||
class_start_idx, # Useful for tensor parallel when each rank only has a subset of classes
|
||||
n_cols, # shapes
|
||||
n_rows,
|
||||
logits_row_stride, # strides
|
||||
BLOCK_SIZE: tl.constexpr,
|
||||
HAS_SMOOTHING: tl.constexpr,
|
||||
# if SPLIT (e.g. tensor parallel), don't include the LSE in the loss since it's not the final LSE
|
||||
SPLIT: tl.constexpr,
|
||||
):
|
||||
row_idx = tl.program_id(0)
|
||||
col_block_idx = tl.program_id(1)
|
||||
logits_ptr = logits_ptr + row_idx * logits_row_stride.to(tl.int64)
|
||||
col_offsets = col_block_idx * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
|
||||
label_idx = tl.load(labels_ptr + row_idx)
|
||||
logits = tl.load(logits_ptr + col_offsets, mask=col_offsets < n_cols, other=-float("inf")).to(
|
||||
tl.float32
|
||||
) * logit_scale
|
||||
max_logits = tl.max(logits, 0)
|
||||
if HAS_SMOOTHING:
|
||||
sum_logits = tl.sum(tl.where(col_offsets < n_cols, logits, 0.0), 0)
|
||||
lse = tl.log(tl.sum(tl.exp(logits - max_logits), 0)) + max_logits
|
||||
tl.store(lse_ptr + col_block_idx * n_rows + row_idx, lse)
|
||||
if label_idx == ignored_index:
|
||||
loss = 0.0
|
||||
z_loss = 0.0
|
||||
else:
|
||||
label_idx -= class_start_idx
|
||||
if label_idx >= col_block_idx * BLOCK_SIZE and label_idx < min(
|
||||
n_cols, (col_block_idx + 1) * BLOCK_SIZE
|
||||
):
|
||||
logits_label = tl.load(logits_ptr + label_idx) * logit_scale
|
||||
if HAS_SMOOTHING:
|
||||
loss = (
|
||||
(lse if not SPLIT else 0.0)
|
||||
- smoothing * sum_logits / total_classes
|
||||
- (1 - smoothing) * logits_label
|
||||
)
|
||||
else:
|
||||
loss = (lse if not SPLIT else 0.0) - logits_label
|
||||
else:
|
||||
# If label is out of bounds, we set the CE loss to 0.0. But we still want the smoothing loss
|
||||
if HAS_SMOOTHING:
|
||||
loss = smoothing * ((lse if not SPLIT else 0.0) - sum_logits / total_classes)
|
||||
else:
|
||||
loss = 0.0
|
||||
if not SPLIT:
|
||||
z_loss = lse_square_scale * lse * lse
|
||||
loss += z_loss
|
||||
else:
|
||||
z_loss = 0.0
|
||||
tl.store(loss_ptr + col_block_idx * n_rows + row_idx, loss)
|
||||
if not SPLIT:
|
||||
tl.store(z_loss_ptr + col_block_idx * n_rows + row_idx, z_loss)
|
||||
|
||||
|
||||
@triton.heuristics(
|
||||
{
|
||||
"HAS_SMOOTHING": lambda args: args["smoothing"] > 0.0,
|
||||
}
|
||||
)
|
||||
@triton.jit
|
||||
def cross_entropy_bwd_kernel(
|
||||
dlogits_ptr, # data ptrs
|
||||
dloss_ptr,
|
||||
logits_ptr,
|
||||
lse_ptr,
|
||||
labels_ptr,
|
||||
smoothing,
|
||||
logit_scale,
|
||||
lse_square_scale,
|
||||
ignored_index,
|
||||
total_classes,
|
||||
class_start_idx, # Useful for tensor parallel when each rank only has a subset of classes
|
||||
n_cols, # shapes
|
||||
logits_row_stride, # strides
|
||||
dlogits_row_stride,
|
||||
dloss_row_stride,
|
||||
BLOCK_SIZE: tl.constexpr,
|
||||
HAS_SMOOTHING: tl.constexpr,
|
||||
):
|
||||
row_idx = tl.program_id(0)
|
||||
col_block_idx = tl.program_id(1)
|
||||
logits_ptr = logits_ptr + row_idx * logits_row_stride.to(tl.int64)
|
||||
dlogits_ptr = dlogits_ptr + row_idx * dlogits_row_stride.to(tl.int64)
|
||||
col_offsets = col_block_idx * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
|
||||
label_idx = tl.load(labels_ptr + row_idx)
|
||||
if label_idx != ignored_index:
|
||||
dloss = tl.load(dloss_ptr + row_idx * dloss_row_stride)
|
||||
else:
|
||||
dloss = 0.0
|
||||
logits = tl.load(logits_ptr + col_offsets, mask=col_offsets < n_cols, other=-float("inf")).to(
|
||||
tl.float32
|
||||
) * logit_scale
|
||||
lse = tl.load(lse_ptr + row_idx)
|
||||
probs = tl.exp(logits - lse)
|
||||
probs += 2.0 * lse_square_scale * lse * probs
|
||||
label_idx -= class_start_idx
|
||||
if HAS_SMOOTHING:
|
||||
smooth_negative = smoothing / total_classes
|
||||
probs = tl.where(col_offsets == label_idx, probs - (1 - smoothing), probs) - smooth_negative
|
||||
else:
|
||||
probs = tl.where(col_offsets == label_idx, probs - 1.0, probs)
|
||||
tl.store(dlogits_ptr + col_offsets, (dloss * logit_scale) * probs, mask=col_offsets < n_cols)
|
||||
|
||||
|
||||
class CrossEntropyLossFunction(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
def forward(
|
||||
ctx,
|
||||
logits,
|
||||
labels,
|
||||
smoothing=0.0,
|
||||
logit_scale=1.0,
|
||||
lse_square_scale=0.0,
|
||||
ignored_index=-100,
|
||||
inplace_backward=False,
|
||||
process_group=None,
|
||||
):
|
||||
n_rows, n_cols = logits.shape
|
||||
assert labels.shape == (n_rows,)
|
||||
world_size = 1 if process_group is None else torch.distributed.get_world_size(process_group)
|
||||
total_classes = world_size * n_cols
|
||||
rank = 0 if process_group is None else torch.distributed.get_rank(process_group)
|
||||
class_start_idx = rank * n_cols
|
||||
|
||||
if logits.stride(-1) != 1:
|
||||
logits = logits.contiguous()
|
||||
# Set these similar to https://github.com/openai/triton/blob/main/python/tutorials/02-fused-softmax.py
|
||||
MAX_BLOCK_SIZE = 64 * 1024
|
||||
BLOCK_SIZE = min(triton.next_power_of_2(n_cols), MAX_BLOCK_SIZE)
|
||||
num_warps = (
|
||||
4
|
||||
if BLOCK_SIZE < 2048
|
||||
else (8 if BLOCK_SIZE < 8192 else (16 if BLOCK_SIZE < 128 * 1024 else 32))
|
||||
)
|
||||
# We may split the lse computation across multiple blocks, then do a reduction
|
||||
# lse(local_lse) to get the final LSE. This is faster for large n_cols (e.g., > 64k)
|
||||
# where having just one thread block processing more than 64k elements is slow.
|
||||
split = world_size > 1 or n_cols > MAX_BLOCK_SIZE
|
||||
n_splits = (n_cols + BLOCK_SIZE - 1) // BLOCK_SIZE
|
||||
loss_shape = (n_splits, n_rows) if n_splits > 1 else (n_rows,)
|
||||
losses = torch.empty(*loss_shape, dtype=torch.float, device=logits.device)
|
||||
lse = torch.empty(*loss_shape, dtype=torch.float, device=logits.device)
|
||||
z_losses = torch.empty(*loss_shape, dtype=torch.float, device=logits.device)
|
||||
# Need this, otherwise Triton tries to launch from cuda:0 and we get
|
||||
# ValueError: Pointer argument (at 0) cannot be accessed from Triton (cpu tensor?)
|
||||
with torch.cuda.device(logits.device.index):
|
||||
cross_entropy_fwd_kernel[(n_rows, n_splits)](
|
||||
losses, # data ptrs
|
||||
lse,
|
||||
z_losses,
|
||||
logits,
|
||||
labels,
|
||||
smoothing,
|
||||
logit_scale,
|
||||
lse_square_scale,
|
||||
ignored_index,
|
||||
total_classes,
|
||||
class_start_idx,
|
||||
n_cols, # shapes
|
||||
n_rows,
|
||||
logits.stride(0), # strides
|
||||
BLOCK_SIZE=BLOCK_SIZE, # constants
|
||||
num_warps=num_warps,
|
||||
SPLIT=split,
|
||||
)
|
||||
|
||||
if split:
|
||||
# If there's no smoothing, if labels are in the vocab of this partition, losses contains
|
||||
# - predicted logit, and 0 otherwise.
|
||||
# If there's smoothing=0.1, for labels in the vocab of this partition, losses contains
|
||||
# -0.9 * predicted logit - 0.1 * sum logit / total_classes.
|
||||
# For labels not in the vocab of this partition, losses contains
|
||||
# -0.1 * sum logit / total_classes.
|
||||
if n_splits > 1:
|
||||
lse = torch.logsumexp(lse, dim=0)
|
||||
losses = losses.sum(dim=0)
|
||||
if world_size > 1:
|
||||
lse_allgather = torch.empty(world_size, n_rows, dtype=lse.dtype, device=lse.device)
|
||||
torch.distributed.all_gather_into_tensor(lse_allgather, lse, group=process_group)
|
||||
handle_losses = torch.distributed.all_reduce(
|
||||
losses, op=torch.distributed.ReduceOp.SUM, group=process_group, async_op=True
|
||||
)
|
||||
lse = torch.logsumexp(lse_allgather, dim=0)
|
||||
handle_losses.wait()
|
||||
# After the allreduce, if there's no smoothing, the total losses are - predicted_logit,
|
||||
# we just have to add the (global) lse.
|
||||
# If there's smoothing=0.1, the total losses are
|
||||
# -0.9 * predicted_logit - 0.1 * sum logit / total_classes.
|
||||
# Again, we just have to add the (global) lse.
|
||||
losses += lse
|
||||
if lse_square_scale != 0.0:
|
||||
z_losses = lse_square_scale * lse.square()
|
||||
z_losses.masked_fill_(labels == ignored_index, 0.0)
|
||||
losses += z_losses
|
||||
else:
|
||||
z_losses = torch.zeros_like(losses)
|
||||
losses.masked_fill_(labels == ignored_index, 0.0)
|
||||
|
||||
ctx.save_for_backward(logits, lse, labels)
|
||||
ctx.mark_non_differentiable(z_losses)
|
||||
ctx.smoothing = smoothing
|
||||
ctx.logit_scale = logit_scale
|
||||
ctx.lse_square_scale = lse_square_scale
|
||||
ctx.ignored_index = ignored_index
|
||||
ctx.total_classes = total_classes
|
||||
ctx.class_start_idx = class_start_idx
|
||||
ctx.inplace_backward = inplace_backward
|
||||
|
||||
return losses, z_losses
|
||||
|
||||
@staticmethod
|
||||
def backward(ctx, grad_losses, grad_z_losses):
|
||||
del grad_z_losses # z_losses are only for logging.
|
||||
|
||||
logits, lse, labels = ctx.saved_tensors
|
||||
dlogits = logits if ctx.inplace_backward else torch.empty_like(logits)
|
||||
n_rows, n_cols = logits.shape
|
||||
BLOCK_SIZE = min(triton.next_power_of_2(n_cols), 4 * 1024)
|
||||
num_warps = 4 if BLOCK_SIZE < 2048 else (8 if BLOCK_SIZE < 8192 else 16)
|
||||
def grid(META): return (n_rows, triton.cdiv(n_cols, META["BLOCK_SIZE"])) # noqa
|
||||
# Need this, otherwise Triton tries to launch from cuda:0 and we get
|
||||
# ValueError: Pointer argument (at 0) cannot be accessed from Triton (cpu tensor?)
|
||||
with torch.cuda.device(logits.device.index):
|
||||
cross_entropy_bwd_kernel[grid](
|
||||
dlogits, # data ptrs
|
||||
grad_losses,
|
||||
logits,
|
||||
lse,
|
||||
labels,
|
||||
ctx.smoothing,
|
||||
ctx.logit_scale,
|
||||
ctx.lse_square_scale,
|
||||
ctx.ignored_index,
|
||||
ctx.total_classes,
|
||||
ctx.class_start_idx,
|
||||
n_cols, # shapes
|
||||
logits.stride(0), # strides
|
||||
dlogits.stride(0),
|
||||
grad_losses.stride(0),
|
||||
BLOCK_SIZE=BLOCK_SIZE, # constants
|
||||
num_warps=num_warps,
|
||||
)
|
||||
return dlogits, None, None, None, None, None, None, None, None
|
||||
|
||||
|
||||
def cross_entropy_loss(
|
||||
logits: torch.Tensor,
|
||||
labels: torch.Tensor,
|
||||
label_smoothing: float = 0.0,
|
||||
logit_scale: float = 1.0,
|
||||
lse_square_scale: float = 0.0,
|
||||
ignored_index=-100,
|
||||
inplace_backward: bool = False,
|
||||
process_group=None,
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
"""
|
||||
Arguments:
|
||||
logits: (batch, vocab_size)
|
||||
labels: (batch,)
|
||||
label_smoothing: float
|
||||
logit_scale: float. Multiply logits by this scale before calculating the loss.
|
||||
lse_square_scale: float. If > 0, we add lse_square_scale * lse(logits) ^ 2 to the loss.
|
||||
This is also referred to as "z-loss".
|
||||
ignored_index: int. If labels == ignored_index, the loss is set to 0.0.
