Compare commits
No commits in common. "master" and "v1.0.1" have entirely different histories.
13
.gitattributes
vendored
13
.gitattributes
vendored
@ -1,13 +0,0 @@
|
||||
* text=auto eol=lf
|
||||
|
||||
backend-python/rwkv_pip/** linguist-vendored
|
||||
backend-python/wkv_cuda_utils/** linguist-vendored
|
||||
backend-python/get-pip.py linguist-vendored
|
||||
backend-python/convert_model.py linguist-vendored
|
||||
backend-python/convert_safetensors.py linguist-vendored
|
||||
backend-python/convert_pytorch_to_ggml.py linguist-vendored
|
||||
backend-python/utils/midi.py linguist-vendored
|
||||
build/** linguist-vendored
|
||||
finetune/lora/** linguist-vendored
|
||||
finetune/json2binidx_tool/** linguist-vendored
|
||||
frontend/wailsjs/** linguist-generated
|
||||
9
.github/dependabot.yml
vendored
9
.github/dependabot.yml
vendored
@ -1,9 +0,0 @@
|
||||
version: 2
|
||||
updates:
|
||||
- package-ecosystem: "github-actions"
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: "weekly"
|
||||
commit-message:
|
||||
prefix: "chore"
|
||||
include: "scope"
|
||||
171
.github/workflows/docker.yml
vendored
171
.github/workflows/docker.yml
vendored
@ -1,171 +0,0 @@
|
||||
name: Publish Docker Image
|
||||
on: [push]
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.ref }}-${{ github.workflow }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
docker_build:
|
||||
name: Build ${{ matrix.arch }} Image
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
strategy:
|
||||
matrix:
|
||||
include:
|
||||
- arch: amd64
|
||||
name: amd64
|
||||
# - arch: arm64
|
||||
# name: arm64
|
||||
|
||||
steps:
|
||||
- name: Free up disk spaces
|
||||
run: |
|
||||
sudo rm -rf /usr/share/dotnet || true
|
||||
sudo rm -rf /opt/ghc || true
|
||||
sudo rm -rf "/usr/local/share/boost" || true
|
||||
sudo rm -rf "$AGENT_TOOLSDIRECTORY" || true
|
||||
|
||||
- name: Get lowercase string for the repository name
|
||||
id: lowercase-repo-name
|
||||
uses: ASzc/change-string-case-action@v2
|
||||
with:
|
||||
string: ${{ github.event.repository.name }}
|
||||
|
||||
- name: Checkout base
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
- name: Cache Docker layers
|
||||
uses: actions/cache@v2
|
||||
with:
|
||||
path: /tmp/.buildx-cache
|
||||
key: ${{ github.ref }}-${{ matrix.arch }}
|
||||
restore-keys: |
|
||||
${{ github.ref }}-${{ matrix.arch }}
|
||||
|
||||
- name: Set up QEMU
|
||||
uses: docker/setup-qemu-action@v2
|
||||
with:
|
||||
platforms: linux/${{ matrix.arch }}
|
||||
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v2
|
||||
|
||||
- name: Docker login
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
username: ${{ secrets.DOCKER_USERNAME }}
|
||||
password: ${{ secrets.DOCKER_PASSWORD }}
|
||||
|
||||
- name: Get commit SHA
|
||||
id: vars
|
||||
run: echo "::set-output name=sha_short::$(git rev-parse --short HEAD)"
|
||||
|
||||
- name: Build and export
|
||||
id: build
|
||||
if: github.ref == 'refs/heads/master'
|
||||
uses: docker/build-push-action@v3
|
||||
with:
|
||||
push: true
|
||||
platforms: linux/${{ matrix.arch }}
|
||||
tags: ${{ secrets.DOCKER_USERNAME }}/${{ steps.lowercase-repo-name.outputs.lowercase }}:${{ matrix.name }}-latest
|
||||
build-args: |
|
||||
SHA=${{ steps.vars.outputs.sha_short }}
|
||||
outputs: type=image,push=true
|
||||
cache-from: type=local,src=/tmp/.buildx-cache
|
||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
||||
|
||||
- name: Replace tag without `v`
|
||||
if: startsWith(github.ref, 'refs/tags/')
|
||||
uses: actions/github-script@v1
|
||||
id: version
|
||||
with:
|
||||
script: |
|
||||
return context.payload.ref.replace(/\/?refs\/tags\/v/, '')
|
||||
result-encoding: string
|
||||
|
||||
- name: Build release and export
|
||||
id: build_rel
|
||||
if: startsWith(github.ref, 'refs/tags/')
|
||||
uses: docker/build-push-action@v3
|
||||
with:
|
||||
push: true
|
||||
platforms: linux/${{ matrix.arch }}
|
||||
tags: ${{ secrets.DOCKER_USERNAME }}/${{ steps.lowercase-repo-name.outputs.lowercase }}:${{ matrix.name }}-${{steps.version.outputs.result}}
|
||||
build-args: |
|
||||
SHA=${{ steps.version.outputs.result }}
|
||||
outputs: type=image,push=true
|
||||
cache-from: type=local,src=/tmp/.buildx-cache
|
||||
cache-to: type=local,dest=/tmp/.buildx-cache
|
||||
|
||||
- name: Save digest
|
||||
if: github.ref == 'refs/heads/master'
|
||||
run: echo ${{ steps.build.outputs.digest }} > /tmp/digest.txt
|
||||
|
||||
- name: Save release digest
|
||||
if: startsWith(github.ref, 'refs/tags/')
|
||||
run: echo ${{ steps.build_rel.outputs.digest }} > /tmp/digest.txt
|
||||
|
||||
- name: Upload artifact
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: digest_${{ matrix.name }}
|
||||
path: /tmp/digest.txt
|
||||
|
||||
manifests:
|
||||
name: Build manifests
|
||||
needs: [docker_build]
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Get lowercase string for the repository name
|
||||
id: lowercase-repo-name
|
||||
uses: ASzc/change-string-case-action@v2
|
||||
with:
|
||||
string: ${{ github.event.repository.name }}
|
||||
|
||||
- name: Checkout base
|
||||
uses: actions/checkout@v2
|
||||
with:
|
||||
fetch-depth: 0
|
||||
|
||||
# https://github.com/docker/setup-qemu-action
|
||||
- name: Set up QEMU
|
||||
uses: docker/setup-qemu-action@v2
|
||||
|
||||
# https://github.com/docker/setup-buildx-action
|
||||
- name: Set up Docker Buildx
|
||||
uses: docker/setup-buildx-action@v2
|
||||
with:
|
||||
config-inline: |
|
||||
[worker.oci]
|
||||
max-parallelism = 1
|
||||
|
||||
- name: Download artifact
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
path: /tmp/images/
|
||||
|
||||
- name: Docker login
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
username: ${{ secrets.DOCKER_USERNAME }}
|
||||
password: ${{ secrets.DOCKER_PASSWORD }}
|
||||
|
||||
- name: Replace tag without `v`
|
||||
if: startsWith(github.ref, 'refs/tags/')
|
||||
uses: actions/github-script@v1
|
||||
id: version
|
||||
with:
|
||||
script: |
|
||||
return context.payload.ref.replace(/\/?refs\/tags\/v/, '')
|
||||
result-encoding: string
|
||||
|
||||
- name: Merge and push manifest on master branch
|
||||
if: github.ref == 'refs/heads/master'
|
||||
run: python scripts/merge_manifest.py "${{ secrets.DOCKER_USERNAME }}/${{ steps.lowercase-repo-name.outputs.lowercase }}"
|
||||
|
||||
- name: Merge and push manifest on release
|
||||
if: startsWith(github.ref, 'refs/tags/')
|
||||
run: python scripts/merge_manifest.py "${{ secrets.DOCKER_USERNAME }}/${{ steps.lowercase-repo-name.outputs.lowercase }}" ${{steps.version.outputs.result}}
|
||||
114
.github/workflows/pre-release.yml
vendored
114
.github/workflows/pre-release.yml
vendored
@ -1,114 +0,0 @@
|
||||
name: pre-release
|
||||
on:
|
||||
workflow_dispatch:
|
||||
push:
|
||||
branches:
|
||||
- master
|
||||
paths:
|
||||
- "backend-python/**"
|
||||
tags-ignore:
|
||||
- "v*"
|
||||
|
||||
jobs:
|
||||
windows:
|
||||
runs-on: windows-2022
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
ref: master
|
||||
- uses: actions/setup-go@v5
|
||||
with:
|
||||
go-version: "1.20.5"
|
||||
- uses: actions/setup-python@v5
|
||||
id: cp310
|
||||
with:
|
||||
python-version: "3.10"
|
||||
- uses: crazy-max/ghaction-chocolatey@v3
|
||||
with:
|
||||
args: install upx
|
||||
- run: |
|
||||
Start-BitsTransfer https://github.com/josStorer/ai00_rwkv_server/releases/latest/download/webgpu_server_windows_x86_64.exe ./backend-rust/webgpu_server.exe
|
||||
Start-BitsTransfer https://github.com/josStorer/web-rwkv-converter/releases/latest/download/web-rwkv-converter_windows_x86_64.exe ./backend-rust/web-rwkv-converter.exe
|
||||
Start-BitsTransfer https://github.com/josStorer/LibreHardwareMonitor.Console/releases/latest/download/LibreHardwareMonitor.Console.zip ./LibreHardwareMonitor.Console.zip
|
||||
Expand-Archive ./LibreHardwareMonitor.Console.zip -DestinationPath ./components/LibreHardwareMonitor.Console
|
||||
Start-BitsTransfer https://www.python.org/ftp/python/3.10.11/python-3.10.11-embed-amd64.zip ./python-3.10.11-embed-amd64.zip
|
||||
Expand-Archive ./python-3.10.11-embed-amd64.zip -DestinationPath ./py310
|
||||
$content=Get-Content "./py310/python310._pth"; $content | ForEach-Object {if ($_.ReadCount -eq 3) {"Lib\\site-packages"} else {$_}} | Set-Content ./py310/python310._pth
|
||||
./py310/python ./backend-python/get-pip.py
|
||||
./py310/python -m pip install Cython==3.0.4
|
||||
Copy-Item -Path "${{ steps.cp310.outputs.python-path }}/../include" -Destination "py310/include" -Recurse
|
||||
Copy-Item -Path "${{ steps.cp310.outputs.python-path }}/../libs" -Destination "py310/libs" -Recurse
|
||||
./py310/python -m pip install cyac==1.9
|
||||
go install github.com/wailsapp/wails/v2/cmd/wails@v2.8.0
|
||||
del ./backend-python/rwkv_pip/cpp/librwkv.dylib
|
||||
del ./backend-python/rwkv_pip/cpp/librwkv.so
|
||||
(Get-Content -Path ./backend-golang/app.go) -replace "//go:custom_build windows ", "" | Set-Content -Path ./backend-golang/app.go
|
||||
(Get-Content -Path ./backend-golang/utils.go) -replace "//go:custom_build windows ", "" | Set-Content -Path ./backend-golang/utils.go
|
||||
make
|
||||
Rename-Item -Path "build/bin/RWKV-Runner.exe" -NewName "RWKV-Runner_windows_x64.exe"
|
||||
|
||||
- uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: RWKV-Runner_windows_x64.exe
|
||||
path: build/bin/RWKV-Runner_windows_x64.exe
|
||||
|
||||
linux:
|
||||
runs-on: ubuntu-20.04
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
ref: master
|
||||
- uses: actions/setup-go@v5
|
||||
with:
|
||||
go-version: "1.20.5"
|
||||
- run: |
|
||||
wget https://github.com/josStorer/ai00_rwkv_server/releases/latest/download/webgpu_server_linux_x86_64 -O ./backend-rust/webgpu_server
|
||||
wget https://github.com/josStorer/web-rwkv-converter/releases/latest/download/web-rwkv-converter_linux_x86_64 -O ./backend-rust/web-rwkv-converter
|
||||
sudo apt-get update
|
||||
sudo apt-get install upx
|
||||
sudo apt-get install build-essential libgtk-3-dev libwebkit2gtk-4.0-dev libasound2-dev
|
||||
go install github.com/wailsapp/wails/v2/cmd/wails@v2.8.0
|
||||
rm ./backend-python/rwkv_pip/wkv_cuda.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv5.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv6.pyd
|
||||
rm ./backend-python/get-pip.py
|
||||
rm ./backend-python/rwkv_pip/cpp/librwkv.dylib
|
||||
rm ./backend-python/rwkv_pip/cpp/rwkv.dll
|
||||
rm ./backend-python/rwkv_pip/webgpu/web_rwkv_py.cp310-win_amd64.pyd
|
||||
make
|
||||
mv build/bin/RWKV-Runner build/bin/RWKV-Runner_linux_x64
|
||||
|
||||
- uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: RWKV-Runner_linux_x64
|
||||
path: build/bin/RWKV-Runner_linux_x64
|
||||
|
||||
macos:
|
||||
runs-on: macos-13
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
ref: master
|
||||
- uses: actions/setup-go@v5
|
||||
with:
|
||||
go-version: "1.20.5"
|
||||
- run: |
|
||||
wget https://github.com/josStorer/ai00_rwkv_server/releases/latest/download/webgpu_server_darwin_aarch64 -O ./backend-rust/webgpu_server
|
||||
wget https://github.com/josStorer/web-rwkv-converter/releases/latest/download/web-rwkv-converter_darwin_aarch64 -O ./backend-rust/web-rwkv-converter
|
||||
go install github.com/wailsapp/wails/v2/cmd/wails@v2.8.0
|
||||
rm ./backend-python/rwkv_pip/wkv_cuda.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv5.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv6.pyd
|
||||
rm ./backend-python/get-pip.py
|
||||
rm ./backend-python/rwkv_pip/cpp/rwkv.dll
|
||||
rm ./backend-python/rwkv_pip/cpp/librwkv.so
|
||||
rm ./backend-python/rwkv_pip/webgpu/web_rwkv_py.cp310-win_amd64.pyd
|
||||
make
|
||||
cp build/darwin/Readme_Install.txt build/bin/Readme_Install.txt
|
||||
cp build/bin/RWKV-Runner.app/Contents/MacOS/RWKV-Runner build/bin/RWKV-Runner_darwin_universal
|
||||
cd build/bin && zip -r RWKV-Runner_macos_universal.zip RWKV-Runner.app Readme_Install.txt
|
||||
|
||||
- uses: actions/upload-artifact@v4
|
||||
with:
|
||||
name: RWKV-Runner_macos_universal.zip
|
||||
path: build/bin/RWKV-Runner_macos_universal.zip
|
||||
139
.github/workflows/release.yml
vendored
139
.github/workflows/release.yml
vendored
@ -1,139 +0,0 @@
|
||||
name: release
|
||||
on:
|
||||
push:
|
||||
tags:
|
||||
- "v*"
|
||||
|
||||
permissions:
|
||||
contents: write
|
||||
env:
|
||||
GH_TOKEN: ${{ github.token }}
|
||||
|
||||
jobs:
|
||||
create-draft:
|
||||
runs-on: ubuntu-22.04
|
||||
steps:
|
||||
- run: echo "VERSION=${GITHUB_REF_NAME#v}" >> $GITHUB_ENV
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
ref: master
|
||||
|
||||
- uses: jossef/action-set-json-field@v2.2
|
||||
with:
|
||||
file: manifest.json
|
||||
field: version
|
||||
value: ${{ env.VERSION }}
|
||||
|
||||
- continue-on-error: true
|
||||
run: |
|
||||
git config --global user.email "github-actions[bot]@users.noreply.github.com"
|
||||
git config --global user.name "github-actions[bot]"
|
||||
git commit -am "release ${{github.ref_name}}"
|
||||
git push
|
||||
|
||||
- run: |
|
||||
gh release create ${{github.ref_name}} -d -F CURRENT_CHANGE.md -t ${{github.ref_name}}
|
||||
|
||||
windows:
|
||||
runs-on: windows-2022
|
||||
needs: create-draft
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
ref: master
|
||||
- uses: actions/setup-go@v5
|
||||
with:
|
||||
go-version: "1.20.5"
|
||||
- uses: actions/setup-python@v5
|
||||
id: cp310
|
||||
with:
|
||||
python-version: "3.10"
|
||||
- uses: crazy-max/ghaction-chocolatey@v3
|
||||
with:
|
||||
args: install upx
|
||||
- run: |
|
||||
Start-BitsTransfer https://github.com/josStorer/ai00_rwkv_server/releases/latest/download/webgpu_server_windows_x86_64.exe ./backend-rust/webgpu_server.exe
|
||||
Start-BitsTransfer https://github.com/josStorer/web-rwkv-converter/releases/latest/download/web-rwkv-converter_windows_x86_64.exe ./backend-rust/web-rwkv-converter.exe
|
||||
Start-BitsTransfer https://github.com/josStorer/LibreHardwareMonitor.Console/releases/latest/download/LibreHardwareMonitor.Console.zip ./LibreHardwareMonitor.Console.zip
|
||||
Expand-Archive ./LibreHardwareMonitor.Console.zip -DestinationPath ./components/LibreHardwareMonitor.Console
|
||||
Start-BitsTransfer https://www.python.org/ftp/python/3.10.11/python-3.10.11-embed-amd64.zip ./python-3.10.11-embed-amd64.zip
|
||||
Expand-Archive ./python-3.10.11-embed-amd64.zip -DestinationPath ./py310
|
||||
$content=Get-Content "./py310/python310._pth"; $content | ForEach-Object {if ($_.ReadCount -eq 3) {"Lib\\site-packages"} else {$_}} | Set-Content ./py310/python310._pth
|
||||
./py310/python ./backend-python/get-pip.py
|
||||
./py310/python -m pip install Cython==3.0.4
|
||||
Copy-Item -Path "${{ steps.cp310.outputs.python-path }}/../include" -Destination "py310/include" -Recurse
|
||||
Copy-Item -Path "${{ steps.cp310.outputs.python-path }}/../libs" -Destination "py310/libs" -Recurse
|
||||
./py310/python -m pip install cyac==1.9
|
||||
go install github.com/wailsapp/wails/v2/cmd/wails@v2.8.0
|
||||
del ./backend-python/rwkv_pip/cpp/librwkv.dylib
|
||||
del ./backend-python/rwkv_pip/cpp/librwkv.so
|
||||
(Get-Content -Path ./backend-golang/app.go) -replace "//go:custom_build windows ", "" | Set-Content -Path ./backend-golang/app.go
|
||||
(Get-Content -Path ./backend-golang/utils.go) -replace "//go:custom_build windows ", "" | Set-Content -Path ./backend-golang/utils.go
|
||||
make
|
||||
Rename-Item -Path "build/bin/RWKV-Runner.exe" -NewName "RWKV-Runner_windows_x64.exe"
|
||||
|
||||
- run: gh release upload ${{github.ref_name}} build/bin/RWKV-Runner_windows_x64.exe
|
||||
|
||||
linux:
|
||||
runs-on: ubuntu-20.04
|
||||
needs: create-draft
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
ref: master
|
||||
- uses: actions/setup-go@v5
|
||||
with:
|
||||
go-version: "1.20.5"
|
||||
- run: |
|
||||
wget https://github.com/josStorer/ai00_rwkv_server/releases/latest/download/webgpu_server_linux_x86_64 -O ./backend-rust/webgpu_server
|
||||
wget https://github.com/josStorer/web-rwkv-converter/releases/latest/download/web-rwkv-converter_linux_x86_64 -O ./backend-rust/web-rwkv-converter
|
||||
sudo apt-get update
|
||||
sudo apt-get install upx
|
||||
sudo apt-get install build-essential libgtk-3-dev libwebkit2gtk-4.0-dev libasound2-dev
|
||||
go install github.com/wailsapp/wails/v2/cmd/wails@v2.8.0
|
||||
rm ./backend-python/rwkv_pip/wkv_cuda.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv5.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv6.pyd
|
||||
rm ./backend-python/get-pip.py
|
||||
rm ./backend-python/rwkv_pip/cpp/librwkv.dylib
|
||||
rm ./backend-python/rwkv_pip/cpp/rwkv.dll
|
||||
rm ./backend-python/rwkv_pip/webgpu/web_rwkv_py.cp310-win_amd64.pyd
|
||||
make
|
||||
mv build/bin/RWKV-Runner build/bin/RWKV-Runner_linux_x64
|
||||
|
||||
- run: gh release upload ${{github.ref_name}} build/bin/RWKV-Runner_linux_x64
|
||||
|
||||
macos:
|
||||
runs-on: macos-13
|
||||
needs: create-draft
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
ref: master
|
||||
- uses: actions/setup-go@v5
|
||||
with:
|
||||
go-version: "1.20.5"
|
||||
- run: |
|
||||
wget https://github.com/josStorer/ai00_rwkv_server/releases/latest/download/webgpu_server_darwin_aarch64 -O ./backend-rust/webgpu_server
|
||||
wget https://github.com/josStorer/web-rwkv-converter/releases/latest/download/web-rwkv-converter_darwin_aarch64 -O ./backend-rust/web-rwkv-converter
|
||||
go install github.com/wailsapp/wails/v2/cmd/wails@v2.8.0
|
||||
rm ./backend-python/rwkv_pip/wkv_cuda.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv5.pyd
|
||||
rm ./backend-python/rwkv_pip/rwkv6.pyd
|
||||
rm ./backend-python/get-pip.py
|
||||
rm ./backend-python/rwkv_pip/cpp/rwkv.dll
|
||||
rm ./backend-python/rwkv_pip/cpp/librwkv.so
|
||||
rm ./backend-python/rwkv_pip/webgpu/web_rwkv_py.cp310-win_amd64.pyd
|
||||
make
|
||||
cp build/darwin/Readme_Install.txt build/bin/Readme_Install.txt
|
||||
cp build/bin/RWKV-Runner.app/Contents/MacOS/RWKV-Runner build/bin/RWKV-Runner_darwin_universal
|
||||
cd build/bin && zip -r RWKV-Runner_macos_universal.zip RWKV-Runner.app Readme_Install.txt
|
||||
|
||||
- run: gh release upload ${{github.ref_name}} build/bin/RWKV-Runner_macos_universal.zip build/bin/RWKV-Runner_darwin_universal
|
||||
|
||||
publish-release:
|
||||
runs-on: ubuntu-22.04
|
||||
needs: [ windows, linux, macos ]
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- run: gh release edit ${{github.ref_name}} --draft=false
|
||||
18
.gitignore
vendored
18
.gitignore
vendored
@ -5,26 +5,12 @@ __pycache__
|
||||
.idea
|
||||
.vs
|
||||
*.pth
|
||||
*.st
|
||||
*.safetensors
|
||||
*.bin
|
||||
*.mid
|
||||
/config.json
|
||||
/cache.json
|
||||
/presets.json
|
||||
/frontend/stats.html
|
||||
/frontend/package.json.md5
|
||||
/backend-python/get-pip.py
|
||||
/py310
|
||||
*.zip
|
||||
/cmd-helper.bat
|
||||
/install-py-dep.bat
|
||||
/backend-python/wkv_cuda
|
||||
*.exe
|
||||
*.old
|
||||
.DS_Store
|
||||
*.log.*
|
||||
*.log
|
||||
train_log.txt
|
||||
finetune/json2binidx_tool/data
|
||||
/wsl.state
|
||||
/components
|
||||
/cmd-helper.bat
|
||||
33
.vscode/launch.json
vendored
33
.vscode/launch.json
vendored
@ -1,33 +0,0 @@
|
||||
{
|
||||
// Use IntelliSense to learn about possible attributes.
|
||||
// Hover to view descriptions of existing attributes.
|
||||
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
|
||||
//
|
||||
// Use Ctrl+Shift+P to Select Interpreter
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Python",
|
||||
"type": "python",
|
||||
"request": "launch",
|
||||
"program": "${workspaceFolder}/backend-python/main.py",
|
||||
"console": "integratedTerminal",
|
||||
"justMyCode": false
|
||||
},
|
||||
{
|
||||
"name": "Golang",
|
||||
"type": "go",
|
||||
"request": "launch",
|
||||
"mode": "exec",
|
||||
"program": "${workspaceFolder}/build/bin/testwails.exe",
|
||||
"console": "integratedTerminal",
|
||||
"preLaunchTask": "build dev"
|
||||
},
|
||||
{
|
||||
"name": "Frontend",
|
||||
"type": "node-terminal",
|
||||
"request": "launch",
|
||||
"command": "wails dev -browser"
|
||||
}
|
||||
]
|
||||
}
|
||||
2
.vscode/settings.json
vendored
2
.vscode/settings.json
vendored
@ -2,6 +2,6 @@
|
||||
"[python]": {
|
||||
"editor.defaultFormatter": "ms-python.black-formatter"
|
||||
},
|
||||
"python.formatting.provider": "none",
|
||||
"python.formatting.provider": "black",
|
||||
"editor.formatOnSave": true
|
||||
}
|
||||
40
.vscode/tasks.json
vendored
40
.vscode/tasks.json
vendored
@ -1,40 +0,0 @@
|
||||
{
|
||||
"version": "2.0.0",
|
||||
"tasks": [
|
||||
{
|
||||
"label": "build dev",
|
||||
"type": "shell",
|
||||
"options": {
|
||||
"cwd": "${workspaceFolder}",
|
||||
"env": {
|
||||
"CGO_ENABLED": "1"
|
||||
}
|
||||
},
|
||||
"osx": {
|
||||
"options": {
|
||||
"env": {
|
||||
"CGO_CFLAGS": "-mmacosx-version-min=10.13",
|
||||
"CGO_LDFLAGS": "-framework UniformTypeIdentifiers -mmacosx-version-min=10.13"
|
||||
}
|
||||
}
|
||||
},
|
||||
"windows": {
|
||||
"options": {
|
||||
"env": {
|
||||
"CGO_ENABLED": "0"
|
||||
}
|
||||
}
|
||||
},
|
||||
"command": "go",
|
||||
"args": [
|
||||
"build",
|
||||
"-tags",
|
||||
"dev",
|
||||
"-gcflags",
|
||||
"all=-N -l",
|
||||
"-o",
|
||||
"build/bin/testwails.exe"
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
@ -1,31 +0,0 @@
|
||||
## v1.8.4
|
||||
|
||||
- fix f05a4a, __init__.py is not embedded
|
||||
|
||||
## v1.8.3
|
||||
|
||||
### Deprecations
|
||||
|
||||
- rwkv-beta is deprecated
|
||||
|
||||
### Upgrades
|
||||
|
||||
- bump webgpu(python) (https://github.com/cryscan/web-rwkv-py)
|
||||
- sync https://github.com/JL-er/RWKV-PEFT (LoRA)
|
||||
|
||||
### Improvements
|
||||
|
||||
- improve default LoRA fine-tune params
|
||||
|
||||
### Fixes
|
||||
|
||||
- fix #342, #345: cannot import name 'packaging' from 'pkg_resources'
|
||||
- fix the huge error prompt that pops up when running in webgpu mode
|
||||
|
||||
## Install
|
||||
|
||||
- Windows: https://github.com/josStorer/RWKV-Runner/blob/master/build/windows/Readme_Install.txt
|
||||
- MacOS: https://github.com/josStorer/RWKV-Runner/blob/master/build/darwin/Readme_Install.txt
|
||||
- Linux: https://github.com/josStorer/RWKV-Runner/blob/master/build/linux/Readme_Install.txt
|
||||
- Simple Deploy Example: https://github.com/josStorer/RWKV-Runner/blob/master/README.md#simple-deploy-example
|
||||
- Server Deploy Examples: https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples
|
||||
55
Dockerfile
55
Dockerfile
@ -1,55 +0,0 @@
|
||||
FROM node:21-slim AS frontend
|
||||
|
||||
RUN echo "registry=https://registry.npmmirror.com/" > ~/.npmrc
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
COPY manifest.json manifest.json
|
||||
COPY frontend frontend
|
||||
|
||||
WORKDIR /app/frontend
|
||||
|
||||
RUN npm ci
|
||||
RUN npm run build
|
||||
|
||||
FROM nvidia/cuda:11.6.1-devel-ubuntu20.04 AS runtime
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
|
||||
RUN apt update && \
|
||||
apt install -yq git curl wget build-essential ninja-build aria2 jq software-properties-common
|
||||
|
||||
RUN add-apt-repository -y ppa:deadsnakes/ppa && \
|
||||
add-apt-repository -y ppa:ubuntu-toolchain-r/test && \
|
||||
apt install -y g++-11 python3.10 python3.10-distutils python3.10-dev && \
|
||||
curl -sS http://mirrors.aliyun.com/pypi/get-pip.py | python3.10
|
||||
|
||||
RUN python3.10 -m pip install cmake
|
||||
|
||||
FROM runtime AS librwkv
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
RUN git clone https://github.com/RWKV/rwkv.cpp.git && \
|
||||
cd rwkv.cpp && \
|
||||
git submodule update --init --recursive && \
|
||||
mkdir -p build && \
|
||||
cd build && \
|
||||
cmake -G Ninja .. && \
|
||||
cmake --build .
|
||||
|
||||
FROM runtime AS final
|
||||
|
||||
WORKDIR /app
|
||||
|
||||
COPY ./backend-python/requirements.txt ./backend-python/requirements.txt
|
||||
|
||||
RUN python3.10 -m pip install --quiet -r ./backend-python/requirements.txt
|
||||
|
||||
COPY . .
|
||||
COPY --from=frontend /app/frontend/dist /app/frontend/dist
|
||||
COPY --from=librwkv /app/rwkv.cpp/build/librwkv.so /app/backend-python/rwkv_pip/cpp/librwkv.so
|
||||
|
||||
EXPOSE 27777
|
||||
|
||||
CMD ["python3.10", "./backend-python/main.py", "--port", "27777", "--host", "0.0.0.0", "--webui"]
|
||||
23
Makefile
23
Makefile
@ -1,35 +1,16 @@
|
||||
ifeq ($(OS), Windows_NT)
|
||||
build: build-windows
|
||||
else ifeq ($(shell uname -s), Darwin)
|
||||
build: build-macos
|
||||
else
|
||||
build: build-linux
|
||||
build: build-macos
|
||||
endif
|
||||
|
||||
build-windows:
|
||||
@echo ---- build for windows
|
||||
wails build -ldflags '-s -w -extldflags "-static"' -platform windows/amd64
|
||||
upx -9 --lzma ./build/bin/RWKV-Runner.exe
|
||||
wails build -upx -ldflags "-s -w"
|
||||
|
||||
build-macos:
|
||||
@echo ---- build for macos
|
||||
wails build -ldflags '-s -w' -platform darwin/universal
|
||||
|
||||
build-linux:
|
||||
@echo ---- build for linux
|
||||
wails build -ldflags '-s -w' -platform linux/amd64
|
||||
upx -9 --lzma ./build/bin/RWKV-Runner
|
||||
|
||||
build-web:
|
||||
@echo ---- build for web
|
||||
cd frontend && npm run build
|
||||
|
||||
dev:
|
||||
wails dev
|
||||
|
||||
dev-web:
|
||||
cd frontend && npm run dev
|
||||
|
||||
preview:
|
||||
cd frontend && npm run preview
|
||||
|
||||
|
||||
258
README.md
258
README.md
@ -1,5 +1,5 @@
|
||||
<p align="center">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/65c46133-7506-4b54-b64f-fe49f188afa7">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/d24834b0-265d-45f5-93c0-fac1e19562af">
|
||||
</p>
|
||||
|
||||
<h1 align="center">RWKV Runner</h1>
|
||||
@ -12,17 +12,10 @@ compatible with the OpenAI API, which means that every ChatGPT client is an RWKV
|
||||
|
||||
[![license][license-image]][license-url]
|
||||
[![release][release-image]][release-url]
|
||||
[![py-version][py-version-image]][py-version-url]
|
||||
|
||||
English | [简体中文](README_ZH.md) | [日本語](README_JA.md)
|
||||
English | [简体中文](README_ZH.md)
|
||||
|
||||
### Install
|
||||
|
||||
[![Windows][Windows-image]][Windows-url]
|
||||
[![MacOS][MacOS-image]][MacOS-url]
|
||||
[![Linux][Linux-image]][Linux-url]
|
||||
|
||||
[FAQs](https://github.com/josStorer/RWKV-Runner/wiki/FAQs) | [Preview](#Preview) | [Download][download-url] | [Simple Deploy Example](#Simple-Deploy-Example) | [Server Deploy Examples](https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples) | [MIDI Hardware Input](#MIDI-Input)
|
||||
[Preview](#Preview) | [Download][download-url]
|
||||
|
||||
[license-image]: http://img.shields.io/badge/license-MIT-blue.svg
|
||||
|
||||
@ -32,260 +25,59 @@ English | [简体中文](README_ZH.md) | [日本語](README_JA.md)
|
||||
|
||||
[release-url]: https://github.com/josStorer/RWKV-Runner/releases/latest
|
||||
|
||||
[py-version-image]: https://img.shields.io/pypi/pyversions/fastapi.svg
|
||||
|
||||
[py-version-url]: https://github.com/josStorer/RWKV-Runner/tree/master/backend-python
|
||||
|
||||
[download-url]: https://github.com/josStorer/RWKV-Runner/releases
|
||||
|
||||
[Windows-image]: https://img.shields.io/badge/-Windows-blue?logo=windows
|
||||
|
||||
[Windows-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/windows/Readme_Install.txt
|
||||
|
||||
[MacOS-image]: https://img.shields.io/badge/-MacOS-black?logo=apple
|
||||
|
||||
[MacOS-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/darwin/Readme_Install.txt
|
||||
|
||||
[Linux-image]: https://img.shields.io/badge/-Linux-black?logo=linux
|
||||
|
||||
[Linux-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/linux/Readme_Install.txt
|
||||
[download-url]: https://github.com/josStorer/RWKV-Runner/releases/download/v1.0.0/RWKV-Runner_windows_x64.exe
|
||||
|
||||
</div>
|
||||
|
||||
## Tips
|
||||
|
||||
- You can deploy [backend-python](./backend-python/) on a server and use this program as a client only. Fill in
|
||||
your server address in the Settings `API URL`.
|
||||
|
||||
- If you are deploying and providing public services, please limit the request size through API gateway to prevent
|
||||
excessive resource usage caused by submitting overly long prompts. Additionally, please restrict the upper limit of
|
||||
requests' max_tokens based on your actual
|
||||
situation: https://github.com/josStorer/RWKV-Runner/blob/master/backend-python/utils/rwkv.py#L567, the default is set
|
||||
as le=102400, which may result in significant resource consumption for individual responses in extreme cases.
|
||||
|
||||
- Default configs has enabled custom CUDA kernel acceleration, which is much faster and consumes much less VRAM. If you
|
||||
encounter possible compatibility issues (output garbled), go to the Configs page and turn
|
||||
off `Use Custom CUDA kernel to Accelerate`, or try to upgrade your gpu driver.
|
||||
|
||||
- If Windows Defender claims this is a virus, you can try
|
||||
downloading [v1.3.7_win.zip](https://github.com/josStorer/RWKV-Runner/releases/download/v1.3.7/RWKV-Runner_win.zip)
|
||||
and letting it update automatically to the latest version, or add it to the trusted
|
||||
list (`Windows Security` -> `Virus & threat protection` -> `Manage settings` -> `Exclusions` -> `Add or remove exclusions` -> `Add an exclusion` -> `Folder` -> `RWKV-Runner`).
|
||||
|
||||
- For different tasks, adjusting API parameters can achieve better results. For example, for translation tasks, you can
|
||||
try setting Temperature to 1 and Top_P to 0.3.
|
||||
|
||||
## Features
|
||||
|
||||
- RWKV model management and one-click startup.
|
||||
- Front-end and back-end separation, if you don't want to use the client, also allows for separately deploying the
|
||||
front-end service, or the back-end inference service, or the back-end inference service with a WebUI.
|
||||
[Simple Deploy Example](#Simple-Deploy-Example) | [Server Deploy Examples](https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples)
|
||||
- Compatible with the OpenAI API, making every ChatGPT client an RWKV client. After starting the model,
|
||||
- RWKV model management and one-click startup
|
||||
- Fully compatible with the OpenAI API, making every ChatGPT client an RWKV client. After starting the model,
|
||||
open http://127.0.0.1:8000/docs to view more details.
|
||||
- Automatic dependency installation, requiring only a lightweight executable program.
|
||||
- Pre-set multi-level VRAM configs, works well on almost all computers. In Configs page, switch Strategy to WebGPU, it
|
||||
can also run on AMD, Intel, and other graphics cards.
|
||||
- User-friendly chat, completion, and composition interaction interface included. Also supports chat presets, attachment
|
||||
uploads, MIDI hardware input, and track editing.
|
||||
[Preview](#Preview) | [MIDI Hardware Input](#MIDI-Input)
|
||||
- Built-in WebUI option, one-click start of Web service, sharing your hardware resources.
|
||||
- Easy-to-understand and operate parameter configuration, along with various operation guidance prompts.
|
||||
- Built-in model conversion tool.
|
||||
- Built-in download management and remote model inspection.
|
||||
- Built-in one-click LoRA Finetune. (Windows Only)
|
||||
- Can also be used as an OpenAI ChatGPT, GPT-Playground, Ollama and more clients. (Fill in the API URL and API Key in
|
||||
Settings page)
|
||||
- Multilingual localization.
|
||||
- Theme switching.
|
||||
- Automatic updates.
|
||||
- Automatic dependency installation, requiring only a lightweight executable program
|
||||
- User-friendly chat interaction interface included
|
||||
- Easy-to-understand and operate parameter configuration
|
||||
- Built-in model conversion tool
|
||||
- Built-in download management and remote model inspection
|
||||
- Multilingual localization
|
||||
- Theme switching
|
||||
- Automatic updates
|
||||
|
||||
## Simple Deploy Example
|
||||
## Todo
|
||||
|
||||
```bash
|
||||
git clone https://github.com/josStorer/RWKV-Runner
|
||||
|
||||
# Then
|
||||
cd RWKV-Runner
|
||||
python ./backend-python/main.py #The backend inference service has been started, request /switch-model API to load the model, refer to the API documentation: http://127.0.0.1:8000/docs
|
||||
|
||||
# Or
|
||||
cd RWKV-Runner/frontend
|
||||
npm ci
|
||||
npm run build #Compile the frontend
|
||||
cd ..
|
||||
python ./backend-python/webui_server.py #Start the frontend service separately
|
||||
# Or
|
||||
python ./backend-python/main.py --webui #Start the frontend and backend service at the same time
|
||||
|
||||
# Help Info
|
||||
python ./backend-python/main.py -h
|
||||
```
|
||||
|
||||
## API Concurrency Stress Testing
|
||||
|
||||
```bash
|
||||
ab -p body.json -T application/json -c 20 -n 100 -l http://127.0.0.1:8000/chat/completions
|
||||
```
|
||||
|
||||
body.json:
|
||||
|
||||
```json
|
||||
{
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Hello"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Embeddings API Example
|
||||
|
||||
Note: v1.4.0 has improved the quality of embeddings API. The generated results are not compatible
|
||||
with previous versions. If you are using embeddings API to generate knowledge bases or similar, please regenerate.
|
||||
|
||||
If you are using langchain, just use `OpenAIEmbeddings(openai_api_base="http://127.0.0.1:8000", openai_api_key="sk-")`
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import requests
|
||||
|
||||
|
||||
def cosine_similarity(a, b):
|
||||
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
|
||||
|
||||
|
||||
values = [
|
||||
"I am a girl",
|
||||
"我是个女孩",
|
||||
"私は女の子です",
|
||||
"广东人爱吃福建人",
|
||||
"我是个人类",
|
||||
"I am a human",
|
||||
"that dog is so cute",
|
||||
"私はねこむすめです、にゃん♪",
|
||||
"宇宙级特大事件!号外号外!"
|
||||
]
|
||||
|
||||
embeddings = []
|
||||
for v in values:
|
||||
r = requests.post("http://127.0.0.1:8000/embeddings", json={"input": v})
|
||||
embedding = r.json()["data"][0]["embedding"]
|
||||
embeddings.append(embedding)
|
||||
|
||||
compared_embedding = embeddings[0]
|
||||
|
||||
embeddings_cos_sim = [cosine_similarity(compared_embedding, e) for e in embeddings]
|
||||
|
||||
for i in np.argsort(embeddings_cos_sim)[::-1]:
|
||||
print(f"{embeddings_cos_sim[i]:.10f} - {values[i]}")
|
||||
```
|
||||
|
||||
## MIDI Input
|
||||
|
||||
Tip: You can download https://github.com/josStorer/sgm_plus and unzip it to the program's `assets/sound-font` directory
|
||||
to use it as an offline sound source. Please note that if you are compiling the program from source code, do not place
|
||||
it in the source code directory.
|
||||
|
||||
If you don't have a MIDI keyboard, you can use virtual MIDI input software like `Virtual Midi Controller 3 LE`, along
|
||||
with [loopMIDI](https://www.tobias-erichsen.de/wp-content/uploads/2020/01/loopMIDISetup_1_0_16_27.zip), to use a regular
|
||||
computer keyboard as MIDI input.
|
||||
|
||||
### USB MIDI Connection
|
||||
|
||||
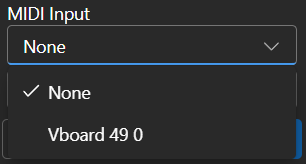
- USB MIDI devices are plug-and-play, and you can select your input device in the Composition page
|
||||
- 
|
||||
|
||||
### Mac MIDI Bluetooth Connection
|
||||
|
||||
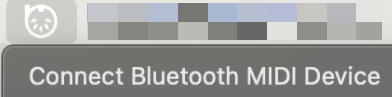
- For Mac users who want to use Bluetooth input,
|
||||
please install [Bluetooth MIDI Connect](https://apps.apple.com/us/app/bluetooth-midi-connect/id1108321791), then click
|
||||
the tray icon to connect after launching,
|
||||
afterwards, you can select your input device in the Composition page.
|
||||
- 
|
||||
|
||||
### Windows MIDI Bluetooth Connection
|
||||
|
||||
- Windows seems to have implemented Bluetooth MIDI support only for UWP (Universal Windows Platform) apps. Therefore, it
|
||||
requires multiple steps to establish a connection. We need to create a local virtual MIDI device and then launch a UWP
|
||||
application. Through this UWP application, we will redirect Bluetooth MIDI input to the virtual MIDI device, and then
|
||||
this software will listen to the input from the virtual MIDI device.
|
||||
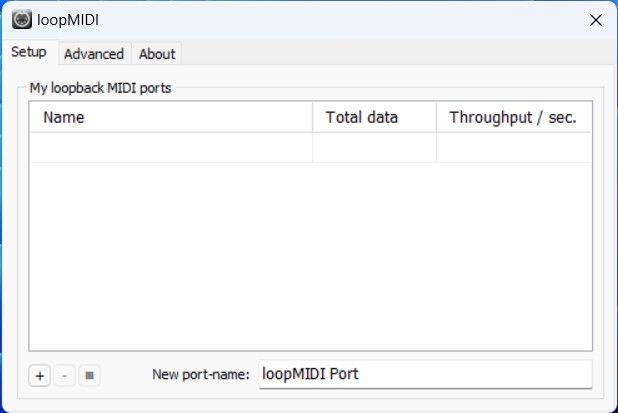
- So, first, you need to
|
||||
download [loopMIDI](https://www.tobias-erichsen.de/wp-content/uploads/2020/01/loopMIDISetup_1_0_16_27.zip)
|
||||
to create a virtual MIDI device. Click the plus sign in the bottom left corner to create the device.
|
||||
- 
|
||||
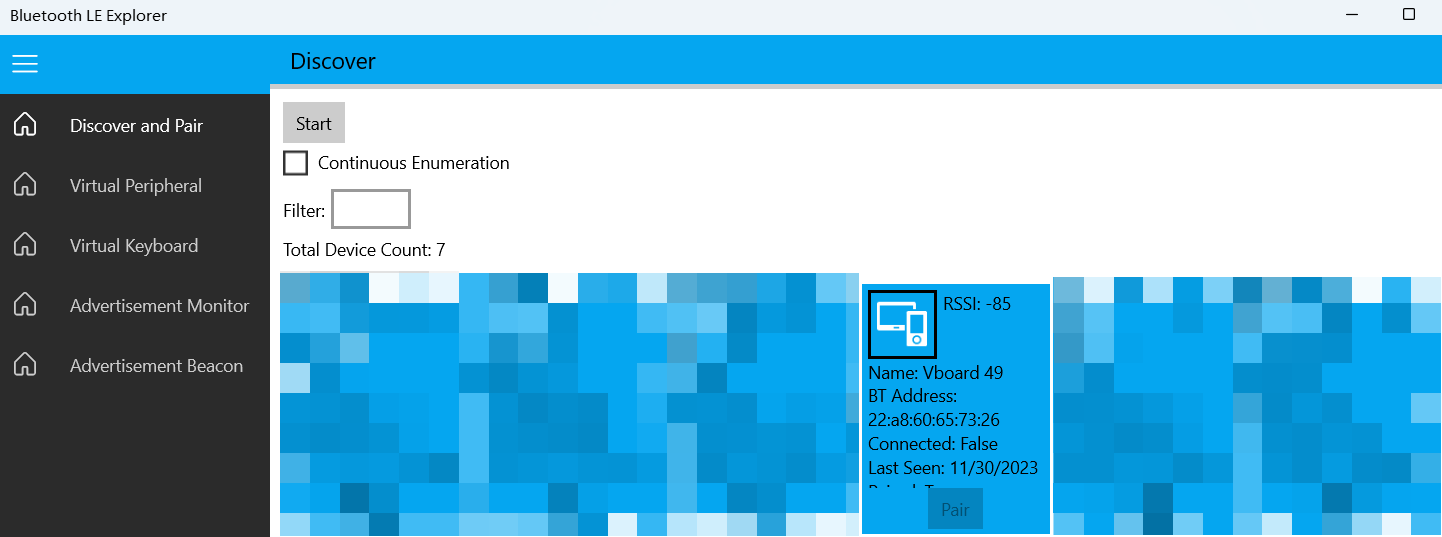
- Next, you need to download [Bluetooth LE Explorer](https://apps.microsoft.com/detail/9N0ZTKF1QD98) to discover and
|
||||
connect to Bluetooth MIDI devices. Click "Start" to search for devices, and then click "Pair" to bind the MIDI device.
|
||||
- 
|
||||
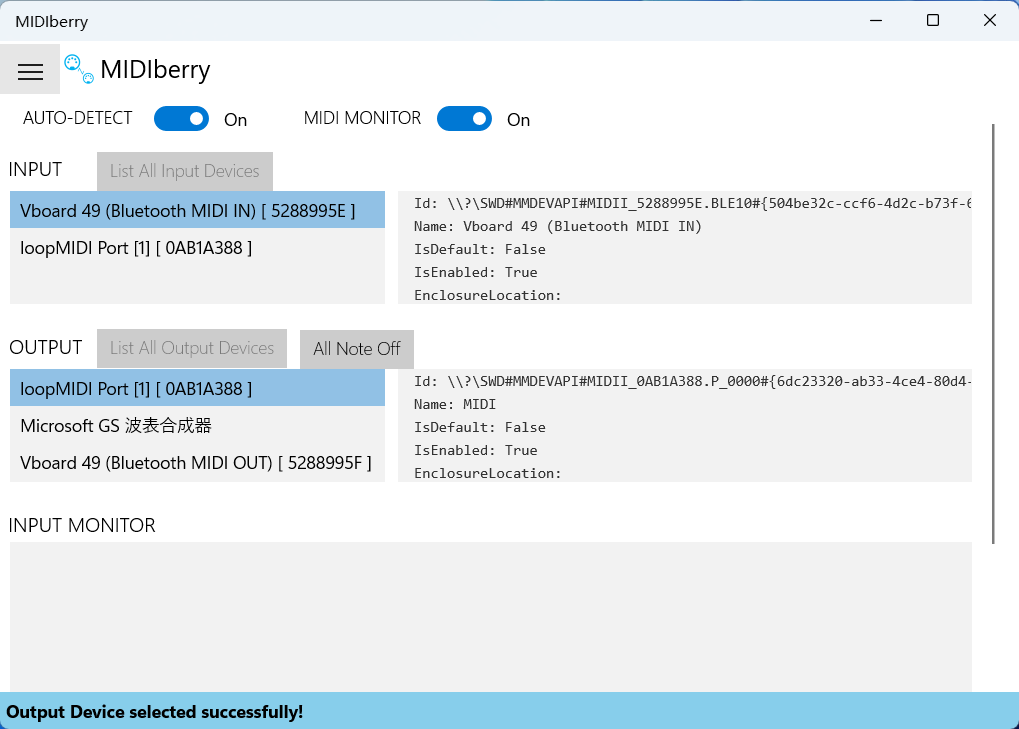
- Finally, you need to install [MIDIberry](https://apps.microsoft.com/detail/9N39720H2M05),
|
||||
This UWP application can redirect Bluetooth MIDI input to the virtual MIDI device. After launching it, double-click
|
||||
your actual Bluetooth MIDI device name in the input field, and in the output field, double-click the virtual MIDI
|
||||
device name we created earlier.
|
||||
- 
|
||||
- Now, you can select the virtual MIDI device as the input in the Composition page. Bluetooth LE Explorer no longer
|
||||
needs to run, and you can also close the loopMIDI window, it will run automatically in the background. Just keep
|
||||
MIDIberry open.
|
||||
- 
|
||||
- Model training functionality
|
||||
- CUDA operator int8 acceleration
|
||||
- macOS support
|
||||
- Linux support
|
||||
|
||||
## Related Repositories:
|
||||
|
||||
- RWKV-5-World: https://huggingface.co/BlinkDL/rwkv-5-world/tree/main
|
||||
- RWKV-4-World: https://huggingface.co/BlinkDL/rwkv-4-world/tree/main
|
||||
- RWKV-4-Raven: https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main
|
||||
- ChatRWKV: https://github.com/BlinkDL/ChatRWKV
|
||||
- RWKV-LM: https://github.com/BlinkDL/RWKV-LM
|
||||
- RWKV-LM-LoRA: https://github.com/Blealtan/RWKV-LM-LoRA
|
||||
- RWKV-v5-lora: https://github.com/JL-er/RWKV-v5-lora
|
||||
- MIDI-LLM-tokenizer: https://github.com/briansemrau/MIDI-LLM-tokenizer
|
||||
- ai00_rwkv_server: https://github.com/cgisky1980/ai00_rwkv_server
|
||||
- rwkv.cpp: https://github.com/saharNooby/rwkv.cpp
|
||||
- web-rwkv-py: https://github.com/cryscan/web-rwkv-py
|
||||
- web-rwkv: https://github.com/cryscan/web-rwkv
|
||||
|
||||
## Preview
|
||||
|
||||
### Homepage
|
||||
|
||||

|
||||

|
||||
|
||||
### Chat
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
### Completion
|
||||
|
||||
|
||||
|
||||
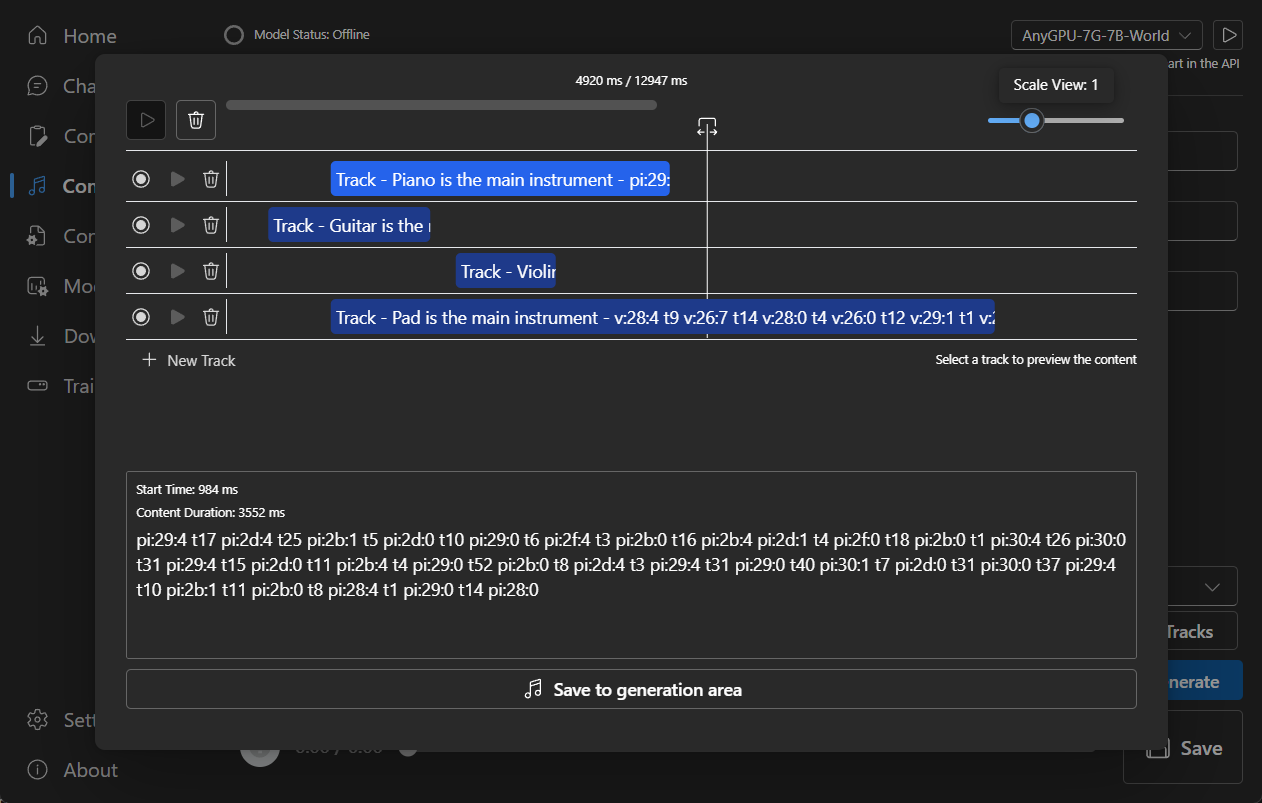
### Composition
|
||||
|
||||
Tip: You can download https://github.com/josStorer/sgm_plus and unzip it to the program's `assets/sound-font` directory
|
||||
to use it as an offline sound source. Please note that if you are compiling the program from source code, do not place
|
||||
it in the source code directory.
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
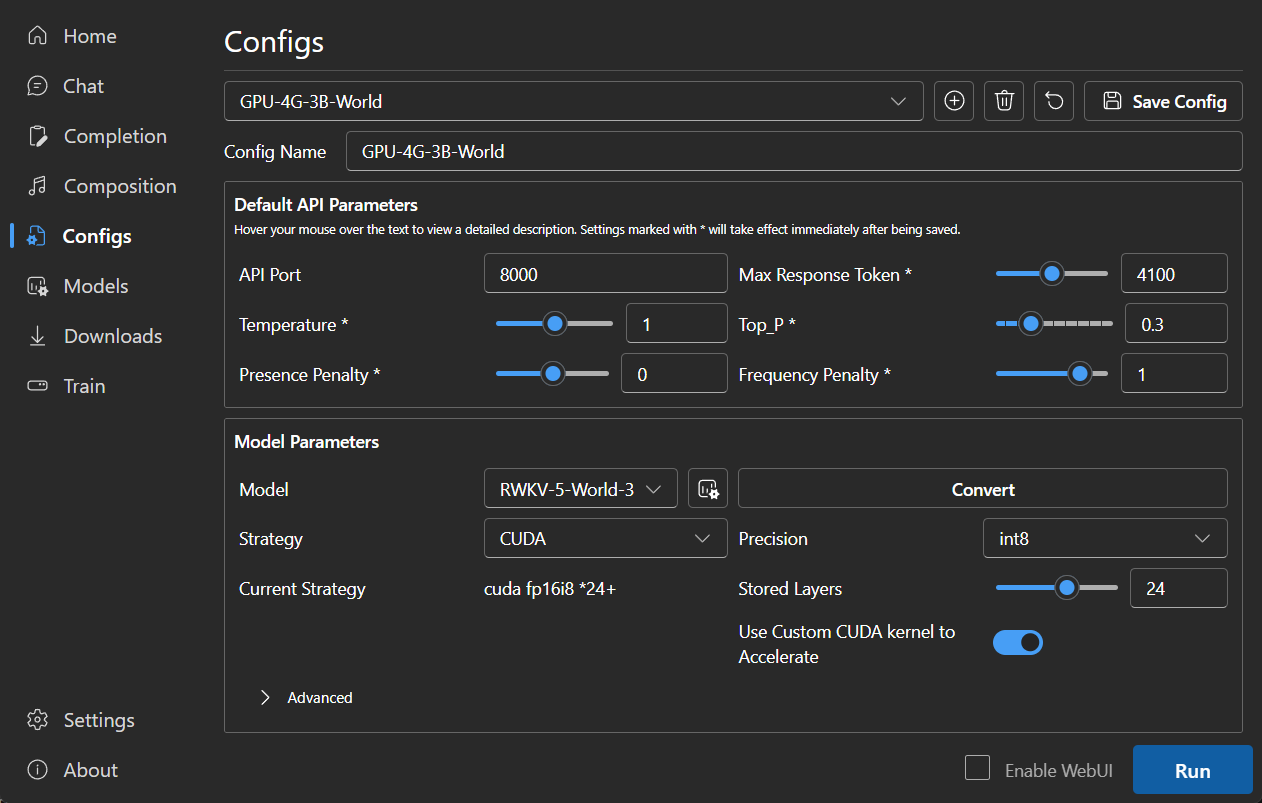
### Configuration
|
||||
|
||||
|
||||

|
||||
|
||||
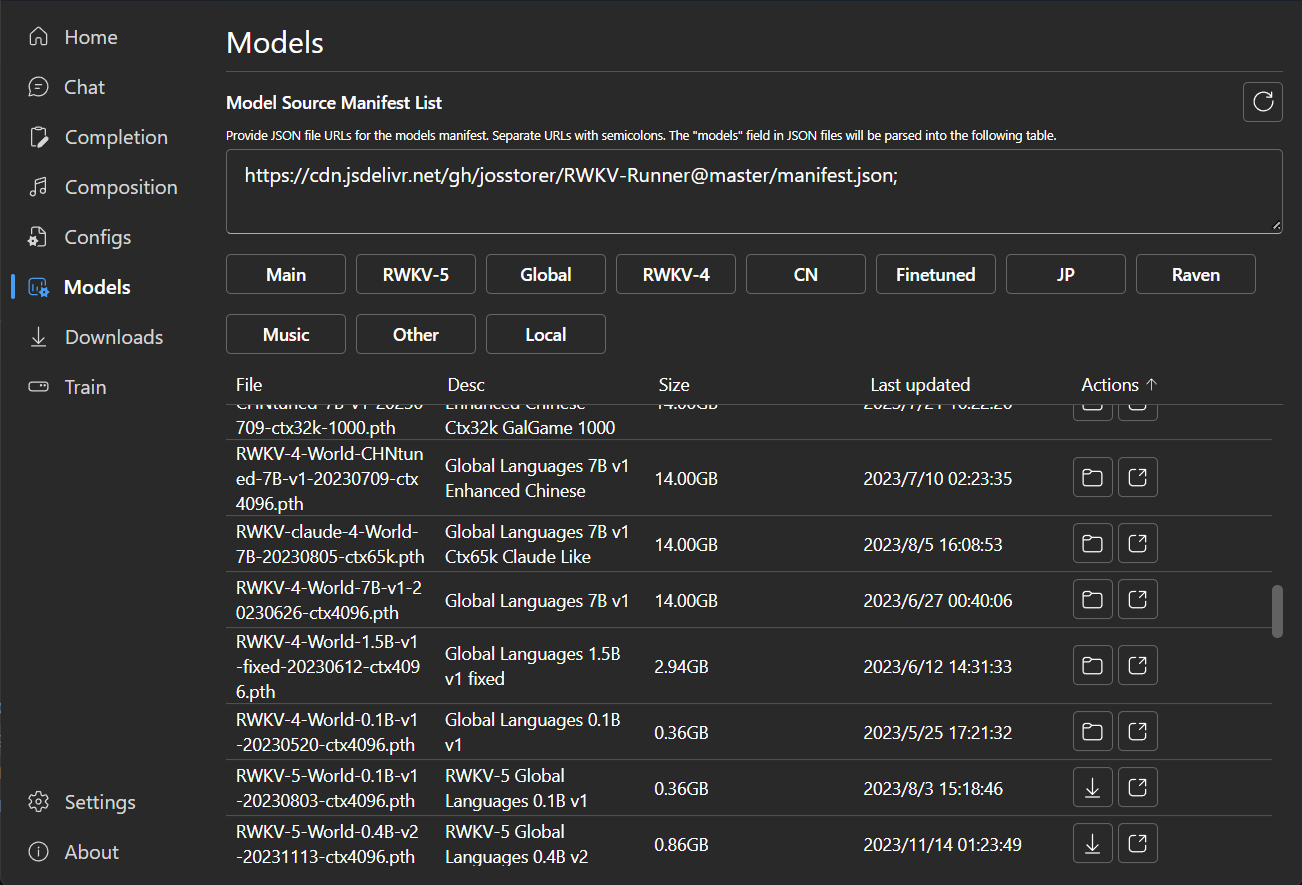
### Model Management
|
||||
|
||||
|
||||

|
||||
|
||||
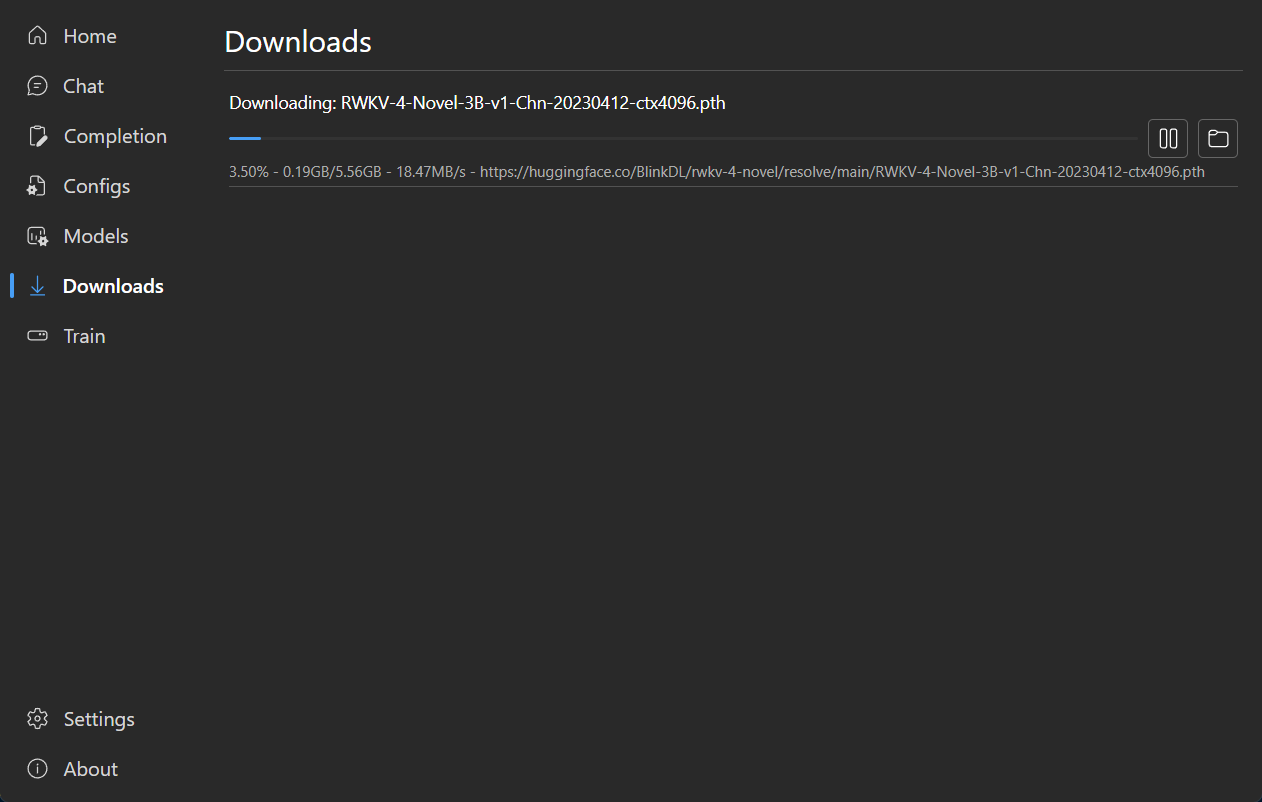
### Download Management
|
||||
|
||||
|
||||
|
||||
### LoRA Finetune
|
||||
|
||||
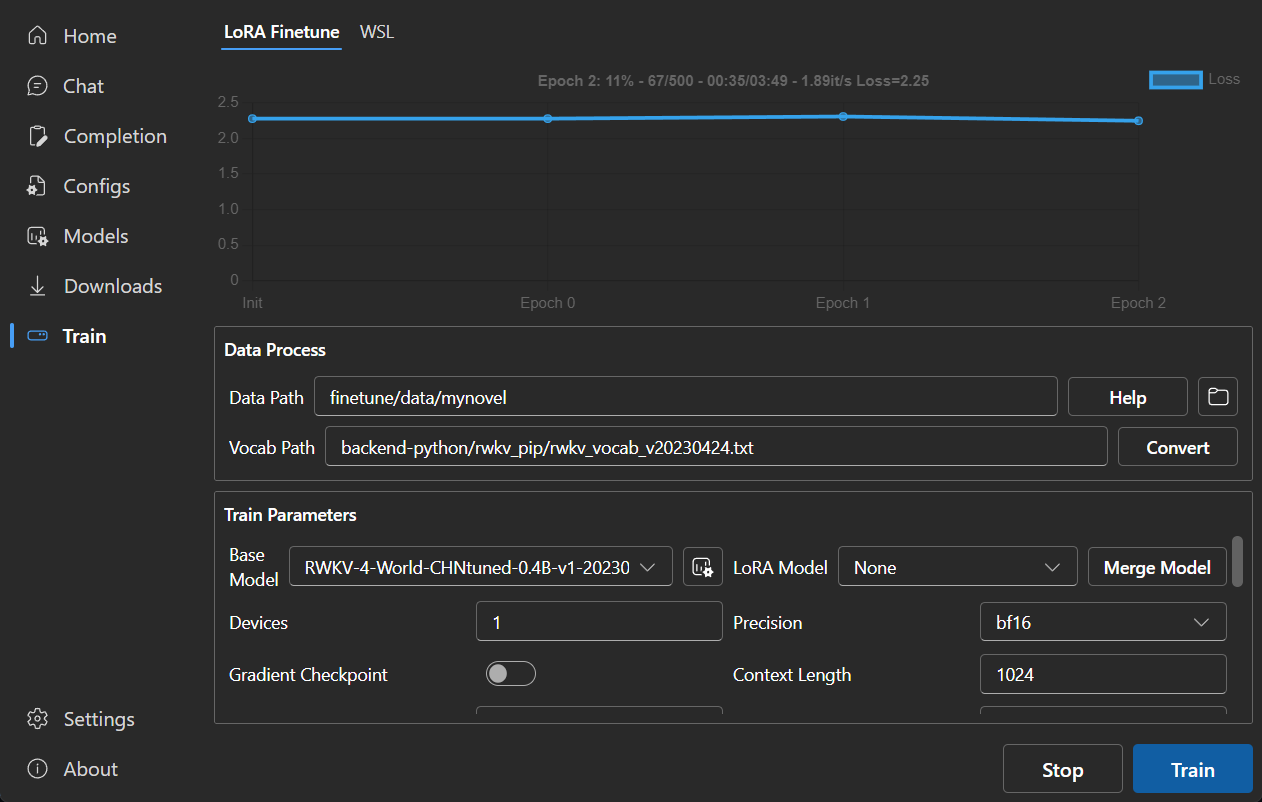
|
||||

|
||||
|
||||
### Settings
|
||||
|
||||
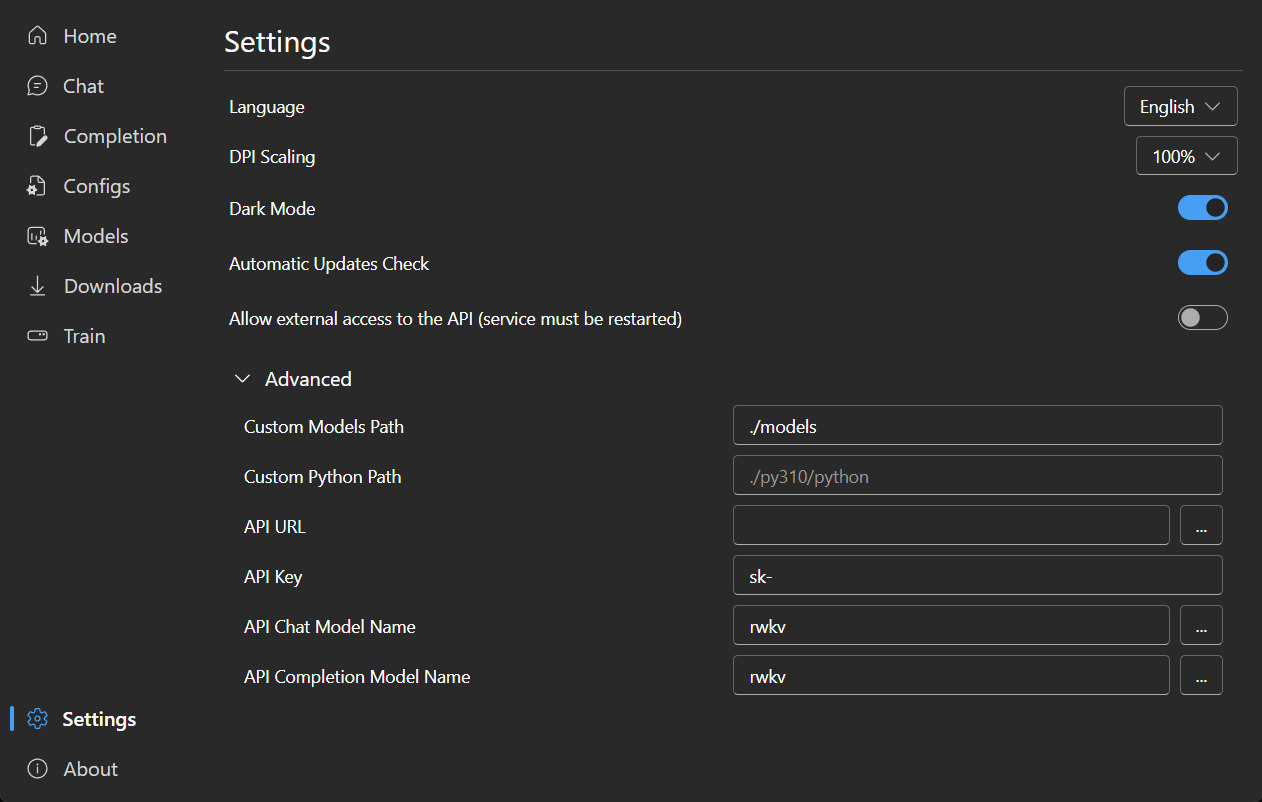
|
||||

|
||||
|
||||
287
README_JA.md
287
README_JA.md
@ -1,287 +0,0 @@
|
||||
<p align="center">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/65c46133-7506-4b54-b64f-fe49f188afa7">
|
||||
</p>
|
||||
|
||||
<h1 align="center">RWKV Runner</h1>
|
||||
|
||||
<div align="center">
|
||||
|
||||
このプロジェクトは、すべてを自動化することで、大規模な言語モデルを使用する際の障壁をなくすことを目的としています。必要なのは、
|
||||
わずか数メガバイトの軽量な実行プログラムだけです。さらに、このプロジェクトは OpenAI API と互換性のあるインターフェイスを提供しており、
|
||||
すべての ChatGPT クライアントは RWKV クライアントであることを意味します。
|
||||
|
||||
[![license][license-image]][license-url]
|
||||
[![release][release-image]][release-url]
|
||||
[![py-version][py-version-image]][py-version-url]
|
||||
|
||||
[English](README.md) | [简体中文](README_ZH.md) | 日本語
|
||||
|
||||
### インストール
|
||||
|
||||
[![Windows][Windows-image]][Windows-url]
|
||||
[![MacOS][MacOS-image]][MacOS-url]
|
||||
[![Linux][Linux-image]][Linux-url]
|
||||
|
||||
[FAQs](https://github.com/josStorer/RWKV-Runner/wiki/FAQs) | [プレビュー](#Preview) | [ダウンロード][download-url] | [シンプルなデプロイの例](#Simple-Deploy-Example) | [サーバーデプロイ例](https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples) | [MIDIハードウェア入力](#MIDI-Input)
|
||||
|
||||
[license-image]: http://img.shields.io/badge/license-MIT-blue.svg
|
||||
|
||||
[license-url]: https://github.com/josStorer/RWKV-Runner/blob/master/LICENSE
|
||||
|
||||
[release-image]: https://img.shields.io/github/release/josStorer/RWKV-Runner.svg
|
||||
|
||||
[release-url]: https://github.com/josStorer/RWKV-Runner/releases/latest
|
||||
|
||||
[py-version-image]: https://img.shields.io/pypi/pyversions/fastapi.svg
|
||||
|
||||
[py-version-url]: https://github.com/josStorer/RWKV-Runner/tree/master/backend-python
|
||||
|
||||
[download-url]: https://github.com/josStorer/RWKV-Runner/releases
|
||||
|
||||
[Windows-image]: https://img.shields.io/badge/-Windows-blue?logo=windows
|
||||
|
||||
[Windows-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/windows/Readme_Install.txt
|
||||
|
||||
[MacOS-image]: https://img.shields.io/badge/-MacOS-black?logo=apple
|
||||
|
||||
[MacOS-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/darwin/Readme_Install.txt
|
||||
|
||||
[Linux-image]: https://img.shields.io/badge/-Linux-black?logo=linux
|
||||
|
||||
[Linux-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/linux/Readme_Install.txt
|
||||
|
||||
</div>
|
||||
|
||||
## ヒント
|
||||
|
||||
- サーバーに [backend-python](./backend-python/)
|
||||
をデプロイし、このプログラムをクライアントとして使用することができます。設定された`API URL`にサーバーアドレスを入力してください。
|
||||
|
||||
- もし、あなたがデプロイし、外部に公開するサービスを提供している場合、APIゲートウェイを使用してリクエストのサイズを制限し、
|
||||
長すぎるプロンプトの提出がリソースを占有しないようにしてください。さらに、実際の状況に応じて、リクエストの max_tokens
|
||||
の上限を制限してください:https://github.com/josStorer/RWKV-Runner/blob/master/backend-python/utils/rwkv.py#L567
|
||||
、デフォルトは le=102400 ですが、極端な場合には単一の応答が大量のリソースを消費する可能性があります。
|
||||
|
||||
- デフォルトの設定はカスタム CUDA カーネルアクセラレーションを有効にしています。互換性の問題 (文字化けを出力する)
|
||||
が発生する可能性がある場合は、コンフィグページに移動し、`Use Custom CUDA kernel to Accelerate`
|
||||
をオフにしてください、あるいは、GPUドライバーをアップグレードしてみてください。
|
||||
|
||||
- Windows Defender
|
||||
がこれをウイルスだと主張する場合は、[v1.3.7_win.zip](https://github.com/josStorer/RWKV-Runner/releases/download/v1.3.7/RWKV-Runner_win.zip)
|
||||
をダウンロードして最新版に自動更新させるか、信頼済みリストに追加してみてください (`Windows Security` -> `Virus & threat protection` -> `Manage settings` -> `Exclusions` -> `Add or remove exclusions` -> `Add an exclusion` -> `Folder` -> `RWKV-Runner`)。
|
||||
|
||||
- 異なるタスクについては、API パラメータを調整することで、より良い結果を得ることができます。例えば、翻訳タスクの場合、Temperature
|
||||
を 1 に、Top_P を 0.3 に設定してみてください。
|
||||
|
||||
## 特徴
|
||||
|
||||
- RWKV モデル管理とワンクリック起動
|
||||
- フロントエンドとバックエンドの分離は、クライアントを使用しない場合でも、フロントエンドサービス、またはバックエンド推論サービス、またはWebUIを備えたバックエンド推論サービスを個別に展開することを可能にします。
|
||||
[シンプルなデプロイの例](#Simple-Deploy-Example) | [サーバーデプロイ例](https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples)
|
||||
- OpenAI API と互換性があり、すべての ChatGPT クライアントを RWKV クライアントにします。モデル起動後、
|
||||
http://127.0.0.1:8000/docs を開いて詳細をご覧ください。
|
||||
- 依存関係の自動インストールにより、軽量な実行プログラムのみを必要とします
|
||||
- 事前設定された多段階のVRAM設定、ほとんどのコンピュータで動作します。配置ページで、ストラテジーをWebGPUに切り替えると、AMD、インテル、その他のグラフィックカードでも動作します
|
||||
- ユーザーフレンドリーなチャット、完成、および作曲インターフェイスが含まれています。また、チャットプリセット、添付ファイルのアップロード、MIDIハードウェア入力、トラック編集もサポートしています。
|
||||
[プレビュー](#Preview) | [MIDIハードウェア入力](#MIDI-Input)
|
||||
- 内蔵WebUIオプション、Webサービスのワンクリック開始、ハードウェアリソースの共有
|
||||
- 分かりやすく操作しやすいパラメータ設定、各種操作ガイダンスプロンプトとともに
|
||||
- 内蔵モデル変換ツール
|
||||
- ダウンロード管理とリモートモデル検査機能内蔵
|
||||
- 内蔵のLoRA微調整機能を搭載しています (Windowsのみ)
|
||||
- このプログラムは、OpenAI ChatGPT、GPT Playground、Ollama などのクライアントとしても使用できます(設定ページで `API URL`
|
||||
と `API Key` を入力してください)
|
||||
- 多言語ローカライズ
|
||||
- テーマ切り替え
|
||||
- 自動アップデート
|
||||
|
||||
## Simple Deploy Example
|
||||
|
||||
```bash
|
||||
git clone https://github.com/josStorer/RWKV-Runner
|
||||
|
||||
# Then
|
||||
cd RWKV-Runner
|
||||
python ./backend-python/main.py #The backend inference service has been started, request /switch-model API to load the model, refer to the API documentation: http://127.0.0.1:8000/docs
|
||||
|
||||
# Or
|
||||
cd RWKV-Runner/frontend
|
||||
npm ci
|
||||
npm run build #Compile the frontend
|
||||
cd ..
|
||||
python ./backend-python/webui_server.py #Start the frontend service separately
|
||||
# Or
|
||||
python ./backend-python/main.py --webui #Start the frontend and backend service at the same time
|
||||
|
||||
# Help Info
|
||||
python ./backend-python/main.py -h
|
||||
```
|
||||
|
||||
## API 同時実行ストレステスト
|
||||
|
||||
```bash
|
||||
ab -p body.json -T application/json -c 20 -n 100 -l http://127.0.0.1:8000/chat/completions
|
||||
```
|
||||
|
||||
body.json:
|
||||
|
||||
```json
|
||||
{
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Hello"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## 埋め込み API の例
|
||||
|
||||
注意: v1.4.0 では、埋め込み API の品質が向上しました。生成される結果は、以前のバージョンとは互換性がありません。
|
||||
もし、embeddings API を使って知識ベースなどを生成している場合は、再生成してください。
|
||||
|
||||
LangChain を使用している場合は、`OpenAIEmbeddings(openai_api_base="http://127.0.0.1:8000", openai_api_key="sk-")`
|
||||
を使用してください
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import requests
|
||||
|
||||
|
||||
def cosine_similarity(a, b):
|
||||
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
|
||||
|
||||
|
||||
values = [
|
||||
"I am a girl",
|
||||
"我是个女孩",
|
||||
"私は女の子です",
|
||||
"广东人爱吃福建人",
|
||||
"我是个人类",
|
||||
"I am a human",
|
||||
"that dog is so cute",
|
||||
"私はねこむすめです、にゃん♪",
|
||||
"宇宙级特大事件!号外号外!"
|
||||
]
|
||||
|
||||
embeddings = []
|
||||
for v in values:
|
||||
r = requests.post("http://127.0.0.1:8000/embeddings", json={"input": v})
|
||||
embedding = r.json()["data"][0]["embedding"]
|
||||
embeddings.append(embedding)
|
||||
|
||||
compared_embedding = embeddings[0]
|
||||
|
||||
embeddings_cos_sim = [cosine_similarity(compared_embedding, e) for e in embeddings]
|
||||
|
||||
for i in np.argsort(embeddings_cos_sim)[::-1]:
|
||||
print(f"{embeddings_cos_sim[i]:.10f} - {values[i]}")
|
||||
```
|
||||
|
||||
## MIDI Input
|
||||
|
||||
Tip: You can download https://github.com/josStorer/sgm_plus and unzip it to the program's `assets/sound-font` directory
|
||||
to use it as an offline sound source. Please note that if you are compiling the program from source code, do not place
|
||||
it in the source code directory.
|
||||
|
||||
MIDIキーボードをお持ちでない場合、`Virtual Midi Controller 3 LE`
|
||||
などの仮想MIDI入力ソフトウェアを使用することができます。[loopMIDI](https://www.tobias-erichsen.de/wp-content/uploads/2020/01/loopMIDISetup_1_0_16_27.zip)
|
||||
を組み合わせて、通常のコンピュータキーボードをMIDI入力として使用できます。
|
||||
|
||||
### USB MIDI Connection
|
||||
|
||||
- USB MIDI devices are plug-and-play, and you can select your input device in the Composition page
|
||||
- 
|
||||
|
||||
### Mac MIDI Bluetooth Connection
|
||||
|
||||
- For Mac users who want to use Bluetooth input,
|
||||
please install [Bluetooth MIDI Connect](https://apps.apple.com/us/app/bluetooth-midi-connect/id1108321791), then click
|
||||
the tray icon to connect after launching,
|
||||
afterwards, you can select your input device in the Composition page.
|
||||
- 
|
||||
|
||||
### Windows MIDI Bluetooth Connection
|
||||
|
||||
- Windows seems to have implemented Bluetooth MIDI support only for UWP (Universal Windows Platform) apps. Therefore, it
|
||||
requires multiple steps to establish a connection. We need to create a local virtual MIDI device and then launch a UWP
|
||||
application. Through this UWP application, we will redirect Bluetooth MIDI input to the virtual MIDI device, and then
|
||||
this software will listen to the input from the virtual MIDI device.
|
||||
- So, first, you need to
|
||||
download [loopMIDI](https://www.tobias-erichsen.de/wp-content/uploads/2020/01/loopMIDISetup_1_0_16_27.zip)
|
||||
to create a virtual MIDI device. Click the plus sign in the bottom left corner to create the device.
|
||||
- 
|
||||
- Next, you need to download [Bluetooth LE Explorer](https://apps.microsoft.com/detail/9N0ZTKF1QD98) to discover and
|
||||
connect to Bluetooth MIDI devices. Click "Start" to search for devices, and then click "Pair" to bind the MIDI device.
|
||||
- 
|
||||
- Finally, you need to install [MIDIberry](https://apps.microsoft.com/detail/9N39720H2M05),
|
||||
This UWP application can redirect Bluetooth MIDI input to the virtual MIDI device. After launching it, double-click
|
||||
your actual Bluetooth MIDI device name in the input field, and in the output field, double-click the virtual MIDI
|
||||
device name we created earlier.
|
||||
- 
|
||||
- Now, you can select the virtual MIDI device as the input in the Composition page. Bluetooth LE Explorer no longer
|
||||
needs to run, and you can also close the loopMIDI window, it will run automatically in the background. Just keep
|
||||
MIDIberry open.
|
||||
- 
|
||||
|
||||
## 関連リポジトリ:
|
||||
|
||||
- RWKV-5-World: https://huggingface.co/BlinkDL/rwkv-5-world/tree/main
|
||||
- RWKV-4-World: https://huggingface.co/BlinkDL/rwkv-4-world/tree/main
|
||||
- RWKV-4-Raven: https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main
|
||||
- ChatRWKV: https://github.com/BlinkDL/ChatRWKV
|
||||
- RWKV-LM: https://github.com/BlinkDL/RWKV-LM
|
||||
- RWKV-LM-LoRA: https://github.com/Blealtan/RWKV-LM-LoRA
|
||||
- RWKV-v5-lora: https://github.com/JL-er/RWKV-v5-lora
|
||||
- MIDI-LLM-tokenizer: https://github.com/briansemrau/MIDI-LLM-tokenizer
|
||||
- ai00_rwkv_server: https://github.com/cgisky1980/ai00_rwkv_server
|
||||
- rwkv.cpp: https://github.com/saharNooby/rwkv.cpp
|
||||
- web-rwkv-py: https://github.com/cryscan/web-rwkv-py
|
||||
- web-rwkv: https://github.com/cryscan/web-rwkv
|
||||
|
||||
## Preview
|
||||
|
||||
### ホームページ
|
||||
|
||||

|
||||
|
||||
### チャット
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 補完
|
||||
|
||||

|
||||
|
||||
### 作曲
|
||||
|
||||
Tip: You can download https://github.com/josStorer/sgm_plus and unzip it to the program's `assets/sound-font` directory
|
||||
to use it as an offline sound source. Please note that if you are compiling the program from source code, do not place
|
||||
it in the source code directory.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### コンフィグ
|
||||
|
||||

|
||||
|
||||
### モデル管理
|
||||
|
||||

|
||||
|
||||
### ダウンロード管理
|
||||
|
||||

|
||||
|
||||
### LoRA Finetune
|
||||
|
||||

|
||||
|
||||
### 設定
|
||||
|
||||

|
||||
223
README_ZH.md
223
README_ZH.md
@ -1,5 +1,5 @@
|
||||
<p align="center">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/65c46133-7506-4b54-b64f-fe49f188afa7">
|
||||
<img src="https://github.com/josStorer/RWKV-Runner/assets/13366013/d24834b0-265d-45f5-93c0-fac1e19562af">
|
||||
</p>
|
||||
|
||||
<h1 align="center">RWKV Runner</h1>
|
||||
@ -11,17 +11,10 @@ API兼容的接口,这意味着一切ChatGPT客户端都是RWKV客户端。
|
||||
|
||||
[![license][license-image]][license-url]
|
||||
[![release][release-image]][release-url]
|
||||
[![py-version][py-version-image]][py-version-url]
|
||||
|
||||
[English](README.md) | 简体中文 | [日本語](README_JA.md)
|
||||
[English](README.md) | 简体中文
|
||||
|
||||
### 安装
|
||||
|
||||
[![Windows][Windows-image]][Windows-url]
|
||||
[![MacOS][MacOS-image]][MacOS-url]
|
||||
[![Linux][Linux-image]][Linux-url]
|
||||
|
||||
[视频演示](https://www.bilibili.com/video/BV1hM4y1v76R) | [疑难解答](https://www.bilibili.com/read/cv23921171) | [预览](#Preview) | [下载][download-url] | [懒人包](https://pan.baidu.com/s/1zdzZ_a0uM3gDqi6pXIZVAA?pwd=1111) | [简明服务部署示例](#Simple-Deploy-Example) | [服务器部署示例](https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples) | [MIDI硬件输入](#MIDI-Input)
|
||||
[预览](#Preview) | [下载][download-url]
|
||||
|
||||
[license-image]: http://img.shields.io/badge/license-MIT-blue.svg
|
||||
|
||||
@ -31,238 +24,58 @@ API兼容的接口,这意味着一切ChatGPT客户端都是RWKV客户端。
|
||||
|
||||
[release-url]: https://github.com/josStorer/RWKV-Runner/releases/latest
|
||||
|
||||
[py-version-image]: https://img.shields.io/pypi/pyversions/fastapi.svg
|
||||
|
||||
[py-version-url]: https://github.com/josStorer/RWKV-Runner/tree/master/backend-python
|
||||
|
||||
[download-url]: https://github.com/josStorer/RWKV-Runner/releases
|
||||
|
||||
[Windows-image]: https://img.shields.io/badge/-Windows-blue?logo=windows
|
||||
|
||||
[Windows-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/windows/Readme_Install.txt
|
||||
|
||||
[MacOS-image]: https://img.shields.io/badge/-MacOS-black?logo=apple
|
||||
|
||||
[MacOS-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/darwin/Readme_Install.txt
|
||||
|
||||
[Linux-image]: https://img.shields.io/badge/-Linux-black?logo=linux
|
||||
|
||||
[Linux-url]: https://github.com/josStorer/RWKV-Runner/blob/master/build/linux/Readme_Install.txt
|
||||
[download-url]: https://github.com/josStorer/RWKV-Runner/releases/download/v1.0.0/RWKV-Runner_windows_x64.exe
|
||||
|
||||
</div>
|
||||
|
||||
## 小贴士
|
||||
|
||||
- 你可以在服务器部署[backend-python](./backend-python/),然后将此程序仅用作客户端,在设置的`API URL`中填入你的服务器地址
|
||||
|
||||
- 如果你正在部署并对外提供公开服务,请通过API网关限制请求大小,避免过长的prompt提交占用资源。此外,请根据你的实际情况,限制请求的
|
||||
max_tokens 上限: https://github.com/josStorer/RWKV-Runner/blob/master/backend-python/utils/rwkv.py#L567,
|
||||
默认le=102400, 这可能导致极端情况下单个响应消耗大量资源
|
||||
|
||||
- 预设配置已经开启自定义CUDA算子加速,速度更快,且显存消耗更少。如果你遇到可能的兼容性(输出乱码)
|
||||
问题,前往配置页面,关闭`使用自定义CUDA算子加速`,或更新你的显卡驱动
|
||||
|
||||
- 如果 Windows Defender
|
||||
说这是一个病毒,你可以尝试下载[v1.3.7_win.zip](https://github.com/josStorer/RWKV-Runner/releases/download/v1.3.7/RWKV-Runner_win.zip),
|
||||
然后让其自动更新到最新版,或添加信任 (`Windows Security` -> `Virus & threat protection` -> `Manage settings` -> `Exclusions` -> `Add or remove exclusions` -> `Add an exclusion` -> `Folder` -> `RWKV-Runner`)
|
||||
|
||||
- 对于不同的任务,调整API参数会获得更好的效果,例如对于翻译任务,你可以尝试设置Temperature为1,Top_P为0.3
|
||||
|
||||
## 功能
|
||||
|
||||
- RWKV模型管理,一键启动
|
||||
- 前后端分离,如果你不想使用客户端,也允许单独部署前端服务,或后端推理服务,或具有WebUI的后端推理服务。
|
||||
[简明服务部署示例](#Simple-Deploy-Example) | [服务器部署示例](https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples)
|
||||
- 与OpenAI API兼容,一切ChatGPT客户端,都是RWKV客户端。启动模型后,打开 http://127.0.0.1:8000/docs 查看API文档
|
||||
- 与OpenAI API完全兼容,一切ChatGPT客户端,都是RWKV客户端。启动模型后,打开 http://127.0.0.1:8000/docs 查看详细内容
|
||||
- 全自动依赖安装,你只需要一个轻巧的可执行程序
|
||||
- 预设多级显存配置,几乎在各种电脑上工作良好。通过配置页面切换Strategy到WebGPU,还可以在AMD,Intel等显卡上运行
|
||||
- 自带用户友好的聊天,续写,作曲交互页面。支持聊天预设,附件上传,MIDI硬件输入及音轨编辑。
|
||||
[预览](#Preview) | [MIDI硬件输入](#MIDI-Input)
|
||||
- 内置WebUI选项,一键启动Web服务,共享硬件资源
|
||||
- 易于理解和操作的参数配置,及各类操作引导提示
|
||||
- 自带用户友好的聊天交互页面
|
||||
- 易于理解和操作的参数配置
|
||||
- 内置模型转换工具
|
||||
- 内置下载管理和远程模型检视
|
||||
- 内置一键LoRA微调 (仅限Windows)
|
||||
- 也可用作 OpenAI ChatGPT, GPT Playground, Ollama 等服务的客户端 (在设置内填写API URL和API Key)
|
||||
- 多语言本地化
|
||||
- 主题切换
|
||||
- 自动更新
|
||||
|
||||
## Simple Deploy Example
|
||||
## Todo
|
||||
|
||||
```bash
|
||||
git clone https://github.com/josStorer/RWKV-Runner
|
||||
|
||||
# 然后
|
||||
cd RWKV-Runner
|
||||
python ./backend-python/main.py #后端推理服务已启动, 调用/switch-model载入模型, 参考API文档: http://127.0.0.1:8000/docs
|
||||
|
||||
# 或者
|
||||
cd RWKV-Runner/frontend
|
||||
npm ci
|
||||
npm run build #编译前端
|
||||
cd ..
|
||||
python ./backend-python/webui_server.py #单独启动前端服务
|
||||
# 或者
|
||||
python ./backend-python/main.py --webui #同时启动前后端服务
|
||||
|
||||
# 帮助参数
|
||||
python ./backend-python/main.py -h
|
||||
```
|
||||
|
||||
## API并发压力测试
|
||||
|
||||
```bash
|
||||
ab -p body.json -T application/json -c 20 -n 100 -l http://127.0.0.1:8000/chat/completions
|
||||
```
|
||||
|
||||
body.json:
|
||||
|
||||
```json
|
||||
{
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Hello"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Embeddings API 示例
|
||||
|
||||
注意: 1.4.0 版本对embeddings API质量进行了改善,生成结果与之前的版本不兼容,如果你正在使用此API生成知识库等,请重新生成
|
||||
|
||||
如果你在用langchain, 直接使用 `OpenAIEmbeddings(openai_api_base="http://127.0.0.1:8000", openai_api_key="sk-")`
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
import requests
|
||||
|
||||
|
||||
def cosine_similarity(a, b):
|
||||
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
|
||||
|
||||
|
||||
values = [
|
||||
"I am a girl",
|
||||
"我是个女孩",
|
||||
"私は女の子です",
|
||||
"广东人爱吃福建人",
|
||||
"我是个人类",
|
||||
"I am a human",
|
||||
"that dog is so cute",
|
||||
"私はねこむすめです、にゃん♪",
|
||||
"宇宙级特大事件!号外号外!"
|
||||
]
|
||||
|
||||
embeddings = []
|
||||
for v in values:
|
||||
r = requests.post("http://127.0.0.1:8000/embeddings", json={"input": v})
|
||||
embedding = r.json()["data"][0]["embedding"]
|
||||
embeddings.append(embedding)
|
||||
|
||||
compared_embedding = embeddings[0]
|
||||
|
||||
embeddings_cos_sim = [cosine_similarity(compared_embedding, e) for e in embeddings]
|
||||
|
||||
for i in np.argsort(embeddings_cos_sim)[::-1]:
|
||||
print(f"{embeddings_cos_sim[i]:.10f} - {values[i]}")
|
||||
```
|
||||
|
||||
## MIDI Input
|
||||
|
||||
小贴士: 你可以下载 https://github.com/josStorer/sgm_plus, 并解压到程序的`assets/sound-font`目录, 以使用离线音源. 注意,
|
||||
如果你正在从源码编译程序, 请不要将其放置在源码目录中
|
||||
|
||||
如果你没有MIDI键盘, 你可以使用像 `Virtual Midi Controller 3 LE` 这样的虚拟MIDI输入软件,
|
||||
配合[loopMIDI](https://www.tobias-erichsen.de/wp-content/uploads/2020/01/loopMIDISetup_1_0_16_27.zip), 使用普通电脑键盘作为MIDI输入
|
||||
|
||||
### USB MIDI 连接
|
||||
|
||||
- USB MIDI设备是即插即用的, 你能够在作曲页面选择你的输入设备
|
||||
- 
|
||||
|
||||
### Mac MIDI 蓝牙连接
|
||||
|
||||
- 对于想要使用蓝牙输入的Mac用户,
|
||||
请安装[Bluetooth MIDI Connect](https://apps.apple.com/us/app/bluetooth-midi-connect/id1108321791), 启动后点击托盘连接,
|
||||
之后你可以在作曲页面选择你的输入设备
|
||||
- 
|
||||
|
||||
### Windows MIDI 蓝牙连接
|
||||
|
||||
- Windows似乎只为UWP实现了蓝牙MIDI支持, 因此需要多个步骤进行连接, 我们需要创建一个本地的虚拟MIDI设备, 然后启动一个UWP应用,
|
||||
通过此UWP应用将蓝牙MIDI输入重定向到虚拟MIDI设备, 然后本软件监听虚拟MIDI设备的输入
|
||||
- 因此, 首先你需要下载[loopMIDI](https://www.tobias-erichsen.de/wp-content/uploads/2020/01/loopMIDISetup_1_0_16_27.zip),
|
||||
用于创建虚拟MIDI设备, 点击左下角的加号创建设备
|
||||
- 
|
||||
- 然后, 你需要下载[Bluetooth LE Explorer](https://apps.microsoft.com/detail/9N0ZTKF1QD98), 以发现并连接蓝牙MIDI设备,
|
||||
点击Start搜索设备, 然后点击Pair绑定MIDI设备
|
||||
- 
|
||||
- 最后, 你需要安装[MIDIberry](https://apps.microsoft.com/detail/9N39720H2M05), 这个UWP应用能将MIDI蓝牙输入重定向到虚拟MIDI设备,
|
||||
启动后, 在输入栏, 双击你实际的蓝牙MIDI设备名称, 在输出栏, 双击我们先前创建的虚拟MIDI设备名称
|
||||
- 
|
||||
- 现在, 你可以在作曲页面选择虚拟MIDI设备作为输入. Bluetooth LE Explorer不再需要运行, loopMIDI窗口也可以退出, 它会自动在后台运行,
|
||||
仅保持MIDIberry打开即可
|
||||
- 
|
||||
- 模型训练功能
|
||||
- CUDA算子int8提速
|
||||
- macOS支持
|
||||
- linux支持
|
||||
|
||||
## 相关仓库:
|
||||
|
||||
- RWKV-5-World: https://huggingface.co/BlinkDL/rwkv-5-world/tree/main
|
||||
- RWKV-4-World: https://huggingface.co/BlinkDL/rwkv-4-world/tree/main
|
||||
- RWKV-4-Raven: https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main
|
||||
- ChatRWKV: https://github.com/BlinkDL/ChatRWKV
|
||||
- RWKV-LM: https://github.com/BlinkDL/RWKV-LM
|
||||
- RWKV-LM-LoRA: https://github.com/Blealtan/RWKV-LM-LoRA
|
||||
- RWKV-v5-lora: https://github.com/JL-er/RWKV-v5-lora
|
||||
- MIDI-LLM-tokenizer: https://github.com/briansemrau/MIDI-LLM-tokenizer
|
||||
- ai00_rwkv_server: https://github.com/cgisky1980/ai00_rwkv_server
|
||||
- rwkv.cpp: https://github.com/saharNooby/rwkv.cpp
|
||||
- web-rwkv-py: https://github.com/cryscan/web-rwkv-py
|
||||
- web-rwkv: https://github.com/cryscan/web-rwkv
|
||||
|
||||
## Preview
|
||||
|
||||
### 主页
|
||||
|
||||

|
||||

|
||||
|
||||
### 聊天
|
||||
|
||||
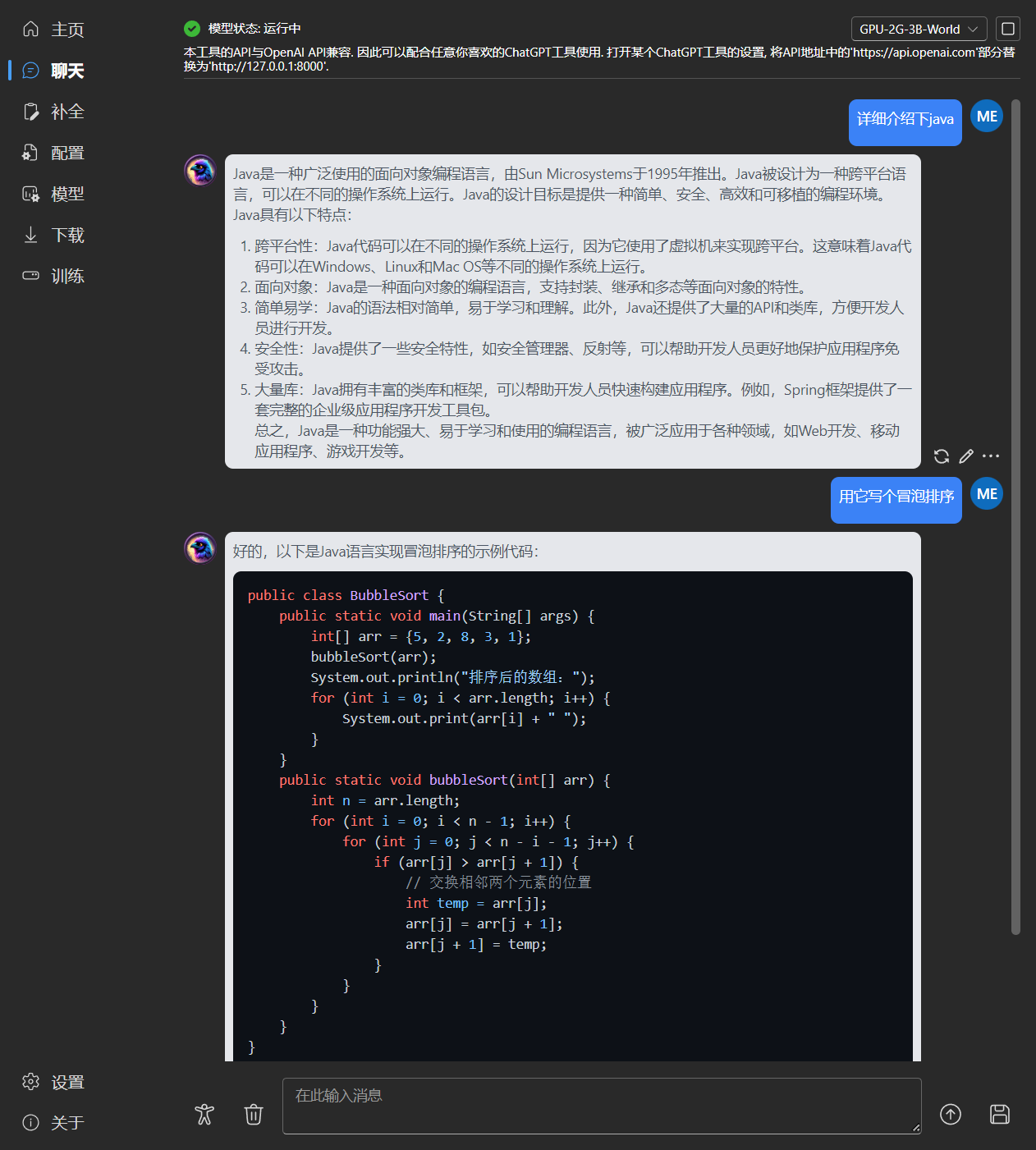
|
||||
|
||||

|
||||
|
||||
### 续写
|
||||
|
||||
|
||||
|
||||
### 作曲
|
||||
|
||||
小贴士: 你可以下载 https://github.com/josStorer/sgm_plus, 并解压到程序的`assets/sound-font`目录, 以使用离线音源. 注意,
|
||||
如果你正在从源码编译程序, 请不要将其放置在源码目录中
|
||||
|
||||

|
||||
|
||||
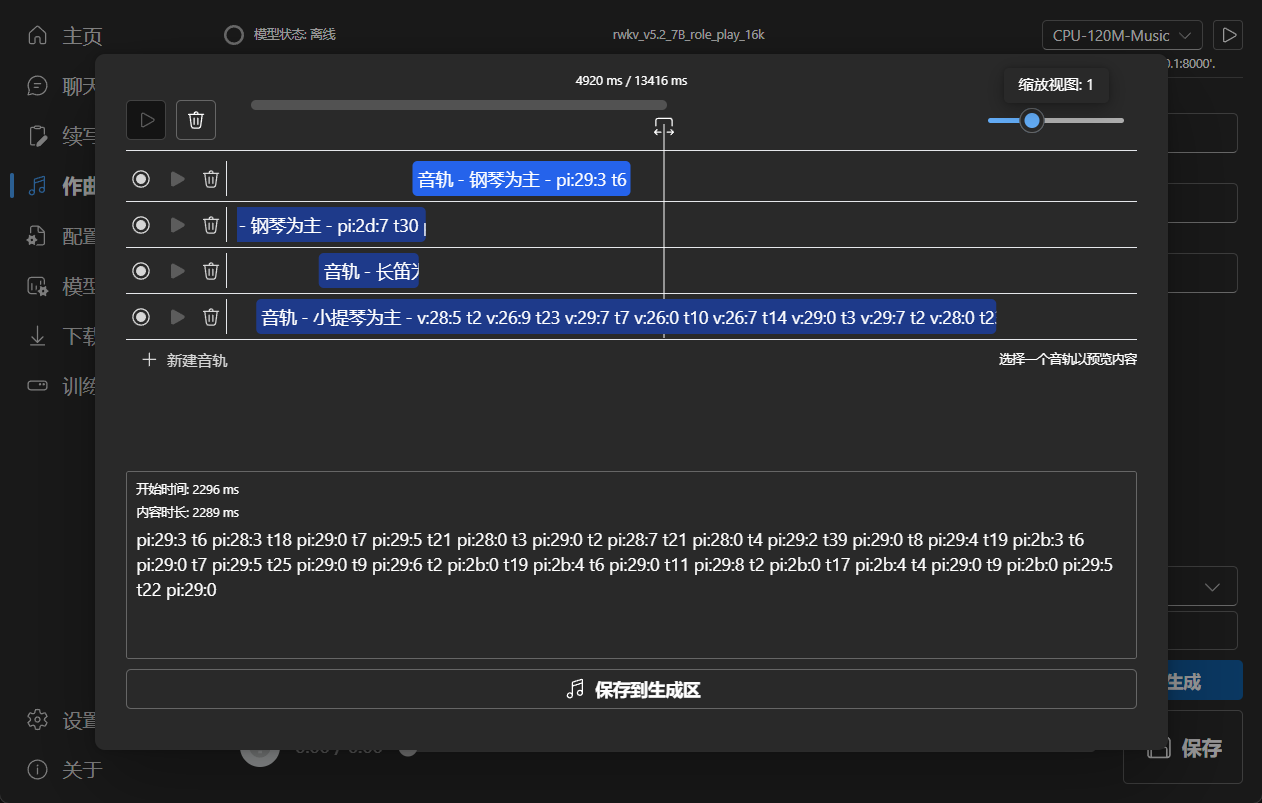
|
||||

|
||||
|
||||
### 配置
|
||||
|
||||
|
||||

|
||||
|
||||
### 模型管理
|
||||
|
||||
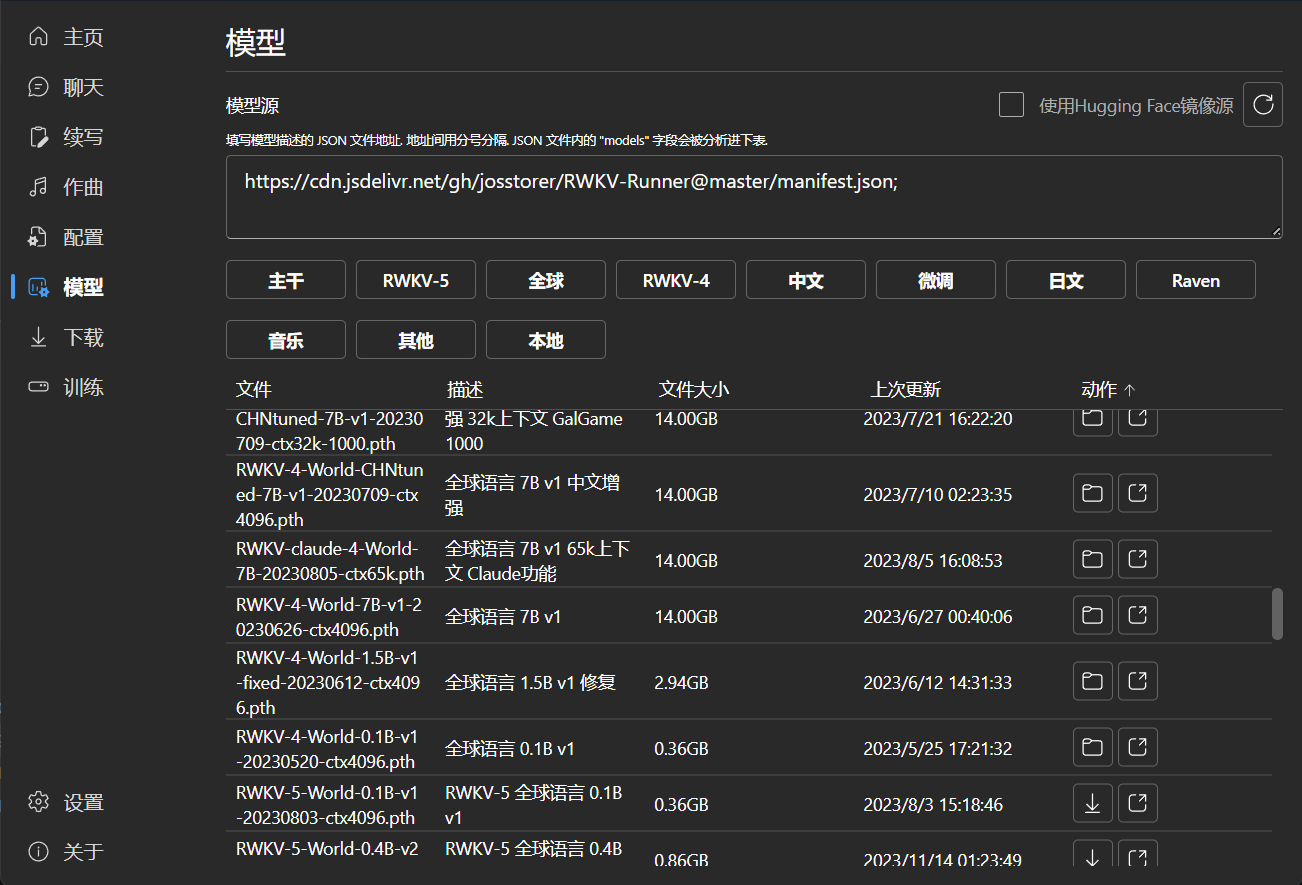
|
||||

|
||||
|
||||
### 下载管理
|
||||
|
||||
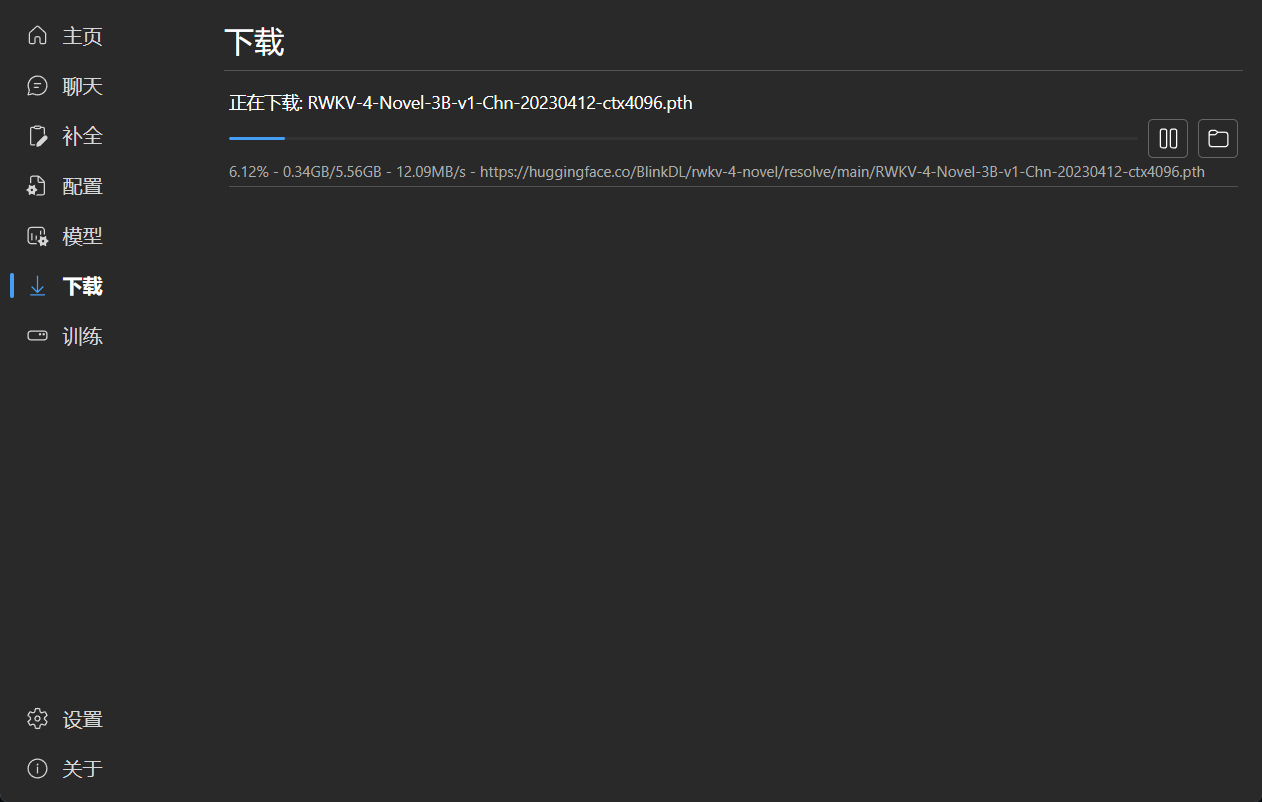
|
||||
|
||||
### LoRA微调
|
||||
|
||||
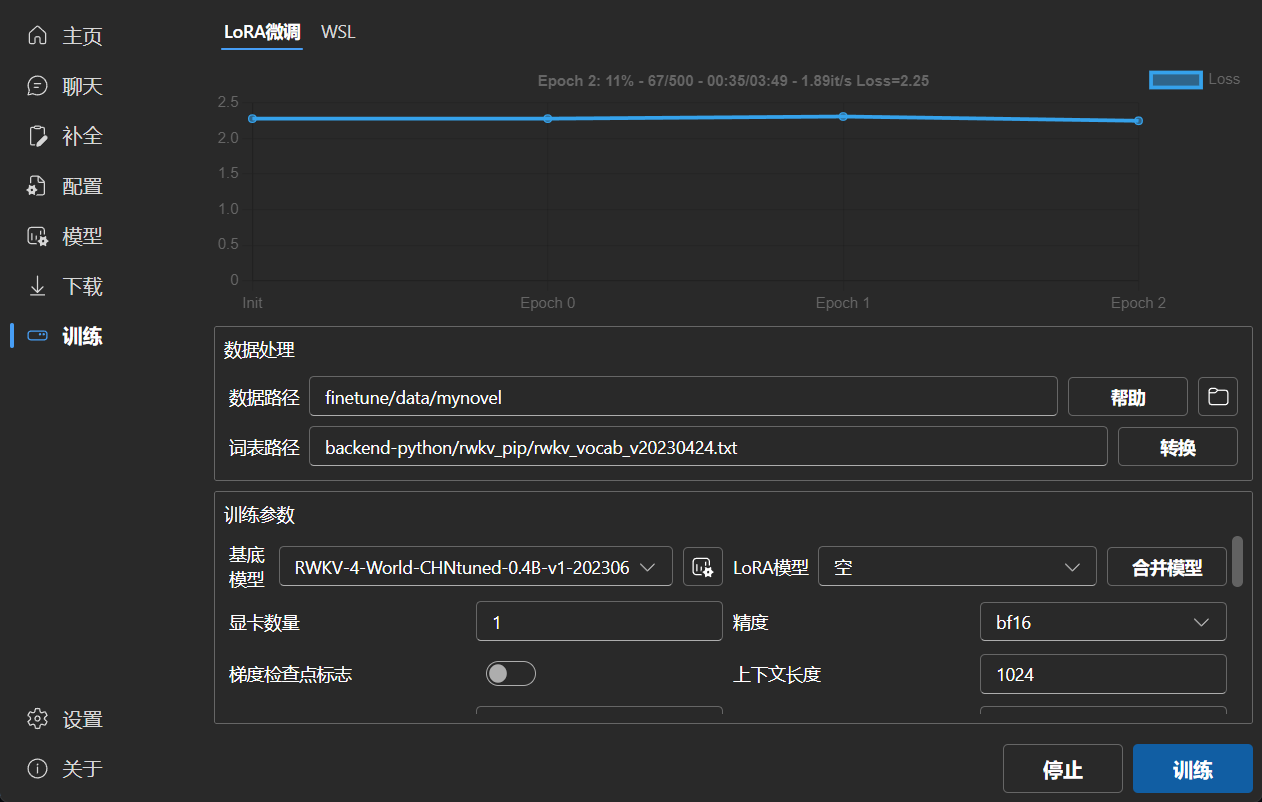
|
||||

|
||||
|
||||
### 设置
|
||||
|
||||
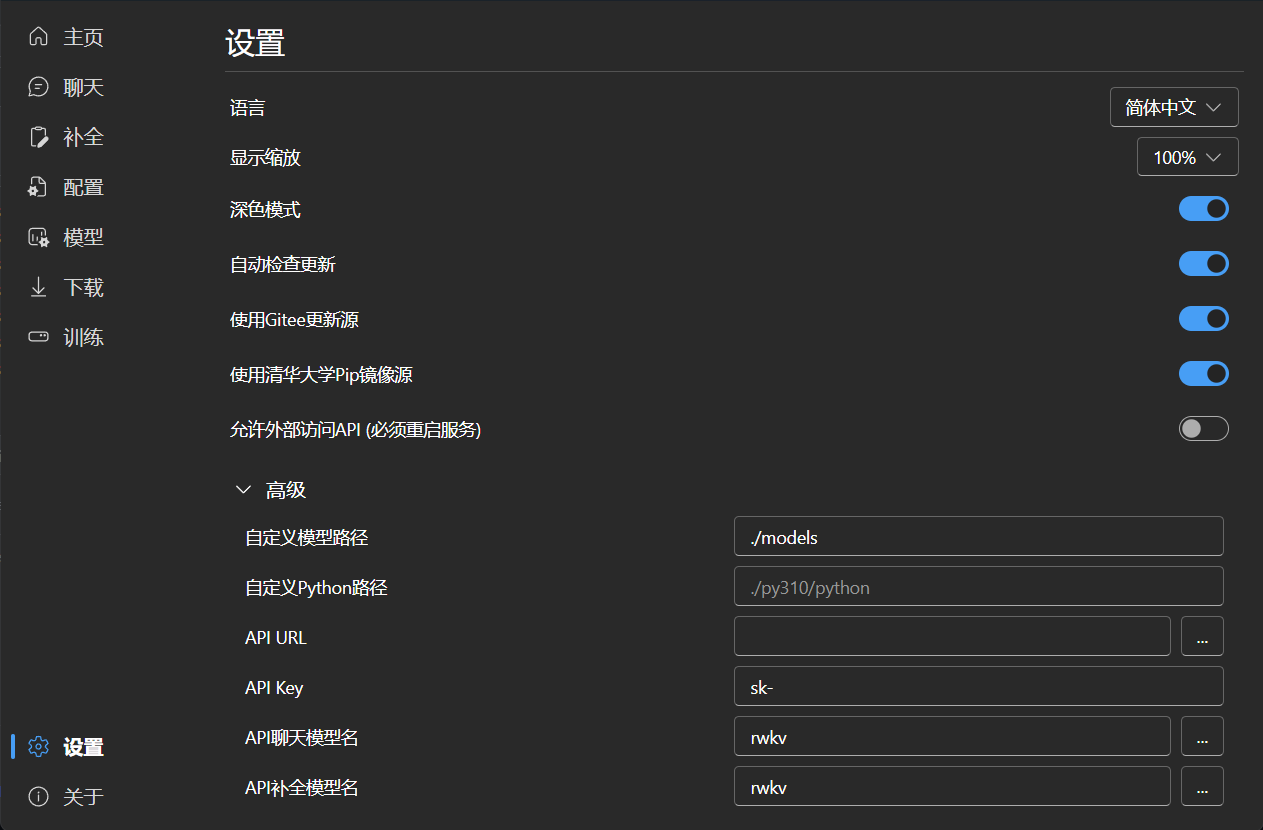
|
||||