|
||||
inplace_backward: bool. If True, we do the backward pass in-place by modifying the logits.
|
||||
This saves memory.
|
||||
process_group: if not None, we're doing Tensor Parallel: each process is responsible for
|
||||
one part of the vocab. The loss will be aggregated across processes.
|
||||
Returns:
|
||||
losses: (batch,), float
|
||||
z_losses: (batch,), float
|
||||
"""
|
||||
return CrossEntropyLossFunction.apply(
|
||||
logits,
|
||||
labels,
|
||||
label_smoothing,
|
||||
logit_scale,
|
||||
lse_square_scale,
|
||||
ignored_index,
|
||||
inplace_backward,
|
||||
process_group,
|
||||
)
|
||||
|
||||
|
||||
class FusedCrossEntropyLoss(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
ignore_index=-100,
|
||||
reduction="mean",
|
||||
label_smoothing=0.0,
|
||||
logit_scale=1.0,
|
||||
lse_square_scale=0.0,
|
||||
inplace_backward=False,
|
||||
process_group=None,
|
||||
return_z_loss=False,
|
||||
):
|
||||
"""
|
||||
Arguments:
|
||||
ignored_index: int. If labels == ignored_index, the loss is set to 0.0.
|
||||
label_smoothing: float
|
||||
lse_square_scale: float. If > 0, we add lse_square_scale * lse(logits) ^ 2 to the loss.
|
||||
This is also referred to as "z-loss".
|
||||
inplace_backward: bool. If True, we do the backward pass in-place by modifying the logits.
|
||||
This saves memory.
|
||||
process_group: if not None, we're doing Tensor Parallel: each process is responsible for
|
||||
one part of the vocab. The loss will be aggregated across processes.
|
||||
return_z_loss: bool. If True, we return the component of the loss contributed by
|
||||
the lse_square_scale value. This value is only for logging and does not support
|
||||
backprop.
|
||||
"""
|
||||
super().__init__()
|
||||
if reduction not in ["mean", "none", "sum"]:
|
||||
raise NotImplementedError("Only support reduction = 'mean' or 'none' or 'sum'")
|
||||
self.ignore_index = ignore_index
|
||||
self.reduction = reduction
|
||||
self.label_smoothing = label_smoothing
|
||||
self.logit_scale = logit_scale
|
||||
self.lse_square_scale = lse_square_scale
|
||||
self.inplace_backward = inplace_backward
|
||||
self.process_group = process_group
|
||||
self.return_z_loss = return_z_loss
|
||||
|
||||
def forward(self, input, target):
|
||||
"""
|
||||
Arguments:
|
||||
input: (batch, vocab_size)
|
||||
target: (batch,)
|
||||
Returns:
|
||||
losses: (batch,) if reduction is 'none', else (1,), dtype float
|
||||
z_loss: (batch,) if reduction is 'none', else (1,), dtype float (if self.return_z_loss)
|
||||
"""
|
||||
assert input.is_cuda and target.is_cuda, "Only support CUDA tensors"
|
||||
loss, z_loss = cross_entropy_loss(
|
||||
input,
|
||||
target,
|
||||
label_smoothing=self.label_smoothing,
|
||||
logit_scale=self.logit_scale,
|
||||
lse_square_scale=self.lse_square_scale,
|
||||
ignored_index=self.ignore_index,
|
||||
inplace_backward=self.inplace_backward,
|
||||
process_group=self.process_group,
|
||||
)
|
||||
if self.reduction == "mean":
|
||||
loss = loss.sum() / (target != self.ignore_index).sum()
|
||||
elif self.reduction == "sum":
|
||||
loss = loss.sum()
|
||||
else:
|
||||
loss = loss
|
||||
|
||||
if not self.return_z_loss:
|
||||
return loss
|
||||
|
||||
if self.reduction == "mean":
|
||||
z_loss = z_loss.sum() / (target != self.ignore_index).sum()
|
||||
elif self.reduction == "sum":
|
||||
z_loss = z_loss.sum()
|
||||
else:
|
||||
z_loss = z_loss
|
||||
|
||||
return loss, z_loss
|
||||
889
finetune/lora/v6/fla/modules/fused_norm_gate.py
vendored
Normal file
889
finetune/lora/v6/fla/modules/fused_norm_gate.py
vendored
Normal file
@ -0,0 +1,889 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Copyright (c) 2023, Tri Dao.
|
||||
# https://github.com/state-spaces/mamba/blob/fb7b5310fa865dbd62aa059b1e26f2b431363e2a/mamba_ssm/ops/triton/layernorm.py
|
||||
# Implement residual + layer_norm / rms_norm.
|
||||
|
||||
# Based on the Triton LayerNorm tutorial: https://triton-lang.org/main/getting-started/tutorials/05-layer-norm.html
|
||||
# For the backward pass, we keep weight_grad and bias_grad in registers and accumulate.
|
||||
# This is faster for dimensions up to 8k, but after that it's much slower due to register spilling.
|
||||
# The models we train have hidden dim up to 8k anyway (e.g. Llama 70B), so this is fine.
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from fla.utils import contiguous
|
||||
|
||||
|
||||
def layer_norm_ref(x, weight, bias, residual=None, eps=1e-6, prenorm=False, upcast=False):
|
||||
dtype = x.dtype
|
||||
if upcast:
|
||||
weight = weight.float()
|
||||
bias = bias.float() if bias is not None else None
|
||||
if upcast:
|
||||
x = x.float()
|
||||
residual = residual.float() if residual is not None else residual
|
||||
if residual is not None:
|
||||
x = (x + residual).to(x.dtype)
|
||||
out = F.layer_norm(x.to(weight.dtype), x.shape[-1:], weight=weight, bias=bias, eps=eps).to(
|
||||
dtype
|
||||
)
|
||||
return out if not prenorm else (out, x)
|
||||
|
||||
|
||||
def rms_norm_ref(x, weight, bias, residual=None, eps=1e-6, prenorm=False, upcast=False):
|
||||
dtype = x.dtype
|
||||
if upcast:
|
||||
weight = weight.float()
|
||||
bias = bias.float() if bias is not None else None
|
||||
if upcast:
|
||||
x = x.float()
|
||||
residual = residual.float() if residual is not None else residual
|
||||
if residual is not None:
|
||||
x = (x + residual).to(x.dtype)
|
||||
rstd = 1 / torch.sqrt((x.square()).mean(dim=-1, keepdim=True) + eps)
|
||||
out = (x * rstd * weight) + \
|
||||
bias if bias is not None else (x * rstd * weight)
|
||||
out = out.to(dtype)
|
||||
return out if not prenorm else (out, x)
|
||||
|
||||
|
||||
@triton.autotune(
|
||||
configs=[
|
||||
triton.Config({}, num_warps=1),
|
||||
triton.Config({}, num_warps=2),
|
||||
triton.Config({}, num_warps=4),
|
||||
triton.Config({}, num_warps=8),
|
||||
triton.Config({}, num_warps=16),
|
||||
triton.Config({}, num_warps=32),
|
||||
],
|
||||
key=["N", "HAS_RESIDUAL", "STORE_RESIDUAL_OUT", "IS_RMS_NORM", "HAS_BIAS"],
|
||||
)
|
||||
# @triton.heuristics({"HAS_BIAS": lambda args: args["B"] is not None})
|
||||
# @triton.heuristics({"HAS_RESIDUAL": lambda args: args["RESIDUAL"] is not None})
|
||||
@triton.jit
|
||||
def _layer_norm_fwd_1pass_kernel(
|
||||
X, # pointer to the input
|
||||
O, # pointer to the gate
|
||||
Y, # pointer to the output
|
||||
W, # pointer to the weights
|
||||
B, # pointer to the biases
|
||||
RESIDUAL, # pointer to the residual
|
||||
RESIDUAL_OUT, # pointer to the residual
|
||||
Mean, # pointer to the mean
|
||||
Rstd, # pointer to the 1/std
|
||||
stride_x_row, # how much to increase the pointer when moving by 1 row
|
||||
stride_y_row,
|
||||
stride_res_row,
|
||||
stride_res_out_row,
|
||||
N, # number of columns in X
|
||||
eps, # epsilon to avoid division by zero
|
||||
IS_RMS_NORM: tl.constexpr,
|
||||
BLOCK_N: tl.constexpr,
|
||||
HAS_RESIDUAL: tl.constexpr,
|
||||
STORE_RESIDUAL_OUT: tl.constexpr,
|
||||
HAS_WEIGHT: tl.constexpr,
|
||||
HAS_BIAS: tl.constexpr
|
||||
):
|
||||
# Map the program id to the row of X and Y it should compute.
|
||||
row = tl.program_id(0)
|
||||
X += row * stride_x_row
|
||||
Y += row * stride_y_row
|
||||
O += row * stride_x_row
|
||||
if HAS_RESIDUAL:
|
||||
RESIDUAL += row * stride_res_row
|
||||
if STORE_RESIDUAL_OUT:
|
||||
RESIDUAL_OUT += row * stride_res_out_row
|
||||
# Compute mean and variance
|
||||
cols = tl.arange(0, BLOCK_N)
|
||||
x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
|
||||
if HAS_RESIDUAL:
|
||||
residual = tl.load(RESIDUAL + cols, mask=cols <
|
||||
N, other=0.0).to(tl.float32)
|
||||
x += residual
|
||||
if STORE_RESIDUAL_OUT:
|
||||
tl.store(RESIDUAL_OUT + cols, x, mask=cols < N)
|
||||
if not IS_RMS_NORM:
|
||||
mean = tl.sum(x, axis=0) / N
|
||||
tl.store(Mean + row, mean)
|
||||
xbar = tl.where(cols < N, x - mean, 0.0)
|
||||
var = tl.sum(xbar * xbar, axis=0) / N
|
||||
else:
|
||||
xbar = tl.where(cols < N, x, 0.0)
|
||||
var = tl.sum(xbar * xbar, axis=0) / N
|
||||
rstd = 1 / tl.sqrt(var + eps)
|
||||
tl.store(Rstd + row, rstd)
|
||||
# Normalize and apply linear transformation
|
||||
mask = cols < N
|
||||
if HAS_WEIGHT:
|
||||
w = tl.load(W + cols, mask=mask).to(tl.float32)
|
||||
if HAS_BIAS:
|
||||
b = tl.load(B + cols, mask=mask).to(tl.float32)
|
||||
x_hat = (x - mean) * rstd if not IS_RMS_NORM else x * rstd
|
||||
y = x_hat * w if HAS_WEIGHT else x_hat
|
||||
if HAS_BIAS:
|
||||
y = y + b
|
||||
|
||||
# Swish output gate
|
||||
o = tl.load(O + cols, mask=cols < N, other=0.0).to(tl.float32)
|
||||
y = y * o * tl.sigmoid(o)
|
||||
|
||||
# Write output
|
||||
tl.store(Y + cols, y, mask=mask)
|
||||
|
||||
|
||||
def _layer_norm_fwd(
|
||||
x, o, weight, bias, eps, residual=None, out_dtype=None, residual_dtype=None, is_rms_norm=False
|
||||
):
|
||||
if residual is not None:
|
||||
residual_dtype = residual.dtype
|
||||
M, N = x.shape
|
||||
assert x.stride(-1) == 1
|
||||
if residual is not None:
|
||||
assert residual.stride(-1) == 1
|
||||
assert residual.shape == (M, N)
|
||||
if weight is not None:
|
||||
assert weight.shape == (N,)
|
||||
assert weight.stride(-1) == 1
|
||||
if bias is not None:
|
||||
assert bias.stride(-1) == 1
|
||||
assert bias.shape == (N,)
|
||||
# allocate output
|
||||
y = torch.empty_like(x, dtype=x.dtype if out_dtype is None else out_dtype)
|
||||
assert y.stride(-1) == 1
|
||||
if residual is not None or (residual_dtype is not None and residual_dtype != x.dtype):
|
||||
residual_out = torch.empty(M, N, device=x.device, dtype=residual_dtype)
|
||||
assert residual_out.stride(-1) == 1
|
||||
else:
|
||||
residual_out = None
|
||||
mean = torch.empty((M,), dtype=torch.float32,
|
||||
device="cuda") if not is_rms_norm else None
|
||||
rstd = torch.empty((M,), dtype=torch.float32, device="cuda")
|
||||
# Less than 64KB per feature: enqueue fused kernel
|
||||
MAX_FUSED_SIZE = 65536 // x.element_size()
|
||||
BLOCK_N = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
|
||||
if N > BLOCK_N:
|
||||
raise RuntimeError(
|
||||
"This layer norm doesn't support feature dim >= 64KB.")