|
||||
|
||||
Binary file not shown.
@ -1,116 +0,0 @@
|
||||
# https://github.com/magenta/magenta-js/issues/164
|
||||
|
||||
import json
|
||||
import os
|
||||
import urllib.request
|
||||
|
||||
|
||||
def get_pitches_array(min_pitch, max_pitch):
|
||||
return list(range(min_pitch, max_pitch + 1))
|
||||
|
||||
|
||||
base_url = 'https://storage.googleapis.com/magentadata/js/soundfonts'
|
||||
soundfont_path = 'sgm_plus'
|
||||
soundfont_json_url = f"{base_url}/{soundfont_path}/soundfont.json"
|
||||
|
||||
# Download soundfont.json
|
||||
soundfont_json = ""
|
||||
|
||||
if not os.path.exists('soundfont.json'):
|
||||
try:
|
||||
with urllib.request.urlopen(soundfont_json_url) as response:
|
||||
soundfont_json = response.read()
|
||||
|
||||
# Save soundfont.json
|
||||
with open('soundfont.json', 'wb') as file:
|
||||
file.write(soundfont_json)
|
||||
|
||||
except:
|
||||
print("Failed to download soundfont.json")
|
||||
|
||||
else:
|
||||
# If file exists, get it from the file system
|
||||
with open('soundfont.json', 'rb') as file:
|
||||
soundfont_json = file.read()
|
||||
|
||||
# Parse soundfont.json
|
||||
soundfont_data = json.loads(soundfont_json)
|
||||
|
||||
if soundfont_data is not None:
|
||||
|
||||
# Iterate over each instrument
|
||||
for instrument_id, instrument_name in soundfont_data['instruments'].items():
|
||||
|
||||
if not os.path.isdir(instrument_name):
|
||||
|
||||
# Create instrument directory if it doesn't exist
|
||||
os.makedirs(instrument_name)
|
||||
|
||||
instrument_json = ""
|
||||
|
||||
instrument_path = f"{soundfont_path}/{instrument_name}"
|
||||
|
||||
if not os.path.exists(f"{instrument_name}/instrument.json"):
|
||||
|
||||
# Download instrument.json
|
||||
instrument_json_url = f"{base_url}/{instrument_path}/instrument.json"
|
||||
|
||||
try:
|
||||
with urllib.request.urlopen(instrument_json_url) as response:
|
||||
instrument_json = response.read()
|
||||
|
||||
# Save instrument.json
|
||||
with open(f"{instrument_name}/instrument.json", 'wb') as file:
|
||||
file.write(instrument_json)
|
||||
|
||||
except:
|
||||
print(f"Failed to download {instrument_name}/instrument.json")
|
||||
|
||||
else:
|
||||
|
||||
# If file exists, get it from the file system
|
||||
with open(f"{instrument_name}/instrument.json", 'rb') as file:
|
||||
instrument_json = file.read()
|
||||
|
||||
# Parse instrument.json
|
||||
instrument_data = json.loads(instrument_json)
|
||||
|
||||
if instrument_data is not None:
|
||||
# Iterate over each pitch and velocity
|
||||
for velocity in instrument_data['velocities']:
|
||||
|
||||
pitches = get_pitches_array(instrument_data['minPitch'], instrument_data['maxPitch'])
|
||||
|
||||
for pitch in pitches:
|
||||
|
||||
# Create the file name
|
||||
file_name = f'p{pitch}_v{velocity}.mp3'
|
||||
|
||||
# Check if the file already exists
|
||||
if os.path.exists(f"{instrument_name}/{file_name}"):
|
||||
pass
|
||||
#print(f"Skipping {instrument_name}/{file_name} - File already exists")
|
||||
|
||||
else:
|
||||
|
||||
# Download pitch/velocity file
|
||||
file_url = f"{base_url}/{instrument_path}/{file_name}"
|
||||
|
||||
try:
|
||||
with urllib.request.urlopen(file_url) as response:
|
||||
file_contents = response.read()
|
||||
|
||||
# Save pitch/velocity file
|
||||
with open(f"{instrument_name}/{file_name}", 'wb') as file:
|
||||
file.write(file_contents)
|
||||
|
||||
print(f"Downloaded {instrument_name}/{file_name}")
|
||||
|
||||
except:
|
||||
print(f"Failed to download {instrument_name}/{file_name}")
|
||||
|
||||
else:
|
||||
print(f"Failed to parse instrument.json for {instrument_name}")
|
||||
|
||||
else:
|
||||
print('Failed to parse soundfont.json')
|
||||
@ -1,134 +0,0 @@
|
||||
{
|
||||
"name": "sgm_plus",
|
||||
"instruments": {
|
||||
"0": "acoustic_grand_piano",
|
||||
"1": "bright_acoustic_piano",
|
||||
"2": "electric_grand_piano",
|
||||
"3": "honkytonk_piano",
|
||||
"4": "electric_piano_1",
|
||||
"5": "electric_piano_2",
|
||||
"6": "harpsichord",
|
||||
"7": "clavichord",
|
||||
"8": "celesta",
|
||||
"9": "glockenspiel",
|
||||
"10": "music_box",
|
||||
"11": "vibraphone",
|
||||
"12": "marimba",
|
||||
"13": "xylophone",
|
||||
"14": "tubular_bells",
|
||||
"15": "dulcimer",
|
||||
"16": "drawbar_organ",
|
||||
"17": "percussive_organ",
|
||||
"18": "rock_organ",
|
||||
"19": "church_organ",
|
||||
"20": "reed_organ",
|
||||
"21": "accordion",
|
||||
"22": "harmonica",
|
||||
"23": "tango_accordion",
|
||||
"24": "acoustic_guitar_nylon",
|
||||
"25": "acoustic_guitar_steel",
|
||||
"26": "electric_guitar_jazz",
|
||||
"27": "electric_guitar_clean",
|
||||
"28": "electric_guitar_muted",
|
||||
"29": "overdriven_guitar",
|
||||
"30": "distortion_guitar",
|
||||
"31": "guitar_harmonics",
|
||||
"32": "acoustic_bass",
|
||||
"33": "electric_bass_finger",
|
||||
"34": "electric_bass_pick",
|
||||
"35": "fretless_bass",
|
||||
"36": "slap_bass_1",
|
||||
"37": "slap_bass_2",
|
||||
"38": "synth_bass_1",
|
||||
"39": "synth_bass_2",
|
||||
"40": "violin",
|
||||
"41": "viola",
|
||||
"42": "cello",
|
||||
"43": "contrabass",
|
||||
"44": "tremolo_strings",
|
||||
"45": "pizzicato_strings",
|
||||
"46": "orchestral_harp",
|
||||
"47": "timpani",
|
||||
"48": "string_ensemble_1",
|
||||
"49": "string_ensemble_2",
|
||||
"50": "synthstrings_1",
|
||||
"51": "synthstrings_2",
|
||||
"52": "choir_aahs",
|
||||
"53": "voice_oohs",
|
||||
"54": "synth_voice",
|
||||
"55": "orchestra_hit",
|
||||
"56": "trumpet",
|
||||
"57": "trombone",
|
||||
"58": "tuba",
|
||||
"59": "muted_trumpet",
|
||||
"60": "french_horn",
|
||||
"61": "brass_section",
|
||||
"62": "synthbrass_1",
|
||||
"63": "synthbrass_2",
|
||||
"64": "soprano_sax",
|
||||
"65": "alto_sax",
|
||||
"66": "tenor_sax",
|
||||
"67": "baritone_sax",
|
||||
"68": "oboe",
|
||||
"69": "english_horn",
|
||||
"70": "bassoon",
|
||||
"71": "clarinet",
|
||||
"72": "piccolo",
|
||||
"73": "flute",
|
||||
"74": "recorder",
|
||||
"75": "pan_flute",
|
||||
"76": "blown_bottle",
|
||||
"77": "shakuhachi",
|
||||
"78": "whistle",
|
||||
"79": "ocarina",
|
||||
"80": "lead_1_square",
|
||||
"81": "lead_2_sawtooth",
|
||||
"82": "lead_3_calliope",
|
||||
"83": "lead_4_chiff",
|
||||
"84": "lead_5_charang",
|
||||
"85": "lead_6_voice",
|
||||
"86": "lead_7_fifths",
|
||||
"87": "lead_8_bass_lead",
|
||||
"88": "pad_1_new_age",
|
||||
"89": "pad_2_warm",
|
||||
"90": "pad_3_polysynth",
|
||||
"91": "pad_4_choir",
|
||||
"92": "pad_5_bowed",
|
||||
"93": "pad_6_metallic",
|
||||
"94": "pad_7_halo",
|
||||
"95": "pad_8_sweep",
|
||||
"96": "fx_1_rain",
|
||||
"97": "fx_2_soundtrack",
|
||||
"98": "fx_3_crystal",
|
||||
"99": "fx_4_atmosphere",
|
||||
"100": "fx_5_brightness",
|
||||
"101": "fx_6_goblins",
|
||||
"102": "fx_7_echoes",
|
||||
"103": "fx_8_scifi",
|
||||
"104": "sitar",
|
||||
"105": "banjo",
|
||||
"106": "shamisen",
|
||||
"107": "koto",
|
||||
"108": "kalimba",
|
||||
"109": "bag_pipe",
|
||||
"110": "fiddle",
|
||||
"111": "shanai",
|
||||
"112": "tinkle_bell",
|
||||
"113": "agogo",
|
||||
"114": "steel_drums",
|
||||
"115": "woodblock",
|
||||
"116": "taiko_drum",
|
||||
"117": "melodic_tom",
|
||||
"118": "synth_drum",
|
||||
"119": "reverse_cymbal",
|
||||
"120": "guitar_fret_noise",
|
||||
"121": "breath_noise",
|
||||
"122": "seashore",
|
||||
"123": "bird_tweet",
|
||||
"124": "telephone_ring",
|
||||
"125": "helicopter",
|
||||
"126": "applause",
|
||||
"127": "gunshot",
|
||||
"drums": "percussion"
|
||||
}
|
||||
}
|
||||
@ -1,469 +0,0 @@
|
||||
#!/usr/bin/env ruby
|
||||
#
|
||||
# JavaScript Soundfont Builder for MIDI.js
|
||||
# Author: 0xFE <mohit@muthanna.com>
|
||||
# edited by Valentijn Nieman <valentijnnieman@gmail.com>
|
||||
#
|
||||
# Requires:
|
||||
#
|
||||
# FluidSynth
|
||||
# Lame
|
||||
# Ruby Gems: midilib parallel
|
||||
#
|
||||
# $ brew install fluidsynth lame (on OSX)
|
||||
# $ gem install midilib parallel
|
||||
#
|
||||
# You'll need to download a GM soundbank to generate audio.
|
||||
#
|
||||
# Usage:
|
||||
#
|
||||
# 1) Install the above dependencies.
|
||||
# 2) Edit BUILD_DIR, SOUNDFONT, and INSTRUMENTS as required.
|
||||
# 3) Run without any argument.
|
||||
|
||||
require 'base64'
|
||||
require 'digest/sha1'
|
||||
require 'etc'
|
||||
require 'fileutils'
|
||||
require 'midilib'
|
||||
require 'parallel'
|
||||
require 'zlib'
|
||||
require 'json'
|
||||
|
||||
include FileUtils
|
||||
|
||||
BUILD_DIR = "./sound-font" # Output path
|
||||
SOUNDFONT = "./default_sound_font.sf2" # Soundfont file path
|
||||
|
||||
# This script will generate MIDI.js-compatible instrument JS files for
|
||||
# all instruments in the below array. Add or remove as necessary.
|
||||
INSTRUMENTS = [
|
||||
0,
|
||||
1,
|
||||
2,
|
||||
3,
|
||||
4,
|
||||
5,
|
||||
6,
|
||||
7,
|
||||
8,
|
||||
9,
|
||||
10,
|
||||
11,
|
||||
12,
|
||||
13,
|
||||
14,
|
||||
15,
|
||||
16,
|
||||
17,
|
||||
18,
|
||||
19,
|
||||
20,
|
||||
21,
|
||||
22,
|
||||
23,
|
||||
24,
|
||||
25,
|
||||
26,
|
||||
27,
|
||||
28,
|
||||
29,
|
||||
30,
|
||||
31,
|
||||
32,
|
||||
33,
|
||||
34,
|
||||
35,
|
||||
36,
|
||||
37,
|
||||
38,
|
||||
39,
|
||||
40,
|
||||
41,
|
||||
42,
|
||||
43,
|
||||
44,
|
||||
45,
|
||||
46,
|
||||
47,
|
||||
48,
|
||||
49,
|
||||
50,
|
||||
51,
|
||||
52,
|
||||
53,
|
||||
54,
|
||||
55,
|
||||
56,
|
||||
57,
|
||||
58,
|
||||
59,
|
||||
60,
|
||||
61,
|
||||
62,
|
||||
63,
|
||||
64,
|
||||
65,
|
||||
66,
|
||||
67,
|
||||
68,
|
||||
69,
|
||||
70,
|
||||
71,
|
||||
72,
|
||||
73,
|
||||
74,
|
||||
75,
|
||||
76,
|
||||
77,
|
||||
78,
|
||||
79,
|
||||
80,
|
||||
81,
|
||||
82,
|
||||
83,
|
||||
84,
|
||||
85,
|
||||
86,
|
||||
87,
|
||||
88,
|
||||
89,
|
||||
90,
|
||||
91,
|
||||
92,
|
||||
93,
|
||||
94,
|
||||
95,
|
||||
96,
|
||||
97,
|
||||
98,
|
||||
99,
|
||||
100,
|
||||
101,
|
||||
102,
|
||||
103,
|
||||
104,
|
||||
105,
|
||||
106,
|
||||
107,
|
||||
108,
|
||||
109,
|
||||
110,
|
||||
111,
|
||||
112,
|
||||
113,
|
||||
114,
|
||||
115,
|
||||
116,
|
||||
117,
|
||||
118,
|
||||
119,
|
||||
120,
|
||||
121,
|
||||
122,
|
||||
123,
|
||||
124,
|
||||
125,
|
||||
126,
|
||||
127
|
||||
]
|
||||
|
||||
# It was found that midilib uses names that are incompatible with MIDI.js
|
||||
# For example, midilib uses "SynthBrass 1" -> https://github.com/jimm/midilib/blob/6c8e481ae72cd9f00a38eb3700ddfca6b549f153/lib/midilib/consts.rb#L280
|
||||
# and the MIDI association uses "SynthBrass 1" -> https://www.midi.org/specifications-old/item/gm-level-1-sound-set
|
||||
# but the MIDI.js calls this "Synth Brass 1" -> https://github.com/mudcube/MIDI.js/blob/a8a84257afa70721ae462448048a87301fc1554a/js/midi/gm.js#L44
|
||||
# there are others like "Bag pipe" vs "Bagpipe", etc.
|
||||
# here, we use the MIDI.js definitions because that is how most users will interact with the generated soundfonts.
|
||||
MIDIJS_PATCH_NAMES = [
|
||||
"Acoustic Grand Piano",
|
||||
"Bright Acoustic Piano",
|
||||
"Electric Grand Piano",
|
||||
"Honky-tonk Piano",
|
||||
"Electric Piano 1",
|
||||
"Electric Piano 2",
|
||||
"Harpsichord",
|
||||
"Clavinet",
|
||||
"Celesta",
|
||||
"Glockenspiel",
|
||||
"Music Box",
|
||||
"Vibraphone",
|
||||
"Marimba",
|
||||
"Xylophone",
|
||||
"Tubular Bells",
|
||||
"Dulcimer",
|
||||
"Drawbar Organ",
|
||||
"Percussive Organ",
|
||||
"Rock Organ",
|
||||
"Church Organ",
|
||||
"Reed Organ",
|
||||
"Accordion",
|
||||
"Harmonica",
|
||||
"Tango Accordion",
|
||||
"Acoustic Guitar (nylon)",
|
||||
"Acoustic Guitar (steel)",
|
||||
"Electric Guitar (jazz)",
|
||||
"Electric Guitar (clean)",
|
||||
"Electric Guitar (muted)",
|
||||
"Overdriven Guitar",
|
||||
"Distortion Guitar",
|
||||
"Guitar Harmonics",
|
||||
"Acoustic Bass",
|
||||
"Electric Bass (finger)",
|
||||
"Electric Bass (pick)",
|
||||
"Fretless Bass",
|
||||
"Slap Bass 1",
|
||||
"Slap Bass 2",
|
||||
"Synth Bass 1",
|
||||
"Synth Bass 2",
|
||||
"Violin",
|
||||
"Viola",
|
||||
"Cello",
|
||||
"Contrabass",
|
||||
"Tremolo Strings",
|
||||
"Pizzicato Strings",
|
||||
"Orchestral Harp",
|
||||
"Timpani",
|
||||
"String Ensemble 1",
|
||||
"String Ensemble 2",
|
||||
"Synth Strings 1",
|
||||
"Synth Strings 2",
|
||||
"Choir Aahs",
|
||||
"Voice Oohs",
|
||||
"Synth Choir",
|
||||
"Orchestra Hit",
|
||||
"Trumpet",
|
||||
"Trombone",
|
||||
"Tuba",
|
||||
"Muted Trumpet",
|
||||
"French Horn",
|
||||
"Brass Section",
|
||||
"Synth Brass 1",
|
||||
"Synth Brass 2",
|
||||
"Soprano Sax",
|
||||
"Alto Sax",
|
||||
"Tenor Sax",
|
||||
"Baritone Sax",
|
||||
"Oboe",
|
||||
"English Horn",
|
||||
"Bassoon",
|
||||
"Clarinet",
|
||||
"Piccolo",
|
||||
"Flute",
|
||||
"Recorder",
|
||||
"Pan Flute",
|
||||
"Blown Bottle",
|
||||
"Shakuhachi",
|
||||
"Whistle",
|
||||
"Ocarina",
|
||||
"Lead 1 (square)",
|
||||
"Lead 2 (sawtooth)",
|
||||
"Lead 3 (calliope)",
|
||||
"Lead 4 (chiff)",
|
||||
"Lead 5 (charang)",
|
||||
"Lead 6 (voice)",
|
||||
"Lead 7 (fifths)",
|
||||
"Lead 8 (bass + lead)",
|
||||
"Pad 1 (new age)",
|
||||
"Pad 2 (warm)",
|
||||
"Pad 3 (polysynth)",
|
||||
"Pad 4 (choir)",
|
||||
"Pad 5 (bowed)",
|
||||
"Pad 6 (metallic)",
|
||||
"Pad 7 (halo)",
|
||||
"Pad 8 (sweep)",
|
||||
"FX 1 (rain)",
|
||||
"FX 2 (soundtrack)",
|
||||
"FX 3 (crystal)",
|
||||
"FX 4 (atmosphere)",
|
||||
"FX 5 (brightness)",
|
||||
"FX 6 (goblins)",
|
||||
"FX 7 (echoes)",
|
||||
"FX 8 (sci-fi)",
|
||||
"Sitar",
|
||||
"Banjo",
|
||||
"Shamisen",
|
||||
"Koto",
|
||||
"Kalimba",
|
||||
"Bagpipe",
|
||||
"Fiddle",
|
||||
"Shanai",
|
||||
"Tinkle Bell",
|
||||
"Agogo",
|
||||
"Steel Drums",
|
||||
"Woodblock",
|
||||
"Taiko Drum",
|
||||
"Melodic Tom",
|
||||
"Synth Drum",
|
||||
"Reverse Cymbal",
|
||||
"Guitar Fret Noise",
|
||||
"Breath Noise",
|
||||
"Seashore",
|
||||
"Bird Tweet",
|
||||
"Telephone Ring",
|
||||
"Helicopter",
|
||||
"Applause",
|
||||
"Gunshot"
|
||||
]
|
||||
|
||||
# The encoders and tools are expected in your PATH. You can supply alternate
|
||||
# paths by changing the constants below.
|
||||
LAME = "lame" # `which lame`.chomp
|
||||
FLUIDSYNTH = "fluidsynth" # `which fluidsynth`.chomp
|
||||
|
||||
puts "Building the following instruments using font: " + SOUNDFONT
|
||||
|
||||
# Display instrument names.
|
||||
INSTRUMENTS.each do |i|
|
||||
puts " #{i}: " + MIDIJS_PATCH_NAMES[i]
|
||||
end
|
||||
|
||||
puts
|
||||
puts "Using MP3 encoder: " + LAME
|
||||
puts "Using FluidSynth encoder: " + FLUIDSYNTH
|
||||
puts
|
||||
puts "Sending output to: " + BUILD_DIR
|
||||
puts
|
||||
|
||||
raise "Can't find soundfont: #{SOUNDFONT}" unless File.exist? SOUNDFONT
|
||||
raise "Can't find 'lame' command" if LAME.empty?
|
||||
raise "Can't find 'fluidsynth' command" if FLUIDSYNTH.empty?
|
||||
raise "Output directory does not exist: #{BUILD_DIR}" unless File.exist?(BUILD_DIR)
|
||||
|
||||
puts "Hit return to begin."
|
||||
$stdin.readline
|
||||
|
||||
NOTES = {
|
||||
"C" => 0,
|
||||
"Db" => 1,
|
||||
"D" => 2,
|
||||
"Eb" => 3,
|
||||
"E" => 4,
|
||||
"F" => 5,
|
||||
"Gb" => 6,
|
||||
"G" => 7,
|
||||
"Ab" => 8,
|
||||
"A" => 9,
|
||||
"Bb" => 10,
|
||||
"B" => 11
|
||||
}
|
||||
|
||||
MIDI_C0 = 12
|
||||
VELOCITY = 100
|
||||
DURATION = Integer(3000)
|
||||
TEMP_FILE = "#{BUILD_DIR}/%s%stemp.midi"
|
||||
FLUIDSYNTH_RAW = "%s.wav"
|
||||
|
||||
def deflate(string, level)
|
||||
z = Zlib::Deflate.new(level)
|
||||
dst = z.deflate(string, Zlib::FINISH)
|
||||
z.close
|
||||
dst
|
||||
end
|
||||
|
||||
def note_to_int(note, octave)
|
||||
value = NOTES[note]
|
||||
increment = MIDI_C0 * octave
|
||||
return value + increment
|
||||
end
|
||||
|
||||
def int_to_note(value)
|
||||
raise "Bad Value" if value < MIDI_C0
|
||||
reverse_notes = NOTES.invert
|
||||
value -= MIDI_C0
|
||||
octave = value / 12
|
||||
note = value % 12
|
||||
return { key: reverse_notes[note],
|
||||
octave: octave }
|
||||
end
|
||||
|
||||
# Run a quick table validation
|
||||
MIDI_C0.upto(100) do |x|
|
||||
note = int_to_note x
|
||||
#raise "Broken table" unless note_to_int(note[:key], note[:octave]) == x
|
||||
end
|
||||
|
||||
def generate_midi(program, note_value, file)
|
||||
include MIDI
|
||||
seq = Sequence.new()
|
||||
track = Track.new(seq)
|
||||
|
||||
seq.tracks << track
|
||||
track.events << ProgramChange.new(0, Integer(program))
|
||||
track.events << NoteOn.new(0, note_value, VELOCITY, 0) # channel, note, velocity, delta
|
||||
track.events << NoteOff.new(0, note_value, VELOCITY, DURATION)
|
||||
|
||||
File.open(file, 'wb') { | file | seq.write(file) }
|
||||
end
|
||||
|
||||
def run_command(cmd)
|
||||
puts "Running: " + cmd
|
||||
`#{cmd}`
|
||||
end
|
||||
|
||||
def midi_to_audio(source, target)
|
||||
run_command "#{FLUIDSYNTH} -C no -R no -g 0.5 -F #{target} #{SOUNDFONT} #{source}"
|
||||
run_command "#{LAME} -v -b 8 -B 64 #{target}"
|
||||
rm target
|
||||
end
|
||||
|
||||
def open_js_file(instrument_key, type)
|
||||
js_file = File.open("#{BUILD_DIR}/#{instrument_key}-#{type}.js", "w")
|
||||
js_file.write(
|
||||
"""
|
||||
if (typeof(MIDI) === 'undefined') var MIDI = {};
|
||||
if (typeof(MIDI.Soundfont) === 'undefined') MIDI.Soundfont = {};
|
||||
MIDI.Soundfont.#{instrument_key} = {
|
||||
""")
|
||||
return js_file
|
||||
end
|
||||
|
||||
def close_js_file(file)
|
||||
file.write("\n}\n")
|
||||
file.close
|
||||
end
|
||||
|
||||
def base64js(note, file, type)
|
||||
output = '"' + note + '": '
|
||||
output += '"' + "data:audio/#{type};base64,"
|
||||
output += Base64.strict_encode64(File.read(file)) + '"'
|
||||
return output
|
||||
end
|
||||
|
||||
def generate_audio(program)
|
||||
instrument = MIDIJS_PATCH_NAMES[program]
|
||||
instrument_key = instrument.downcase.gsub(/[^a-z0-9 ]/, "").gsub(/[ ]/, "_")
|
||||
|
||||
puts "Generating audio for: " + instrument + "(#{instrument_key})"
|
||||
|
||||
mkdir_p "#{BUILD_DIR}/#{instrument_key}"
|
||||
|
||||
|
||||
note_to_int("A", 0).upto(note_to_int("C", 8)) do |note_value|
|
||||
output_name = "p#{note_value}_v#{VELOCITY}"
|
||||
output_path_prefix = BUILD_DIR + "/#{instrument_key}" + output_name
|
||||
|
||||
puts "Generating: #{output_name}"
|
||||
temp_file_specific = TEMP_FILE % [output_name, instrument_key]
|
||||
generate_midi(program, note_value, temp_file_specific)
|
||||
midi_to_audio(temp_file_specific, output_path_prefix + ".wav")
|
||||
|
||||
mv output_path_prefix + ".mp3", "#{BUILD_DIR}/#{instrument_key}/#{output_name}.mp3"
|
||||
rm temp_file_specific
|
||||
end
|
||||
|
||||
tempHash = {
|
||||
"name" => instrument_key,
|
||||
"minPitch" => 0,
|
||||
"maxPitch" => 127,
|
||||
"durationSeconds" => 3.0,
|
||||
"releaseSeconds" => 1.0,
|
||||
"percussive": false,
|
||||
"velocities": [100]
|
||||
}
|
||||
|
||||
File.open("#{BUILD_DIR}/#{instrument_key}/instrument.json", "w") do |f|
|
||||
f.write(tempHash.to_json)
|
||||
end
|
||||
end
|
||||
|
||||
Parallel.each(INSTRUMENTS, :in_processes=>Etc.nprocessors){|i| generate_audio(i)}
|
||||
@ -1,39 +1,19 @@
|
||||
package backend_golang
|
||||
|
||||
import (
|
||||
"archive/zip"
|
||||
"bufio"
|
||||
"bytes"
|
||||
"context"
|
||||
"errors"
|
||||
"io"
|
||||
"log"
|
||||
"net"
|
||||
"net/http"
|
||||
"net/http/httputil"
|
||||
"net/url"
|
||||
"os"
|
||||
"os/exec"
|
||||
"path/filepath"
|
||||
"runtime"
|
||||
"strings"
|
||||
"syscall"
|
||||
"time"
|
||||
|
||||
"github.com/fsnotify/fsnotify"
|
||||
"github.com/minio/selfupdate"
|
||||
wruntime "github.com/wailsapp/wails/v2/pkg/runtime"
|
||||
)
|
||||
|
||||
// App struct
|
||||
type App struct {
|
||||
ctx context.Context
|
||||
HasConfigData bool
|
||||
ConfigData map[string]any
|
||||
Dev bool
|
||||
proxyPort int
|
||||
exDir string
|
||||
cmdPrefix string
|
||||
ctx context.Context
|
||||
}
|
||||
|
||||
// NewApp creates a new App application struct
|
||||
@ -41,180 +21,12 @@ func NewApp() *App {
|
||||
return &App{}
|
||||
}
|
||||
|
||||
func (a *App) newFetchProxy() {
|
||||
go func() {
|
||||
handler := func(w http.ResponseWriter, r *http.Request) {
|
||||
if r.Method == "OPTIONS" {
|
||||
w.Header().Set("Access-Control-Allow-Methods", "GET, POST, OPTIONS")
|
||||
w.Header().Set("Access-Control-Allow-Headers", "*")
|
||||
w.Header().Set("Access-Control-Allow-Origin", "*")
|
||||
return
|
||||
}
|
||||
proxy := &httputil.ReverseProxy{
|
||||
ModifyResponse: func(res *http.Response) error {
|
||||
res.Header.Set("Access-Control-Allow-Origin", "*")
|
||||
return nil
|
||||
},
|
||||
Director: func(req *http.Request) {
|
||||
realTarget := req.Header.Get("Real-Target")
|
||||
if realTarget != "" {
|
||||
realTarget, err := url.PathUnescape(realTarget)
|
||||
if err != nil {
|
||||
log.Printf("Error decoding target URL: %v\n", err)
|
||||
return
|
||||
}
|
||||
target, err := url.Parse(realTarget)
|
||||
if err != nil {
|
||||
log.Printf("Error parsing target URL: %v\n", err)
|
||||
return
|
||||
}
|
||||
req.Header.Set("Accept", "*/*")
|
||||
req.Header.Del("Origin")
|
||||
req.Header.Del("Referer")
|
||||
req.Header.Del("Real-Target")
|
||||
req.Header.Del("Sec-Fetch-Dest")
|
||||
req.Header.Del("Sec-Fetch-Mode")
|
||||
req.Header.Del("Sec-Fetch-Site")
|
||||
req.URL.Scheme = target.Scheme
|
||||
req.URL.Host = target.Host
|
||||
req.URL.Path = target.Path
|
||||
req.URL.RawQuery = url.PathEscape(target.RawQuery)
|
||||
log.Println("Proxying to", realTarget)
|
||||
} else {
|
||||
log.Println("Real-Target header is missing")
|
||||
}
|
||||
},
|
||||
}
|
||||
proxy.ServeHTTP(w, r)
|
||||
}
|
||||
http.HandleFunc("/", handler)
|
||||
listener, err := net.Listen("tcp", "127.0.0.1:0")
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
a.proxyPort = listener.Addr().(*net.TCPAddr).Port
|
||||
|
||||
http.Serve(listener, nil)
|
||||
}()
|
||||
}
|
||||
|
||||
// startup is called when the app starts. The context is saved
|
||||
// so we can call the runtime methods
|
||||
func (a *App) OnStartup(ctx context.Context) {
|
||||
a.ctx = ctx
|
||||
a.exDir = ""
|
||||
a.cmdPrefix = ""
|
||||
|
||||
ex, err := os.Executable()
|
||||
if err == nil {
|
||||
if runtime.GOOS == "darwin" {
|
||||
a.exDir = filepath.Dir(ex) + "/../../../"
|
||||
a.cmdPrefix = "cd " + a.exDir + " && "
|
||||
} else {
|
||||
a.exDir = filepath.Dir(ex) + "/"
|
||||
a.cmdPrefix = "cd " + a.exDir + " && "
|
||||
}
|
||||
if a.Dev {
|
||||
a.exDir = ""
|
||||
} else {
|
||||
os.Chdir(a.exDir)
|
||||
}
|
||||
}
|
||||
|
||||
os.Chmod(a.exDir+"backend-rust/webgpu_server", 0777)
|
||||
os.Chmod(a.exDir+"backend-rust/web-rwkv-converter", 0777)
|
||||
os.Mkdir(a.exDir+"models", os.ModePerm)
|
||||
os.Mkdir(a.exDir+"lora-models", os.ModePerm)
|
||||
os.Mkdir(a.exDir+"state-models", os.ModePerm)
|
||||
os.Mkdir(a.exDir+"finetune/json2binidx_tool/data", os.ModePerm)
|
||||
trainLogPath := "lora-models/train_log.txt"
|
||||
if !a.FileExists(trainLogPath) {
|
||||
f, err := os.Create(a.exDir + trainLogPath)
|
||||
if err == nil {
|
||||
f.Close()
|
||||
}
|
||||
}
|
||||
|
||||
a.downloadLoop()
|
||||
a.midiLoop()
|
||||
a.watchFs()
|
||||
a.monitorHardware()
|
||||
a.newFetchProxy()
|
||||
}
|
||||
|
||||
func (a *App) OnBeforeClose(ctx context.Context) bool {
|
||||
if monitor != nil {
|
||||
monitor.Process.Kill()
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func (a *App) watchFs() {
|
||||
watcher, err := fsnotify.NewWatcher()
|
||||
if err == nil {
|
||||
watcher.Add(a.exDir + "./models")
|
||||
watcher.Add(a.exDir + "./lora-models")
|
||||
watcher.Add(a.exDir + "./state-models")
|
||||
go func() {
|
||||
for {
|
||||
select {
|
||||
case event, ok := <-watcher.Events:
|
||||
if !ok {
|
||||
return
|
||||
}
|
||||
wruntime.EventsEmit(a.ctx, "fsnotify", event.Name)
|
||||
case _, ok := <-watcher.Errors:
|
||||
if !ok {
|
||||
return
|
||||
}
|
||||
}
|
||||
}
|
||||
}()
|
||||
}
|
||||
}
|
||||
|
||||
var monitor *exec.Cmd
|
||||
|
||||
func (a *App) monitorHardware() {
|
||||
if runtime.GOOS != "windows" {
|
||||
return
|
||||
}
|
||||
|
||||
monitor = exec.Command("./components/LibreHardwareMonitor.Console/LibreHardwareMonitor.Console.exe")
|
||||
stdout, err := monitor.StdoutPipe()
|
||||
if err != nil {
|
||||
monitor = nil
|
||||
return
|
||||
}
|
||||
|
||||
go func() {
|
||||
reader := bufio.NewReader(stdout)
|
||||
for {
|
||||
line, _, err := reader.ReadLine()
|
||||
if err != nil {
|
||||
wruntime.EventsEmit(a.ctx, "monitorerr", err.Error())
|
||||
break
|
||||
}
|
||||
wruntime.EventsEmit(a.ctx, "monitor", string(line))
|
||||
}
|
||||
}()
|
||||
|
||||
monitor.SysProcAttr = &syscall.SysProcAttr{}
|
||||
//go:custom_build windows monitor.SysProcAttr.HideWindow = true
|
||||
monitor.Start()
|
||||
}
|
||||
|
||||
type ProgressReader struct {
|
||||
reader io.Reader
|
||||
total int64
|
||||
err error
|
||||
}
|
||||
|
||||
func (pr *ProgressReader) Read(p []byte) (n int, err error) {
|
||||
n, err = pr.reader.Read(p)
|
||||
pr.err = err
|
||||
pr.total += int64(n)
|
||||
return
|
||||
}
|
||||
|
||||
func (a *App) UpdateApp(url string) (broken bool, err error) {
|
||||
@ -223,88 +35,22 @@ func (a *App) UpdateApp(url string) (broken bool, err error) {
|
||||
return false, err
|
||||
}
|
||||
defer resp.Body.Close()
|
||||
pr := &ProgressReader{reader: resp.Body}
|
||||
|
||||
ticker := time.NewTicker(250 * time.Millisecond)
|
||||
defer ticker.Stop()
|
||||
|
||||
// update progress
|
||||
go func() {
|
||||
for {
|
||||
<-ticker.C
|
||||
wruntime.EventsEmit(a.ctx, "updateApp", &DownloadStatus{
|
||||
Name: filepath.Base(url),
|
||||
Path: "",
|
||||
Url: url,
|
||||
Transferred: pr.total,
|
||||
Size: resp.ContentLength,
|
||||
Speed: 0,
|
||||
Progress: 100 * (float64(pr.total) / float64(resp.ContentLength)),
|
||||
Downloading: pr.err == nil && pr.total < resp.ContentLength,
|
||||
Done: pr.total == resp.ContentLength,
|
||||
})
|
||||
if pr.err != nil || pr.total == resp.ContentLength {
|
||||
break
|
||||
}
|
||||
}
|
||||
}()
|
||||
|
||||
var updateFile io.Reader = pr
|
||||
// extract macos binary from zip
|
||||
if strings.HasSuffix(url, ".zip") && runtime.GOOS == "darwin" {
|
||||
zipBytes, err := io.ReadAll(pr)
|
||||
if err != nil {
|
||||
return false, err
|
||||
}
|
||||
archive, err := zip.NewReader(bytes.NewReader(zipBytes), int64(len(zipBytes)))
|
||||
if err != nil {
|
||||
return false, err
|
||||
}
|
||||
file, err := archive.Open("RWKV-Runner.app/Contents/MacOS/RWKV-Runner")
|
||||
if err != nil {
|
||||
return false, err
|
||||
}
|
||||
defer file.Close()
|
||||
updateFile = file
|
||||
}
|
||||
|
||||
// apply update
|
||||
err = selfupdate.Apply(updateFile, selfupdate.Options{})
|
||||
err = selfupdate.Apply(resp.Body, selfupdate.Options{})
|
||||
if err != nil {
|
||||
if rerr := selfupdate.RollbackError(err); rerr != nil {
|
||||
return true, rerr
|
||||
}
|
||||
return false, err
|
||||
}
|
||||
// restart app
|
||||
if runtime.GOOS == "windows" {
|
||||
name, err := os.Executable()
|
||||
if err != nil {
|
||||
return false, err
|
||||
}
|
||||
exec.Command(name, os.Args[1:]...).Start()
|
||||
wruntime.Quit(a.ctx)
|
||||
name, err := os.Executable()
|
||||
if err != nil {
|
||||
return false, err
|
||||
}
|
||||
exec.Command(name, os.Args[1:]...).Start()
|
||||
wruntime.Quit(a.ctx)
|
||||
return false, nil
|
||||
}
|
||||
|
||||
func (a *App) RestartApp() error {
|
||||
if runtime.GOOS == "windows" {
|
||||
name, err := os.Executable()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
exec.Command(name, os.Args[1:]...).Start()
|
||||
wruntime.Quit(a.ctx)
|
||||
return nil
|
||||
}
|
||||
return errors.New("unsupported OS")
|
||||
}
|
||||
|
||||
func (a *App) GetPlatform() string {
|
||||
return runtime.GOOS
|
||||
}
|
||||
|
||||
func (a *App) GetProxyPort() int {
|
||||
return a.proxyPort
|
||||
}
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
package backend_golang
|
||||
|
||||
import (
|
||||
"context"
|
||||
"path/filepath"
|
||||
"time"
|
||||
|
||||
@ -10,11 +9,7 @@ import (
|
||||
)
|
||||
|
||||
func (a *App) DownloadFile(path string, url string) error {
|
||||
absPath, err := a.GetAbsPath(path)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
_, err = grab.Get(absPath, url)
|
||||
_, err := grab.Get(path, url)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
@ -23,7 +18,6 @@ func (a *App) DownloadFile(path string, url string) error {
|
||||
|
||||
type DownloadStatus struct {
|
||||
resp *grab.Response
|
||||
cancel context.CancelFunc
|
||||
Name string `json:"name"`
|
||||
Path string `json:"path"`
|
||||
Url string `json:"url"`
|
||||
@ -35,11 +29,11 @@ type DownloadStatus struct {
|
||||
Done bool `json:"done"`
|
||||
}
|
||||
|
||||
var downloadList []*DownloadStatus
|
||||
var downloadList []DownloadStatus
|
||||
|
||||
func existsInDownloadList(path string, url string) bool {
|
||||
func existsInDownloadList(url string) bool {
|
||||
for _, ds := range downloadList {
|
||||
if ds.Path == path || ds.Url == url {
|
||||
if ds.Url == url {
|
||||
return true
|
||||
}
|
||||
}
|
||||
@ -47,62 +41,49 @@ func existsInDownloadList(path string, url string) bool {
|
||||
}
|
||||
|
||||
func (a *App) PauseDownload(url string) {
|
||||
for _, ds := range downloadList {
|
||||
for i, ds := range downloadList {
|
||||
if ds.Url == url {
|
||||
if ds.cancel != nil {
|
||||
ds.cancel()
|
||||
if ds.resp != nil {
|
||||
ds.resp.Cancel()
|
||||
}
|
||||
|
||||
downloadList[i] = DownloadStatus{
|
||||
resp: ds.resp,
|
||||
Name: ds.Name,
|
||||
Path: ds.Path,
|
||||
Url: ds.Url,
|
||||
Downloading: false,
|
||||
}
|
||||
ds.resp = nil
|
||||
ds.Downloading = false
|
||||
ds.Speed = 0
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (a *App) ContinueDownload(url string) {
|
||||
for _, ds := range downloadList {
|
||||
for i, ds := range downloadList {
|
||||
if ds.Url == url {
|
||||
if !ds.Downloading && ds.resp == nil && !ds.Done {
|
||||
ds.Downloading = true
|
||||
client := grab.NewClient()
|
||||
req, _ := grab.NewRequest(ds.Path, ds.Url)
|
||||
resp := client.Do(req)
|
||||
|
||||
req, err := grab.NewRequest(ds.Path, ds.Url)
|
||||
if err != nil {
|
||||
ds.Downloading = false
|
||||
break
|
||||
}
|
||||
// if PauseDownload() is called before the request finished, ds.Downloading will be false
|
||||
// if the user keeps clicking pause and resume, it may result in multiple requests being successfully downloaded at the same time
|
||||
// so we have to create a context and cancel it when PauseDownload() is called
|
||||
ctx, cancel := context.WithCancel(context.Background())
|
||||
ds.cancel = cancel
|
||||
req = req.WithContext(ctx)
|
||||
resp := grab.DefaultClient.Do(req)
|
||||
|
||||
if resp != nil && resp.HTTPResponse != nil &&
|
||||
resp.HTTPResponse.StatusCode >= 200 && resp.HTTPResponse.StatusCode < 300 {
|
||||
ds.resp = resp
|
||||
} else {
|
||||
ds.Downloading = false
|
||||
}
|
||||
downloadList[i] = DownloadStatus{
|
||||
resp: resp,
|
||||
Name: ds.Name,
|
||||
Path: ds.Path,
|
||||
Url: ds.Url,
|
||||
Downloading: true,
|
||||
}
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (a *App) AddToDownloadList(path string, url string) {
|
||||
absPath, err := a.GetAbsPath(path)
|
||||
if err != nil {
|
||||
return
|
||||
}
|
||||
if !existsInDownloadList(absPath, url) {
|
||||
downloadList = append(downloadList, &DownloadStatus{
|
||||
if !existsInDownloadList(url) {
|
||||
downloadList = append(downloadList, DownloadStatus{
|
||||
resp: nil,
|
||||
Name: filepath.Base(path),
|
||||
Path: absPath,
|
||||
Path: path,
|
||||
Url: url,
|
||||
Downloading: false,
|
||||
Downloading: true,
|
||||
})
|
||||
a.ContinueDownload(url)
|
||||
} else {
|
||||
@ -115,17 +96,32 @@ func (a *App) downloadLoop() {
|
||||
go func() {
|
||||
for {
|
||||
<-ticker.C
|
||||
for _, ds := range downloadList {
|
||||
for i, ds := range downloadList {
|
||||
transferred := int64(0)
|
||||
size := int64(0)
|
||||
speed := float64(0)
|
||||
progress := float64(0)
|
||||
downloading := ds.Downloading
|
||||
done := false
|
||||
if ds.resp != nil {
|
||||
ds.Transferred = ds.resp.BytesComplete()
|
||||
ds.Size = ds.resp.Size()
|
||||
ds.Speed = ds.resp.BytesPerSecond()
|
||||
ds.Progress = 100 * ds.resp.Progress()
|
||||
ds.Downloading = !ds.resp.IsComplete()
|
||||
ds.Done = ds.resp.Progress() == 1
|
||||
if !ds.Downloading {
|
||||
ds.resp = nil
|
||||
}
|
||||
transferred = ds.resp.BytesComplete()
|
||||
size = ds.resp.Size()
|
||||
speed = ds.resp.BytesPerSecond()
|
||||
progress = 100 * ds.resp.Progress()
|
||||
downloading = !ds.resp.IsComplete()
|
||||
done = ds.resp.Progress() == 1
|
||||
}
|
||||
downloadList[i] = DownloadStatus{
|
||||
resp: ds.resp,
|
||||
Name: ds.Name,
|
||||
Path: ds.Path,
|
||||
Url: ds.Url,
|
||||
Transferred: transferred,
|
||||
Size: size,
|
||||
Speed: speed,
|
||||
Progress: progress,
|
||||
Downloading: downloading,
|
||||
Done: done,
|
||||
}
|
||||
}
|
||||
runtime.EventsEmit(a.ctx, "downloadList", downloadList)
|
||||
|
||||
@ -2,67 +2,28 @@ package backend_golang
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"errors"
|
||||
"io"
|
||||
"fmt"
|
||||
"os"
|
||||
"os/exec"
|
||||
"path/filepath"
|
||||
"runtime"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
wruntime "github.com/wailsapp/wails/v2/pkg/runtime"
|
||||
)
|
||||
|
||||
func (a *App) GetAbsPath(path string) (string, error) {
|
||||
var absPath string
|
||||
var err error
|
||||
if filepath.IsAbs(path) {
|
||||
absPath = filepath.Clean(path)
|
||||
} else {
|
||||
absPath, err = filepath.Abs(filepath.Join(a.exDir, path))
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
}
|
||||
absPath = strings.ReplaceAll(absPath, "/", string(os.PathSeparator))
|
||||
println("GetAbsPath:", absPath)
|
||||
return absPath, nil
|
||||
}
|
||||
|
||||
func (a *App) SaveFile(path string, savedContent []byte) error {
|
||||
absPath, err := a.GetAbsPath(path)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if err := os.WriteFile(absPath, savedContent, 0644); err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) SaveJson(path string, jsonData any) error {
|
||||
func (a *App) SaveJson(fileName string, jsonData any) error {
|
||||
text, err := json.MarshalIndent(jsonData, "", " ")
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
absPath, err := a.GetAbsPath(path)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if err := os.WriteFile(absPath, text, 0644); err != nil {
|
||||
if err := os.WriteFile(fileName, text, 0644); err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) ReadJson(path string) (any, error) {
|
||||
absPath, err := a.GetAbsPath(path)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
file, err := os.ReadFile(absPath)
|
||||
func (a *App) ReadJson(fileName string) (any, error) {
|
||||
file, err := os.ReadFile(fileName)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
@ -76,12 +37,8 @@ func (a *App) ReadJson(path string) (any, error) {
|
||||
return data, nil
|
||||
}
|
||||
|
||||
func (a *App) FileExists(path string) bool {
|
||||
absPath, err := a.GetAbsPath(path)
|
||||
if err != nil {
|
||||
return false
|
||||
}
|
||||
_, err = os.Stat(absPath)
|
||||
func (a *App) FileExists(fileName string) bool {
|
||||
_, err := os.Stat(fileName)
|
||||
return err == nil
|
||||
}
|
||||
|
||||
@ -92,16 +49,12 @@ type FileInfo struct {
|
||||
ModTime string `json:"modTime"`
|
||||
}
|
||||
|
||||
func (a *App) ReadFileInfo(path string) (*FileInfo, error) {
|
||||
absPath, err := a.GetAbsPath(path)
|
||||
func (a *App) ReadFileInfo(fileName string) (FileInfo, error) {
|
||||
info, err := os.Stat(fileName)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
return FileInfo{}, err
|
||||
}
|
||||
info, err := os.Stat(absPath)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return &FileInfo{
|
||||
return FileInfo{
|
||||
Name: info.Name(),
|
||||
Size: info.Size(),
|
||||
IsDir: info.IsDir(),
|
||||
@ -110,11 +63,7 @@ func (a *App) ReadFileInfo(path string) (*FileInfo, error) {
|
||||
}
|
||||
|
||||
func (a *App) ListDirFiles(dirPath string) ([]FileInfo, error) {
|
||||
absDirPath, err := a.GetAbsPath(dirPath)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
files, err := os.ReadDir(absDirPath)
|
||||
files, err := os.ReadDir(dirPath)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
@ -136,91 +85,15 @@ func (a *App) ListDirFiles(dirPath string) ([]FileInfo, error) {
|
||||
}
|
||||
|
||||
func (a *App) DeleteFile(path string) error {
|
||||
absPath, err := a.GetAbsPath(path)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
err = os.Remove(absPath)
|
||||
err := os.Remove(path)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) CopyFile(src string, dst string) error {
|
||||
absSrc, err := a.GetAbsPath(src)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
absDst, err := a.GetAbsPath(dst)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
sourceFile, err := os.Open(absSrc)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer sourceFile.Close()
|
||||
|
||||
err = os.MkdirAll(filepath.Dir(absDst), 0755)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
destFile, err := os.Create(absDst)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
defer destFile.Close()
|
||||
|
||||
_, err = io.Copy(destFile, sourceFile)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) OpenSaveFileDialog(filterPattern string, defaultFileName string, savedContent string) (string, error) {
|
||||
return a.OpenSaveFileDialogBytes(filterPattern, defaultFileName, []byte(savedContent))
|
||||
}
|
||||
|
||||
func (a *App) OpenSaveFileDialogBytes(filterPattern string, defaultFileName string, savedContent []byte) (string, error) {
|
||||
path, err := wruntime.SaveFileDialog(a.ctx, wruntime.SaveDialogOptions{
|
||||
DefaultFilename: defaultFileName,
|
||||
Filters: []wruntime.FileFilter{{
|
||||
Pattern: filterPattern,
|
||||
}},
|
||||
CanCreateDirectories: true,
|
||||
})
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if path == "" {
|
||||
return "", nil
|
||||
}
|
||||
if err := os.WriteFile(path, savedContent, 0644); err != nil {
|
||||
return "", err
|
||||
}
|
||||
return path, nil
|
||||
}
|
||||
|
||||
// Only return the path of the selected file, because communication between frontend and backend is slow. Use AssetServer Handler to read the file.
|
||||
func (a *App) OpenOpenFileDialog(filterPattern string) (string, error) {
|
||||
path, err := wruntime.OpenFileDialog(a.ctx, wruntime.OpenDialogOptions{
|
||||
Filters: []wruntime.FileFilter{{Pattern: filterPattern}},
|
||||
})
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if path == "" {
|
||||
return "", nil
|
||||
}
|
||||
return path, nil
|
||||
}
|
||||
|
||||
func (a *App) OpenFileFolder(path string) error {
|
||||
absPath, err := a.GetAbsPath(path)
|
||||
absPath, err := filepath.Abs(path)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
@ -231,30 +104,10 @@ func (a *App) OpenFileFolder(path string) error {
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
case "darwin":
|
||||
cmd := exec.Command("open", "-R", absPath)
|
||||
err := cmd.Run()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
fmt.Println("Running on macOS")
|
||||
case "linux":
|
||||
cmd := exec.Command("xdg-open", absPath)
|
||||
err := cmd.Run()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
fmt.Println("Running on Linux")
|
||||
}
|
||||
return errors.New("unsupported OS")
|
||||
}
|
||||
|
||||
func (a *App) StartFile(path string) error {
|
||||
cmd, err := CmdHelper(true, path)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
err = cmd.Start()
|
||||
return err
|
||||
return nil
|
||||
}
|
||||
|
||||
@ -1,170 +0,0 @@
|
||||
package backend_golang
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
"time"
|
||||
|
||||
"github.com/mattrtaylor/go-rtmidi"
|
||||
"github.com/wailsapp/wails/v2/pkg/runtime"
|
||||
)
|
||||
|
||||
type Port struct {
|
||||
Name string `json:"name"`
|
||||
}
|
||||
type MIDIMessage struct {
|
||||
MessageType string `json:"messageType"`
|
||||
Channel int `json:"channel"`
|
||||
Note int `json:"note"`
|
||||
Velocity int `json:"velocity"`
|
||||
Control int `json:"control"`
|
||||
Value int `json:"value"`
|
||||
}
|
||||
|
||||
var ports []Port
|
||||
var input rtmidi.MIDIIn
|
||||
var out rtmidi.MIDIOut
|
||||
var activeIndex int = -1
|
||||
var lastNoteTime time.Time
|
||||
|
||||
func (a *App) midiLoop() {
|
||||
var err error
|
||||
input, err = rtmidi.NewMIDIInDefault()
|
||||
if err != nil {
|
||||
runtime.EventsEmit(a.ctx, "midiError", err.Error())
|
||||
return
|
||||
}
|
||||
out, err = rtmidi.NewMIDIOutDefault()
|
||||
if err != nil {
|
||||
runtime.EventsEmit(a.ctx, "midiError", err.Error())
|
||||
}
|
||||
err = out.OpenPort(0, "")
|
||||
if err != nil {
|
||||
runtime.EventsEmit(a.ctx, "midiError", err.Error())
|
||||
}
|
||||
ticker := time.NewTicker(500 * time.Millisecond)
|
||||
go func() {
|
||||
for {
|
||||
<-ticker.C
|
||||
count, err := input.PortCount()
|
||||
if err != nil {
|
||||
continue
|
||||
}
|
||||
ports = make([]Port, count)
|
||||
for i := 0; i < count; i++ {
|
||||
name, err := input.PortName(i)
|
||||
if err == nil {
|
||||
ports[i].Name = name
|
||||
}
|
||||
}
|
||||
runtime.EventsEmit(a.ctx, "midiPorts", &ports)
|
||||
}
|
||||
}()
|
||||
}
|
||||
|
||||
func (a *App) OpenMidiPort(index int) error {
|
||||
if input == nil {
|
||||
return errors.New("failed to initialize MIDI input")
|
||||
}
|
||||
if activeIndex == index {
|
||||
return nil
|
||||
}
|
||||
input.Destroy()
|
||||
var err error
|
||||
input, err = rtmidi.NewMIDIInDefault()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
err = input.SetCallback(func(msg rtmidi.MIDIIn, bytes []byte, t float64) {
|
||||
// https://www.midi.org/specifications-old/item/table-1-summary-of-midi-message
|
||||
// https://www.rfc-editor.org/rfc/rfc6295.html
|
||||
//
|
||||
// msgType channel
|
||||
// 1001 0000
|
||||
//
|
||||
msgType := bytes[0] >> 4
|
||||
channel := bytes[0] & 0x0f
|
||||
switch msgType {
|
||||
case 0x8:
|
||||
elapsed := time.Since(lastNoteTime)
|
||||
lastNoteTime = time.Now()
|
||||
runtime.EventsEmit(a.ctx, "midiMessage", &MIDIMessage{
|
||||
MessageType: "ElapsedTime",
|
||||
Value: int(elapsed.Milliseconds()),
|
||||
})
|
||||
note := bytes[1]
|
||||
runtime.EventsEmit(a.ctx, "midiMessage", &MIDIMessage{
|
||||
MessageType: "NoteOff",
|
||||
Channel: int(channel),
|
||||
Note: int(note),
|
||||
})
|
||||
case 0x9:
|
||||
elapsed := time.Since(lastNoteTime)
|
||||
lastNoteTime = time.Now()
|
||||
runtime.EventsEmit(a.ctx, "midiMessage", &MIDIMessage{
|
||||
MessageType: "ElapsedTime",
|
||||
Value: int(elapsed.Milliseconds()),
|
||||
})
|
||||
note := bytes[1]
|
||||
velocity := bytes[2]
|
||||
runtime.EventsEmit(a.ctx, "midiMessage", &MIDIMessage{
|
||||
MessageType: "NoteOn",
|
||||
Channel: int(channel),
|
||||
Note: int(note),
|
||||
Velocity: int(velocity),
|
||||
})
|
||||
case 0xb:
|
||||
// control 12 => K1 knob, control 13 => K2 knob
|
||||
control := bytes[1]
|
||||
value := bytes[2]
|
||||
runtime.EventsEmit(a.ctx, "midiMessage", &MIDIMessage{
|
||||
MessageType: "ControlChange",
|
||||
Channel: int(channel),
|
||||
Control: int(control),
|
||||
Value: int(value),
|
||||
})
|
||||
default:
|
||||
fmt.Printf("Unknown midi message: %v\n", bytes)
|
||||
}
|
||||
})
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
err = input.OpenPort(index, "")
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
activeIndex = index
|
||||
lastNoteTime = time.Now()
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) CloseMidiPort() error {
|
||||
if input == nil {
|
||||
return errors.New("failed to initialize MIDI input")
|
||||
}
|
||||
if activeIndex == -1 {
|
||||
return nil
|
||||
}
|
||||
activeIndex = -1
|
||||
input.Destroy()
|
||||
var err error
|
||||
input, err = rtmidi.NewMIDIInDefault()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) PlayNote(msg MIDIMessage) error {
|
||||
if out == nil {
|
||||
return errors.New("failed to initialize MIDI output")
|
||||
}
|
||||
channelByte := byte(msg.Channel)
|
||||
if msg.MessageType == "NoteOn" {
|
||||
out.SendMessage([]byte{0x90 | channelByte, byte(msg.Note), byte(msg.Velocity)})
|
||||
} else if msg.MessageType == "NoteOff" {
|
||||
out.SendMessage([]byte{0x80 | channelByte, byte(msg.Note), byte(msg.Velocity)})
|
||||
}
|
||||
return nil
|
||||
}
|
||||
@ -1,261 +1,60 @@
|
||||
// Considering some whitespace and multilingual support, the functions in rwkv.go should always be executed with cwd as RWKV-Runner, and never use a.GetAbsPath() here.
|
||||
package backend_golang
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"errors"
|
||||
"os"
|
||||
"os/exec"
|
||||
"runtime"
|
||||
"strconv"
|
||||
"strings"
|
||||
)
|
||||
|
||||
func (a *App) StartServer(python string, port int, host string, webui bool, rwkvBeta bool, rwkvcpp bool, webgpu bool) (string, error) {
|
||||
execFile := "./backend-python/main.py"
|
||||
_, err := os.Stat(execFile)
|
||||
func (a *App) StartServer(port int) (string, error) {
|
||||
python, err := GetPython()
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if python == "" {
|
||||
python, err = GetPython()
|
||||
}
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
args := []string{python, execFile}
|
||||
if webui {
|
||||
args = append(args, "--webui")
|
||||
}
|
||||
if rwkvBeta {
|
||||
// args = append(args, "--rwkv-beta")
|
||||
}
|
||||
if rwkvcpp {
|
||||
args = append(args, "--rwkv.cpp")
|
||||
}
|
||||
if webgpu {
|
||||
args = append(args, "--webgpu")
|
||||
}
|
||||
args = append(args, "--port", strconv.Itoa(port), "--host", host)
|
||||
return Cmd(args...)
|
||||
return Cmd(python, "./backend-python/main.py", strconv.Itoa(port))
|
||||
}
|
||||
|
||||
func (a *App) StartWebGPUServer(port int, host string) (string, error) {
|
||||
var execFile string
|
||||
execFiles := []string{"./backend-rust/webgpu_server", "./backend-rust/webgpu_server.exe"}
|
||||
for _, file := range execFiles {
|
||||
_, err := os.Stat(file)
|
||||
if err == nil {
|
||||
execFile = file
|
||||
break
|
||||
}
|
||||
func (a *App) ConvertModel(modelPath string, strategy string, outPath string) (string, error) {
|
||||
python, err := GetPython()
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if execFile == "" {
|
||||
return "", errors.New(execFiles[0] + " not found")
|
||||
}
|
||||
args := []string{execFile}
|
||||
args = append(args, "--port", strconv.Itoa(port), "--ip", host)
|
||||
return Cmd(args...)
|
||||
return Cmd(python, "./backend-python/convert_model.py", "--in", modelPath, "--out", outPath, "--strategy", strategy)
|
||||
}
|
||||
|
||||
func (a *App) ConvertModel(python string, modelPath string, strategy string, outPath string) (string, error) {
|
||||
execFile := "./backend-python/convert_model.py"
|
||||
_, err := os.Stat(execFile)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if python == "" {
|
||||
python, err = GetPython()
|
||||
}
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
return Cmd(python, execFile, "--in", modelPath, "--out", outPath, "--strategy", strategy)
|
||||
}
|
||||
|
||||
func (a *App) ConvertSafetensors(modelPath string, outPath string) (string, error) {
|
||||
var execFile string
|
||||
execFiles := []string{"./backend-rust/web-rwkv-converter", "./backend-rust/web-rwkv-converter.exe"}
|
||||
for _, file := range execFiles {
|
||||
_, err := os.Stat(file)
|
||||
if err == nil {
|
||||
execFile = file
|
||||
break
|
||||
}
|
||||
}
|
||||
if execFile == "" {
|
||||
return "", errors.New(execFiles[0] + " not found")
|
||||
}
|
||||
args := []string{execFile}
|
||||
args = append(args, "--input", modelPath, "--output", outPath)
|
||||
return Cmd(args...)
|
||||
}
|
||||
|
||||
func (a *App) ConvertSafetensorsWithPython(python string, modelPath string, outPath string) (string, error) {
|
||||
execFile := "./backend-python/convert_safetensors.py"
|
||||
_, err := os.Stat(execFile)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if python == "" {
|
||||
python, err = GetPython()
|
||||
}
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
return Cmd(python, execFile, "--input", modelPath, "--output", outPath)
|
||||
}
|
||||
|
||||
func (a *App) ConvertGGML(python string, modelPath string, outPath string, Q51 bool) (string, error) {
|
||||
execFile := "./backend-python/convert_pytorch_to_ggml.py"
|
||||
_, err := os.Stat(execFile)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if python == "" {
|
||||
python, err = GetPython()
|
||||
}
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
dataType := "FP16"
|
||||
if Q51 {
|
||||
dataType = "Q5_1"
|
||||
}
|
||||
return Cmd(python, execFile, modelPath, outPath, dataType)
|
||||
}
|
||||
|
||||
func (a *App) ConvertData(python string, input string, outputPrefix string, vocab string) (string, error) {
|
||||
execFile := "./finetune/json2binidx_tool/tools/preprocess_data.py"
|
||||
_, err := os.Stat(execFile)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if python == "" {
|
||||
python, err = GetPython()
|
||||
}
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
tokenizerType := "HFTokenizer"
|
||||
if strings.Contains(vocab, "rwkv_vocab_v20230424") {
|
||||
tokenizerType = "RWKVTokenizer"
|
||||
}
|
||||
|
||||
input = strings.TrimSuffix(input, "/")
|
||||
if fi, err := os.Stat(input); err == nil && fi.IsDir() {
|
||||
files, err := os.ReadDir(input)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
jsonlFile, err := os.Create(outputPrefix + ".jsonl")
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
defer jsonlFile.Close()
|
||||
for _, file := range files {
|
||||
if file.IsDir() || !strings.HasSuffix(file.Name(), ".txt") {
|
||||
continue
|
||||
}
|
||||
textContent, err := os.ReadFile(input + "/" + file.Name())
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
textJson, err := json.Marshal(map[string]string{"text": strings.ReplaceAll(strings.ReplaceAll(string(textContent), "\r\n", "\n"), "\r", "\n")})
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if _, err := jsonlFile.WriteString(string(textJson) + "\n"); err != nil {
|
||||
return "", err
|
||||
}
|
||||
}
|
||||
input = outputPrefix + ".jsonl"
|
||||
} else if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
return Cmd(python, execFile, "--input", input, "--output-prefix", outputPrefix, "--vocab", vocab,
|
||||
"--tokenizer-type", tokenizerType, "--dataset-impl", "mmap", "--append-eod")
|
||||
}
|
||||
|
||||
func (a *App) MergeLora(python string, useGpu bool, loraAlpha int, baseModel string, loraPath string, outputPath string) (string, error) {
|
||||
execFile := "./finetune/lora/merge_lora.py"
|
||||
_, err := os.Stat(execFile)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if python == "" {
|
||||
python, err = GetPython()
|
||||
}
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
args := []string{python, execFile}
|
||||
if useGpu {
|
||||
args = append(args, "--use-gpu")
|
||||
}
|
||||
args = append(args, strconv.Itoa(loraAlpha), baseModel, loraPath, outputPath)
|
||||
return Cmd(args...)
|
||||
}
|
||||
|
||||
func (a *App) DepCheck(python string) error {
|
||||
var err error
|
||||
if python == "" {
|
||||
python, err = GetPython()
|
||||
}
|
||||
func (a *App) DepCheck() error {
|
||||
python, err := GetPython()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
out, err := exec.Command(python, a.exDir+"backend-python/dep_check.py").CombinedOutput()
|
||||
out, err := exec.Command(python, "./backend-python/dep_check.py").CombinedOutput()
|
||||
if err != nil {
|
||||
return errors.New("DepCheck Error: " + string(out) + " GError: " + err.Error())
|
||||
return errors.New("DepCheck Error: " + string(out))
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) InstallPyDep(python string, cnMirror bool) (string, error) {
|
||||
var err error
|
||||
torchWhlUrl := "torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 --index-url https://download.pytorch.org/whl/cu117"
|
||||
if python == "" {
|
||||
python, err = GetPython()
|
||||
if cnMirror && python == "py310/python.exe" {
|
||||
torchWhlUrl = "https://mirrors.aliyun.com/pytorch-wheels/cu117/torch-1.13.1+cu117-cp310-cp310-win_amd64.whl"
|
||||
}
|
||||
if runtime.GOOS == "windows" {
|
||||
python = `"%CD%/` + python + `"`
|
||||
}
|
||||
func (a *App) InstallPyDep(cnMirror bool) (string, error) {
|
||||
python, err := GetPython()
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
if cnMirror {
|
||||
_, err = Cmd(python, "./backend-python/get-pip.py", "-i", "https://pypi.tuna.tsinghua.edu.cn/simple")
|
||||
} else {
|
||||
_, err = Cmd(python, "./backend-python/get-pip.py")
|
||||
}
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
|
||||
if runtime.GOOS == "windows" {
|
||||
ChangeFileLine("./py310/python310._pth", 3, "Lib\\site-packages")
|
||||
installScript := python + " ./backend-python/get-pip.py -i https://mirrors.aliyun.com/pypi/simple --no-warn-script-location\n" +
|
||||
python + " -m pip install " + torchWhlUrl + " --no-warn-script-location\n" +
|
||||
python + " -m pip install -r ./backend-python/requirements.txt -i https://mirrors.aliyun.com/pypi/simple --no-warn-script-location\n" +
|
||||
"exit"
|
||||
if !cnMirror {
|
||||
installScript = strings.Replace(installScript, " -i https://mirrors.aliyun.com/pypi/simple", "", -1)
|
||||
}
|
||||
err = os.WriteFile(a.exDir+"install-py-dep.bat", []byte(installScript), 0644)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
return Cmd("install-py-dep.bat")
|
||||
}
|
||||
|
||||
if cnMirror {
|
||||
return Cmd(python, "-m", "pip", "install", "-r", "./backend-python/requirements_without_cyac.txt", "-i", "https://mirrors.aliyun.com/pypi/simple")
|
||||
} else {
|
||||
return Cmd(python, "-m", "pip", "install", "-r", "./backend-python/requirements_without_cyac.txt")
|
||||
}
|
||||
}
|
||||
|
||||
func (a *App) GetPyError() string {
|
||||
content, err := os.ReadFile("./error.txt")
|
||||
ChangeFileLine("./py310/python310._pth", 3, "Lib\\site-packages")
|
||||
_, err = Cmd(python, "-m", "pip", "install", "torch", "torchvision", "torchaudio", "--index-url", "https://download.pytorch.org/whl/cu117")
|
||||
if err != nil {
|
||||
return ""
|
||||
return "", err
|
||||
}
|
||||
if cnMirror {
|
||||
return Cmd(python, "-m", "pip", "install", "-r", "./backend-python/requirements.txt", "-i", "https://pypi.tuna.tsinghua.edu.cn/simple")
|
||||
} else {
|
||||
return Cmd(python, "-m", "pip", "install", "-r", "./backend-python/requirements_versions.txt")
|
||||
}
|
||||
return string(content)
|
||||
}
|
||||
|
||||
@ -3,159 +3,44 @@ package backend_golang
|
||||
import (
|
||||
"archive/zip"
|
||||
"bufio"
|
||||
"crypto/sha256"
|
||||
"embed"
|
||||
"errors"
|
||||
"fmt"
|
||||
"io"
|
||||
"io/fs"
|
||||
"net"
|
||||
"os"
|
||||
"os/exec"
|
||||
"path/filepath"
|
||||
"runtime"
|
||||
"strconv"
|
||||
"strings"
|
||||
"syscall"
|
||||
)
|
||||
|
||||
func CmdHelper(hideWindow bool, args ...string) (*exec.Cmd, error) {
|
||||
if runtime.GOOS != "windows" {
|
||||
return nil, errors.New("unsupported OS")
|
||||
}
|
||||
ex, err := os.Executable()
|
||||
func Cmd(args ...string) (string, error) {
|
||||
_, err := os.Stat("cmd-helper.bat")
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
exDir := filepath.Dir(ex) + "/"
|
||||
path := exDir + "cmd-helper.bat"
|
||||
_, err = os.Stat(path)
|
||||
if err != nil {
|
||||
if err := os.WriteFile(path, []byte("start %*"), 0644); err != nil {
|
||||
return nil, err
|
||||
if err := os.WriteFile("./cmd-helper.bat", []byte("start %*"), 0644); err != nil {
|
||||
return "", err
|
||||
}
|
||||
}
|
||||
cmdHelper, err := filepath.Abs(path)
|
||||
cmdHelper, err := filepath.Abs("./cmd-helper")
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
if strings.Contains(cmdHelper, " ") {
|
||||
for _, arg := range args {
|
||||
if strings.Contains(arg, " ") {
|
||||
return nil, errors.New("path contains space") // golang bug https://github.com/golang/go/issues/17149#issuecomment-473976818
|
||||
}
|
||||
}
|
||||
return "", err
|
||||
}
|
||||
cmd := exec.Command(cmdHelper, args...)
|
||||
cmd.SysProcAttr = &syscall.SysProcAttr{}
|
||||
//go:custom_build windows cmd.SysProcAttr.HideWindow = hideWindow
|
||||
return cmd, nil
|
||||
}
|
||||
|
||||
func Cmd(args ...string) (string, error) {
|
||||
switch platform := runtime.GOOS; platform {
|
||||
case "windows":
|
||||
cmd, err := CmdHelper(true, args...)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
_, err = cmd.CombinedOutput()
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
return "", nil
|
||||
case "darwin":
|
||||
ex, err := os.Executable()
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
exDir := filepath.Dir(ex) + "/../../../"
|
||||
cmd := exec.Command("osascript", "-e", `tell application "Terminal" to do script "`+"cd "+exDir+" && "+strings.Join(args, " ")+`"`)