|
||||
# heuristics for number of warps
|
||||
with torch.cuda.device(x.device.index):
|
||||
_layer_norm_fwd_1pass_kernel[(M,)](
|
||||
x,
|
||||
o,
|
||||
y,
|
||||
weight,
|
||||
bias,
|
||||
residual,
|
||||
residual_out,
|
||||
mean,
|
||||
rstd,
|
||||
x.stride(0),
|
||||
y.stride(0),
|
||||
residual.stride(0) if residual is not None else 0,
|
||||
residual_out.stride(0) if residual_out is not None else 0,
|
||||
N,
|
||||
eps,
|
||||
is_rms_norm,
|
||||
BLOCK_N,
|
||||
residual is not None,
|
||||
residual_out is not None,
|
||||
weight is not None,
|
||||
bias is not None,
|
||||
)
|
||||
# residual_out is None if residual is None and residual_dtype == input_dtype
|
||||
return y, mean, rstd, residual_out if residual_out is not None else x
|
||||
|
||||
|
||||
@triton.autotune(
|
||||
configs=[
|
||||
triton.Config({}, num_warps=1),
|
||||
triton.Config({}, num_warps=2),
|
||||
triton.Config({}, num_warps=4),
|
||||
triton.Config({}, num_warps=8),
|
||||
triton.Config({}, num_warps=16),
|
||||
triton.Config({}, num_warps=32),
|
||||
],
|
||||
key=["N", "HAS_DRESIDUAL", "STORE_DRESIDUAL", "IS_RMS_NORM", "HAS_BIAS"],
|
||||
)
|
||||
# @triton.heuristics({"HAS_BIAS": lambda args: args["B"] is not None})
|
||||
# @triton.heuristics({"HAS_DRESIDUAL": lambda args: args["DRESIDUAL"] is not None})
|
||||
# @triton.heuristics({"STORE_DRESIDUAL": lambda args: args["DRESIDUAL_IN"] is not None})
|
||||
@triton.heuristics({"RECOMPUTE_OUTPUT": lambda args: args["Y"] is not None})
|
||||
@triton.jit
|
||||
def _layer_norm_bwd_kernel(
|
||||
X, # pointer to the input
|
||||
O, # pointer to the gate
|
||||
W, # pointer to the weights
|
||||
B, # pointer to the biases
|
||||
Y, # pointer to the output to be recomputed
|
||||
DY, # pointer to the output gradient
|
||||
DX, # pointer to the input gradient
|
||||
DO, # pointer to the gate gradient
|
||||
DW, # pointer to the partial sum of weights gradient
|
||||
DB, # pointer to the partial sum of biases gradient
|
||||
DRESIDUAL,
|
||||
DRESIDUAL_IN,
|
||||
Mean, # pointer to the mean
|
||||
Rstd, # pointer to the 1/std
|
||||
stride_x_row, # how much to increase the pointer when moving by 1 row
|
||||
stride_y_row,
|
||||
stride_dy_row,
|
||||
stride_dx_row,
|
||||
stride_dres_row,
|
||||
stride_dres_in_row,
|
||||
M, # number of rows in X
|
||||
N, # number of columns in X
|
||||
eps, # epsilon to avoid division by zero
|
||||
rows_per_program,
|
||||
IS_RMS_NORM: tl.constexpr,
|
||||
BLOCK_N: tl.constexpr,
|
||||
HAS_DRESIDUAL: tl.constexpr,
|
||||
STORE_DRESIDUAL: tl.constexpr,
|
||||
HAS_WEIGHT: tl.constexpr,
|
||||
HAS_BIAS: tl.constexpr,
|
||||
RECOMPUTE_OUTPUT: tl.constexpr,
|
||||
):
|
||||
# Map the program id to the elements of X, DX, and DY it should compute.
|
||||
row_block_id = tl.program_id(0)
|
||||
row_start = row_block_id * rows_per_program
|
||||
cols = tl.arange(0, BLOCK_N)
|
||||
mask = cols < N
|
||||
X += row_start * stride_x_row
|
||||
O += row_start * stride_x_row
|
||||
if HAS_DRESIDUAL:
|
||||
DRESIDUAL += row_start * stride_dres_row
|
||||
if STORE_DRESIDUAL:
|
||||
DRESIDUAL_IN += row_start * stride_dres_in_row
|
||||
DY += row_start * stride_dy_row
|
||||
DX += row_start * stride_dx_row
|
||||
DO += row_start * stride_dx_row
|
||||
if RECOMPUTE_OUTPUT:
|
||||
Y += row_start * stride_y_row
|
||||
if HAS_WEIGHT:
|
||||
w = tl.load(W + cols, mask=mask).to(tl.float32)
|
||||
dw = tl.zeros((BLOCK_N,), dtype=tl.float32)
|
||||
if RECOMPUTE_OUTPUT and HAS_BIAS:
|
||||
b = tl.load(B + cols, mask=mask, other=0.0).to(tl.float32)
|
||||
if HAS_BIAS:
|
||||
db = tl.zeros((BLOCK_N,), dtype=tl.float32)
|
||||
row_end = min((row_block_id + 1) * rows_per_program, M)
|
||||
for row in range(row_start, row_end):
|
||||
# Load data to SRAM
|
||||
x = tl.load(X + cols, mask=mask, other=0).to(tl.float32)
|
||||
o = tl.load(O + cols, mask=mask, other=0).to(tl.float32)
|
||||
dy = tl.load(DY + cols, mask=mask, other=0).to(tl.float32)
|
||||
|
||||
if not IS_RMS_NORM:
|
||||
mean = tl.load(Mean + row)
|
||||
rstd = tl.load(Rstd + row)
|
||||
# Compute dx
|
||||
xhat = (x - mean) * rstd if not IS_RMS_NORM else x * rstd
|
||||
xhat = tl.where(mask, xhat, 0.0)
|
||||
|
||||
y = xhat * w if HAS_WEIGHT else xhat
|
||||
if HAS_BIAS:
|
||||
y = y + b
|
||||
if RECOMPUTE_OUTPUT:
|
||||
tl.store(Y + cols, y, mask=mask)
|
||||
|
||||
sigmoid_o = tl.sigmoid(o)
|
||||
do = dy * y * (sigmoid_o + o * sigmoid_o * (1 - sigmoid_o))
|
||||
dy = dy * o * sigmoid_o
|
||||
wdy = dy
|
||||
if HAS_WEIGHT:
|
||||
wdy = dy * w
|
||||
dw += dy * xhat
|
||||
if HAS_BIAS:
|
||||
db += dy
|
||||
if not IS_RMS_NORM:
|
||||
c1 = tl.sum(xhat * wdy, axis=0) / N
|
||||
c2 = tl.sum(wdy, axis=0) / N
|
||||
dx = (wdy - (xhat * c1 + c2)) * rstd
|
||||
else:
|
||||
c1 = tl.sum(xhat * wdy, axis=0) / N
|
||||
dx = (wdy - xhat * c1) * rstd
|
||||
if HAS_DRESIDUAL:
|
||||
dres = tl.load(DRESIDUAL + cols, mask=mask, other=0).to(tl.float32)
|
||||
dx += dres
|
||||
# Write dx
|
||||
if STORE_DRESIDUAL:
|
||||
tl.store(DRESIDUAL_IN + cols, dx, mask=mask)
|
||||
tl.store(DX + cols, dx, mask=mask)
|
||||
tl.store(DO + cols, do, mask=mask)
|
||||
|
||||
X += stride_x_row
|
||||
O += stride_x_row
|
||||
if HAS_DRESIDUAL:
|
||||
DRESIDUAL += stride_dres_row
|
||||
if STORE_DRESIDUAL:
|
||||
DRESIDUAL_IN += stride_dres_in_row
|
||||
if RECOMPUTE_OUTPUT:
|
||||
Y += stride_y_row
|
||||
DY += stride_dy_row
|
||||
DX += stride_dx_row
|
||||
DO += stride_dx_row
|
||||
if HAS_WEIGHT:
|
||||
tl.store(DW + row_block_id * N + cols, dw, mask=mask)
|
||||
if HAS_BIAS:
|
||||
tl.store(DB + row_block_id * N + cols, db, mask=mask)
|
||||
|
||||
|
||||
def _layer_norm_bwd(
|
||||
dy,
|
||||
x,
|
||||
o,
|
||||
weight,
|
||||
bias,
|
||||
eps,
|
||||
mean,
|
||||
rstd,
|
||||
dresidual=None,
|
||||
has_residual=False,
|
||||
is_rms_norm=False,
|
||||
x_dtype=None,
|
||||
recompute_output=False,
|
||||
):
|
||||
M, N = x.shape
|
||||
assert x.stride(-1) == 1
|
||||
assert dy.stride(-1) == 1
|
||||
assert dy.shape == (M, N)
|
||||
if dresidual is not None:
|
||||
assert dresidual.stride(-1) == 1
|
||||
assert dresidual.shape == (M, N)
|
||||
if weight is not None:
|
||||
assert weight.shape == (N,)
|
||||
assert weight.stride(-1) == 1
|
||||
if bias is not None:
|
||||
assert bias.stride(-1) == 1
|
||||
assert bias.shape == (N,)
|
||||
# allocate output
|
||||
dx = (
|
||||
torch.empty_like(x)
|
||||
if x_dtype is None
|
||||
else torch.empty(M, N, dtype=x_dtype, device=x.device)
|
||||
)
|
||||
do = (
|
||||
torch.empty_like(o)
|
||||
if x_dtype is None
|
||||
else torch.empty(M, N, dtype=x_dtype, device=x.device)
|
||||
)
|
||||
dresidual_in = torch.empty_like(x) if has_residual and dx.dtype != x.dtype else None
|
||||
y = torch.empty(M, N, dtype=dy.dtype, device=dy.device) if recompute_output else None
|
||||
|
||||
# Less than 64KB per feature: enqueue fused kernel
|
||||
MAX_FUSED_SIZE = 65536 // x.element_size()
|
||||
BLOCK_N = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
|
||||
if N > BLOCK_N:
|
||||
raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
|
||||
sm_count = torch.cuda.get_device_properties(x.device).multi_processor_count
|
||||
_dw = (
|
||||
torch.empty((sm_count, N), dtype=torch.float32, device=weight.device)
|
||||
if weight is not None
|
||||
else None
|
||||
)
|
||||
_db = (
|
||||
torch.empty((sm_count, N), dtype=torch.float32, device=bias.device)
|
||||
if bias is not None
|
||||
else None
|
||||
)
|
||||
rows_per_program = math.ceil(M / sm_count)
|
||||
grid = (sm_count,)
|
||||
with torch.cuda.device(x.device.index):
|
||||
_layer_norm_bwd_kernel[grid](
|
||||
x,
|
||||
o,
|
||||
weight,
|
||||
bias,
|
||||
y,
|
||||
dy,
|
||||
dx,
|
||||
do,
|
||||
_dw,
|
||||
_db,
|
||||
dresidual,
|
||||
dresidual_in,
|
||||
mean,
|
||||
rstd,
|
||||
x.stride(0),
|
||||
0 if not recompute_output else y.stride(0),
|
||||
dy.stride(0),
|
||||
dx.stride(0),
|
||||
dresidual.stride(0) if dresidual is not None else 0,
|
||||
dresidual_in.stride(0) if dresidual_in is not None else 0,
|
||||
M,
|
||||
N,
|
||||
eps,
|
||||
rows_per_program,
|
||||
is_rms_norm,
|
||||
BLOCK_N,
|
||||
dresidual is not None,
|
||||
dresidual_in is not None,
|
||||
weight is not None,
|
||||
bias is not None,
|
||||
)
|
||||
dw = _dw.sum(0).to(weight.dtype) if weight is not None else None
|
||||
db = _db.sum(0).to(bias.dtype) if bias is not None else None
|
||||
# Don't need to compute dresidual_in separately in this case
|
||||
if has_residual and dx.dtype == x.dtype:
|
||||
dresidual_in = dx
|
||||
return (dx, do, dw, db, dresidual_in) if not recompute_output else (dx, do, dw, db, dresidual_in, y)
|
||||
|
||||
|
||||
class LayerNormSwishGateFn(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
@contiguous
|
||||
def forward(
|
||||
ctx,
|
||||
x,
|
||||
o,
|
||||
weight,
|
||||
bias,
|
||||
residual=None,
|
||||
eps=1e-6,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
is_rms_norm=False,
|
||||
):
|
||||
x_shape_og = x.shape
|
||||
o_shape_og = o.shape
|
||||
# reshape input data into 2D tensor
|
||||
x = x.reshape(-1, x.shape[-1])
|
||||
o = o.reshape(-1, o.shape[-1])
|
||||
if residual is not None:
|
||||
assert residual.shape == x_shape_og
|
||||
residual = residual.reshape(-1, residual.shape[-1])
|
||||
residual_dtype = (
|
||||
residual.dtype
|
||||
if residual is not None
|
||||
else (torch.float32 if residual_in_fp32 else None)
|
||||
)
|
||||
y, mean, rstd, residual_out = _layer_norm_fwd(
|
||||
x, o, weight, bias, eps, residual, residual_dtype=residual_dtype, is_rms_norm=is_rms_norm
|
||||
)
|
||||
ctx.save_for_backward(residual_out, o, weight, bias, mean, rstd)
|
||||
ctx.x_shape_og = x_shape_og
|
||||
ctx.o_shape_og = o_shape_og
|
||||
ctx.eps = eps
|
||||
ctx.is_rms_norm = is_rms_norm
|
||||
ctx.has_residual = residual is not None
|
||||
ctx.prenorm = prenorm
|
||||
ctx.x_dtype = x.dtype
|
||||
y = y.reshape(x_shape_og)
|
||||
return y if not prenorm else (y, residual_out.reshape(x_shape_og))
|
||||
|
||||
@staticmethod
|
||||
@contiguous
|
||||
def backward(ctx, dy, *args):
|
||||
x, o, weight, bias, mean, rstd = ctx.saved_tensors
|
||||
dy = dy.reshape(-1, dy.shape[-1])
|
||||
assert dy.shape == x.shape
|
||||
if ctx.prenorm:
|
||||
dresidual = args[0]
|
||||
dresidual = dresidual.reshape(-1, dresidual.shape[-1])
|
||||
assert dresidual.shape == x.shape
|
||||
else:
|
||||
dresidual = None
|
||||
dx, do, dw, db, dresidual_in = _layer_norm_bwd(
|
||||
dy,
|
||||
x,
|
||||
o,
|
||||
weight,
|
||||
bias,
|
||||
ctx.eps,
|
||||
mean,
|
||||
rstd,
|
||||
dresidual,
|
||||
ctx.has_residual,
|
||||
ctx.is_rms_norm,
|
||||
x_dtype=ctx.x_dtype,
|
||||
)
|
||||
return (
|
||||
dx.reshape(ctx.x_shape_og),
|
||||
do.reshape(ctx.o_shape_og),
|
||||
dw,
|
||||
db,
|
||||
dresidual_in.reshape(ctx.x_shape_og) if ctx.has_residual else None,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
)
|
||||
|
||||
|
||||
class LayerNormSwishGateLinearFn(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
@contiguous
|
||||
def forward(
|
||||
ctx,
|
||||
x,
|
||||
o,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
linear_weight,
|
||||
linear_bias,
|
||||
residual=None,
|
||||
eps=1e-6,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
is_rms_norm=False,
|
||||
):
|
||||
x_shape_og = x.shape
|
||||
o_shape_og = o.shape
|
||||
# reshape input data into 2D tensor
|
||||
x = x.reshape(-1, x.shape[-1])
|
||||
o = o.reshape(-1, o.shape[-1])