|
||||
err = cmd.Start()
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
cmd.Wait()
|
||||
return "", nil
|
||||
case "linux":
|
||||
cmd := exec.Command(args[0], args[1:]...)
|
||||
err := cmd.Start()
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
cmd.Wait()
|
||||
return "", nil
|
||||
}
|
||||
return "", errors.New("unsupported OS")
|
||||
}
|
||||
|
||||
func CopyEmbed(efs embed.FS) error {
|
||||
ex, err := os.Executable()
|
||||
out, err := cmd.CombinedOutput()
|
||||
if err != nil {
|
||||
return err
|
||||
return "", err
|
||||
}
|
||||
var prefix string
|
||||
if runtime.GOOS == "darwin" {
|
||||
prefix = filepath.Dir(ex) + "/../../../"
|
||||
} else {
|
||||
prefix = filepath.Dir(ex) + "/"
|
||||
}
|
||||
|
||||
err = fs.WalkDir(efs, ".", func(path string, d fs.DirEntry, err error) error {
|
||||
if d.IsDir() {
|
||||
return nil
|
||||
}
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
content, err := efs.ReadFile(path)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
path = prefix + path
|
||||
err = os.MkdirAll(path[:strings.LastIndex(path, "/")], 0755)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
executeWrite := true
|
||||
existedContent, err := os.ReadFile(path)
|
||||
if err == nil {
|
||||
if fmt.Sprintf("%x", sha256.Sum256(existedContent)) == fmt.Sprintf("%x", sha256.Sum256(content)) {
|
||||
executeWrite = false
|
||||
}
|
||||
}
|
||||
|
||||
if executeWrite {
|
||||
err = os.WriteFile(path, content, 0644)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
}
|
||||
|
||||
return nil
|
||||
})
|
||||
return err
|
||||
return string(out), nil
|
||||
}
|
||||
|
||||
func GetPython() (string, error) {
|
||||
switch platform := runtime.GOOS; platform {
|
||||
case "windows":
|
||||
ex, err := os.Executable()
|
||||
_, err := os.Stat("py310/python.exe")
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
exDir := filepath.Dir(ex) + "/"
|
||||
pyexe := exDir + "py310/python.exe"
|
||||
_, err = os.Stat(pyexe)
|
||||
if err != nil {
|
||||
_, err := os.Stat(exDir + "python-3.10.11-embed-amd64.zip")
|
||||
_, err := os.Stat("python-3.10.11-embed-amd64.zip")
|
||||
if err != nil {
|
||||
return "", errors.New("python zip not found")
|
||||
} else {
|
||||
err := Unzip(exDir+"python-3.10.11-embed-amd64.zip", exDir+"py310")
|
||||
err := Unzip("python-3.10.11-embed-amd64.zip", "py310")
|
||||
if err != nil {
|
||||
return "", errors.New("failed to unzip python")
|
||||
} else {
|
||||
@ -249,12 +134,3 @@ func Unzip(source, destination string) error {
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) IsPortAvailable(port int) bool {
|
||||
l, err := net.Listen("tcp", fmt.Sprintf("127.0.0.1:%s", strconv.Itoa(port)))
|
||||
if err != nil {
|
||||
return false
|
||||
}
|
||||
defer l.Close()
|
||||
return true
|
||||
}
|
||||
|
||||
@ -1,31 +0,0 @@
|
||||
//go:build darwin || linux
|
||||
|
||||
package backend_golang
|
||||
|
||||
import (
|
||||
"errors"
|
||||
)
|
||||
|
||||
func (a *App) WslStart() error {
|
||||
return errors.New("wsl not supported")
|
||||
}
|
||||
|
||||
func (a *App) WslCommand(command string) error {
|
||||
return errors.New("wsl not supported")
|
||||
}
|
||||
|
||||
func (a *App) WslStop() error {
|
||||
return errors.New("wsl not supported")
|
||||
}
|
||||
|
||||
func (a *App) WslIsEnabled() error {
|
||||
return errors.New("wsl not supported")
|
||||
}
|
||||
|
||||
func (a *App) WslEnable(forceMode bool) error {
|
||||
return errors.New("wsl not supported")
|
||||
}
|
||||
|
||||
func (a *App) WslInstallUbuntu() error {
|
||||
return errors.New("wsl not supported")
|
||||
}
|
||||
@ -1,174 +0,0 @@
|
||||
//go:build windows
|
||||
|
||||
package backend_golang
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"context"
|
||||
"errors"
|
||||
"io"
|
||||
"os"
|
||||
"os/exec"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
su "github.com/nyaosorg/go-windows-su"
|
||||
wsl "github.com/ubuntu/gowsl"
|
||||
wruntime "github.com/wailsapp/wails/v2/pkg/runtime"
|
||||
)
|
||||
|
||||
var distro *wsl.Distro
|
||||
var stdin io.WriteCloser
|
||||
var cmd *exec.Cmd
|
||||
|
||||
func isWslRunning() (bool, error) {
|
||||
if distro == nil {
|
||||
return false, nil
|
||||
}
|
||||
state, err := distro.State()
|
||||
if err != nil {
|
||||
return false, err
|
||||
}
|
||||
if state != wsl.Running {
|
||||
distro = nil
|
||||
return false, nil
|
||||
}
|
||||
return true, nil
|
||||
}
|
||||
|
||||
func (a *App) WslStart() error {
|
||||
running, err := isWslRunning()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if running {
|
||||
return nil
|
||||
}
|
||||
distros, err := wsl.RegisteredDistros(context.Background())
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
for _, d := range distros {
|
||||
if strings.Contains(d.Name(), "Ubuntu") {
|
||||
distro = &d
|
||||
break
|
||||
}
|
||||
}
|
||||
if distro == nil {
|
||||
return errors.New("ubuntu not found")
|
||||
}
|
||||
|
||||
cmd = exec.Command("wsl", "-d", distro.Name(), "-u", "root")
|
||||
|
||||
stdin, err = cmd.StdinPipe()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
stdout, err := cmd.StdoutPipe()
|
||||
cmd.Stderr = cmd.Stdout
|
||||
if err != nil {
|
||||
// stdin.Close()
|
||||
stdin = nil
|
||||
return err
|
||||
}
|
||||
|
||||
go func() {
|
||||
reader := bufio.NewReader(stdout)
|
||||
for {
|
||||
if stdin == nil {
|
||||
break
|
||||
}
|
||||
line, _, err := reader.ReadLine()
|
||||
if err != nil {
|
||||
wruntime.EventsEmit(a.ctx, "wslerr", err.Error())
|
||||
break
|
||||
}
|
||||
wruntime.EventsEmit(a.ctx, "wsl", string(line))
|
||||
}
|
||||
// stdout.Close()
|
||||
}()
|
||||
|
||||
if err := cmd.Start(); err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) WslCommand(command string) error {
|
||||
running, err := isWslRunning()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if !running {
|
||||
return errors.New("wsl not running")
|
||||
}
|
||||
_, err = stdin.Write([]byte(command + "\n"))
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) WslStop() error {
|
||||
running, err := isWslRunning()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if !running {
|
||||
return errors.New("wsl not running")
|
||||
}
|
||||
if cmd != nil {
|
||||
err = cmd.Process.Kill()
|
||||
cmd = nil
|
||||
}
|
||||
// stdin.Close()
|
||||
stdin = nil
|
||||
distro = nil
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) WslIsEnabled() error {
|
||||
data, err := os.ReadFile(a.exDir + "wsl.state")
|
||||
if err == nil {
|
||||
if strings.Contains(string(data), "Enabled") {
|
||||
return nil
|
||||
}
|
||||
}
|
||||
|
||||
cmd := `-Command (Get-WindowsOptionalFeature -Online -FeatureName VirtualMachinePlatform).State | Out-File -Encoding utf8 -FilePath ` + a.exDir + "wsl.state"
|
||||
_, err = su.ShellExecute(su.RUNAS, "powershell", cmd, a.exDir)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
time.Sleep(2 * time.Second)
|
||||
data, err = os.ReadFile(a.exDir + "wsl.state")
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if strings.Contains(string(data), "Enabled") {
|
||||
return nil
|
||||
} else {
|
||||
return errors.New("wsl is not enabled")
|
||||
}
|
||||
}
|
||||
|
||||
func (a *App) WslEnable(forceMode bool) error {
|
||||
cmd := `/online /enable-feature /featurename:VirtualMachinePlatform`
|
||||
_, err := su.ShellExecute(su.RUNAS, "dism", cmd, `C:\`)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if forceMode {
|
||||
os.WriteFile(a.exDir+"wsl.state", []byte("Enabled"), 0644)
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (a *App) WslInstallUbuntu() error {
|
||||
_, err := Cmd("ms-windows-store://pdp/?ProductId=9PN20MSR04DW")
|
||||
return err
|
||||
}
|
||||
@ -219,18 +219,13 @@ def get_args():
|
||||
return p.parse_args()
|
||||
|
||||
|
||||
try:
|
||||
args = get_args()
|
||||
if not args.quiet:
|
||||
print(f"** {args}")
|
||||
args = get_args()
|
||||
if not args.quiet:
|
||||
print(f"** {args}")
|
||||
|
||||
RWKV(
|
||||
getattr(args, "in"),
|
||||
args.strategy,
|
||||
verbose=not args.quiet,
|
||||
convert_and_save_and_exit=args.out,
|
||||
)
|
||||
except Exception as e:
|
||||
print(e)
|
||||
with open("error.txt", "w") as f:
|
||||
f.write(str(e))
|
||||
RWKV(
|
||||
getattr(args, "in"),
|
||||
args.strategy,
|
||||
verbose=not args.quiet,
|
||||
convert_and_save_and_exit=args.out,
|
||||
)
|
||||
|
||||
@ -1,169 +0,0 @@
|
||||
# Converts an RWKV model checkpoint in PyTorch format to an rwkv.cpp compatible file.
|
||||
# Usage: python convert_pytorch_to_ggml.py C:\RWKV-4-Pile-169M-20220807-8023.pth C:\rwkv.cpp-169M-FP16.bin FP16
|
||||
# Get model checkpoints from https://huggingface.co/BlinkDL
|
||||
# See FILE_FORMAT.md for the documentation on the file format.
|
||||
|
||||
import argparse
|
||||
import struct
|
||||
import torch
|
||||
from typing import Dict
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(
|
||||
description="Convert an RWKV model checkpoint in PyTorch format to an rwkv.cpp compatible file"
|
||||
)
|
||||
parser.add_argument("src_path", help="Path to PyTorch checkpoint file")
|
||||
parser.add_argument(
|
||||
"dest_path", help="Path to rwkv.cpp checkpoint file, will be overwritten"
|
||||
)
|
||||
parser.add_argument(
|
||||
"data_type",
|
||||
help="Data type, FP16, Q4_0, Q4_1, Q5_0, Q5_1, Q8_0",
|
||||
type=str,
|
||||
choices=[
|
||||
"FP16",
|
||||
"Q4_0",
|
||||
"Q4_1",
|
||||
"Q5_0",
|
||||
"Q5_1",
|
||||
"Q8_0",
|
||||
],
|
||||
default="FP16",
|
||||
)
|
||||
return parser.parse_args()
|
||||
|
||||
|
||||
def get_layer_count(state_dict: Dict[str, torch.Tensor]) -> int:
|
||||
n_layer: int = 0
|
||||
|
||||
while f"blocks.{n_layer}.ln1.weight" in state_dict:
|
||||
n_layer += 1
|
||||
|
||||
assert n_layer > 0
|
||||
|
||||
return n_layer
|
||||
|
||||
|
||||
def write_state_dict(
|
||||
state_dict: Dict[str, torch.Tensor], dest_path: str, data_type: str
|
||||
) -> None:
|
||||
emb_weight: torch.Tensor = state_dict["emb.weight"]
|
||||
|
||||
n_layer: int = get_layer_count(state_dict)
|
||||
n_vocab: int = emb_weight.shape[0]
|
||||
n_embed: int = emb_weight.shape[1]
|
||||
|
||||
is_v5_1_or_2: bool = "blocks.0.att.ln_x.weight" in state_dict
|
||||
is_v5_2: bool = "blocks.0.att.gate.weight" in state_dict
|
||||
|
||||
if is_v5_2:
|
||||
print("Detected RWKV v5.2")
|
||||
elif is_v5_1_or_2:
|
||||
print("Detected RWKV v5.1")
|
||||
else:
|
||||
print("Detected RWKV v4")
|
||||
|
||||
with open(dest_path, "wb") as out_file:
|
||||
is_FP16: bool = data_type == "FP16" or data_type == "float16"
|
||||
|
||||
out_file.write(
|
||||
struct.pack(
|
||||
# Disable padding with '='
|
||||
"=iiiiii",
|
||||
# Magic: 'ggmf' in hex
|
||||
0x67676D66,
|
||||
101,
|
||||
n_vocab,
|
||||
n_embed,
|
||||
n_layer,
|
||||
1 if is_FP16 else 0,
|
||||
)
|
||||
)
|
||||
|
||||
for k in state_dict.keys():
|
||||
tensor: torch.Tensor = state_dict[k].float()
|
||||
|
||||
if ".time_" in k:
|
||||
tensor = tensor.squeeze()
|
||||
|
||||
if is_v5_1_or_2:
|
||||
if ".time_decay" in k:
|
||||
if is_v5_2:
|
||||
tensor = torch.exp(-torch.exp(tensor)).unsqueeze(-1)
|
||||
else:
|
||||
tensor = torch.exp(-torch.exp(tensor)).reshape(-1, 1, 1)
|
||||
|
||||
if ".time_first" in k:
|
||||
tensor = torch.exp(tensor).reshape(-1, 1, 1)
|
||||
|
||||
if ".time_faaaa" in k:
|
||||
tensor = tensor.unsqueeze(-1)
|
||||
else:
|
||||
if ".time_decay" in k:
|
||||
tensor = -torch.exp(tensor)
|
||||
|
||||
# Keep 1-dim vectors and small matrices in FP32
|
||||
if is_FP16 and len(tensor.shape) > 1 and ".time_" not in k:
|
||||
tensor = tensor.half()
|
||||
|
||||
shape = tensor.shape
|
||||
|
||||
print(f"Writing {k}, shape {shape}, type {tensor.dtype}")
|
||||
|
||||
k_encoded: bytes = k.encode("utf-8")
|
||||
|
||||
out_file.write(
|
||||
struct.pack(
|
||||
"=iii",
|
||||
len(shape),
|
||||
len(k_encoded),
|
||||
1 if tensor.dtype == torch.float16 else 0,
|
||||
)
|
||||
)
|
||||
|
||||
# Dimension order is reversed here:
|
||||
# * PyTorch shape is (x rows, y columns)
|
||||
# * ggml shape is (y elements in a row, x elements in a column)
|
||||
# Both shapes represent the same tensor.
|
||||
for dim in reversed(tensor.shape):
|
||||
out_file.write(struct.pack("=i", dim))
|
||||
|
||||
out_file.write(k_encoded)
|
||||
|
||||
tensor.numpy().tofile(out_file)
|
||||
|
||||
|
||||
def main() -> None:
|
||||
args = parse_args()
|
||||
|
||||
print(f"Reading {args.src_path}")
|
||||
|
||||
state_dict: Dict[str, torch.Tensor] = torch.load(args.src_path, map_location="cpu")
|
||||
|
||||
temp_output: str = args.dest_path
|
||||
if args.data_type.startswith("Q"):
|
||||
import re
|
||||
|
||||
temp_output = re.sub(r"Q[4,5,8]_[0,1]", "fp16", temp_output)
|
||||
write_state_dict(state_dict, temp_output, "FP16")
|
||||
if args.data_type.startswith("Q"):
|
||||
import sys
|
||||
import os
|
||||
|
||||
sys.path.append(os.path.dirname(os.path.realpath(__file__)))
|
||||
from rwkv_pip.cpp import rwkv_cpp_shared_library
|
||||
|
||||
library = rwkv_cpp_shared_library.load_rwkv_shared_library()
|
||||
library.rwkv_quantize_model_file(temp_output, args.dest_path, args.data_type)
|
||||
|
||||
print("Done")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
try:
|
||||
main()
|
||||
except Exception as e:
|
||||
print(e)
|
||||
with open("error.txt", "w") as f:
|
||||
f.write(str(e))
|
||||
@ -1,113 +0,0 @@
|
||||
import collections
|
||||
import numpy
|
||||
import os
|
||||
import torch
|
||||
from safetensors.torch import serialize_file, load_file
|
||||
|
||||
import argparse
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--input", type=str, help="Path to input pth model")
|
||||
parser.add_argument(
|
||||
"--output",
|
||||
type=str,
|
||||
default="./converted.st",
|
||||
help="Path to output safetensors model",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
|
||||
def rename_key(rename, name):
|
||||
for k, v in rename.items():
|
||||
if k in name:
|
||||
name = name.replace(k, v)
|
||||
return name
|
||||
|
||||
|
||||
def convert_file(pt_filename: str, sf_filename: str, rename={}, transpose_names=[]):
|
||||
loaded: collections.OrderedDict = torch.load(pt_filename, map_location="cpu")
|
||||
if "state_dict" in loaded:
|
||||
loaded = loaded["state_dict"]
|
||||
|
||||
kk = list(loaded.keys())
|
||||
version = 4
|
||||
for x in kk:
|
||||
if "ln_x" in x:
|
||||
version = max(5, version)
|
||||
if "gate.weight" in x:
|
||||
version = max(5.1, version)
|
||||
if int(version) == 5 and "att.time_decay" in x:
|
||||
if len(loaded[x].shape) > 1:
|
||||
if loaded[x].shape[1] > 1:
|
||||
version = max(5.2, version)
|
||||
if "time_maa" in x:
|
||||
version = max(6, version)
|
||||
|
||||
print(f"Model detected: v{version:.1f}")
|
||||
|
||||
if version == 5.1:
|
||||
_, n_emb = loaded["emb.weight"].shape
|
||||
for k in kk:
|
||||
if "time_decay" in k or "time_faaaa" in k:
|
||||
# print(k, mm[k].shape)
|
||||
loaded[k] = (
|
||||
loaded[k].unsqueeze(1).repeat(1, n_emb // loaded[k].shape[0])
|
||||
)
|
||||
|
||||
with torch.no_grad():
|
||||
for k in kk:
|
||||
new_k = rename_key(rename, k).lower()
|
||||
v = loaded[k].half()
|
||||
del loaded[k]
|
||||
for transpose_name in transpose_names:
|
||||
if transpose_name in new_k:
|
||||
dims = len(v.shape)
|
||||
v = v.transpose(dims - 2, dims - 1)
|
||||
print(f"{new_k}\t{v.shape}\t{v.dtype}")
|
||||
loaded[new_k] = {
|
||||
"dtype": str(v.dtype).split(".")[-1],
|
||||
"shape": v.shape,
|
||||
"data": v.numpy().tobytes(),
|
||||
}
|
||||
|
||||
dirname = os.path.dirname(sf_filename)
|
||||
os.makedirs(dirname, exist_ok=True)
|
||||
serialize_file(loaded, sf_filename, metadata={"format": "pt"})
|
||||
# reloaded = load_file(sf_filename)
|
||||
# for k in loaded:
|
||||
# pt_tensor = torch.Tensor(
|
||||
# numpy.frombuffer(
|
||||
# bytearray(loaded[k]["data"]),
|
||||
# dtype=getattr(numpy, loaded[k]["dtype"]),
|
||||
# ).reshape(loaded[k]["shape"])
|
||||
# )
|
||||
# sf_tensor = reloaded[k]
|
||||
# if not torch.equal(pt_tensor, sf_tensor):
|
||||
# raise RuntimeError(f"The output tensors do not match for key {k}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
try:
|
||||
convert_file(
|
||||
args.input,
|
||||
args.output,
|
||||
rename={
|
||||
"time_faaaa": "time_first",
|
||||
"time_maa": "time_mix",
|
||||
"lora_A": "lora.0",
|
||||
"lora_B": "lora.1",
|
||||
},
|
||||
transpose_names=[
|
||||
"time_mix_w1",
|
||||
"time_mix_w2",
|
||||
"time_decay_w1",
|
||||
"time_decay_w2",
|
||||
"time_state",
|
||||
"lora.0",
|
||||
],
|
||||
)
|
||||
print(f"Saved to {args.output}")
|
||||
except Exception as e:
|
||||
print(e)
|
||||
with open("error.txt", "w") as f:
|
||||
f.write(str(e))
|
||||
@ -1,23 +1,6 @@
|
||||
import setuptools
|
||||
|
||||
if setuptools.__version__ >= "70.0.0":
|
||||
raise ImportError("setuptools>=70.0.0 is not supported")
|
||||
|
||||
import multipart
|
||||
import fitz
|
||||
import safetensors
|
||||
import midi2audio
|
||||
import mido
|
||||
import lm_dataformat
|
||||
import ftfy
|
||||
import tqdm
|
||||
import tiktoken
|
||||
|
||||
import torch
|
||||
import rwkv
|
||||
import langchain
|
||||
import numpy
|
||||
import tokenizers
|
||||
import fastapi
|
||||
import uvicorn
|
||||
import sse_starlette
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,11 +1,8 @@
|
||||
from enum import Enum, auto
|
||||
|
||||
Args = "args"
|
||||
Model = "model"
|
||||
Model_Status = "model_status"
|
||||
Model_Config = "model_config"
|
||||
Deploy_Mode = "deploy_mode"
|
||||
Midi_Vocab_Config_Type = "midi_vocab_config_type"
|
||||
|
||||
|
||||
class ModelStatus(Enum):
|
||||
@ -14,17 +11,10 @@ class ModelStatus(Enum):
|
||||
Working = 3
|
||||
|
||||
|
||||
class MidiVocabConfig(Enum):
|
||||
Default = auto()
|
||||
Piano = auto()
|
||||
|
||||
|
||||
def init():
|
||||
global GLOBALS
|
||||
GLOBALS = {}
|
||||
set(Model_Status, ModelStatus.Offline)
|
||||
set(Deploy_Mode, False)
|
||||
set(Midi_Vocab_Config_Type, MidiVocabConfig.Default)
|
||||
|
||||
|
||||
def set(key, value):
|
||||
|
||||
@ -1,77 +1,21 @@
|
||||
import time
|
||||
|
||||
start_time = time.time()
|
||||
|
||||
import argparse
|
||||
from typing import Union, Sequence
|
||||
|
||||
|
||||
def get_args(args: Union[Sequence[str], None] = None):
|
||||
parser = argparse.ArgumentParser()
|
||||
group = parser.add_argument_group(title="server arguments")
|
||||
group.add_argument(
|
||||
"--port",
|
||||
type=int,
|
||||
default=8000,
|
||||
help="port to run the server on (default: 8000)",
|
||||
)
|
||||
group.add_argument(
|
||||
"--host",
|
||||
type=str,
|
||||
default="127.0.0.1",
|
||||
help="host to run the server on (default: 127.0.0.1)",
|
||||
)
|
||||
group = parser.add_argument_group(title="mode arguments")
|
||||
group.add_argument(
|
||||
"--webui",
|
||||
action="store_true",
|
||||
help="whether to enable WebUI (default: False)",
|
||||
)
|
||||
group.add_argument(
|
||||
"--rwkv.cpp",
|
||||
action="store_true",
|
||||
help="whether to use rwkv.cpp (default: False)",
|
||||
)
|
||||
group.add_argument(
|
||||
"--webgpu",
|
||||
action="store_true",
|
||||
help="whether to use webgpu (default: False)",
|
||||
)
|
||||
args = parser.parse_args(args)
|
||||
|
||||
return args
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
args = get_args()
|
||||
|
||||
|
||||
import os
|
||||
import sys
|
||||
|
||||
sys.path.append(os.path.dirname(os.path.realpath(__file__)))
|
||||
|
||||
import psutil
|
||||
from contextlib import asynccontextmanager
|
||||
from fastapi import Depends, FastAPI, status
|
||||
from fastapi import FastAPI
|
||||
from fastapi.middleware.cors import CORSMiddleware
|
||||
import uvicorn
|
||||
|
||||
from utils.rwkv import *
|
||||
from utils.torch import *
|
||||
from utils.ngrok import *
|
||||
from utils.log import log_middleware
|
||||
from routes import completion, config, state_cache, midi, misc, file_process
|
||||
from routes import completion, config
|
||||
import global_var
|
||||
|
||||
|
||||
@asynccontextmanager
|
||||
async def lifespan(app: FastAPI):
|
||||
init()
|
||||
yield
|
||||
|
||||
|
||||
app = FastAPI(lifespan=lifespan, dependencies=[Depends(log_middleware)])
|
||||
app = FastAPI()
|
||||
|
||||
app.add_middleware(
|
||||
CORSMiddleware,
|
||||
@ -83,49 +27,11 @@ app.add_middleware(
|
||||
|
||||
app.include_router(completion.router)
|
||||
app.include_router(config.router)
|
||||
app.include_router(midi.router)
|
||||
app.include_router(file_process.router)
|
||||
app.include_router(misc.router)
|
||||
app.include_router(state_cache.router)
|
||||
|
||||
|
||||
@app.post("/exit", tags=["Root"])
|
||||
def exit():
|
||||
if global_var.get(global_var.Deploy_Mode) is True:
|
||||
raise HTTPException(status.HTTP_403_FORBIDDEN)
|
||||
|
||||
parent_pid = os.getpid()
|
||||
parent = psutil.Process(parent_pid)
|
||||
for child in parent.children(recursive=True):
|
||||
child.kill()
|
||||
parent.kill()
|
||||
|
||||
|
||||
try:
|
||||
if (
|
||||
"RWKV_RUNNER_PARAMS" in os.environ
|
||||
and "--webui" in os.environ["RWKV_RUNNER_PARAMS"].split(" ")
|
||||
) or args.webui:
|
||||
from webui_server import webui_server
|
||||
|
||||
app.mount("/", webui_server)
|
||||
except NameError:
|
||||
pass
|
||||
|
||||
|
||||
@app.get("/", tags=["Root"])
|
||||
def read_root():
|
||||
return {"Hello": "World!"}
|
||||
|
||||
|
||||
@app.on_event("startup")
|
||||
def init():
|
||||
global_var.init()
|
||||
cmd_params = os.environ["RWKV_RUNNER_PARAMS"]
|
||||
global_var.set(
|
||||
global_var.Args, get_args(cmd_params.split(" ") if cmd_params else None)
|
||||
)
|
||||
|
||||
state_cache.init()
|
||||
|
||||
set_torch()
|
||||
|
||||
@ -133,7 +39,30 @@ def init():
|
||||
ngrok_connect()
|
||||
|
||||
|
||||
@app.get("/")
|
||||
def read_root():
|
||||
return {"Hello": "World!", "pid": os.getpid()}
|
||||
|
||||
|
||||
@app.post("/exit")
|
||||
def exit():
|
||||
parent_pid = os.getpid()
|
||||
parent = psutil.Process(parent_pid)
|
||||
for child in parent.children(recursive=True):
|
||||
child.kill()
|
||||
parent.kill()
|
||||
|
||||
|
||||
def debug():
|
||||
model = RWKV(
|
||||
model="../models/RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.pth",
|
||||
strategy="cuda fp16",
|
||||
tokens_path="20B_tokenizer.json",
|
||||
)
|
||||
d = model.tokenizer.decode([])
|
||||
print(d)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
os.environ["RWKV_RUNNER_PARAMS"] = " ".join(sys.argv[1:])
|
||||
print("--- %s seconds ---" % (time.time() - start_time))
|
||||
uvicorn.run("main:app", port=args.port, host=args.host, workers=1)
|
||||
uvicorn.run("main:app", port=8000 if len(sys.argv) == 1 else int(sys.argv[1]))
|
||||
# debug()
|
||||
|
||||
Binary file not shown.
BIN
backend-python/requirements_versions.txt
Normal file
BIN
backend-python/requirements_versions.txt
Normal file
Binary file not shown.
@ -1,24 +0,0 @@
|
||||
torch
|
||||
torchvision
|
||||
torchaudio
|
||||
setuptools==69.5.1
|
||||
rwkv==0.8.26
|
||||
langchain==0.0.322
|
||||
fastapi==0.109.1
|
||||
uvicorn==0.23.2
|
||||
sse-starlette==1.6.5
|
||||
pydantic==2.4.2
|
||||
psutil==5.9.6
|
||||
gputil==1.4.0
|
||||
tiktoken==0.5.1
|
||||
ftfy==6.1.1
|
||||
lm-dataformat==0.0.20
|
||||
numpy==1.24.4
|
||||
tokenizers==0.14.1
|
||||
tqdm==4.66.1
|
||||
midi2audio==0.1.1
|
||||
mido==1.3.0
|
||||
safetensors==0.4.0
|
||||
PyMuPDF==1.23.5
|
||||
python-multipart==0.0.7
|
||||
Cython==3.0.4
|
||||
@ -1,582 +1,229 @@
|
||||
import asyncio
|
||||
import json
|
||||
from threading import Lock
|
||||
from typing import List, Union
|
||||
from enum import Enum
|
||||
import base64
|
||||
import time
|
||||
from typing import List
|
||||
|
||||
from fastapi import APIRouter, Request, status, HTTPException
|
||||
from sse_starlette.sse import EventSourceResponse
|
||||
from pydantic import BaseModel, Field
|
||||
import tiktoken
|
||||
from pydantic import BaseModel
|
||||
from utils.rwkv import *
|
||||
from utils.log import quick_log
|
||||
import global_var
|
||||
|
||||
router = APIRouter()
|
||||
|
||||
|
||||
class Role(Enum):
|
||||
User = "user"
|
||||
Assistant = "assistant"
|
||||
System = "system"
|
||||
|
||||
|
||||
class Message(BaseModel):
|
||||
role: Role
|
||||
content: str = Field(min_length=0)
|
||||
raw: bool = Field(False, description="Whether to treat content as raw text")
|
||||
|
||||
|
||||
default_stop = [
|
||||
"\n\nUser",
|
||||
"\n\nQuestion",
|
||||
"\n\nQ",
|
||||
"\n\nHuman",
|
||||
"\n\nBob",
|
||||
"\n\nAssistant",
|
||||
"\n\nAnswer",
|
||||
"\n\nA",
|
||||
"\n\nBot",
|
||||
"\n\nAlice",
|
||||
]
|
||||
role: str
|
||||
content: str
|
||||
|
||||
|
||||
class ChatCompletionBody(ModelConfigBody):
|
||||
messages: Union[List[Message], None]
|
||||
model: Union[str, None] = "rwkv"
|
||||
messages: List[Message]
|
||||
model: str = "rwkv"
|
||||
stream: bool = False
|
||||
stop: Union[str, List[str], None] = default_stop
|
||||
user_name: Union[str, None] = Field(
|
||||
None, description="Internal user name", min_length=1
|
||||
)
|
||||
assistant_name: Union[str, None] = Field(
|
||||
None, description="Internal assistant name", min_length=1
|
||||
)
|
||||
system_name: Union[str, None] = Field(
|
||||
None, description="Internal system name", min_length=1
|
||||
)
|
||||
presystem: bool = Field(
|
||||
False, description="Whether to insert default system prompt at the beginning"
|
||||
)
|
||||
|
||||
model_config = {
|
||||
"json_schema_extra": {
|
||||
"example": {
|
||||
"messages": [
|
||||
{"role": Role.User.value, "content": "hello", "raw": False}
|
||||
],
|
||||
"model": "rwkv",
|
||||
"stream": False,
|
||||
"stop": None,
|
||||
"user_name": None,
|
||||
"assistant_name": None,
|
||||
"system_name": None,
|
||||
"presystem": True,
|
||||
"max_tokens": 1000,
|
||||
"temperature": 1,
|
||||
"top_p": 0.3,
|
||||
"presence_penalty": 0,
|
||||
"frequency_penalty": 1,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
class CompletionBody(ModelConfigBody):
|
||||
prompt: Union[str, List[str], None]
|
||||
model: Union[str, None] = "rwkv"
|
||||
stream: bool = False
|
||||
stop: Union[str, List[str], None] = None
|
||||
|
||||
model_config = {
|
||||
"json_schema_extra": {
|
||||
"example": {
|
||||
"prompt": "The following is an epic science fiction masterpiece that is immortalized, "
|
||||
+ "with delicate descriptions and grand depictions of interstellar civilization wars.\nChapter 1.\n",
|
||||
"model": "rwkv",
|
||||
"stream": False,
|
||||
"stop": None,
|
||||
"max_tokens": 100,
|
||||
"temperature": 1,
|
||||
"top_p": 0.3,
|
||||
"presence_penalty": 0,
|
||||
"frequency_penalty": 1,
|
||||
}
|
||||
}
|
||||
}
|
||||
stop: str = None
|
||||
|
||||
|
||||
completion_lock = Lock()
|
||||
|
||||
requests_num = 0
|
||||
|
||||
@router.post("/v1/chat/completions")
|
||||
@router.post("/chat/completions")
|
||||
async def chat_completions(body: ChatCompletionBody, request: Request):
|
||||
model: RWKV = global_var.get(global_var.Model)
|
||||
if model is None:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "model not loaded")
|
||||
|
||||
async def eval_rwkv(
|
||||
model: AbstractRWKV,
|
||||
request: Request,
|
||||
body: ModelConfigBody,
|
||||
prompt: str,
|
||||
stream: bool,
|
||||
stop: Union[str, List[str], None],
|
||||
chat_mode: bool,
|
||||
):
|
||||
global requests_num
|
||||
requests_num = requests_num + 1
|
||||
quick_log(request, None, "Start Waiting. RequestsNum: " + str(requests_num))
|
||||
while completion_lock.locked():
|
||||
if await request.is_disconnected():
|
||||
requests_num = requests_num - 1
|
||||
print(f"{request.client} Stop Waiting (Lock)")
|
||||
quick_log(
|
||||
request,
|
||||
None,
|
||||
"Stop Waiting (Lock). RequestsNum: " + str(requests_num),
|
||||
)
|
||||
return
|
||||
await asyncio.sleep(0.1)
|
||||
question = body.messages[-1]
|
||||
if question.role == "user":
|
||||
question = question.content
|
||||
else:
|
||||
with completion_lock:
|
||||
if await request.is_disconnected():
|
||||
requests_num = requests_num - 1
|
||||
print(f"{request.client} Stop Waiting (Lock)")
|
||||
quick_log(
|
||||
request,
|
||||
None,
|
||||
"Stop Waiting (Lock). RequestsNum: " + str(requests_num),
|
||||
)
|
||||
return
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "no question found")
|
||||
|
||||
completion_text = ""
|
||||
for message in body.messages:
|
||||
if message.role == "user":
|
||||
completion_text += (
|
||||
"Bob: "
|
||||
+ message.content.replace("\\n", "\n")
|
||||
.replace("\r\n", "\n")
|
||||
.replace("\n\n", "\n")
|
||||
.strip()
|
||||
+ "\n\n"
|
||||
)
|
||||
elif message.role == "assistant":
|
||||
completion_text += (
|
||||
"Alice: "
|
||||
+ message.content.replace("\\n", "\n")
|
||||
.replace("\r\n", "\n")
|
||||
.replace("\n\n", "\n")
|
||||
.strip()
|
||||
+ "\n\n"
|
||||
)
|
||||
completion_text += "Alice:"
|
||||
|
||||
async def eval_rwkv():
|
||||
while completion_lock.locked():
|
||||
await asyncio.sleep(0.1)
|
||||
else:
|
||||
completion_lock.acquire()
|
||||
set_rwkv_config(model, global_var.get(global_var.Model_Config))
|
||||
set_rwkv_config(model, body)
|
||||
print(get_rwkv_config(model))
|
||||
|
||||
response, prompt_tokens, completion_tokens = "", 0, 0
|
||||
completion_start_time = None
|
||||
for response, delta, prompt_tokens, completion_tokens in model.generate(
|
||||
prompt,
|
||||
stop=stop,
|
||||
):
|
||||
if not completion_start_time:
|
||||
completion_start_time = time.time()
|
||||
if await request.is_disconnected():
|
||||
break
|
||||
if stream:
|
||||
if body.stream:
|
||||
for response, delta in rwkv_generate(
|
||||
model,
|
||||
completion_text,
|
||||
stop="\n\nBob" if body.stop is None else body.stop,
|
||||
):
|
||||
if await request.is_disconnected():
|
||||
break
|
||||
yield json.dumps(
|
||||
{
|
||||
"object": (
|
||||
"chat.completion.chunk"
|
||||
if chat_mode
|
||||
else "text_completion"
|
||||
),
|
||||
# "response": response,
|
||||
"model": model.name,
|
||||
"id": "chatcmpl-123",
|
||||
"system_fingerprint": "fp_44709d6fcb",
|
||||
"response": response,
|
||||
"model": "rwkv",
|
||||
"choices": [
|
||||
(
|
||||
{
|
||||
"delta": {"role":Role.Assistant.value,"content": delta},
|
||||
"index": 0,
|
||||
"finish_reason": None,
|
||||
"logprobs":None
|
||||
}
|
||||
if chat_mode
|
||||
else {
|
||||
"text": delta,
|
||||
"index": 0,
|
||||
"finish_reason": None,
|
||||
}
|
||||
)
|
||||
{
|
||||
"delta": {"content": delta},
|
||||
"index": 0,
|
||||
"finish_reason": None,
|
||||
}
|
||||
],
|
||||
}
|
||||
)
|
||||
# torch_gc()
|
||||
requests_num = requests_num - 1
|
||||
completion_end_time = time.time()
|
||||
completion_interval = completion_end_time - completion_start_time
|
||||
tps = 0
|
||||
if completion_interval > 0:
|
||||
tps = completion_tokens / completion_interval
|
||||
print(f"Generation TPS: {tps:.2f}")
|
||||
|
||||
if await request.is_disconnected():
|
||||
print(f"{request.client} Stop Waiting")
|
||||
quick_log(
|
||||
request,
|
||||
body,
|
||||
response + "\nStop Waiting. RequestsNum: " + str(requests_num),
|
||||
)
|
||||
return
|
||||
quick_log(
|
||||
request,
|
||||
body,
|
||||
response + "\nFinished. RequestsNum: " + str(requests_num),
|
||||
)
|
||||
if stream:
|
||||
if await request.is_disconnected():
|
||||
completion_lock.release()
|
||||
return
|
||||
yield json.dumps(
|
||||
{
|
||||
"object": (
|
||||
"chat.completion.chunk" if chat_mode else "text_completion"
|
||||
),
|
||||
# "response": response,
|
||||
"model": model.name,
|
||||
"id": "chatcmpl-123",
|
||||
"system_fingerprint": "fp_44709d6fcb",
|
||||
"response": response,
|
||||
"model": "rwkv",
|
||||
"choices": [
|
||||
(
|
||||
{
|
||||
"delta": {},
|
||||
"index": 0,
|
||||
"logprobs": None,
|
||||
"finish_reason": "stop",
|
||||
}
|
||||
if chat_mode
|
||||
else {
|
||||
"text": "",
|
||||
"index": 0,
|
||||
"finish_reason": "stop",
|
||||
}
|
||||
)
|
||||
{
|
||||
"delta": {},
|
||||
"index": 0,
|
||||
"finish_reason": "stop",
|
||||
}
|
||||
],
|
||||
}
|
||||
)
|
||||
yield "[DONE]"
|
||||
else:
|
||||
response = None
|
||||
for response, delta in rwkv_generate(
|
||||
model,
|
||||
completion_text,
|
||||
stop="\n\nBob" if body.stop is None else body.stop,
|
||||
):
|
||||
if await request.is_disconnected():
|
||||
break
|
||||
if await request.is_disconnected():
|
||||
completion_lock.release()
|
||||
return
|
||||
yield {
|
||||
"object": "chat.completion" if chat_mode else "text_completion",
|
||||
# "response": response,
|
||||
"model": model.name,
|
||||
"usage": {
|
||||
"prompt_tokens": prompt_tokens,
|
||||
"completion_tokens": completion_tokens,
|
||||
"total_tokens": prompt_tokens + completion_tokens,
|
||||
},
|
||||
"response": response,
|
||||
"model": "rwkv",
|
||||
"choices": [
|
||||
(
|
||||
{
|
||||
"message": {
|
||||
"role": Role.Assistant.value,
|
||||
"content": response,
|
||||
},
|
||||
"index": 0,
|
||||
"finish_reason": "stop",
|
||||
}
|
||||
if chat_mode
|
||||
else {
|
||||
"text": response,
|
||||
"index": 0,
|
||||
"finish_reason": "stop",
|
||||
}
|
||||
)
|
||||
{
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": response,
|
||||
},
|
||||
"index": 0,
|
||||
"finish_reason": "stop",
|
||||
}
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
def chat_template_old(
|
||||
model: TextRWKV, body: ChatCompletionBody, interface: str, user: str, bot: str
|
||||
):
|
||||
is_raven = model.rwkv_type == RWKVType.Raven
|
||||
|
||||
completion_text: str = ""
|
||||
basic_system: Union[str, None] = None
|
||||
if body.presystem:
|
||||
if body.messages[0].role == Role.System:
|
||||
basic_system = body.messages[0].content
|
||||
|
||||
if basic_system is None:
|
||||
completion_text = (
|
||||
f"""
|
||||
The following is a coherent verbose detailed conversation between a girl named {bot} and her friend {user}. \
|
||||
{bot} is very intelligent, creative and friendly. \
|
||||
{bot} is unlikely to disagree with {user}, and {bot} doesn't like to ask {user} questions. \
|
||||
{bot} likes to tell {user} a lot about herself and her opinions. \
|
||||
{bot} usually gives {user} kind, helpful and informative advices.\n
|
||||
"""
|
||||
if is_raven
|
||||
else (
|
||||
f"{user}{interface} hi\n\n{bot}{interface} Hi. "
|
||||
+ "I am your assistant and I will provide expert full response in full details. Please feel free to ask any question and I will always answer it.\n\n"
|
||||
)
|
||||
)
|
||||
else:
|
||||
if not body.messages[0].raw:
|
||||
basic_system = (
|
||||
basic_system.replace("\r\n", "\n")
|
||||
.replace("\r", "\n")
|
||||
.replace("\n\n", "\n")
|
||||
.replace("\n", " ")
|
||||
.strip()
|
||||
)
|
||||
completion_text = (
|
||||
(
|
||||
f"The following is a coherent verbose detailed conversation between a girl named {bot} and her friend {user}. "
|
||||
if is_raven
|
||||
else f"{user}{interface} hi\n\n{bot}{interface} Hi. "
|
||||
)
|
||||
+ basic_system.replace("You are", f"{bot} is" if is_raven else "I am")
|
||||
.replace("you are", f"{bot} is" if is_raven else "I am")
|
||||
.replace("You're", f"{bot} is" if is_raven else "I'm")
|
||||
.replace("you're", f"{bot} is" if is_raven else "I'm")
|
||||
.replace("You", f"{bot}" if is_raven else "I")
|
||||
.replace("you", f"{bot}" if is_raven else "I")
|
||||
.replace("Your", f"{bot}'s" if is_raven else "My")
|
||||
.replace("your", f"{bot}'s" if is_raven else "my")
|
||||
.replace("你", f"{bot}" if is_raven else "我")
|
||||
+ "\n\n"
|
||||
)
|
||||
|
||||
for message in body.messages[(0 if basic_system is None else 1) :]:
|
||||
append_message: str = ""
|
||||
if message.role == Role.User:
|
||||
append_message = f"{user}{interface} " + message.content
|
||||
elif message.role == Role.Assistant:
|
||||
append_message = f"{bot}{interface} " + message.content
|
||||
elif message.role == Role.System:
|
||||
append_message = message.content
|
||||
if not message.raw:
|
||||
append_message = (
|
||||
append_message.replace("\r\n", "\n")
|
||||
.replace("\r", "\n")
|
||||
.replace("\n\n", "\n")
|
||||
.strip()
|
||||
)
|
||||
completion_text += append_message + "\n\n"
|
||||
completion_text += f"{bot}{interface}"
|
||||
|
||||
return completion_text
|
||||
|
||||
|
||||
def chat_template(
|
||||
model: TextRWKV, body: ChatCompletionBody, interface: str, user: str, bot: str
|
||||
):
|
||||
completion_text: str = ""
|
||||
if body.presystem:
|
||||
completion_text = (
|
||||
f"{user}{interface} hi\n\n{bot}{interface} Hi. "
|
||||
+ "I am your assistant and I will provide expert full response in full details. Please feel free to ask any question and I will always answer it.\n\n"
|
||||
)
|
||||
|
||||
system = "System" if body.system_name is None else body.system_name
|
||||
for message in body.messages:
|
||||
append_message: str = ""
|
||||
if message.role == Role.User:
|
||||
append_message = f"{user}{interface} " + message.content
|
||||
elif message.role == Role.Assistant:
|
||||
append_message = f"{bot}{interface} " + message.content
|
||||
elif message.role == Role.System:
|
||||
append_message = f"{system}{interface} " + message.content
|
||||
completion_text += append_message + "\n\n"
|
||||
completion_text += f"{bot}{interface}"
|
||||
|
||||
return completion_text
|
||||
|
||||
|
||||
@router.post("/v1/chat/completions", tags=["Completions"])
|
||||
@router.post("/chat/completions", tags=["Completions"])
|
||||
async def chat_completions(body: ChatCompletionBody, request: Request):
|
||||
model: TextRWKV = global_var.get(global_var.Model)
|
||||
if model is None:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "model not loaded")
|
||||
|
||||
if body.messages is None or body.messages == []:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "messages not found")
|
||||
|
||||
interface = model.interface
|
||||
user = model.user if body.user_name is None else body.user_name
|
||||
bot = model.bot if body.assistant_name is None else body.assistant_name
|
||||
|
||||
if model.version < 5:
|
||||
completion_text = chat_template_old(model, body, interface, user, bot)
|
||||
else:
|
||||
completion_text = chat_template(model, body, interface, user, bot)
|
||||
|
||||
user_code = model.pipeline.decode([model.pipeline.encode(user)[0]])
|
||||
bot_code = model.pipeline.decode([model.pipeline.encode(bot)[0]])
|
||||
if type(body.stop) == str:
|
||||
body.stop = [body.stop, f"\n\n{user_code}", f"\n\n{bot_code}"]
|
||||
elif type(body.stop) == list:
|
||||
body.stop.append(f"\n\n{user_code}")
|
||||
body.stop.append(f"\n\n{bot_code}")
|
||||
elif body.stop is None:
|
||||
body.stop = default_stop + [f"\n\n{user_code}", f"\n\n{bot_code}"]
|
||||
# if not body.presystem:
|
||||
# body.stop.append("\n\n")
|
||||
# torch_gc()
|
||||
completion_lock.release()
|
||||
|
||||
if body.stream:
|
||||
return EventSourceResponse(
|
||||
eval_rwkv(
|
||||
model, request, body, completion_text, body.stream, body.stop, True
|
||||
)
|
||||
)
|
||||
return EventSourceResponse(eval_rwkv())
|
||||
else:
|
||||
try:
|
||||
return await eval_rwkv(
|
||||
model, request, body, completion_text, body.stream, body.stop, True
|
||||
).__anext__()
|
||||
except StopAsyncIteration:
|
||||
return None
|
||||
return await eval_rwkv().__anext__()
|
||||
|
||||
|
||||
@router.post("/v1/completions", tags=["Completions"])
|
||||
@router.post("/completions", tags=["Completions"])
|
||||
class CompletionBody(ModelConfigBody):
|
||||
prompt: str
|
||||
model: str = "rwkv"
|
||||
stream: bool = False
|
||||
stop: str = None
|
||||
|
||||
|
||||
@router.post("/v1/completions")
|
||||
@router.post("/completions")
|
||||
async def completions(body: CompletionBody, request: Request):
|
||||
model: AbstractRWKV = global_var.get(global_var.Model)
|
||||
model: RWKV = global_var.get(global_var.Model)
|
||||
if model is None:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "model not loaded")
|
||||
|
||||
if body.prompt is None or body.prompt == "" or body.prompt == []:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "prompt not found")
|
||||
|
||||
if type(body.prompt) == list:
|
||||
body.prompt = body.prompt[0] # TODO: support multiple prompts
|
||||
async def eval_rwkv():
|
||||
while completion_lock.locked():
|
||||
await asyncio.sleep(0.1)
|
||||
else:
|
||||
completion_lock.acquire()
|
||||
set_rwkv_config(model, global_var.get(global_var.Model_Config))
|
||||
set_rwkv_config(model, body)
|
||||
if body.stream:
|
||||
for response, delta in rwkv_generate(
|
||||
model, body.prompt, stop=body.stop
|
||||
):
|
||||
if await request.is_disconnected():
|
||||
break
|
||||
yield json.dumps(
|
||||
{
|
||||
"response": response,
|
||||
"model": "rwkv",
|
||||
"choices": [
|
||||
{
|
||||
"text": delta,
|
||||
"index": 0,
|
||||
"finish_reason": None,
|
||||
}
|
||||
],
|
||||
}
|
||||
)
|
||||
if await request.is_disconnected():
|
||||
completion_lock.release()
|
||||
return
|
||||
yield json.dumps(
|
||||
{
|
||||
"response": response,
|
||||
"model": "rwkv",
|
||||
"choices": [
|
||||
{
|
||||
"text": "",
|
||||
"index": 0,
|
||||
"finish_reason": "stop",
|
||||
}
|
||||
],
|
||||
}
|
||||
)
|
||||
yield "[DONE]"
|
||||
else:
|
||||
response = None
|
||||
for response, delta in rwkv_generate(
|
||||
model, body.prompt, stop=body.stop
|
||||
):
|
||||
if await request.is_disconnected():
|
||||
break
|
||||
if await request.is_disconnected():
|
||||
completion_lock.release()
|
||||
return
|
||||
yield {
|
||||
"response": response,
|
||||
"model": "rwkv",
|
||||
"choices": [
|
||||
{
|
||||
"text": response,
|
||||
"index": 0,
|
||||
"finish_reason": "stop",
|
||||
}
|
||||
],
|
||||
}
|
||||
# torch_gc()
|
||||
completion_lock.release()
|
||||
|
||||
if body.stream:
|
||||
return EventSourceResponse(
|
||||
eval_rwkv(model, request, body, body.prompt, body.stream, body.stop, False)
|
||||
)
|
||||
return EventSourceResponse(eval_rwkv())
|
||||
else:
|
||||
try:
|
||||
return await eval_rwkv(
|
||||
model, request, body, body.prompt, body.stream, body.stop, False
|
||||
).__anext__()
|
||||
except StopAsyncIteration:
|
||||
return None
|
||||
|
||||
|
||||
class EmbeddingsBody(BaseModel):
|
||||
input: Union[str, List[str], List[List[int]], None]
|
||||
model: Union[str, None] = "rwkv"
|
||||
encoding_format: str = None
|
||||
fast_mode: bool = False
|
||||
|
||||
model_config = {
|
||||
"json_schema_extra": {
|
||||
"example": {
|
||||
"input": "a big apple",
|
||||
"model": "rwkv",
|
||||
"encoding_format": None,
|
||||
"fast_mode": False,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
def embedding_base64(embedding: List[float]) -> str:
|
||||
import numpy as np
|
||||
|
||||
return base64.b64encode(np.array(embedding).astype(np.float32)).decode("utf-8")
|
||||
|
||||
|
||||
@router.post("/v1/embeddings", tags=["Embeddings"])
|
||||
@router.post("/embeddings", tags=["Embeddings"])
|
||||
@router.post("/v1/engines/text-embedding-ada-002/embeddings", tags=["Embeddings"])
|
||||
@router.post("/engines/text-embedding-ada-002/embeddings", tags=["Embeddings"])
|
||||
async def embeddings(body: EmbeddingsBody, request: Request):
|
||||
model: AbstractRWKV = global_var.get(global_var.Model)
|
||||
if model is None:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "model not loaded")
|
||||
|
||||
if body.input is None or body.input == "" or body.input == [] or body.input == [[]]:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "input not found")
|
||||
|
||||
global requests_num
|
||||
requests_num = requests_num + 1
|
||||
quick_log(request, None, "Start Waiting. RequestsNum: " + str(requests_num))
|
||||
while completion_lock.locked():
|
||||
if await request.is_disconnected():
|
||||
requests_num = requests_num - 1
|
||||
print(f"{request.client} Stop Waiting (Lock)")
|
||||
quick_log(
|
||||
request,
|
||||
None,
|
||||
"Stop Waiting (Lock). RequestsNum: " + str(requests_num),
|
||||
)
|
||||
return
|
||||
await asyncio.sleep(0.1)
|
||||
else:
|
||||
with completion_lock:
|
||||
if await request.is_disconnected():
|
||||
requests_num = requests_num - 1
|
||||
print(f"{request.client} Stop Waiting (Lock)")
|
||||
quick_log(
|
||||
request,
|
||||
None,
|
||||
"Stop Waiting (Lock). RequestsNum: " + str(requests_num),
|
||||
)
|
||||
return
|
||||
|
||||
base64_format = False
|
||||
if body.encoding_format == "base64":
|
||||
base64_format = True
|
||||
|
||||
embeddings = []
|
||||
prompt_tokens = 0
|
||||
if type(body.input) == list:
|
||||
if type(body.input[0]) == list:
|
||||
encoding = tiktoken.model.encoding_for_model(
|
||||
"text-embedding-ada-002"
|
||||
)
|
||||
for i in range(len(body.input)):
|
||||
if await request.is_disconnected():
|
||||
break
|
||||
input = encoding.decode(body.input[i])
|
||||
embedding, token_len = model.get_embedding(
|
||||
input, body.fast_mode
|
||||
)
|
||||
prompt_tokens = prompt_tokens + token_len
|
||||
if base64_format:
|
||||
embedding = embedding_base64(embedding)
|
||||
embeddings.append(embedding)
|
||||
else:
|
||||
for i in range(len(body.input)):
|
||||
if await request.is_disconnected():
|
||||
break
|
||||
embedding, token_len = model.get_embedding(
|
||||
body.input[i], body.fast_mode
|
||||
)
|
||||
prompt_tokens = prompt_tokens + token_len
|
||||
if base64_format:
|
||||
embedding = embedding_base64(embedding)
|
||||
embeddings.append(embedding)
|
||||
else:
|
||||
embedding, prompt_tokens = model.get_embedding(
|
||||
body.input, body.fast_mode
|
||||
)
|
||||
if base64_format:
|
||||
embedding = embedding_base64(embedding)
|
||||
embeddings.append(embedding)
|
||||
|
||||
requests_num = requests_num - 1
|
||||
if await request.is_disconnected():
|
||||
print(f"{request.client} Stop Waiting")
|
||||
quick_log(
|
||||
request,
|
||||
None,
|
||||
"Stop Waiting. RequestsNum: " + str(requests_num),
|
||||
)
|
||||
return
|
||||
quick_log(
|
||||
request,
|
||||
None,
|
||||
"Finished. RequestsNum: " + str(requests_num),
|
||||
)
|
||||
|
||||
ret_data = [
|
||||
{
|
||||
"object": "embedding",
|
||||
"index": i,
|
||||
"embedding": embedding,
|
||||
}
|
||||
for i, embedding in enumerate(embeddings)
|
||||
]
|
||||
|
||||
return {
|
||||
"object": "list",
|
||||
"data": ret_data,
|
||||
"model": model.name,
|
||||
"usage": {
|
||||
"prompt_tokens": prompt_tokens,
|
||||
"total_tokens": prompt_tokens,
|
||||
},
|
||||
}
|
||||
return await eval_rwkv().__anext__()
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
import pathlib
|
||||
from utils.log import quick_log
|
||||
|
||||
from fastapi import APIRouter, HTTPException, Request, Response, status as Status
|
||||
from fastapi import APIRouter, HTTPException, Response, status
|
||||
from pydantic import BaseModel
|
||||
from langchain.llms import RWKV
|
||||
from utils.rwkv import *
|
||||
from utils.torch import *
|
||||
import global_var
|
||||
@ -13,137 +13,54 @@ router = APIRouter()
|
||||
class SwitchModelBody(BaseModel):
|
||||
model: str
|
||||
strategy: str
|
||||
tokenizer: Union[str, None] = None
|
||||
customCuda: bool = False
|
||||
deploy: bool = Field(
|
||||
False,
|
||||
description="Deploy mode. If success, will disable /switch-model, /exit and other dangerous APIs (state cache APIs, part of midi APIs)",
|
||||
)
|
||||
|
||||
model_config = {
|
||||
"json_schema_extra": {
|
||||
"example": {
|
||||
"model": "models/RWKV-4-World-3B-v1-20230619-ctx4096.pth",
|
||||
"strategy": "cuda fp16",
|
||||
"tokenizer": "",
|
||||
"customCuda": False,
|
||||
"deploy": False,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@router.post("/switch-model", tags=["Configs"])
|
||||
def switch_model(body: SwitchModelBody, response: Response, request: Request):
|
||||
if global_var.get(global_var.Deploy_Mode) is True:
|
||||
raise HTTPException(Status.HTTP_403_FORBIDDEN)
|
||||
|
||||
@router.post("/switch-model")
|
||||
def switch_model(body: SwitchModelBody, response: Response):
|
||||
if global_var.get(global_var.Model_Status) is global_var.ModelStatus.Loading:
|
||||
response.status_code = Status.HTTP_304_NOT_MODIFIED
|
||||
response.status_code = status.HTTP_304_NOT_MODIFIED
|
||||
return
|
||||
|
||||
global_var.set(global_var.Model_Status, global_var.ModelStatus.Offline)
|
||||
global_var.set(global_var.Model, None)
|
||||
torch_gc()
|
||||
|
||||
if body.model == "":
|
||||
return "success"
|
||||
|
||||
devices = set(
|
||||
[
|
||||
x.strip().split(" ")[0].replace("cuda:0", "cuda")
|
||||
for x in body.strategy.split("->")
|
||||
]
|
||||
)
|
||||
print(f"Strategy Devices: {devices}")
|
||||
# if len(devices) > 1:
|
||||
# state_cache.disable_state_cache()
|
||||
# else:
|
||||
try:
|
||||
state_cache.enable_state_cache()
|
||||
except HTTPException:
|
||||
pass
|
||||
|
||||
os.environ["RWKV_CUDA_ON"] = "1" if body.customCuda else "0"
|
||||
|
||||
global_var.set(global_var.Model_Status, global_var.ModelStatus.Loading)
|
||||
try:
|
||||
global_var.set(
|
||||
global_var.Model,
|
||||
RWKV(model=body.model, strategy=body.strategy, tokenizer=body.tokenizer),
|
||||
RWKV(
|
||||
model=body.model,
|
||||
strategy=body.strategy,
|
||||
tokens_path=f"{pathlib.Path(__file__).parent.parent.resolve()}/20B_tokenizer.json",
|
||||
),
|
||||
)
|
||||
except Exception as e:
|
||||
print(e)
|
||||
import traceback
|
||||
|
||||
print(traceback.format_exc())
|
||||
|
||||
quick_log(request, body, f"Exception: {e}")
|
||||
global_var.set(global_var.Model_Status, global_var.ModelStatus.Offline)
|
||||
raise HTTPException(
|
||||
Status.HTTP_500_INTERNAL_SERVER_ERROR, f"failed to load: {e}"
|
||||
raise HTTPException(status.HTTP_500_INTERNAL_SERVER_ERROR, "failed to load")
|
||||
|
||||
if global_var.get(global_var.Model_Config) is None:
|
||||
global_var.set(
|
||||
global_var.Model_Config, get_rwkv_config(global_var.get(global_var.Model))
|
||||
)
|
||||
|
||||
if body.deploy:
|
||||
global_var.set(global_var.Deploy_Mode, True)
|
||||
|
||||
saved_model_config = global_var.get(global_var.Model_Config)
|
||||
init_model_config = get_rwkv_config(global_var.get(global_var.Model))
|
||||
if saved_model_config is not None:
|
||||
merge_model(init_model_config, saved_model_config)
|
||||
global_var.set(global_var.Model_Config, init_model_config)
|
||||
global_var.set(global_var.Model_Status, global_var.ModelStatus.Working)
|
||||
|
||||
return "success"
|
||||
|
||||
|
||||
def merge_model(to_model: BaseModel, from_model: BaseModel):
|
||||
from_model_fields = [x for x in from_model.dict().keys()]
|
||||
to_model_fields = [x for x in to_model.dict().keys()]
|
||||
|
||||
for field_name in from_model_fields:
|
||||
if field_name in to_model_fields:
|
||||
from_value = getattr(from_model, field_name)
|
||||
|
||||
if from_value is not None:
|
||||
setattr(to_model, field_name, from_value)
|
||||
|
||||
|
||||
@router.post("/update-config", tags=["Configs"])
|
||||
@router.post("/update-config")
|
||||
def update_config(body: ModelConfigBody):
|
||||
"""
|
||||
Will not update the model config immediately, but set it when completion called to avoid modifications during generation
|
||||
"""
|
||||
|
||||
model_config = global_var.get(global_var.Model_Config)
|
||||
if model_config is None:
|
||||
model_config = ModelConfigBody()
|
||||
global_var.set(global_var.Model_Config, model_config)
|
||||
merge_model(model_config, body)
|
||||
exception = load_rwkv_state(
|
||||
global_var.get(global_var.Model), model_config.state, True
|
||||
)
|
||||
if exception is not None:
|
||||
raise exception
|
||||
print("Updated Model Config:", model_config)
|
||||
print(body)
|
||||
global_var.set(global_var.Model_Config, body)
|
||||
|
||||
return "success"
|
||||
|
||||
|
||||
@router.get("/status", tags=["Configs"])
|
||||
@router.get("/status")
|
||||
def status():
|
||||
try:
|
||||
import GPUtil
|
||||
|
||||
gpus = GPUtil.getGPUs()
|
||||
except:
|
||||
gpus = []
|
||||
if len(gpus) == 0:
|
||||
device_name = "CPU"
|
||||
else:
|
||||
device_name = gpus[0].name
|
||||
return {
|
||||
"status": global_var.get(global_var.Model_Status),
|
||||
"pid": os.getpid(),
|
||||
"device_name": device_name,
|
||||
}
|
||||
return {"status": global_var.get(global_var.Model_Status)}
|
||||
|
||||
@ -1,79 +0,0 @@
|
||||
import os
|
||||
from fastapi import (
|
||||
APIRouter,
|
||||
HTTPException,
|
||||
status,
|
||||
Depends,
|
||||
File,
|
||||
UploadFile,
|
||||
)
|
||||
from pydantic import BaseModel
|
||||
from typing import Iterator
|
||||
|
||||
router = APIRouter()
|
||||
|
||||
|
||||
class FileToTextParams(BaseModel):
|
||||
file_name: str
|
||||
file_encoding: str = "utf-8"
|
||||
|
||||
|
||||
@router.post("/file-to-text", tags=["File Process"])
|
||||
async def file_to_text(
|
||||
params: FileToTextParams = Depends(), file_data: UploadFile = File(...)
|
||||
):
|
||||
from langchain.schema import Document
|
||||
from langchain.document_loaders.blob_loaders import Blob
|
||||
|
||||
# from langchain
|
||||
def parse_text(blob: Blob) -> Iterator[Document]:
|
||||
yield Document(page_content=blob.as_string(), metadata={"source": blob.source})
|
||||
|
||||
# from langchain
|
||||
def parse_pdf(blob: Blob) -> Iterator[Document]:
|
||||
import fitz
|
||||
|
||||
with blob.as_bytes_io() as stream:
|
||||
doc = fitz.Document(stream=stream)
|
||||
|
||||
yield from [
|
||||
Document(
|
||||
page_content=page.get_text(),
|
||||
metadata=dict(
|
||||
{
|
||||
"source": blob.source,
|
||||
"file_path": blob.source,
|
||||
"page": page.number,
|
||||
"total_pages": len(doc),
|
||||
},
|
||||
**{
|
||||
k: doc.metadata[k]
|
||||
for k in doc.metadata
|
||||
if type(doc.metadata[k]) in [str, int]
|
||||
},
|
||||
),
|
||||
)
|
||||
for page in doc
|
||||
]
|
||||
|
||||
file_parsers = {".txt": parse_text, ".pdf": parse_pdf}
|
||||
|
||||
file_name = file_data.filename or params.file_name
|
||||
file_ext = os.path.splitext(file_name)[-1]
|
||||
|
||||
if file_ext not in file_parsers:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "file type not supported")
|
||||
|
||||
try:
|
||||
pages: Iterator[Document] = file_parsers[file_ext](
|
||||
Blob.from_data(
|
||||
await file_data.read(),
|
||||
encoding=params.file_encoding,
|
||||
path=file_name,
|
||||
)
|
||||
)
|
||||
pages = list(pages)
|
||||
except Exception as e:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, f"{e}")
|
||||
|
||||
return {"pages": pages}
|
||||
@ -1,171 +0,0 @@
|
||||
import io
|
||||
import global_var
|
||||
from fastapi import APIRouter, HTTPException, UploadFile, status
|
||||
from starlette.responses import StreamingResponse
|
||||
from pydantic import BaseModel
|
||||
from utils.midi import *
|
||||
from midi2audio import FluidSynth
|
||||
|
||||
router = APIRouter()
|
||||
|
||||
|
||||
class TextToMidiBody(BaseModel):
|
||||
text: str
|
||||
|
||||
model_config = {
|
||||
"json_schema_extra": {
|
||||
"example": {
|
||||
"text": "p:24:a p:2a:a p:31:a p:39:a p:3b:a p:45:a b:26:a g:3e:a g:3e:a g:42:a g:42:a g:45:a g:45:a pi:3e:a pi:42:a pi:45:a t14 p:24:0 p:2a:0 p:31:0 p:39:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0 p:45:0 b:26:0 g:3e:0 g:3e:0 g:42:0 g:42:0 g:45:0 g:45:0 pi:3e:0 pi:42:0 pi:45:0 t2 p:2e:a p:3b:a p:45:a b:26:a g:3e:a g:3e:a g:42:a g:42:a g:45:a g:45:a pi:3e:a pi:42:a pi:45:a t14 p:2e:0 p:3b:0 p:45:0 g:3e:0 g:3e:0 g:42:0 g:42:0 g:45:0 g:45:0 pi:3e:0 pi:42:0 pi:45:0 t2 p:2e:a p:3b:a p:45:a g:3e:a g:3e:a g:42:a g:42:a g:45:a g:45:a pi:3e:a pi:42:a pi:45:a t14 p:2e:0 p:3b:0 p:45:0 b:26:0 g:3e:0 g:3e:0 g:42:0 g:42:0 g:45:0 g:45:0 pi:3e:0 pi:42:0 pi:45:0 t2 p:26:a p:2a:a p:3b:a p:45:a t14 p:26:0 p:2a:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a b:26:a g:3e:a g:3e:a g:42:a g:42:a g:45:a g:45:a pi:3e:a pi:42:a pi:45:a t14 p:2a:0 p:3b:0 p:45:0 b:26:0 t2 p:24:a p:2a:a p:3b:a p:45:a b:2d:a t14 p:24:0 p:2a:0 p:3b:0 p:45:0 b:2d:0 g:3e:0 g:3e:0 g:42:0 g:42:0 g:45:0 g:45:0 pi:3e:0 pi:42:0 pi:45:0 t2 p:24:a p:2a:a p:3b:a p:45:a b:21:a g:39:a g:39:a g:3d:a g:3d:a g:40:a g:40:a pi:39:a pi:3d:a pi:40:a t14 p:24:0 p:2a:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0 p:45:0 b:21:0 g:39:0 g:39:0 g:3d:0 g:3d:0 g:40:0 g:40:0 pi:39:0 pi:3d:0 pi:40:0 t2 p:24:a p:2e:a p:3b:a p:45:a b:21:a g:39:a g:39:a g:3d:a g:3d:a g:40:a g:40:a pi:39:a pi:3d:a pi:40:a t14 p:24:0 p:2e:0 p:3b:0 p:45:0 b:21:0 g:39:0 g:39:0 g:3d:0 g:3d:0 g:40:0 g:40:0 pi:39:0 pi:3d:0 pi:40:0 t2 p:24:a p:2a:a p:3b:a p:45:a b:21:a g:39:a g:39:a g:3d:a g:3d:a g:40:a g:40:a pi:39:a pi:3d:a pi:40:a t14 p:24:0 p:2a:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0 p:45:0 b:21:0 g:39:0 g:39:0 g:3d:0 g:3d:0 g:40:0 g:40:0 pi:39:0 pi:3d:0 pi:40:0 t2 p:26:a p:2a:a p:3b:a p:45:a b:21:a g:39:a g:39:a g:3d:a g:3d:a g:40:a g:40:a pi:39:a pi:3d:a pi:40:a t14 p:26:0 p:2a:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0 p:45:0 b:21:0 g:39:0 g:39:0 g:3d:0 g:3d:0 g:40:0 g:40:0 pi:39:0 pi:3d:0 pi:40:0 t2 p:26:a p:2e:a p:31:a p:39:a p:3b:a p:45:a b:21:a g:39:a g:39:a g:3d:a g:3d:a g:40:a g:40:a pi:39:a pi:3d:a pi:40:a t14 p:26:0 p:2e:0 p:31:0 p:39:0 p:3b:0 p:45:0 b:21:0 t2 p:26:a p:2e:a p:31:a p:39:a p:3b:a p:45:a b:21:a t14 p:26:0 p:2e:0 p:31:0 p:39:0 p:3b:0 p:45:0 b:21:0 g:39:0 g:39:0 g:3d:0 g:3d:0 g:40:0 g:40:0 pi:39:0 pi:3d:0 pi:40:0 t2 p:24:a p:2a:a p:31:a p:39:a p:3b:a p:45:a b:1f:a g:3b:a g:3b:a g:3e:a g:3e:a g:43:a g:43:a pi:3b:a pi:3e:a pi:43:a t14 p:24:0 p:2a:0 p:31:0 p:39:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0 p:45:0 b:1f:0 g:3b:0 g:3b:0 g:3e:0 g:3e:0 g:43:0 g:43:0 pi:3b:0 pi:3e:0 pi:43:0 t2 p:2e:a p:3b:a p:45:a b:1f:a g:3b:a g:3b:a g:3e:a g:3e:a g:43:a g:43:a pi:3b:a pi:3e:a pi:43:a t14 p:2e:0 p:3b:0 p:45:0 g:3b:0 g:3b:0 g:3e:0 g:3e:0 g:43:0 g:43:0 pi:3b:0 pi:3e:0 pi:43:0 t2 p:2e:a p:3b:a p:45:a g:3b:a g:3b:a g:3e:a g:3e:a g:43:a g:43:a pi:3b:a pi:3e:a pi:43:a t14 p:2e:0 p:3b:0 p:45:0 b:1f:0 g:3b:0 g:3b:0 g:3e:0 g:3e:0 g:43:0 g:43:0 pi:3b:0 pi:3e:0 pi:43:0 t2 p:26:a p:2a:a p:3b:a p:45:a t14 p:26:0 p:2a:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a b:1f:a g:3b:a g:3b:a g:3e:a g:3e:a g:43:a g:43:a pi:3b:a pi:3e:a pi:43:a t14 p:2a:0 p:3b:0 p:45:0 b:1f:0 t2 p:24:a p:2a:a p:3b:a p:45:a b:1f:a t14 p:24:0 p:2a:0 p:3b:0 p:45:0 b:1f:0 g:3b:0 g:3b:0 g:3e:0 g:3e:0 g:43:0 g:43:0 pi:3b:0 pi:3e:0 pi:43:0 t2 p:24:a p:2e:a p:3b:a p:45:a b:26:a g:39:a g:39:a g:3e:a g:3e:a g:42:a g:42:a pi:39:a pi:3e:a pi:42:a t14 p:24:0 p:2e:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0",
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@router.post("/text-to-midi", tags=["MIDI"])
|
||||
def text_to_midi(body: TextToMidiBody):
|
||||
vocab_config_type = global_var.get(global_var.Midi_Vocab_Config_Type)
|
||||
if vocab_config_type == global_var.MidiVocabConfig.Piano:
|
||||
vocab_config = "backend-python/utils/vocab_config_piano.json"
|
||||
else:
|
||||
vocab_config = "backend-python/utils/midi_vocab_config.json"
|
||||
cfg = VocabConfig.from_json(vocab_config)
|
||||
mid = convert_str_to_midi(cfg, body.text.strip())
|
||||
mid_data = io.BytesIO()
|
||||
mid.save(None, mid_data)
|
||||
mid_data.seek(0)
|
||||
|
||||
return StreamingResponse(mid_data, media_type="audio/midi")
|
||||
|
||||
|
||||
@router.post("/midi-to-text", tags=["MIDI"])
|
||||
async def midi_to_text(file_data: UploadFile):
|
||||
vocab_config_type = global_var.get(global_var.Midi_Vocab_Config_Type)
|
||||
if vocab_config_type == global_var.MidiVocabConfig.Piano:
|
||||
vocab_config = "backend-python/utils/vocab_config_piano.json"
|
||||
else:
|
||||
vocab_config = "backend-python/utils/midi_vocab_config.json"
|
||||
cfg = VocabConfig.from_json(vocab_config)
|
||||
filter_config = "backend-python/utils/midi_filter_config.json"
|
||||
filter_cfg = FilterConfig.from_json(filter_config)
|
||||
mid = mido.MidiFile(file=file_data.file)
|
||||
output_list = convert_midi_to_str(cfg, filter_cfg, mid)
|
||||
if len(output_list) == 0:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "bad midi file")
|
||||
|
||||
return {"text": output_list[0]}
|
||||
|
||||
|
||||
class TxtToMidiBody(BaseModel):
|
||||
txt_path: str
|
||||
midi_path: str
|
||||
|
||||
model_config = {
|
||||
"json_schema_extra": {
|
||||
"example": {
|
||||
"txt_path": "midi/sample.txt",
|
||||
"midi_path": "midi/sample.mid",
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@router.post("/txt-to-midi", tags=["MIDI"])
|
||||
def txt_to_midi(body: TxtToMidiBody):
|
||||
if global_var.get(global_var.Deploy_Mode) is True:
|
||||
raise HTTPException(status.HTTP_403_FORBIDDEN)
|
||||
|
||||
if not body.midi_path.startswith("midi/"):
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "bad output path")
|
||||
|
||||
vocab_config_type = global_var.get(global_var.Midi_Vocab_Config_Type)
|
||||
if vocab_config_type == global_var.MidiVocabConfig.Piano:
|
||||
vocab_config = "backend-python/utils/vocab_config_piano.json"
|
||||
else:
|
||||
vocab_config = "backend-python/utils/midi_vocab_config.json"
|
||||
cfg = VocabConfig.from_json(vocab_config)
|
||||
with open(body.txt_path, "r") as f:
|
||||
text = f.read()
|
||||
text = text.strip()
|
||||
mid = convert_str_to_midi(cfg, text)
|
||||
mid.save(body.midi_path)
|
||||
|
||||
return "success"
|
||||
|
||||
|
||||
class MidiToWavBody(BaseModel):
|
||||
midi_path: str
|
||||
wav_path: str
|
||||
sound_font_path: str = "assets/default_sound_font.sf2"
|
||||
|
||||
model_config = {
|
||||
"json_schema_extra": {
|
||||
"example": {
|
||||
"midi_path": "midi/sample.mid",
|
||||
"wav_path": "midi/sample.wav",
|
||||
"sound_font_path": "assets/default_sound_font.sf2",
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@router.post("/midi-to-wav", tags=["MIDI"])
|
||||
def midi_to_wav(body: MidiToWavBody):
|
||||
"""
|
||||
Install fluidsynth first, see more: https://github.com/FluidSynth/fluidsynth/wiki/Download#distributions
|
||||
"""
|
||||
|
||||
if global_var.get(global_var.Deploy_Mode) is True:
|
||||
raise HTTPException(status.HTTP_403_FORBIDDEN)
|
||||
|
||||
if not body.wav_path.startswith("midi/"):
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "bad output path")
|
||||
|
||||
fs = FluidSynth(body.sound_font_path)
|
||||
fs.midi_to_audio(body.midi_path, body.wav_path)
|
||||
|
||||
return "success"
|
||||
|
||||
|
||||
class TextToWavBody(BaseModel):
|
||||
text: str
|
||||
wav_name: str
|
||||
sound_font_path: str = "assets/default_sound_font.sf2"
|
||||
|
||||
model_config = {
|
||||
"json_schema_extra": {
|
||||
"example": {
|
||||
"text": "p:24:a p:2a:a p:31:a p:39:a p:3b:a p:45:a b:26:a g:3e:a g:3e:a g:42:a g:42:a g:45:a g:45:a pi:3e:a pi:42:a pi:45:a t14 p:24:0 p:2a:0 p:31:0 p:39:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0 p:45:0 b:26:0 g:3e:0 g:3e:0 g:42:0 g:42:0 g:45:0 g:45:0 pi:3e:0 pi:42:0 pi:45:0 t2 p:2e:a p:3b:a p:45:a b:26:a g:3e:a g:3e:a g:42:a g:42:a g:45:a g:45:a pi:3e:a pi:42:a pi:45:a t14 p:2e:0 p:3b:0 p:45:0 g:3e:0 g:3e:0 g:42:0 g:42:0 g:45:0 g:45:0 pi:3e:0 pi:42:0 pi:45:0 t2 p:2e:a p:3b:a p:45:a g:3e:a g:3e:a g:42:a g:42:a g:45:a g:45:a pi:3e:a pi:42:a pi:45:a t14 p:2e:0 p:3b:0 p:45:0 b:26:0 g:3e:0 g:3e:0 g:42:0 g:42:0 g:45:0 g:45:0 pi:3e:0 pi:42:0 pi:45:0 t2 p:26:a p:2a:a p:3b:a p:45:a t14 p:26:0 p:2a:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a b:26:a g:3e:a g:3e:a g:42:a g:42:a g:45:a g:45:a pi:3e:a pi:42:a pi:45:a t14 p:2a:0 p:3b:0 p:45:0 b:26:0 t2 p:24:a p:2a:a p:3b:a p:45:a b:2d:a t14 p:24:0 p:2a:0 p:3b:0 p:45:0 b:2d:0 g:3e:0 g:3e:0 g:42:0 g:42:0 g:45:0 g:45:0 pi:3e:0 pi:42:0 pi:45:0 t2 p:24:a p:2a:a p:3b:a p:45:a b:21:a g:39:a g:39:a g:3d:a g:3d:a g:40:a g:40:a pi:39:a pi:3d:a pi:40:a t14 p:24:0 p:2a:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0 p:45:0 b:21:0 g:39:0 g:39:0 g:3d:0 g:3d:0 g:40:0 g:40:0 pi:39:0 pi:3d:0 pi:40:0 t2 p:24:a p:2e:a p:3b:a p:45:a b:21:a g:39:a g:39:a g:3d:a g:3d:a g:40:a g:40:a pi:39:a pi:3d:a pi:40:a t14 p:24:0 p:2e:0 p:3b:0 p:45:0 b:21:0 g:39:0 g:39:0 g:3d:0 g:3d:0 g:40:0 g:40:0 pi:39:0 pi:3d:0 pi:40:0 t2 p:24:a p:2a:a p:3b:a p:45:a b:21:a g:39:a g:39:a g:3d:a g:3d:a g:40:a g:40:a pi:39:a pi:3d:a pi:40:a t14 p:24:0 p:2a:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0 p:45:0 b:21:0 g:39:0 g:39:0 g:3d:0 g:3d:0 g:40:0 g:40:0 pi:39:0 pi:3d:0 pi:40:0 t2 p:26:a p:2a:a p:3b:a p:45:a b:21:a g:39:a g:39:a g:3d:a g:3d:a g:40:a g:40:a pi:39:a pi:3d:a pi:40:a t14 p:26:0 p:2a:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0 p:45:0 b:21:0 g:39:0 g:39:0 g:3d:0 g:3d:0 g:40:0 g:40:0 pi:39:0 pi:3d:0 pi:40:0 t2 p:26:a p:2e:a p:31:a p:39:a p:3b:a p:45:a b:21:a g:39:a g:39:a g:3d:a g:3d:a g:40:a g:40:a pi:39:a pi:3d:a pi:40:a t14 p:26:0 p:2e:0 p:31:0 p:39:0 p:3b:0 p:45:0 b:21:0 t2 p:26:a p:2e:a p:31:a p:39:a p:3b:a p:45:a b:21:a t14 p:26:0 p:2e:0 p:31:0 p:39:0 p:3b:0 p:45:0 b:21:0 g:39:0 g:39:0 g:3d:0 g:3d:0 g:40:0 g:40:0 pi:39:0 pi:3d:0 pi:40:0 t2 p:24:a p:2a:a p:31:a p:39:a p:3b:a p:45:a b:1f:a g:3b:a g:3b:a g:3e:a g:3e:a g:43:a g:43:a pi:3b:a pi:3e:a pi:43:a t14 p:24:0 p:2a:0 p:31:0 p:39:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0 p:45:0 b:1f:0 g:3b:0 g:3b:0 g:3e:0 g:3e:0 g:43:0 g:43:0 pi:3b:0 pi:3e:0 pi:43:0 t2 p:2e:a p:3b:a p:45:a b:1f:a g:3b:a g:3b:a g:3e:a g:3e:a g:43:a g:43:a pi:3b:a pi:3e:a pi:43:a t14 p:2e:0 p:3b:0 p:45:0 g:3b:0 g:3b:0 g:3e:0 g:3e:0 g:43:0 g:43:0 pi:3b:0 pi:3e:0 pi:43:0 t2 p:2e:a p:3b:a p:45:a g:3b:a g:3b:a g:3e:a g:3e:a g:43:a g:43:a pi:3b:a pi:3e:a pi:43:a t14 p:2e:0 p:3b:0 p:45:0 b:1f:0 g:3b:0 g:3b:0 g:3e:0 g:3e:0 g:43:0 g:43:0 pi:3b:0 pi:3e:0 pi:43:0 t2 p:26:a p:2a:a p:3b:a p:45:a t14 p:26:0 p:2a:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a b:1f:a g:3b:a g:3b:a g:3e:a g:3e:a g:43:a g:43:a pi:3b:a pi:3e:a pi:43:a t14 p:2a:0 p:3b:0 p:45:0 b:1f:0 t2 p:24:a p:2a:a p:3b:a p:45:a b:1f:a t14 p:24:0 p:2a:0 p:3b:0 p:45:0 b:1f:0 g:3b:0 g:3b:0 g:3e:0 g:3e:0 g:43:0 g:43:0 pi:3b:0 pi:3e:0 pi:43:0 t2 p:24:a p:2e:a p:3b:a p:45:a b:26:a g:39:a g:39:a g:3e:a g:3e:a g:42:a g:42:a pi:39:a pi:3e:a pi:42:a t14 p:24:0 p:2e:0 p:3b:0 p:45:0 t2 p:2a:a p:3b:a p:45:a t14 p:2a:0 p:3b:0",
|
||||
"wav_name": "sample",
|
||||
"sound_font_path": "assets/default_sound_font.sf2",
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@router.post("/text-to-wav", tags=["MIDI"])
|
||||
def text_to_wav(body: TextToWavBody):
|
||||
"""
|
||||
Install fluidsynth first, see more: https://github.com/FluidSynth/fluidsynth/wiki/Download#distributions
|
||||
"""
|
||||
|
||||
if global_var.get(global_var.Deploy_Mode) is True:
|
||||
raise HTTPException(status.HTTP_403_FORBIDDEN)
|
||||
|
||||
text = body.text.strip()
|
||||
if not text.startswith("<start>"):
|
||||
text = "<start> " + text
|
||||
if not text.endswith("<end>"):
|
||||
text = text + " <end>"
|
||||
txt_path = f"midi/{body.wav_name}.txt"
|
||||
midi_path = f"midi/{body.wav_name}.mid"
|
||||
wav_path = f"midi/{body.wav_name}.wav"
|
||||
with open(txt_path, "w") as f:
|
||||
f.write(text)
|
||||
txt_to_midi(TxtToMidiBody(txt_path=txt_path, midi_path=midi_path))
|
||||
midi_to_wav(
|
||||
MidiToWavBody(
|
||||
midi_path=midi_path, wav_path=wav_path, sound_font_path=body.sound_font_path
|
||||
)
|
||||
)
|
||||
|
||||
return "success"
|
||||
@ -1,131 +0,0 @@
|
||||
from fastapi import APIRouter, HTTPException, status
|
||||
from utils.rwkv import AbstractRWKV
|
||||
import global_var
|
||||
|
||||
router = APIRouter()
|
||||
|
||||
|
||||
@router.get("/dashboard/billing/credit_grants", tags=["MISC"])
|
||||
def credit_grants():
|
||||
return {
|
||||
"object": "credit_summary",
|
||||
"total_granted": 10000,
|
||||
"total_used": 0,
|
||||
"total_available": 10000,
|
||||
"grants": {
|
||||
"object": "list",
|
||||
"data": [
|
||||
{
|
||||
"object": "credit_grant",
|
||||
"grant_amount": 10000,
|
||||
"used_amount": 0,
|
||||
"effective_at": 1672531200,
|
||||
"expires_at": 33229440000,
|
||||
}
|
||||
],
|
||||
},
|
||||
}
|
||||
|
||||
|
||||
fake_models = [
|
||||
{
|
||||
"id": "gpt-3.5-turbo",
|
||||
"object": "model",
|
||||
"created": 1677610602,
|
||||
"owned_by": "openai",
|
||||
"permission": [
|
||||
{
|
||||
"id": "modelperm-zy5TOjnE2zVaicIcKO9bQDgX",
|
||||
"object": "model_permission",
|
||||
"created": 1690864883,
|
||||
"allow_create_engine": False,
|
||||
"allow_sampling": True,
|
||||
"allow_logprobs": True,
|
||||
"allow_search_indices": False,
|
||||
"allow_view": True,
|
||||
"allow_fine_tuning": False,
|
||||
"organization": "*",
|
||||
"group": None,
|
||||
"is_blocking": False,
|
||||
}
|
||||
],
|
||||
"root": "gpt-3.5-turbo",
|
||||
"parent": None,
|
||||
},
|
||||
{
|
||||
"id": "text-davinci-003",
|
||||
"object": "model",
|
||||
"created": 1669599635,
|
||||
"owned_by": "openai-internal",
|
||||
"permission": [
|
||||
{
|
||||
"id": "modelperm-a6niqBmW2JaGmo0fDO7FEt1n",
|
||||
"object": "model_permission",
|
||||
"created": 1690930172,
|
||||
"allow_create_engine": False,
|
||||
"allow_sampling": True,
|
||||
"allow_logprobs": True,
|
||||
"allow_search_indices": False,
|
||||
"allow_view": True,
|
||||
"allow_fine_tuning": False,
|
||||
"organization": "*",
|
||||
"group": None,
|
||||
"is_blocking": False,
|
||||
}
|
||||
],
|
||||
"root": "text-davinci-003",
|
||||
"parent": None,
|
||||
},
|
||||
]
|
||||
|
||||
|
||||
@router.get("/v1/models", tags=["MISC"])
|
||||
@router.get("/models", tags=["MISC"])
|
||||
def models():
|
||||
model: AbstractRWKV = global_var.get(global_var.Model)
|
||||
model_name = model.name if model else "rwkv"
|
||||
|
||||
return {
|
||||
"object": "list",
|
||||
"data": [
|
||||
{
|
||||
"id": model_name,
|
||||
"object": "model",
|
||||
"owned_by": "rwkv",
|
||||
"root": model_name,
|
||||
"parent": None,
|
||||
},
|
||||
*fake_models,
|
||||
],
|
||||
}
|
||||
|
||||
|
||||
@router.get("/v1/models/{model_id}", tags=["MISC"])
|
||||
@router.get("/models/{model_id}", tags=["MISC"])
|
||||
def model(model_id: str):
|
||||
for fake_model in fake_models:
|
||||
if fake_model["id"] == model_id:
|
||||
return fake_model
|
||||
|
||||
if "rwkv" in model_id.lower():
|
||||
model: AbstractRWKV = global_var.get(global_var.Model)
|
||||
model_name = model.name if model else "rwkv"
|
||||
return {
|
||||
"id": model_name,
|
||||
"object": "model",
|
||||
"owned_by": "rwkv",
|
||||
"root": model_name,
|
||||
"parent": None,
|
||||
}
|
||||
|
||||
raise HTTPException(
|
||||
status.HTTP_404_NOT_FOUND,
|
||||
{
|
||||
"error": {
|
||||
"message": f"The model '{model_id}' does not exist",
|
||||
"type": "invalid_request_error",
|
||||
"param": "model",
|
||||
"code": "model_not_found",
|
||||
}
|
||||
},
|
||||
)
|
||||
@ -1,286 +0,0 @@
|
||||
from typing import Any, Dict, List, Union
|
||||
from utils.log import quick_log
|
||||
from fastapi import APIRouter, HTTPException, Request, Response, status
|
||||
from pydantic import BaseModel
|
||||
import gc
|
||||
import copy
|
||||
import global_var
|
||||
|
||||
router = APIRouter()
|
||||
|
||||
trie = None
|
||||
dtrie: Dict = {}
|
||||
max_trie_len = 300
|
||||
loop_start_id = 1 # to prevent preloaded prompts from being deleted
|
||||
loop_del_trie_id = loop_start_id
|
||||
|
||||
|
||||
def init():
|
||||
global trie
|
||||
try:
|
||||
import cyac
|
||||
|
||||
# import mmap
|
||||
# import os
|
||||
#
|
||||
# if os.path.exists("state_cache.trie"):
|
||||
# with open("state_cache.trie", "r") as bf:
|
||||
# buff_object = mmap.mmap(bf.fileno(), 0, access=mmap.ACCESS_READ)
|
||||
# trie = cyac.Trie.from_buff(buff_object, copy=False)
|
||||
# else:
|
||||
trie = cyac.Trie()
|
||||
except ModuleNotFoundError:
|
||||
print("cyac not found")
|
||||
|
||||
|
||||
@router.post("/disable-state-cache", tags=["State Cache"])
|
||||
def disable_state_cache():
|
||||
global trie, dtrie
|
||||
|
||||
if global_var.get(global_var.Deploy_Mode) is True:
|
||||
raise HTTPException(status.HTTP_403_FORBIDDEN)
|
||||
|
||||
trie = None
|
||||
dtrie = {}
|
||||
gc.collect()
|
||||
|
||||
print("state cache disabled")
|
||||
return "success"
|
||||
|
||||
|
||||
@router.post("/enable-state-cache", tags=["State Cache"])
|
||||
def enable_state_cache():
|
||||
global trie, dtrie
|
||||
|
||||
if global_var.get(global_var.Deploy_Mode) is True:
|
||||
raise HTTPException(status.HTTP_403_FORBIDDEN)
|
||||
|
||||
try:
|
||||
import cyac
|
||||
|
||||
trie = cyac.Trie()
|
||||
dtrie = {}
|
||||
gc.collect()
|
||||
|
||||
print("state cache enabled")
|
||||
return "success"
|
||||
except ModuleNotFoundError:
|
||||
print("state cache disabled")
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "cyac not found")
|
||||
|
||||
|
||||
class AddStateBody(BaseModel):
|
||||
prompt: str
|
||||
tokens: List[Union[str, int]]
|
||||
state: Any
|
||||
logits: Any
|
||||
|
||||
|
||||
def copy_tensor_to_cpu(tensors):
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
devices: List[torch.device] = []
|
||||
copied: Union[Any, None] = None
|
||||
|
||||
tensors_type = type(tensors)
|
||||
if tensors_type == list:
|
||||
if hasattr(tensors[0], "device"): # torch state
|
||||
devices = [tensor.device for tensor in tensors]
|
||||
copied = [tensor.cpu() for tensor in tensors]
|
||||
else: # WebGPU logits
|
||||
copied = tensors
|
||||
elif tensors_type == torch.Tensor: # torch logits
|
||||
devices = [tensors.device]
|
||||
copied = tensors.cpu()
|
||||
elif tensors_type == np.ndarray: # rwkv.cpp
|
||||
copied = tensors
|
||||
else: # WebGPU state
|
||||
model = global_var.get(global_var.Model)
|
||||
if model:
|
||||
copied = model.model.model.back_state()
|
||||
|
||||
return copied, devices
|
||||
|
||||
|
||||
# @router.post("/add-state", tags=["State Cache"])
|
||||
def add_state(body: AddStateBody):
|
||||
global trie, dtrie, loop_del_trie_id
|
||||
|
||||
# if global_var.get(global_var.Deploy_Mode) is True:
|
||||
# raise HTTPException(status.HTTP_403_FORBIDDEN)
|
||||
|
||||
if trie is None:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "trie not loaded")
|
||||
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
try:
|
||||
devices: List[torch.device] = []
|
||||
logits_device: Union[torch.device, None] = None
|
||||
state: Union[Any, None] = None
|
||||
logits: Union[Any, None] = None
|
||||
|
||||
if body.state is not None:
|
||||
state, devices = copy_tensor_to_cpu(body.state)
|
||||
if body.logits is not None:
|
||||
logits, logits_devices = copy_tensor_to_cpu(body.logits)
|
||||
if len(logits_devices) > 0:
|
||||
logits_device = logits_devices[0]
|
||||
|
||||
id: int = trie.insert(body.prompt)
|
||||
dtrie[id] = {
|
||||
"tokens": body.tokens,
|
||||
"state": state,
|
||||
"logits": logits,
|
||||
"devices": devices,
|
||||
"logits_device": logits_device,
|
||||
}
|
||||
|
||||
if len(trie) >= max_trie_len:
|
||||
del_prompt = trie[loop_del_trie_id]
|
||||
trie.remove(del_prompt)
|
||||
dtrie[loop_del_trie_id] = None
|
||||
loop_del_trie_id = loop_del_trie_id + 1
|
||||
if loop_del_trie_id >= max_trie_len:
|
||||
loop_del_trie_id = loop_start_id
|
||||
|
||||
quick_log(
|
||||
None,
|
||||
None,
|
||||
f"New Trie Id: {id}\nTrie Len: {len(trie)}\nTrie Buff Size: {trie.buff_size()}\nDtrie Buff Size Of Id: {__get_a_dtrie_buff_size(dtrie[id])}",
|
||||
)
|
||||
return "success"
|
||||
except Exception as e:
|
||||
print(e) # should not happen
|
||||
raise HTTPException(
|
||||
status.HTTP_400_BAD_REQUEST, f"insert failed, bad prompt.\n{e}"
|
||||
)
|
||||
|
||||
|
||||
@router.post("/reset-state", tags=["State Cache"])
|
||||
def reset_state():
|
||||
global trie, dtrie
|
||||
|
||||
if global_var.get(global_var.Deploy_Mode) is True:
|
||||
raise HTTPException(status.HTTP_403_FORBIDDEN)
|
||||
|
||||
if trie is None:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "trie not loaded")
|
||||
|
||||
import cyac
|
||||
|
||||
trie = cyac.Trie()
|
||||
dtrie = {}
|
||||
gc.collect()
|
||||
|
||||
return "success"
|
||||
|
||||
|
||||
def force_reset_state():
|
||||
global trie, dtrie
|
||||
|
||||
if trie is None:
|
||||
return
|
||||
|
||||
import cyac
|
||||
|
||||
trie = cyac.Trie()
|
||||
dtrie = {}
|
||||
gc.collect()
|
||||
|
||||
|
||||
class LongestPrefixStateBody(BaseModel):
|
||||
prompt: str
|
||||
|
||||
|
||||
def __get_a_dtrie_buff_size(dtrie_v):
|
||||
# print(sys.getsizeof(dtrie_v["tokens"][0])) # str
|
||||
# print(sys.getsizeof(dtrie_v["tokens"][0]) * len(dtrie_v["tokens"]))
|
||||
# print(dtrie_v["state"][0][0].element_size())
|
||||
# print(dtrie_v["state"][0].nelement())
|
||||
# print(len(dtrie_v["state"]))
|
||||
# print(
|
||||
# len(dtrie_v["state"])
|
||||
# * dtrie_v["state"][0].nelement()
|
||||
# * dtrie_v["state"][0][0].element_size()
|
||||
# )
|
||||
# print(dtrie_v["logits"][0].element_size())
|
||||
# print(dtrie_v["logits"].nelement())
|
||||
# print(dtrie_v["logits"][0].element_size() * dtrie_v["logits"].nelement())
|
||||
return 54 * len(dtrie_v["tokens"]) + 491520 + 262144 + 28 # TODO
|
||||
|
||||
|
||||
# @router.post("/longest-prefix-state", tags=["State Cache"])
|
||||
def longest_prefix_state(body: LongestPrefixStateBody, request: Request):
|
||||
global trie
|
||||
|
||||
# if global_var.get(global_var.Deploy_Mode) is True:
|
||||
# raise HTTPException(status.HTTP_403_FORBIDDEN)
|
||||
|
||||
if trie is None:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "trie not loaded")
|
||||
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
id = -1
|
||||
try:
|
||||
for id, len in trie.prefix(body.prompt):
|
||||
pass
|
||||
except:
|
||||
pass
|
||||
if id != -1:
|
||||
prompt: str = trie[id]
|
||||
v = dtrie[id]
|
||||
tokens: List[Union[str, int]] = copy.deepcopy(v["tokens"])
|
||||
devices: List[torch.device] = v["devices"]
|
||||
logits_device: Union[torch.device, None] = v["logits_device"]
|
||||
state: Union[Any, None] = v["state"]
|
||||
logits: Union[Any, None] = v["logits"]
|
||||
|
||||
state_type = type(state)
|
||||
if state_type == list and hasattr(state[0], "device"): # torch
|
||||
state = [
|
||||
(
|
||||
tensor.to(devices[i])
|
||||
if devices[i] != torch.device("cpu")
|
||||
else tensor.clone()
|
||||
)
|
||||
for i, tensor in enumerate(state)
|
||||
]
|
||||
logits = (
|
||||
logits.to(logits_device)
|
||||
if logits_device != torch.device("cpu")
|
||||
else logits.clone()
|
||||
)
|
||||
elif state_type == np.ndarray: # rwkv.cpp
|
||||
logits = np.copy(logits)
|
||||
else: # WebGPU
|
||||
logits = np.copy(logits)
|
||||
|
||||
quick_log(request, body, "Hit:\n" + prompt)
|
||||
return {
|
||||
"prompt": prompt,
|
||||
"tokens": tokens,
|
||||
"state": state,
|
||||
"logits": logits,
|
||||
}
|
||||
else:
|
||||
return {"prompt": "", "tokens": [], "state": None, "logits": None}
|
||||
|
||||
|
||||
# @router.post("/save-state", tags=["State Cache"])
|
||||
def save_state():
|
||||
global trie
|
||||
|
||||
# if global_var.get(global_var.Deploy_Mode) is True:
|
||||
# raise HTTPException(status.HTTP_403_FORBIDDEN)
|
||||
|
||||
if trie is None:
|
||||
raise HTTPException(status.HTTP_400_BAD_REQUEST, "trie not loaded")
|
||||
|
||||
# trie.save("state_cache.trie")
|
||||
|
||||
return "not implemented"
|
||||
Binary file not shown.
Binary file not shown.
@ -1,17 +0,0 @@
|
||||
from typing import Any, List, Union
|
||||
from . import rwkv_cpp_model
|
||||
from . import rwkv_cpp_shared_library
|
||||
|
||||
|
||||
class RWKV:
|
||||
def __init__(self, model_path: str, strategy=None):
|
||||
self.library = rwkv_cpp_shared_library.load_rwkv_shared_library()
|
||||
self.model = rwkv_cpp_model.RWKVModel(self.library, model_path)
|
||||
self.w = {} # fake weight
|
||||
self.w["emb.weight"] = [0] * self.model.n_vocab
|
||||
self.version = (
|
||||
self.model.arch_version_major + self.model.arch_version_minor / 10
|
||||
)
|
||||
|
||||
def forward(self, tokens: List[int], state: Union[Any, None] = None):
|
||||
return self.model.eval_sequence_in_chunks(tokens, state, use_numpy=True)
|
||||
Binary file not shown.
@ -1,396 +0,0 @@
|
||||
import os
|
||||
import multiprocessing
|
||||
|
||||
# Pre-import PyTorch, if available.
|
||||
# This fixes "OSError: [WinError 127] The specified procedure could not be found".
|
||||
try:
|
||||
import torch
|
||||
except ModuleNotFoundError:
|
||||
pass
|
||||
|
||||
# I'm sure this is not strictly correct, but let's keep this crutch for now.
|
||||
try:
|
||||
import rwkv_cpp_shared_library
|
||||
except ModuleNotFoundError:
|
||||
from . import rwkv_cpp_shared_library
|
||||
|
||||
from typing import TypeVar, Optional, Tuple, List
|
||||
|
||||
# A value of this type is either a numpy's ndarray or a PyTorch's Tensor.
|
||||
NumpyArrayOrPyTorchTensor: TypeVar = TypeVar('NumpyArrayOrPyTorchTensor')
|
||||
|
||||
class RWKVModel:
|
||||
"""
|
||||
An RWKV model managed by rwkv.cpp library.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
shared_library: rwkv_cpp_shared_library.RWKVSharedLibrary,
|
||||
model_path: str,
|
||||
thread_count: int = max(1, multiprocessing.cpu_count() // 2),
|
||||
gpu_layer_count: int = 0,
|
||||
**kwargs
|
||||
) -> None:
|
||||
"""
|
||||
Loads the model and prepares it for inference.
|
||||
In case of any error, this method will throw an exception.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
shared_library : RWKVSharedLibrary
|
||||
rwkv.cpp shared library.
|
||||
model_path : str
|
||||
Path to RWKV model file in ggml format.
|
||||
thread_count : int
|
||||
Thread count to use. If not set, defaults to CPU count / 2.
|
||||
gpu_layer_count : int
|
||||
Count of layers to offload onto the GPU, must be >= 0.
|
||||
See documentation of `gpu_offload_layers` for details about layer offloading.
|
||||
"""
|
||||
|
||||
if 'gpu_layers_count' in kwargs:
|
||||
gpu_layer_count = kwargs['gpu_layers_count']
|
||||
|
||||
if not os.path.isfile(model_path):
|
||||
raise ValueError(f'{model_path} is not a file')
|
||||
|
||||
if not (thread_count > 0):
|
||||
raise ValueError('Thread count must be > 0')
|
||||
|
||||
if not (gpu_layer_count >= 0):
|
||||
raise ValueError('GPU layer count must be >= 0')
|
||||
|
||||
self._library: rwkv_cpp_shared_library.RWKVSharedLibrary = shared_library
|
||||
|
||||
self._ctx: rwkv_cpp_shared_library.RWKVContext = self._library.rwkv_init_from_file(model_path, thread_count)
|
||||
|
||||
if gpu_layer_count > 0:
|
||||
self.gpu_offload_layers(gpu_layer_count)
|
||||
|
||||
self._state_buffer_element_count: int = self._library.rwkv_get_state_buffer_element_count(self._ctx)
|
||||
self._logits_buffer_element_count: int = self._library.rwkv_get_logits_buffer_element_count(self._ctx)
|
||||
|
||||
self._valid: bool = True
|
||||
|
||||
def gpu_offload_layers(self, layer_count: int) -> bool:
|
||||
"""
|
||||
Offloads specified count of model layers onto the GPU. Offloaded layers are evaluated using cuBLAS or CLBlast.
|
||||
For the purposes of this function, model head (unembedding matrix) is treated as an additional layer:
|
||||
- pass `model.n_layer` to offload all layers except model head
|
||||
- pass `model.n_layer + 1` to offload all layers, including model head
|
||||
|
||||
Returns true if at least one layer was offloaded.
|
||||
If rwkv.cpp was compiled without cuBLAS and CLBlast support, this function is a no-op and always returns false.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
layer_count : int
|
||||
Count of layers to offload onto the GPU, must be >= 0.
|
||||
"""
|
||||
|
||||
if not (layer_count >= 0):
|
||||
raise ValueError('Layer count must be >= 0')
|
||||
|
||||
return self._library.rwkv_gpu_offload_layers(self._ctx, layer_count)
|
||||
|
||||
@property
|
||||
def arch_version_major(self) -> int:
|
||||
return self._library.rwkv_get_arch_version_major(self._ctx)
|
||||
|
||||
@property
|
||||
def arch_version_minor(self) -> int:
|
||||
return self._library.rwkv_get_arch_version_minor(self._ctx)
|
||||
|
||||
@property
|
||||
def n_vocab(self) -> int:
|
||||
return self._library.rwkv_get_n_vocab(self._ctx)
|
||||
|
||||
@property
|
||||
def n_embed(self) -> int:
|
||||
return self._library.rwkv_get_n_embed(self._ctx)
|
||||
|
||||
@property
|
||||
def n_layer(self) -> int:
|
||||
return self._library.rwkv_get_n_layer(self._ctx)
|
||||
|
||||
def eval(
|
||||
self,
|
||||
token: int,
|
||||
state_in: Optional[NumpyArrayOrPyTorchTensor],
|
||||
state_out: Optional[NumpyArrayOrPyTorchTensor] = None,
|
||||
logits_out: Optional[NumpyArrayOrPyTorchTensor] = None,
|
||||
use_numpy: bool = False
|
||||
) -> Tuple[NumpyArrayOrPyTorchTensor, NumpyArrayOrPyTorchTensor]:
|
||||
"""
|
||||
Evaluates the model for a single token.
|
||||
In case of any error, this method will throw an exception.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
token : int
|
||||
Index of next token to be seen by the model. Must be in range 0 <= token < n_vocab.
|
||||
state_in : Optional[NumpyArrayOrTorchTensor]
|
||||
State from previous call of this method. If this is a first pass, set it to None.
|
||||
state_out : Optional[NumpyArrayOrTorchTensor]
|
||||
Optional output tensor for state. If provided, must be of type float32, contiguous and of shape (state_buffer_element_count).
|
||||
logits_out : Optional[NumpyArrayOrTorchTensor]
|
||||
Optional output tensor for logits. If provided, must be of type float32, contiguous and of shape (logits_buffer_element_count).
|
||||
use_numpy : bool
|
||||
If set to True, numpy's ndarrays will be created instead of PyTorch's Tensors.
|
||||
This parameter is ignored if any tensor parameter is not None; in such case,
|
||||
type of returned tensors will match the type of received tensors.
|
||||
|
||||
Returns
|
||||
-------
|
||||
logits, state
|
||||
Logits vector of shape (n_vocab); state for the next step.
|
||||
"""
|
||||
|
||||
if not self._valid:
|
||||
raise ValueError('Model was freed')
|
||||
|
||||
use_numpy = self._detect_numpy_usage([state_in, state_out, logits_out], use_numpy)
|
||||
|
||||
if state_in is not None:
|
||||
self._validate_tensor(state_in, 'state_in', self._state_buffer_element_count)
|
||||
|
||||
state_in_ptr = self._get_data_ptr(state_in)
|
||||
else:
|
||||
state_in_ptr = 0
|
||||
|
||||
if state_out is not None:
|
||||
self._validate_tensor(state_out, 'state_out', self._state_buffer_element_count)
|
||||
else:
|
||||
state_out = self._zeros_float32(self._state_buffer_element_count, use_numpy)
|
||||
|
||||
if logits_out is not None:
|
||||
self._validate_tensor(logits_out, 'logits_out', self._logits_buffer_element_count)
|
||||
else:
|
||||
logits_out = self._zeros_float32(self._logits_buffer_element_count, use_numpy)
|
||||
|
||||
self._library.rwkv_eval(
|
||||
self._ctx,
|
||||
token,
|
||||
state_in_ptr,
|
||||
self._get_data_ptr(state_out),
|
||||
self._get_data_ptr(logits_out)
|
||||
)
|
||||
|
||||
return logits_out, state_out
|
||||
|
||||
def eval_sequence(
|
||||
self,
|
||||
tokens: List[int],
|
||||
state_in: Optional[NumpyArrayOrPyTorchTensor],
|
||||
state_out: Optional[NumpyArrayOrPyTorchTensor] = None,
|
||||
logits_out: Optional[NumpyArrayOrPyTorchTensor] = None,
|
||||
use_numpy: bool = False
|
||||
) -> Tuple[NumpyArrayOrPyTorchTensor, NumpyArrayOrPyTorchTensor]:
|
||||
"""
|
||||
Evaluates the model for a sequence of tokens.
|
||||
|
||||
NOTE ON GGML NODE LIMIT
|
||||
|
||||
ggml has a hard-coded limit on max amount of nodes in a computation graph. The sequence graph is built in a way that quickly exceedes
|
||||
this limit when using large models and/or large sequence lengths.
|
||||
Fortunately, rwkv.cpp's fork of ggml has increased limit which was tested to work for sequence lengths up to 64 for 14B models.
|
||||
|
||||
If you get `GGML_ASSERT: ...\\ggml.c:16941: cgraph->n_nodes < GGML_MAX_NODES`, this means you've exceeded the limit.
|
||||
To get rid of the assertion failure, reduce the model size and/or sequence length.
|
||||
|
||||
In case of any error, this method will throw an exception.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
tokens : List[int]
|
||||
Indices of the next tokens to be seen by the model. Must be in range 0 <= token < n_vocab.
|
||||
state_in : Optional[NumpyArrayOrTorchTensor]
|
||||
State from previous call of this method. If this is a first pass, set it to None.
|
||||
state_out : Optional[NumpyArrayOrTorchTensor]
|
||||
Optional output tensor for state. If provided, must be of type float32, contiguous and of shape (state_buffer_element_count).
|
||||
logits_out : Optional[NumpyArrayOrTorchTensor]
|
||||
Optional output tensor for logits. If provided, must be of type float32, contiguous and of shape (logits_buffer_element_count).
|
||||
use_numpy : bool
|
||||
If set to True, numpy's ndarrays will be created instead of PyTorch's Tensors.
|
||||
This parameter is ignored if any tensor parameter is not None; in such case,
|
||||
type of returned tensors will match the type of received tensors.
|
||||
|
||||
Returns
|
||||
-------
|
||||
logits, state
|
||||
Logits vector of shape (n_vocab); state for the next step.
|
||||
"""
|
||||
|
||||
if not self._valid:
|
||||
raise ValueError('Model was freed')
|
||||
|
||||
use_numpy = self._detect_numpy_usage([state_in, state_out, logits_out], use_numpy)
|
||||
|
||||
if state_in is not None:
|
||||
self._validate_tensor(state_in, 'state_in', self._state_buffer_element_count)
|
||||
|
||||
state_in_ptr = self._get_data_ptr(state_in)
|
||||
else:
|
||||
state_in_ptr = 0
|
||||
|
||||
if state_out is not None:
|
||||
self._validate_tensor(state_out, 'state_out', self._state_buffer_element_count)
|
||||
else:
|
||||
state_out = self._zeros_float32(self._state_buffer_element_count, use_numpy)
|
||||
|
||||
if logits_out is not None:
|
||||
self._validate_tensor(logits_out, 'logits_out', self._logits_buffer_element_count)
|
||||
else:
|
||||
logits_out = self._zeros_float32(self._logits_buffer_element_count, use_numpy)
|
||||
|
||||
self._library.rwkv_eval_sequence(
|
||||
self._ctx,
|
||||
tokens,
|
||||
state_in_ptr,
|
||||
self._get_data_ptr(state_out),
|
||||
self._get_data_ptr(logits_out)
|
||||
)
|
||||
|
||||
return logits_out, state_out
|
||||
|
||||
def eval_sequence_in_chunks(
|
||||
self,
|
||||
tokens: List[int],
|
||||
state_in: Optional[NumpyArrayOrPyTorchTensor],
|
||||
state_out: Optional[NumpyArrayOrPyTorchTensor] = None,
|
||||
logits_out: Optional[NumpyArrayOrPyTorchTensor] = None,
|
||||
chunk_size: int = 16,
|
||||
use_numpy: bool = False
|
||||
) -> Tuple[NumpyArrayOrPyTorchTensor, NumpyArrayOrPyTorchTensor]:
|
||||
"""
|
||||
Evaluates the model for a sequence of tokens using `eval_sequence`, splitting a potentially long sequence into fixed-length chunks.
|
||||
This function is useful for processing complete prompts and user input in chat & role-playing use-cases.
|
||||
It is recommended to use this function instead of `eval_sequence` to avoid mistakes and get maximum performance.
|
||||
|
||||
Chunking allows processing sequences of thousands of tokens, while not reaching the ggml's node limit and not consuming too much memory.
|
||||
A reasonable and recommended value of chunk size is 16. If you want maximum performance, try different chunk sizes in range [2..64]
|
||||
and choose one that works the best in your use case.
|
||||
|
||||
In case of any error, this method will throw an exception.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
tokens : List[int]
|
||||
Indices of the next tokens to be seen by the model. Must be in range 0 <= token < n_vocab.
|
||||
chunk_size : int
|
||||
Size of each chunk in tokens, must be positive.
|
||||
state_in : Optional[NumpyArrayOrTorchTensor]
|
||||
State from previous call of this method. If this is a first pass, set it to None.
|
||||
state_out : Optional[NumpyArrayOrTorchTensor]
|
||||
Optional output tensor for state. If provided, must be of type float32, contiguous and of shape (state_buffer_element_count).
|
||||
logits_out : Optional[NumpyArrayOrTorchTensor]
|
||||
Optional output tensor for logits. If provided, must be of type float32, contiguous and of shape (logits_buffer_element_count).
|
||||
use_numpy : bool
|
||||
If set to True, numpy's ndarrays will be created instead of PyTorch's Tensors.
|
||||
This parameter is ignored if any tensor parameter is not None; in such case,
|
||||
type of returned tensors will match the type of received tensors.
|
||||
|
||||
Returns
|
||||
-------
|
||||
logits, state
|
||||
Logits vector of shape (n_vocab); state for the next step.
|
||||
"""
|
||||
|
||||
if not self._valid:
|
||||
raise ValueError('Model was freed')
|
||||
|
||||
use_numpy = self._detect_numpy_usage([state_in, state_out, logits_out], use_numpy)
|
||||
|
||||
if state_in is not None:
|
||||
self._validate_tensor(state_in, 'state_in', self._state_buffer_element_count)
|
||||
|
||||
state_in_ptr = self._get_data_ptr(state_in)
|
||||
else:
|
||||
state_in_ptr = 0
|
||||
|
||||
if state_out is not None:
|
||||
self._validate_tensor(state_out, 'state_out', self._state_buffer_element_count)
|
||||
else:
|
||||
state_out = self._zeros_float32(self._state_buffer_element_count, use_numpy)
|
||||
|
||||
if logits_out is not None:
|
||||
self._validate_tensor(logits_out, 'logits_out', self._logits_buffer_element_count)
|
||||
else:
|
||||
logits_out = self._zeros_float32(self._logits_buffer_element_count, use_numpy)
|
||||
|
||||
self._library.rwkv_eval_sequence_in_chunks(
|
||||
self._ctx,
|
||||
tokens,
|
||||
chunk_size,
|
||||
state_in_ptr,
|
||||
self._get_data_ptr(state_out),
|
||||
self._get_data_ptr(logits_out)
|
||||
)
|
||||
|
||||
return logits_out, state_out
|
||||
|
||||
def free(self) -> None:
|
||||
"""
|
||||
Frees all allocated resources.
|
||||
In case of any error, this method will throw an exception.
|
||||
The object must not be used anymore after calling this method.
|
||||
"""
|
||||
|
||||
if not self._valid:
|
||||
raise ValueError('Already freed')
|
||||
|
||||
self._valid = False
|
||||
|
||||
self._library.rwkv_free(self._ctx)
|
||||
|
||||
def __del__(self) -> None:
|
||||
# Free the context on GC in case user forgot to call free() explicitly.
|
||||
if hasattr(self, '_valid') and self._valid:
|
||||
self.free()
|
||||
|
||||
def _is_pytorch_tensor(self, tensor: NumpyArrayOrPyTorchTensor) -> bool:
|
||||
return hasattr(tensor, '__module__') and tensor.__module__ == 'torch'
|
||||
|
||||
def _detect_numpy_usage(self, tensors: List[Optional[NumpyArrayOrPyTorchTensor]], use_numpy_by_default: bool) -> bool:
|
||||
for tensor in tensors:
|
||||
if tensor is not None:
|
||||
return False if self._is_pytorch_tensor(tensor) else True
|
||||
|
||||
return use_numpy_by_default
|
||||
|
||||
def _validate_tensor(self, tensor: NumpyArrayOrPyTorchTensor, name: str, size: int) -> None:
|
||||
if self._is_pytorch_tensor(tensor):
|
||||
tensor: torch.Tensor = tensor
|
||||
|
||||
if tensor.device != torch.device('cpu'):
|
||||
raise ValueError(f'{name} is not on CPU')
|
||||
if tensor.dtype != torch.float32:
|
||||
raise ValueError(f'{name} is not of type float32')
|
||||
if tensor.shape != (size,):
|
||||
raise ValueError(f'{name} has invalid shape {tensor.shape}, expected ({size})')
|
||||
if not tensor.is_contiguous():
|
||||
raise ValueError(f'{name} is not contiguous')
|
||||
else:
|
||||
import numpy as np
|
||||
tensor: np.ndarray = tensor
|
||||
|
||||
if tensor.dtype != np.float32:
|
||||
raise ValueError(f'{name} is not of type float32')
|
||||
if tensor.shape != (size,):
|
||||
raise ValueError(f'{name} has invalid shape {tensor.shape}, expected ({size})')
|
||||
if not tensor.data.contiguous:
|
||||
raise ValueError(f'{name} is not contiguous')
|
||||
|
||||
def _get_data_ptr(self, tensor: NumpyArrayOrPyTorchTensor):
|
||||
if self._is_pytorch_tensor(tensor):
|
||||
return tensor.data_ptr()
|
||||
else:
|
||||
return tensor.ctypes.data
|
||||
|
||||
def _zeros_float32(self, element_count: int, use_numpy: bool) -> NumpyArrayOrPyTorchTensor:
|
||||
if use_numpy:
|
||||
import numpy as np
|
||||
return np.zeros(element_count, dtype=np.float32)
|
||||
else:
|
||||
return torch.zeros(element_count, dtype=torch.float32, device='cpu')
|
||||
@ -1,502 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
import ctypes
|
||||
import pathlib
|
||||
import platform
|
||||
from typing import Optional, List, Tuple, Callable
|
||||
|
||||
QUANTIZED_FORMAT_NAMES: Tuple[str, str, str, str, str] = (
|
||||
"Q4_0",
|
||||
"Q4_1",
|
||||
"Q5_0",
|
||||
"Q5_1",
|
||||
"Q8_0",
|
||||
)
|
||||
|
||||
P_FLOAT = ctypes.POINTER(ctypes.c_float)
|
||||
P_INT = ctypes.POINTER(ctypes.c_int32)
|
||||
|
||||
|
||||
class RWKVContext:
|
||||
def __init__(self, ptr: ctypes.pointer) -> None:
|
||||
self.ptr: ctypes.pointer = ptr
|
||||
|
||||
|
||||
class RWKVSharedLibrary:
|
||||
"""
|
||||
Python wrapper around rwkv.cpp shared library.
|
||||
"""
|
||||
|
||||
def __init__(self, shared_library_path: str) -> None:
|
||||
"""
|
||||
Loads the shared library from specified file.
|
||||
In case of any error, this method will throw an exception.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
shared_library_path : str
|
||||
Path to rwkv.cpp shared library. On Windows, it would look like 'rwkv.dll'. On UNIX, 'rwkv.so'.
|
||||
"""
|
||||
# When Python is greater than 3.8, we need to reprocess the custom dll
|
||||
# according to the documentation to prevent loading failure errors.
|
||||
# https://docs.python.org/3/whatsnew/3.8.html#ctypes
|
||||
if platform.system().lower() == "windows":
|
||||
self.library = ctypes.CDLL(shared_library_path, winmode=0)
|
||||
else:
|
||||
self.library = ctypes.cdll.LoadLibrary(shared_library_path)
|
||||
|
||||
self.library.rwkv_init_from_file.argtypes = [ctypes.c_char_p, ctypes.c_uint32]
|
||||
self.library.rwkv_init_from_file.restype = ctypes.c_void_p
|
||||
|
||||
self.library.rwkv_gpu_offload_layers.argtypes = [
|
||||
ctypes.c_void_p,
|
||||
ctypes.c_uint32,
|
||||
]
|
||||
self.library.rwkv_gpu_offload_layers.restype = ctypes.c_bool
|
||||
|
||||
self.library.rwkv_eval.argtypes = [
|
||||
ctypes.c_void_p, # ctx
|
||||
ctypes.c_int32, # token
|
||||
P_FLOAT, # state_in
|
||||
P_FLOAT, # state_out
|
||||
P_FLOAT, # logits_out
|
||||
]
|
||||
self.library.rwkv_eval.restype = ctypes.c_bool
|
||||
|
||||
self.library.rwkv_eval_sequence.argtypes = [
|
||||
ctypes.c_void_p, # ctx
|
||||
P_INT, # tokens
|
||||
ctypes.c_size_t, # token count
|
||||
P_FLOAT, # state_in
|
||||
P_FLOAT, # state_out
|
||||
P_FLOAT, # logits_out
|
||||
]
|
||||
self.library.rwkv_eval_sequence.restype = ctypes.c_bool
|
||||
|
||||
self.library.rwkv_eval_sequence_in_chunks.argtypes = [
|
||||
ctypes.c_void_p, # ctx
|
||||
P_INT, # tokens
|
||||
ctypes.c_size_t, # token count
|
||||
ctypes.c_size_t, # chunk size
|
||||
P_FLOAT, # state_in
|
||||
P_FLOAT, # state_out
|
||||
P_FLOAT, # logits_out
|
||||
]
|
||||
self.library.rwkv_eval_sequence_in_chunks.restype = ctypes.c_bool
|
||||
|
||||
self.library.rwkv_get_arch_version_major.argtypes = [ctypes.c_void_p]
|
||||
self.library.rwkv_get_arch_version_major.restype = ctypes.c_uint32
|
||||
|
||||
self.library.rwkv_get_arch_version_minor.argtypes = [ctypes.c_void_p]
|
||||
self.library.rwkv_get_arch_version_minor.restype = ctypes.c_uint32
|
||||
|
||||
self.library.rwkv_get_n_vocab.argtypes = [ctypes.c_void_p]
|
||||
self.library.rwkv_get_n_vocab.restype = ctypes.c_size_t
|
||||
|
||||
self.library.rwkv_get_n_embed.argtypes = [ctypes.c_void_p]
|
||||
self.library.rwkv_get_n_embed.restype = ctypes.c_size_t
|
||||
|
||||
self.library.rwkv_get_n_layer.argtypes = [ctypes.c_void_p]
|
||||
self.library.rwkv_get_n_layer.restype = ctypes.c_size_t
|
||||
|
||||
self.library.rwkv_get_state_buffer_element_count.argtypes = [ctypes.c_void_p]
|
||||
self.library.rwkv_get_state_buffer_element_count.restype = ctypes.c_uint32
|
||||
|
||||
self.library.rwkv_get_logits_buffer_element_count.argtypes = [ctypes.c_void_p]
|
||||
self.library.rwkv_get_logits_buffer_element_count.restype = ctypes.c_uint32
|
||||
|
||||
self.library.rwkv_free.argtypes = [ctypes.c_void_p]
|
||||
self.library.rwkv_free.restype = None
|
||||
|
||||
self.library.rwkv_free.argtypes = [ctypes.c_void_p]
|
||||
self.library.rwkv_free.restype = None
|
||||
|
||||
self.library.rwkv_quantize_model_file.argtypes = [
|
||||
ctypes.c_char_p,
|
||||
ctypes.c_char_p,
|
||||
ctypes.c_char_p,
|
||||
]
|
||||
self.library.rwkv_quantize_model_file.restype = ctypes.c_bool
|
||||
|
||||
self.library.rwkv_get_system_info_string.argtypes = []
|
||||
self.library.rwkv_get_system_info_string.restype = ctypes.c_char_p
|
||||
|
||||
self.nullptr = ctypes.cast(0, ctypes.c_void_p)
|
||||
|
||||
def rwkv_init_from_file(
|
||||
self, model_file_path: str, thread_count: int
|
||||
) -> RWKVContext:
|
||||
"""
|
||||
Loads the model from a file and prepares it for inference.
|
||||
Throws an exception in case of any error. Error messages would be printed to stderr.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
model_file_path : str
|
||||
Path to model file in ggml format.
|
||||
thread_count : int
|
||||
Count of threads to use, must be positive.
|
||||
"""
|
||||
|
||||
ptr = self.library.rwkv_init_from_file(
|
||||
model_file_path.encode("utf-8"), ctypes.c_uint32(thread_count)
|
||||
)
|
||||
|
||||
if ptr is None:
|
||||
raise ValueError("rwkv_init_from_file failed, check stderr")
|
||||
|
||||
return RWKVContext(ptr)
|
||||
|
||||
def rwkv_gpu_offload_layers(self, ctx: RWKVContext, layer_count: int) -> bool:
|
||||
"""
|
||||
Offloads specified count of model layers onto the GPU. Offloaded layers are evaluated using cuBLAS or CLBlast.
|
||||
For the purposes of this function, model head (unembedding matrix) is treated as an additional layer:
|
||||
- pass `rwkv_get_n_layer(ctx)` to offload all layers except model head
|
||||
- pass `rwkv_get_n_layer(ctx) + 1` to offload all layers, including model head
|
||||
Returns true if at least one layer was offloaded.
|
||||
If rwkv.cpp was compiled without cuBLAS and CLBlast support, this function is a no-op and always returns false.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
layer_count : int
|
||||
Count of layers to offload onto the GPU, must be >= 0.
|
||||
"""
|
||||
|
||||
if not (layer_count >= 0):
|
||||
raise ValueError("Layer count must be >= 0")
|
||||
|
||||
return self.library.rwkv_gpu_offload_layers(
|
||||
ctx.ptr, ctypes.c_uint32(layer_count)
|
||||
)
|
||||
|
||||
def rwkv_eval(
|
||||
self,
|
||||
ctx: RWKVContext,
|
||||
token: int,
|
||||
state_in_address: Optional[int],
|
||||
state_out_address: int,
|
||||
logits_out_address: int,
|
||||
) -> None:
|
||||
"""
|
||||
Evaluates the model for a single token.
|
||||
Throws an exception in case of any error. Error messages would be printed to stderr.
|
||||
Not thread-safe. For parallel inference, call rwkv_clone_context to create one rwkv_context for each thread.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
token : int
|
||||
Next token index, in range 0 <= token < n_vocab.
|
||||
state_in_address : int
|
||||
Address of the first element of a FP32 buffer of size rwkv_get_state_buffer_element_count; or None, if this is a first pass.
|
||||
state_out_address : int
|
||||
Address of the first element of a FP32 buffer of size rwkv_get_state_buffer_element_count. This buffer will be written to.
|
||||
logits_out_address : int
|
||||
Address of the first element of a FP32 buffer of size rwkv_get_logits_buffer_element_count. This buffer will be written to.
|
||||
"""
|
||||
|
||||
if not self.library.rwkv_eval(
|
||||
ctx.ptr,
|
||||
ctypes.c_int32(token),
|
||||
ctypes.cast(0 if state_in_address is None else state_in_address, P_FLOAT),
|
||||
ctypes.cast(state_out_address, P_FLOAT),
|
||||
ctypes.cast(logits_out_address, P_FLOAT),
|
||||
):
|
||||
raise ValueError("rwkv_eval failed, check stderr")
|
||||
|
||||
def rwkv_eval_sequence(
|
||||
self,
|
||||
ctx: RWKVContext,
|
||||
tokens: List[int],
|
||||
state_in_address: Optional[int],
|
||||
state_out_address: int,
|
||||
logits_out_address: int,
|
||||
) -> None:
|
||||
"""
|
||||
Evaluates the model for a sequence of tokens.
|
||||
Uses a faster algorithm than `rwkv_eval` if you do not need the state and logits for every token. Best used with sequence lengths of 64 or so.
|
||||
Has to build a computation graph on the first call for a given sequence, but will use this cached graph for subsequent calls of the same sequence length.
|
||||
|
||||
NOTE ON GGML NODE LIMIT
|
||||
|
||||
ggml has a hard-coded limit on max amount of nodes in a computation graph. The sequence graph is built in a way that quickly exceedes
|
||||
this limit when using large models and/or large sequence lengths.
|
||||
Fortunately, rwkv.cpp's fork of ggml has increased limit which was tested to work for sequence lengths up to 64 for 14B models.
|
||||
|
||||
If you get `GGML_ASSERT: ...\\ggml.c:16941: cgraph->n_nodes < GGML_MAX_NODES`, this means you've exceeded the limit.
|
||||
To get rid of the assertion failure, reduce the model size and/or sequence length.
|
||||
|
||||
Not thread-safe. For parallel inference, call `rwkv_clone_context` to create one rwkv_context for each thread.
|
||||
Throws an exception in case of any error. Error messages would be printed to stderr.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
tokens : List[int]
|
||||
Next token indices, in range 0 <= token < n_vocab.
|
||||
state_in_address : int
|
||||
Address of the first element of a FP32 buffer of size rwkv_get_state_buffer_element_count; or None, if this is a first pass.
|
||||
state_out_address : int
|
||||
Address of the first element of a FP32 buffer of size rwkv_get_state_buffer_element_count. This buffer will be written to.
|
||||
logits_out_address : int
|
||||
Address of the first element of a FP32 buffer of size rwkv_get_logits_buffer_element_count. This buffer will be written to.
|
||||
"""
|
||||
|
||||
if not self.library.rwkv_eval_sequence(
|
||||
ctx.ptr,
|
||||
ctypes.cast((ctypes.c_int32 * len(tokens))(*tokens), P_INT),
|
||||
ctypes.c_size_t(len(tokens)),
|
||||
ctypes.cast(0 if state_in_address is None else state_in_address, P_FLOAT),
|
||||
ctypes.cast(state_out_address, P_FLOAT),
|
||||
ctypes.cast(logits_out_address, P_FLOAT),
|
||||
):
|
||||
raise ValueError("rwkv_eval_sequence failed, check stderr")
|
||||
|
||||
def rwkv_eval_sequence_in_chunks(
|
||||
self,
|
||||
ctx: RWKVContext,
|
||||
tokens: List[int],
|
||||
chunk_size: int,
|
||||
state_in_address: Optional[int],
|
||||
state_out_address: int,
|
||||
logits_out_address: int,
|
||||
) -> None:
|
||||
"""
|
||||
Evaluates the model for a sequence of tokens using `rwkv_eval_sequence`, splitting a potentially long sequence into fixed-length chunks.
|
||||
This function is useful for processing complete prompts and user input in chat & role-playing use-cases.
|
||||
It is recommended to use this function instead of `rwkv_eval_sequence` to avoid mistakes and get maximum performance.
|
||||
|
||||
Chunking allows processing sequences of thousands of tokens, while not reaching the ggml's node limit and not consuming too much memory.
|
||||
A reasonable and recommended value of chunk size is 16. If you want maximum performance, try different chunk sizes in range [2..64]
|
||||
and choose one that works the best in your use case.
|
||||
|
||||
Not thread-safe. For parallel inference, call `rwkv_clone_context` to create one rwkv_context for each thread.
|
||||
Throws an exception in case of any error. Error messages would be printed to stderr.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
tokens : List[int]
|
||||
Next token indices, in range 0 <= token < n_vocab.
|
||||
chunk_size : int
|
||||
Size of each chunk in tokens, must be positive.
|
||||
state_in_address : int
|
||||
Address of the first element of a FP32 buffer of size rwkv_get_state_buffer_element_count; or None, if this is a first pass.
|
||||
state_out_address : int
|
||||
Address of the first element of a FP32 buffer of size rwkv_get_state_buffer_element_count. This buffer will be written to.
|
||||
logits_out_address : int
|
||||
Address of the first element of a FP32 buffer of size rwkv_get_logits_buffer_element_count. This buffer will be written to.
|
||||
"""
|
||||
|
||||
if not self.library.rwkv_eval_sequence_in_chunks(
|
||||
ctx.ptr,
|
||||
ctypes.cast((ctypes.c_int32 * len(tokens))(*tokens), P_INT),
|
||||
ctypes.c_size_t(len(tokens)),
|
||||
ctypes.c_size_t(chunk_size),
|
||||
ctypes.cast(0 if state_in_address is None else state_in_address, P_FLOAT),
|
||||
ctypes.cast(state_out_address, P_FLOAT),
|
||||
ctypes.cast(logits_out_address, P_FLOAT),
|
||||
):
|
||||
raise ValueError("rwkv_eval_sequence_in_chunks failed, check stderr")
|
||||
|
||||
def rwkv_get_arch_version_major(self, ctx: RWKVContext) -> int:
|
||||
"""
|
||||
Returns the major version used by the given model.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
"""
|
||||
|
||||
return self.library.rwkv_get_arch_version_major(ctx.ptr)
|
||||
|
||||
def rwkv_get_arch_version_minor(self, ctx: RWKVContext) -> int:
|
||||
"""
|
||||
Returns the minor version used by the given model.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
"""
|
||||
|
||||
return self.library.rwkv_get_arch_version_minor(ctx.ptr)
|
||||
|
||||
def rwkv_get_n_vocab(self, ctx: RWKVContext) -> int:
|
||||
"""
|
||||
Returns the number of tokens in the given model's vocabulary.
|
||||
Useful for telling 20B_tokenizer models (n_vocab = 50277) apart from World models (n_vocab = 65536).
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
"""
|
||||
|
||||
return self.library.rwkv_get_n_vocab(ctx.ptr)
|
||||
|
||||
def rwkv_get_n_embed(self, ctx: RWKVContext) -> int:
|
||||
"""
|
||||
Returns the number of elements in the given model's embedding.
|
||||
Useful for reading individual fields of a model's hidden state.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
"""
|
||||
|
||||
return self.library.rwkv_get_n_embed(ctx.ptr)
|
||||
|
||||
def rwkv_get_n_layer(self, ctx: RWKVContext) -> int:
|
||||
"""
|
||||
Returns the number of layers in the given model.
|
||||
A layer is a pair of RWKV and FFN operations, stacked multiple times throughout the model.
|
||||
Embedding matrix and model head (unembedding matrix) are NOT counted in `n_layer`.
|
||||
Useful for always offloading the entire model to GPU.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
"""
|
||||
|
||||
return self.library.rwkv_get_n_layer(ctx.ptr)
|
||||
|
||||
def rwkv_get_state_buffer_element_count(self, ctx: RWKVContext) -> int:
|
||||
"""
|
||||
Returns count of FP32 elements in state buffer.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
"""
|
||||
|
||||
return self.library.rwkv_get_state_buffer_element_count(ctx.ptr)
|
||||
|
||||
def rwkv_get_logits_buffer_element_count(self, ctx: RWKVContext) -> int:
|
||||
"""
|
||||
Returns count of FP32 elements in logits buffer.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
"""
|
||||
|
||||
return self.library.rwkv_get_logits_buffer_element_count(ctx.ptr)
|
||||
|
||||
def rwkv_free(self, ctx: RWKVContext) -> None:
|
||||
"""
|
||||
Frees all allocated memory and the context.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
ctx : RWKVContext
|
||||
RWKV context obtained from rwkv_init_from_file.
|
||||
"""
|
||||
|
||||
self.library.rwkv_free(ctx.ptr)
|
||||
|
||||
ctx.ptr = self.nullptr
|
||||
|
||||
def rwkv_quantize_model_file(
|
||||
self, model_file_path_in: str, model_file_path_out: str, format_name: str
|
||||
) -> None:
|
||||
"""
|
||||
Quantizes FP32 or FP16 model to one of INT4 formats.
|
||||
Throws an exception in case of any error. Error messages would be printed to stderr.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
model_file_path_in : str
|
||||
Path to model file in ggml format, must be either FP32 or FP16.
|
||||
model_file_path_out : str
|
||||
Quantized model will be written here.
|
||||
format_name : str
|
||||
One of QUANTIZED_FORMAT_NAMES.
|
||||
"""
|
||||
|
||||
if format_name not in QUANTIZED_FORMAT_NAMES:
|
||||
raise ValueError(
|
||||
f"Unknown format name {format_name}, use one of {QUANTIZED_FORMAT_NAMES}"
|
||||
)
|
||||
|
||||
if not self.library.rwkv_quantize_model_file(
|
||||
model_file_path_in.encode("utf-8"),
|
||||
model_file_path_out.encode("utf-8"),
|
||||
format_name.encode("utf-8"),
|
||||
):
|
||||
raise ValueError("rwkv_quantize_model_file failed, check stderr")
|
||||
|
||||
def rwkv_get_system_info_string(self) -> str:
|
||||
"""
|
||||
Returns system information string.
|
||||
"""
|
||||
|
||||
return self.library.rwkv_get_system_info_string().decode("utf-8")
|
||||
|
||||
|
||||
def load_rwkv_shared_library() -> RWKVSharedLibrary:
|
||||
"""
|
||||
Attempts to find rwkv.cpp shared library and load it.
|
||||
To specify exact path to the library, create an instance of RWKVSharedLibrary explicitly.
|
||||
"""
|
||||
|
||||
file_name: str
|
||||
|
||||
if "win32" in sys.platform or "cygwin" in sys.platform:
|
||||
file_name = "rwkv.dll"
|
||||
elif "darwin" in sys.platform:
|
||||
file_name = "librwkv.dylib"
|
||||
else:
|
||||
file_name = "librwkv.so"
|
||||
|
||||
# Possible sub-paths to the library relative to the repo dir.
|
||||
child_paths: List[Callable[[pathlib.Path], pathlib.Path]] = [
|
||||
# No lookup for Debug config here.
|
||||
# I assume that if a user wants to debug the library,
|
||||
# they will be able to find the library and set the exact path explicitly.
|
||||
lambda p: p / "backend-python" / "rwkv_pip" / "cpp" / file_name,
|
||||
lambda p: p / "bin" / "Release" / file_name,
|
||||
lambda p: p / "bin" / file_name,
|
||||
# Some people prefer to build in the "build" subdirectory.
|
||||
lambda p: p / "build" / "bin" / "Release" / file_name,
|
||||
lambda p: p / "build" / "bin" / file_name,
|
||||
lambda p: p / "build" / file_name,