|
||||
if residual is not None:
|
||||
assert residual.shape == x_shape_og
|
||||
residual = residual.reshape(-1, residual.shape[-1])
|
||||
residual_dtype = (
|
||||
residual.dtype
|
||||
if residual is not None
|
||||
else (torch.float32 if residual_in_fp32 else None)
|
||||
)
|
||||
y, mean, rstd, residual_out = _layer_norm_fwd(
|
||||
x,
|
||||
o,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
eps,
|
||||
residual,
|
||||
residual_dtype=residual_dtype,
|
||||
is_rms_norm=is_rms_norm
|
||||
)
|
||||
y = y.reshape(x_shape_og)
|
||||
dtype = torch.get_autocast_gpu_dtype() if torch.is_autocast_enabled() else y.dtype
|
||||
linear_weight = linear_weight.to(dtype)
|
||||
linear_bias = linear_bias.to(dtype) if linear_bias is not None else None
|
||||
out = F.linear(y.to(linear_weight.dtype), linear_weight, linear_bias)
|
||||
# We don't store y, will be recomputed in the backward pass to save memory
|
||||
ctx.save_for_backward(residual_out, o, norm_weight, norm_bias, linear_weight, mean, rstd)
|
||||
ctx.x_shape_og = x_shape_og
|
||||
ctx.o_shape_og = o_shape_og
|
||||
ctx.eps = eps
|
||||
ctx.is_rms_norm = is_rms_norm
|
||||
ctx.has_residual = residual is not None
|
||||
ctx.prenorm = prenorm
|
||||
ctx.x_dtype = x.dtype
|
||||
ctx.linear_bias_is_none = linear_bias is None
|
||||
return out if not prenorm else (out, residual_out.reshape(x_shape_og))
|
||||
|
||||
@staticmethod
|
||||
@contiguous
|
||||
def backward(ctx, dout, *args):
|
||||
x, o, norm_weight, norm_bias, linear_weight, mean, rstd = ctx.saved_tensors
|
||||
dout = dout.reshape(-1, dout.shape[-1])
|
||||
dy = F.linear(dout, linear_weight.t())
|
||||
dlinear_bias = None if ctx.linear_bias_is_none else dout.sum(0)
|
||||
assert dy.shape == x.shape
|
||||
if ctx.prenorm:
|
||||
dresidual = args[0]
|
||||
dresidual = dresidual.reshape(-1, dresidual.shape[-1])
|
||||
assert dresidual.shape == x.shape
|
||||
else:
|
||||
dresidual = None
|
||||
dx, do, dnorm_weight, dnorm_bias, dresidual_in, y = _layer_norm_bwd(
|
||||
dy,
|
||||
x,
|
||||
o,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
ctx.eps,
|
||||
mean,
|
||||
rstd,
|
||||
dresidual=dresidual,
|
||||
has_residual=ctx.has_residual,
|
||||
is_rms_norm=ctx.is_rms_norm,
|
||||
x_dtype=ctx.x_dtype,
|
||||
recompute_output=True,
|
||||
)
|
||||
dlinear_weight = torch.einsum("bo,bi->oi", dout, y)
|
||||
return (
|
||||
dx.reshape(ctx.x_shape_og),
|
||||
do.reshape(ctx.o_shape_og),
|
||||
dnorm_weight,
|
||||
dnorm_bias,
|
||||
dlinear_weight,
|
||||
dlinear_bias,
|
||||
dresidual_in.reshape(ctx.x_shape_og) if ctx.has_residual else None,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
)
|
||||
|
||||
|
||||
def layer_norm_swish_gate_fn(
|
||||
x,
|
||||
o,
|
||||
weight,
|
||||
bias,
|
||||
residual=None,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
eps=1e-6
|
||||
):
|
||||
return LayerNormSwishGateFn.apply(
|
||||
x,
|
||||
o,
|
||||
weight,
|
||||
bias,
|
||||
residual,
|
||||
eps,
|
||||
prenorm,
|
||||
residual_in_fp32,
|
||||
False
|
||||
)
|
||||
|
||||
|
||||
def rms_norm_swish_gate_fn(
|
||||
x,
|
||||
o,
|
||||
weight,
|
||||
bias,
|
||||
residual=None,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
eps=1e-6
|
||||
):
|
||||
return LayerNormSwishGateFn.apply(
|
||||
x,
|
||||
o,
|
||||
weight,
|
||||
bias,
|
||||
residual,
|
||||
eps,
|
||||
prenorm,
|
||||
residual_in_fp32,
|
||||
True
|
||||
)
|
||||
|
||||
|
||||
def layer_norm_swish_gate_linear_fn(
|
||||
x,
|
||||
o,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
linear_weight,
|
||||
linear_bias,
|
||||
residual=None,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
eps=1e-6
|
||||
):
|
||||
return LayerNormSwishGateLinearFn.apply(
|
||||
x,
|
||||
o,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
linear_weight,
|
||||
linear_bias,
|
||||
residual,
|
||||
eps,
|
||||
prenorm,
|
||||
residual_in_fp32,
|
||||
False
|
||||
)
|
||||
|
||||
|
||||
def rms_norm_swish_gate_linear_fn(
|
||||
x,
|
||||
o,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
linear_weight,
|
||||
linear_bias,
|
||||
residual=None,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
eps=1e-6
|
||||
):
|
||||
return LayerNormSwishGateLinearFn.apply(
|
||||
x,
|
||||
o,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
linear_weight,
|
||||
linear_bias,
|
||||
residual,
|
||||
eps,
|
||||
prenorm,
|
||||
residual_in_fp32,
|
||||
True
|
||||
)
|
||||
|
||||
|
||||
class FusedLayerNormSwishGate(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size,
|
||||
elementwise_affine: bool = True,
|
||||
eps=1e-5
|
||||
) -> FusedLayerNormSwishGate:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.eps = eps
|
||||
|
||||
if elementwise_affine:
|
||||
self.weight = nn.Parameter(torch.ones(hidden_size))
|
||||
else:
|
||||
self.register_parameter("weight", None)
|
||||
self.register_parameter("bias", None)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}({self.hidden_size}"
|
||||
if not self.elementwise_affine:
|
||||
s += f", elementwise_affine={self.elementwise_affine}"
|
||||
s += f", eps={self.eps}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x, o, residual=None, prenorm=False, residual_in_fp32=False):
|
||||
return layer_norm_swish_gate_fn(
|
||||
x,
|
||||
o,
|
||||
self.weight,
|
||||
self.bias,
|
||||
residual=residual,
|
||||
eps=self.eps,
|
||||
prenorm=prenorm,
|
||||
residual_in_fp32=residual_in_fp32
|
||||
)
|
||||
|
||||
|
||||
class FusedRMSNormSwishGate(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size,
|
||||
elementwise_affine: bool = True,
|
||||
eps=1e-5
|
||||
) -> FusedRMSNormSwishGate:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.eps = eps
|
||||
|
||||
if elementwise_affine:
|
||||
self.weight = nn.Parameter(torch.ones(hidden_size))
|
||||
else:
|
||||
self.register_parameter("weight", None)
|
||||
self.register_parameter("bias", None)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}({self.hidden_size}"
|
||||
if not self.elementwise_affine:
|
||||
s += f", elementwise_affine={self.elementwise_affine}"
|
||||
s += f", eps={self.eps}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x, o, residual=None, prenorm=False, residual_in_fp32=False):
|
||||
return rms_norm_swish_gate_fn(
|
||||
x,
|
||||
o,
|
||||
self.weight,
|
||||
self.bias,
|
||||
residual=residual,
|
||||
eps=self.eps,
|
||||
prenorm=prenorm,
|
||||
residual_in_fp32=residual_in_fp32
|
||||
)
|
||||
|
||||
|
||||
class FusedLayerNormSwishGateLinear(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size,
|
||||
elementwise_affine: bool = True,
|
||||
eps=1e-5
|
||||
) -> FusedLayerNormSwishGateLinear:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.eps = eps
|
||||
|
||||
if elementwise_affine:
|
||||
self.weight = nn.Parameter(torch.ones(hidden_size))
|
||||
else:
|
||||
self.register_parameter("weight", None)
|
||||
self.register_parameter("bias", None)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}({self.hidden_size}"
|
||||
if not self.elementwise_affine:
|
||||
s += f", elementwise_affine={self.elementwise_affine}"
|
||||
s += f", eps={self.eps}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x, o, weight, bias, residual=None, prenorm=False, residual_in_fp32=False):
|
||||
return layer_norm_swish_gate_linear_fn(
|
||||
x,
|
||||
o,
|
||||
self.weight,
|
||||
self.bias,
|
||||
weight,
|
||||
bias,
|
||||
residual=residual,
|
||||
eps=self.eps,
|
||||
prenorm=prenorm,
|
||||
residual_in_fp32=residual_in_fp32
|
||||
)
|
||||
|
||||
|
||||
class FusedRMSNormSwishGateLinear(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size,
|
||||
elementwise_affine: bool = True,
|
||||
eps=1e-5
|
||||
) -> FusedRMSNormSwishGateLinear:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.eps = eps
|
||||
|
||||
if elementwise_affine:
|
||||
self.weight = nn.Parameter(torch.ones(hidden_size))
|
||||
else:
|
||||
self.register_parameter("weight", None)
|
||||
self.register_parameter("bias", None)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}({self.hidden_size}"
|
||||
if not self.elementwise_affine:
|
||||
s += f", elementwise_affine={self.elementwise_affine}"
|
||||
s += f", eps={self.eps}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x, o, weight, bias, residual=None, prenorm=False, residual_in_fp32=False):
|
||||
return rms_norm_swish_gate_linear_fn(
|
||||
x,
|
||||
o,
|
||||
self.weight,
|
||||
self.bias,
|
||||
weight,
|
||||
bias,
|
||||
residual=residual,
|
||||
eps=self.eps,
|
||||
prenorm=prenorm,
|
||||
residual_in_fp32=residual_in_fp32
|
||||
)
|
||||
216
finetune/lora/v6/fla/modules/l2norm.py
vendored
Normal file
216
finetune/lora/v6/fla/modules/l2norm.py
vendored
Normal file
@ -0,0 +1,216 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
import math
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from torch.cuda.amp import custom_fwd, custom_bwd
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
@triton.autotune(
|
||||
configs=[
|
||||
triton.Config({}, num_warps=1),
|
||||
triton.Config({}, num_warps=2),
|
||||
triton.Config({}, num_warps=4),
|
||||
triton.Config({}, num_warps=8),
|
||||
triton.Config({}, num_warps=16),
|
||||
triton.Config({}, num_warps=32),
|
||||
],
|
||||
key=["N"],
|
||||
)
|
||||
# @triton.heuristics({"HAS_BIAS": lambda args: args["B"] is not None})
|
||||
# @triton.heuristics({"HAS_RESIDUAL": lambda args: args["RESIDUAL"] is not None})
|
||||
@triton.jit
|
||||
def _l2_norm_fwd_1pass_kernel(
|
||||
X, # pointer to the input
|
||||
Y, # pointer to the output
|
||||
stride_x_row, # how much to increase the pointer when moving by 1 row
|
||||
N, # number of columns in X
|
||||
eps, # epsilon to avoid division by zero
|
||||
BLOCK_N: tl.constexpr,
|
||||
):
|
||||
# Map the program id to the row of X and Y it should compute.
|
||||
row = tl.program_id(0)
|
||||
X += row * stride_x_row
|
||||
Y += row * stride_x_row
|
||||
# Compute mean and variance
|
||||
cols = tl.arange(0, BLOCK_N)
|
||||
x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
|
||||
xbar = tl.where(cols < N, x, 0.0)
|
||||
var = tl.sum(xbar * xbar, axis=0)
|
||||
rstd = 1 / tl.sqrt(var + eps)
|
||||
# tl.store(Rstd + row, rstd)
|
||||
# Normalize and apply linear transformation
|
||||
mask = cols < N
|
||||
y = x * rstd
|
||||
# Write output
|
||||
tl.store(Y + cols, y, mask=mask)
|
||||
|
||||
|
||||
@triton.autotune(
|
||||
configs=[
|
||||
triton.Config({}, num_warps=1),
|
||||
triton.Config({}, num_warps=2),
|
||||
triton.Config({}, num_warps=4),
|
||||
triton.Config({}, num_warps=8),
|
||||
triton.Config({}, num_warps=16),
|
||||
triton.Config({}, num_warps=32),
|
||||
],
|
||||
key=["N"],
|
||||
)
|
||||
# @triton.heuristics({"HAS_BIAS": lambda args: args["B"] is not None})
|
||||
# @triton.heuristics({"HAS_DRESIDUAL": lambda args: args["DRESIDUAL"] is not None})
|
||||
# @triton.heuristics({"STORE_DRESIDUAL": lambda args: args["DRESIDUAL_IN"] is not None})
|
||||
# @triton.heuristics({"RECOMPUTE_OUTPUT": lambda args: args["Y"] is not None})
|
||||
@triton.jit
|
||||
def _l2_norm_bwd_kernel(
|
||||
X, # pointer to the input
|
||||
# Y, # pointer to the output to be recomputed
|
||||
DY, # pointer to the output gradient
|
||||
DX, # pointer to the input gradient
|
||||
stride_x_row, # how much to increase the pointer when moving by 1 row
|
||||
N, # number of columns in X
|
||||
eps, # epsilon to avoid division by zero
|
||||
BLOCK_N: tl.constexpr,
|
||||
):
|
||||
# Map the program id to the elements of X, DX, and DY it should compute.
|
||||
# Map the program id to the row of X and Y it should compute.
|
||||
row = tl.program_id(0)
|
||||
X += row * stride_x_row
|
||||
DX += row * stride_x_row
|
||||
DY += row * stride_x_row
|
||||
|
||||
# Y += row * stride_y_row
|
||||
cols = tl.arange(0, BLOCK_N)
|
||||
x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
|
||||
x = tl.where(cols < N, x, 0.0)
|
||||
var = tl.sum(x * x)
|
||||
rstd = 1 / tl.sqrt(var + eps)
|
||||
# tl.store(Rstd + row, rstd)
|
||||
# Normalize and apply linear transformation
|
||||
mask = cols < N
|
||||
# y = x * rstd
|
||||
dy = tl.load(DY + cols, mask=cols < N, other=0.0).to(tl.float32)
|
||||
dy = tl.where(cols < N, dy, 0.0)
|
||||
# dx = dy * rstd - tl.sum(dy * x) * (1 / (var+eps)) * rstd * x
|
||||
dx = dy * rstd - tl.sum(dy * x) * (1 / (var+eps)) * rstd * x
|
||||
tl.store(DX + cols, dx, mask=mask)
|
||||
|
||||
def _l2_norm_fwd(
|
||||
x, eps=1e-6
|
||||
):
|
||||
x_shape_og = x.shape
|
||||
x = x.reshape(-1, x.shape[-1])
|
||||
if x.stride(-1) != 1:
|
||||
x = x.contiguous()
|
||||
M, N = x.shape
|
||||
assert x.stride(-1) == 1
|
||||
# allocate output
|
||||
y = torch.empty_like(x)
|
||||
assert y.stride(-1) == 1
|
||||
N = x.shape[-1]
|
||||
M = x.shape[0]
|
||||
# rstd = torch.empty((M,), dtype=torch.float32, device="cuda")
|
||||
# Less than 64KB per feature: enqueue fused kernel
|
||||
MAX_FUSED_SIZE = 65536 // x.element_size()
|
||||
BLOCK_N = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
|
||||
if N > BLOCK_N:
|
||||
raise RuntimeError(
|
||||
"This layer norm doesn't support feature dim >= 64KB.")
|
||||
# heuristics for number of warps
|
||||
with torch.cuda.device(x.device.index):
|
||||
_l2_norm_fwd_1pass_kernel[(M,)](
|
||||
x,
|
||||
y,
|
||||
x.stride(0),
|
||||
N,
|
||||
eps,
|
||||
# is_rms_norm,
|
||||
BLOCK_N,
|
||||
# residual is not None,
|
||||
# residual_out is not None,
|
||||
# bias is not None,
|
||||
)
|
||||
return y.reshape(x_shape_og)
|
||||
|
||||
def _l2_norm_bwd(
|
||||
x, dy, eps=1e-5,
|
||||
):
|
||||
x_shape_og = x.shape
|
||||
x = x.reshape(-1, dy.shape[-1])
|
||||
dy = dy.reshape(-1, dy.shape[-1])
|
||||
if dy.stride(-1) != 1:
|
||||
dy = dy.contiguous()
|
||||
assert dy.shape == x.shape
|
||||
# allocate output
|
||||
dx = torch.empty_like(x)
|
||||
N = x.shape[-1]
|
||||
M = x.shape[0]
|
||||
assert x.stride(-1) == 1
|
||||
assert dy.stride(-1) == 1
|
||||
# rstd = torch.empty((M,), dtype=torch.float32, device="cuda")
|
||||
# Less than 64KB per feature: enqueue fused kernel
|
||||
MAX_FUSED_SIZE = 65536 // x.element_size()
|
||||
BLOCK_N = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
|
||||
if N > BLOCK_N:
|
||||
raise RuntimeError(
|
||||
"This layer norm doesn't support feature dim >= 64KB.")
|
||||
# heuristics for number of warps
|
||||
with torch.cuda.device(x.device.index):
|
||||
_l2_norm_bwd_kernel[(M,)](
|
||||
x,
|
||||
dy,
|
||||
dx,
|
||||
x.stride(0),
|
||||
N,
|
||||
eps,
|
||||
BLOCK_N,
|
||||
)
|
||||
return dx.reshape(x_shape_og)
|
||||
|
||||
|
||||
class L2NormFN(torch.autograd.Function):
|
||||
@staticmethod
|
||||
def forward(
|
||||
ctx,
|
||||
x,
|
||||
eps=1e-6,
|
||||
):
|
||||
# reshape input data into 2D tensor
|
||||
y = _l2_norm_fwd(x, eps)
|
||||
ctx.x_shape_og = x_shape_og
|
||||
ctx.eps = eps
|
||||
ctx.x_dtype = x.dtype
|
||||
ctx.save_for_backward(x)
|
||||
return y
|
||||
|
||||
@staticmethod
|
||||
def backward(ctx, dy, *args):
|
||||
x, = ctx.saved_tensors
|
||||
dx = _l2_norm_bwd(
|
||||
x,
|
||||
dy,
|
||||
ctx.eps,
|
||||
)
|
||||
return (
|
||||
dx,
|
||||
None
|
||||
)
|
||||
|
||||
l2_norm_fn = L2NormFN.apply
|
||||
|
||||
if __name__ == '__main__':
|
||||
x = torch.rand(10, 10, 100).cuda().requires_grad_(True)
|
||||
y = torch.nn.functional.normalize(x, dim=-1, p=2)
|
||||
dy = torch.rand_like(y)
|
||||
y.backward(dy, retain_graph=True)
|
||||
x_grad, x.grad = x.grad, None
|
||||
y2 = l2_norm_fn(x, 1e-6)
|
||||
print((y-y2).abs().max())
|
||||
y2.backward(dy, retain_graph=True)
|
||||
x_grad2, x.grad = x.grad, None
|
||||
print((x_grad2-x_grad).abs().max())
|
||||
breakpoint()
|
||||
|
||||
|
||||
|
||||
|
||||
802
finetune/lora/v6/fla/modules/layernorm.py
vendored
Normal file
802
finetune/lora/v6/fla/modules/layernorm.py
vendored
Normal file
@ -0,0 +1,802 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Copyright (c) 2023, Tri Dao.
|
||||
# https://github.com/state-spaces/mamba/blob/fb7b5310fa865dbd62aa059b1e26f2b431363e2a/mamba_ssm/ops/triton/layernorm.py
|
||||
# Implement residual + layer_norm / rms_norm.
|
||||
|
||||
# Based on the Triton LayerNorm tutorial: https://triton-lang.org/main/getting-started/tutorials/05-layer-norm.html
|
||||
# For the backward pass, we keep weight_grad and bias_grad in registers and accumulate.
|
||||
# This is faster for dimensions up to 8k, but after that it's much slower due to register spilling.
|
||||
# The models we train have hidden dim up to 8k anyway (e.g. Llama 70B), so this is fine.
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from fla.utils import contiguous
|
||||
|
||||
|
||||
def layer_norm_ref(x, weight, bias, residual=None, eps=1e-6, prenorm=False, upcast=False):
|
||||
dtype = x.dtype
|
||||
if upcast:
|
||||
weight = weight.float()
|
||||
bias = bias.float() if bias is not None else None
|
||||
if upcast:
|
||||
x = x.float()
|
||||
residual = residual.float() if residual is not None else residual
|
||||
if residual is not None:
|
||||
x = (x + residual).to(x.dtype)
|
||||
out = F.layer_norm(x.to(weight.dtype), x.shape[-1:], weight=weight, bias=bias, eps=eps).to(
|
||||
dtype
|
||||
)
|
||||
return out if not prenorm else (out, x)
|
||||
|
||||
|
||||
def rms_norm_ref(x, weight, bias, residual=None, eps=1e-6, prenorm=False, upcast=False):
|
||||
dtype = x.dtype
|
||||
if upcast:
|
||||
weight = weight.float()
|
||||
bias = bias.float() if bias is not None else None
|
||||
if upcast:
|
||||
x = x.float()
|
||||
residual = residual.float() if residual is not None else residual
|
||||
if residual is not None:
|
||||
x = (x + residual).to(x.dtype)
|
||||
rstd = 1 / torch.sqrt((x.square()).mean(dim=-1, keepdim=True) + eps)
|
||||
out = (x * rstd * weight) + \
|
||||
bias if bias is not None else (x * rstd * weight)
|
||||
out = out.to(dtype)
|
||||
return out if not prenorm else (out, x)
|
||||
|
||||
|
||||
@triton.autotune(
|
||||
configs=[
|
||||
triton.Config({}, num_warps=1),
|
||||
triton.Config({}, num_warps=2),
|
||||
triton.Config({}, num_warps=4),
|
||||
triton.Config({}, num_warps=8),
|
||||
triton.Config({}, num_warps=16),
|
||||
triton.Config({}, num_warps=32),
|
||||
],
|
||||
key=["N", "HAS_RESIDUAL", "STORE_RESIDUAL_OUT", "IS_RMS_NORM", "HAS_BIAS"],
|
||||
)
|
||||
# @triton.heuristics({"HAS_BIAS": lambda args: args["B"] is not None})
|
||||
# @triton.heuristics({"HAS_RESIDUAL": lambda args: args["RESIDUAL"] is not None})
|
||||
@triton.jit
|
||||
def _layer_norm_fwd_1pass_kernel(
|
||||
X, # pointer to the input
|
||||
Y, # pointer to the output
|
||||
W, # pointer to the weights
|
||||
B, # pointer to the biases
|
||||
RESIDUAL, # pointer to the residual
|
||||
RESIDUAL_OUT, # pointer to the residual
|
||||
Mean, # pointer to the mean
|
||||
Rstd, # pointer to the 1/std
|
||||
stride_x_row, # how much to increase the pointer when moving by 1 row
|
||||
stride_y_row,
|
||||
stride_res_row,
|
||||
stride_res_out_row,
|
||||
N, # number of columns in X
|
||||
eps, # epsilon to avoid division by zero
|
||||
IS_RMS_NORM: tl.constexpr,
|
||||
BLOCK_N: tl.constexpr,
|
||||
HAS_RESIDUAL: tl.constexpr,
|
||||
STORE_RESIDUAL_OUT: tl.constexpr,
|
||||
HAS_WEIGHT: tl.constexpr,
|
||||
HAS_BIAS: tl.constexpr
|
||||
):
|
||||
# Map the program id to the row of X and Y it should compute.
|
||||
row = tl.program_id(0)
|
||||
X += row * stride_x_row
|
||||
Y += row * stride_y_row
|
||||
if HAS_RESIDUAL:
|
||||
RESIDUAL += row * stride_res_row
|
||||
if STORE_RESIDUAL_OUT:
|
||||
RESIDUAL_OUT += row * stride_res_out_row
|
||||
# Compute mean and variance
|
||||
cols = tl.arange(0, BLOCK_N)
|
||||
x = tl.load(X + cols, mask=cols < N, other=0.0).to(tl.float32)
|
||||
if HAS_RESIDUAL:
|
||||
residual = tl.load(RESIDUAL + cols, mask=cols <
|
||||
N, other=0.0).to(tl.float32)
|
||||
x += residual
|
||||
if STORE_RESIDUAL_OUT:
|
||||
tl.store(RESIDUAL_OUT + cols, x, mask=cols < N)
|
||||
if not IS_RMS_NORM:
|
||||
mean = tl.sum(x, axis=0) / N
|
||||
tl.store(Mean + row, mean)
|
||||
xbar = tl.where(cols < N, x - mean, 0.0)
|
||||
var = tl.sum(xbar * xbar, axis=0) / N
|
||||
else:
|
||||
xbar = tl.where(cols < N, x, 0.0)
|
||||
var = tl.sum(xbar * xbar, axis=0) / N
|
||||
rstd = 1 / tl.sqrt(var + eps)
|
||||
tl.store(Rstd + row, rstd)
|
||||
# Normalize and apply linear transformation
|
||||
mask = cols < N
|
||||
if HAS_WEIGHT:
|
||||
w = tl.load(W + cols, mask=mask).to(tl.float32)
|
||||
if HAS_BIAS:
|
||||
b = tl.load(B + cols, mask=mask).to(tl.float32)
|
||||
x_hat = (x - mean) * rstd if not IS_RMS_NORM else x * rstd
|
||||
|
||||
y = x_hat * w if HAS_WEIGHT else x_hat
|
||||
if HAS_BIAS:
|
||||
y = y + b
|
||||
# Write output
|
||||
tl.store(Y + cols, y, mask=mask)
|
||||
|
||||
|
||||
def _layer_norm_fwd(
|
||||
x, weight, bias, eps, residual=None, out_dtype=None, residual_dtype=None, is_rms_norm=False
|
||||
):
|
||||
if residual is not None:
|
||||
residual_dtype = residual.dtype
|
||||
M, N = x.shape
|
||||
assert x.stride(-1) == 1
|
||||
if residual is not None:
|
||||
assert residual.stride(-1) == 1
|
||||
assert residual.shape == (M, N)
|
||||
if weight is not None:
|
||||
assert weight.shape == (N,)
|
||||
assert weight.stride(-1) == 1
|
||||
if bias is not None:
|
||||
assert bias.stride(-1) == 1
|
||||
assert bias.shape == (N,)
|
||||
# allocate output
|
||||
y = torch.empty_like(x, dtype=x.dtype if out_dtype is None else out_dtype)
|
||||
assert y.stride(-1) == 1
|
||||
if residual is not None or (residual_dtype is not None and residual_dtype != x.dtype):
|
||||
residual_out = torch.empty(M, N, device=x.device, dtype=residual_dtype)
|
||||
assert residual_out.stride(-1) == 1
|
||||
else:
|
||||
residual_out = None
|
||||
mean = torch.empty((M,), dtype=torch.float32,
|
||||
device="cuda") if not is_rms_norm else None
|
||||
rstd = torch.empty((M,), dtype=torch.float32, device="cuda")
|
||||
# Less than 64KB per feature: enqueue fused kernel
|
||||
MAX_FUSED_SIZE = 65536 // x.element_size()
|
||||
BLOCK_N = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
|
||||
if N > BLOCK_N:
|
||||
raise RuntimeError(
|
||||
"This layer norm doesn't support feature dim >= 64KB.")