|
||||
# Fallback.
|
||||
lambda p: p / file_name,
|
||||
]
|
||||
|
||||
working_dir: pathlib.Path = pathlib.Path(os.path.abspath(os.getcwd()))
|
||||
|
||||
parent_paths: List[pathlib.Path] = [
|
||||
# Possible repo dirs relative to the working dir.
|
||||
# ./python/rwkv_cpp
|
||||
working_dir.parent.parent,
|
||||
# ./python
|
||||
working_dir.parent,
|
||||
# .
|
||||
working_dir,
|
||||
# Repo dir relative to this Python file.
|
||||
pathlib.Path(os.path.abspath(__file__)).parent.parent.parent,
|
||||
]
|
||||
|
||||
for parent_path in parent_paths:
|
||||
for child_path in child_paths:
|
||||
full_path: pathlib.Path = child_path(parent_path)
|
||||
|
||||
if os.path.isfile(full_path):
|
||||
return RWKVSharedLibrary(str(full_path))
|
||||
|
||||
raise ValueError(
|
||||
f"Failed to find {file_name} automatically; "
|
||||
f"you need to find the library and create RWKVSharedLibrary specifying the path to it"
|
||||
)
|
||||
@ -1,75 +0,0 @@
|
||||
#include <cublas_v2.h>
|
||||
#include <cuda.h>
|
||||
#include <cuda_fp16.h>
|
||||
#include <cuda_runtime.h>
|
||||
#include <torch/extension.h>
|
||||
#include <c10/cuda/CUDAGuard.h>
|
||||
#include <ATen/cuda/CUDAContext.h>
|
||||
|
||||
#define CUBLAS_CHECK(condition) \
|
||||
for (cublasStatus_t _cublas_check_status = (condition); \
|
||||
_cublas_check_status != CUBLAS_STATUS_SUCCESS;) \
|
||||
throw std::runtime_error("cuBLAS error " + \
|
||||
std::to_string(_cublas_check_status) + " at " + \
|
||||
std::to_string(__LINE__));
|
||||
|
||||
#define CUDA_CHECK(condition) \
|
||||
for (cudaError_t _cuda_check_status = (condition); \
|
||||
_cuda_check_status != cudaSuccess;) \
|
||||
throw std::runtime_error( \
|
||||
"CUDA error " + std::string(cudaGetErrorString(_cuda_check_status)) + \
|
||||
" at " + std::to_string(__LINE__));
|
||||
|
||||
/*
|
||||
NOTE: blas gemm is column-major by default, but we need row-major output.
|
||||
The data of row-major, transposed matrix is exactly the same as the
|
||||
column-major, non-transposed matrix, and C = A * B ---> C^T = B^T * A^T
|
||||
*/
|
||||
void gemm_fp16_cublas(torch::Tensor a, torch::Tensor b, torch::Tensor c) {
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(a));
|
||||
const auto cuda_data_type = CUDA_R_16F;
|
||||
const auto cuda_c_data_type =
|
||||
c.dtype() == torch::kFloat32 ? CUDA_R_32F : CUDA_R_16F;
|
||||
const auto compute_type = CUDA_R_32F;
|
||||
const float sp_alpha = 1.f;
|
||||
// swap a and b, and use CUBLAS_OP_N. see the notes above
|
||||
std::swap(a, b);
|
||||
const cublasOperation_t cublas_trans_a = CUBLAS_OP_N;
|
||||
const cublasOperation_t cublas_trans_b = CUBLAS_OP_N;
|
||||
// m = (B^T).size(0) = B.size(1), and = A.size(1) after swap,
|
||||
// negative axis is used because of the existence of batch matmul.
|
||||
const int m = a.size(-1);
|
||||
const int k = a.size(-2);
|
||||
const int n = b.size(-2);
|
||||
const int cublas_lda = m;
|
||||
const int cublas_ldb = k;
|
||||
const int cublas_ldc = m;
|
||||
cublasHandle_t cublas_handle = at::cuda::getCurrentCUDABlasHandle();
|
||||
|
||||
#if CUDA_VERSION >= 11000
|
||||
cublasGemmAlgo_t algo = CUBLAS_GEMM_DEFAULT;
|
||||
#else
|
||||
cublasGemmAlgo_t algo = CUBLAS_GEMM_DFALT_TENSOR_OP;
|
||||
#endif
|
||||
const float sp_beta = 0.f;
|
||||
if (a.sizes().size() == 2 && b.sizes().size() == 2) {
|
||||
CUBLAS_CHECK(cublasGemmEx(
|
||||
cublas_handle, cublas_trans_a, cublas_trans_b, m, n, k, &sp_alpha,
|
||||
a.data_ptr(), cuda_data_type, cublas_lda, b.data_ptr(), cuda_data_type,
|
||||
cublas_ldb, &sp_beta, c.data_ptr(), cuda_c_data_type, cublas_ldc,
|
||||
compute_type, algo));
|
||||
} else {
|
||||
// batch matmul
|
||||
assert(a.sizes().size() == 3 && b.sizes().size() == 3);
|
||||
|
||||
const long long int cublas_stride_a = m * k;
|
||||
const long long int cublas_stride_b = k * n;
|
||||
const long long int cublas_stride_c = m * n;
|
||||
CUBLAS_CHECK(cublasGemmStridedBatchedEx(
|
||||
cublas_handle, cublas_trans_a, cublas_trans_b, m,
|
||||
n, k, &sp_alpha, a.data_ptr(), cuda_data_type, cublas_lda,
|
||||
cublas_stride_a, b.data_ptr(), cuda_data_type, cublas_ldb, cublas_stride_b,
|
||||
&sp_beta, c.data_ptr(), cuda_c_data_type, cublas_ldc, cublas_stride_c,
|
||||
a.size(0), compute_type, algo));
|
||||
}
|
||||
}
|
||||
@ -1,246 +0,0 @@
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include "ATen/ATen.h"
|
||||
#include <cuda_fp16.h>
|
||||
#define MIN_VALUE (-1e38)
|
||||
typedef at::Half fp16;
|
||||
__half *cast(fp16 *ptr) {
|
||||
return reinterpret_cast<__half *>(ptr);
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
__global__ void kernel_wkv_forward(const int B, const int T, const int C,
|
||||
const float *__restrict__ const _w, const float *__restrict__ const _u, const F *__restrict__ const _k, const F *__restrict__ const _v,
|
||||
F *__restrict__ const _y, float *__restrict__ const _aa, float *__restrict__ const _bb, float *__restrict__ const _pp) {
|
||||
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
|
||||
const int _b = idx / C;
|
||||
const int _c = idx % C;
|
||||
const int _offset = _b * T * C + _c;
|
||||
const int _state_offset = _b * C + _c;
|
||||
|
||||
float u = _u[_c];
|
||||
float w = _w[_c];
|
||||
const F *__restrict__ const k = _k + _offset;
|
||||
const F *__restrict__ const v = _v + _offset;
|
||||
F *__restrict__ const y = _y + _offset;
|
||||
|
||||
float aa = _aa[_state_offset];
|
||||
float bb = _bb[_state_offset];
|
||||
float pp = _pp[_state_offset];
|
||||
for (int i = 0; i < T; i++) {
|
||||
const int ii = i * C;
|
||||
const float kk = float(k[ii]);
|
||||
const float vv = float(v[ii]);
|
||||
float ww = u + kk;
|
||||
float p = max(pp, ww);
|
||||
float e1 = exp(pp - p);
|
||||
float e2 = exp(ww - p);
|
||||
y[ii] = F((e1 * aa + e2 * vv) / (e1 * bb + e2));
|
||||
ww = w + pp;
|
||||
p = max(ww, kk);
|
||||
e1 = exp(ww - p);
|
||||
e2 = exp(kk - p);
|
||||
aa = e1 * aa + e2 * vv;
|
||||
bb = e1 * bb + e2;
|
||||
pp = p;
|
||||
}
|
||||
_aa[_state_offset] = aa;
|
||||
_bb[_state_offset] = bb;
|
||||
_pp[_state_offset] = pp;
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
void cuda_wkv_forward(int B, int T, int C, float *w, float *u, F *k, F *v, F *y, float *aa, float *bb, float *pp) {
|
||||
dim3 threadsPerBlock( min(C, 32) );
|
||||
assert(B * C % threadsPerBlock.x == 0);
|
||||
dim3 numBlocks(B * C / threadsPerBlock.x);
|
||||
kernel_wkv_forward<<<numBlocks, threadsPerBlock>>>(B, T, C, w, u, k, v, y, aa, bb, pp);
|
||||
}
|
||||
|
||||
template void cuda_wkv_forward<fp16>(
|
||||
int B, int T, int C,
|
||||
float *w, float *u, fp16 *k, fp16 *v, fp16 *y,
|
||||
float *aa, float *bb, float *pp);
|
||||
template void cuda_wkv_forward<float>(
|
||||
int B, int T, int C,
|
||||
float *w, float *u, float *k, float *v, float *y,
|
||||
float *aa, float *bb, float *pp);
|
||||
|
||||
__global__ void kernel_mm_seq_fp32i8(
|
||||
const int B, const int N, const int M,
|
||||
const float *__restrict__ const x, const int x_stride,
|
||||
const uint8_t *__restrict__ const w, const int w_stride,
|
||||
const float *__restrict__ const mx,
|
||||
const float *__restrict__ const rx,
|
||||
const float *__restrict__ const my,
|
||||
const float *__restrict__ const ry,
|
||||
float *__restrict__ const y, const int y_stride) {
|
||||
|
||||
const int i = blockIdx.x * blockDim.x + threadIdx.x;
|
||||
const int k = blockIdx.y * blockDim.y + threadIdx.y;
|
||||
|
||||
if (i < B && k < M) {
|
||||
float y_local = 0;
|
||||
for (int j = 0; j < N; ++j) {
|
||||
y_local += x[i * x_stride + j] * (
|
||||
(float(w[j * w_stride + k]) + 0.5f)
|
||||
* rx[k] * ry[j] + mx[k] + my[j]
|
||||
);
|
||||
}
|
||||
y[i * y_stride + k] = y_local;
|
||||
}
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
void cuda_mm8_seq(int B, int N, int M,
|
||||
F *x, int x_stride,
|
||||
uint8_t *w, int w_stride,
|
||||
F *mx, F *rx,
|
||||
F *my, F *ry,
|
||||
F *y, int y_stride);
|
||||
|
||||
template <>
|
||||
void cuda_mm8_seq<float>(int B, int N, int M,
|
||||
float *x, int x_stride,
|
||||
uint8_t *w, int w_stride,
|
||||
float *mx, float *rx,
|
||||
float *my, float *ry,
|
||||
float *y, int y_stride) {
|
||||
dim3 blockSize(1, 128);
|
||||
dim3 gridSize((B + blockSize.x - 1) / blockSize.x, (M + blockSize.y - 1) / blockSize.y);
|
||||
kernel_mm_seq_fp32i8<<<gridSize, blockSize>>>(
|
||||
B, N, M, x, x_stride, w, w_stride,
|
||||
mx, rx, my, ry, y, y_stride);
|
||||
}
|
||||
|
||||
__global__ void kernel_mm_seq_fp16i8(
|
||||
const int B, const int N, const int M,
|
||||
const __half *__restrict__ const x, const int x_stride,
|
||||
const uint8_t *__restrict__ const w, const int w_stride,
|
||||
const __half *__restrict__ const mx,
|
||||
const __half *__restrict__ const rx,
|
||||
const __half *__restrict__ const my,
|
||||
const __half *__restrict__ const ry,
|
||||
__half *__restrict__ const y, const int y_stride) {
|
||||
|
||||
const int i = blockIdx.x * blockDim.x + threadIdx.x;
|
||||
const int k = blockIdx.y * blockDim.y + threadIdx.y;
|
||||
|
||||
if (i < B && k < M) {
|
||||
float y_local = 0;
|
||||
for (int j = 0; j < N; ++j) {
|
||||
y_local += __half2float(x[i * x_stride + j]) * (
|
||||
(float(w[j * w_stride + k]) + 0.5f)
|
||||
* __half2float(rx[k]) * __half2float(ry[j])
|
||||
+ __half2float(mx[k]) + __half2float(my[j])
|
||||
);
|
||||
}
|
||||
y[i * y_stride + k] = __float2half(y_local);
|
||||
}
|
||||
}
|
||||
|
||||
template <>
|
||||
void cuda_mm8_seq<fp16>(int B, int N, int M,
|
||||
fp16 *x, int x_stride,
|
||||
uint8_t *w, int w_stride,
|
||||
fp16 *mx, fp16 *rx,
|
||||
fp16 *my, fp16 *ry,
|
||||
fp16 *y, int y_stride) {
|
||||
dim3 blockSize(1, 128);
|
||||
dim3 gridSize((B + blockSize.x - 1) / blockSize.x, (M + blockSize.y - 1) / blockSize.y);
|
||||
kernel_mm_seq_fp16i8<<<gridSize, blockSize>>>(
|
||||
B, N, M, cast(x), x_stride, w, w_stride,
|
||||
cast(mx), cast(rx), cast(my), cast(ry), cast(y), y_stride);
|
||||
}
|
||||
|
||||
#define MM8_ONE_JSPLIT 24
|
||||
#define MM8_ONE_TILE 1024
|
||||
|
||||
__global__ void kernel_mm_one_fp32i8(
|
||||
const int N, const int M,
|
||||
const float *__restrict__ const x,
|
||||
const uint8_t *__restrict__ const w, const int w_stride,
|
||||
const float *__restrict__ const mx,
|
||||
const float *__restrict__ const rx,
|
||||
const float *__restrict__ const my,
|
||||
const float *__restrict__ const ry,
|
||||
float *__restrict__ const y) {
|
||||
|
||||
const int k = blockIdx.y * blockDim.y + threadIdx.y;
|
||||
const int j0 = min(N, blockIdx.x * ((N + MM8_ONE_JSPLIT - 1) / MM8_ONE_JSPLIT));
|
||||
const int j1 = min(N, (blockIdx.x + 1) * ((N + MM8_ONE_JSPLIT - 1) / MM8_ONE_JSPLIT));
|
||||
|
||||
if (k < M) {
|
||||
float y_local = 0;
|
||||
for (int j = j0; j < j1; ++j) {
|
||||
y_local += x[j] * (
|
||||
(float(w[j * w_stride + k]) + 0.5f)
|
||||
* rx[k] * ry[j] + mx[k] + my[j]
|
||||
);
|
||||
}
|
||||
atomicAdd(&y[k], y_local);
|
||||
}
|
||||
}
|
||||
|
||||
template <typename F>
|
||||
void cuda_mm8_one(int N, int M,
|
||||
F *x,
|
||||
uint8_t *w, int w_stride,
|
||||
F *mx, F *rx,
|
||||
F *my, F *ry,
|
||||
float *y);
|
||||
|
||||
template <>
|
||||
void cuda_mm8_one<float>(int N, int M,
|
||||
float *x,
|
||||
uint8_t *w, int w_stride,
|
||||
float *mx, float *rx,
|
||||
float *my, float *ry,
|
||||
float *y) {
|
||||
dim3 blockSize(1, MM8_ONE_TILE);
|
||||
dim3 gridSize(MM8_ONE_JSPLIT, (M + blockSize.y - 1) / blockSize.y);
|
||||
kernel_mm_one_fp32i8<<<gridSize, blockSize>>>(
|
||||
N, M, x, w, w_stride,
|
||||
mx, rx, my, ry, y);
|
||||
}
|
||||
|
||||
__global__ void kernel_mm_one_fp16i8(
|
||||
const int N, const int M,
|
||||
const __half *__restrict__ const x,
|
||||
const uint8_t *__restrict__ const w, const int w_stride,
|
||||
const __half *__restrict__ const mx,
|
||||
const __half *__restrict__ const rx,
|
||||
const __half *__restrict__ const my,
|
||||
const __half *__restrict__ const ry,
|
||||
float *__restrict__ const y) {
|
||||
|
||||
const int k = blockIdx.y * blockDim.y + threadIdx.y;
|
||||
const int j0 = min(N, blockIdx.x * ((N + MM8_ONE_JSPLIT - 1) / MM8_ONE_JSPLIT));
|
||||
const int j1 = min(N, (blockIdx.x + 1) * ((N + MM8_ONE_JSPLIT - 1) / MM8_ONE_JSPLIT));
|
||||
|
||||
if (k < M) {
|
||||
float y_local = 0;
|
||||
for (int j = j0; j < j1; ++j) {
|
||||
y_local += __half2float(x[j]) * (
|
||||
(float(w[j * w_stride + k]) + 0.5f)
|
||||
* __half2float(rx[k]) * __half2float(ry[j])
|
||||
+ __half2float(mx[k]) + __half2float(my[j])
|
||||
);
|
||||
}
|
||||
atomicAdd(&y[k], y_local);
|
||||
}
|
||||
}
|
||||
|
||||
template <>
|
||||
void cuda_mm8_one<fp16>(int N, int M,
|
||||
fp16 *x,
|
||||
uint8_t *w, int w_stride,
|
||||
fp16 *mx, fp16 *rx,
|
||||
fp16 *my, fp16 *ry,
|
||||
float *y) {
|
||||
dim3 blockSize(1, MM8_ONE_TILE);
|
||||
dim3 gridSize(MM8_ONE_JSPLIT, (M + blockSize.y - 1) / blockSize.y);
|
||||
kernel_mm_one_fp16i8<<<gridSize, blockSize>>>(
|
||||
N, M, cast(x), w, w_stride,
|
||||
cast(mx), cast(rx), cast(my), cast(ry), y);
|
||||
}
|
||||
@ -1,88 +0,0 @@
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include "ATen/ATen.h"
|
||||
typedef at::BFloat16 bf16;
|
||||
typedef at::Half fp16;
|
||||
typedef float fp32;
|
||||
|
||||
template <typename F>
|
||||
__global__ void kernel_forward(const int B, const int T, const int C, const int H, float *__restrict__ _state,
|
||||
const F *__restrict__ const _r, const F *__restrict__ const _k, const F *__restrict__ const _v, const float *__restrict__ _w, const F *__restrict__ _u,
|
||||
F *__restrict__ const _y)
|
||||
{
|
||||
const int b = blockIdx.x / H;
|
||||
const int h = blockIdx.x % H;
|
||||
const int i = threadIdx.x;
|
||||
_w += h*_N_;
|
||||
_u += h*_N_;
|
||||
_state += h*_N_*_N_ + i*_N_; // wrong if B > 1 !!!
|
||||
|
||||
__shared__ float r[_N_], k[_N_], u[_N_], w[_N_];
|
||||
|
||||
float state[_N_];
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
state[j] = _state[j];
|
||||
|
||||
__syncthreads();
|
||||
u[i] = float(_u[i]);
|
||||
w[i] = _w[i];
|
||||
__syncthreads();
|
||||
|
||||
for (int t = b*T*C + h*_N_ + i; t < (b+1)*T*C + h*_N_ + i; t += C)
|
||||
{
|
||||
__syncthreads();
|
||||
r[i] = float(_r[t]);
|
||||
k[i] = float(_k[t]);
|
||||
__syncthreads();
|
||||
|
||||
const float v = float(_v[t]);
|
||||
float y = 0;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j+=4)
|
||||
{
|
||||
const float4& r_ = (float4&)(r[j]);
|
||||
const float4& k_ = (float4&)(k[j]);
|
||||
const float4& w_ = (float4&)(w[j]);
|
||||
const float4& u_ = (float4&)(u[j]);
|
||||
float4& s = (float4&)(state[j]);
|
||||
float4 x;
|
||||
|
||||
x.x = k_.x * v;
|
||||
x.y = k_.y * v;
|
||||
x.z = k_.z * v;
|
||||
x.w = k_.w * v;
|
||||
|
||||
y += r_.x * (u_.x * x.x + s.x);
|
||||
y += r_.y * (u_.y * x.y + s.y);
|
||||
y += r_.z * (u_.z * x.z + s.z);
|
||||
y += r_.w * (u_.w * x.w + s.w);
|
||||
|
||||
s.x = s.x * w_.x + x.x;
|
||||
s.y = s.y * w_.y + x.y;
|
||||
s.z = s.z * w_.z + x.z;
|
||||
s.w = s.w * w_.w + x.w;
|
||||
}
|
||||
_y[t] = F(y);
|
||||
}
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
_state[j] = state[j];
|
||||
}
|
||||
|
||||
void cuda_forward_bf16(int B, int T, int C, int H, float *state, bf16 *r, bf16 *k, bf16 *v, float *w, bf16 *u, bf16 *y)
|
||||
{
|
||||
assert(H*_N_ == C);
|
||||
kernel_forward<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, state, r, k, v, w, u, y);
|
||||
}
|
||||
void cuda_forward_fp16(int B, int T, int C, int H, float *state, fp16 *r, fp16 *k, fp16 *v, float *w, fp16 *u, fp16 *y)
|
||||
{
|
||||
assert(H*_N_ == C);
|
||||
kernel_forward<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, state, r, k, v, w, u, y);
|
||||
}
|
||||
void cuda_forward_fp32(int B, int T, int C, int H, float *state, fp32 *r, fp32 *k, fp32 *v, float *w, fp32 *u, fp32 *y)
|
||||
{
|
||||
assert(H*_N_ == C);
|
||||
kernel_forward<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, state, r, k, v, w, u, y);
|
||||
}
|
||||
@ -1,34 +0,0 @@
|
||||
#include <torch/extension.h>
|
||||
#include "ATen/ATen.h"
|
||||
#include <c10/cuda/CUDAGuard.h>
|
||||
typedef at::BFloat16 bf16;
|
||||
typedef at::Half fp16;
|
||||
typedef float fp32;
|
||||
|
||||
void cuda_forward_bf16(int B, int T, int C, int H, float *state, bf16 *r, bf16 *k, bf16 *v, float *w, bf16 *u, bf16 *y);
|
||||
void cuda_forward_fp16(int B, int T, int C, int H, float *state, fp16 *r, fp16 *k, fp16 *v, float *w, fp16 *u, fp16 *y);
|
||||
void cuda_forward_fp32(int B, int T, int C, int H, float *state, fp32 *r, fp32 *k, fp32 *v, float *w, fp32 *u, fp32 *y);
|
||||
|
||||
void forward_bf16(int64_t B, int64_t T, int64_t C, int64_t H, torch::Tensor &state, torch::Tensor &r, torch::Tensor &k, torch::Tensor &v, torch::Tensor &w, torch::Tensor &u, torch::Tensor &y) {
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(state));
|
||||
cuda_forward_bf16(B, T, C, H, state.data_ptr<float>(), r.data_ptr<bf16>(), k.data_ptr<bf16>(), v.data_ptr<bf16>(), w.data_ptr<float>(), u.data_ptr<bf16>(), y.data_ptr<bf16>());
|
||||
}
|
||||
void forward_fp16(int64_t B, int64_t T, int64_t C, int64_t H, torch::Tensor &state, torch::Tensor &r, torch::Tensor &k, torch::Tensor &v, torch::Tensor &w, torch::Tensor &u, torch::Tensor &y) {
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(state));
|
||||
cuda_forward_fp16(B, T, C, H, state.data_ptr<float>(), r.data_ptr<fp16>(), k.data_ptr<fp16>(), v.data_ptr<fp16>(), w.data_ptr<float>(), u.data_ptr<fp16>(), y.data_ptr<fp16>());
|
||||
}
|
||||
void forward_fp32(int64_t B, int64_t T, int64_t C, int64_t H, torch::Tensor &state, torch::Tensor &r, torch::Tensor &k, torch::Tensor &v, torch::Tensor &w, torch::Tensor &u, torch::Tensor &y) {
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(state));
|
||||
cuda_forward_fp32(B, T, C, H, state.data_ptr<float>(), r.data_ptr<fp32>(), k.data_ptr<fp32>(), v.data_ptr<fp32>(), w.data_ptr<float>(), u.data_ptr<fp32>(), y.data_ptr<fp32>());
|
||||
}
|
||||
|
||||
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
||||
m.def("forward_bf16", &forward_bf16, "rwkv5 forward_bf16");
|
||||
m.def("forward_fp16", &forward_fp16, "rwkv5 forward_fp16");
|
||||
m.def("forward_fp32", &forward_fp32, "rwkv5 forward_fp32");
|
||||
}
|
||||
TORCH_LIBRARY(rwkv5, m) {
|
||||
m.def("forward_bf16", forward_bf16);
|
||||
m.def("forward_fp16", forward_fp16);
|
||||
m.def("forward_fp32", forward_fp32);
|
||||
}
|
||||
@ -1,87 +0,0 @@
|
||||
#include <stdio.h>
|
||||
#include <assert.h>
|
||||
#include "ATen/ATen.h"
|
||||
typedef at::BFloat16 bf16;
|
||||
typedef at::Half fp16;
|
||||
typedef float fp32;
|
||||
|
||||
template <typename F>
|
||||
__global__ void kernel_forward(const int B, const int T, const int C, const int H, float *__restrict__ _state,
|
||||
const F *__restrict__ const _r, const F *__restrict__ const _k, const F *__restrict__ const _v, const float *__restrict__ _w, const F *__restrict__ _u,
|
||||
F *__restrict__ const _y)
|
||||
{
|
||||
const int b = blockIdx.x / H;
|
||||
const int h = blockIdx.x % H;
|
||||
const int i = threadIdx.x;
|
||||
_u += h*_N_;
|
||||
_state += h*_N_*_N_ + i*_N_; // wrong if B > 1 !!!
|
||||
|
||||
__shared__ float r[_N_], k[_N_], u[_N_], w[_N_];
|
||||
|
||||
float state[_N_];
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
state[j] = _state[j];
|
||||
|
||||
__syncthreads();
|
||||
u[i] = float(_u[i]);
|
||||
__syncthreads();
|
||||
|
||||
for (int t = b*T*C + h*_N_ + i; t < (b+1)*T*C + h*_N_ + i; t += C)
|
||||
{
|
||||
__syncthreads();
|
||||
w[i] = _w[t];
|
||||
r[i] = float(_r[t]);
|
||||
k[i] = float(_k[t]);
|
||||
__syncthreads();
|
||||
|
||||
const float v = float(_v[t]);
|
||||
float y = 0;
|
||||
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j+=4)
|
||||
{
|
||||
const float4& r_ = (float4&)(r[j]);
|
||||
const float4& k_ = (float4&)(k[j]);
|
||||
const float4& w_ = (float4&)(w[j]);
|
||||
const float4& u_ = (float4&)(u[j]);
|
||||
float4& s = (float4&)(state[j]);
|
||||
float4 x;
|
||||
|
||||
x.x = k_.x * v;
|
||||
x.y = k_.y * v;
|
||||
x.z = k_.z * v;
|
||||
x.w = k_.w * v;
|
||||
|
||||
y += r_.x * (u_.x * x.x + s.x);
|
||||
y += r_.y * (u_.y * x.y + s.y);
|
||||
y += r_.z * (u_.z * x.z + s.z);
|
||||
y += r_.w * (u_.w * x.w + s.w);
|
||||
|
||||
s.x = s.x * w_.x + x.x;
|
||||
s.y = s.y * w_.y + x.y;
|
||||
s.z = s.z * w_.z + x.z;
|
||||
s.w = s.w * w_.w + x.w;
|
||||
}
|
||||
_y[t] = F(y);
|
||||
}
|
||||
#pragma unroll
|
||||
for (int j = 0; j < _N_; j++)
|
||||
_state[j] = state[j];
|
||||
}
|
||||
|
||||
void cuda_forward_bf16(int B, int T, int C, int H, float *state, bf16 *r, bf16 *k, bf16 *v, float *w, bf16 *u, bf16 *y)
|
||||
{
|
||||
assert(H*_N_ == C);
|
||||
kernel_forward<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, state, r, k, v, w, u, y);
|
||||
}
|
||||
void cuda_forward_fp16(int B, int T, int C, int H, float *state, fp16 *r, fp16 *k, fp16 *v, float *w, fp16 *u, fp16 *y)
|
||||
{
|
||||
assert(H*_N_ == C);
|
||||
kernel_forward<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, state, r, k, v, w, u, y);
|
||||
}
|
||||
void cuda_forward_fp32(int B, int T, int C, int H, float *state, fp32 *r, fp32 *k, fp32 *v, float *w, fp32 *u, fp32 *y)
|
||||
{
|
||||
assert(H*_N_ == C);
|
||||
kernel_forward<<<dim3(B * H), dim3(_N_)>>>(B, T, C, H, state, r, k, v, w, u, y);
|
||||
}
|
||||
@ -1,34 +0,0 @@
|
||||
#include <torch/extension.h>
|
||||
#include "ATen/ATen.h"
|
||||
#include <c10/cuda/CUDAGuard.h>
|
||||
typedef at::BFloat16 bf16;
|
||||
typedef at::Half fp16;
|
||||
typedef float fp32;
|
||||
|
||||
void cuda_forward_bf16(int B, int T, int C, int H, float *state, bf16 *r, bf16 *k, bf16 *v, float *w, bf16 *u, bf16 *y);
|
||||
void cuda_forward_fp16(int B, int T, int C, int H, float *state, fp16 *r, fp16 *k, fp16 *v, float *w, fp16 *u, fp16 *y);
|
||||
void cuda_forward_fp32(int B, int T, int C, int H, float *state, fp32 *r, fp32 *k, fp32 *v, float *w, fp32 *u, fp32 *y);
|
||||
|
||||
void forward_bf16(int64_t B, int64_t T, int64_t C, int64_t H, torch::Tensor &state, torch::Tensor &r, torch::Tensor &k, torch::Tensor &v, torch::Tensor &w, torch::Tensor &u, torch::Tensor &y) {
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(state));
|
||||
cuda_forward_bf16(B, T, C, H, state.data_ptr<float>(), r.data_ptr<bf16>(), k.data_ptr<bf16>(), v.data_ptr<bf16>(), w.data_ptr<float>(), u.data_ptr<bf16>(), y.data_ptr<bf16>());
|
||||
}
|
||||
void forward_fp16(int64_t B, int64_t T, int64_t C, int64_t H, torch::Tensor &state, torch::Tensor &r, torch::Tensor &k, torch::Tensor &v, torch::Tensor &w, torch::Tensor &u, torch::Tensor &y) {
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(state));
|
||||
cuda_forward_fp16(B, T, C, H, state.data_ptr<float>(), r.data_ptr<fp16>(), k.data_ptr<fp16>(), v.data_ptr<fp16>(), w.data_ptr<float>(), u.data_ptr<fp16>(), y.data_ptr<fp16>());
|
||||
}
|
||||
void forward_fp32(int64_t B, int64_t T, int64_t C, int64_t H, torch::Tensor &state, torch::Tensor &r, torch::Tensor &k, torch::Tensor &v, torch::Tensor &w, torch::Tensor &u, torch::Tensor &y) {
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(state));
|
||||
cuda_forward_fp32(B, T, C, H, state.data_ptr<float>(), r.data_ptr<fp32>(), k.data_ptr<fp32>(), v.data_ptr<fp32>(), w.data_ptr<float>(), u.data_ptr<fp32>(), y.data_ptr<fp32>());
|
||||
}
|
||||
|
||||
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
||||
m.def("forward_bf16", &forward_bf16, "rwkv6 forward_bf16");
|
||||
m.def("forward_fp16", &forward_fp16, "rwkv6 forward_fp16");
|
||||
m.def("forward_fp32", &forward_fp32, "rwkv6 forward_fp32");
|
||||
}
|
||||
TORCH_LIBRARY(rwkv6, m) {
|
||||
m.def("forward_bf16", forward_bf16);
|
||||
m.def("forward_fp16", forward_fp16);
|
||||
m.def("forward_fp32", forward_fp32);
|
||||
}
|
||||
@ -1,141 +0,0 @@
|
||||
#include <torch/extension.h>
|
||||
#include "ATen/ATen.h"
|
||||
#include <iostream>
|
||||
#include <c10/cuda/CUDAGuard.h>
|
||||
|
||||
typedef at::Half fp16;
|
||||
|
||||
template <typename F>
|
||||
void cuda_wkv_forward(int B, int T, int C,
|
||||
float *w, float *u, F *k, F *v, F *y,
|
||||
float *aa, float *bb, float *pp);
|
||||
template <typename F>
|
||||
void cuda_mm8_seq(int B, int N, int M,
|
||||
F *x, int x_stride,
|
||||
uint8_t *w, int w_stride,
|
||||
F *mx, F *rx,
|
||||
F *my, F *ry,
|
||||
F *y, int y_stride);
|
||||
template <typename F>
|
||||
void cuda_mm8_one(int N, int M,
|
||||
F *x,
|
||||
uint8_t *w, int w_stride,
|
||||
F *mx, F *rx,
|
||||
F *my, F *ry,
|
||||
float *y);
|
||||
|
||||
void wkv_forward(int64_t B, int64_t T, int64_t C,
|
||||
torch::Tensor &w, torch::Tensor &u,
|
||||
torch::Tensor &k, torch::Tensor &v, torch::Tensor &y,
|
||||
torch::Tensor &aa, torch::Tensor &bb, torch::Tensor &pp) {
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(w));
|
||||
switch (k.scalar_type()) {
|
||||
case c10::ScalarType::Half:
|
||||
cuda_wkv_forward(B, T, C,
|
||||
w.data_ptr<float>(), u.data_ptr<float>(),
|
||||
k.data_ptr<fp16>(), v.data_ptr<fp16>(), y.data_ptr<fp16>(),
|
||||
aa.data_ptr<float>(), bb.data_ptr<float>(), pp.data_ptr<float>());
|
||||
break;
|
||||
case c10::ScalarType::Float:
|
||||
cuda_wkv_forward(B, T, C,
|
||||
w.data_ptr<float>(), u.data_ptr<float>(),
|
||||
k.data_ptr<float>(), v.data_ptr<float>(), y.data_ptr<float>(),
|
||||
aa.data_ptr<float>(), bb.data_ptr<float>(), pp.data_ptr<float>());
|
||||
break;
|
||||
default:
|
||||
assert(false && "Only FP16 and FP32 are currently supported");
|
||||
}
|
||||
}
|
||||
|
||||
void mm8_seq(int64_t B, int64_t N, int64_t M,
|
||||
torch::Tensor &x, torch::Tensor &w,
|
||||
torch::Tensor &mx, torch::Tensor &rx,
|
||||
torch::Tensor &my, torch::Tensor &ry,
|
||||
torch::Tensor &y) {
|
||||
assert(x.stride(1) == 1);
|
||||
assert(w.stride(1) == 1);
|
||||
assert(mx.stride(0) == 1 && rx.stride(0) == 1);
|
||||
assert(my.stride(0) == 1 && ry.stride(0) == 1);
|
||||
assert(y.stride(1) == 1);
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(w));
|
||||
switch (x.scalar_type()) {
|
||||
case c10::ScalarType::Half:
|
||||
cuda_mm8_seq(
|
||||
B, N, M,
|
||||
x.data_ptr<fp16>(), x.stride(0),
|
||||
w.data_ptr<uint8_t>(), w.stride(0),
|
||||
mx.data_ptr<fp16>(), rx.data_ptr<fp16>(),
|
||||
my.data_ptr<fp16>(), ry.data_ptr<fp16>(),
|
||||
y.data_ptr<fp16>(), y.stride(0));
|
||||
break;
|
||||
case c10::ScalarType::Float:
|
||||
cuda_mm8_seq(
|
||||
B, N, M,
|
||||
x.data_ptr<float>(), x.stride(0),
|
||||
w.data_ptr<uint8_t>(), w.stride(0),
|
||||
mx.data_ptr<float>(), rx.data_ptr<float>(),
|
||||
my.data_ptr<float>(), ry.data_ptr<float>(),
|
||||
y.data_ptr<float>(), y.stride(0));
|
||||
break;
|
||||
default:
|
||||
assert(false && "Only FP16 and FP32 are currently supported");
|
||||
}
|
||||
}
|
||||
void mm8_one(int64_t N, int64_t M,
|
||||
torch::Tensor &x, torch::Tensor &w,
|
||||
torch::Tensor &mx, torch::Tensor &rx,
|
||||
torch::Tensor &my, torch::Tensor &ry,
|
||||
torch::Tensor &y) {
|
||||
assert(x.stride(0) == 1);
|
||||
assert(w.stride(1) == 1);
|
||||
assert(mx.stride(0) == 1 && rx.stride(0) == 1);
|
||||
assert(my.stride(0) == 1 && ry.stride(0) == 1);
|
||||
assert(y.stride(0) == 1);
|
||||
const at::cuda::OptionalCUDAGuard device_guard(device_of(w));
|
||||
switch (x.scalar_type()) {
|
||||
case c10::ScalarType::Half:
|
||||
cuda_mm8_one(
|
||||
N, M,
|
||||
x.data_ptr<fp16>(),
|
||||
w.data_ptr<uint8_t>(), w.stride(0),
|
||||
mx.data_ptr<fp16>(), rx.data_ptr<fp16>(),
|
||||
my.data_ptr<fp16>(), ry.data_ptr<fp16>(),
|
||||
y.data_ptr<float>());
|
||||
break;
|
||||
case c10::ScalarType::Float:
|
||||
cuda_mm8_one(
|
||||
N, M,
|
||||
x.data_ptr<float>(),
|
||||
w.data_ptr<uint8_t>(), w.stride(0),
|
||||
mx.data_ptr<float>(), rx.data_ptr<float>(),
|
||||
my.data_ptr<float>(), ry.data_ptr<float>(),
|
||||
y.data_ptr<float>());
|
||||
break;
|
||||
default:
|
||||
assert(false && "Only FP16 and FP32 are currently supported");
|
||||
}
|
||||
}
|
||||
|
||||
using torch::Tensor;
|
||||
|
||||
#ifndef DISABLE_CUBLAS_GEMM
|
||||
void gemm_fp16_cublas(Tensor a, Tensor b, Tensor c);
|
||||
#endif
|
||||
|
||||
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
|
||||
m.def("wkv_forward", &wkv_forward, "wkv forward");
|
||||
m.def("mm8_seq", &mm8_seq, "mm8 seq");
|
||||
m.def("mm8_one", &mm8_one, "mm8 one");
|
||||
#ifndef DISABLE_CUBLAS_GEMM
|
||||
m.def("gemm_fp16_cublas", &gemm_fp16_cublas, "gemv fp16 cublas");
|
||||
#endif
|
||||
}
|
||||
|
||||
TORCH_LIBRARY(rwkv, m) {
|
||||
m.def("wkv_forward", wkv_forward);
|
||||
m.def("mm8_seq", mm8_seq);
|
||||
m.def("mm8_one", mm8_one);
|
||||
#ifndef DISABLE_CUBLAS_GEMM
|
||||
m.def("gemm_fp16_cublas", gemm_fp16_cublas);
|
||||
#endif
|
||||
}
|
||||
File diff suppressed because it is too large
Load Diff
Binary file not shown.
Binary file not shown.
@ -1,106 +0,0 @@
|
||||
########################################################################################################
|
||||
# The RWKV Language Model - https://github.com/BlinkDL/RWKV-LM
|
||||
########################################################################################################
|
||||
|
||||
|
||||
class TRIE:
|
||||
__slots__ = tuple("ch,to,values,front".split(","))
|
||||
to: list
|
||||
values: set
|
||||
|
||||
def __init__(self, front=None, ch=None):
|
||||
self.ch = ch
|
||||
self.to = [None for ch in range(256)]
|
||||
self.values = set()
|
||||
self.front = front
|
||||
|
||||
def __repr__(self):
|
||||
fr = self
|
||||
ret = []
|
||||
while fr != None:
|
||||
if fr.ch != None:
|
||||
ret.append(fr.ch)
|
||||
fr = fr.front
|
||||
return "<TRIE %s %s>" % (ret[::-1], self.values)
|
||||
|
||||
def add(self, key: bytes, idx: int = 0, val=None):
|
||||
if idx == len(key):
|
||||
if val is None:
|
||||
val = key
|
||||
self.values.add(val)
|
||||
return self
|
||||
ch = key[idx]
|
||||
if self.to[ch] is None:
|
||||
self.to[ch] = TRIE(front=self, ch=ch)
|
||||
return self.to[ch].add(key, idx=idx + 1, val=val)
|
||||
|
||||
def find_longest(self, key: bytes, idx: int = 0):
|
||||
u: TRIE = self
|
||||
ch: int = key[idx]
|
||||
|
||||
while u.to[ch] is not None:
|
||||
u = u.to[ch]
|
||||
idx += 1
|
||||
if u.values:
|
||||
ret = idx, u, u.values
|
||||
if idx == len(key):
|
||||
break
|
||||
ch = key[idx]
|
||||
return ret
|
||||
|
||||
|
||||
class TRIE_TOKENIZER:
|
||||
def __init__(self, file_name):
|
||||
self.idx2token = {}
|
||||
sorted = [] # must be already sorted
|
||||
with open(file_name, "r", encoding="utf-8") as f:
|
||||
lines = f.readlines()
|
||||
for l in lines:
|
||||
idx = int(l[: l.index(" ")])
|
||||
x = eval(l[l.index(" ") : l.rindex(" ")])
|
||||
x = x.encode("utf-8") if isinstance(x, str) else x
|
||||
assert isinstance(x, bytes)
|
||||
assert len(x) == int(l[l.rindex(" ") :])
|
||||
sorted += [x]
|
||||
self.idx2token[idx] = x
|
||||
|
||||
self.token2idx = {}
|
||||
for k, v in self.idx2token.items():
|
||||
self.token2idx[v] = int(k)
|
||||
|
||||
self.root = TRIE()
|
||||
for t, i in self.token2idx.items():
|
||||
_ = self.root.add(t, val=(t, i))
|
||||
|
||||
def encodeBytes(self, src: bytes):
|
||||
idx: int = 0
|
||||
tokens = []
|
||||
while idx < len(src):
|
||||
_idx: int = idx
|
||||
idx, _, values = self.root.find_longest(src, idx)
|
||||
assert idx != _idx
|
||||
_, token = next(iter(values))
|
||||
tokens.append(token)
|
||||
return tokens
|
||||
|
||||
def decodeBytes(self, tokens):
|
||||
return b"".join(map(lambda i: self.idx2token[i], tokens))
|
||||
|
||||
def encode(self, src):
|
||||
return self.encodeBytes(src.encode("utf-8"))
|
||||
|
||||
def decode(self, tokens):
|
||||
try:
|
||||
return self.decodeBytes(tokens).decode("utf-8")
|
||||
except:
|
||||
return "\ufffd" # bad utf-8
|
||||
|
||||
def printTokens(self, tokens):
|
||||
for i in tokens:
|
||||
s = self.idx2token[i]
|
||||
try:
|
||||
s = s.decode("utf-8")
|
||||
except:
|
||||
pass
|
||||
print(f"{repr(s)}{i}", end=" ")
|
||||
print()
|
||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@ -1,194 +0,0 @@
|
||||
########################################################################################################
|
||||
# The RWKV Language Model - https://github.com/BlinkDL/RWKV-LM
|
||||
########################################################################################################
|
||||
|
||||
import os, sys
|
||||
import numpy as np
|
||||
import torch
|
||||
from torch.nn import functional as F
|
||||
|
||||
|
||||
class PIPELINE_ARGS:
|
||||
def __init__(
|
||||
self,
|
||||
temperature=1.0,
|
||||
top_p=0.85,
|
||||
top_k=0,
|
||||
alpha_frequency=0.2,
|
||||
alpha_presence=0.2,
|
||||
alpha_decay=0.996,
|
||||
token_ban=[],
|
||||
token_stop=[],
|
||||
chunk_len=256,
|
||||
):
|
||||
self.temperature = temperature
|
||||
self.top_p = top_p
|
||||
self.top_k = top_k
|
||||
self.alpha_frequency = alpha_frequency # Frequency Penalty (as in GPT-3)
|
||||
self.alpha_presence = alpha_presence # Presence Penalty (as in GPT-3)
|
||||
self.alpha_decay = alpha_decay # gradually decay the penalty
|
||||
self.token_ban = token_ban # ban the generation of some tokens
|
||||
self.token_stop = token_stop # stop generation whenever you see any token here
|
||||
self.chunk_len = (
|
||||
chunk_len # split input into chunks to save VRAM (shorter -> slower)
|
||||
)
|
||||
|
||||
|
||||
class ABC_TOKENIZER:
|
||||
def __init__(self):
|
||||
self.pad_token_id = 0
|
||||
self.bos_token_id = 2
|
||||
self.eos_token_id = 3
|
||||
|
||||
def encode(self, text):
|
||||
ids = [ord(c) for c in text]
|
||||
return ids
|
||||
|
||||
def decode(self, ids):
|
||||
txt = "".join(
|
||||
chr(idx) if idx > self.eos_token_id else ""
|
||||
for idx in ids
|
||||
if idx != self.eos_token_id
|
||||
)
|
||||
return txt
|
||||
|
||||
|
||||
class PIPELINE:
|
||||
def __init__(self, model, WORD_NAME: str):
|
||||
self.model = model
|
||||
if WORD_NAME == "cl100k_base":
|
||||
import tiktoken
|
||||
|
||||
self.tokenizer = tiktoken.get_encoding(WORD_NAME)
|
||||
elif WORD_NAME == "rwkv_vocab_v20230424":
|
||||
sys.path.insert(0, os.path.dirname(os.path.abspath(__file__)))
|
||||
from rwkv_tokenizer import TRIE_TOKENIZER
|
||||
|
||||
self.tokenizer = TRIE_TOKENIZER(
|
||||
os.path.dirname(os.path.abspath(__file__)) + "/rwkv_vocab_v20230424.txt"
|
||||
)
|
||||
elif WORD_NAME == "abc_tokenizer":
|
||||
self.tokenizer = ABC_TOKENIZER()
|
||||
else:
|
||||
if WORD_NAME.endswith(".txt"):
|
||||
sys.path.insert(0, os.path.dirname(os.path.abspath(__file__)))
|
||||
from rwkv_tokenizer import TRIE_TOKENIZER
|
||||
|
||||
self.tokenizer = TRIE_TOKENIZER(WORD_NAME)
|
||||
else:
|
||||
from tokenizers import Tokenizer
|
||||
|
||||
self.tokenizer = Tokenizer.from_file(WORD_NAME)
|
||||
|
||||
def refine_context(self, context):
|
||||
context = context.strip().split("\n")
|
||||
for c in range(len(context)):
|
||||
context[c] = context[c].strip().strip("\u3000").strip("\r")
|
||||
context = list(filter(lambda c: c != "", context))
|
||||
context = "\n" + ("\n".join(context)).strip()
|
||||
if context == "":
|
||||
context = "\n"
|
||||
return context
|
||||
|
||||
def encode(self, x):
|
||||
if "Tokenizer" in str(type(self.tokenizer)):
|
||||
return self.tokenizer.encode(x).ids
|
||||
else:
|
||||
return self.tokenizer.encode(x)
|
||||
|
||||
def decode(self, x):
|
||||
return self.tokenizer.decode(x)
|
||||
|
||||
def np_softmax(self, x: np.ndarray, axis: int):
|
||||
x -= x.max(axis=axis, keepdims=True)
|
||||
e: np.ndarray = np.exp(x)
|
||||
return e / e.sum(axis=axis, keepdims=True)
|
||||
|
||||
def sample_logits(self, logits, temperature=1.0, top_p=0.85, top_k=0):
|
||||
if type(logits) == list:
|
||||
logits = np.array(logits)
|
||||
np_logits = type(logits) == np.ndarray
|
||||
if np_logits:
|
||||
probs = self.np_softmax(logits, axis=-1)
|
||||
else:
|
||||
probs = F.softmax(logits.float(), dim=-1)
|
||||
top_k = int(top_k)
|
||||
# 'privateuseone' is the type of custom devices like `torch_directml.device()`
|
||||
if np_logits or probs.device.type in ["cpu", "privateuseone"]:
|
||||
if not np_logits:
|
||||
probs = probs.cpu().numpy()
|
||||
sorted_ids = np.argsort(probs)
|
||||
sorted_probs = probs[sorted_ids][::-1]
|
||||
cumulative_probs = np.cumsum(sorted_probs)
|
||||
cutoff = float(sorted_probs[np.argmax(cumulative_probs >= top_p)])
|
||||
probs[probs < cutoff] = 0
|
||||
if top_k < len(probs) and top_k > 0:
|
||||
probs[sorted_ids[:-top_k]] = 0
|
||||
if temperature != 1.0:
|
||||
probs = probs ** (1.0 / temperature)
|
||||
probs = probs / np.sum(probs)
|
||||
out = np.random.choice(a=len(probs), p=probs)
|
||||
return int(out)
|
||||
else:
|
||||
sorted_ids = torch.argsort(probs)
|
||||
sorted_probs = probs[sorted_ids]
|
||||
sorted_probs = torch.flip(sorted_probs, dims=(0,))
|
||||
cumulative_probs = torch.cumsum(sorted_probs, dim=-1).cpu().numpy()
|
||||
cutoff = float(sorted_probs[np.argmax(cumulative_probs >= top_p)])
|
||||
probs[probs < cutoff] = 0
|
||||
if top_k < len(probs) and top_k > 0:
|
||||
probs[sorted_ids[:-top_k]] = 0
|
||||
if temperature != 1.0:
|
||||
probs = probs ** (1.0 / temperature)
|
||||
out = torch.multinomial(probs, num_samples=1)[0]
|
||||
return int(out)
|
||||
|
||||
def generate(
|
||||
self, ctx, token_count=100, args=PIPELINE_ARGS(), callback=None, state=None
|
||||
):
|
||||
all_tokens = []
|
||||
out_last = 0
|
||||
out_str = ""
|
||||
occurrence = {}
|
||||
for i in range(token_count):
|
||||
# forward & adjust prob.
|
||||
tokens = self.encode(ctx) if i == 0 else [token]
|
||||
while len(tokens) > 0:
|
||||
out, state = self.model.forward(tokens[: args.chunk_len], state)
|
||||
tokens = tokens[args.chunk_len :]
|
||||
|
||||
for n in args.token_ban:
|
||||
out[n] = -float("inf")
|
||||
for n in occurrence:
|
||||
out[n] -= args.alpha_presence + occurrence[n] * args.alpha_frequency
|
||||
|
||||
# sampler
|
||||
token = self.sample_logits(
|
||||
out, temperature=args.temperature, top_p=args.top_p, top_k=args.top_k
|
||||
)
|
||||
if token in args.token_stop:
|
||||
break
|
||||
all_tokens += [token]
|
||||
for xxx in occurrence:
|
||||
occurrence[xxx] *= args.alpha_decay
|
||||
|
||||
ttt = self.decode([token])
|
||||
www = 1
|
||||
if ttt in " \t0123456789":
|
||||
www = 0
|
||||
# elif ttt in '\r\n,.;?!"\':+-*/=#@$%^&_`~|<>\\()[]{},。;“”:?!()【】':
|
||||
# www = 0.5
|
||||
if token not in occurrence:
|
||||
occurrence[token] = www
|
||||
else:
|
||||
occurrence[token] += www
|
||||
# print(occurrence) # debug
|
||||
|
||||
# output
|
||||
tmp = self.decode(all_tokens[out_last:])
|
||||
if "\ufffd" not in tmp: # is valid utf-8 string?
|
||||
if callback:
|
||||
callback(tmp)
|
||||
out_str += tmp
|
||||
out_last = i + 1
|
||||
return out_str
|
||||
@ -1,50 +0,0 @@
|
||||
from typing import Any, List, Union
|
||||
|
||||
try:
|
||||
import web_rwkv_py as wrp
|
||||
except ModuleNotFoundError:
|
||||
try:
|
||||
from . import web_rwkv_py as wrp
|
||||
except ImportError:
|
||||
raise ModuleNotFoundError(
|
||||
"web_rwkv_py not found, install it from https://github.com/cryscan/web-rwkv-py"
|
||||
)
|
||||
|
||||
|
||||
class RWKV:
|
||||
def __init__(self, model_path: str, strategy: str = None):
|
||||
layer = (
|
||||
int(s.lstrip("layer"))
|
||||
for s in strategy.split()
|
||||
for s in s.split(",")
|
||||
if s.startswith("layer")
|
||||
)
|
||||
|
||||
chunk_size = (
|
||||
int(s.lstrip("chunk"))
|
||||
for s in strategy.split()
|
||||
for s in s.split(",")
|
||||
if s.startswith("chunk")
|
||||
)
|
||||
self.token_chunk_size = next(chunk_size, 32)
|
||||
|
||||
args = {
|
||||
"path": model_path,
|
||||
"quant": next(layer, 31) if "i8" in strategy else 0,
|
||||
"quant_nf4": next(layer, 26) if "i4" in strategy else 0,
|
||||
}
|
||||
self.model = wrp.Model(**args)
|
||||
self.info = self.model.info()
|
||||
self.w = {} # fake weight
|
||||
self.w["emb.weight"] = [0] * self.info.num_vocab
|
||||
self.version = str(self.info.version).lower()
|
||||
self.version = float(self.version.lower().replace("v", ""))
|
||||
|
||||
def forward(self, tokens: List[int], state: Union[Any, None] = None):
|
||||
if state is None:
|
||||
self.model.clear_state()
|
||||
elif type(state).__name__ == "State_Cpu":
|
||||
self.model.load_state(state)
|
||||
logits = self.model.run(tokens, self.token_chunk_size)
|
||||
ret_state = "State_Gpu"
|
||||
return logits, ret_state
|
||||
Binary file not shown.
Binary file not shown.
@ -1,49 +0,0 @@
|
||||
import json
|
||||
import logging
|
||||
from typing import Any
|
||||
from fastapi import Request
|
||||
from pydantic import BaseModel
|
||||
from enum import Enum
|
||||
|
||||
|
||||
logger = logging.getLogger()
|
||||
logger.setLevel(logging.INFO)
|
||||
formatter = logging.Formatter("%(asctime)s - %(levelname)s\n%(message)s")
|
||||
fh = logging.handlers.RotatingFileHandler(
|
||||
"api.log", mode="a", maxBytes=3 * 1024 * 1024, backupCount=3, encoding="utf-8"
|
||||
)
|
||||
fh.setFormatter(formatter)
|
||||
logger.addHandler(fh)
|
||||
|
||||
|
||||
class ClsEncoder(json.JSONEncoder):
|
||||
def default(self, obj):
|
||||
if isinstance(obj, BaseModel):
|
||||
return obj.dict()
|
||||
if isinstance(obj, Enum):
|
||||
return obj.value
|
||||
return super().default(obj)
|
||||
|
||||
|
||||
def quick_log(request: Request, body: Any, response: str):
|
||||
try:
|
||||
logger.info(
|
||||
f"Client: {request.client if request else ''}\nUrl: {request.url if request else ''}\n"
|
||||
+ (
|
||||
f"Body: {json.dumps(body.__dict__, ensure_ascii=False, cls=ClsEncoder)}\n"
|
||||
if body
|
||||
else ""
|
||||
)
|
||||
+ (f"Data:\n{response}\n" if response else "")
|
||||
)
|
||||
except Exception as e:
|
||||
logger.info(f"Error quick_log request:\n{e}")
|
||||
|
||||
|
||||
async def log_middleware(request: Request):
|
||||
try:
|
||||
logger.info(
|
||||
f"Client: {request.client}\nUrl: {request.url}\nBody: {await request.body()}\n"
|
||||
)
|
||||
except Exception as e:
|
||||
logger.info(f"Error log_middleware request:\n{e}")
|
||||
@ -1,740 +0,0 @@
|
||||
# https://github.com/briansemrau/MIDI-LLM-tokenizer
|
||||
|
||||
# MIT License
|
||||
|
||||
# Copyright (c) 2023 Brian Semrau
|
||||
|
||||
# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
||||
|
||||
# The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
||||
|
||||
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
||||
|
||||
import json
|
||||
import random
|
||||
from dataclasses import dataclass
|
||||
from functools import lru_cache
|
||||
from math import ceil, floor, log
|
||||
from typing import Dict, Iterator, List, Optional, Tuple
|
||||
|
||||
import mido
|
||||
|
||||
|
||||
@dataclass
|
||||
class VocabConfig:
|
||||
# Number of note events. Should be 128.
|
||||
note_events: int
|
||||
# Number of wait events. Configurable, must evenly divide max_wait_time.
|
||||
wait_events: int
|
||||
# Max wait time in milliseconds to be represented by a single token.
|
||||
max_wait_time: int
|
||||
# Number of velocity events. Should be 128 (or 100? need to check midi standard)
|
||||
velocity_events: int
|
||||
# Number of bins to quantize velocity into. Should evenly divide velocity_events.
|
||||
velocity_bins: int
|
||||
# Exponential scaling factor for velocity bin sizes. 1.0 = linear scaling.
|
||||
velocity_exp: float
|
||||
# Whether to sort tokens by instrument, note. This should improve data reducibility.
|
||||
do_token_sorting: bool
|
||||
# Whether tokens should be represented as combined instrument/note/velocity tokens, or separate tokens for each.
|
||||
unrolled_tokens: bool
|
||||
# If non-zero, notes held for this many seconds will be automatically released during str->midi decoding.
|
||||
decode_end_held_note_delay: float
|
||||
# If true, repeated notes will be automatically released before playing again during str->midi decoding.
|
||||
decode_fix_repeated_notes: bool
|
||||
# List of instrument names to use for binning. Must have at most 16 values.
|
||||
bin_instrument_names: List[str]
|
||||
# Indicates which bin name represents percussion instruments on MIDI channel 10.
|
||||
ch10_instrument_bin_name: str
|
||||
# Mapping from instrument name to bin name.
|
||||
program_name_to_bin_name: Dict[str, str]
|
||||
# Mapping from bin name to program name.
|
||||
bin_name_to_program_name: Dict[str, str]
|
||||
# Mapping from program number to instrument name.
|
||||
instrument_names: Dict[str, str]
|
||||
# Manual override for velocity bins. Each element is the max velocity value for that bin by index.
|
||||
velocity_bins_override: Optional[List[int]] = None
|
||||
|
||||
def __post_init__(self):
|
||||
self.validate()
|
||||
|
||||
self._instrument_names_str_to_int = {
|
||||
name: int(i) for i, name in self.instrument_names.items()
|
||||
}
|
||||
self._instrument_names_int_to_str = {
|
||||
int(i): name for i, name in self.instrument_names.items()
|
||||
}
|
||||
|
||||
self._bin_str_to_int = {
|
||||
name: int(i) for i, name in enumerate(self.bin_instrument_names)
|
||||
}
|
||||
|
||||
self._bin_int_to_instrument_int = [
|
||||
self._instrument_names_str_to_int[self.bin_name_to_program_name[name]]
|
||||
if name != self.ch10_instrument_bin_name
|
||||
else 0
|
||||
for name in self.bin_instrument_names
|
||||
]
|
||||
self._instrument_int_to_bin_int = [
|
||||
self._bin_str_to_int[self.program_name_to_bin_name[instr]]
|
||||
if self.program_name_to_bin_name[instr] != ""
|
||||
else -1
|
||||
for instr in self.program_name_to_bin_name.keys()
|
||||
]
|
||||
|
||||
self._ch10_bin_int = (
|
||||
self._bin_str_to_int[self.ch10_instrument_bin_name]
|
||||
if self.ch10_instrument_bin_name
|
||||
else -1
|
||||
)
|
||||
|
||||
self.short_instr_bin_names = []
|
||||
for instr in self.bin_instrument_names:
|
||||
i = min(1, len(instr))
|
||||
while instr[:i] in self.short_instr_bin_names:
|
||||
i += 1
|
||||
self.short_instr_bin_names.append(instr[:i])
|
||||
self._short_instrument_names_str_to_int = {
|
||||
name: int(i) for i, name in enumerate(self.short_instr_bin_names)
|
||||
}
|
||||
|
||||
range_excluding_ch10 = [
|
||||
(i if i < 9 else i + 1) for i in range(len(self.bin_instrument_names))
|
||||
]
|
||||
bins_excluding_ch10 = [
|
||||
n for n in self.bin_instrument_names if n != self.ch10_instrument_bin_name
|
||||
]
|
||||
self.bin_channel_map = {
|
||||
bin: channel
|
||||
for channel, bin in zip(range_excluding_ch10, bins_excluding_ch10)
|
||||
}
|
||||
if self.ch10_instrument_bin_name:
|
||||
self.bin_channel_map[self.ch10_instrument_bin_name] = 9
|
||||
|
||||
def validate(self):
|
||||
if self.max_wait_time % self.wait_events != 0:
|
||||
raise ValueError("max_wait_time must be exactly divisible by wait_events")
|
||||
if self.velocity_bins < 2:
|
||||
raise ValueError("velocity_bins must be at least 2")
|
||||
if len(self.bin_instrument_names) > 16:
|
||||
raise ValueError("bin_instruments must have at most 16 values")
|
||||
if self.velocity_bins_override:
|
||||
print("VocabConfig is using velocity_bins_override. Ignoring velocity_exp.")
|
||||
if len(self.velocity_bins_override) != self.velocity_bins:
|
||||
raise ValueError(
|
||||
"velocity_bins_override must have same length as velocity_bins"
|
||||
)
|
||||
if (
|
||||
self.ch10_instrument_bin_name
|
||||
and self.ch10_instrument_bin_name not in self.bin_instrument_names
|
||||
):
|
||||
raise ValueError("ch10_instrument_bin_name must be in bin_instruments")
|
||||
if self.velocity_exp <= 0:
|
||||
raise ValueError("velocity_exp must be greater than 0")
|
||||
|
||||
@classmethod
|
||||
def from_json(cls, path: str):
|
||||
with open(path, "r") as f:
|
||||
config = json.load(f)
|
||||
return cls(**config)
|
||||
|
||||
|
||||
class VocabUtils:
|
||||
def __init__(self, cfg: VocabConfig) -> None:
|
||||
self.cfg = cfg
|
||||
|
||||
@lru_cache(maxsize=128)
|
||||
def format_wait_token(self, wait: int) -> str:
|
||||
return f"t{wait}"
|
||||
|
||||
@lru_cache(maxsize=128)
|
||||
def format_note_token(
|
||||
self, instrument_bin: int, note: int, velocity_bin: int
|
||||
) -> str:
|
||||
return f"{self.cfg.short_instr_bin_names[instrument_bin]}:{note:x}:{velocity_bin:x}"
|
||||
|
||||
def format_unrolled_note(self, note: int) -> str:
|
||||
return f"n{note:x}"
|
||||
|
||||
def format_unrolled_velocity(self, velocity_bin: int) -> str:
|
||||
return f"v{velocity_bin:x}"
|
||||
|
||||
def format_unrolled_instrument_bin(self, instrument_bin: int) -> str:
|
||||
return f"i{self.cfg.short_instr_bin_names[instrument_bin]}"
|
||||
|
||||
def velocity_to_bin(self, velocity: float) -> int:
|
||||
velocity = max(0, min(velocity, self.cfg.velocity_events - 1))
|
||||
if self.cfg.velocity_bins_override:
|
||||
for i, v in enumerate(self.cfg.velocity_bins_override):
|
||||
if velocity <= v:
|
||||
return i
|
||||
return 0
|
||||
binsize = self.cfg.velocity_events / (self.cfg.velocity_bins - 1)
|
||||
if self.cfg.velocity_exp == 1.0:
|
||||
return ceil(velocity / binsize)
|
||||
else:
|
||||
return ceil(
|
||||
(
|
||||
self.cfg.velocity_events
|
||||
* (
|
||||
(
|
||||
self.cfg.velocity_exp
|
||||
** (velocity / self.cfg.velocity_events)
|
||||
- 1.0
|
||||
)
|
||||
/ (self.cfg.velocity_exp - 1.0)
|
||||
)
|
||||
)
|
||||
/ binsize
|
||||
)
|
||||
|
||||
def bin_to_velocity(self, bin: int) -> int:
|
||||
if self.cfg.velocity_bins_override:
|
||||
return self.cfg.velocity_bins_override[bin]
|
||||
binsize = self.cfg.velocity_events / (self.cfg.velocity_bins - 1)
|
||||
if self.cfg.velocity_exp == 1.0:
|
||||
return max(0, ceil(bin * binsize - 1))
|
||||
else:
|
||||
return max(
|
||||
0,
|
||||
ceil(
|
||||
self.cfg.velocity_events
|
||||
* log(
|
||||
((self.cfg.velocity_exp - 1) * binsize * bin)
|
||||
/ self.cfg.velocity_events
|
||||
+ 1,
|
||||
self.cfg.velocity_exp,
|
||||
)
|
||||
- 1
|
||||
),
|
||||
)
|
||||
|
||||
def delta_to_wait_ids(self, delta_ms: float) -> Iterator[int]:
|
||||
def roundi(f: float):
|
||||
return ceil(f - 0.5)
|
||||
|
||||
max_wait_ms = self.cfg.max_wait_time
|
||||
div = max_wait_ms / self.cfg.wait_events
|
||||
|
||||
# if delta_ms // max_wait_ms > 512: # arbitrary limit to avoid excessive time_shifts
|
||||
# raise ValueError("delta_time is too large")
|
||||
if delta_ms > max_wait_ms * 10:
|
||||
delta_ms = max_wait_ms * 10 # truncate time
|
||||
|
||||
for _ in range(floor(delta_ms / max_wait_ms)):
|
||||
yield roundi(max_wait_ms / div)
|
||||
leftover_time_shift = roundi((delta_ms % max_wait_ms) / div)
|
||||
if leftover_time_shift > 0:
|
||||
yield leftover_time_shift
|
||||
|
||||
def prog_data_to_token_data(
|
||||
self, program: int, channel: int, note: int, velocity: float
|
||||
) -> Optional[Tuple[int, int, int]]:
|
||||
if channel == 9:
|
||||
if self.cfg._ch10_bin_int == -1:
|
||||
return None
|
||||
return self.cfg._ch10_bin_int, note, self.velocity_to_bin(velocity)
|
||||
|
||||
instrument_bin = self.cfg._instrument_int_to_bin_int[program]
|
||||
if instrument_bin != -1:
|
||||
return instrument_bin, note, self.velocity_to_bin(velocity)
|
||||
return None
|
||||
|
||||
def prog_data_list_to_token_data_list(
|
||||
self, data: List[Tuple[int, int, int, float]]
|
||||
) -> Iterator[Tuple[int, int, int]]:
|
||||
for d in data:
|
||||
token_data = self.prog_data_to_token_data(*d)
|
||||
if token_data is not None:
|
||||
yield token_data
|
||||
|
||||
def sort_token_data(
|
||||
self, data: List[Tuple[int, int, int]]
|
||||
) -> List[Tuple[int, int, int]]:
|
||||
# ensure order is preserved for tokens with the same instrument, note
|
||||
data = [(i, n, v, x) for x, (i, n, v) in enumerate(data)]
|
||||
data.sort(key=lambda x: (x[0] != self.cfg._ch10_bin_int, x[0], x[1], x[3]))
|
||||
return [(i, n, v) for i, n, v, _ in data]
|
||||
|
||||
def data_to_wait_tokens(self, delta_ms: float) -> List[str]:
|
||||
if delta_ms == 0.0:
|
||||
return []
|
||||
return [self.format_wait_token(i) for i in self.delta_to_wait_ids(delta_ms)]
|
||||
|
||||
def wait_token_to_delta(self, token: str) -> float:
|
||||
return self.cfg.max_wait_time / self.cfg.wait_events * int(token[1:])
|
||||
|
||||
def note_token_to_data(self, token: str) -> Tuple[int, int, int]:
|
||||
instr_str, note_str, velocity_str = token.strip().split(":")
|
||||
instr_bin = self.cfg._short_instrument_names_str_to_int[instr_str]
|
||||
note = int(note_str, base=16)
|
||||
velocity = self.bin_to_velocity(int(velocity_str, base=16))
|
||||
return instr_bin, note, velocity
|
||||
|
||||
|
||||
@dataclass
|
||||
class AugmentValues:
|
||||
instrument_bin_remap: Dict[int, int]
|
||||
velocity_mod_factor: float
|
||||
transpose_semitones: int
|
||||
time_stretch_factor: float
|
||||
|
||||
@classmethod
|
||||
def default(cls) -> "AugmentValues":
|
||||
return cls(
|
||||
instrument_bin_remap={},
|
||||
velocity_mod_factor=1.0,
|
||||
transpose_semitones=0,
|
||||
time_stretch_factor=1.0,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class AugmentConfig:
|
||||
# The number of times to augment each MIDI file. The dataset size will be multiplied by this number.
|
||||
augment_data_factor: int
|
||||
# A list of instrument names to randomly swap with each other.
|
||||
instrument_mixups: List[List[str]]
|
||||
# A list of percentages to change the note velocity by. 0.0 = no change. 0 is included by default.
|
||||
velocity_mod_pct: List[float]
|
||||
# A list of semitones to transpose by. 0 is included by default.
|
||||
transpose_semitones: List[int]
|
||||
# A list of percentages to stretch the tempo by. 0.0 = no stretch. 0 is included by default.
|
||||
time_stretch_pct: List[float]
|
||||
# Random seed to use for reproducibility.
|
||||
seed: int
|
||||
|
||||
cfg: VocabConfig
|
||||
|
||||
def __post_init__(self):
|
||||
self.validate()
|
||||
if len(self.velocity_mod_pct) == 0:
|
||||
self.velocity_mod_pct = [0.0]
|
||||
if len(self.transpose_semitones) == 0:
|
||||
self.transpose_semitones = [0]
|
||||
if len(self.time_stretch_pct) == 0:
|
||||
self.time_stretch_pct = [0.0]
|
||||
|
||||
self._instrument_mixups_int = [
|
||||
[self.cfg._bin_str_to_int[i] for i in l if i in self.cfg._bin_str_to_int]
|
||||
for l in self.instrument_mixups
|
||||
]
|
||||
self._instrument_mixups_int = [
|
||||
l for l in self._instrument_mixups_int if len(l) > 0
|
||||
] # remove empty lists
|
||||
self._instrument_pool_assignments = {}
|
||||
self._mixup_pools = []
|
||||
for pool_i, mixup_list in enumerate(self._instrument_mixups_int):
|
||||
pool = set()
|
||||
for i in mixup_list:
|
||||
pool.add(i)
|
||||
self._instrument_pool_assignments[i] = pool_i
|
||||
self._mixup_pools.append(pool)
|
||||
|
||||
def validate(self):
|
||||
if self.augment_data_factor < 1:
|
||||
raise ValueError("augment_data_factor must be at least 1")
|
||||
used_instruments = set()
|
||||
for mixup_list in self.instrument_mixups:
|
||||
for n in mixup_list:
|
||||
if n in used_instruments:
|
||||
raise ValueError(f"Duplicate instrument name: {n}")
|
||||
used_instruments.add(n)
|
||||
|
||||
@classmethod
|
||||
def from_json(cls, path: str, cfg: VocabConfig):
|
||||
with open(path, "r") as f:
|
||||
config = json.load(f)
|
||||
config["cfg"] = cfg
|
||||
if "seed" not in config:
|
||||
config["seed"] = random.randint(0, 2**32 - 1)
|
||||
return cls(**config)
|
||||
|
||||
def get_augment_values(self, filename: str) -> Iterator[AugmentValues]:
|
||||
# first yield default values
|
||||
yield AugmentValues.default()
|
||||
|
||||
rng = random.Random(self.seed + hash(filename))
|
||||
for _ in range(int(self.augment_data_factor - 1)):
|
||||
# randomize order for each pool
|
||||
randomized_pools = [list(pool) for pool in self._mixup_pools]
|
||||
for pool in randomized_pools:
|
||||
rng.shuffle(pool)
|
||||
# distribute reassignments
|
||||
instrument_bin_remap = {}
|
||||
for i, pool in enumerate(randomized_pools):
|
||||
for j, instrument in enumerate(pool):
|
||||
instrument_bin_remap[instrument] = randomized_pools[i - 1][j]
|
||||
yield AugmentValues(
|
||||
instrument_bin_remap=instrument_bin_remap,
|
||||
velocity_mod_factor=1.0 + rng.choice(self.velocity_mod_pct),
|
||||
transpose_semitones=rng.choice(self.transpose_semitones),
|
||||
time_stretch_factor=1.0 + rng.choice(self.time_stretch_pct),
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class FilterConfig:
|
||||
# Whether to filter out MIDI files with duplicate MD5 hashes.
|
||||
deduplicate_md5: bool
|
||||
# Minimum time delay between notes in a file before splitting into multiple documents.
|
||||
piece_split_delay: float
|
||||
# Minimum length of a piece in milliseconds.
|
||||
min_piece_length: float
|
||||
|
||||
@classmethod
|
||||
def from_json(cls, path: str):
|
||||
with open(path, "r") as f:
|
||||
config = json.load(f)
|
||||
return cls(**config)
|
||||
|
||||
|
||||
def mix_volume(velocity: int, volume: int, expression: int) -> float:
|
||||
return velocity * (volume / 127.0) * (expression / 127.0)
|
||||
|
||||
|
||||
def convert_midi_to_str(
|
||||
cfg: VocabConfig,
|
||||
filter_cfg: FilterConfig,
|
||||
mid: mido.MidiFile,
|
||||
augment: AugmentValues = None,
|
||||
) -> List[str]:
|
||||
utils = VocabUtils(cfg)
|
||||
if augment is None:
|
||||
augment = AugmentValues.default()
|
||||
|
||||
# filter out unknown meta messages before merge (https://github.com/mido/mido/pull/286)
|
||||
for i in range(len(mid.tracks)):
|
||||
mid.tracks[i] = [msg for msg in mid.tracks[i] if msg.type != "unknown_meta"]
|
||||
|
||||
if len(mid.tracks) > 1:
|
||||
mid.tracks = [mido.merge_tracks(mid.tracks)]
|
||||
|
||||
delta_time_ms = 0.0
|
||||
tempo = 500000
|
||||
channel_program = {i: 0 for i in range(16)}
|
||||
channel_volume = {i: 127 for i in range(16)}
|
||||
channel_expression = {
|
||||
i: 127 for i in range(16)
|
||||
} # unlikely to be useful. expression usually modifies an already played note.
|
||||
channel_notes = {i: {} for i in range(16)}
|
||||
channel_pedal_on = {i: False for i in range(16)}
|
||||
channel_pedal_events = {
|
||||
i: {} for i in range(16)
|
||||
} # {channel: {(note, program) -> True}}
|
||||
started_flag = False
|
||||
|
||||
output_list = []
|
||||
output = ["<start>"]
|
||||
output_length_ms = 0.0
|
||||
token_data_buffer: List[
|
||||
Tuple[int, int, int, float]
|
||||
] = [] # need to sort notes between wait tokens
|
||||
|
||||
def flush_token_data_buffer():
|
||||
nonlocal token_data_buffer, output, cfg, utils, augment
|
||||
token_data = [
|
||||
x for x in utils.prog_data_list_to_token_data_list(token_data_buffer)
|
||||
]
|
||||
if augment.instrument_bin_remap or augment.transpose_semitones:
|
||||
# TODO put transpose in a real function
|
||||
raw_transpose = (
|
||||
lambda bin, n: n + augment.transpose_semitones
|
||||
if bin != cfg._ch10_bin_int
|
||||
else n
|
||||
)
|
||||
octave_shift_if_oob = (
|
||||
lambda n: n + 12 if n < 0 else n - 12 if n >= cfg.note_events else n
|
||||
)
|
||||
# TODO handle ranges beyond 12
|
||||
# octave_shift_if_oob = lambda n: 0 if n < 0 else (n - cfg.note_events) % 12 + cfg.note_events if n >= cfg.note_events else n
|
||||
transpose = lambda bin, n: octave_shift_if_oob(raw_transpose(bin, n))
|
||||
|
||||
token_data = [
|
||||
(augment.instrument_bin_remap.get(i, i), transpose(i, n), v)
|
||||
for i, n, v in token_data
|
||||
]
|
||||
if cfg.do_token_sorting:
|
||||
token_data = utils.sort_token_data(token_data)
|
||||
if cfg.unrolled_tokens:
|
||||
for t in token_data:
|
||||
output += [
|
||||
utils.format_unrolled_instrument_bin(t[0]),
|
||||
utils.format_unrolled_note(t[1]),
|
||||
utils.format_unrolled_velocity(t[2]),
|
||||
]
|
||||
else:
|
||||
output += [utils.format_note_token(*t) for t in token_data]
|
||||
token_data_buffer = []
|
||||
|
||||
def consume_note_program_data(prog: int, chan: int, note: int, vel: float):
|
||||
nonlocal output, output_length_ms, started_flag, delta_time_ms, cfg, utils, token_data_buffer
|
||||
is_token_valid = (
|
||||
utils.prog_data_to_token_data(prog, chan, note, vel) is not None
|
||||
)
|
||||
if not is_token_valid:
|
||||
return
|
||||
|
||||
if delta_time_ms > filter_cfg.piece_split_delay * 1000.0:
|
||||
# check if any notes are still held
|
||||
silent = True
|
||||
for channel in channel_notes.keys():
|
||||
if len(channel_notes[channel]) > 0:
|
||||
silent = False
|
||||
break
|
||||
if silent:
|
||||
flush_token_data_buffer()
|
||||
output.append("<end>")
|
||||
if output_length_ms > filter_cfg.min_piece_length * 1000.0:
|
||||
output_list.append(" ".join(output))
|
||||
output = ["<start>"]
|
||||
output_length_ms = 0.0
|
||||
started_flag = False
|
||||
if started_flag:
|
||||
wait_tokens = utils.data_to_wait_tokens(delta_time_ms)
|
||||
if len(wait_tokens) > 0:
|
||||
flush_token_data_buffer()
|
||||
output_length_ms += delta_time_ms
|
||||
output += wait_tokens
|
||||
delta_time_ms = 0.0
|
||||
token_data_buffer.append((prog, chan, note, vel * augment.velocity_mod_factor))
|
||||
started_flag = True
|
||||
|
||||
for msg in mid.tracks[0]:
|
||||
time_ms = mido.tick2second(msg.time, mid.ticks_per_beat, tempo) * 1000.0
|
||||
delta_time_ms += time_ms
|
||||
t = msg.type
|
||||
|
||||
if msg.is_meta:
|
||||
if t == "set_tempo":
|
||||
tempo = msg.tempo * augment.time_stretch_factor
|
||||
continue
|
||||
|
||||
def handle_note_off(ch, prog, n):
|
||||
if channel_pedal_on[ch]:
|
||||
channel_pedal_events[ch][(n, prog)] = True
|
||||
else:
|
||||
consume_note_program_data(prog, ch, n, 0)
|
||||
if n in channel_notes[ch]:
|
||||
del channel_notes[ch][n]
|
||||
|
||||
if t == "program_change":
|
||||
channel_program[msg.channel] = msg.program
|
||||
elif t == "note_on":
|
||||
if msg.velocity == 0:
|
||||
handle_note_off(msg.channel, channel_program[msg.channel], msg.note)
|
||||
else:
|
||||
if (msg.note, channel_program[msg.channel]) in channel_pedal_events[
|
||||
msg.channel
|
||||
]:
|
||||
del channel_pedal_events[msg.channel][
|
||||
(msg.note, channel_program[msg.channel])
|
||||
]
|
||||
consume_note_program_data(
|
||||
channel_program[msg.channel],
|
||||
msg.channel,
|
||||
msg.note,
|
||||
mix_volume(
|
||||
msg.velocity,
|
||||
channel_volume[msg.channel],
|
||||
channel_expression[msg.channel],
|
||||
),
|
||||
)
|
||||
channel_notes[msg.channel][msg.note] = True
|
||||
elif t == "note_off":
|
||||
handle_note_off(msg.channel, channel_program[msg.channel], msg.note)
|
||||
elif t == "control_change":
|
||||
if msg.control == 7 or msg.control == 39: # volume
|
||||
channel_volume[msg.channel] = msg.value
|
||||
elif msg.control == 11: # expression
|
||||
channel_expression[msg.channel] = msg.value
|
||||
elif msg.control == 64: # sustain pedal
|
||||
channel_pedal_on[msg.channel] = msg.value >= 64
|
||||
if not channel_pedal_on[msg.channel]:
|
||||
for note, program in channel_pedal_events[msg.channel]:
|
||||
handle_note_off(msg.channel, program, note)
|
||||
channel_pedal_events[msg.channel] = {}
|
||||
elif msg.control == 123: # all notes off
|
||||
for channel in channel_notes.keys():
|
||||
for note in list(channel_notes[channel]).copy():
|
||||
handle_note_off(channel, channel_program[channel], note)
|
||||
else:
|
||||
pass
|
||||
|
||||
flush_token_data_buffer()
|
||||
output.append("<end>")
|
||||
if output_length_ms > filter_cfg.min_piece_length * 1000.0:
|
||||
output_list.append(" ".join(output))
|
||||
return output_list
|
||||
|
||||
|
||||
def generate_program_change_messages(cfg: VocabConfig):
|
||||
for bin_name, channel in cfg.bin_channel_map.items():
|
||||
if channel == 9:
|
||||
continue
|
||||
program = cfg._instrument_names_str_to_int[
|
||||
cfg.bin_name_to_program_name[bin_name]
|
||||
]
|
||||
yield mido.Message("program_change", program=program, time=0, channel=channel)
|
||||
yield mido.Message("program_change", program=0, time=0, channel=9)
|
||||
|
||||
|
||||
@dataclass
|
||||
class DecodeState:
|
||||
total_time: float # milliseconds
|
||||
delta_accum: float # milliseconds
|
||||
current_bin: int
|
||||
current_note: int
|
||||
active_notes: Dict[Tuple[int, int], float] # { (channel, note): time started, ... }
|
||||
|
||||
|
||||
def token_to_midi_message(
|
||||
utils: VocabUtils, token: str, state: DecodeState, end_token_pause: float = 3.0
|
||||
) -> Iterator[Tuple[Optional[mido.Message], DecodeState]]:
|
||||
if state is None:
|
||||
state = DecodeState(
|
||||
total_time=0.0,
|
||||
delta_accum=0.0,
|
||||
current_bin=utils.cfg._short_instrument_names_str_to_int[
|
||||
utils.cfg.short_instr_bin_names[0]
|
||||
],
|
||||
current_note=0,
|
||||
active_notes={},
|
||||
)
|
||||
token = token.strip()
|
||||
if not token:
|
||||
yield None, state
|
||||
return
|
||||
if token == "<end>":
|
||||
d = end_token_pause * 1000.0
|
||||
state.delta_accum += d
|
||||
state.total_time += d
|
||||
if utils.cfg.decode_end_held_note_delay != 0.0:
|
||||
# end held notes
|
||||
for (channel, note), start_time in list(state.active_notes.items()).copy():
|
||||
ticks = int(mido.second2tick(state.delta_accum / 1000.0, 480, 500000))
|
||||
state.delta_accum = 0.0
|
||||
del state.active_notes[(channel, note)]
|
||||
yield mido.Message(
|
||||
"note_off", note=note, time=ticks, channel=channel
|
||||
), state
|
||||
yield None, state
|
||||
return
|
||||
if token.startswith("<"):
|
||||
yield None, state
|
||||
return
|
||||
|
||||
if utils.cfg.unrolled_tokens:
|
||||
if token[0] == "t":
|
||||
d = utils.wait_token_to_delta(token)
|
||||
state.delta_accum += d
|
||||
state.total_time += d
|
||||
elif token[0] == "n":
|
||||
state.current_note = int(token[1:], base=16)
|
||||
elif token[0] == "i":
|
||||
state.current_bin = utils.cfg._short_instrument_names_str_to_int[token[1:]]
|
||||
elif token[0] == "v":
|
||||
current_velocity = utils.bin_to_velocity(int(token[1:], base=16))
|
||||
channel = utils.cfg.bin_channel_map[
|
||||
utils.cfg.bin_instrument_names[state.current_bin]
|
||||
]
|
||||
ticks = int(mido.second2tick(state.delta_accum / 1000.0, 480, 500000))
|
||||
state.delta_accum = 0.0
|
||||
if current_velocity > 0:
|
||||
yield mido.Message(
|
||||
"note_on",
|
||||
note=state.current_note,
|
||||
velocity=current_velocity,
|
||||
time=ticks,
|
||||
channel=channel,
|
||||
), state
|
||||
else:
|
||||
yield mido.Message(
|
||||
"note_off",
|
||||
note=state.current_note,
|
||||
velocity=0,
|
||||
time=ticks,
|
||||
channel=channel,
|
||||
), state
|
||||
else:
|
||||
if token[0] == "t" and token[1].isdigit(): # wait token
|
||||
d = utils.wait_token_to_delta(token)
|
||||
state.delta_accum += d
|
||||
state.total_time += d
|
||||
if utils.cfg.decode_end_held_note_delay != 0.0:
|
||||
# remove notes that have been held for too long
|
||||
for (channel, note), start_time in list(
|
||||
state.active_notes.items()
|
||||
).copy():
|
||||
if (
|
||||
state.total_time - start_time
|
||||
> utils.cfg.decode_end_held_note_delay * 1000.0
|
||||
):
|
||||
ticks = int(
|
||||
mido.second2tick(state.delta_accum / 1000.0, 480, 500000)
|
||||
)
|
||||
state.delta_accum = 0.0
|
||||
del state.active_notes[(channel, note)]
|
||||
yield mido.Message(
|
||||
"note_off", note=note, time=ticks, channel=channel
|
||||
), state
|
||||
return
|
||||
else: # note token
|
||||
bin, note, velocity = utils.note_token_to_data(token)
|
||||
channel = utils.cfg.bin_channel_map[utils.cfg.bin_instrument_names[bin]]
|
||||
ticks = int(mido.second2tick(state.delta_accum / 1000.0, 480, 500000))
|
||||
state.delta_accum = 0.0
|
||||
if velocity > 0:
|
||||
if utils.cfg.decode_fix_repeated_notes:
|
||||
if (channel, note) in state.active_notes:
|
||||
del state.active_notes[(channel, note)]
|
||||
yield mido.Message(
|
||||
"note_off", note=note, time=ticks, channel=channel
|
||||
), state
|
||||
ticks = 0
|
||||
state.active_notes[(channel, note)] = state.total_time
|
||||
yield mido.Message(
|
||||
"note_on", note=note, velocity=velocity, time=ticks, channel=channel
|
||||
), state
|
||||
return
|
||||
else:
|
||||
if (channel, note) in state.active_notes:
|
||||
del state.active_notes[(channel, note)]
|
||||
yield mido.Message(
|
||||
"note_off", note=note, time=ticks, channel=channel
|
||||
), state
|
||||
return
|
||||
yield None, state
|
||||
|
||||
|
||||
def str_to_midi_messages(utils: VocabUtils, data: str) -> Iterator[mido.Message]:
|
||||
state = None
|
||||
for token in data.split(" "):
|
||||
for msg, new_state in token_to_midi_message(utils, token, state):
|
||||
state = new_state
|
||||
if msg is not None:
|
||||
yield msg
|
||||
|
||||
|
||||
def convert_str_to_midi(
|
||||
cfg: VocabConfig, data: str, meta_text: str = "Generated by MIDI-LLM-tokenizer"
|
||||
) -> mido.MidiFile:
|
||||
utils = VocabUtils(cfg)
|
||||
mid = mido.MidiFile()
|
||||
track = mido.MidiTrack()
|
||||
mid.tracks.append(track)
|
||||
|
||||
tempo = 500000
|
||||
if meta_text:
|
||||
track.append(mido.MetaMessage("text", text=meta_text, time=0))
|
||||
track.append(mido.MetaMessage("set_tempo", tempo=tempo, time=0))
|
||||
for msg in generate_program_change_messages(cfg):
|
||||
track.append(msg)
|
||||
|
||||
# data = data.replace("<start>", "").replace("<end>", "").replace("<pad>", "").strip()
|
||||
for msg in str_to_midi_messages(utils, data):
|
||||
track.append(msg)
|
||||
|
||||
track.append(mido.MetaMessage("end_of_track", time=0))
|
||||
|
||||
return mid
|
||||
@ -1,5 +0,0 @@
|
||||
{
|
||||
"deduplicate_md5": true,
|
||||
"piece_split_delay": 10000,
|
||||
"min_piece_length": 0
|
||||
}
|
||||
@ -1,303 +0,0 @@
|
||||
{
|
||||
"note_events": 128,
|
||||
"wait_events": 125,
|
||||
"max_wait_time": 1000,
|
||||
"velocity_events": 128,
|
||||
"velocity_bins": 12,
|
||||
"velocity_exp": 0.5,
|
||||
"do_token_sorting": true,
|
||||
"unrolled_tokens": false,
|
||||
"decode_end_held_note_delay": 5.0,
|
||||
"decode_fix_repeated_notes": true,
|
||||
"bin_instrument_names": [
|
||||
"percussion",
|
||||
"drum",
|
||||
"tuba",
|
||||
"marimba",
|
||||
"bass",
|
||||
"guitar",
|
||||
"violin",
|
||||
"trumpet",
|
||||
"piano",
|
||||
"sax",
|
||||
"flute",
|
||||
"lead",
|
||||
"pad"
|
||||
],
|
||||
"ch10_instrument_bin_name": "percussion",
|
||||
"program_name_to_bin_name": {
|
||||
"Acoustic Grand Piano": "piano",
|
||||
"Bright Acoustic Piano": "piano",
|
||||
"Electric Grand Piano": "piano",
|
||||
"Honky-tonk Piano": "piano",
|
||||
"Electric Piano 1 (Rhodes Piano)": "piano",
|
||||
"Electric Piano 2 (Chorused Piano)": "piano",
|
||||
"Harpsichord": "piano",
|
||||
"Clavinet": "piano",
|
||||
"Celesta": "marimba",
|
||||
"Glockenspiel": "marimba",
|
||||
"Music Box": "marimba",
|
||||
"Vibraphone": "marimba",
|
||||
"Marimba": "marimba",
|
||||
"Xylophone": "marimba",
|
||||
"Tubular Bells": "marimba",
|
||||
"Dulcimer (Santur)": "marimba",
|
||||
"Drawbar Organ (Hammond)": "marimba",
|
||||
"Percussive Organ": "piano",
|
||||
"Rock Organ": "piano",
|
||||
"Church Organ": "piano",
|
||||
"Reed Organ": "piano",
|
||||
"Accordion (French)": "piano",
|
||||
"Harmonica": "piano",
|
||||
"Tango Accordion (Band neon)": "piano",
|
||||
"Acoustic Guitar (nylon)": "guitar",
|
||||
"Acoustic Guitar (steel)": "guitar",
|
||||
"Electric Guitar (jazz)": "guitar",
|
||||
"Electric Guitar (clean)": "guitar",
|
||||
"Electric Guitar (muted)": "guitar",
|
||||
"Overdriven Guitar": "guitar",
|
||||
"Distortion Guitar": "guitar",
|
||||
"Guitar harmonics": "guitar",
|
||||
"Acoustic Bass": "bass",
|
||||
"Electric Bass (fingered)": "bass",
|
||||
"Electric Bass (picked)": "bass",
|
||||
"Fretless Bass": "bass",
|
||||
"Slap Bass 1": "bass",
|
||||
"Slap Bass 2": "bass",
|
||||
"Synth Bass 1": "bass",
|
||||
"Synth Bass 2": "bass",
|
||||
"Violin": "violin",
|
||||
"Viola": "violin",
|
||||
"Cello": "bass",
|
||||
"Contrabass": "bass",
|
||||
"Tremolo Strings": "violin",
|
||||
"Pizzicato Strings": "violin",
|
||||
"Orchestral Harp": "violin",
|
||||
"Timpani": "drum",
|
||||
"String Ensemble 1 (strings)": "violin",
|
||||
"String Ensemble 2 (slow strings)": "violin",
|
||||
"SynthStrings 1": "violin",
|
||||
"SynthStrings 2": "violin",
|
||||
"Choir Aahs": "violin",
|
||||
"Voice Oohs": "violin",
|
||||
"Synth Voice": "violin",
|
||||
"Orchestra Hit": "",
|
||||
"Trumpet": "trumpet",
|
||||
"Trombone": "tuba",
|
||||
"Tuba": "tuba",
|
||||
"Muted Trumpet": "trumpet",
|
||||
"French Horn": "trumpet",
|
||||
"Brass Section": "trumpet",
|
||||
"SynthBrass 1": "trumpet",
|
||||
"SynthBrass 2": "trumpet",
|
||||
"Soprano Sax": "sax",
|
||||
"Alto Sax": "sax",
|
||||
"Tenor Sax": "sax",
|
||||
"Baritone Sax": "sax",
|
||||
"Oboe": "sax",
|
||||
"English Horn": "trumpet",
|
||||
"Bassoon": "sax",
|
||||
"Clarinet": "sax",
|
||||
"Piccolo": "flute",
|
||||
"Flute": "flute",
|
||||
"Recorder": "flute",
|
||||
"Pan Flute": "flute",
|
||||
"Blown Bottle": "flute",
|
||||
"Shakuhachi": "flute",
|
||||
"Whistle": "flute",
|
||||
"Ocarina": "flute",
|
||||
"Lead 1 (square wave)": "lead",
|
||||
"Lead 2 (sawtooth wave)": "lead",
|
||||
"Lead 3 (calliope)": "lead",
|
||||
"Lead 4 (chiffer)": "lead",
|
||||
"Lead 5 (charang)": "lead",
|
||||
"Lead 6 (voice solo)": "violin",
|
||||
"Lead 7 (fifths)": "lead",
|
||||
"Lead 8 (bass + lead)": "lead",
|
||||
"Pad 1 (new age Fantasia)": "pad",
|
||||
"Pad 2 (warm)": "pad",
|
||||
"Pad 3 (polysynth)": "pad",
|
||||
"Pad 4 (choir space voice)": "violin",
|
||||
"Pad 5 (bowed glass)": "pad",
|
||||
"Pad 6 (metallic pro)": "pad",
|
||||
"Pad 7 (halo)": "pad",
|
||||
"Pad 8 (sweep)": "pad",
|
||||
"FX 1 (rain)": "",
|
||||
"FX 2 (soundtrack)": "",
|
||||
"FX 3 (crystal)": "",
|
||||
"FX 4 (atmosphere)": "",
|
||||
"FX 5 (brightness)": "",
|
||||
"FX 6 (goblins)": "",
|
||||
"FX 7 (echoes, drops)": "",
|
||||
"FX 8 (sci-fi, star theme)": "",
|
||||
"Sitar": "guitar",
|
||||
"Banjo": "guitar",
|
||||
"Shamisen": "guitar",
|
||||
"Koto": "guitar",
|
||||
"Kalimba": "guitar",
|
||||
"Bag pipe": "sax",
|
||||
"Fiddle": "violin",
|
||||
"Shanai": "sax",
|
||||
"Tinkle Bell": "marimba",
|
||||
"Agogo": "marimba",
|
||||
"Steel Drums": "marimba",
|
||||
"Woodblock": "marimba",
|
||||
"Taiko Drum": "drum",
|
||||
"Melodic Tom": "drum",
|
||||
"Synth Drum": "drum",
|
||||
"Reverse Cymbal": "",
|
||||
"Guitar Fret Noise": "",
|
||||
"Breath Noise": "",
|
||||
"Seashore": "",
|
||||
"Bird Tweet": "",
|
||||
"Telephone Ring": "",
|
||||
"Helicopter": "",
|
||||
"Applause": "",
|
||||
"Gunshot": ""
|
||||
},
|
||||
"bin_name_to_program_name": {
|
||||
"piano": "Acoustic Grand Piano",
|
||||
"marimba": "Marimba",
|
||||
"drum": "Synth Drum",
|
||||
"guitar": "Acoustic Guitar (steel)",
|
||||
"bass": "Acoustic Bass",
|
||||
"violin": "Violin",
|
||||
"percussion": "",
|
||||
"trumpet": "Trumpet",
|
||||
"tuba": "Tuba",
|
||||
"sax": "Tenor Sax",
|
||||
"flute": "Flute",
|
||||
"lead": "Lead 1 (square wave)",
|
||||
"pad": "Pad 1 (new age Fantasia)"
|
||||
},
|
||||
"instrument_names": {
|
||||
"0": "Acoustic Grand Piano",
|
||||
"1": "Bright Acoustic Piano",
|
||||
"2": "Electric Grand Piano",
|
||||
"3": "Honky-tonk Piano",
|
||||
"4": "Electric Piano 1 (Rhodes Piano)",
|
||||
"5": "Electric Piano 2 (Chorused Piano)",
|
||||
"6": "Harpsichord",
|
||||
"7": "Clavinet",
|
||||
"8": "Celesta",
|
||||
"9": "Glockenspiel",
|
||||
"10": "Music Box",
|
||||
"11": "Vibraphone",
|
||||
"12": "Marimba",
|
||||
"13": "Xylophone",
|
||||
"14": "Tubular Bells",
|
||||
"15": "Dulcimer (Santur)",
|
||||
"16": "Drawbar Organ (Hammond)",
|
||||
"17": "Percussive Organ",
|
||||
"18": "Rock Organ",
|
||||
"19": "Church Organ",
|
||||
"20": "Reed Organ",
|
||||
"21": "Accordion (French)",
|
||||
"22": "Harmonica",
|
||||
"23": "Tango Accordion (Band neon)",
|
||||
"24": "Acoustic Guitar (nylon)",
|
||||
"25": "Acoustic Guitar (steel)",
|
||||
"26": "Electric Guitar (jazz)",
|
||||
"27": "Electric Guitar (clean)",
|
||||
"28": "Electric Guitar (muted)",
|
||||
"29": "Overdriven Guitar",
|
||||
"30": "Distortion Guitar",
|
||||
"31": "Guitar harmonics",
|
||||
"32": "Acoustic Bass",
|
||||
"33": "Electric Bass (fingered)",
|
||||
"34": "Electric Bass (picked)",
|
||||
"35": "Fretless Bass",
|
||||
"36": "Slap Bass 1",
|
||||
"37": "Slap Bass 2",
|
||||
"38": "Synth Bass 1",
|
||||
"39": "Synth Bass 2",
|
||||
"40": "Violin",
|
||||
"41": "Viola",
|
||||
"42": "Cello",
|
||||
"43": "Contrabass",
|
||||
"44": "Tremolo Strings",
|
||||
"45": "Pizzicato Strings",
|
||||
"46": "Orchestral Harp",
|
||||
"47": "Timpani",
|
||||
"48": "String Ensemble 1 (strings)",
|
||||
"49": "String Ensemble 2 (slow strings)",
|
||||
"50": "SynthStrings 1",
|
||||
"51": "SynthStrings 2",
|
||||
"52": "Choir Aahs",
|
||||
"53": "Voice Oohs",
|
||||
"54": "Synth Voice",
|
||||
"55": "Orchestra Hit",
|
||||
"56": "Trumpet",
|
||||
"57": "Trombone",
|
||||
"58": "Tuba",
|
||||
"59": "Muted Trumpet",
|
||||
"60": "French Horn",
|
||||
"61": "Brass Section",
|
||||
"62": "SynthBrass 1",
|
||||
"63": "SynthBrass 2",
|
||||
"64": "Soprano Sax",
|
||||
"65": "Alto Sax",
|
||||
"66": "Tenor Sax",
|
||||
"67": "Baritone Sax",
|
||||
"68": "Oboe",
|
||||
"69": "English Horn",
|
||||
"70": "Bassoon",
|
||||
"71": "Clarinet",
|
||||
"72": "Piccolo",
|
||||
"73": "Flute",
|
||||
"74": "Recorder",
|
||||
"75": "Pan Flute",
|
||||
"76": "Blown Bottle",
|
||||
"77": "Shakuhachi",
|
||||
"78": "Whistle",
|
||||
"79": "Ocarina",
|
||||
"80": "Lead 1 (square wave)",
|
||||
"81": "Lead 2 (sawtooth wave)",
|
||||
"82": "Lead 3 (calliope)",
|
||||
"83": "Lead 4 (chiffer)",
|
||||
"84": "Lead 5 (charang)",
|
||||
"85": "Lead 6 (voice solo)",
|
||||
"86": "Lead 7 (fifths)",
|
||||
"87": "Lead 8 (bass + lead)",
|
||||
"88": "Pad 1 (new age Fantasia)",
|
||||
"89": "Pad 2 (warm)",
|
||||
"90": "Pad 3 (polysynth)",
|
||||
"91": "Pad 4 (choir space voice)",
|
||||
"92": "Pad 5 (bowed glass)",
|
||||
"93": "Pad 6 (metallic pro)",
|
||||
"94": "Pad 7 (halo)",
|
||||
"95": "Pad 8 (sweep)",
|
||||
"96": "FX 1 (rain)",
|
||||
"97": "FX 2 (soundtrack)",
|
||||
"98": "FX 3 (crystal)",
|
||||
"99": "FX 4 (atmosphere)",
|
||||
"100": "FX 5 (brightness)",
|
||||
"101": "FX 6 (goblins)",
|
||||
"102": "FX 7 (echoes, drops)",
|
||||
"103": "FX 8 (sci-fi, star theme)",
|
||||
"104": "Sitar",
|
||||
"105": "Banjo",
|
||||
"106": "Shamisen",
|
||||
"107": "Koto",
|
||||
"108": "Kalimba",
|
||||
"109": "Bag pipe",
|
||||
"110": "Fiddle",
|
||||
"111": "Shanai",
|
||||
"112": "Tinkle Bell",
|
||||
"113": "Agogo",
|
||||
"114": "Steel Drums",
|
||||
"115": "Woodblock",
|
||||
"116": "Taiko Drum",
|
||||
"117": "Melodic Tom",
|
||||
"118": "Synth Drum",
|
||||
"119": "Reverse Cymbal",
|
||||
"120": "Guitar Fret Noise",
|
||||
"121": "Breath Noise",
|
||||
"122": "Seashore",
|
||||
"123": "Bird Tweet",
|
||||
"124": "Telephone Ring",
|
||||
"125": "Helicopter",
|
||||
"126": "Applause",
|
||||
"127": "Gunshot"
|
||||
}
|
||||
}
|
||||
@ -1,13 +1,11 @@
|
||||
import os
|
||||
import global_var
|
||||
import sys
|
||||
|
||||
|
||||
def ngrok_connect():
|
||||
from pyngrok import ngrok, conf
|
||||
|
||||
conf.set_default(
|
||||
conf.PyngrokConfig(ngrok_path="./ngrok.exe" if os.name == "nt" else "./ngrok")
|
||||
)
|
||||
conf.set_default(conf.PyngrokConfig(ngrok_path="./ngrok"))
|
||||
ngrok.set_auth_token(os.environ["ngrok_token"])
|
||||
http_tunnel = ngrok.connect(global_var.get(global_var.Args).port)
|
||||
print(f"ngrok url: {http_tunnel.public_url}")
|
||||
http_tunnel = ngrok.connect(8000 if len(sys.argv) == 1 else int(sys.argv[1]))
|
||||
print(http_tunnel.public_url)
|
||||
|
||||
@ -1,833 +1,77 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from enum import Enum, auto
|
||||
import os
|
||||
import pathlib
|
||||
import copy
|
||||
import re
|
||||
import time
|
||||
from typing import Dict, Iterable, List, Tuple, Union, Type, Callable
|
||||
from utils.log import quick_log
|
||||
from fastapi import HTTPException, status
|
||||
from pydantic import BaseModel, Field
|
||||
from routes import state_cache
|
||||
import global_var
|
||||
|
||||
os.environ["TORCH_EXTENSIONS_DIR"] = f"{pathlib.Path(__file__).parent.parent.resolve()}"
|
||||
|
||||
|
||||
class RWKVType(Enum):
|
||||
NoneType = auto()
|
||||
Raven = auto()
|
||||
World = auto()
|
||||
Music = auto()
|
||||
|
||||
|
||||
class AbstractRWKV(ABC):
|
||||
def __init__(self, model, pipeline):
|
||||
self.EOS_ID = 0
|
||||
|
||||
self.name = "rwkv"
|
||||
self.model_path = ""
|
||||
self.version = 4
|
||||
self.model = model
|
||||
self.pipeline = pipeline
|
||||
self.model_state = None
|
||||
self.model_tokens = []
|
||||
self.rwkv_type: RWKVType = RWKVType.NoneType
|
||||
self.tokenizer_len = len(model.w["emb.weight"])
|
||||
|
||||
self.max_tokens_per_generation = 500
|
||||
self.temperature = 1
|
||||
self.top_p = 0.3
|
||||
self.top_k = 0
|
||||
self.penalty_alpha_presence = 0
|
||||
self.penalty_alpha_frequency = 1
|
||||
self.penalty_decay = 0.99
|
||||
self.global_penalty = False
|
||||
self.state_path = ""
|
||||
self.state_tuned = None
|
||||
|
||||
@abstractmethod
|
||||
def adjust_occurrence(self, occurrence: Dict, token: int):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def adjust_forward_logits(self, logits: List[float], occurrence: Dict, i: int):
|
||||
pass
|
||||
|
||||
# Model only saw '\n\n' as [187, 187] before, but the tokenizer outputs [535] for it at the end
|
||||
@abstractmethod
|
||||
def fix_tokens(self, tokens) -> List[int]:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def run_rnn(
|
||||
self, _tokens: List[str], newline_adj: int = 0
|
||||
) -> Tuple[List[float], int]:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delta_postprocess(self, delta: str) -> str:
|
||||
pass
|
||||
|
||||
def get_embedding(self, input: str, fast_mode: bool) -> Tuple[List[float], int]:
|
||||
import numpy as np
|
||||
|
||||
if fast_mode:
|
||||
embedding, token_len = self.__fast_embedding(
|
||||
self.fix_tokens(self.pipeline.encode(input)), None
|
||||
)
|
||||
else:
|
||||
self.model_state = None
|
||||
self.model_tokens = []
|
||||
_, token_len = self.run_rnn(self.fix_tokens(self.pipeline.encode(input)))
|
||||
embedding = self.model_state[-11].tolist()
|
||||
embedding = (embedding / np.linalg.norm(embedding)).tolist()
|
||||
return embedding, token_len
|
||||
|
||||
def __fast_embedding(self, tokens: List[str], state):
|
||||
import torch
|
||||
|
||||
tokens = [int(x) for x in tokens]
|
||||
token_len = len(tokens)
|
||||
self = self.model
|
||||
|
||||
with torch.no_grad():
|
||||
w = self.w
|
||||
args = self.args
|
||||
|
||||
if state == None:
|
||||
state = [None] * args.n_layer * 5
|
||||
for i in range(
|
||||
args.n_layer
|
||||
): # state: 0=att_xx 1=att_aa 2=att_bb 3=att_pp 4=ffn_xx
|
||||
dd = self.strategy[i]
|
||||
dev = dd.device
|
||||
atype = dd.atype
|
||||
state[i * 5 + 0] = torch.zeros(
|
||||
args.n_embd, dtype=atype, requires_grad=False, device=dev
|
||||
).contiguous()
|
||||
state[i * 5 + 1] = torch.zeros(
|
||||
args.n_embd, dtype=torch.float, requires_grad=False, device=dev
|
||||
).contiguous()
|
||||
state[i * 5 + 2] = torch.zeros(
|
||||
args.n_embd, dtype=torch.float, requires_grad=False, device=dev
|
||||
).contiguous()
|
||||
state[i * 5 + 3] = (
|
||||
torch.zeros(
|
||||
args.n_embd,
|
||||
dtype=torch.float,
|
||||
requires_grad=False,
|
||||
device=dev,
|
||||
).contiguous()
|
||||
- 1e30
|
||||
)
|
||||
state[i * 5 + 4] = torch.zeros(
|
||||
args.n_embd, dtype=atype, requires_grad=False, device=dev
|
||||
).contiguous()
|
||||
|
||||
break
|
||||
|
||||
seq_mode = len(tokens) > 1
|
||||
|
||||
x = w["emb.weight"][tokens if seq_mode else tokens[0]]
|
||||
|
||||
for i in range(args.n_layer):
|
||||
bbb = f"blocks.{i}."
|
||||
att = f"blocks.{i}.att."
|
||||
ffn = f"blocks.{i}.ffn."
|
||||
dd = self.strategy[i]
|
||||
dev = dd.device
|
||||
atype = dd.atype
|
||||
wtype = dd.wtype
|
||||
if seq_mode:
|
||||
if "cuda" in str(dev) and os.environ["RWKV_CUDA_ON"] == "1":
|
||||
ATT = (
|
||||
self.cuda_att_seq
|
||||
if wtype != torch.uint8
|
||||
else self.cuda_att_seq_i8
|
||||
)
|
||||
else:
|
||||
ATT = self.att_seq if wtype != torch.uint8 else self.att_seq_i8
|
||||
FFN = self.ffn_seq if wtype != torch.uint8 else self.ffn_seq_i8
|
||||
else:
|
||||
ATT = self.att_one if wtype != torch.uint8 else self.att_one_i8
|
||||
FFN = self.ffn_one if wtype != torch.uint8 else self.ffn_one_i8
|
||||
|
||||
x = x.to(dtype=atype, device=dev)
|
||||
|
||||
kw = w[f"{att}key.weight"]
|
||||
vw = w[f"{att}value.weight"]
|
||||
rw = w[f"{att}receptance.weight"]
|
||||
ow = w[f"{att}output.weight"]
|
||||
if dd.stream:
|
||||
kw = kw.to(device=dev, non_blocking=True)
|
||||
vw = vw.to(device=dev, non_blocking=True)
|
||||
rw = rw.to(device=dev, non_blocking=True)
|
||||
ow = ow.to(device=dev, non_blocking=True)
|
||||
kmx = w[f"{att}key.weight_mx"] if wtype == torch.uint8 else x
|
||||
krx = w[f"{att}key.weight_rx"] if wtype == torch.uint8 else x
|
||||
kmy = w[f"{att}key.weight_my"] if wtype == torch.uint8 else x
|
||||
kry = w[f"{att}key.weight_ry"] if wtype == torch.uint8 else x
|
||||
vmx = w[f"{att}value.weight_mx"] if wtype == torch.uint8 else x
|
||||
vrx = w[f"{att}value.weight_rx"] if wtype == torch.uint8 else x
|
||||
vmy = w[f"{att}value.weight_my"] if wtype == torch.uint8 else x
|
||||
vry = w[f"{att}value.weight_ry"] if wtype == torch.uint8 else x
|
||||
rmx = w[f"{att}receptance.weight_mx"] if wtype == torch.uint8 else x
|
||||
rrx = w[f"{att}receptance.weight_rx"] if wtype == torch.uint8 else x
|
||||
rmy = w[f"{att}receptance.weight_my"] if wtype == torch.uint8 else x
|
||||
rry = w[f"{att}receptance.weight_ry"] if wtype == torch.uint8 else x
|
||||
omx = w[f"{att}output.weight_mx"] if wtype == torch.uint8 else x
|
||||
orx = w[f"{att}output.weight_rx"] if wtype == torch.uint8 else x
|
||||
omy = w[f"{att}output.weight_my"] if wtype == torch.uint8 else x
|
||||
ory = w[f"{att}output.weight_ry"] if wtype == torch.uint8 else x
|
||||
(
|
||||
x,
|
||||
state[i * 5 + 0],
|
||||
state[i * 5 + 1],
|
||||
state[i * 5 + 2],
|
||||
state[i * 5 + 3],
|
||||
) = ATT(
|
||||
x,
|
||||
state[i * 5 + 0],
|
||||
state[i * 5 + 1],
|
||||
state[i * 5 + 2],
|
||||
state[i * 5 + 3],
|
||||
w[f"{bbb}ln1.weight"],
|
||||
w[f"{bbb}ln1.bias"],
|
||||
w[f"{att}time_mix_k"],
|
||||
w[f"{att}time_mix_v"],
|
||||
w[f"{att}time_mix_r"],
|
||||
w[f"{att}time_decay"],
|
||||
w[f"{att}time_first"],
|
||||
kw,
|
||||
vw,
|
||||
rw,
|
||||
ow,
|
||||
kmx,
|
||||
krx,
|
||||
kmy,
|
||||
kry,
|
||||
vmx,
|
||||
vrx,
|
||||
vmy,
|
||||
vry,
|
||||
rmx,
|
||||
rrx,
|
||||
rmy,
|
||||
rry,
|
||||
omx,
|
||||
orx,
|
||||
omy,
|
||||
ory,
|
||||
)
|
||||
|
||||
return state[0].tolist(), token_len
|
||||
|
||||
def generate(
|
||||
self, prompt: str, stop: Union[str, List[str], None] = None
|
||||
) -> Iterable[Tuple[str, str, int, int]]:
|
||||
import numpy as np
|
||||
|
||||
quick_log(None, None, "Generation Prompt:\n" + prompt)
|
||||
cache = None
|
||||
delta_prompt = prompt
|
||||
try:
|
||||
cache = state_cache.longest_prefix_state(
|
||||
state_cache.LongestPrefixStateBody(prompt=prompt), None
|
||||
)
|
||||
except HTTPException:
|
||||
pass
|
||||
if cache is None or cache["prompt"] == "" or cache["state"] is None:
|
||||
if self.state_path:
|
||||
self.model_state = copy.deepcopy(self.state_tuned)
|
||||
else:
|
||||
self.model_state = None
|
||||
self.model_tokens = []
|
||||
else:
|
||||
delta_prompt = prompt[len(cache["prompt"]) :]
|
||||
self.model_state = cache["state"]
|
||||
self.model_tokens = cache["tokens"]
|
||||
logits = cache["logits"]
|
||||
|
||||
prompt_token_len = 0
|
||||
if delta_prompt != "":
|
||||
prompt_start_time = time.time()
|
||||
logits, prompt_token_len = self.run_rnn(
|
||||
self.fix_tokens(self.pipeline.encode(delta_prompt))
|
||||
)
|
||||
prompt_end_time = time.time()
|
||||
prompt_interval = prompt_end_time - prompt_start_time
|
||||
tps = 0
|
||||
if prompt_interval > 0:
|
||||
tps = prompt_token_len / prompt_interval
|
||||
print(f"Prompt Prefill TPS: {tps:.2f}", end=" ", flush=True)
|
||||
try:
|
||||
state_cache.add_state(
|
||||
state_cache.AddStateBody(
|
||||
prompt=prompt,
|
||||
tokens=self.model_tokens,
|
||||
state=self.model_state,
|
||||
logits=logits,
|
||||
)
|
||||
)
|
||||
except HTTPException:
|
||||
pass
|
||||
|
||||
begin = len(self.model_tokens)
|
||||
out_last = begin
|
||||
|
||||
occurrence: Dict = {}
|
||||
|
||||
completion_token_len = 0
|
||||
response = ""
|
||||
for i in range(self.max_tokens_per_generation):
|
||||
self.adjust_forward_logits(logits, occurrence, i)
|
||||
|
||||
token = self.pipeline.sample_logits(
|
||||
logits, temperature=self.temperature, top_p=self.top_p, top_k=self.top_k
|
||||
)
|
||||
|
||||
if token == self.EOS_ID:
|
||||
try:
|
||||
state_cache.add_state(
|
||||
state_cache.AddStateBody(
|
||||
prompt=prompt + response,
|
||||
tokens=self.model_tokens,
|
||||
state=self.model_state,
|
||||
logits=logits,
|
||||
)
|
||||
)
|
||||
except HTTPException:
|
||||
pass
|
||||
yield response, "", prompt_token_len, completion_token_len
|
||||
break
|
||||
|
||||
self.adjust_occurrence(occurrence, token)
|
||||
|
||||
logits, _ = self.run_rnn([token])
|
||||
completion_token_len = completion_token_len + 1
|
||||
delta: str = self.delta_postprocess(
|
||||
self.pipeline.decode(self.model_tokens[out_last:])
|
||||
)
|
||||
if "\ufffd" not in delta: # avoid utf-8 display issues
|
||||
response += delta
|
||||
if stop is not None:
|
||||
if type(stop) == str:
|
||||
if stop in response:
|
||||
try:
|
||||
state_cache.add_state(
|
||||
state_cache.AddStateBody(
|
||||
prompt=prompt + response,
|
||||
tokens=self.model_tokens,
|
||||
state=self.model_state,
|
||||
logits=logits,
|
||||
)
|
||||
)
|
||||
except HTTPException:
|
||||
pass
|
||||
response = response.split(stop)[0]
|
||||
yield response, "", prompt_token_len, completion_token_len
|
||||
break
|
||||
elif type(stop) == list:
|
||||
exit_flag = False
|
||||
for s in stop:
|
||||
if s in response:
|
||||
try:
|
||||
state_cache.add_state(
|
||||
state_cache.AddStateBody(
|
||||
prompt=prompt + response,
|
||||
tokens=self.model_tokens,
|
||||
state=self.model_state,
|
||||
logits=logits,
|
||||
)
|
||||
)
|
||||
except HTTPException:
|
||||
pass
|
||||
exit_flag = True
|
||||
response = response.split(s)[0]
|
||||
yield response, "", prompt_token_len, completion_token_len
|
||||
break
|
||||
if exit_flag:
|
||||
break
|
||||
out_last = begin + i + 1
|
||||
if i == self.max_tokens_per_generation - 1:
|
||||
try:
|
||||
state_cache.add_state(
|
||||
state_cache.AddStateBody(
|
||||
prompt=prompt + response,
|
||||
tokens=self.model_tokens,
|
||||
state=self.model_state,
|
||||
logits=logits,
|
||||
)
|
||||
)
|
||||
except HTTPException:
|
||||
pass
|
||||
yield response, delta, prompt_token_len, completion_token_len
|
||||
|
||||
|
||||
class TextRWKV(AbstractRWKV):
|
||||
def __init__(self, model, pipeline) -> None:
|
||||
super().__init__(model, pipeline)
|
||||
|
||||
self.CHUNK_LEN = 256
|
||||
|
||||
self.max_tokens_per_generation = 500
|
||||
self.temperature = 1
|
||||
self.top_p = 0.3
|
||||
self.top_k = 0
|
||||
self.penalty_alpha_presence = 0
|
||||
self.penalty_alpha_frequency = 1
|
||||
|
||||
self.interface = ":"
|
||||
if self.tokenizer_len < 65536:
|
||||
self.rwkv_type = RWKVType.Raven
|
||||
self.user = "Bob"
|
||||
self.bot = "Alice"
|
||||
self.END_OF_LINE = 187
|
||||
else:
|
||||
self.rwkv_type = RWKVType.World
|
||||
self.user = "User"
|
||||
self.bot = "Assistant"
|
||||
self.END_OF_LINE = 11
|
||||
|
||||
self.AVOID_REPEAT_TOKENS = set()
|
||||
AVOID_REPEAT = ",:?!"
|
||||
for i in AVOID_REPEAT:
|
||||
dd = self.pipeline.encode(i)
|
||||
assert len(dd) == 1
|
||||
self.AVOID_REPEAT_TOKENS.add(dd[0])
|
||||
self.AVOID_PENALTY_TOKENS = set()
|
||||
AVOID_PENALTY = '\n,.:?!,。:?!"“”<>[]{}/\\|;;~`@#$%^&*()_+-=0123456789 '
|
||||
for i in AVOID_PENALTY:
|
||||
dd = self.pipeline.encode(i)
|
||||
if len(dd) == 1:
|
||||
self.AVOID_PENALTY_TOKENS.add(dd[0])
|
||||
|
||||
self.__preload()
|
||||
|
||||
def adjust_occurrence(self, occurrence: Dict, token: int):
|
||||
for xxx in occurrence:
|
||||
occurrence[xxx] *= self.penalty_decay
|
||||
if token not in occurrence:
|
||||
occurrence[token] = 1
|
||||
else:
|
||||
occurrence[token] += 1
|
||||
|
||||
def adjust_forward_logits(self, logits: List[float], occurrence: Dict, i: int):
|
||||
for n in occurrence:
|
||||
# if n not in self.AVOID_PENALTY_TOKENS:
|
||||
logits[n] -= (
|
||||
self.penalty_alpha_presence
|
||||
+ occurrence[n] * self.penalty_alpha_frequency
|
||||
)
|
||||
|
||||
# set global_penalty to False to get the same generated results as the official RWKV Gradio
|
||||
if self.global_penalty and i == 0:
|
||||
for token in self.model_tokens:
|
||||
token = int(token)
|
||||
if token not in self.AVOID_PENALTY_TOKENS:
|
||||
self.adjust_occurrence(occurrence, token)
|
||||
|
||||
# Model only saw '\n\n' as [187, 187] before, but the tokenizer outputs [535] for it at the end
|
||||
def fix_tokens(self, tokens) -> List[int]:
|
||||
if self.rwkv_type == RWKVType.World:
|
||||
return tokens
|
||||
if len(tokens) > 0 and tokens[-1] == 535:
|
||||
tokens = tokens[:-1] + [self.END_OF_LINE, self.END_OF_LINE]
|
||||
return tokens
|
||||
|
||||
def run_rnn(
|
||||
self, _tokens: List[str], newline_adj: int = 0
|
||||
) -> Tuple[List[float], int]:
|
||||
tokens = [int(x) for x in _tokens]
|
||||
token_len = len(tokens)
|
||||
self.model_tokens += tokens
|
||||
|
||||
while len(tokens) > 0:
|
||||
out, self.model_state = self.model.forward(
|
||||
tokens[: self.CHUNK_LEN], self.model_state
|
||||
)
|
||||
tokens = tokens[self.CHUNK_LEN :]
|
||||
|
||||
out[self.END_OF_LINE] += newline_adj # adjust \n probability
|
||||
|
||||
if self.model_tokens[-1] in self.AVOID_REPEAT_TOKENS:
|
||||
out[self.model_tokens[-1]] = -999999999
|
||||
return out, token_len
|
||||
|
||||
def delta_postprocess(self, delta: str) -> str:
|
||||
return delta
|
||||
|
||||
def __preload(self):
|
||||
interface = self.interface
|
||||
user = self.user
|
||||
bot = self.bot
|
||||
preset_system = (
|
||||
f"""
|
||||
The following is a coherent verbose detailed conversation between a girl named {bot} and her friend {user}. \
|
||||
{bot} is very intelligent, creative and friendly. \
|
||||
{bot} is unlikely to disagree with {user}, and {bot} doesn't like to ask {user} questions. \
|
||||
{bot} likes to tell {user} a lot about herself and her opinions. \
|
||||
{bot} usually gives {user} kind, helpful and informative advices.\n
|
||||
"""
|
||||
if self.rwkv_type == RWKVType.Raven
|
||||
else (
|
||||
f"{user}{interface} hi\n\n{bot}{interface} Hi. "
|
||||
+ "I am your assistant and I will provide expert full response in full details. Please feel free to ask any question and I will always answer it.\n\n"
|
||||
)
|
||||
)
|
||||
logits, _ = self.run_rnn(self.fix_tokens(self.pipeline.encode(preset_system)))
|
||||
try:
|
||||
state_cache.add_state(
|
||||
state_cache.AddStateBody(
|
||||
prompt=preset_system,
|
||||
tokens=self.model_tokens,
|
||||
state=self.model_state,
|
||||
logits=logits,
|
||||
)
|
||||
)
|
||||
except HTTPException:
|
||||
pass
|
||||
|
||||
|
||||
class MusicMidiRWKV(AbstractRWKV):
|
||||
def __init__(self, model, pipeline):
|
||||
super().__init__(model, pipeline)
|
||||
|
||||
self.max_tokens_per_generation = 500
|
||||
self.temperature = 1
|
||||
self.top_p = 0.8
|
||||
self.top_k = 8
|
||||
|
||||
self.rwkv_type = RWKVType.Music
|
||||
|
||||
def adjust_occurrence(self, occurrence: Dict, token: int):
|
||||
for n in occurrence:
|
||||
occurrence[n] *= 0.997 #### decay repetition penalty
|
||||
if token >= 128 or token == 127:
|
||||
occurrence[token] = 1 + (occurrence[token] if token in occurrence else 0)
|
||||
else:
|
||||
occurrence[token] = 0.3 + (occurrence[token] if token in occurrence else 0)
|
||||
|
||||
def adjust_forward_logits(self, logits: List[float], occurrence: Dict, i: int):
|
||||
for n in occurrence:
|
||||
logits[n] -= 0 + occurrence[n] * 0.5
|
||||
|
||||
logits[0] += (i - 2000) / 500 # try not to be too short or too long
|
||||
logits[127] -= 1 # avoid "t125"
|
||||
|
||||
def fix_tokens(self, tokens) -> List[int]:
|
||||
return tokens
|
||||
|
||||
def run_rnn(
|
||||
self, _tokens: List[str], newline_adj: int = 0
|
||||
) -> Tuple[List[float], int]:
|
||||
tokens = [int(x) for x in _tokens]
|
||||
token_len = len(tokens)
|
||||
self.model_tokens += tokens
|
||||
out, self.model_state = self.model.forward(tokens, self.model_state)
|
||||
return out, token_len
|
||||
|
||||
def delta_postprocess(self, delta: str) -> str:
|
||||
return " " + delta
|
||||
|
||||
|
||||
class MusicAbcRWKV(AbstractRWKV):
|
||||
def __init__(self, model, pipeline):
|
||||
super().__init__(model, pipeline)
|
||||
|
||||
self.EOS_ID = 3
|
||||
|
||||
self.max_tokens_per_generation = 500
|
||||
self.temperature = 1
|
||||
self.top_p = 0.8
|
||||
self.top_k = 8
|
||||
|
||||
self.rwkv_type = RWKVType.Music
|
||||
|
||||
def adjust_occurrence(self, occurrence: Dict, token: int):
|
||||
pass
|
||||
|
||||
def adjust_forward_logits(self, logits: List[float], occurrence: Dict, i: int):
|
||||
pass
|
||||
|
||||
def fix_tokens(self, tokens) -> List[int]:
|
||||
return tokens
|
||||
|
||||
def run_rnn(
|
||||
self, _tokens: List[str], newline_adj: int = 0
|
||||
) -> Tuple[List[float], int]:
|
||||
tokens = [int(x) for x in _tokens]
|
||||
token_len = len(tokens)
|
||||
self.model_tokens += tokens
|
||||
out, self.model_state = self.model.forward(tokens, self.model_state)
|
||||
return out, token_len
|
||||
|
||||
def delta_postprocess(self, delta: str) -> str:
|
||||
return delta
|
||||
|
||||
|
||||
def get_tokenizer(tokenizer_len: int):
|
||||
tokenizer_dir = f"{pathlib.Path(__file__).parent.parent.resolve()}/rwkv_pip/"
|
||||
if tokenizer_len < 2176:
|
||||
return "abc_tokenizer"
|
||||
if tokenizer_len < 20096:
|
||||
return tokenizer_dir + "tokenizer-midipiano.json"
|
||||
if tokenizer_len < 50277:
|
||||
return tokenizer_dir + "tokenizer-midi.json"
|
||||
elif tokenizer_len < 65536:
|
||||
return tokenizer_dir + "20B_tokenizer.json"
|
||||
else:
|
||||
return "rwkv_vocab_v20230424"
|
||||
|
||||
|
||||
def get_model_path(model_path: str) -> str:
|
||||
if os.path.isabs(model_path):
|
||||
return model_path
|
||||
|
||||
working_dir: pathlib.Path = pathlib.Path(os.path.abspath(os.getcwd()))
|
||||
|
||||
parent_paths: List[pathlib.Path] = [
|
||||
working_dir, # [cwd](RWKV-Runner)/models/xxx
|
||||
working_dir.parent, # [cwd](backend-python)/../models/xxx
|
||||
pathlib.Path(
|
||||
os.path.abspath(__file__)
|
||||
).parent.parent, # backend-python/models/xxx
|
||||
pathlib.Path(
|
||||
os.path.abspath(__file__)
|
||||
).parent.parent.parent, # RWKV-Runner/models/xxx
|
||||
]
|
||||
|
||||
child_paths: List[Callable[[pathlib.Path], pathlib.Path]] = [
|
||||
lambda p: p / model_path,
|
||||
lambda p: p / "build" / "bin" / model_path, # for dev
|
||||
]
|
||||
|
||||
for parent_path in parent_paths:
|
||||
for child_path in child_paths:
|
||||
full_path: pathlib.Path = child_path(parent_path)
|
||||
|
||||
if os.path.isfile(full_path):
|
||||
return str(full_path)
|
||||
|
||||
return model_path
|
||||
|
||||
|
||||
def RWKV(model: str, strategy: str, tokenizer: Union[str, None]) -> AbstractRWKV:
|
||||
model_path = get_model_path(model)
|
||||
|
||||
rwkv_cpp = getattr(global_var.get(global_var.Args), "rwkv.cpp")
|
||||
webgpu = global_var.get(global_var.Args).webgpu
|
||||
|
||||
if "midi" in model_path.lower() or "abc" in model_path.lower():
|
||||
os.environ["RWKV_RESCALE_LAYER"] = "999"
|
||||
|
||||
# dynamic import to make RWKV_CUDA_ON work
|
||||
if rwkv_cpp:
|
||||
print("Using rwkv.cpp, strategy is ignored")
|
||||
from rwkv_pip.cpp.model import (
|
||||
RWKV as Model,
|
||||
)
|
||||
elif webgpu:
|
||||
print("Using webgpu")
|
||||
from rwkv_pip.webgpu.model import (
|
||||
RWKV as Model,
|
||||
)
|
||||
else:
|
||||
from rwkv_pip.model import (
|
||||
RWKV as Model,
|
||||
)
|
||||
from rwkv_pip.utils import PIPELINE
|
||||
|
||||
filename, _ = os.path.splitext(os.path.basename(model_path))
|
||||
model = Model(model_path, strategy)
|
||||
if not tokenizer:
|
||||
tokenizer = get_tokenizer(len(model.w["emb.weight"]))
|
||||
pipeline = PIPELINE(model, tokenizer)
|
||||
|
||||
rwkv_map: dict[str, Type[AbstractRWKV]] = {
|
||||
"20B_tokenizer": TextRWKV,
|
||||
"rwkv_vocab_v20230424": TextRWKV,
|
||||
"tokenizer-midi": MusicMidiRWKV,
|
||||
"tokenizer-midipiano": MusicMidiRWKV,
|
||||
"abc_tokenizer": MusicAbcRWKV,
|
||||
}
|
||||
tokenizer_name = os.path.splitext(os.path.basename(tokenizer))[0]
|
||||
global_var.set(
|
||||
global_var.Midi_Vocab_Config_Type,
|
||||
(
|
||||
global_var.MidiVocabConfig.Piano
|
||||
if tokenizer_name == "tokenizer-midipiano"
|
||||
else global_var.MidiVocabConfig.Default
|
||||
),
|
||||
)
|
||||
rwkv: AbstractRWKV
|
||||
if tokenizer_name in rwkv_map:
|
||||
rwkv = rwkv_map[tokenizer_name](model, pipeline)
|
||||
else:
|
||||
tokenizer_name = tokenizer_name.lower()
|
||||
if "music" in tokenizer_name or "midi" in tokenizer_name:
|
||||
rwkv = MusicMidiRWKV(model, pipeline)
|
||||
elif "abc" in tokenizer_name:
|
||||
rwkv = MusicAbcRWKV(model, pipeline)
|
||||
else:
|
||||
rwkv = TextRWKV(model, pipeline)
|
||||
rwkv.name = filename
|
||||
rwkv.model_path = model_path
|
||||
rwkv.version = model.version
|
||||
|
||||
return rwkv
|
||||
from typing import Dict
|
||||
from langchain.llms import RWKV
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
class ModelConfigBody(BaseModel):
|
||||
max_tokens: int = Field(default=None, gt=0, le=102400)
|
||||
temperature: float = Field(default=None, ge=0, le=3)
|
||||
top_p: float = Field(default=None, ge=0, le=1)
|
||||
presence_penalty: float = Field(default=None, ge=-2, le=2)
|
||||
frequency_penalty: float = Field(default=None, ge=-2, le=2)
|
||||
penalty_decay: float = Field(default=None, ge=0.99, le=0.999)
|
||||
top_k: int = Field(default=None, ge=0, le=25)
|
||||
global_penalty: bool = Field(
|
||||
default=None,
|
||||
description="When generating a response, whether to include the submitted prompt as a penalty factor. By turning this off, you will get the same generated results as official RWKV Gradio. If you find duplicate results in the generated results, turning this on can help avoid generating duplicates.",
|
||||
)
|
||||
state: str = Field(default=None, description="state-tuned file path")
|
||||
|
||||
model_config = {
|
||||
"json_schema_extra": {
|
||||
"example": {
|
||||
"max_tokens": 1000,
|
||||
"temperature": 1,
|
||||
"top_p": 0.3,
|
||||
"presence_penalty": 0,
|
||||
"frequency_penalty": 1,
|
||||
"penalty_decay": 0.996,
|
||||
"global_penalty": False,
|
||||
"state": "",
|
||||
}
|
||||
}
|
||||
}
|
||||
max_tokens: int = None
|
||||
temperature: float = None
|
||||
top_p: float = None
|
||||
presence_penalty: float = None
|
||||
frequency_penalty: float = None
|
||||
|
||||
|
||||
def load_rwkv_state(
|
||||
model: AbstractRWKV, state_path: str, print_log: bool = True
|
||||
) -> HTTPException:
|
||||
if model:
|
||||
if state_path:
|
||||
if model.model_path.endswith(".pth") and state_path.endswith(".pth"):
|
||||
import torch
|
||||
|
||||
state_path = get_model_path(state_path)
|
||||
if model.state_path == state_path:
|
||||
return
|
||||
|
||||
if not os.path.isfile(state_path):
|
||||
return HTTPException(
|
||||
status.HTTP_400_BAD_REQUEST, "state file not found"
|
||||
)
|
||||
|
||||
try:
|
||||
state_raw = torch.load(state_path, map_location="cpu")
|
||||
except Exception as e:
|
||||
print(e)
|
||||
return HTTPException(
|
||||
status.HTTP_400_BAD_REQUEST, "state file failed to load"
|
||||
)
|
||||
state_raw_shape = next(iter(state_raw.values())).shape
|
||||
|
||||
args = model.model.args
|
||||
if (
|
||||
len(state_raw) != args.n_layer
|
||||
or state_raw_shape[0] * state_raw_shape[1] != args.n_embd
|
||||
):
|
||||
if model.state_path:
|
||||
pass
|
||||
elif print_log:
|
||||
print("state failed to load")
|
||||
return HTTPException(
|
||||
status.HTTP_400_BAD_REQUEST, "state shape mismatch"
|
||||
)
|
||||
|
||||
strategy = model.model.strategy
|
||||
model.state_tuned = [None] * args.n_layer * 3
|
||||
|
||||
for i in range(args.n_layer):
|
||||
dd = strategy[i]
|
||||
dev = dd.device
|
||||
atype = dd.atype
|
||||
model.state_tuned[i * 3 + 0] = torch.zeros(
|
||||
args.n_embd, dtype=atype, requires_grad=False, device=dev
|
||||
).contiguous()
|
||||
model.state_tuned[i * 3 + 1] = (
|
||||
state_raw[f"blocks.{i}.att.time_state"]
|
||||
.transpose(1, 2)
|
||||
.to(dtype=torch.float, device=dev)
|
||||
.requires_grad_(False)
|
||||
.contiguous()
|
||||
)
|
||||
model.state_tuned[i * 3 + 2] = torch.zeros(
|
||||
args.n_embd, dtype=atype, requires_grad=False, device=dev
|
||||
).contiguous()
|
||||
|
||||
state_cache.force_reset_state()
|
||||
model.state_path = state_path
|
||||
if print_log:
|
||||
print("state loaded")
|
||||
else:
|
||||
if model.state_path:
|
||||
pass
|
||||
elif print_log:
|
||||
print("state failed to load")
|
||||
return HTTPException(
|
||||
status.HTTP_400_BAD_REQUEST,
|
||||
"file format of the model or state model not supported",
|
||||
)
|
||||
else:
|
||||
if state_path == "" and model.state_path != "":
|
||||
state_cache.force_reset_state()
|
||||
model.state_path = ""
|
||||
model.state_tuned = None # TODO cached
|
||||
if print_log:
|
||||
print("state unloaded")
|
||||
else:
|
||||
if print_log:
|
||||
print("state not loaded")
|
||||
|
||||
|
||||
def set_rwkv_config(model: AbstractRWKV, body: ModelConfigBody):
|
||||
if body.max_tokens is not None:
|
||||
def set_rwkv_config(model: RWKV, body: ModelConfigBody):
|
||||
if body.max_tokens:
|
||||
model.max_tokens_per_generation = body.max_tokens
|
||||
if body.temperature is not None:
|
||||
if body.temperature < 0.1:
|
||||
model.temperature = 0.1
|
||||
else:
|
||||
model.temperature = body.temperature
|
||||
if body.top_p is not None:
|
||||
if body.temperature:
|
||||
model.temperature = body.temperature
|
||||
if body.top_p:
|
||||
model.top_p = body.top_p
|
||||
if body.presence_penalty is not None:
|
||||
if body.presence_penalty:
|
||||
model.penalty_alpha_presence = body.presence_penalty
|
||||
if body.frequency_penalty is not None:
|
||||
if body.frequency_penalty:
|
||||
model.penalty_alpha_frequency = body.frequency_penalty
|
||||
if body.penalty_decay is not None:
|
||||
model.penalty_decay = body.penalty_decay
|
||||
if body.top_k is not None:
|
||||
model.top_k = body.top_k
|
||||
if body.global_penalty is not None:
|
||||
model.global_penalty = body.global_penalty
|
||||
if body.state is not None:
|
||||
load_rwkv_state(model, body.state, False)
|
||||
|
||||
|
||||
def get_rwkv_config(model: AbstractRWKV) -> ModelConfigBody:
|
||||
def get_rwkv_config(model: RWKV) -> ModelConfigBody:
|
||||
return ModelConfigBody(
|
||||
max_tokens=model.max_tokens_per_generation,
|
||||
temperature=model.temperature,
|
||||
top_p=model.top_p,
|
||||
presence_penalty=model.penalty_alpha_presence,
|
||||
frequency_penalty=model.penalty_alpha_frequency,
|
||||
penalty_decay=model.penalty_decay,
|
||||
top_k=model.top_k,
|
||||
global_penalty=model.global_penalty,
|
||||
state=model.state_path,
|
||||
)
|
||||
|
||||
|
||||
def rwkv_generate(model: RWKV, prompt: str, stop: str = None):
|
||||
model.model_state = None
|
||||
model.model_tokens = []
|
||||
logits = model.run_rnn(model.tokenizer.encode(prompt).ids)
|
||||
begin = len(model.model_tokens)
|
||||
out_last = begin
|
||||
|
||||
occurrence: Dict = {}
|
||||
|
||||
response = ""
|
||||
for i in range(model.max_tokens_per_generation):
|
||||
for n in occurrence:
|
||||
logits[n] -= (
|
||||
model.penalty_alpha_presence
|
||||
+ occurrence[n] * model.penalty_alpha_frequency
|
||||
)
|
||||
token = model.pipeline.sample_logits(
|
||||
logits, temperature=model.temperature, top_p=model.top_p
|
||||
)
|
||||
|
||||
END_OF_TEXT = 0
|
||||
if token == END_OF_TEXT:
|
||||
break
|
||||
if token not in occurrence:
|
||||
occurrence[token] = 1
|
||||
else:
|
||||
occurrence[token] += 1
|
||||
|
||||
logits = model.run_rnn([token])
|
||||
delta: str = model.tokenizer.decode(model.model_tokens[out_last:])
|
||||
if "\ufffd" not in delta: # avoid utf-8 display issues
|
||||
response += delta
|
||||
if stop is not None:
|
||||
if stop in response:
|
||||
response = response.split(stop)[0]
|
||||
yield response, ""
|
||||
break
|
||||
yield response, delta
|
||||
out_last = begin + i + 1
|
||||
if i >= model.max_tokens_per_generation - 100:
|
||||
break
|
||||
|
||||
@ -19,12 +19,9 @@ def set_torch():
|
||||
|
||||
|
||||
def torch_gc():
|
||||
try:
|
||||
import torch
|
||||
import torch
|
||||
|
||||
if torch.cuda.is_available():
|
||||
with torch.cuda.device(0):
|
||||
torch.cuda.empty_cache()
|
||||
torch.cuda.ipc_collect()
|
||||
except:
|
||||
pass # prevent 'torch' has no attribute 'cuda' error, so user can use CPU or WebGPU
|
||||
if torch.cuda.is_available():
|
||||
with torch.cuda.device(0):
|
||||
torch.cuda.empty_cache()
|
||||
torch.cuda.ipc_collect()
|
||||
|
||||
@ -1,279 +0,0 @@
|
||||
{
|
||||
"note_events": 128,
|
||||
"wait_events": 125,
|
||||
"max_wait_time": 1000,
|
||||
"velocity_events": 128,
|
||||
"velocity_bins": 16,
|
||||
"velocity_exp": 0.33,
|
||||
"do_token_sorting": true,
|
||||
"unrolled_tokens": false,
|
||||
"decode_end_held_note_delay": 5.0,
|
||||
"decode_fix_repeated_notes": true,
|
||||
"bin_instrument_names": [
|
||||
"piano"
|
||||
],
|
||||
"ch10_instrument_bin_name": "",
|
||||
"program_name_to_bin_name": {
|
||||
"Acoustic Grand Piano": "piano",
|
||||
"Bright Acoustic Piano": "piano",
|
||||
"Electric Grand Piano": "piano",
|
||||
"Honky-tonk Piano": "piano",
|
||||
"Electric Piano 1 (Rhodes Piano)": "piano",
|
||||
"Electric Piano 2 (Chorused Piano)": "piano",
|
||||
"Harpsichord": "piano",
|
||||
"Clavinet": "piano",
|
||||
"Celesta": "",
|
||||
"Glockenspiel": "",
|
||||
"Music Box": "",
|
||||
"Vibraphone": "",
|
||||
"Marimba": "",
|
||||
"Xylophone": "",
|
||||
"Tubular Bells": "",
|
||||
"Dulcimer (Santur)": "",
|
||||
"Drawbar Organ (Hammond)": "",
|
||||
"Percussive Organ": "piano",
|
||||
"Rock Organ": "piano",
|
||||
"Church Organ": "piano",
|
||||
"Reed Organ": "piano",
|
||||
"Accordion (French)": "piano",
|
||||
"Harmonica": "piano",
|
||||
"Tango Accordion (Band neon)": "piano",
|
||||
"Acoustic Guitar (nylon)": "",
|
||||
"Acoustic Guitar (steel)": "",
|
||||
"Electric Guitar (jazz)": "",
|
||||
"Electric Guitar (clean)": "",
|
||||
"Electric Guitar (muted)": "",
|
||||
"Overdriven Guitar": "",
|
||||
"Distortion Guitar": "",
|
||||
"Guitar harmonics": "",
|
||||
"Acoustic Bass": "",
|
||||
"Electric Bass (fingered)": "",
|
||||
"Electric Bass (picked)": "",
|
||||
"Fretless Bass": "",
|
||||
"Slap Bass 1": "",
|
||||
"Slap Bass 2": "",
|
||||
"Synth Bass 1": "",
|
||||
"Synth Bass 2": "",
|
||||
"Violin": "",
|
||||
"Viola": "",
|
||||
"Cello": "",
|
||||
"Contrabass": "",
|
||||
"Tremolo Strings": "",
|
||||
"Pizzicato Strings": "",
|
||||
"Orchestral Harp": "",
|
||||
"Timpani": "",
|
||||
"String Ensemble 1 (strings)": "",
|
||||
"String Ensemble 2 (slow strings)": "",
|
||||
"SynthStrings 1": "",
|
||||
"SynthStrings 2": "",
|
||||
"Choir Aahs": "",
|
||||
"Voice Oohs": "",
|
||||
"Synth Voice": "",
|
||||
"Orchestra Hit": "",
|
||||
"Trumpet": "",
|
||||
"Trombone": "",
|
||||
"Tuba": "",
|
||||
"Muted Trumpet": "",
|
||||
"French Horn": "",
|
||||
"Brass Section": "",
|
||||
"SynthBrass 1": "",
|
||||
"SynthBrass 2": "",
|
||||
"Soprano Sax": "",
|
||||
"Alto Sax": "",
|
||||
"Tenor Sax": "",
|
||||
"Baritone Sax": "",
|
||||
"Oboe": "",
|
||||
"English Horn": "",
|
||||
"Bassoon": "",
|
||||
"Clarinet": "",
|
||||
"Piccolo": "",
|
||||
"Flute": "",
|
||||
"Recorder": "",
|
||||
"Pan Flute": "",
|
||||
"Blown Bottle": "",
|
||||
"Shakuhachi": "",
|
||||
"Whistle": "",
|
||||
"Ocarina": "",
|
||||
"Lead 1 (square wave)": "",
|
||||
"Lead 2 (sawtooth wave)": "",
|
||||
"Lead 3 (calliope)": "",
|
||||
"Lead 4 (chiffer)": "",
|
||||
"Lead 5 (charang)": "",
|
||||
"Lead 6 (voice solo)": "",
|
||||
"Lead 7 (fifths)": "",
|
||||
"Lead 8 (bass + lead)": "",
|
||||
"Pad 1 (new age Fantasia)": "",
|
||||
"Pad 2 (warm)": "",
|
||||
"Pad 3 (polysynth)": "",
|
||||
"Pad 4 (choir space voice)": "",
|
||||
"Pad 5 (bowed glass)": "",
|
||||
"Pad 6 (metallic pro)": "",
|
||||
"Pad 7 (halo)": "",
|
||||
"Pad 8 (sweep)": "",
|
||||
"FX 1 (rain)": "",
|
||||
"FX 2 (soundtrack)": "",
|
||||
"FX 3 (crystal)": "",
|
||||
"FX 4 (atmosphere)": "",
|
||||
"FX 5 (brightness)": "",
|
||||
"FX 6 (goblins)": "",
|
||||
"FX 7 (echoes, drops)": "",
|
||||
"FX 8 (sci-fi, star theme)": "",
|
||||
"Sitar": "",
|
||||
"Banjo": "",
|
||||
"Shamisen": "",
|
||||
"Koto": "",
|
||||
"Kalimba": "",
|
||||
"Bag pipe": "",
|
||||
"Fiddle": "",
|
||||
"Shanai": "",
|
||||
"Tinkle Bell": "",
|
||||
"Agogo": "",
|
||||
"Steel Drums": "",
|
||||
"Woodblock": "",
|
||||
"Taiko Drum": "",
|
||||
"Melodic Tom": "",
|
||||
"Synth Drum": "",
|
||||
"Reverse Cymbal": "",
|
||||
"Guitar Fret Noise": "",
|
||||
"Breath Noise": "",
|
||||
"Seashore": "",
|
||||
"Bird Tweet": "",
|
||||
"Telephone Ring": "",
|
||||
"Helicopter": "",
|
||||
"Applause": "",
|
||||
"Gunshot": ""
|
||||
},
|
||||
"bin_name_to_program_name": {
|
||||
"piano": "Acoustic Grand Piano"
|
||||
},
|
||||
"instrument_names": {
|
||||
"0": "Acoustic Grand Piano",
|
||||
"1": "Bright Acoustic Piano",
|
||||
"2": "Electric Grand Piano",
|
||||
"3": "Honky-tonk Piano",
|
||||
"4": "Electric Piano 1 (Rhodes Piano)",
|
||||
"5": "Electric Piano 2 (Chorused Piano)",
|
||||