|
||||
# heuristics for number of warps
|
||||
with torch.cuda.device(x.device.index):
|
||||
_layer_norm_fwd_1pass_kernel[(M,)](
|
||||
x,
|
||||
y,
|
||||
weight,
|
||||
bias,
|
||||
residual,
|
||||
residual_out,
|
||||
mean,
|
||||
rstd,
|
||||
x.stride(0),
|
||||
y.stride(0),
|
||||
residual.stride(0) if residual is not None else 0,
|
||||
residual_out.stride(0) if residual_out is not None else 0,
|
||||
N,
|
||||
eps,
|
||||
is_rms_norm,
|
||||
BLOCK_N,
|
||||
residual is not None,
|
||||
residual_out is not None,
|
||||
weight is not None,
|
||||
bias is not None,
|
||||
)
|
||||
# residual_out is None if residual is None and residual_dtype == input_dtype
|
||||
return y, mean, rstd, residual_out if residual_out is not None else x
|
||||
|
||||
|
||||
@triton.autotune(
|
||||
configs=[
|
||||
triton.Config({}, num_warps=1),
|
||||
triton.Config({}, num_warps=2),
|
||||
triton.Config({}, num_warps=4),
|
||||
triton.Config({}, num_warps=8),
|
||||
triton.Config({}, num_warps=16),
|
||||
triton.Config({}, num_warps=32),
|
||||
],
|
||||
key=["N", "HAS_DRESIDUAL", "STORE_DRESIDUAL", "IS_RMS_NORM", "HAS_BIAS"],
|
||||
)
|
||||
# @triton.heuristics({"HAS_BIAS": lambda args: args["B"] is not None})
|
||||
# @triton.heuristics({"HAS_DRESIDUAL": lambda args: args["DRESIDUAL"] is not None})
|
||||
# @triton.heuristics({"STORE_DRESIDUAL": lambda args: args["DRESIDUAL_IN"] is not None})
|
||||
@triton.heuristics({"RECOMPUTE_OUTPUT": lambda args: args["Y"] is not None})
|
||||
@triton.jit
|
||||
def _layer_norm_bwd_kernel(
|
||||
X, # pointer to the input
|
||||
W, # pointer to the weights
|
||||
B, # pointer to the biases
|
||||
Y, # pointer to the output to be recomputed
|
||||
DY, # pointer to the output gradient
|
||||
DX, # pointer to the input gradient
|
||||
DW, # pointer to the partial sum of weights gradient
|
||||
DB, # pointer to the partial sum of biases gradient
|
||||
DRESIDUAL,
|
||||
DRESIDUAL_IN,
|
||||
Mean, # pointer to the mean
|
||||
Rstd, # pointer to the 1/std
|
||||
stride_x_row, # how much to increase the pointer when moving by 1 row
|
||||
stride_y_row,
|
||||
stride_dy_row,
|
||||
stride_dx_row,
|
||||
stride_dres_row,
|
||||
stride_dres_in_row,
|
||||
M, # number of rows in X
|
||||
N, # number of columns in X
|
||||
eps, # epsilon to avoid division by zero
|
||||
rows_per_program,
|
||||
IS_RMS_NORM: tl.constexpr,
|
||||
BLOCK_N: tl.constexpr,
|
||||
HAS_DRESIDUAL: tl.constexpr,
|
||||
STORE_DRESIDUAL: tl.constexpr,
|
||||
HAS_WEIGHT: tl.constexpr,
|
||||
HAS_BIAS: tl.constexpr,
|
||||
RECOMPUTE_OUTPUT: tl.constexpr,
|
||||
):
|
||||
# Map the program id to the elements of X, DX, and DY it should compute.
|
||||
row_block_id = tl.program_id(0)
|
||||
row_start = row_block_id * rows_per_program
|
||||
cols = tl.arange(0, BLOCK_N)
|
||||
mask = cols < N
|
||||
X += row_start * stride_x_row
|
||||
if HAS_DRESIDUAL:
|
||||
DRESIDUAL += row_start * stride_dres_row
|
||||
if STORE_DRESIDUAL:
|
||||
DRESIDUAL_IN += row_start * stride_dres_in_row
|
||||
DY += row_start * stride_dy_row
|
||||
DX += row_start * stride_dx_row
|
||||
if RECOMPUTE_OUTPUT:
|
||||
Y += row_start * stride_y_row
|
||||
if HAS_WEIGHT:
|
||||
w = tl.load(W + cols, mask=mask).to(tl.float32)
|
||||
dw = tl.zeros((BLOCK_N,), dtype=tl.float32)
|
||||
if RECOMPUTE_OUTPUT and HAS_BIAS:
|
||||
b = tl.load(B + cols, mask=mask, other=0.0).to(tl.float32)
|
||||
if HAS_BIAS:
|
||||
db = tl.zeros((BLOCK_N,), dtype=tl.float32)
|
||||
row_end = min((row_block_id + 1) * rows_per_program, M)
|
||||
for row in range(row_start, row_end):
|
||||
# Load data to SRAM
|
||||
x = tl.load(X + cols, mask=mask, other=0).to(tl.float32)
|
||||
dy = tl.load(DY + cols, mask=mask, other=0).to(tl.float32)
|
||||
if not IS_RMS_NORM:
|
||||
mean = tl.load(Mean + row)
|
||||
rstd = tl.load(Rstd + row)
|
||||
# Compute dx
|
||||
xhat = (x - mean) * rstd if not IS_RMS_NORM else x * rstd
|
||||
xhat = tl.where(mask, xhat, 0.0)
|
||||
if RECOMPUTE_OUTPUT:
|
||||
y = xhat * w if HAS_WEIGHT else xhat
|
||||
if HAS_BIAS:
|
||||
y = y + b
|
||||
tl.store(Y + cols, y, mask=mask)
|
||||
wdy = dy
|
||||
if HAS_WEIGHT:
|
||||
wdy = dy * w
|
||||
dw += dy * xhat
|
||||
if HAS_BIAS:
|
||||
db += dy
|
||||
if not IS_RMS_NORM:
|
||||
c1 = tl.sum(xhat * wdy, axis=0) / N
|
||||
c2 = tl.sum(wdy, axis=0) / N
|
||||
dx = (wdy - (xhat * c1 + c2)) * rstd
|
||||
else:
|
||||
c1 = tl.sum(xhat * wdy, axis=0) / N
|
||||
dx = (wdy - xhat * c1) * rstd
|
||||
if HAS_DRESIDUAL:
|
||||
dres = tl.load(DRESIDUAL + cols, mask=mask, other=0).to(tl.float32)
|
||||
dx += dres
|
||||
# Write dx
|
||||
if STORE_DRESIDUAL:
|
||||
tl.store(DRESIDUAL_IN + cols, dx, mask=mask)
|
||||
tl.store(DX + cols, dx, mask=mask)
|
||||
|
||||
X += stride_x_row
|
||||
if HAS_DRESIDUAL:
|
||||
DRESIDUAL += stride_dres_row
|
||||
if STORE_DRESIDUAL:
|
||||
DRESIDUAL_IN += stride_dres_in_row
|
||||
if RECOMPUTE_OUTPUT:
|
||||
Y += stride_y_row
|
||||
DY += stride_dy_row
|
||||
DX += stride_dx_row
|
||||
if HAS_WEIGHT:
|
||||
tl.store(DW + row_block_id * N + cols, dw, mask=mask)
|
||||
if HAS_BIAS:
|
||||
tl.store(DB + row_block_id * N + cols, db, mask=mask)
|
||||
|
||||
|
||||
def _layer_norm_bwd(
|
||||
dy,
|
||||
x,
|
||||
weight,
|
||||
bias,
|
||||
eps,
|
||||
mean,
|
||||
rstd,
|
||||
dresidual=None,
|
||||
has_residual=False,
|
||||
is_rms_norm=False,
|
||||
x_dtype=None,
|
||||
recompute_output=False,
|
||||
):
|
||||
M, N = x.shape
|
||||
assert x.stride(-1) == 1
|
||||
assert dy.stride(-1) == 1
|
||||
assert dy.shape == (M, N)
|
||||
if dresidual is not None:
|
||||
assert dresidual.stride(-1) == 1
|
||||
assert dresidual.shape == (M, N)
|
||||
if weight is not None:
|
||||
assert weight.shape == (N,)
|
||||
assert weight.stride(-1) == 1
|
||||
if bias is not None:
|
||||
assert bias.stride(-1) == 1
|
||||
assert bias.shape == (N,)
|
||||
# allocate output
|
||||
dx = (
|
||||
torch.empty_like(x)
|
||||
if x_dtype is None
|
||||
else torch.empty(M, N, dtype=x_dtype, device=x.device)
|
||||
)
|
||||
dresidual_in = torch.empty_like(
|
||||
x) if has_residual and dx.dtype != x.dtype else None
|
||||
y = torch.empty(M, N, dtype=dy.dtype,
|
||||
device=dy.device) if recompute_output else None
|
||||
|
||||
# Less than 64KB per feature: enqueue fused kernel
|
||||
MAX_FUSED_SIZE = 65536 // x.element_size()
|
||||
BLOCK_N = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
|
||||
if N > BLOCK_N:
|
||||
raise RuntimeError(
|
||||
"This layer norm doesn't support feature dim >= 64KB.")