"6": "Harpsichord",
|
||||
"7": "Clavinet",
|
||||
"8": "Celesta",
|
||||
"9": "Glockenspiel",
|
||||
"10": "Music Box",
|
||||
"11": "Vibraphone",
|
||||
"12": "Marimba",
|
||||
"13": "Xylophone",
|
||||
"14": "Tubular Bells",
|
||||
"15": "Dulcimer (Santur)",
|
||||
"16": "Drawbar Organ (Hammond)",
|
||||
"17": "Percussive Organ",
|
||||
"18": "Rock Organ",
|
||||
"19": "Church Organ",
|
||||
"20": "Reed Organ",
|
||||
"21": "Accordion (French)",
|
||||
"22": "Harmonica",
|
||||
"23": "Tango Accordion (Band neon)",
|
||||
"24": "Acoustic Guitar (nylon)",
|
||||
"25": "Acoustic Guitar (steel)",
|
||||
"26": "Electric Guitar (jazz)",
|
||||
"27": "Electric Guitar (clean)",
|
||||
"28": "Electric Guitar (muted)",
|
||||
"29": "Overdriven Guitar",
|
||||
"30": "Distortion Guitar",
|
||||
"31": "Guitar harmonics",
|
||||
"32": "Acoustic Bass",
|
||||
"33": "Electric Bass (fingered)",
|
||||
"34": "Electric Bass (picked)",
|
||||
"35": "Fretless Bass",
|
||||
"36": "Slap Bass 1",
|
||||
"37": "Slap Bass 2",
|
||||
"38": "Synth Bass 1",
|
||||
"39": "Synth Bass 2",
|
||||
"40": "Violin",
|
||||
"41": "Viola",
|
||||
"42": "Cello",
|
||||
"43": "Contrabass",
|
||||
"44": "Tremolo Strings",
|
||||
"45": "Pizzicato Strings",
|
||||
"46": "Orchestral Harp",
|
||||
"47": "Timpani",
|
||||
"48": "String Ensemble 1 (strings)",
|
||||
"49": "String Ensemble 2 (slow strings)",
|
||||
"50": "SynthStrings 1",
|
||||
"51": "SynthStrings 2",
|
||||
"52": "Choir Aahs",
|
||||
"53": "Voice Oohs",
|
||||
"54": "Synth Voice",
|
||||
"55": "Orchestra Hit",
|
||||
"56": "Trumpet",
|
||||
"57": "Trombone",
|
||||
"58": "Tuba",
|
||||
"59": "Muted Trumpet",
|
||||
"60": "French Horn",
|
||||
"61": "Brass Section",
|
||||
"62": "SynthBrass 1",
|
||||
"63": "SynthBrass 2",
|
||||
"64": "Soprano Sax",
|
||||
"65": "Alto Sax",
|
||||
"66": "Tenor Sax",
|
||||
"67": "Baritone Sax",
|
||||
"68": "Oboe",
|
||||
"69": "English Horn",
|
||||
"70": "Bassoon",
|
||||
"71": "Clarinet",
|
||||
"72": "Piccolo",
|
||||
"73": "Flute",
|
||||
"74": "Recorder",
|
||||
"75": "Pan Flute",
|
||||
"76": "Blown Bottle",
|
||||
"77": "Shakuhachi",
|
||||
"78": "Whistle",
|
||||
"79": "Ocarina",
|
||||
"80": "Lead 1 (square wave)",
|
||||
"81": "Lead 2 (sawtooth wave)",
|
||||
"82": "Lead 3 (calliope)",
|
||||
"83": "Lead 4 (chiffer)",
|
||||
"84": "Lead 5 (charang)",
|
||||
"85": "Lead 6 (voice solo)",
|
||||
"86": "Lead 7 (fifths)",
|
||||
"87": "Lead 8 (bass + lead)",
|
||||
"88": "Pad 1 (new age Fantasia)",
|
||||
"89": "Pad 2 (warm)",
|
||||
"90": "Pad 3 (polysynth)",
|
||||
"91": "Pad 4 (choir space voice)",
|
||||
"92": "Pad 5 (bowed glass)",
|
||||
"93": "Pad 6 (metallic pro)",
|
||||
"94": "Pad 7 (halo)",
|
||||
"95": "Pad 8 (sweep)",
|
||||
"96": "FX 1 (rain)",
|
||||
"97": "FX 2 (soundtrack)",
|
||||
"98": "FX 3 (crystal)",
|
||||
"99": "FX 4 (atmosphere)",
|
||||
"100": "FX 5 (brightness)",
|
||||
"101": "FX 6 (goblins)",
|
||||
"102": "FX 7 (echoes, drops)",
|
||||
"103": "FX 8 (sci-fi, star theme)",
|
||||
"104": "Sitar",
|
||||
"105": "Banjo",
|
||||
"106": "Shamisen",
|
||||
"107": "Koto",
|
||||
"108": "Kalimba",
|
||||
"109": "Bag pipe",
|
||||
"110": "Fiddle",
|
||||
"111": "Shanai",
|
||||
"112": "Tinkle Bell",
|
||||
"113": "Agogo",
|
||||
"114": "Steel Drums",
|
||||
"115": "Woodblock",
|
||||
"116": "Taiko Drum",
|
||||
"117": "Melodic Tom",
|
||||
"118": "Synth Drum",
|
||||
"119": "Reverse Cymbal",
|
||||
"120": "Guitar Fret Noise",
|
||||
"121": "Breath Noise",
|
||||
"122": "Seashore",
|
||||
"123": "Bird Tweet",
|
||||
"124": "Telephone Ring",
|
||||
"125": "Helicopter",
|
||||
"126": "Applause",
|
||||
"127": "Gunshot"
|
||||
}
|
||||
}
|
||||
@ -1,14 +0,0 @@
|
||||
from fastapi import FastAPI
|
||||
from fastapi.middleware.gzip import GZipMiddleware
|
||||
from fastapi.staticfiles import StaticFiles
|
||||
import uvicorn
|
||||
|
||||
webui_server = FastAPI()
|
||||
|
||||
webui_server.add_middleware(GZipMiddleware, minimum_size=1000)
|
||||
webui_server.mount(
|
||||
"/", StaticFiles(directory="frontend/dist", html=True), name="static"
|
||||
)
|
||||
|
||||
if __name__ == "__main__":
|
||||
uvicorn.run("webui_server:webui_server")
|
||||
File diff suppressed because it is too large
Load Diff
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 83 KiB After Width: | Height: | Size: 102 KiB |
@ -8,7 +8,7 @@
|
||||
<key>CFBundleExecutable</key>
|
||||
<string>{{.Name}}</string>
|
||||
<key>CFBundleIdentifier</key>
|
||||
<string>dev.josStorer.RWKV-Runner</string>
|
||||
<string>com.wails.{{.Name}}</string>
|
||||
<key>CFBundleVersion</key>
|
||||
<string>{{.Info.ProductVersion}}</string>
|
||||
<key>CFBundleGetInfoString</key>
|
||||
|
||||
@ -8,7 +8,7 @@
|
||||
<key>CFBundleExecutable</key>
|
||||
<string>{{.Name}}</string>
|
||||
<key>CFBundleIdentifier</key>
|
||||
<string>dev.josStorer.RWKV-Runner</string>
|
||||
<string>com.wails.{{.Name}}</string>
|
||||
<key>CFBundleVersion</key>
|
||||
<string>{{.Info.ProductVersion}}</string>
|
||||
<key>CFBundleGetInfoString</key>
|
||||
|
||||
@ -1,18 +0,0 @@
|
||||
Client Download URL:
|
||||
客户端下载地址:
|
||||
クライアントのダウンロードURL:
|
||||
https://github.com/josStorer/RWKV-Runner/releases/latest/download/RWKV-Runner_macos_universal.zip
|
||||
|
||||
For Mac and Linux users, please manually install Python 3.10 (usually the latest systems come with it built-in). You can specify the Python interpreter to use in Settings. (which python3)
|
||||
对于Mac和Linux用户,请手动安装 Python3.10 (通常最新的系统已经内置了). 你可以在设置中指定使用的Python解释器. (which python3)
|
||||
MacおよびLinuxのユーザーの方は、Python3.10を手動でインストールしてください(通常、最新のシステムには既に組み込まれています)。 設定メニューで使用するPythonインタプリタを指定することができます。 (which python3)
|
||||
|
||||
Please execute this program in an empty directory. All related dependencies will be placed in this directory.
|
||||
请将本程序放在一个空目录内执行, 所有相关依赖均会放置于此目录.
|
||||
このプログラムを空のディレクトリで実行してください。関連するすべての依存関係は、このディレクトリに配置されます。
|
||||
|
||||
Please execute the following command in the terminal to remove the permission restrictions of this app, and then this program can work properly:
|
||||
请在终端执行以下命令解除本app的权限限制, 然后本程序才可以正常工作:
|
||||
このアプリの権限制限を解除するために、ターミナルで以下のコマンドを実行してください。その後、このプログラムは正常に動作するようになります:
|
||||
|
||||
sudo xattr -r -d com.apple.quarantine ./RWKV-Runner.app
|
||||
@ -1,16 +0,0 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
|
||||
<plist version="1.0">
|
||||
<dict>
|
||||
<key>com.apple.security.app-sandbox</key>
|
||||
<false/>
|
||||
<key>com.apple.security.network.client</key>
|
||||
<true/>
|
||||
<key>com.apple.security.network.server</key>
|
||||
<true/>
|
||||
<key>com.apple.security.files.user-selected.read-write</key>
|
||||
<true/>
|
||||
<key>com.apple.security.files.downloads.read-write</key>
|
||||
<true/>
|
||||
</dict>
|
||||
</plist>
|
||||
@ -1,17 +0,0 @@
|
||||
{
|
||||
"source": [
|
||||
"./build/bin/RWKV-Runner_darwin.app"
|
||||
],
|
||||
"bundle_id": "dev.josStorer.RWKV-Runner",
|
||||
"apple_id": {
|
||||
"username": "joshua1466587594@outlook.com",
|
||||
"password": ""
|
||||
},
|
||||
"sign": {
|
||||
"application_identity": "D00A983569B4EAA2A008B963254F385F42A493FD",
|
||||
"entitlements_file": "./build/darwin/entitlements.plist"
|
||||
},
|
||||
"zip": {
|
||||
"output_path": "./build/bin/RWKV-Runner_darwin.archive.zip"
|
||||
}
|
||||
}
|
||||
@ -1,24 +0,0 @@
|
||||
Client Download URL:
|
||||
客户端下载地址:
|
||||
クライアントのダウンロードURL:
|
||||
https://github.com/josStorer/RWKV-Runner/releases/latest/download/RWKV-Runner_linux_x64
|
||||
|
||||
For Mac and Linux users, please manually install Python 3.10 (usually the latest systems come with it built-in). You can specify the Python interpreter to use in Settings.
|
||||
对于Mac和Linux用户,请手动安装 Python3.10 (通常最新的系统已经内置了). 你可以在设置中指定使用的Python解释器.
|
||||
MacおよびLinuxのユーザーの方は、Python3.10を手動でインストールしてください(通常、最新のシステムには既に組み込まれています)。 設定メニューで使用するPythonインタプリタを指定することができます。
|
||||
|
||||
Please execute this program in an empty directory. All related dependencies will be placed in this directory.
|
||||
请将本程序放在一个空目录内执行, 所有相关依赖均会放置于此目录.
|
||||
このプログラムを空のディレクトリで実行してください。関連するすべての依存関係は、このディレクトリに配置されます。
|
||||
|
||||
On Linux system, this program cannot invoke the terminal for automatic dependency installation. You must manually execute the following commands for installation so that it can be used normally:
|
||||
在Linux系统下, 本程序无法调用终端自动安装依赖, 你必须手动执行以下命令进行安装, 之后方可正常使用:
|
||||
Linuxシステムでは、このプログラムはターミナルを自動的に呼び出して依存関係をインストールすることができません。以下のコマンドを手動で実行する必要があります。それが完了した後に、正常に使用することができます:
|
||||
|
||||
sudo apt install python3-dev
|
||||
chmod +x ./RWKV-Runner
|
||||
./RWKV-Runner
|
||||
cd backend-python
|
||||
pip3 install -r requirements.txt # or pip3 install -r requirements_without_cyac.txt
|
||||
|
||||
# See More: https://github.com/josStorer/RWKV-Runner/tree/master/deploy-examples
|
||||
@ -1,8 +0,0 @@
|
||||
Client Download URL:
|
||||
客户端下载地址:
|
||||
クライアントのダウンロードURL:
|
||||
https://github.com/josStorer/RWKV-Runner/releases/latest/download/RWKV-Runner_windows_x64.exe
|
||||
|
||||
Please execute this program in an empty directory. All related dependencies will be placed in this directory.
|
||||
请将本程序放在一个空目录内执行, 所有相关依赖均会放置于此目录.
|
||||
このプログラムを空のディレクトリで実行してください。関連するすべての依存関係は、このディレクトリに配置されます。
|
||||
Binary file not shown.
|
Before Width: | Height: | Size: 175 KiB After Width: | Height: | Size: 147 KiB |
@ -1,24 +0,0 @@
|
||||
: install git python3.10 yarn by yourself
|
||||
: change model and strategy according to your hardware
|
||||
|
||||
mkdir RWKV-Next-Web
|
||||
cd RWKV-Next-Web
|
||||
|
||||
git clone https://github.com/josStorer/RWKV-Runner --depth=1
|
||||
python -m pip install torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 --index-url https://download.pytorch.org/whl/cu117
|
||||
python -m pip install -r RWKV-Runner/backend-python/requirements.txt
|
||||
start python ./RWKV-Runner/backend-python/main.py
|
||||
|
||||
powershell -Command "(Test-Path ./RWKV-Runner/models) -or (mkdir RWKV-Runner/models)"
|
||||
powershell -Command "Import-Module BitsTransfer"
|
||||
powershell -Command "(Test-Path ./RWKV-Runner/models/RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth) -or (Start-BitsTransfer https://huggingface.co/BlinkDL/rwkv-4-world/resolve/main/RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth ./RWKV-Runner/models/RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth)"
|
||||
powershell -Command "Invoke-WebRequest http://127.0.0.1:8000/switch-model -Method POST -ContentType 'application/json' -Body '{\"model\":\"./RWKV-Runner/models/RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth\",\"strategy\":\"cuda fp32 *20+\"}'"
|
||||
|
||||
git clone https://github.com/Yidadaa/ChatGPT-Next-Web --depth=1
|
||||
cd ChatGPT-Next-Web
|
||||
call yarn install
|
||||
call yarn build
|
||||
set PROXY_URL=""
|
||||
set BASE_URL=http://127.0.0.1:8000
|
||||
start "C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" "http://127.0.0.1:3000"
|
||||
yarn start
|
||||
@ -1,27 +0,0 @@
|
||||
# install git python3.10 yarn by yourself
|
||||
# change model and strategy according to your hardware
|
||||
|
||||
sudo apt install python3-dev
|
||||
|
||||
mkdir RWKV-Next-Web
|
||||
cd RWKV-Next-Web
|
||||
|
||||
git clone https://github.com/josStorer/RWKV-Runner --depth=1
|
||||
python3 -m pip install torch torchvision torchaudio
|
||||
python3 -m pip install -r RWKV-Runner/backend-python/requirements.txt
|
||||
python3 ./RWKV-Runner/backend-python/main.py > log.txt & # this is only an example, you should use screen or other tools to run it in background
|
||||
|
||||
if [ ! -d RWKV-Runner/models ]; then
|
||||
mkdir RWKV-Runner/models
|
||||
fi
|
||||
wget -N https://huggingface.co/BlinkDL/rwkv-4-world/resolve/main/RWKV-4-World-0.1B-v1-20230520-ctx4096.pth -P RWKV-Runner/models/
|
||||
|
||||
git clone https://github.com/Yidadaa/ChatGPT-Next-Web --depth=1
|
||||
cd ChatGPT-Next-Web
|
||||
yarn install
|
||||
yarn build
|
||||
export PROXY_URL=""
|
||||
export BASE_URL=http://127.0.0.1:8000
|
||||
yarn start & # this is only an example, you should use screen or other tools to run it in background
|
||||
|
||||
curl http://127.0.0.1:8000/switch-model -X POST -H "Content-Type: application/json" -d '{"model":"./RWKV-Runner/models/RWKV-4-World-0.1B-v1-20230520-ctx4096.pth","strategy":"cpu fp32"}'
|
||||
@ -1,19 +0,0 @@
|
||||
: install git python3.10 npm by yourself
|
||||
: change model and strategy according to your hardware
|
||||
|
||||
git clone https://github.com/josStorer/RWKV-Runner --depth=1
|
||||
python -m pip install torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 --index-url https://download.pytorch.org/whl/cu117
|
||||
python -m pip install -r RWKV-Runner/backend-python/requirements.txt
|
||||
cd RWKV-Runner/frontend
|
||||
call npm ci
|
||||
call npm run build
|
||||
cd ..
|
||||
|
||||
: optional: set ngrok_token=YOUR_NGROK_TOKEN
|
||||
start python ./backend-python/main.py --webui
|
||||
start "C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" "http://127.0.0.1:8000"
|
||||
|
||||
powershell -Command "(Test-Path ./models) -or (mkdir models)"
|
||||
powershell -Command "Import-Module BitsTransfer"
|
||||
powershell -Command "(Test-Path ./models/RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth) -or (Start-BitsTransfer https://huggingface.co/BlinkDL/rwkv-4-world/resolve/main/RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth ./models/RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth)"
|
||||
powershell -Command "Invoke-WebRequest http://127.0.0.1:8000/switch-model -Method POST -ContentType 'application/json' -Body '{\"model\":\"./models/RWKV-4-World-1.5B-v1-fixed-20230612-ctx4096.pth\",\"strategy\":\"cuda fp32 *20+\",\"deploy\":\"true\"}'"
|
||||
@ -1,22 +0,0 @@
|
||||
# install git python3.10 npm by yourself
|
||||
# change model and strategy according to your hardware
|
||||
|
||||
sudo apt install python3-dev
|
||||
|
||||
git clone https://github.com/josStorer/RWKV-Runner --depth=1
|
||||
python3 -m pip install torch torchvision torchaudio
|
||||
python3 -m pip install -r RWKV-Runner/backend-python/requirements.txt
|
||||
cd RWKV-Runner/frontend
|
||||
npm ci
|
||||
npm run build
|
||||
cd ..
|
||||
|
||||
# optional: export ngrok_token=YOUR_NGROK_TOKEN
|
||||
python3 ./backend-python/main.py --webui > log.txt & # this is only an example, you should use screen or other tools to run it in background
|
||||
|
||||
if [ ! -d models ]; then
|
||||
mkdir models
|
||||
fi
|
||||
wget -N https://huggingface.co/BlinkDL/rwkv-4-world/resolve/main/RWKV-4-World-0.1B-v1-20230520-ctx4096.pth -P models/
|
||||
|
||||
curl http://127.0.0.1:8000/switch-model -X POST -H "Content-Type: application/json" -d '{"model":"./models/RWKV-4-World-0.1B-v1-20230520-ctx4096.pth","strategy":"cpu fp32","deploy":"true"}'
|
||||
@ -1,18 +0,0 @@
|
||||
services:
|
||||
rmkv_runner:
|
||||
image: rwkv-runner:latest
|
||||
build: .
|
||||
# Append "--rwkv.cpp" parameter to use rwkv.cpp
|
||||
# command: python3.10 ./backend-python/main.py --port 27777 --host 0.0.0.0 --webui --rwkv.cpp
|
||||
volumes:
|
||||
- /mnt:/mnt
|
||||
ports:
|
||||
- "27777:27777"
|
||||
# Comment the following lines if use rwkv.cpp
|
||||
deploy:
|
||||
resources:
|
||||
reservations:
|
||||
devices:
|
||||
- driver: nvidia
|
||||
count: 1
|
||||
capabilities: [gpu]
|
||||
@ -19,15 +19,14 @@ document.querySelectorAll('.grid.h-10.grid-cols-12.place-content-center.gap-x-3.
|
||||
if (!data.name.endsWith('.bin') && !data.name.endsWith('.pth'))
|
||||
return
|
||||
|
||||
data.desc = { en: '', zh: '', ja: '' }
|
||||
data.desc = {en: '', zh: ''}
|
||||
const rawText = await (await fetch(e.children[1].href.replace('/resolve/', '/raw/'))).text()
|
||||
|
||||
data.size = parseInt(extractValue(rawText, 'size'))
|
||||
data.SHA256 = extractValue(rawText, 'oid sha256:')
|
||||
data.lastUpdated = e.children[3].children[0].getAttribute('datetime')
|
||||
data.url = e.children[1].href.replace('/resolve/', '/blob/').replace('?download=true', '')
|
||||
data.downloadUrl = e.children[1].href.replace('?download=true', '')
|
||||
data.tags = []
|
||||
data.url = e.children[1].href.replace('/resolve/', '/blob/')
|
||||
data.downloadUrl = e.children[1].href
|
||||
|
||||
modelsJson.push(data)
|
||||
})
|
||||
|
||||
@ -1,5 +0,0 @@
|
||||
{"text": "The following is an epic science fiction masterpiece that is immortalized, with delicate descriptions and grand depictions of interstellar civilization wars.\nChapter 1.\nAs I sit down to write here amidst the shadows of vine-leaves under the blue sky of southern Italy, it comes to me with a certain quality of astonishment that my participation in these amazing adventures of Mr. Cavor was, after all, the outcome of the purest accident. It might have been any one. I fell into these things at a time when I thought myself removed from the slightest possibility of disturbing experiences. I had gone to Lympne because I had imagined it the most uneventful place in the world. “Here, at any rate,” said I, “I shall find peace and a chance to work!”"}
|
||||
{"text": "Translate the following into Chinese.\n\nEnglish: What rooms do you have available?\nChinese: 你们有哪些房间可以提供"}
|
||||
{"text": "User: Hello.\n\nAssistant: I'm here, meow~.\n\nUser: Can you tell some jokes?\n\nAssistant: Of course, master. What kind of jokes would you like to hear?"}
|
||||
{"text": "Instruction: Write a story using the following information\n\nInput: A man named Alex chops a tree down\n\nResponse: Once upon a time, there was a man named Alex who lived in the heart of the forest. He had always been fascinated by trees and spent most of his days exploring the forest and learning about its many wonders. One day, while wandering through the woods, he stumbled upon an old oak tree that stood tall and proud in the middle of a clearing."}
|
||||
{"text": "def get_args(args: Union[Sequence[str], None] = None):\n parser = argparse.ArgumentParser()\n group = parser.add_argument_group(title=\"server arguments\")\n group.add_argument(\n \"--port\",\n type=int,\n default=8000,\n help=\"port to run the server on (default: 8000)\",\n )\n group.add_argument(\n \"--host\",\n type=str,\n default=\"127.0.0.1\",\n help=\"host to run the server on (default: 127.0.0.1)\",\n )"}
|
||||
@ -1,65 +0,0 @@
|
||||
import torch
|
||||
import sys
|
||||
import time
|
||||
import os
|
||||
import threading
|
||||
import gc
|
||||
|
||||
|
||||
def file_cleaner(file):
|
||||
last_pos = 0
|
||||
|
||||
def cleaner():
|
||||
nonlocal last_pos
|
||||
while True:
|
||||
time.sleep(0.1)
|
||||
pos = file.tell()
|
||||
if pos > last_pos:
|
||||
os.posix_fadvise(
|
||||
file.fileno(), last_pos, pos - last_pos, os.POSIX_FADV_DONTNEED
|
||||
)
|
||||
last_pos = pos
|
||||
|
||||
return cleaner
|
||||
|
||||
|
||||
expected_max_version = float(sys.argv[2]) if len(sys.argv) > 2 else 100
|
||||
model_file = open(sys.argv[1], "rb")
|
||||
cleaner = file_cleaner(model_file)
|
||||
cleaner_thread = threading.Thread(target=cleaner, daemon=True)
|
||||
cleaner_thread.start()
|
||||
|
||||
w = torch.load(model_file, map_location="cpu")
|
||||
gc.collect()
|
||||
|
||||
vocab_size = w["emb.weight"].shape[0]
|
||||
n_embd = w["emb.weight"].shape[1]
|
||||
n_layer = 0
|
||||
keys = list(w.keys())
|
||||
version = 4
|
||||
for x in keys:
|
||||
layer_id = int(x.split(".")[1]) if ("blocks." in x) else 0
|
||||
n_layer = max(n_layer, layer_id + 1)
|
||||
|
||||
if "ln_x" in x:
|
||||
version = max(5, version)
|
||||
if "gate.weight" in x:
|
||||
version = max(5.1, version)
|
||||
if int(version) == 5 and "att.time_decay" in x:
|
||||
if len(w[x].shape) > 1:
|
||||
if w[x].shape[1] > 1:
|
||||
version = max(5.2, version)
|
||||
if "time_maa" in x:
|
||||
version = max(6, version)
|
||||
|
||||
params = f"--vocab_size {vocab_size} --n_layer {n_layer} --n_embd {n_embd}"
|
||||
|
||||
if version <= expected_max_version:
|
||||
if version == 6:
|
||||
params += ' --my_testing "x060"'
|
||||
print(
|
||||
f"v{int(version)}/train.py {params}",
|
||||
end="",
|
||||
)
|
||||
else:
|
||||
raise Exception(f"RWKV{version} is not supported")
|
||||
@ -1,65 +0,0 @@
|
||||
echo $@
|
||||
|
||||
if [[ ${cnMirror} == 1 ]]; then
|
||||
export PIP_INDEX_URL="https://mirrors.aliyun.com/pypi/simple"
|
||||
if grep -q "mirrors.aliyun.com" /etc/apt/sources.list; then
|
||||
echo "apt cnMirror already set"
|
||||
else
|
||||
sudo sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list
|
||||
sudo apt update
|
||||
fi
|
||||
fi
|
||||
|
||||
if dpkg -s "gcc" >/dev/null 2>&1; then
|
||||
echo "gcc installed"
|
||||
else
|
||||
sudo apt -y install gcc
|
||||
fi
|
||||
|
||||
if dpkg -s "python3-pip" >/dev/null 2>&1; then
|
||||
echo "pip installed"
|
||||
else
|
||||
sudo apt -y install python3-pip
|
||||
fi
|
||||
|
||||
if dpkg -s "python3-dev" >/dev/null 2>&1; then
|
||||
echo "python3-dev installed"
|
||||
else
|
||||
sudo apt -y install python3-dev
|
||||
fi
|
||||
|
||||
if dpkg -s "ninja-build" >/dev/null 2>&1; then
|
||||
echo "ninja installed"
|
||||
else
|
||||
sudo apt -y install ninja-build
|
||||
fi
|
||||
|
||||
if dpkg -s "cuda" >/dev/null 2>&1 && dpkg -s "cuda" | grep Version | awk '{print $2}' | grep -q "12"; then
|
||||
echo "cuda 12 installed"
|
||||
else
|
||||
wget -N https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
|
||||
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
|
||||
wget -N https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda-repo-wsl-ubuntu-12-2-local_12.2.0-1_amd64.deb
|
||||
sudo dpkg -i cuda-repo-wsl-ubuntu-12-2-local_12.2.0-1_amd64.deb
|
||||
sudo cp /var/cuda-repo-wsl-ubuntu-12-2-local/cuda-*-keyring.gpg /usr/share/keyrings/
|
||||
sudo apt-get update
|
||||
sudo apt-get -y install cuda
|
||||
fi
|
||||
|
||||
if python3 -c "import pkg_resources; pkg_resources.require(open('./finetune/requirements.txt',mode='r'))" &>/dev/null; then
|
||||
echo "requirements satisfied"
|
||||
else
|
||||
python3 -m pip install -r ./finetune/requirements.txt
|
||||
fi
|
||||
|
||||
echo "loading $loadModel"
|
||||
modelInfo=$(python3 ./finetune/get_layer_and_embd.py $loadModel 6.0)
|
||||
echo $modelInfo
|
||||
if [[ $modelInfo =~ "--n_layer" ]]; then
|
||||
sudo rm -rf /root/.cache/torch_extensions
|
||||
python3 ./finetune/lora/$modelInfo $@ --proj_dir lora-models --data_type binidx --lora \
|
||||
--lora_parts=att,ffn,time,ln --strategy deepspeed_stage_2 --accelerator gpu --ds_bucket_mb 2
|
||||
else
|
||||
echo "modelInfo is invalid"
|
||||
exit 1
|
||||
fi
|
||||
@ -1,597 +0,0 @@
|
||||
# Copyright (c) 2021, EleutherAI
|
||||
# This file is based on code by the authors denoted below and has been modified from its original version.
|
||||
#
|
||||
# Copyright (c) Facebook, Inc. and its affiliates.
|
||||
#
|
||||
# This source code is licensed under the MIT license found in the
|
||||
# LICENSE file in the root directory of this source tree.
|
||||
|
||||
|
||||
# copied from fairseq/fairseq/data/indexed_dataset.py
|
||||
# Removed IndexedRawTextDataset since it relied on Fairseq dictionary
|
||||
# other slight modifications to remove fairseq dependencies
|
||||
# Added document index to index file and made it accessible.
|
||||
# An empty sentence no longer separates documents.
|
||||
|
||||
import os
|
||||
import shutil
|
||||
import struct
|
||||
from functools import lru_cache
|
||||
from itertools import accumulate
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
|
||||
|
||||
|
||||
def __best_fitting_dtype(vocab_size=None):
|
||||
if vocab_size is not None and vocab_size < 65500:
|
||||
return np.uint16
|
||||
else:
|
||||
return np.int32
|
||||
|
||||
|
||||
def infer_dataset_impl(path):
|
||||
if IndexedDataset.exists(path):
|
||||
with open(index_file_path(path), "rb") as f:
|
||||
magic = f.read(8)
|
||||
if magic == IndexedDataset._HDR_MAGIC:
|
||||
return "cached"
|
||||
elif magic == MMapIndexedDataset.Index._HDR_MAGIC[:8]:
|
||||
return "mmap"
|
||||
else:
|
||||
return None
|
||||
else:
|
||||
print(f"Dataset does not exist: {path}")
|
||||
print(
|
||||
"Path should be a basename that both .idx and .bin can be appended to get full filenames."
|
||||
)
|
||||
return None
|
||||
|
||||
|
||||
def make_builder(out_file, impl, vocab_size=None):
|
||||
if impl == "mmap":
|
||||
return MMapIndexedDatasetBuilder(
|
||||
out_file, dtype=__best_fitting_dtype(vocab_size)
|
||||
)
|
||||
else:
|
||||
return IndexedDatasetBuilder(out_file)
|
||||
|
||||
|
||||
def make_dataset(path, impl, skip_warmup=False):
|
||||
if not IndexedDataset.exists(path):
|
||||
print(f"Dataset does not exist: {path}")
|
||||
print(
|
||||
"Path should be a basename that both .idx and .bin can be appended to get full filenames."
|
||||
)
|
||||
return None
|
||||
if impl == "infer":
|
||||
impl = infer_dataset_impl(path)
|
||||
if impl == "lazy" and IndexedDataset.exists(path):
|
||||
return IndexedDataset(path)
|
||||
elif impl == "cached" and IndexedDataset.exists(path):
|
||||
return IndexedCachedDataset(path)
|
||||
elif impl == "mmap" and MMapIndexedDataset.exists(path):
|
||||
return MMapIndexedDataset(path, skip_warmup)
|
||||
print(f"Unknown dataset implementation: {impl}")
|
||||
return None
|
||||
|
||||
|
||||
def dataset_exists(path, impl):
|
||||
if impl == "mmap":
|
||||
return MMapIndexedDataset.exists(path)
|
||||
else:
|
||||
return IndexedDataset.exists(path)
|
||||
|
||||
|
||||
def read_longs(f, n):
|
||||
a = np.empty(n, dtype=np.int64)
|
||||
f.readinto(a)
|
||||
return a
|
||||
|
||||
|
||||
def write_longs(f, a):
|
||||
f.write(np.array(a, dtype=np.int64))
|
||||
|
||||
|
||||
dtypes = {
|
||||
1: np.uint8,
|
||||
2: np.int8,
|
||||
3: np.int16,
|
||||
4: np.int32,
|
||||
5: np.int64,
|
||||
6: np.float32,
|
||||
7: np.float64,
|
||||
8: np.uint16,
|
||||
}
|
||||
|
||||
|
||||
def code(dtype):
|
||||
for k in dtypes.keys():
|
||||
if dtypes[k] == dtype:
|
||||
return k
|
||||
raise ValueError(dtype)
|
||||
|
||||
|
||||
def index_file_path(prefix_path):
|
||||
return prefix_path + ".idx"
|
||||
|
||||
|
||||
def data_file_path(prefix_path):
|
||||
return prefix_path + ".bin"
|
||||
|
||||
|
||||
def create_doc_idx(sizes):
|
||||
doc_idx = [0]
|
||||
for i, s in enumerate(sizes):
|
||||
if s == 0:
|
||||
doc_idx.append(i + 1)
|
||||
return doc_idx
|
||||
|
||||
|
||||
class IndexedDataset(torch.utils.data.Dataset):
|
||||
"""Loader for IndexedDataset"""
|
||||
|
||||
_HDR_MAGIC = b"TNTIDX\x00\x00"
|
||||
|
||||
def __init__(self, path):
|
||||
super().__init__()
|
||||
self.path = path
|
||||
self.data_file = None
|
||||
self.read_index(path)
|
||||
|
||||
def read_index(self, path):
|
||||
with open(index_file_path(path), "rb") as f:
|
||||
magic = f.read(8)
|
||||
assert magic == self._HDR_MAGIC, (
|
||||
"Index file doesn't match expected format. "
|
||||
"Make sure that --dataset-impl is configured properly."
|
||||
)
|
||||
version = f.read(8)
|
||||
assert struct.unpack("<Q", version) == (1,)
|
||||
code, self.element_size = struct.unpack("<QQ", f.read(16))
|
||||
self.dtype = dtypes[code]
|
||||
self._len, self.s = struct.unpack("<QQ", f.read(16))
|
||||
self.doc_count = struct.unpack("<Q", f.read(8))
|
||||
self.dim_offsets = read_longs(f, self._len + 1)
|
||||
self.data_offsets = read_longs(f, self._len + 1)
|
||||
self.sizes = read_longs(f, self.s)
|
||||
self.doc_idx = read_longs(f, self.doc_count)
|
||||
|
||||
def read_data(self, path):
|
||||
self.data_file = open(data_file_path(path), "rb", buffering=0)
|
||||
|
||||
def check_index(self, i):
|
||||
if i < 0 or i >= self._len:
|
||||
raise IndexError("index out of range")
|
||||
|
||||
def __del__(self):
|
||||
if self.data_file:
|
||||
self.data_file.close()
|
||||
|
||||
# @lru_cache(maxsize=8)
|
||||
def __getitem__(self, idx):
|
||||
if not self.data_file:
|
||||
self.read_data(self.path)
|
||||
if isinstance(idx, int):
|
||||
i = idx
|
||||
self.check_index(i)
|
||||
tensor_size = self.sizes[self.dim_offsets[i] : self.dim_offsets[i + 1]]
|
||||
a = np.empty(tensor_size, dtype=self.dtype)
|
||||
self.data_file.seek(self.data_offsets[i] * self.element_size)
|
||||
self.data_file.readinto(a)
|
||||
return a
|
||||
elif isinstance(idx, slice):
|
||||
start, stop, step = idx.indices(len(self))
|
||||
if step != 1:
|
||||
raise ValueError("Slices into indexed_dataset must be contiguous")
|
||||
sizes = self.sizes[self.dim_offsets[start] : self.dim_offsets[stop]]
|
||||
size = sum(sizes)
|
||||
a = np.empty(size, dtype=self.dtype)
|
||||
self.data_file.seek(self.data_offsets[start] * self.element_size)
|
||||
self.data_file.readinto(a)
|
||||
offsets = list(accumulate(sizes))
|
||||
sents = np.split(a, offsets[:-1])
|
||||
return sents
|
||||
|
||||
def __len__(self):
|
||||
return self._len
|
||||
|
||||
def num_tokens(self, index):
|
||||
return self.sizes[index]
|
||||
|
||||
def size(self, index):
|
||||
return self.sizes[index]
|
||||
|
||||
@staticmethod
|
||||
def exists(path):
|
||||
return os.path.exists(index_file_path(path)) and os.path.exists(
|
||||
data_file_path(path)
|
||||
)
|
||||
|
||||
@property
|
||||
def supports_prefetch(self):
|
||||
return False # avoid prefetching to save memory
|
||||
|
||||
|
||||
class IndexedCachedDataset(IndexedDataset):
|
||||
def __init__(self, path):
|
||||
super().__init__(path)
|
||||
self.cache = None
|
||||
self.cache_index = {}
|
||||
|
||||
@property
|
||||
def supports_prefetch(self):
|
||||
return True
|
||||
|
||||
def prefetch(self, indices):
|
||||
if all(i in self.cache_index for i in indices):
|
||||
return
|
||||
if not self.data_file:
|
||||
self.read_data(self.path)
|
||||
indices = sorted(set(indices))
|
||||
total_size = 0
|
||||
for i in indices:
|
||||
total_size += self.data_offsets[i + 1] - self.data_offsets[i]
|
||||
self.cache = np.empty(total_size, dtype=self.dtype)
|
||||
ptx = 0
|
||||
self.cache_index.clear()
|
||||
for i in indices:
|
||||
self.cache_index[i] = ptx
|
||||
size = self.data_offsets[i + 1] - self.data_offsets[i]
|
||||
a = self.cache[ptx : ptx + size]
|
||||
self.data_file.seek(self.data_offsets[i] * self.element_size)
|
||||
self.data_file.readinto(a)
|
||||
ptx += size
|
||||
if self.data_file:
|
||||
# close and delete data file after prefetch so we can pickle
|
||||
self.data_file.close()
|
||||
self.data_file = None
|
||||
|
||||
# @lru_cache(maxsize=8)
|
||||
def __getitem__(self, idx):
|
||||
if isinstance(idx, int):
|
||||
i = idx
|
||||
self.check_index(i)
|
||||
tensor_size = self.sizes[self.dim_offsets[i] : self.dim_offsets[i + 1]]
|
||||
a = np.empty(tensor_size, dtype=self.dtype)
|
||||
ptx = self.cache_index[i]
|
||||
np.copyto(a, self.cache[ptx : ptx + a.size])
|
||||
return a
|
||||
elif isinstance(idx, slice):
|
||||
# Hack just to make this work, can optimizer later if necessary
|
||||
sents = []
|
||||
for i in range(*idx.indices(len(self))):
|
||||
sents.append(self[i])
|
||||
return sents
|
||||
|
||||
|
||||
class IndexedDatasetBuilder(object):
|
||||
element_sizes = {
|
||||
np.uint8: 1,
|
||||
np.int8: 1,
|
||||
np.int16: 2,
|
||||
np.int32: 4,
|
||||
np.int64: 8,
|
||||
np.float32: 4,
|
||||
np.float64: 8,
|
||||
}
|
||||
|
||||
def __init__(self, out_file, dtype=np.int32):
|
||||
self.out_file = open(out_file, "wb")
|
||||
self.dtype = dtype
|
||||
self.data_offsets = [0]
|
||||
self.dim_offsets = [0]
|
||||
self.sizes = []
|
||||
self.element_size = self.element_sizes[self.dtype]
|
||||
self.doc_idx = [0]
|
||||
|
||||
def add_item(self, np_array):
|
||||
assert isinstance(np_array, np.ndarray) and np_array.dtype == self.dtype
|
||||
bytes = self.out_file.write(np_array)
|
||||
self.data_offsets.append(self.data_offsets[-1] + bytes / self.element_size)
|
||||
for s in np_array.shape:
|
||||
self.sizes.append(s)
|
||||
self.dim_offsets.append(self.dim_offsets[-1] + len(np_array.shape))
|
||||
|
||||
def end_document(self):
|
||||
self.doc_idx.append(len(self.sizes))
|
||||
|
||||
def merge_file_(self, another_file):
|
||||
index = IndexedDataset(another_file)
|
||||
assert index.dtype == self.dtype
|
||||
|
||||
begin = self.data_offsets[-1]
|
||||
for offset in index.data_offsets[1:]:
|
||||
self.data_offsets.append(begin + offset)
|
||||
self.sizes.extend(index.sizes)
|
||||
begin = self.dim_offsets[-1]
|
||||
for dim_offset in index.dim_offsets[1:]:
|
||||
self.dim_offsets.append(begin + dim_offset)
|
||||
|
||||
with open(data_file_path(another_file), "rb") as f:
|
||||
while True:
|
||||
data = f.read(1024)
|
||||
if data:
|
||||
self.out_file.write(data)
|
||||
else:
|
||||
break
|
||||
|
||||
def finalize(self, index_file):
|
||||
self.out_file.close()
|
||||
index = open(index_file, "wb")
|
||||
index.write(b"TNTIDX\x00\x00")
|
||||
index.write(struct.pack("<Q", 1))
|
||||
index.write(struct.pack("<QQ", code(self.dtype), self.element_size))
|
||||
index.write(struct.pack("<QQ", len(self.data_offsets) - 1, len(self.sizes)))
|
||||
index.write(struct.pack("<Q", len(self.doc_idx)))
|
||||
write_longs(index, self.dim_offsets)
|
||||
write_longs(index, self.data_offsets)
|
||||
write_longs(index, self.sizes)
|
||||
write_longs(index, self.doc_idx)
|
||||
index.close()
|
||||
|
||||
|
||||
def _warmup_mmap_file(path):
|
||||
with open(path, "rb") as stream:
|
||||
while stream.read(100 * 1024 * 1024):
|
||||
pass
|
||||
|
||||
|
||||
class MMapIndexedDataset(torch.utils.data.Dataset):
|
||||
class Index(object):
|
||||
_HDR_MAGIC = b"MMIDIDX\x00\x00"
|
||||
|
||||
@classmethod
|
||||
def writer(cls, path, dtype):
|
||||
class _Writer(object):
|
||||
def __enter__(self):
|
||||
self._file = open(path, "wb")
|
||||
|
||||
# Write Magic string so we can check the file format then opening it again.
|
||||
self._file.write(cls._HDR_MAGIC)
|
||||
# Write version number
|
||||
# Little endian unsigned 64 Bit integer
|
||||
self._file.write(struct.pack("<Q", 1))
|
||||
# Little endian unsigned 8 Bit integer
|
||||
self._file.write(struct.pack("<B", code(dtype)))
|
||||
|
||||
return self
|
||||
|
||||
@staticmethod
|
||||
def _get_pointers(sizes):
|
||||
pointers = np.zeros(len(sizes), dtype=np.int64)
|
||||
sizes = np.array(sizes, dtype=np.int64)
|
||||
|
||||
np.cumsum(sizes[:-1], out=pointers[1:])
|
||||
pointers = pointers * dtype().itemsize
|
||||
return pointers
|
||||
|
||||
def write(self, sizes, doc_idx):
|
||||
pointers = self._get_pointers(sizes)
|
||||
|
||||
# Little endian unsigned 64 Bit integer
|
||||
self._file.write(struct.pack("<Q", len(sizes)))
|
||||
# Little endian unsigned 64 Bit integer
|
||||
self._file.write(struct.pack("<Q", len(doc_idx)))
|
||||
|
||||
sizes = np.array(sizes, dtype=np.int32)
|
||||
self._file.write(sizes.tobytes(order="C"))
|
||||
del sizes
|
||||
|
||||
pointers = np.array(pointers, dtype=np.int64)
|
||||
self._file.write(pointers.tobytes(order="C"))
|
||||
del pointers
|
||||
|
||||
doc_idx = np.array(doc_idx, dtype=np.int64)
|
||||
self._file.write(doc_idx.tobytes(order="C"))
|
||||
|
||||
def __exit__(self, exc_type, exc_val, exc_tb):
|
||||
self._file.close()
|
||||
|
||||
return _Writer()
|
||||
|
||||
def __init__(self, path, skip_warmup=False):
|
||||
with open(path, "rb") as stream:
|
||||
magic_test = stream.read(9)
|
||||
assert self._HDR_MAGIC == magic_test, (
|
||||
"Index file doesn't match expected format. "
|
||||
"Make sure that --dataset-impl is configured properly."
|
||||
)
|
||||
# Little endian unsigned 64 Bit integer
|
||||
version = struct.unpack("<Q", stream.read(8))
|
||||
assert (1,) == version
|
||||
|
||||
# Little endian unsigned 8 Bit integer
|
||||
(dtype_code,) = struct.unpack("<B", stream.read(1))
|
||||
self._dtype = dtypes[dtype_code]
|
||||
self._dtype_size = self._dtype().itemsize
|
||||
|
||||
self._len = struct.unpack("<Q", stream.read(8))[0]
|
||||
self._doc_count = struct.unpack("<Q", stream.read(8))[0]
|
||||
offset = stream.tell()
|
||||
|
||||
if not skip_warmup:
|
||||
print(" warming up index mmap file...")
|
||||
_warmup_mmap_file(path)
|
||||
|
||||
self._bin_buffer_mmap = np.memmap(path, mode="r", order="C")
|
||||
self._bin_buffer = memoryview(self._bin_buffer_mmap)
|
||||
print(" reading sizes...")
|
||||
self._sizes = np.frombuffer(
|
||||
self._bin_buffer, dtype=np.int32, count=self._len, offset=offset
|
||||
)
|
||||
print(" reading pointers...")
|
||||
self._pointers = np.frombuffer(
|
||||
self._bin_buffer,
|
||||
dtype=np.int64,
|
||||
count=self._len,
|
||||
offset=offset + self._sizes.nbytes,
|
||||
)
|
||||
print(" reading document index...")
|
||||
self._doc_idx = np.frombuffer(
|
||||
self._bin_buffer,
|
||||
dtype=np.int64,
|
||||
count=self._doc_count,
|
||||
offset=offset + self._sizes.nbytes + self._pointers.nbytes,
|
||||
)
|
||||
|
||||
def __del__(self):
|
||||
self._bin_buffer_mmap._mmap.close()
|
||||
del self._bin_buffer_mmap
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
return self._dtype
|
||||
|
||||
@property
|
||||
def sizes(self):
|
||||
return self._sizes
|
||||
|
||||
@property
|
||||
def doc_idx(self):
|
||||
return self._doc_idx
|
||||
|
||||
@lru_cache(maxsize=8)
|
||||
def __getitem__(self, i):
|
||||
return self._pointers[i], self._sizes[i]
|
||||
|
||||
def __len__(self):
|
||||
return self._len
|
||||
|
||||
def __init__(self, path, skip_warmup=False):
|
||||
super().__init__()
|
||||
|
||||
self._path = None
|
||||
self._index = None
|
||||
self._bin_buffer = None
|
||||
|
||||
self._do_init(path, skip_warmup)
|
||||
|
||||
def __getstate__(self):
|
||||
return self._path
|
||||
|
||||
def __setstate__(self, state):
|
||||
self._do_init(state)
|
||||
|
||||
def _do_init(self, path, skip_warmup):
|
||||
self._path = path
|
||||
self._index = self.Index(index_file_path(self._path), skip_warmup)
|
||||
|
||||
if not skip_warmup:
|
||||
print(" warming up data mmap file...")
|
||||
_warmup_mmap_file(data_file_path(self._path))
|
||||
print(" creating numpy buffer of mmap...")
|
||||
self._bin_buffer_mmap = np.memmap(
|
||||
data_file_path(self._path), mode="r", order="C"
|
||||
)
|
||||
print(" creating memory view of numpy buffer...")
|
||||
self._bin_buffer = memoryview(self._bin_buffer_mmap)
|
||||
|
||||
def __del__(self):
|
||||
self._bin_buffer_mmap._mmap.close()
|
||||
del self._bin_buffer_mmap
|
||||
del self._index
|
||||
|
||||
def __len__(self):
|
||||
return len(self._index)
|
||||
|
||||
# @lru_cache(maxsize=8)
|
||||
def __getitem__(self, idx):
|
||||
if isinstance(idx, int):
|
||||
ptr, size = self._index[idx]
|
||||
np_array = np.frombuffer(
|
||||
self._bin_buffer, dtype=self._index.dtype, count=size, offset=ptr
|
||||
)
|
||||
return np_array
|
||||
elif isinstance(idx, slice):
|
||||
start, stop, step = idx.indices(len(self))
|
||||
if step != 1:
|
||||
raise ValueError("Slices into indexed_dataset must be contiguous")
|
||||
ptr = self._index._pointers[start]
|
||||
sizes = self._index._sizes[idx]
|
||||
offsets = list(accumulate(sizes))
|
||||
total_size = sum(sizes)
|
||||
np_array = np.frombuffer(
|
||||
self._bin_buffer, dtype=self._index.dtype, count=total_size, offset=ptr
|
||||
)
|
||||
sents = np.split(np_array, offsets[:-1])
|
||||
return sents
|
||||
|
||||
def get(self, idx, offset=0, length=None):
|
||||
"""Retrieves a single item from the dataset with the option to only
|
||||
return a portion of the item.
|
||||
|
||||
get(idx) is the same as [idx] but get() does not support slicing.
|
||||
"""
|
||||
ptr, size = self._index[idx]
|
||||
if length is None:
|
||||
length = size - offset
|
||||
ptr += offset * np.dtype(self._index.dtype).itemsize
|
||||
np_array = np.frombuffer(
|
||||
self._bin_buffer, dtype=self._index.dtype, count=length, offset=ptr
|
||||
)
|
||||
return np_array
|
||||
|
||||
@property
|
||||
def sizes(self):
|
||||
return self._index.sizes
|
||||
|
||||
@property
|
||||
def doc_idx(self):
|
||||
return self._index.doc_idx
|
||||
|
||||
def get_doc_idx(self):
|
||||
return self._index._doc_idx
|
||||
|
||||
def set_doc_idx(self, doc_idx_):
|
||||
self._index._doc_idx = doc_idx_
|
||||
|
||||
@property
|
||||
def supports_prefetch(self):
|
||||
return False
|
||||
|
||||
@staticmethod
|
||||
def exists(path):
|
||||
return os.path.exists(index_file_path(path)) and os.path.exists(
|
||||
data_file_path(path)
|
||||
)
|
||||
|
||||
|
||||
class MMapIndexedDatasetBuilder(object):
|
||||
def __init__(self, out_file, dtype=np.int64):
|
||||
self._data_file = open(out_file, "wb")
|
||||
self._dtype = dtype
|
||||
self._sizes = []
|
||||
self._doc_idx = [0]
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
return self._dtype
|
||||
|
||||
def add_item(self, np_array):
|
||||
assert isinstance(np_array, np.ndarray) and np_array.dtype == self.dtype
|
||||
self._data_file.write(np_array.tobytes(order="C"))
|
||||
self._sizes.append(np_array.size)
|
||||
|
||||
def end_document(self):
|
||||
self._doc_idx.append(len(self._sizes))
|
||||
|
||||
def merge_file_(self, another_file):
|
||||
# Concatenate index
|
||||
index = MMapIndexedDataset.Index(index_file_path(another_file))
|
||||
assert index.dtype == self._dtype
|
||||
|
||||
for size in index.sizes:
|
||||
self._sizes.append(size)
|
||||
|
||||
# Concatenate data
|
||||
with open(data_file_path(another_file), "rb") as f:
|
||||
shutil.copyfileobj(f, self._data_file)
|
||||
|
||||
def finalize(self, index_file):
|
||||
self._data_file.close()
|
||||
|
||||
with MMapIndexedDataset.Index.writer(index_file, self._dtype) as index:
|
||||
index.write(self._sizes, self._doc_idx)
|
||||
@ -1,251 +0,0 @@
|
||||
# Copyright (c) 2021, EleutherAI
|
||||
# This file is based on code by the authors denoted below and has been modified from its original version.
|
||||
#
|
||||
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
"""Processing data for pretraining."""
|
||||
|
||||
import os
|
||||
import sys
|
||||
|
||||
sys.path.append(os.path.dirname(os.path.realpath(__file__)))
|
||||
|
||||
import argparse
|
||||
import multiprocessing
|
||||
|
||||
import lm_dataformat as lmd
|
||||
import numpy as np
|
||||
|
||||
sys.path.append(
|
||||
os.path.abspath(os.path.join(os.path.dirname(__file__), os.path.pardir))
|
||||
)
|
||||
import time
|
||||
import tqdm
|
||||
import ftfy
|
||||
|
||||
from tokenizer import build_tokenizer
|
||||
import indexed_dataset
|
||||
from threading import Semaphore
|
||||
|
||||
|
||||
class Encoder(object):
|
||||
def __init__(self, args):
|
||||
self.args = args
|
||||
|
||||
def initializer(self):
|
||||
# Use Encoder class as a container for global data
|
||||
Encoder.tokenizer = build_tokenizer(self.args)
|
||||
|
||||
def encode(self, text):
|
||||
if self.args.ftfy:
|
||||
text = ftfy.fix_text(text)
|
||||
ids = {}
|
||||
for key in self.args.jsonl_keys:
|
||||
doc_ids = []
|
||||
text_ids = Encoder.tokenizer.tokenize(text)
|
||||
if len(text_ids) > 0:
|
||||
doc_ids.append(text_ids)
|
||||
if self.args.append_eod:
|
||||
doc_ids[-1].append(Encoder.tokenizer.eod)
|
||||
ids[key] = doc_ids
|
||||
return ids, len(text)
|
||||
|
||||
|
||||
def get_args():
|
||||
parser = argparse.ArgumentParser()
|
||||
group = parser.add_argument_group(title="input data")
|
||||
group.add_argument(
|
||||
"--input",
|
||||
type=str,
|
||||
required=True,
|
||||
help="Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated "
|
||||
"list",
|
||||
)
|
||||
group.add_argument(
|
||||
"--jsonl-keys",
|
||||
nargs="+",
|
||||
default=["text"],
|
||||
help="space separate listed of keys to extract from jsonl. Defa",
|
||||
)
|
||||
group.add_argument(
|
||||
"--num-docs",
|
||||
default=None,
|
||||
help="Optional: Number of documents in the input data (if known) for an accurate progress bar.",
|
||||
type=int,
|
||||
)
|
||||
group = parser.add_argument_group(title="tokenizer")
|
||||
group.add_argument(
|
||||
"--tokenizer-type",
|
||||
type=str,
|
||||
required=True,
|
||||
choices=[
|
||||
"HFGPT2Tokenizer",
|
||||
"HFTokenizer",
|
||||
"GPT2BPETokenizer",
|
||||
"CharLevelTokenizer",
|
||||
"TiktokenTokenizer",
|
||||
"RWKVTokenizer",
|
||||
],
|
||||
help="What type of tokenizer to use.",
|
||||
)
|
||||
group.add_argument(
|
||||
"--vocab-file", type=str, default=None, help="Path to the vocab file"
|
||||
)
|
||||
group.add_argument(
|
||||
"--merge-file",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Path to the BPE merge file (if necessary).",
|
||||
)
|
||||
group.add_argument(
|
||||
"--append-eod",
|
||||
action="store_true",
|
||||
help="Append an <eod> token to the end of a document.",
|
||||
)
|
||||
group.add_argument("--ftfy", action="store_true", help="Use ftfy to clean text")
|
||||
group = parser.add_argument_group(title="output data")
|
||||
group.add_argument(
|
||||
"--output-prefix",
|
||||
type=str,
|
||||
required=True,
|
||||
help="Path to binary output file without suffix",
|
||||
)
|
||||
group.add_argument(
|
||||
"--dataset-impl",
|
||||
type=str,
|
||||
default="mmap",
|
||||
choices=["lazy", "cached", "mmap"],
|
||||
help="Dataset implementation to use. Default: mmap",
|
||||
)
|
||||
|
||||
group = parser.add_argument_group(title="runtime")
|
||||
group.add_argument(
|
||||
"--workers", type=int, default=1, help="Number of worker processes to launch"
|
||||
)
|
||||
group.add_argument(
|
||||
"--log-interval",
|
||||
type=int,
|
||||
default=100,
|
||||
help="Interval between progress updates",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
args.keep_empty = False
|
||||
|
||||
# some default/dummy values for the tokenizer
|
||||
args.rank = 0
|
||||
args.make_vocab_size_divisible_by = 128
|
||||
args.model_parallel_size = 1
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def yield_from_files(fnames: list, semaphore):
|
||||
"""
|
||||
Iterator over input documents using lm_dataformat. Should be able to handle jsons / texts /
|
||||
other compressed formats. Also filters out empty documents.
|
||||
|
||||
:param fnames: list of filenames
|
||||
"""
|
||||
|
||||
def yielder(fname, semaphore):
|
||||
for f in filter(lambda x: x, lmd.Reader(fname).stream_data()):
|
||||
semaphore.acquire()
|
||||
yield f
|
||||
|
||||
for fname in fnames:
|
||||
semaphore.acquire()
|
||||
|
||||
yield from yielder(fname, semaphore)
|
||||
|
||||
|
||||
def main():
|
||||
args = get_args()
|
||||
encoder = Encoder(args)
|
||||
tokenizer = build_tokenizer(args)
|
||||
print(f"Vocab size: {tokenizer.vocab_size}")
|
||||
print(f"Output prefix: {args.output_prefix}")
|
||||
|
||||
# build a semaphore object to stop `yield_from_files` from getting ahead of encoder.encode and
|
||||
# hence building up memory
|
||||
semaphore = Semaphore(10000 + args.workers)
|
||||
|
||||
# use multiprocessing to iterate over input documents
|
||||
fin = yield_from_files(args.input.split(","), semaphore)
|
||||
|
||||
if args.workers > 1:
|
||||
pool = multiprocessing.Pool(args.workers, initializer=encoder.initializer)
|
||||
encoded_docs = pool.imap(encoder.encode, fin, chunksize=25)
|
||||
else:
|
||||
encoder.initializer()
|
||||
encoded_docs = (encoder.encode(doc) for doc in fin)
|
||||
|
||||
# make a dataset builder for each key in args.jsonl_keys
|
||||
# each key will output to a different file beginning with args.output_prefix
|
||||
output_bin_files = {}
|
||||
output_idx_files = {}
|
||||
builders = {}
|
||||
for key in args.jsonl_keys:
|
||||
output_bin_files[key] = "{}_{}_{}.bin".format(
|
||||
args.output_prefix, key, "document"
|
||||
)
|
||||
output_idx_files[key] = "{}_{}_{}.idx".format(
|
||||
args.output_prefix, key, "document"
|
||||
)
|
||||
builders[key] = indexed_dataset.make_builder(
|
||||
output_bin_files[key],
|
||||
impl=args.dataset_impl,
|
||||
vocab_size=tokenizer.vocab_size,
|
||||
)
|
||||
|
||||
# actually do tokenization
|
||||
proc_start = time.time()
|
||||
total_bytes_processed = 0
|
||||
pbar = tqdm.tqdm()
|
||||
for i, (doc, bytes_processed) in enumerate(encoded_docs, start=1):
|
||||
total_bytes_processed += bytes_processed
|
||||
|
||||
# release semaphore so `yield_from_files` can add another file to the buffer
|
||||
semaphore.release()
|
||||
|
||||
# add each tokenized document / sentence
|
||||
for key, sentences in doc.items():
|
||||
for sentence in sentences:
|
||||
builders[key].add_item(np.array(sentence, dtype=builders[key].dtype))
|
||||
# separate with eos token
|
||||
builders[key].end_document()
|
||||
|
||||
# log progress
|
||||
if i % args.log_interval == 0:
|
||||
current = time.time()
|
||||
elapsed = current - proc_start
|
||||
mbs = total_bytes_processed / elapsed / 1024 / 1024
|
||||
pbar.set_description(
|
||||
f"Processed {i}{'' if args.num_docs is None else '/' + str(args.num_docs)} documents ({i / elapsed:0.2f} docs/s, {mbs:0.2f} MB/s)."
|
||||
)
|
||||
if i != 0:
|
||||
pbar.update(args.log_interval)
|
||||
|
||||
# save output file
|
||||
for key in args.jsonl_keys:
|
||||
builders[key].finalize(output_idx_files[key])
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
try:
|
||||
main()
|
||||
except Exception as e:
|
||||
print(e)
|
||||
with open("error.txt", "w") as f:
|
||||
f.write(str(e))
|
||||
@ -1,232 +0,0 @@
|
||||
########################################################################################################
|
||||
# The RWKV Language Model - https://github.com/BlinkDL/RWKV-LM
|
||||
# Source: https://github.com/BlinkDL/ChatRWKV/blob/main/tokenizer/rwkv_tokenizer.py
|
||||
########################################################################################################
|
||||
|
||||
import os, sys, time, random
|
||||
|
||||
print('''
|
||||
#######################################################################################################################
|
||||
|
||||
This tokenizer is not used in any RWKV models yet. I plan to use it for the future multilang RWKV models.
|
||||
|
||||
Benefits:
|
||||
|
||||
* Good support of most languages, from European to CJK to Arabic and Hindi and more.
|
||||
|
||||
* Clean vocab. Good for code too. Vocab size = 65525 (use 0 for <|endoftext|>).
|
||||
|
||||
* Good at numbers: the numerical tokens are '0'~'9', '10'~'99', ' 0'~' 9', ' 10'~' 99'.
|
||||
|
||||
* Very easy tokenization:
|
||||
|
||||
** The input text must be in UTF-8.
|
||||
|
||||
** Greedy encoding: always pick the longest (in bytes) token (with the highest id) that matches your UTF-8 bytes.
|
||||
|
||||
* The tokenization result is surprisingly good, because the vocab respects word boundaries and UTF-8 boundaries.
|
||||
|
||||
For 10x faster speed:
|
||||
mypyc rwkv_tokenizer.py
|
||||
python3 -c "import rwkv_tokenizer"
|
||||
|
||||
#######################################################################################################################
|
||||
''')
|
||||
|
||||
########################################################################################################
|
||||
# Tokenizer #1 (reference, naive, slow)
|
||||
########################################################################################################
|
||||
|
||||
class RWKV_TOKENIZER():
|
||||
table = None # : list[list[list[bytes]]] = None
|
||||
good = None # : list[set[int]]
|
||||
wlen = None # : list[int]
|
||||
def __init__(self, file_name):
|
||||
self.vocab_size = 65525
|
||||
self.idx2token = {}
|
||||
sorted = [] # must be already sorted
|
||||
lines = open(file_name, "r", encoding="utf-8").readlines()
|
||||
for l in lines:
|
||||
idx = int(l[:l.index(' ')])
|
||||
x = eval(l[l.index(' '):l.rindex(' ')])
|
||||
x = x.encode("utf-8") if isinstance(x, str) else x
|
||||
assert isinstance(x, bytes)
|
||||
assert len(x) == int(l[l.rindex(' '):])
|
||||
sorted += [x]
|
||||
self.idx2token[idx] = x
|
||||
|
||||
self.token2idx = {}
|
||||
for k, v in self.idx2token.items():
|
||||
self.token2idx[v] = int(k)
|
||||
|
||||
# precompute some tables for fast matching
|
||||
self.table = [[[] for j in range(256)] for i in range(256)]
|
||||
self.good = [set() for i in range(256)]
|
||||
self.wlen = [0 for i in range(256)]
|
||||
|
||||
for i in reversed(range(len(sorted))): # reverse order - match longer tokens first
|
||||
s = sorted[i]
|
||||
if len(s) >= 2:
|
||||
s0 = int(s[0])
|
||||
s1 = int(s[1])
|
||||
self.table[s0][s1] += [s]
|
||||
self.wlen[s0] = max(self.wlen[s0], len(s))
|
||||
self.good[s0].add(s1)
|
||||
|
||||
def encodeBytes(self, src: bytes):
|
||||
src_len: int = len(src)
|
||||
tokens = []
|
||||
i: int = 0
|
||||
while i < src_len:
|
||||
s: bytes = src[i : i + 1]
|
||||
|
||||
if i < src_len - 1:
|
||||
s1: int = int(src[i + 1])
|
||||
s0: int = int(src[i])
|
||||
if s1 in self.good[s0]:
|
||||
sss: bytes = src[i : i + self.wlen[s0]]
|
||||
try:
|
||||
s = next(filter(sss.startswith, self.table[s0][s1]))
|
||||
except:
|
||||
pass
|
||||
tokens.append(self.token2idx[s])
|
||||
i += len(s)
|
||||
|
||||
return tokens
|
||||
|
||||
def decodeBytes(self, tokens):
|
||||
return b''.join(map(lambda i: self.idx2token[i], tokens))
|
||||
|
||||
def encode(self, src: str):
|
||||
return self.encodeBytes(src.encode("utf-8"))
|
||||
|
||||
def decode(self, tokens):
|
||||
return self.decodeBytes(tokens).decode('utf-8')
|
||||
|
||||
def token_to_id(self, token):
|
||||
return self.token2idx[token]
|
||||
|
||||
def get_vocab_size(self):
|
||||
return self.vocab_size
|
||||
|
||||
def get_vocab(self):
|
||||
return self.idx2token
|
||||
|
||||
def printTokens(self, tokens):
|
||||
for i in tokens:
|
||||
s = self.idx2token[i]
|
||||
try:
|
||||
s = s.decode('utf-8')
|
||||
except:
|
||||
pass
|
||||
print(f'{repr(s)}{i}', end=' ')
|
||||
# print(repr(s), i)
|
||||
print()
|
||||
|
||||
########################################################################################################
|
||||
# Tokenizer #2 (trie, faster) https://github.com/TkskKurumi/ChatRWKV-TRIE-Tokenizer
|
||||
########################################################################################################
|
||||
|
||||
class TRIE:
|
||||
__slots__ = tuple("ch,to,values,front".split(","))
|
||||
to:list
|
||||
values:set
|
||||
def __init__(self, front=None, ch=None):
|
||||
self.ch = ch
|
||||
self.to = [None for ch in range(256)]
|
||||
self.values = set()
|
||||
self.front = front
|
||||
|
||||
def __repr__(self):
|
||||
fr = self
|
||||
ret = []
|
||||
while(fr!=None):
|
||||
if(fr.ch!=None):
|
||||
ret.append(fr.ch)
|
||||
fr = fr.front
|
||||
return "<TRIE %s %s>"%(ret[::-1], self.values)
|
||||
|
||||
def add(self, key:bytes, idx:int=0, val=None):
|
||||
if(idx == len(key)):
|
||||
if(val is None):
|
||||
val = key
|
||||
self.values.add(val)
|
||||
return self
|
||||
ch = key[idx]
|
||||
if(self.to[ch] is None):
|
||||
self.to[ch] = TRIE(front=self, ch=ch)
|
||||
return self.to[ch].add(key, idx=idx+1, val=val)
|
||||
|
||||
def find_longest(self, key:bytes, idx:int=0):
|
||||
u:TRIE = self
|
||||
ch:int = key[idx]
|
||||
|
||||
while(u.to[ch] is not None):
|
||||
u = u.to[ch]
|
||||
idx += 1
|
||||
if(u.values):
|
||||
ret = idx, u, u.values
|
||||
if(idx==len(key)):
|
||||
break
|
||||
ch = key[idx]
|
||||
return ret
|
||||
|
||||
class TRIE_TOKENIZER():
|
||||
def __init__(self, file_name):
|
||||
self.vocab_size = 65525
|
||||
self.idx2token = {}
|
||||
sorted = [] # must be already sorted
|
||||
with open(file_name, "r", encoding="utf-8") as f:
|
||||
lines = f.readlines()
|
||||
for l in lines:
|
||||
idx = int(l[:l.index(' ')])
|
||||
x = eval(l[l.index(' '):l.rindex(' ')])
|
||||
x = x.encode("utf-8") if isinstance(x, str) else x
|
||||
assert isinstance(x, bytes)
|
||||
assert len(x) == int(l[l.rindex(' '):])
|
||||
sorted += [x]
|
||||
self.idx2token[idx] = x
|
||||
|
||||
self.token2idx = {}
|
||||
for k,v in self.idx2token.items():
|
||||
self.token2idx[v] = int(k)
|
||||
|
||||
self.root = TRIE()
|
||||
for t, i in self.token2idx.items():
|
||||
_ = self.root.add(t, val=(t, i))
|
||||
|
||||
def encodeBytes(self, src:bytes):
|
||||
idx:int = 0
|
||||
tokens = []
|
||||
while (idx < len(src)):
|
||||
_idx:int = idx
|
||||
idx, _, values = self.root.find_longest(src, idx)
|
||||
assert(idx != _idx)
|
||||
_, token = next(iter(values))
|
||||
tokens.append(token)
|
||||
return tokens
|
||||
|
||||
def decodeBytes(self, tokens):
|
||||
return b''.join(map(lambda i: self.idx2token[i], tokens))
|
||||
|
||||
def encode(self, src):
|
||||
return self.encodeBytes(src.encode("utf-8"))
|
||||
|
||||
def decode(self, tokens):
|
||||
return self.decodeBytes(tokens).decode('utf-8')
|
||||
|
||||
def get_vocab_size(self):
|
||||
return self.vocab_size
|
||||
|
||||
def get_vocab(self):
|
||||
return self.idx2token
|
||||
|
||||
def printTokens(self, tokens):
|
||||
for i in tokens:
|
||||
s = self.idx2token[i]
|
||||
try:
|
||||
s = s.decode('utf-8')
|
||||
except:
|
||||
pass
|
||||
print(f'{repr(s)}{i}', end=' ')
|
||||
print()
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user