|
||||
sm_count = torch.cuda.get_device_properties(x.device).multi_processor_count
|
||||
_dw = (
|
||||
torch.empty((sm_count, N), dtype=torch.float32, device=weight.device)
|
||||
if weight is not None
|
||||
else None
|
||||
)
|
||||
_db = (
|
||||
torch.empty((sm_count, N), dtype=torch.float32, device=bias.device)
|
||||
if bias is not None
|
||||
else None
|
||||
)
|
||||
rows_per_program = math.ceil(M / sm_count)
|
||||
grid = (sm_count,)
|
||||
with torch.cuda.device(x.device.index):
|
||||
_layer_norm_bwd_kernel[grid](
|
||||
x,
|
||||
weight,
|
||||
bias,
|
||||
y,
|
||||
dy,
|
||||
dx,
|
||||
_dw,
|
||||
_db,
|
||||
dresidual,
|
||||
dresidual_in,
|
||||
mean,
|
||||
rstd,
|
||||
x.stride(0),
|
||||
0 if not recompute_output else y.stride(0),
|
||||
dy.stride(0),
|
||||
dx.stride(0),
|
||||
dresidual.stride(0) if dresidual is not None else 0,
|
||||
dresidual_in.stride(0) if dresidual_in is not None else 0,
|
||||
M,
|
||||
N,
|
||||
eps,
|
||||
rows_per_program,
|
||||
is_rms_norm,
|
||||
BLOCK_N,
|
||||
dresidual is not None,
|
||||
dresidual_in is not None,
|
||||
weight is not None,
|
||||
bias is not None,
|
||||
)
|
||||
dw = _dw.sum(0).to(weight.dtype) if weight is not None else None
|
||||
db = _db.sum(0).to(bias.dtype) if bias is not None else None
|
||||
# Don't need to compute dresidual_in separately in this case
|
||||
if has_residual and dx.dtype == x.dtype:
|
||||
dresidual_in = dx
|
||||
return (dx, dw, db, dresidual_in) if not recompute_output else (dx, dw, db, dresidual_in, y)
|
||||
|
||||
|
||||
class LayerNormFn(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
@contiguous
|
||||
def forward(
|
||||
ctx,
|
||||
x,
|
||||
weight,
|
||||
bias,
|
||||
residual=None,
|
||||
eps=1e-6,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
is_rms_norm=False,
|
||||
):
|
||||
x_shape_og = x.shape
|
||||
# reshape input data into 2D tensor
|
||||
x = x.reshape(-1, x.shape[-1])
|
||||
if residual is not None:
|
||||
assert residual.shape == x_shape_og
|
||||
residual = residual.reshape(-1, residual.shape[-1])
|
||||
residual_dtype = (
|
||||
residual.dtype
|
||||
if residual is not None
|
||||
else (torch.float32 if residual_in_fp32 else None)
|
||||
)
|
||||
y, mean, rstd, residual_out = _layer_norm_fwd(
|
||||
x, weight, bias, eps, residual, residual_dtype=residual_dtype, is_rms_norm=is_rms_norm
|
||||
)
|
||||
ctx.save_for_backward(residual_out, weight, bias, mean, rstd)
|
||||
ctx.x_shape_og = x_shape_og
|
||||
ctx.eps = eps
|
||||
ctx.is_rms_norm = is_rms_norm
|
||||
ctx.has_residual = residual is not None
|
||||
ctx.prenorm = prenorm
|
||||
ctx.x_dtype = x.dtype
|
||||
y = y.reshape(x_shape_og)
|
||||
return y if not prenorm else (y, residual_out.reshape(x_shape_og))
|
||||
|
||||
@staticmethod
|
||||
@contiguous
|
||||
def backward(ctx, dy, *args):
|
||||
x, weight, bias, mean, rstd = ctx.saved_tensors
|
||||
dy = dy.reshape(-1, dy.shape[-1])
|
||||
assert dy.shape == x.shape
|
||||
if ctx.prenorm:
|
||||
dresidual = args[0]
|
||||
dresidual = dresidual.reshape(-1, dresidual.shape[-1])
|
||||
assert dresidual.shape == x.shape
|
||||
else:
|
||||
dresidual = None
|
||||
dx, dw, db, dresidual_in = _layer_norm_bwd(
|
||||
dy,
|
||||
x,
|
||||
weight,
|
||||
bias,
|
||||
ctx.eps,
|
||||
mean,
|
||||
rstd,
|
||||
dresidual,
|
||||
ctx.has_residual,
|
||||
ctx.is_rms_norm,
|
||||
x_dtype=ctx.x_dtype,
|
||||
)
|
||||
return (
|
||||
dx.reshape(ctx.x_shape_og),
|
||||
dw,
|
||||
db,
|
||||
dresidual_in.reshape(ctx.x_shape_og) if ctx.has_residual else None,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
)
|
||||
|
||||
|
||||
def layer_norm_fn(
|
||||
x,
|
||||
weight,
|
||||
bias,
|
||||
residual=None,
|
||||
eps=1e-6,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
is_rms_norm=False,
|
||||
):
|
||||
return LayerNormFn.apply(x, weight, bias, residual, eps, prenorm, residual_in_fp32, is_rms_norm)
|
||||
|
||||
|
||||
def rms_norm_fn(
|
||||
x,
|
||||
weight,
|
||||
bias,
|
||||
residual=None,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
eps=1e-6
|
||||
):
|
||||
return LayerNormFn.apply(x, weight, bias, residual, eps, prenorm, residual_in_fp32, True)
|
||||
|
||||
|
||||
class LayerNorm(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
elementwise_affine: bool = True,
|
||||
eps: float = 1e-5
|
||||
) -> LayerNorm:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.eps = eps
|
||||
|
||||
if elementwise_affine:
|
||||
self.weight = nn.Parameter(torch.ones(hidden_size))
|
||||
else:
|
||||
self.register_parameter("weight", None)
|
||||
self.register_parameter("bias", None)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}({self.hidden_size}"
|
||||
if not self.elementwise_affine:
|
||||
s += f", elementwise_affine={self.elementwise_affine}"
|
||||
s += f", eps={self.eps}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x, residual=None, prenorm=False, residual_in_fp32=False):
|
||||
return layer_norm_fn(
|
||||
x,
|
||||
self.weight,
|
||||
self.bias,
|
||||
residual=residual,
|
||||
eps=self.eps,
|
||||
prenorm=prenorm,
|
||||
residual_in_fp32=residual_in_fp32
|
||||
)
|
||||
|
||||
|
||||
class RMSNorm(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
elementwise_affine: bool = True,
|
||||
eps: float = 1e-5
|
||||
) -> RMSNorm:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.eps = eps
|
||||
|
||||
if elementwise_affine:
|
||||
self.weight = nn.Parameter(torch.ones(hidden_size))
|
||||
else:
|
||||
self.register_parameter("weight", None)
|
||||
self.register_parameter("bias", None)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}({self.hidden_size}"
|
||||
if not self.elementwise_affine:
|
||||
s += f", elementwise_affine={self.elementwise_affine}"
|
||||
s += f", eps={self.eps}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x, residual=None, prenorm=False, residual_in_fp32=False):
|
||||
return rms_norm_fn(
|
||||
x,
|
||||
self.weight,
|
||||
self.bias,
|
||||
residual=residual,
|
||||
eps=self.eps,
|
||||
prenorm=prenorm,
|
||||
residual_in_fp32=residual_in_fp32,
|
||||
)
|
||||
|
||||
|
||||
class LayerNormLinearFn(torch.autograd.Function):
|
||||
|
||||
@staticmethod
|
||||
@contiguous
|
||||
def forward(
|
||||
ctx,
|
||||
x,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
linear_weight,
|
||||
linear_bias,
|
||||
residual=None,
|
||||
eps=1e-6,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
is_rms_norm=False,
|
||||
):
|
||||
x_shape_og = x.shape
|
||||
# reshape input data into 2D tensor
|
||||
x = x.reshape(-1, x.shape[-1])
|
||||
if residual is not None:
|
||||
assert residual.shape == x_shape_og
|
||||
residual = residual.reshape(-1, residual.shape[-1])
|
||||
residual_dtype = (
|
||||
residual.dtype
|
||||
if residual is not None
|
||||
else (torch.float32 if residual_in_fp32 else None)
|
||||
)
|
||||
y, mean, rstd, residual_out = _layer_norm_fwd(
|
||||
x,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
eps,
|
||||
residual,
|
||||
out_dtype=None if not torch.is_autocast_enabled() else torch.get_autocast_gpu_dtype(),
|
||||
residual_dtype=residual_dtype,
|
||||
is_rms_norm=is_rms_norm,
|
||||
)
|
||||
y = y.reshape(x_shape_og)
|
||||
dtype = torch.get_autocast_gpu_dtype() if torch.is_autocast_enabled() else y.dtype
|
||||
linear_weight = linear_weight.to(dtype)
|
||||
linear_bias = linear_bias.to(
|
||||
dtype) if linear_bias is not None else None
|
||||
out = F.linear(y.to(linear_weight.dtype), linear_weight, linear_bias)
|
||||
# We don't store y, will be recomputed in the backward pass to save memory
|
||||
ctx.save_for_backward(residual_out, norm_weight,
|
||||
norm_bias, linear_weight, mean, rstd)
|
||||
ctx.x_shape_og = x_shape_og
|
||||
ctx.eps = eps
|
||||
ctx.is_rms_norm = is_rms_norm
|
||||
ctx.has_residual = residual is not None
|
||||
ctx.prenorm = prenorm
|
||||
ctx.x_dtype = x.dtype
|
||||
ctx.linear_bias_is_none = linear_bias is None
|
||||
return out if not prenorm else (out, residual_out.reshape(x_shape_og))
|
||||
|
||||
@staticmethod
|
||||
@contiguous
|
||||
def backward(ctx, dout, *args):
|
||||
x, norm_weight, norm_bias, linear_weight, mean, rstd = ctx.saved_tensors
|
||||
dout = dout.reshape(-1, dout.shape[-1])
|
||||
dy = F.linear(dout, linear_weight.t())
|
||||
dlinear_bias = None if ctx.linear_bias_is_none else dout.sum(0)
|
||||
assert dy.shape == x.shape
|
||||
if ctx.prenorm:
|
||||
dresidual = args[0]
|
||||
dresidual = dresidual.reshape(-1, dresidual.shape[-1])
|
||||
assert dresidual.shape == x.shape
|
||||
else:
|
||||
dresidual = None
|
||||
dx, dnorm_weight, dnorm_bias, dresidual_in, y = _layer_norm_bwd(
|
||||
dy,
|
||||
x,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
ctx.eps,
|
||||
mean,
|
||||
rstd,
|
||||
dresidual,
|
||||
ctx.has_residual,
|
||||
ctx.is_rms_norm,
|
||||
x_dtype=ctx.x_dtype,
|
||||
recompute_output=True,
|
||||
)
|
||||
dlinear_weight = torch.einsum("bo,bi->oi", dout, y)
|
||||
return (
|
||||
dx.reshape(ctx.x_shape_og),
|
||||
dnorm_weight,
|
||||
dnorm_bias,
|
||||
dlinear_weight,
|
||||
dlinear_bias,
|
||||
dresidual_in.reshape(ctx.x_shape_og) if ctx.has_residual else None,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
None,
|
||||
)
|
||||
|
||||
|
||||
def layer_norm_linear_fn(
|
||||
x,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
linear_weight,
|
||||
linear_bias,
|
||||
residual=None,
|
||||
eps=1e-6,
|
||||
prenorm=False,
|
||||
residual_in_fp32=False,
|
||||
is_rms_norm=False,
|
||||
):
|
||||
return LayerNormLinearFn.apply(
|
||||
x,
|
||||
norm_weight,
|
||||
norm_bias,
|
||||
linear_weight,
|
||||
linear_bias,
|
||||
residual,
|
||||
eps,
|
||||
prenorm,
|
||||
residual_in_fp32,
|
||||
is_rms_norm,
|
||||
)
|
||||
|
||||
|
||||
class LayerNormLinear(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size,
|
||||
elementwise_affine: bool = True,
|
||||
eps=1e-5
|
||||
) -> LayerNormLinear:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.eps = eps
|
||||
|
||||
if elementwise_affine:
|
||||
self.weight = nn.Parameter(torch.ones(hidden_size))
|
||||
else:
|
||||
self.register_parameter("weight", None)
|
||||
self.register_parameter("bias", None)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}({self.hidden_size}"
|
||||
if not self.elementwise_affine:
|
||||
s += f", elementwise_affine={self.elementwise_affine}"
|
||||
s += f", eps={self.eps}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x, weight, bias, residual=None, prenorm=False, residual_in_fp32=False):
|
||||
return layer_norm_linear_fn(
|
||||
x,
|
||||
self.weight,
|
||||
self.bias,
|
||||
weight,
|
||||
bias,
|
||||
residual=residual,
|
||||
eps=self.eps,
|
||||
prenorm=prenorm,
|
||||
residual_in_fp32=residual_in_fp32,
|
||||
is_rms_norm=False
|
||||
)
|
||||
|
||||
|
||||
class RMSNormLinear(nn.Module):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size,
|
||||
elementwise_affine: bool = True,
|
||||
eps=1e-5
|
||||
) -> RMSNormLinear:
|
||||
super().__init__()
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.elementwise_affine = elementwise_affine
|
||||
self.eps = eps
|
||||
|
||||
if elementwise_affine:
|
||||
self.weight = nn.Parameter(torch.ones(hidden_size))
|
||||
else:
|
||||
self.register_parameter("weight", None)
|
||||
self.register_parameter("bias", None)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
s = f"{self.__class__.__name__}({self.hidden_size}"
|
||||
if not self.elementwise_affine:
|
||||
s += f", elementwise_affine={self.elementwise_affine}"
|
||||
s += f", eps={self.eps}"
|
||||
s += ")"
|
||||
return s
|
||||
|
||||
def forward(self, x, weight, bias, residual=None, prenorm=False, residual_in_fp32=False):
|
||||
return layer_norm_linear_fn(
|
||||
x,
|
||||
self.weight,
|
||||
self.bias,
|
||||
weight,
|
||||
bias,
|
||||
residual=residual,
|
||||
eps=self.eps,
|
||||
prenorm=prenorm,
|
||||
residual_in_fp32=residual_in_fp32,
|
||||
is_rms_norm=True
|
||||
)
|
||||
310
finetune/lora/v6/fla/modules/rotary.py
vendored
Normal file
310
finetune/lora/v6/fla/modules/rotary.py
vendored
Normal file
@ -0,0 +1,310 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Copyright (c) 2023, Tri Dao.
|
||||
|
||||
from typing import Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from einops import rearrange, repeat
|
||||
|
||||
from fla.ops.rotary import apply_rotary
|
||||
|
||||
|
||||
def rotate_half(x, interleaved=False):
|
||||
if not interleaved:
|
||||
x1, x2 = x.chunk(2, dim=-1)
|
||||
return torch.cat((-x2, x1), dim=-1)
|
||||
else:
|
||||
x1, x2 = x[..., ::2], x[..., 1::2]
|
||||
return rearrange(torch.stack((-x2, x1), dim=-1), "... d two -> ... (d two)", two=2)
|
||||
|
||||
|
||||
def apply_rotary_emb_torch(x, cos, sin, interleaved=False):
|
||||
"""
|
||||
x: (batch_size, seqlen, nheads, headdim)
|
||||
cos, sin: (seqlen, rotary_dim / 2) or (batch_size, seqlen, rotary_dim / 2)
|
||||
"""
|
||||
ro_dim = cos.shape[-1] * 2
|
||||
assert ro_dim <= x.shape[-1]
|
||||
cos = repeat(
|
||||
cos, "... d -> ... 1 (2 d)" if not interleaved else "... d -> ... 1 (d 2)")
|
||||
sin = repeat(
|
||||
sin, "... d -> ... 1 (2 d)" if not interleaved else "... d -> ... 1 (d 2)")
|
||||
return torch.cat(
|
||||
[x[..., :ro_dim] * cos +
|
||||
rotate_half(x[..., :ro_dim], interleaved) * sin, x[..., ro_dim:]],
|
||||
dim=-1,
|
||||
)
|
||||
|
||||
|
||||
class ApplyRotaryEmb(torch.autograd.Function):
|
||||
@staticmethod
|
||||
def forward(
|
||||
ctx,
|
||||
x,
|
||||
cos,
|
||||
sin,
|
||||
interleaved=False,
|
||||
inplace=False,
|
||||
seqlen_offsets: Union[int, torch.Tensor] = 0,
|
||||
cu_seqlens: Optional[torch.Tensor] = None,
|
||||
max_seqlen: Optional[int] = None,
|
||||
):
|
||||
out = apply_rotary(
|
||||
x,
|
||||
cos,
|
||||
sin,
|
||||
seqlen_offsets=seqlen_offsets,
|
||||
cu_seqlens=cu_seqlens,
|
||||
max_seqlen=max_seqlen,
|
||||
interleaved=interleaved,
|
||||
inplace=inplace,
|
||||
)
|
||||
if isinstance(seqlen_offsets, int):
|
||||
# Can't save int with save_for_backward
|
||||
ctx.save_for_backward(cos, sin, cu_seqlens)
|
||||
ctx.seqlen_offsets = seqlen_offsets
|
||||
else:
|
||||
ctx.save_for_backward(cos, sin, cu_seqlens, seqlen_offsets)
|
||||
ctx.seqlen_offsets = None
|
||||
ctx.interleaved = interleaved
|
||||
ctx.inplace = inplace
|
||||
ctx.max_seqlen = max_seqlen
|
||||
return out if not inplace else x
|
||||
|
||||
@staticmethod
|
||||
def backward(ctx, do):
|
||||
seqlen_offsets = ctx.seqlen_offsets
|
||||
if seqlen_offsets is None:
|
||||
cos, sin, cu_seqlens, seqlen_offsets = ctx.saved_tensors
|
||||
else:
|
||||
cos, sin, cu_seqlens = ctx.saved_tensors
|
||||
# TD [2023-09-02]: For some reason Triton (2.0.0.post1) errors with
|
||||
# "[CUDA]: invalid device context", and cloning makes it work. Idk why. Triton 2.1.0 works.
|
||||
if not ctx.interleaved and not ctx.inplace:
|
||||
do = do.clone()
|
||||
dx = apply_rotary(
|
||||
do,
|
||||
cos,
|
||||
sin,
|
||||
seqlen_offsets=seqlen_offsets,
|
||||
cu_seqlens=cu_seqlens,
|
||||
max_seqlen=ctx.max_seqlen,
|
||||
interleaved=ctx.interleaved,
|
||||
inplace=ctx.inplace,
|
||||
conjugate=True,
|
||||
)
|
||||
return dx, None, None, None, None, None, None, None
|
||||
|
||||
|
||||
def apply_rotary_emb(
|
||||
x,
|
||||
cos,
|
||||
sin,
|
||||
interleaved=False,
|
||||
inplace=False,
|
||||
seqlen_offsets: Union[int, torch.Tensor] = 0,
|
||||
cu_seqlens: Optional[torch.Tensor] = None,
|
||||
max_seqlen: Optional[int] = None,
|
||||
):
|
||||
"""
|
||||
Arguments:
|
||||
x: (batch_size, seqlen, nheads, headdim) if cu_seqlens is None
|
||||
else (total_seqlen, nheads, headdim)
|
||||
cos, sin: (seqlen_rotary, rotary_dim / 2)
|
||||
interleaved: if True, rotate pairs of even and odd dimensions (GPT-J style) instead
|
||||
of 1st half and 2nd half (GPT-NeoX style).
|
||||
inplace: if True, apply rotary embedding in-place.
|
||||
seqlen_offsets: (batch_size,) or int. Each sequence in x is shifted by this amount.
|
||||
Most commonly used in inference when we have KV cache.
|
||||
cu_seqlens: (batch + 1,) or None
|
||||
max_seqlen: int
|
||||
Return:
|
||||
out: (batch_size, seqlen, nheads, headdim) if cu_seqlens is None
|
||||
else (total_seqlen, nheads, headdim)
|
||||
rotary_dim must be <= headdim
|
||||
Apply rotary embedding to the first rotary_dim of x.
|
||||
"""
|
||||
return ApplyRotaryEmb.apply(
|
||||
x, cos, sin, interleaved, inplace, seqlen_offsets, cu_seqlens, max_seqlen
|
||||
)
|
||||
|
||||
|
||||
# For backward compatibility
|
||||
apply_rotary_emb_func = apply_rotary_emb
|
||||
|
||||
|
||||
class RotaryEmbedding(torch.nn.Module):
|
||||
"""
|
||||
The rotary position embeddings from RoFormer_ (Su et. al).
|
||||
A crucial insight from the method is that the query and keys are
|
||||
transformed by rotation matrices which depend on the relative positions.
|
||||
|
||||
Other implementations are available in the Rotary Transformer repo_ and in
|
||||
GPT-NeoX_, GPT-NeoX was an inspiration
|
||||
|
||||
.. _RoFormer: https://arxiv.org/abs/2104.09864
|
||||
.. _repo: https://github.com/ZhuiyiTechnology/roformer
|
||||
.. _GPT-NeoX: https://github.com/EleutherAI/gpt-neox
|
||||
|
||||
If scale_base is not None, this implements XPos (Sun et al., https://arxiv.org/abs/2212.10554).
|
||||
A recommended value for scale_base is 512: https://github.com/HazyResearch/flash-attention/issues/96
|
||||
Reference: https://github.com/sunyt32/torchscale/blob/main/torchscale/component/xpos_relative_position.py
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
dim: int,
|
||||
base=10000.0,
|
||||
interleaved=False,
|
||||
scale_base=None,
|
||||
pos_idx_in_fp32=True,
|
||||
device=None,
|
||||
):
|
||||
"""
|
||||
interleaved: if True, rotate pairs of even and odd dimensions (GPT-J style) instead
|
||||
of 1st half and 2nd half (GPT-NeoX style).
|
||||
pos_idx_in_fp32: if True, the position indices [0.0, ..., seqlen - 1] are in fp32,
|
||||
otherwise they might be in lower precision.
|
||||
This option was added because previously (before 2023-07-02), when we construct
|
||||
the position indices, we use the dtype of self.inv_freq. In most cases this would
|
||||
be fp32, but if the model is trained in pure bf16 (not mixed precision), then
|
||||
self.inv_freq would be bf16, and the position indices are also in bf16.
|
||||
Because of the limited precision of bf16 (e.g. 1995.0 is rounded to 2000.0), the
|
||||
embeddings for some positions will coincide.
|
||||
To maintain compatibility with models previously trained in pure bf16,
|
||||
we add this option.
|
||||
"""
|
||||
super().__init__()
|
||||
self.dim = dim
|
||||
self.base = float(base)
|
||||
self.pos_idx_in_fp32 = pos_idx_in_fp32
|
||||
# Generate and save the inverse frequency buffer (non trainable)
|
||||
inv_freq = self._compute_inv_freq(device)
|
||||
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
||||
self.interleaved = interleaved
|
||||
self.scale_base = scale_base
|
||||
scale = (
|
||||
(torch.arange(0, dim, 2, device=device,
|
||||
dtype=torch.float32) + 0.4 * dim) / (1.4 * dim)
|
||||
if scale_base is not None
|
||||
else None
|
||||
)
|
||||
self.register_buffer("scale", scale, persistent=False)
|
||||
|
||||
self._seq_len_cached = 0
|
||||
self._cos_cached = None
|
||||
self._sin_cached = None
|
||||
self._cos_k_cached = None
|
||||
self._sin_k_cached = None
|
||||
|
||||
def _compute_inv_freq(self, device=None):
|
||||
return 1.0 / (
|
||||
self.base
|
||||
** (torch.arange(0, self.dim, 2, device=device, dtype=torch.float32) / self.dim)
|
||||
)
|
||||
|
||||
def _update_cos_sin_cache(self, seqlen, device=None, dtype=None):
|
||||
# Reset the tables if the sequence length has changed,
|
||||
# if we're on a new device (possibly due to tracing for instance),
|
||||
# or if we're switching from inference mode to training
|
||||
if (
|
||||
seqlen > self._seq_len_cached
|
||||
or self._cos_cached is None
|
||||
or self._cos_cached.device != device
|
||||
or self._cos_cached.dtype != dtype
|
||||
or (self.training and self._cos_cached.is_inference())
|
||||
):
|
||||
self._seq_len_cached = seqlen
|
||||
# We want fp32 here, not self.inv_freq.dtype, since the model could be loaded in bf16
|
||||
# And the output of arange can be quite large, so bf16 would lose a lot of precision.
|
||||
# However, for compatibility reason, we add an option to use the dtype of self.inv_freq.
|
||||
if self.pos_idx_in_fp32:
|
||||
t = torch.arange(seqlen, device=device, dtype=torch.float32)
|
||||
# We want fp32 here as well since inv_freq will be multiplied with t, and the output
|
||||
# will be large. Having it in bf16 will lose a lot of precision and cause the
|
||||
# cos & sin output to change significantly.
|
||||
# We want to recompute self.inv_freq if it was not loaded in fp32
|
||||
if self.inv_freq.dtype != torch.float32:
|
||||
inv_freq = self._compute_inv_freq(device=device)
|
||||
else:
|
||||
inv_freq = self.inv_freq
|
||||
else:
|
||||
t = torch.arange(seqlen, device=device,
|
||||
dtype=self.inv_freq.dtype)
|
||||
inv_freq = self.inv_freq
|
||||
# Don't do einsum, it converts fp32 to fp16 under AMP
|
||||
# freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
||||
freqs = torch.outer(t, inv_freq)
|
||||
if self.scale is None:
|
||||
self._cos_cached = torch.cos(freqs).to(dtype)
|
||||
self._sin_cached = torch.sin(freqs).to(dtype)
|
||||
else:
|
||||
power = (
|
||||
torch.arange(seqlen, dtype=self.scale.dtype,
|
||||
device=self.scale.device)
|
||||
- seqlen // 2
|
||||
) / self.scale_base
|
||||
scale = self.scale.to(
|
||||
device=power.device) ** rearrange(power, "s -> s 1")
|
||||
# We want the multiplication by scale to happen in fp32
|
||||
self._cos_cached = (torch.cos(freqs) * scale).to(dtype)
|
||||
self._sin_cached = (torch.sin(freqs) * scale).to(dtype)
|
||||
self._cos_k_cached = (torch.cos(freqs) / scale).to(dtype)
|
||||
self._sin_k_cached = (torch.sin(freqs) / scale).to(dtype)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
q: torch.Tensor,
|
||||
k: torch.Tensor,
|
||||
seqlen_offset: Union[int, torch.Tensor] = 0,
|
||||
max_seqlen: Optional[int] = None,
|
||||
) -> Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:
|
||||
"""
|
||||
qkv: (batch, seqlen, 3, nheads, headdim) if kv is none,
|
||||
else it's just q of shape (batch, seqlen, nheads, headdim)
|
||||
kv: (batch, seqlen, 2, nheads, headdim)
|
||||
seqlen_offset: (batch_size,) or int. Each sequence in x is shifted by this amount.
|
||||
Most commonly used in inference when we have KV cache.
|
||||
If it's a tensor of shape (batch_size,), then to update the cos / sin cache, one
|
||||
should pass in max_seqlen, which will update the cos / sin cache up to that length.
|
||||
Apply rotary embedding *inplace* to qkv and / or kv.
|
||||
"""
|
||||
seqlen = q.shape[1]
|
||||
if max_seqlen is not None:
|
||||
self._update_cos_sin_cache(max_seqlen, device=q.device, dtype=q.dtype)
|
||||
elif isinstance(seqlen_offset, int):
|
||||
self._update_cos_sin_cache(seqlen + seqlen_offset, device=q.device, dtype=q.dtype)
|
||||
if self.scale is None:
|
||||
q = apply_rotary_emb_func(
|
||||
q,
|
||||
self._cos_cached,
|
||||
self._sin_cached,
|
||||
interleaved=self.interleaved,
|
||||
seqlen_offsets=seqlen_offset,
|
||||
)
|
||||
k = apply_rotary_emb_func(
|
||||
k,
|
||||
self._cos_cached,
|
||||
self._sin_cached,
|
||||
interleaved=self.interleaved,
|
||||
seqlen_offsets=seqlen_offset,
|
||||
)
|
||||
|
||||
else:
|
||||
q = apply_rotary_emb_func(
|
||||
q,
|
||||
self._cos_cached,
|
||||
self._sin_cached,
|
||||
interleaved=self.interleaved,
|
||||
seqlen_offsets=seqlen_offset,
|
||||
)
|
||||
k = apply_rotary_emb_func(
|
||||
k,
|
||||
self._cos_k_cached,
|
||||
self._sin_k_cached,
|
||||
interleaved=self.interleaved,
|
||||
seqlen_offsets=seqlen_offset,
|
||||
)
|
||||
|
||||
return q, k
|
||||
18
finetune/lora/v6/fla/ops/__init__.py
vendored
Normal file
18
finetune/lora/v6/fla/ops/__init__.py
vendored
Normal file
@ -0,0 +1,18 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from .based import fused_chunk_based, parallel_based
|
||||
from .gla import chunk_gla, fused_chunk_gla, fused_recurrent_gla
|
||||
from .retention import (chunk_retention, fused_chunk_retention,
|
||||
fused_recurrent_retention, parallel_retention)
|
||||
|
||||
__all__ = [
|
||||
'fused_chunk_based',
|
||||
'parallel_based',
|
||||
'chunk_gla',
|
||||
'fused_chunk_gla',
|
||||
'fused_recurrent_gla',
|
||||
'chunk_retention',
|
||||
'fused_chunk_retention',
|
||||
'fused_recurrent_retention',
|
||||
'parallel_retention'
|
||||
]
|
||||
11
finetune/lora/v6/fla/ops/abc/__init__.py
vendored
Normal file
11
finetune/lora/v6/fla/ops/abc/__init__.py
vendored
Normal file
@ -0,0 +1,11 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from .chunk import chunk_abc
|
||||
from .chunk_gate import chunk_gated_abc
|
||||
from .recurrent_fuse import fused_recurrent_gated_abc
|
||||
|
||||
__all__ = [
|
||||
'chunk_abc',
|
||||
'chunk_gated_abc',
|
||||
'fused_recurrent_gated_abc'
|
||||
]
|
||||
1194
finetune/lora/v6/fla/ops/abc/chunk.py
vendored
Normal file
1194
finetune/lora/v6/fla/ops/abc/chunk.py
vendored
Normal file
File diff suppressed because it is too large
Load Diff
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user